TL;DR
On TPC-H SF100, a single 59-core ClickHouse Cloud node is competitive on raw runtime against Snowflake, Databricks, BigQuery, and Redshift, while ranking first on cost-performance. At SF10, it runs all 22 queries for less than one cent.
ClickHouse Cloud joins the TPC-H comparison #
We ran the full TPC-H workload on ClickHouse Cloud, Snowflake, Databricks, BigQuery, and Redshift.
At SF100, that is 100 GB of data, 866M rows, and 22 join-heavy analytical queries.
The result: ClickHouse Cloud was competitive on raw runtime and ranked first on cost-performance.
At SF10, the full workload ran in 2.9 seconds for $0.009 in compute cost.
Less than one cent.
This post shows the benchmark results. The companion post explains the two years of join engineering behind them.
Benchmark setup #
All benchmark scripts, queries, and result files are available in a public GitHub repository, so the results can be reproduced and inspected.
Dataset and runtime measurement #
The main comparison uses TPC-H SF100: 22 queries over 866M rows.
For runtime measurements, we distinguish between cold and hot runs:
Cold runs: We did not systematically compare cold-start performance. Cloud warehouses exhibit different caching behavior, and most do not let users reliably reset OS-level page cache or restart compute on demand. Because cold conditions cannot be standardized, cold results would not be fair or reproducible.
Hot runs: Each query was run three times with result caching disabled. Charts use the fastest hot run. Result caching was disabled, so the benchmark measures query execution, not returning a previously cached result.
Compared systems #
For ClickHouse Cloud, we used one fixed configuration: a single AWS compute node with 59 cores. For the other systems, we selected practical warehouse or serverless capacity configurations, and discuss the closest hardware comparisons later.
- Snowflake: Small, Medium, Large, and 4X-Large Gen2 warehouses
- Databricks (SQL Serverless): Small, Medium, Large, and 4X-Large warehouses
- BigQuery: 2,000 slots
- Redshift Serverless: 128 RPUs
Cost calculations #
For cost calculations, we use the same methodology introduced in our earlier posts on cloud data warehouse billing and cost-performance. We apply each vendor’s public billing model to the measured query runtimes, assume perfect per-second compute billing for all systems, and use Enterprise-tier pricing in comparable US East regions: AWS us-east for supported systems and GCP us-east for BigQuery.
