Database compression turns analytical storage from an I/O-bound problem into a CPU-bound one. By stacking a column-aware encoding (dictionary, run-length, delta, Gorilla, frame-of-reference) under a general-purpose codec (LZ4 or ZSTD), columnar engines like ClickHouse hit 5-10× compression on typical analytical data and 30×+ on low-cardinality columns. On the ClickBench 100M-row benchmark, ClickHouse stores the dataset in 9.26 GiB compared with PostgreSQL's ~100 GiB, a 10× advantage driven by storage layout. This article covers how that compression works, when it backfires, and how to configure it.
TL;DR #
- Database compression has two regimes: row-based (page-level, 1.5-3× typical) and column-based (per-column encoding stacked under a codec, 5-10× typical, 30×+ on low-cardinality columns).
- Column-based compression is a two-stage stack: a column-aware encoding (dictionary, RLE, delta, delta-of-delta, Gorilla, frame-of-reference) below a general-purpose codec (LZ4, ZSTD, Snappy).
- ClickBench measures ClickHouse at 9.26 GiB vs PostgreSQL ~100 GiB on 100M rows. Customer-side, Character.AI reports averages of 15-20× across columns. Seemplicity reports 5-6× over Postgres.
- LZ4 decompresses 3-5× faster than ZSTD. ZSTD compresses ~30% smaller. Pick LZ4 for hot query paths, ZSTD for cold storage.
- Heavy codecs on high-cardinality strings make the query path CPU-bound, which is the worst-case failure mode.
Why do databases compress data? #
At the most fundamental level, compression reduces the number of bytes stored on disk. This means less data read during queries, which improves performance, and less storage space used overall, which reduces storage costs.
A scan that reads 10 GiB instead of 100 GiB completes 10× faster on the same hardware, and costs 10× less to keep on disk or in object storage. The CPU spent decompressing is almost always cheaper than the I/O it saves. Storage volumes can easily run into terabytes or petabytes. Without compression, those datasets quickly become expensive to manage and slow to query.
| Benefit | Why it matters |
|---|---|
| Lower storage costs | Disk space is not free. Whether you manage your own hardware or use cloud storage, fewer bytes means a smaller bill. |
| Faster queries | Reading less data from disk or network reduces I/O time. In analytical workloads, I/O is often the bottleneck. |
| Better cache utilization | More rows can fit into memory or CPU caches when compressed, leading to higher hit rates and faster repeated queries. |
| Cheaper data movement | Compression reduces the size of data replicated across nodes or shipped to backups. |
| CPU vs I/O trade-off | Decompression does use CPU, but in many real-world workloads the CPU cost is far outweighed by I/O savings. |
Compressed data not only saves money but also makes queries faster and enables use cases that wouldn’t be practical otherwise. For a system like ClickHouse, which thrives on scanning and aggregating massive datasets, getting compression right is one of the most important levers for both performance and cost efficiency.
What types of compression exist in databases? #
Database compression splits cleanly into two regimes by storage layout. Row-based engines compress at the page level on heterogeneous data. Columnar engines compress each column separately on homogeneous data. Compression ratios differ by an order of magnitude between the two because adjacent values in a column share a type and often a distribution.
Row-based compression #
Row-oriented databases like PostgreSQL, MySQL, and SQL Server group rows into fixed-size pages on disk. Compression happens at the page level. Each page is a block of mixed integers, strings, dates, and floats, and a general-purpose codec applied to that mix finds limited redundancy because adjacent bytes have nothing in common.
Row-based compression saves space, but ratios are usually modest. A typical Postgres TOAST + pg_lz pipeline achieves 1.5-3× on most analytical data.
