The rise of cloud-scale analytics and AI has driven the need for data architectures that combine flexibility, performance, and openness.
Traditional data lakes offer scale and cost efficiency, while data warehouses provide structure and reliability - but managing both often leads to complexity and data duplication.
The data lakehouse has emerged as a convergent architecture that brings these worlds together. By applying database principles to data lake infrastructure, it maintains the flexibility and scalability of cloud object storage while delivering the performance, consistency, and governance of a warehouse.
This foundation enables organizations to manage and analyze all types of data—from raw, unstructured files to highly curated tables—on a single platform optimized for both traditional analytics and modern AI/ML workloads.
What is a data lakehouse? #
A data lakehouse is a data architecture that unifies the capabilities of data lakes and data warehouses into a single, cohesive platform. It provides the scalability and flexibility of a data lake while adding the reliability, structure, and performance traditionally associated with a data warehouse.
At its core, the data lakehouse applies database management principles—such as schema enforcement, transactions, and metadata management—to the open, scalable storage systems used in data lakes. This combination enables organizations to store all types of data, from raw and unstructured to highly structured, in one location while supporting a wide range of analytical and machine learning workloads.
Unlike traditional architectures that separate storage and analytics across different systems, the lakehouse model eliminates the need for complex data movement and synchronization. It offers a unified approach where the same data can serve multiple purposes: powering dashboards, advanced analytics, and AI applications—all directly from cloud object storage.
This convergence delivers the best of both worlds: the openness and scale of a data lake, and the performance and reliability of a data warehouse.
How does a data lakehouse differ from a data warehouse or data lake? #
A data lakehouse differs from traditional data warehouses and data lakes by combining the best characteristics of both into a single architecture. It offers the open, flexible storage of a data lake together with the performance, consistency, and governance features of a data warehouse.
Data lake vs. data warehouse vs. data lakehouse #
Data lakes are designed for large-scale, low-cost storage of raw, unstructured, and semi-structured data. They are ideal for flexibility and scale but lack built-in mechanisms for schema enforcement, transactions, and governance. As a result, maintaining data quality and running fast analytical queries can be challenging without additional layers.
Data warehouses provide structured storage and optimized query performance for analytical workloads. They enforce schemas, maintain data integrity, and deliver consistent performance, but they are often built on proprietary storage formats and tightly coupled compute layers. This design can increase costs and limit flexibility, making it difficult to adopt new query engines, processing frameworks, or analytical tools as needs evolve.
The data lakehouse bridges this gap. It stores data in open formats on cost-effective cloud object storage while applying database principles—such as ACID transactions, schema enforcement, and metadata management—to ensure reliability and consistency. This approach allows organizations to use the same data for diverse use cases: traditional BI, large-scale analytics, and AI/ML—all without duplicating or moving data between systems.
Summary of key differences #
| Feature | Data Lake | Data Warehouse | Data Lakehouse |
|---|---|---|---|
| Data type | Raw, unstructured, or semi-structured | Structured, curated | All types in one system |
| Storage format | Open formats (e.g., Parquet, ORC) | Proprietary formats | Open formats (e.g., Parquet + Iceberg/Delta Lake) |
| Schema enforcement | Optional or manual | Strictly enforced | Enforced with flexibility |
| Transactions (ACID) | Not supported | Fully supported | Supported through table formats |
| Performance | Slower, depends on tools | High | High, optimized via query engines |
| Governance and security | Limited | Strong | Centralized through catalogs |
| Scalability and cost | Highly scalable, low cost | Limited scalability, higher cost | Scalable and cost-efficient |
In short, the data lakehouse merges the low-cost, open, and scalable nature of data lakes with the governance and performance of data warehouses, enabling a single platform for both analytics and machine learning.
What are the components of the data lakehouse? #
A data lakehouse architecture combines the scalability of a data lake with the reliability of a data warehouse. It’s built from six key components - object storage, table format, metadata catalog, query engine, client applications, and data sources - that work together to create a unified, high-performance data platform.
Each layer plays a distinct but interconnected role in storing, organizing, managing, and analyzing data at scale. This layered design also allows teams to mix and match technologies, ensuring flexibility, cost efficiency, and long-term adaptability.