With that setup, we first look at raw hot runtime.
TPC-H SF100: raw hot runtime #
TPC-H SF100 consists of 100 GB of data, 866M rows, and 22 join-heavy analytical queries.
In the diagram below, each bar sums the fastest of three runs for each of the 22 TPC-H queries. Lower is better.
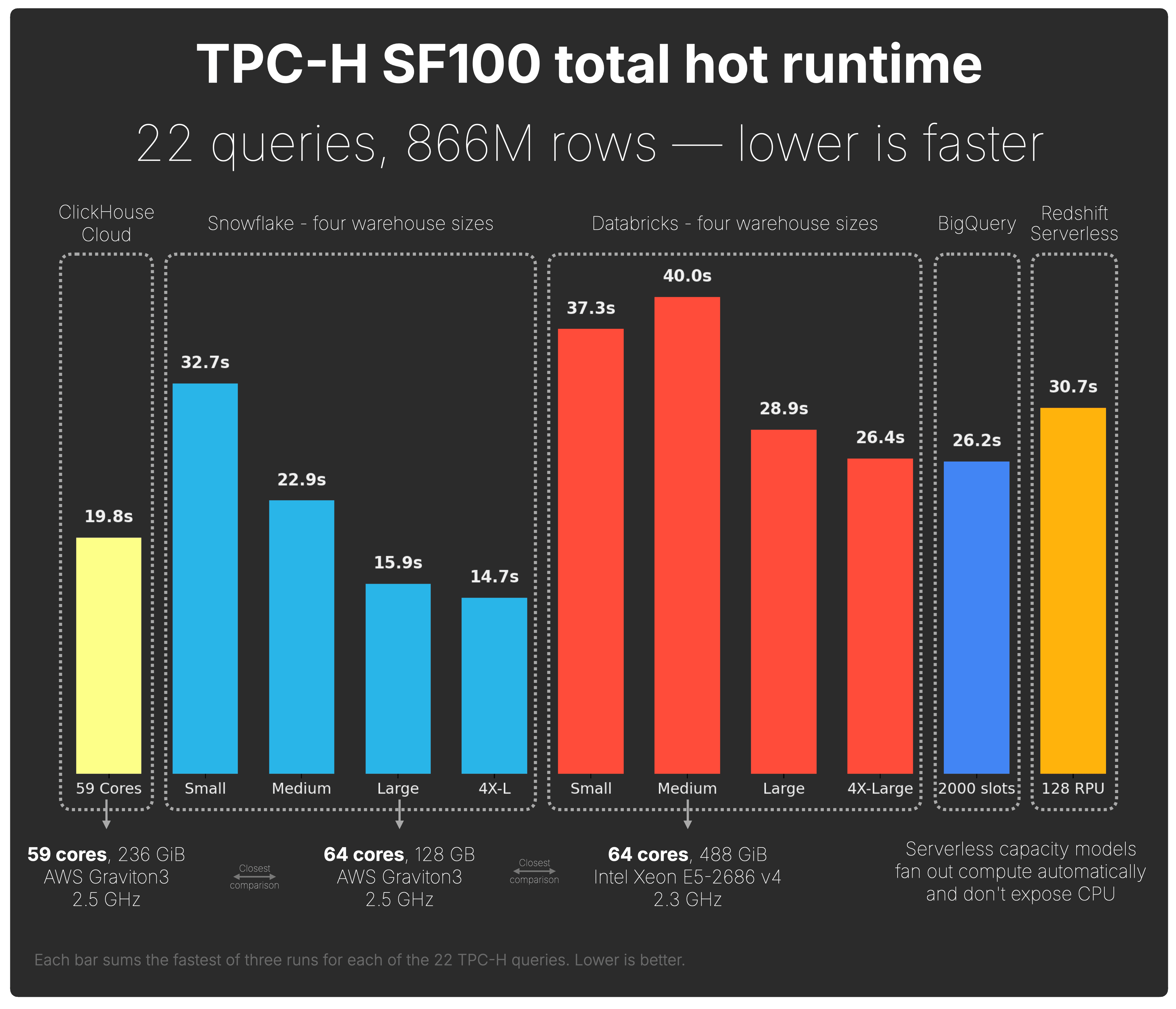
ClickHouse Cloud completed the workload in 19.8s.
Snowflake finished in 32.7s on a Small warehouse, 22.9s on Medium, 15.9s on Large, and 14.7s on 4X-Large.
Databricks finished in 37.3s on a Small warehouse, 40.0s on Medium, 28.9s on Large, and 26.4s on 4X-Large.
BigQuery finished in 26.2s with 2,000 slots.
Redshift Serverless finished in 30.7s with 128 RPUs.
Note that the compute behind these numbers is not identical across systems. ClickHouse Cloud used one Graviton3 compute node with 59 cores and 236 GiB of memory.
For Snowflake and Databricks, we tested multiple warehouse sizes to show how runtime changes as compute scales. The closest hardware reference points to ClickHouse Cloud’s 59-core node are Snowflake Large Gen2, understood to use 64 AWS Graviton3 cores and 128 GB of memory, and Databricks Large, which maps to 64 Intel Xeon E5-2686 v4 cores and 488 GiB of memory in the documented classic compute-plane sizing. We used Databricks SQL Serverless for the benchmark, but the published warehouse sizing provides a useful reference point.
Also note that systems with serverless capacity models automatically fan out query work across large, pre-provisioned compute pools: BigQuery used up to 2,000 slots in this benchmark, and Redshift Serverless used 128 RPUs.
With one 59-core compute node, ClickHouse Cloud is competitive on raw TPC-H SF100 runtime against major cloud data warehouses, including comparable 64-core Snowflake and Databricks warehouse configurations and serverless engines that automatically fan out across large pre-provisioned compute pools far beyond 59 cores.
Runtime is only half the story #
As mentioned above, it is hard to directly compare the compute each system used to run the TPC-H SF100 workload.
But we can directly compare the cost of running the workload.
The chart below keeps the same runtime bars and overlays the hot-run compute cost using each vendor’s public billing model.