To see this in practice, the ClickBench benchmark compared storage sizes across formats. PostgreSQL, a row-based system, required far more space than ClickHouse for the same dataset of 100 million records:
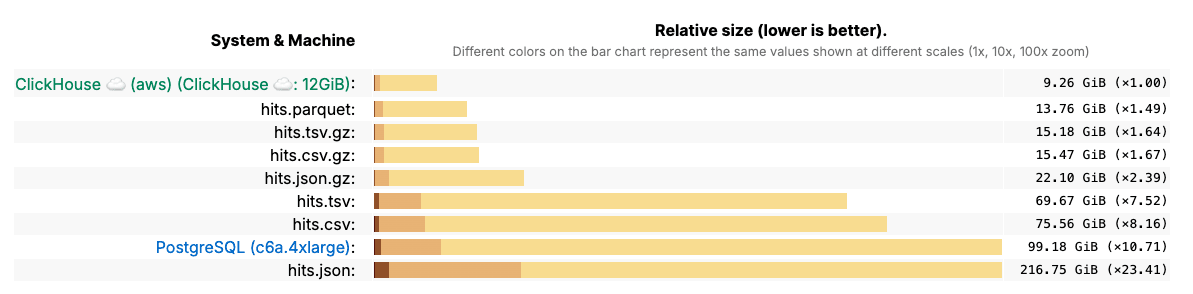
Column-based compression #
Column-oriented databases store each column of a table separately on disk. Adjacent values in a column share a type (all UInt64, all DateTime, all Enum8) and often share a distribution (monotonic timestamps, low-cardinality enums, narrow numeric ranges). The same compressor sees orders of magnitude more redundancy and produces ratios 3-5× tighter than the same data compressed row-by-row, as Abadi, Madden, and Ferreira documented in Integrating Compression and Execution in Column-Oriented Database Systems (SIGMOD 2006), the canonical reference on the subject.
Column-based engines layer two stages: a column-aware encoding that exploits per-column patterns, then a general-purpose codec that compresses the residual byte stream. ClickHouse, Parquet, ORC, and Arrow all follow this pattern with different vocabularies.
How does column-based compression work? #
Column-based compression works in two stages. An encoding (dictionary, run-length, delta, Gorilla, frame-of-reference) rewrites the column into a compact form that exploits its type and distribution. A general-purpose codec (LZ4, ZSTD, Snappy) then squeezes the residual bytes. Both stages are needed: encodings know patterns codecs cannot see, and codecs catch entropy encodings leave behind.
The encoding layer is type-aware. It knows that timestamps are likely monotonic, that boolean columns have two values, that an HTTP-status column probably has fewer than ten distinct values across a billion rows. The codec layer is type-blind: it sees a byte stream and looks for repetition. Stacking them compounds the ratio. A timestamp column might shrink 10× under delta-of-delta encoding, then a further 2× under LZ4, yielding 20× overall with each stage handling redundancy the other cannot see.
ClickHouse exposes this stack directly in DDL via the CODEC clause:
CREATE TABLE events (
event_time DateTime CODEC(DoubleDelta, LZ4),
user_id UInt64 CODEC(Delta, ZSTD(3)),
country LowCardinality(String) CODEC(LZ4),
metric Float64 CODEC(Gorilla, LZ4)
) ENGINE = MergeTree
ORDER BY (user_id, event_time);
In many cases, its not necessary to define encodings and codecs manually. Databases like ClickHouse ship with intelligent defaults that apply the right encodings and codecs for most cases, while offering the ability to optimise for specific cases.
The full set of available codecs is documented in the ClickHouse compression docs.
Dictionary encoding #
Dictionary encoding stores the unique value set once, then represents each row as an index into that dictionary. A column with 200 distinct country names across a billion rows compresses by storing 200 strings plus a billion small integer indices. Every columnar engine implements some form of dictionary encoding: ClickHouse exposes it as the LowCardinality(String) type, Parquet uses PLAIN_DICTIONARY, Arrow uses DictionaryArray.
Dictionary encoding wins on cardinality below ~50k distinct values per block. Above that threshold the index width grows, the dictionary itself becomes large, and the technique loses to general-purpose codecs.
Run-length encoding (RLE) #
RLE encodes runs of identical adjacent values as (value, count) pairs. A sorted boolean column with 1M consecutive true values stored as (true, 1000000) is one of the highest compression ratios any technique can deliver. RLE wins on sorted, low-cardinality columns: partition keys, sorted boolean flags, sorted enum columns.