Let’s break down each component and its role in the overall architecture:
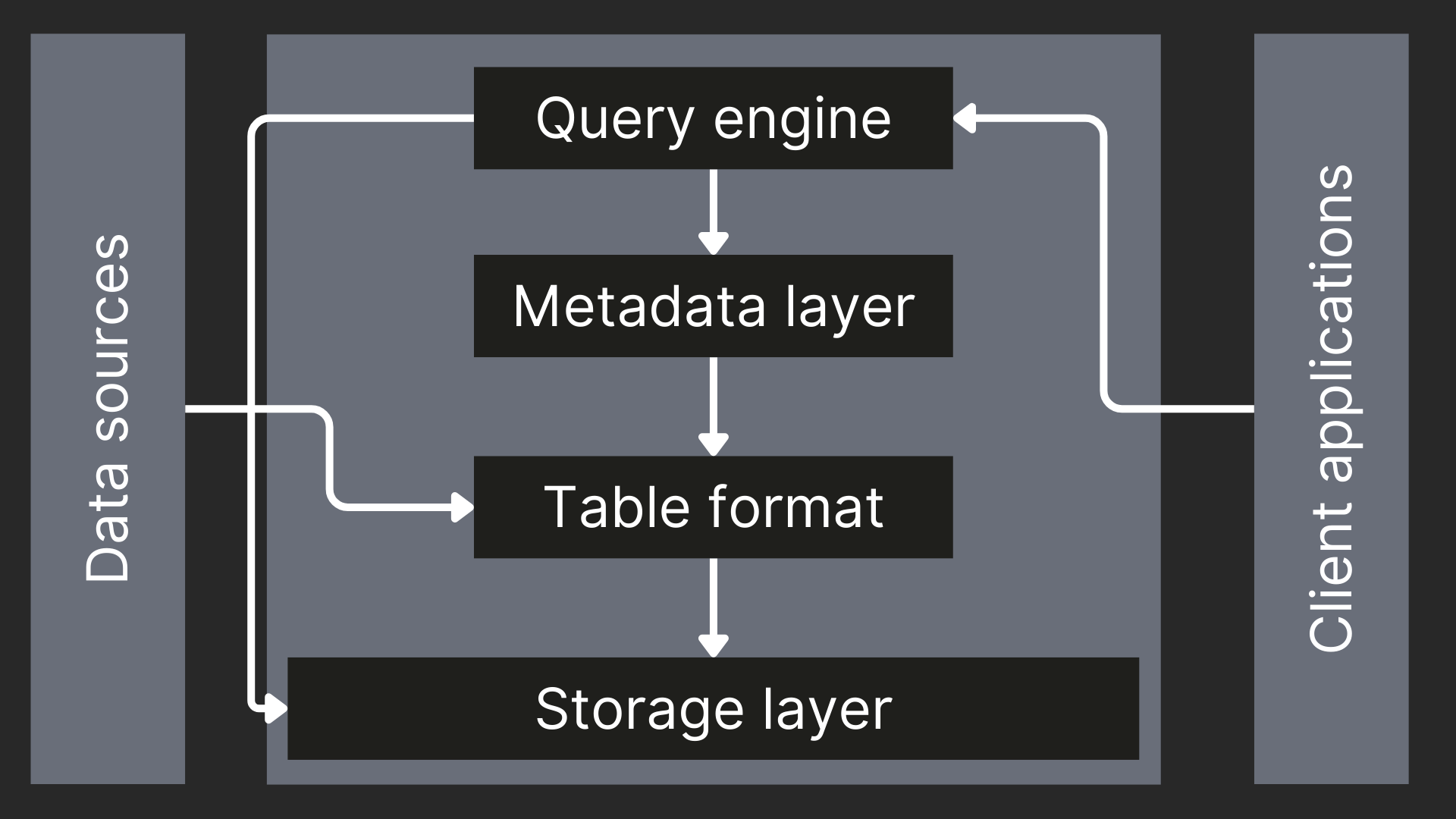
Object storage layer #
The object storage layer is the foundation of the lakehouse. It provides scalable, durable, and cost-effective storage for all data files and metadata. Object storage handles the physical persistence of data in open formats (like Parquet or ORC), allowing direct access by multiple systems and tools.