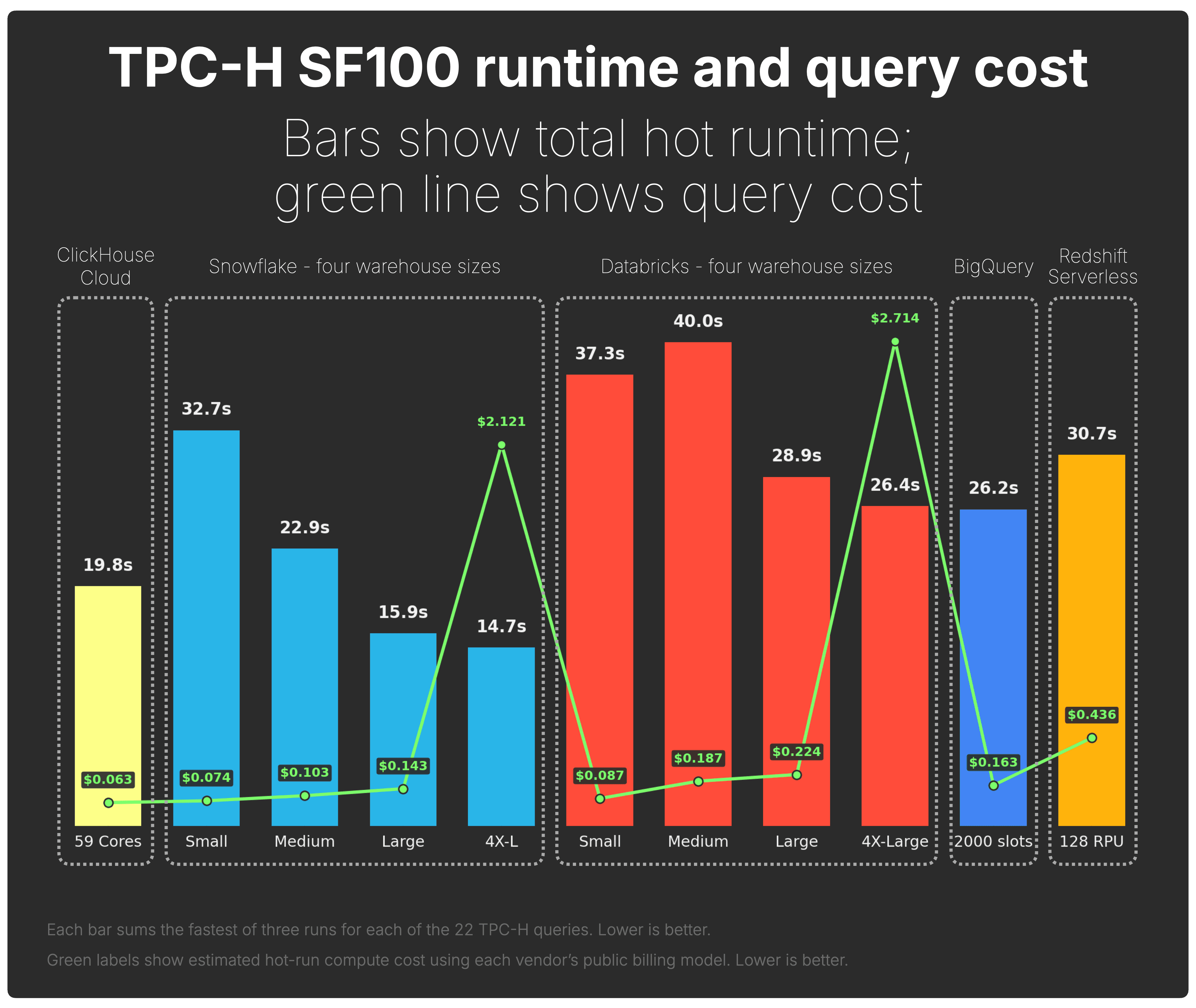
ClickHouse Cloud finished the workload in 19.8s with a compute cost of $0.063.
Snowflake Large was faster at 15.9s, but cost $0.143. Snowflake 4X-Large was faster again at 14.7s, but cost $2.121. Databricks ranged from $0.087 to $2.714. BigQuery finished in 26.2s for $0.163, and Redshift Serverless in 30.7s for $0.436.
The section below collapses runtime and cost into a single cost-performance score.
TPC-H SF100: cost-performance ranking #
The previous chart showed runtime and cost side by side. Now we combine both into a simple cost-performance score:
cost-performance score = compute cost × runtime
Lower is better.
That lets us answer the real cloud benchmark question:
Who gives the most join performance per dollar?
Fast systems score better. Low-cost systems score better. Slow or expensive systems fall behind quickly. And when a system is both slower and more expensive, the two effects compound.