The catch is that RLE depends on physical sort order. The same column unsorted compresses by far less. ClickHouse exploits this by encouraging sort keys (ORDER BY) that put low-cardinality columns first, so the prefix gets an RLE-like benefit at no extra storage cost.
Delta and delta-of-delta encoding #
Delta encoding stores each value as the difference from the previous. A monotonic UInt64 ID column with values 1000, 1001, 1002, 1003 becomes 1000, 1, 1, 1, and the residuals pack into a single byte each under bit-packing.
Delta-of-delta extends the idea to second-order differences. Timestamps sampled at a regular interval (12:00:00.000, 12:00:00.500, 12:00:01.000) have constant deltas, so the deltas of deltas are mostly zero. Facebook's Gorilla paper (VLDB 2015) reported delta-of-delta cutting timestamp storage by over 95% on production time-series workloads. ClickHouse exposes both as CODEC(Delta) and CODEC(DoubleDelta), and they are correct defaults for any monotonic integer or timestamp column.
Gorilla compression #
Gorilla is a floating-point compression technique published by Facebook in the same 2015 VLDB paper. It XORs each value against the previous, then encodes the leading and trailing zero bits of the XOR. Consecutive values in time-series data tend to be close, so the XORs are small and most bits compress to zero. The original paper reported a 12× reduction on Facebook's production time-series database.
CODEC(Gorilla) in ClickHouse and the equivalent Chimp codec in Parquet 2.x both descend from this paper. Use Gorilla on Float32 and Float64 time-series metrics. Do not apply it to integer or string columns: the XOR pattern on those is irregular, and the encoding adds metadata overhead with no compression benefit.
Frame-of-reference (FOR) and bit-packing #
Frame-of-reference subtracts a base value from each entry, then bit-packs the residual into the smallest number of bits that fits the range. A column of integers between 1,000,000 and 1,000,255 has a range of 256, so eight bits per value suffices instead of 32 or 64. FOR + bit-packing underlies Parquet's DELTA_BINARY_PACKED encoding and Arrow's run-length and dictionary indices, and is one of the techniques BtrBlocks (Kuschewski et al., BtrBlocks: Efficient Columnar Compression for Data Lakes, SIGMOD 2023) used to beat ZSTD on numeric data while decompressing an order of magnitude faster. ClickHouse's T64 codec applies the same idea to 64-bit integer columns.
General-purpose codecs (LZ4, ZSTD, Snappy) #
General-purpose codecs are the second stage. They compress the byte stream produced by the encoding layer. ClickHouse defaults to LZ4 for hot query paths and offers ZSTD with configurable levels (1-22) for cold storage. Parquet defaults to Snappy. ORC defaults to Zlib. The choice is a compression-ratio-versus-decompression-speed tradeoff, not a quality ranking.
| Codec | Typical ratio | Decompression (per core) | Use when |
|---|---|---|---|
| LZ4 | ~2× | 3-5 GB/s | Query path, hot columns |
| Snappy | ~2× | 2-4 GB/s | Lake defaults (Parquet) |
| ZSTD level 1-3 | ~2.5× | 1-2 GB/s | Mixed hot/cold |
| ZSTD level 9-19 | ~3× | 0.3-1 GB/s | Cold archival |
| Zlib | ~3× | 0.2-0.4 GB/s | ORC default, Hive ecosystem |
ZSTD compresses about 30% smaller than LZ4 at default levels but decompresses 2-3× slower. On a query that scans 100GB of LZ4-compressed data, the codec is invisible to wall-clock time. The same query against ZSTD(19) can become CPU-bound on the decoder.
Does data compression affect data accuracy? #
Database compression is almost always lossless. The compressed bytes decompress back to the exact original values. Dictionary, RLE, delta, Gorilla, and the general-purpose codecs (LZ4, ZSTD, Snappy, Zlib) all guarantee bit-for-bit fidelity.
