ClickHouse was released in open source on Jun 15 2016, ten years ago. Since then, it became the most popular open source analytical database with more than 2000 contributors.
Building in the open #
There are different levels of open-source.
Level 0: The minimum level is making the code open to the public for reading, but nothing more. This is the case of archival and museum releases, such as Doom or MS-DOS.
Level 1: The next level is when the software is updated by commits in a public repository, but not necessarily accepting contributors. This is also an example of open source. SQLite and Ladybird are examples.
Level 2: Accepting contributions but without a transparent and open development process. Most active open-source projects are on this level.
Level 3: Open contribution guidelines, task tracker, code review system, development roadmap, testing and CI system, release cycle, user support, and documentation.
I always aim for the maximum. ClickHouse should be the best example of:
How to build a great database - if you want to build a new database, ClickHouse source code and development practices will serve as the best example. I always write the code so everyone can learn from it - by keeping it modular, orthogonal, and well-documented. When the code requires a complex concept, I explain it in the comments from scratch, so the readers don't have to refer to textbooks, Wikipedia, or AI.
A place to learn C++ development. Many people are looking for repositories representing the frontier of software engineering, and today ClickHouse is one of the most popular open source repositories in C++, where everyone can learn both the exciting stuff (C++23) and boring stuff (build systems, continuous integration and testing, code review practices, and AI).
A place for experiments on data structures and performance optimization. You can open a pull request as an experiment, without aiming for it to be merged - it will be tested with the same level of scrutiny as production releases. Found a new memory allocator, a new compression library, a new hash table, a data format, or a sorting algorithm? - bring it to ClickHouse, and it will expose it inside-out. The roadmap also includes a section about experimental, weird, and even ridiculous things.
Where you can be proud of your work. ClickHouse credits every contributor in the changelog and even inside the database in the system.contributors table! There are countless cases when a contributor sends an initial, incomplete implementation of a feature, and we help to finish it together. Even if the code has to be entirely rewritten, we do it proactively and take the responsibility for that, and always credit the initial author, because we care about your use case and the initial intent that made it happen. To put it simply, we love our contributors.
Before open source #
Prototypes and first commits #
The first commit in ClickHouse was made on May 29, 2009, and it was a performance optimization (a replacement of libc functions localtime, mktime, gmtime, which were extremely slow and annoyed me by showing up in the profiler). But it was before ClickHouse existed.
ClickHouse started as my experiment while I was working on data processing for a web analytics system. The system, similar to Google Analytics, received logs about pageviews sent from websites, and it was implemented with MySQL, data processing in C++, and custom data structures in C++ where MySQL couldn't suffice. The MySQL databases stored pre-aggregated reports for customers, and custom data structures used for calculating user sessions, user history, and similar stuff.
My experience from that time was - the data volume is growing, nothing works, and the new data appears in real time. If we can't process a five-minute chunk of logs in five minutes, there will be a delay. I will search for any creative solution while the delay accumulates and deploy it on the same work day.
That's how I was searching for any solution that works - any type of databases, any libraries, etc. Can we use TokuDB? Colleagues use LMDB, maybe it will save us? Let's try Judy Arrays. Someone at lunch told us about Hadoop, should we use it? I heard briefly about LZO and QuickLZ in the corridor - let's try it. If we store HyperLogLogs in MySQL BLOBs, how will we sum them? On a weekend, I will read that data compression book or the documentation on event-loop servers...
While stabilizing the data pipeline, I was also thinking about new features that I can bring to the product. If we record clicks on links, we can show a heat map on every page. And if we record the position of every click in the DOM, we can make a click map. For Apr 1, I made a 3D click map in Flash with anaglyph colors. The more interesting feature was to let our users construct any report instead of a set of pre-aggregated ones.
For this task, I explored column-oriented databases. I've read about them from random company mailing lists, websites like dbms2.com, and my colleagues from the ads department. The idea is to store non-aggregated, but structured logs and aggregate them on the fly, while the customer waits for page load. I tested a few extensions to MySQL: Infobright, InfiniDB, and a few standalone analytical databases: Vertica, MonetDB, and LucidDB. For some reason, none worked on loading 100 billion records a day with 500 columns. Then I tried to implement a simple prototype of a custom data structure: every column (only integers, with hashes instead of strings) for every day and every website in a single binary file (a billion of files needed XFS), with lightweight compression, updated once a day with a delay of a few hours, queried with an API allowing to specify columns to group by, aggregate functions, filters, and sorting (queries were specified in XML). The most difficult part was populating historical data from MySQL by "unaggregating" it so that aggregated data would show the same result - it was solved by my colleague, Evgenii Gatov.