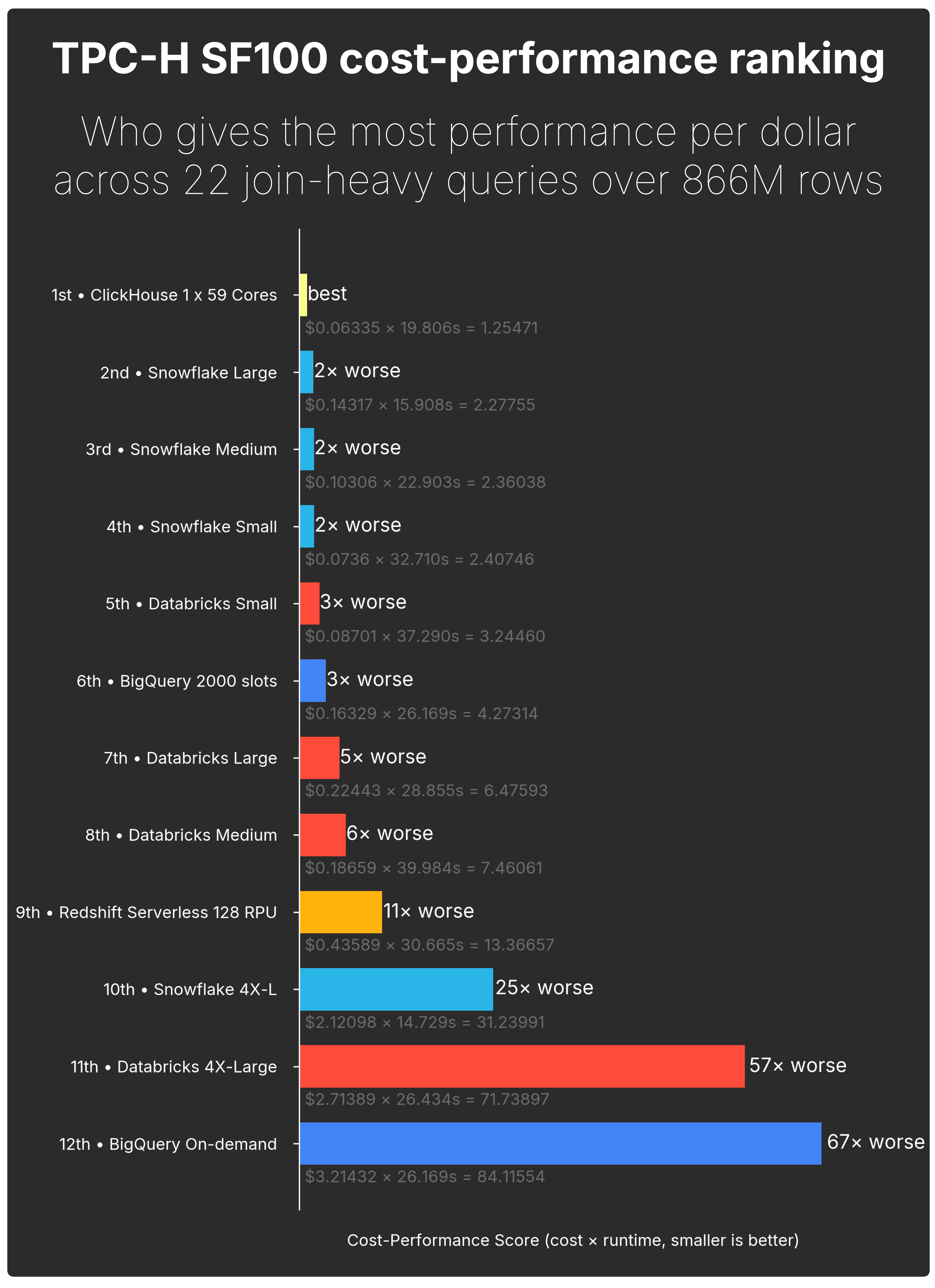
ClickHouse Cloud ranks first.
The next closest configurations were Snowflake Large and Snowflake Medium, both about 2× worse. Databricks Small and BigQuery with 2,000 slots are at 3× worse. Databricks Large and Medium followed at 5× and 6× worse.
At the high end, Redshift Serverless was 11× worse, Snowflake 4X-Large was 25× worse, Databricks 4X-Large was 57× worse, and BigQuery On-demand was 67× worse.
ClickHouse Cloud delivers the best cost-performance on TPC-H SF100: lowest score overall, with the nearest tested configurations about 2× worse.
TPC-H SF100: per-query runtime breakdown #
For completeness, here is the per-query runtime breakdown. Each bar shows the fastest of three runs for one of the 22 TPC-H queries.