What sometimes gets confused with compression is deliberate accuracy trade-offs: storing less precise versions of data to save space. Those are separate techniques, not lossy compression:
| Type | Meaning | Examples | Trade-offs |
|---|---|---|---|
| Lossless compression | Decompresses to the exact original bytes. | Dictionary, RLE, delta, LZ4, ZSTD, GZIP | Guarantees accuracy. Savings depend on redundancy. |
| Lossy reduction | Stores a reduced or approximate form. Some information is lost. | Sampling, aggregation states, reduced precision (seconds vs microseconds) | Larger savings. Cannot reconstruct raw rows. |
When teams use the word "compression" they almost always mean the lossless kind. Lossy reductions are usually exposed as separate features (sampled tables, materialised views aggregating to AggregateFunction state, lower-precision data types).
What are best practices for database compression? #
The compression ratio you see in production depends as much on schema decisions as on codec choice. Five practices move the needle:
- Choose the smallest data types that fit. Int16 instead of Int64. Float32 instead of Float64 when full precision isn't needed. Smaller types give general-purpose codecs less work and shrink the column before any encoding runs.
- Use enums or
LowCardinalityfor low-cardinality strings. Status codes, country names, log levels, and HTTP methods all benefit. Dictionary encoding does the rest of the work automatically. - Avoid unnecessary precision. A timestamp truncated to seconds compresses better than the same timestamp at microsecond resolution. Latitude/longitude as Float32 instead of Float64 is usually indistinguishable in practice.
- Match codecs to data patterns. Delta and DoubleDelta for monotonic columns. Gorilla for float time-series. RLE for sorted low-cardinality. Dictionary for unsorted low-cardinality strings. T64 or FOR + bit-packing for bounded numeric ranges.
- Measure per column. ClickHouse's
system.parts_columnsshows compressed and uncompressed bytes per column. The columns furthest from a 5× ratio are usually where mis-matched codecs hide.
The decision matrix below maps the most common column shapes to the encoding + codec combination that wins them:
| Column type | Cardinality | Pattern | Encoding | Codec |
|---|---|---|---|---|
| String enum (status, country) | Low (<10k) | Mixed | Dictionary / LowCardinality | LZ4 |
| String free-text (logs, UA) | High | None | None | ZSTD |
| Integer ID, monotonic | High | Monotonic | Delta + T64 | LZ4 |
| Timestamp, regular interval | High | Constant deltas | DoubleDelta | LZ4 |
| Float metric, time-series | High | Slow-changing | Gorilla | LZ4 |
| Boolean, sorted | Binary | Sorted | RLE (via ORDER BY) | LZ4 |
| Bounded numeric range | Bounded | Any | T64 / FOR + bit-packing | LZ4 |
Worked example: NOAA weather data #
The NOAA Global Historical Climatology Network is a public dataset of decades of daily weather observations. Loaded into ClickHouse with naive types, the table compresses around 3-4×. After a series of schema-level optimisations:
- Narrowed integer types from Int64 to Int16 where the value range allowed.
- Converted weather-type strings to Enum8 (a fixed set of values).
- Dropped float precision: latitude/longitude from Float64 to Float32.
- Applied
Delta + ZSTDcodecs to time-series columns.
The compressed size dropped substantially without any change to query semantics. Detailed steps are in the ClickHouse blog write-up on optimising codecs and compression schema.
When does compression backfire? #
Compression backfires when the CPU cost of the codec outpaces the I/O it saves. The two main failure modes are heavy codecs on high-cardinality data and over-aggressive level tuning on hot query paths. A third, subtler failure is using sort-order-dependent encodings on physically unsorted columns, where the metadata overhead exceeds any compression gain.
A free-text string column (log messages, user-agent strings, JSON blobs) has high entropy. Dictionary encoding fails because every value is unique. FOR fails because there is no numeric range. The general-purpose codec is doing all the work. Stacking ZSTD(19) on top reaches ~3× ratio at the cost of a query path 5-10× slower than LZ4. The right choice on such a column is often LZ4 alone, or moving the column into a separate, rarely-read part.