This simple prototype (named OLAPServer, implemented in Dec 2008, deployed in Jan 2009) worked. I've also created an endpoint to let people analyze global Internet data instead of single websites, and it worked like a miracle. One example: there was a statistics department processing Internet logs using an internal version of MapReduce, but analysts in the company started to use my service instead, because it answers instantly.
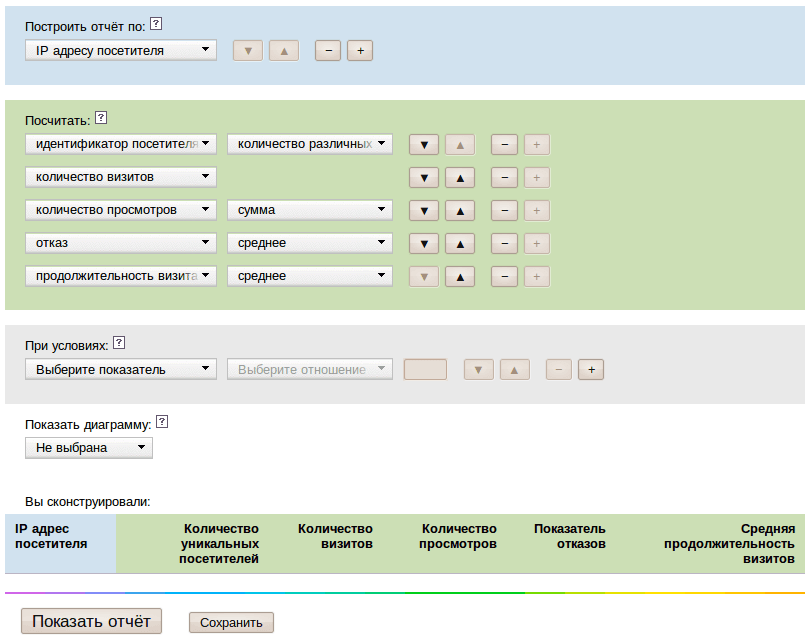 The first prototype of report generator. The frontend and design are also mine.
The first prototype of report generator. The frontend and design are also mine.
Then I decided to replace aggregated reports in MySQL (it accumulated about 50 TB of data on 50 shards). Many custom data structures were stored as BLOBs, and to aggregate them, the programs had to read them from the database, apply custom code, and insert them back. Moreover, data in MySQL was uncompressed. And even more - the data was reading slowly, because the order of its arrival (by time) didn't correspond with the order of queried ranges (by website ID). I was reading about LevelDB and TokuDB, so I decided to implement a custom data structure for incremental aggregation with background merges. Every record in this table was defined by a custom C++ struct, representing CRDT with add, update, merge, serializeText/Binary and deserializeText/Binary methods. On read, the partially aggregated data is finally merged and returned to the API. This data structure can be used for any aggregated report, such as unique users and visits by region, or a click map for every page.
This simple prototype (named Metrage) also worked. So we end up with two custom data structures - one column-oriented for non-aggregated data, updated daily, with only integer types, and another row-oriented, updated in real-time, with arbitrary CRDT.
For a long time, these two custom data structures solved our problems. To be honest, no one demanded more. But I thought - what if I try to combine a column-oriented approach for aggregation speed and a merge tree for realtime updates and data locality? And also generalize it to allow a real query language and data types? This is how ClickHouse started.
How was ClickHouse built? #
ClickHouse is a rare example of a database system that is not based on any existing one - implemented entirely from scratch. Today, most of the database management systems are implemented on top of Postgres, Datafusion, and even ClickHouse. It might be interesting to look at how it is possible to bootstrap a DBMS out of nothing, in what steps?
The first commits in 2009 are related to optimizations related to other data structures in the same mono-repository. They are visible because, during open-sourcing, I carefully split the repository while preserving all the history.
The first commit where I started implementing a new DBMS (the name ClickHouse came later) is here - the implementation of columns in memory: you can see already familiar classes IColumn and Field. Compare it to today's implementation :) You might think that this is similar to Apache Arrow (which focuses on column representation in memory), and why didn't we use it - but Apache Arrow didn't exist then (other column-oriented formats, such as RCFile, Trevni, ORC, and Parquet didn't exist either).
Then aggregate functions were introduced in this commit. It is still one of the most important parts of ClickHouse.
Then table engines were introduced. It is funny that table engines were named "primary key", but only for a few days. This allowed reading and writing columns on disk. The first table engine was similar to TinyLog, which exists till today.
Then compression was added. Initially, it was QuickLZ, but as soon as I read Yann Collet's blog, I replaced it with LZ4.
Then block streams - components of the data processing pipeline that produce, consume, or transform chunks of columns in a streaming form. Today, these are replaced with Processors. This unlocked the way for formatting results and implementing queries on tables. The same commit added StorageSystemNumbers - introduced for testing query pipelines, and it remains today as our beloved system.numbers table. The first query pipeline in ClickHouse was printing numbers in TSV.