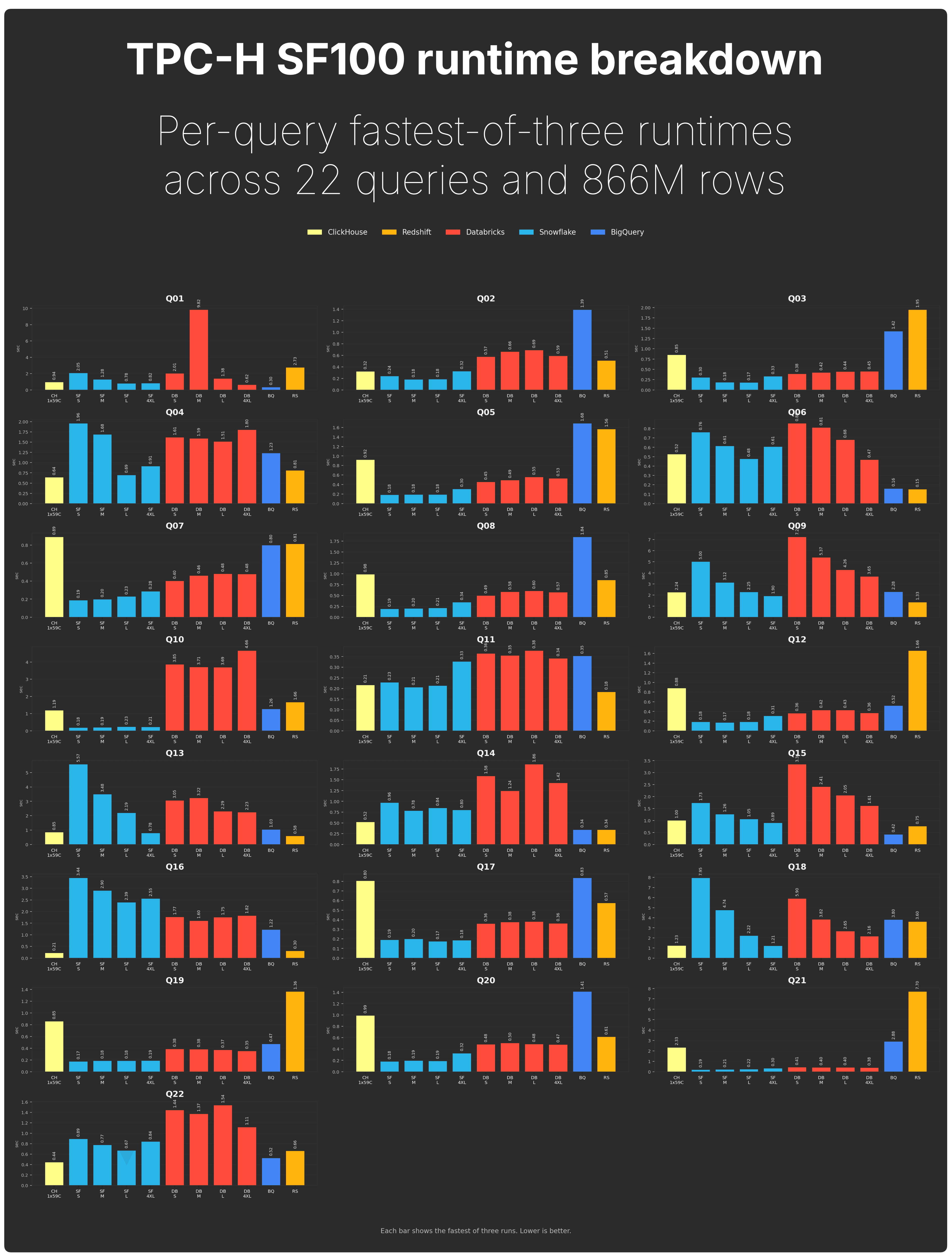
The aggregate result is not driven by one outlier. ClickHouse Cloud is consistently competitive across the full query set.
