With ClickHouse, we can serve fresh data, query raw events directly, lean on materialized views when needed, and build new capabilities in weeks instead of months or quarters.

Accelerate your data lake with ClickHouse
ClickHouse brings high concurrency, low latency analytics and unlocks your data lake for AI driven access across multiple data sources without lock in.
- Point ClickHouse at any catalog, on any cloud, and query with full SQL.
- Accelerate into MergeTree for sub-second, high-concurrency analytics.
- Write results back to open formats so every tool in your stack can use them.
- Federate across multiple catalogs and JOIN datasets using the same engine.
Trusted by





















Join the companies choosing ClickHouse to accelerate their data lake
Query in place, at speed
Query Iceberg, Delta Lake, or Parquet data directly on S3, GCS, or Azure without moving it.
Fast native Parquet reads, data caching, and smart use of file metadata to minimize IO. Scale on one machine or distribute across nodes with standard SQL.
Any catalog, any cloud, no lock-in.

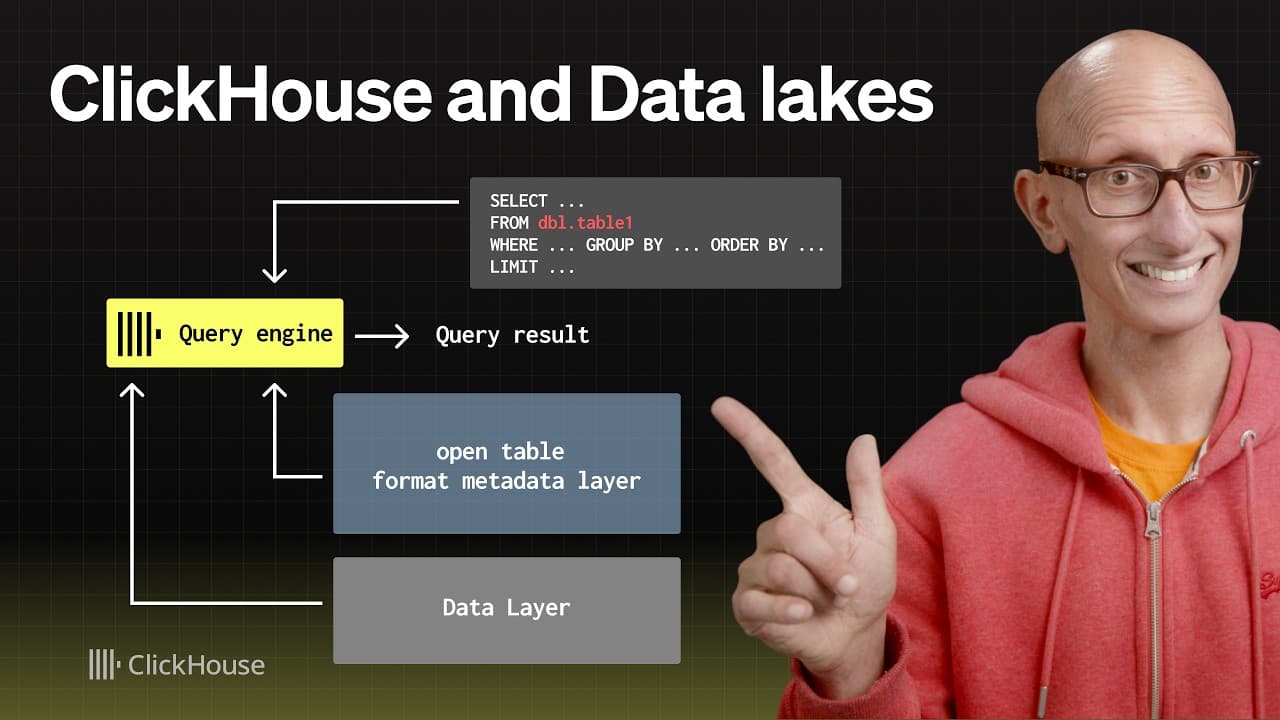
One query engine for every catalog on any cloud
ClickHouse is catalog and cloud-agnostic, working across main object storage vendors, table formats, and metastore services without lock-in.



Connect to your catalog, exposing it as just another database. Federate queries across catalogs, join datasets across clouds, and run a single SQL layer on top of your entire data lake ecosystem.
Supported catalogs
AWS Glue Catalog
Unity Catalog
Micrsoft Onelake
Lakekeeper
Project Nessie
Google Big Lake
Apache Polaris
Why choose ClickHouse to power your data lake?

Faster explorations on open data formats
Run interactive, federated queries directly on open table formats with industry leading Parquet performance backed by Benchmarks and full SQL support.

Real time acceleration when it's needed
Load data into ClickHouse’s MergeTree for your use facing analytical workloads which need sub second queries and high concurrency at scale.

AI powered workloads
Enable AI powered workloads on your data lake with low latency, high concurrency, and seamless federation across catalogs and data sources.

Always Open. No Lock In.
Query data where it lives and write results back in open formats to preserve interoperability across your ecosystem.
Bring real-time analytics to your data lake
Data lakes are built for openness and scale. But if you need sub second latency and high concurrency, you need ClickHouse.
Use ClickHouse as your hot performance layer by loading data from open table formats into ClickHouse’s MergeTree. Alternatively, ingest directly into ClickHouse with high write throughput and automatic merging.
Unlock your data lake with AI
ClickHouse provides the performance layer that makes low latency, highly concurrent AI experiences possible. Interact with your data lake tables using LLMs without moving your data or writing SQL.
Loading video...
- Talk to your data using ClickHouse MCP server and LibreChat integrations
- Build and share no code, specialized agents across your team or with customers
- Create charts, visualizations, and dashboards directly from conversations
- Save and share chats and generated artifacts securely
Build AI powered analytics experiences on top of your data lake while keeping your data open, interoperable, and exactly where it lives.
Scale your data lake with ClickHouse Cloud
ClickHouse Cloud separates compute and storage by design, giving you independent control over performance and cost.
Scale vertically to use every core and resource on a machine, or add horizontal compute instantly to accelerate demanding workloads with the click of a button.
When queries stop running, compute idles so you only pay for what you use. Flexible compute for the performance you need.
Data lakes
Catalog connectivity made simple with ClickHouse Cloud
ClickHouse Cloud makes connecting to your data lake catalog a matter of a few clicks.
Securely connect to your catalogs with guided UI workflows, with no complex setup required.
Instantly expose databases and tables as native ClickHouse tables and start querying with full SQL support.

Stay open.
Stay interoperable.
Write results back to open table formats to keep your data portable and ecosystem friendly.
Store aggregations, curated subsets, or transformed datasets in Iceberg, Delta, and other open formats for long term storage, sharing, or reverse ETL workloads.
Use refreshable materialized views to offload data automatically, ensuring ClickHouse accelerates your data lake without creating silos or lock in.

Learn about ClickHouse with data lakes