The second failure is treating the codec level as a tuning knob. Going from ZSTD(3) to ZSTD(9) typically buys 5-10% additional compression at 2-3× the decompression cost. Going from ZSTD(9) to ZSTD(19) buys another 3-5% at another 2× cost. The marginal compression flattens fast while the marginal decompression cost stays linear. For cold columns, ZSTD(3) is a common stopping point. Beyond that, the math rarely justifies itself.
The third failure is encodings that depend on sort order applied to unsorted columns. RLE on an unsorted boolean column adds metadata overhead with no compression benefit. Always check that the sort key matches the encoding assumption before adding CODEC(...) clauses.
What are the best high data compression databases? #
Not all databases are equally efficient when it comes to storage. To see the difference, we can look at results from the ClickBench benchmark, which compares several popular systems on the same dataset.
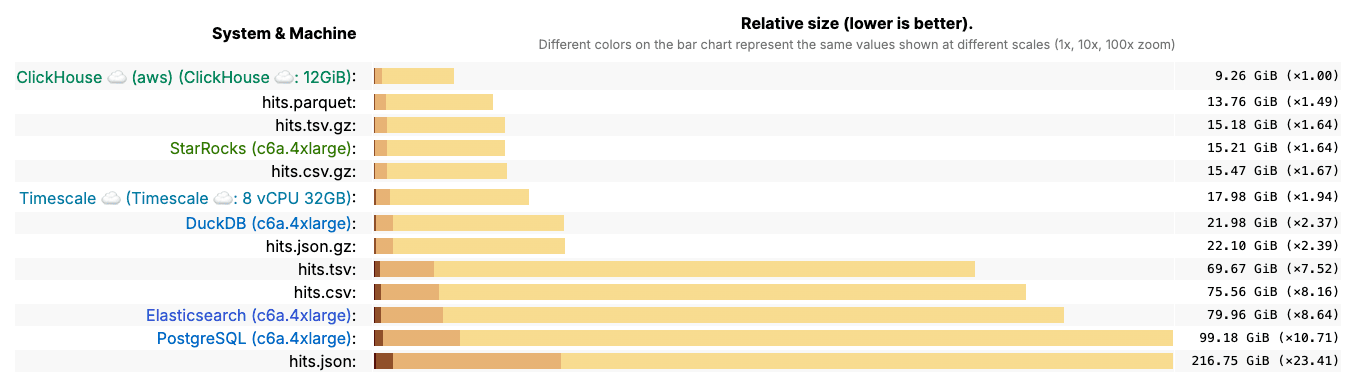
The results are striking. ClickHouse stores the dataset in just 9.26 GiB, while PostgreSQL requires almost 100 GiB - more than ten times larger. Other systems, including Elasticsearch and Timescale, fall somewhere in between but still lag significantly. Even highly optimized formats like Parquet or compressed CSV/TSV files can’t match ClickHouse.
This outcome isn’t surprising given what we discussed earlier: ClickHouse’s columnar layout, per-column codecs, and ordering-aware compression allow it to shrink data much more aggressively than row-based systems or general-purpose file formats.
And these gains aren’t limited to benchmarks. Real-world users see the same results in production:
Character.AI, which ingests massive streams of observability data from thousands of GPUs, relies on ClickHouse to keep storage under control:
“I was genuinely impressed by the compression we achieved with ClickHouse. Some columns gave us 10x, others 20x - even up to 50x in some cases. On average, we're seeing 15–20x compression!”
— Character.AI
Seemplicity, a security analytics platform processing tens of billions of updates per month, found that compression was a key factor in scaling beyond Postgres:
“Compression has also been a major win. Seemplicity’s ClickHouse footprint sits at around 10 terabytes - a fraction of their Postgres instance. I’d guess Postgres is 5 to 6 times bigger. That space efficiency, plus the ability to stream tens of billions of updates per month, gives them room to grow without worrying about bloat or system strain.”
— Seemplicity
Together, the benchmark and these customer experiences make one thing clear: if you’re looking for the best high data compression database available today, ClickHouse stands out from the pack.