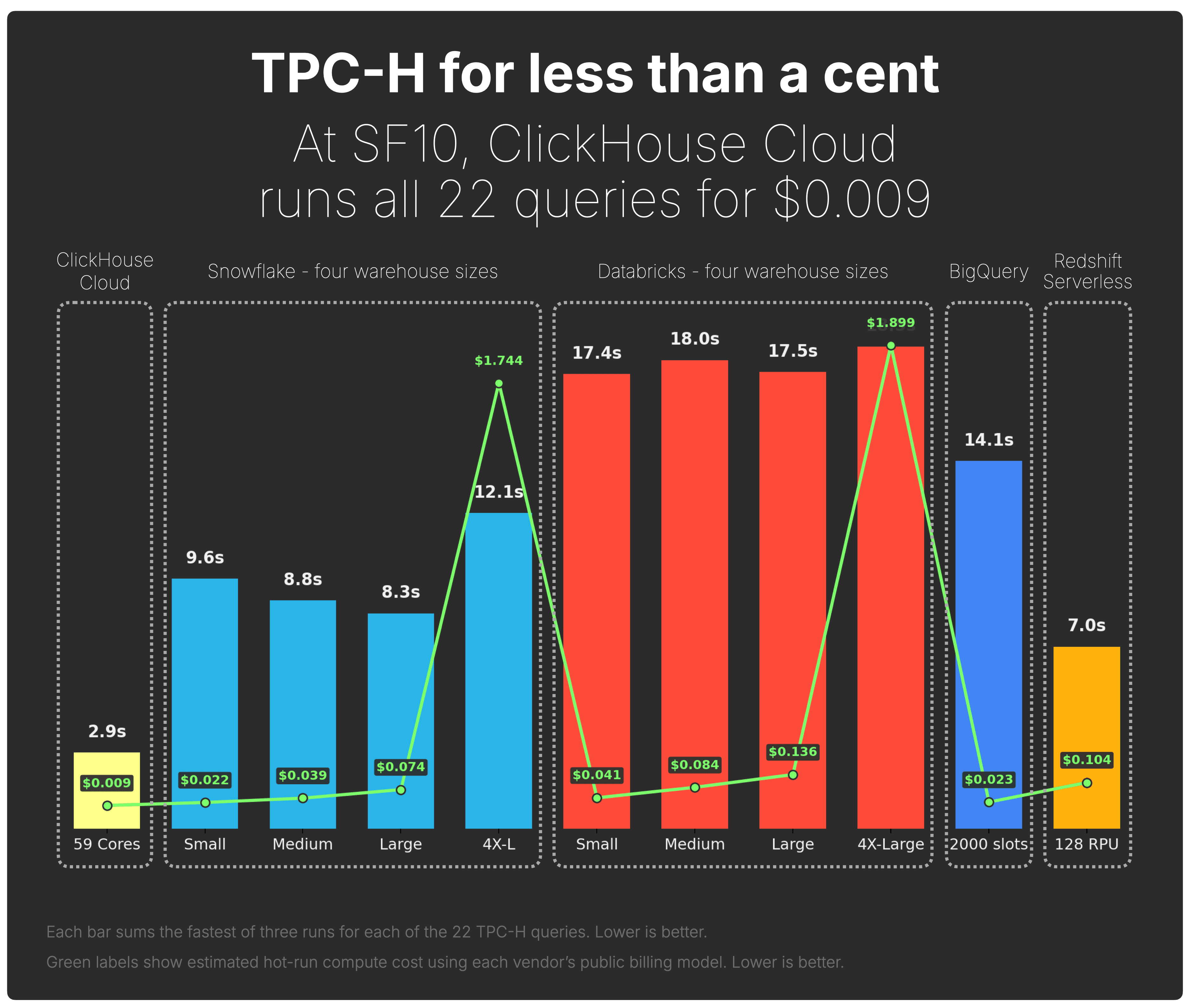
Scaling down: TPC-H for less than a cent #
SF100 is the main benchmark in this post. But scaling down to SF10 gives us the title moment.
At SF10, the workload contains 86M rows across the same 22 join-heavy TPC-H queries.
On the same ClickHouse Cloud configuration with one 59-core compute node, the full hot workload ran in 2.9s with a compute cost of $0.009.
The chart below collapses runtime and cost into a single cost-performance score to answer the “Who gives the most join performance per dollar?” question.