Here you can see which table engines were introduced in what order.
The first relational operator in the ClickHouse code base was LIMIT.
Then I tried to add a SQL parser. The first attempt tried to use boost::spirit, which failed. After a while, I made a recursive descent parser.
Interesting to point out some initial ideas that were rejected or reintroduced later. Initially, I tried to add a column with variable-length encoded numbers. It was removed due to slowness, and only much later we introduced custom compression codecs, independent of columns. Initially, I added a column type Variant containing arbitrary field values. It was also slow, and I removed it - a better version of Variant was added in 2025. I also had a fixed-size array data type along with a variable-size array, but I removed it due to the lack of need. Only today we are considering adding it back. I believe that removing unnecessary code is more important than adding new code, and today, removing code is my favorite thing to do. You can find a lot of commits in ClickHouse titled "remove trash" and similarly.
Here you can see the first real table structure tested in ClickHouse - it is the hits table you can still see today in ClickBench.
Trying to read and write this table uncovered that C++ iostreams are slow, so in this commit you can see the introduction of WriteBuffer, ReadBuffer, which are still used today.
First functions in SQL appeared here - arithmetic operators. And it allowed to implement the first SELECT query interpreter. At this time, the SELECT query interpreter was only accessible from a test program, but it allowed quickly implementing new aggregate and regular functions, relational operators, data formats and other components.
ClickHouse server was introduced on Mar 9, 2012 and clickhouse-client on Mar 25. Together with the Log, TinyLog, Merge, Distributed, and Memory table engines, it was enough to deploy ClickHouse on production. The first deployment was to store incoming chunks of logs for further processing and for global queries on top of raw logs (this is what Merge and Distributed do). We can say that the first production usage of ClickHouse was a persistent log queue with SQL queries on top 😂
Then I've added MergeTree - it allowed incremental sorting of data in the background, so that while the data arrives by time, range queries by a single website work fast, and we can deploy it for production as a replacement for both early prototypes, OLAPServer and Metrage. The first version contained a few curiosities for our production, like a more aggressive merge of data parts at night.
In 2012, I had a chance to hire the employee №2 in my team, Michael Kolupaev, and I have the pleasure to work with him to this day.
Our production was deployed in multiple regional data centers, and the infra team was deliberately turning off a data center for an hour once a month (it was named "drills"), so that unprepared services experienced downtime - this was to teach everyone to implement highly available multi-DC services. So everything in production has to be replicated in multiple DCs. Initially, I used simple double-write for that with backfill for a DC after its downtime. But we wanted 100% consistency with automatic repair, and for that, we needed distributed consensus. Some of my colleagues were Java engineers, so they hooked us on ZooKeeper as a coordination system (don't worry, I forgive them), and Michael implemented ReplicatedMergeTree using ZooKeeper as a metadata layer. It allowed deploying ClickHouse for production for user-facing queries in 2014.
How did ClickHouse get open-sourced? #
In 2014, ClickHouse was in production, storing hundreds of billions of records every day and answering realtime queries from customers. I've also made it accessible for data scientists in the company who used it to calculate trends on the Internet. I published a simple documentation on ClickHouse usage. Other departments, such as ads, e-commerce, infra, and business analytics, tried ClickHouse and migrated some of their use-cases from other systems, such as internal map-reduce (where they were literally writing jobs on text logs with Perl), MySQL, and Postgres. At the end of 2014, ClickHouse was widely used, but only in a single company (with one exception - CERN also deployed it in a cooperation for LHCb experiment).
When I watched presentations on tech conferences and read blogs, I noticed that in other companies, engineers often do something similar to OLAPServer or Metrage, because none of the existing databases could reasonably work on their use-cases - a story very familiar to me! And I thought - what if I can present about ClickHouse? I published an article about ClickHouse in 2015 (translation), and it proved the interest in it even more. My thought - if I make it accessible for everyone, it can fill this empty niche. If I don't - someone else will eventually do it, and it is really scary.
I prepared a list of items to motivate company management to approve the open-source release, with the list of potential advantages and potential risks. Somehow, I was convincing enough, and it was approved, so I created a plan for release, designers made the first logo, I created the first website, prepared the blog post, created a Debian repository (with the infra team), and it was opened to everyone in the world on Jun 15, 2016.
I want this story to also motivate every engineer to try open-sourcing their code. In the worst case, nothing will come out of it, but there is a chance it will influence generations, as ClickHouse does! Don't worry about being ashamed of your code - I just showed you my code from fifteen years ago, and it looks kind of funny. Today, ClickHouse is the most popular analytical database used by the largest companies across the world.




{kind=link}
{kind=link}
{kind=link}