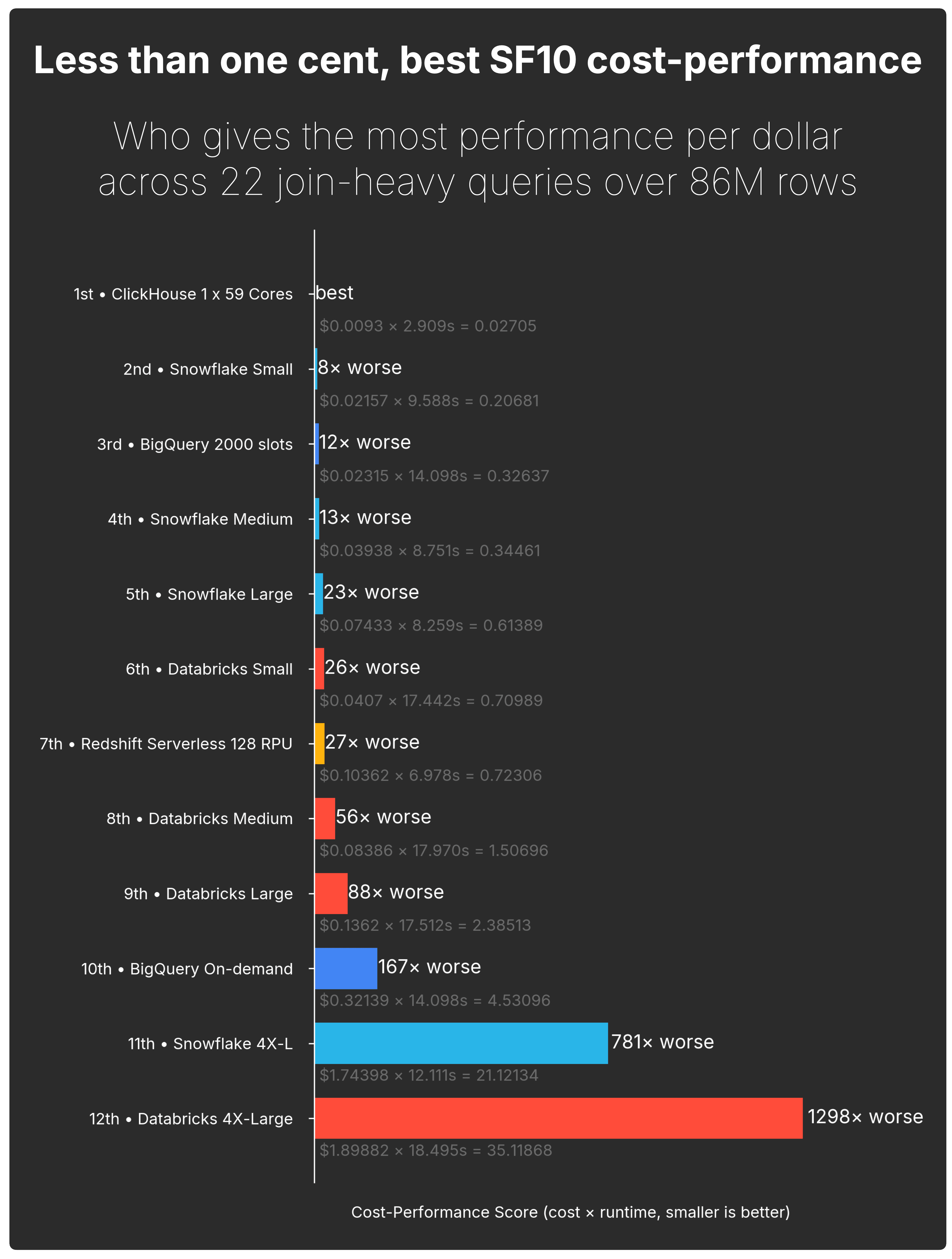
At this scale, ClickHouse Cloud wins on both dimensions: it is the fastest tested configuration and the cheapest to run. Snowflake was next in terms of cost-performance, but still 8× worse. BigQuery was 12× worse, Redshift Serverless 27× worse, and the larger Snowflake and Databricks configurations were much further behind.
At SF10, ClickHouse Cloud runs all 22 TPC-H queries in 2.9s for less than one cent, and delivers the best cost-performance by a wide margin.
Scaling up: SF1000 and beyond #
The SF100 results show where ClickHouse is today: with a single 59-core compute node, ClickHouse Cloud is competitive on both runtime and cost-performance against major cloud data warehouses, including systems using larger or more elastic compute configurations.
But SF100 is not the end of the story.
For much larger scale factors, such as TPC-H SF1000 and beyond, join execution needs to scale across multiple nodes properly. That is where the engineering team is focusing next, with multi-stage distributed query execution for large distributed joins in ClickHouse Cloud.
That is the next chapter. This one was made possible by the last two years of join engineering.
How we got here #
The results above are the outcome of two years of focused join engineering at ClickHouse.
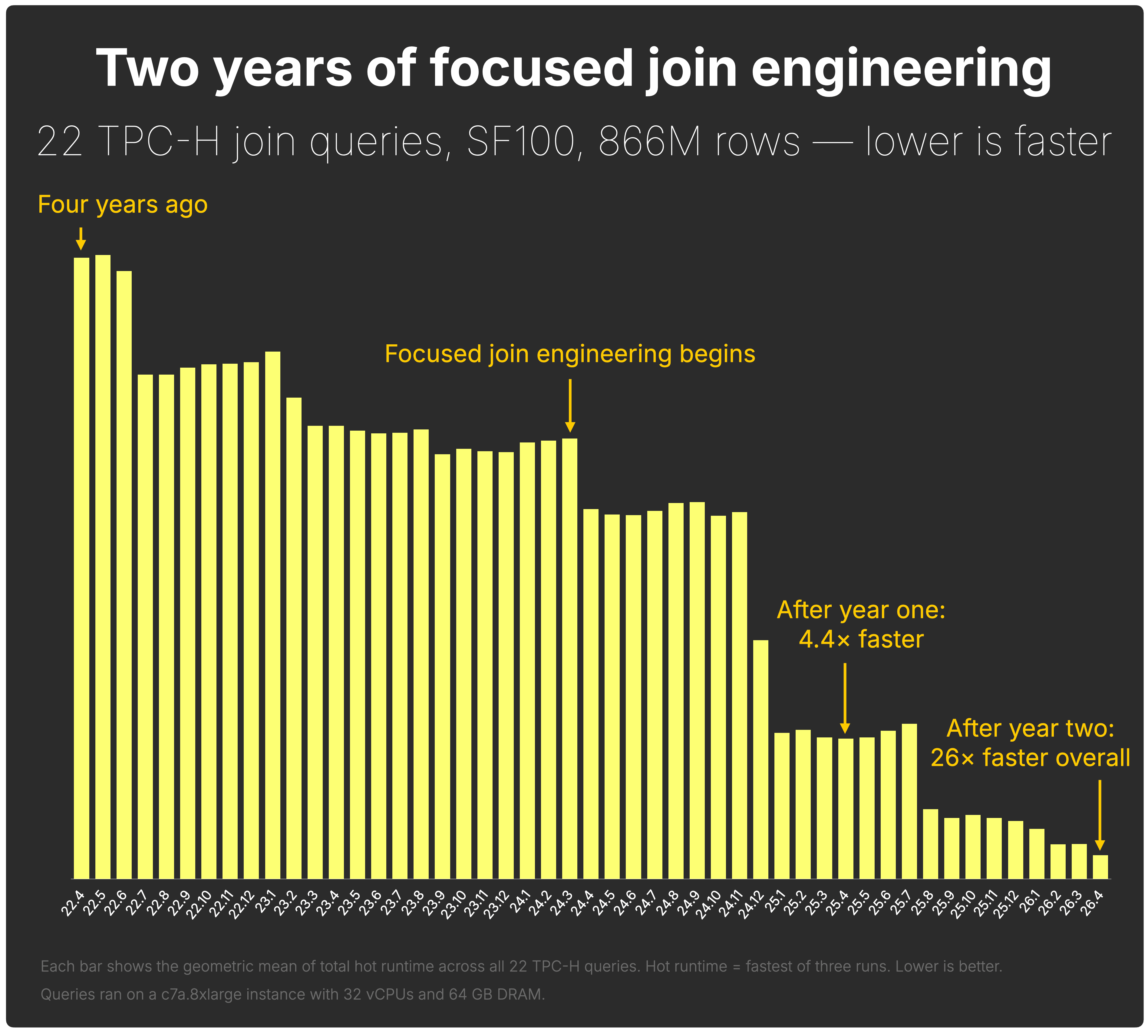
A year into that effort, the same TPC-H SF100 join-heavy workload was already 4.4× faster than in 22.4. One year later, it is now 26× faster overall, with the last year alone contributing another 6× improvement under default settings.
That progress came from improvements across the stack: faster hash joins, better planning, correlated subquery support, lazy column replication, runtime filters, and statistics-based join reordering.
The companion post explains the engineering story behind those numbers: how ClickHouse went from “fast, but not for joins” to competitive join performance by default.
Two years of focused join engineering made ClickHouse 26× faster on the TPC-H SF100 join-heavy workload, and that is what made these benchmark results possible.