Common technologies: Amazon S3, Google Cloud Storage, Azure Blob Storage, MinIO or Ceph for on-premise and hybrid environments
Table format layer #
The table format layer organizes raw files into logical tables and brings database-like features, such as ACID transactions, schema evolution, time travel, and performance optimizations (e.g., data skipping, clustering). It bridges the gap between unstructured storage and structured analysis.
Common technologies: Apache Iceberg, Delta Lake, Apache Hudi
Metadata catalog #
The metadata catalog serves as the central source of truth for metadata - including schemas, partitions, and access policies. It enables data discovery, governance, lineage tracking, and integration with query engines or BI tools.
Common technologies: AWS Glue, Unity Catalog (Databricks), Apache Hive Metastore. Project Nessie
Query engine #
The query engine layer executes analytical queries directly against the data in object storage, using metadata and table-format optimizations to achieve fast, SQL-based analysis at scale. Modern engines like ClickHouse provide performance close to a data warehouse while maintaining the flexibility of a lakehouse.
Common technologies: ClickHouse. Apache Spark, Dremio, Amazon Athena
Client applications #
Client applications are the tools that connect to the lakehouse to query, visualize, and transform data. These include BI platforms, data notebooks, ETL/ELT pipelines, and custom apps that support data exploration and product development.
Common technologies:
- BI tools: Tableau, Power BI, Looker, Superset
- Data science notebooks: Jupyter, Zeppelin, Hex
- ETL/ELT tools: dbt, Airflow, Fivetran, Apache NiFi
Data Sources #
The data sources feeding the lakehouse include operational databases, streaming platforms, IoT devices, application logs, and external data providers. Together, they ensure the lakehouse serves as a central hub for both real-time and historical data.
Common technologies:
- Databases: PostgreSQL, MySQL, MongoDB
- Streaming platforms: Apache Kafka, AWS Kinesis
- Application and log data: web analytics, server telemetry, API feeds
- IoT and sensor data: MQTT, OPC UA
What are the benefits of the data lakehouse? #
A data lakehouse combines the performance and reliability of a data warehouse with the scalability, flexibility, and openness of a data lake. This unified architecture delivers cost efficiency, vendor flexibility, open data access, and support for advanced analytics and AI, all while maintaining strong governance and query performance.
In other words, the lakehouse model offers the best of both worlds: the speed and consistency of a warehouse and the freedom and scale of a lake.
Let’s look at how those benefits appear when compared directly to traditional data warehouses and data lakes.
Compared to traditional data warehouses #
- Cost efficiency: Lakehouses leverage inexpensive object storage rather than proprietary storage formats, significantly reducing storage costs compared to data warehouses that charge premium prices for their integrated storage.
- Component flexibility and interchangeability: The lakehouse architecture allows organizations to substitute different components. Traditional systems require wholesale replacement when requirements change or technology advances, while lakehouses enable incremental evolution by swapping out individual components like query engines or table formats. This flexibility reduces vendor lock-in and allows organizations to adapt to changing needs without disruptive migrations.
- Open format support: Lakehouses store data in open file formats like Parquet, allowing direct access from various tools without vendor lock-in, unlike proprietary data warehouse formats that restrict access to their ecosystem.
- AI/ML integration: Lakehouses provide direct access to data for machine learning frameworks and Python/R libraries, whereas data warehouses typically require extracting data before using it for advanced analytics.
- Independent scaling: Lakehouses separate storage from compute, allowing each to scale independently based on actual needs, unlike many data warehouses, where they scale together.
Compared to data lakes #
- Query performance: Lakehouses implement indexing, statistics, and data layout optimizations that enable SQL queries to run at speeds comparable to data warehouses, overcoming the poor performance of raw data lakes.
- Data consistency: Through ACID transaction support, lakehouses ensure consistency during concurrent operations, solving a major limitation of traditional data lakes, where file conflicts can corrupt data.
- Schema management: Lakehouses enforce schema validation and track schema evolution, preventing the "data swamp" problem common in data lakes where data becomes unusable due to schema inconsistencies.
- Governance capabilities: Lakehouses provide fine-grained access control and auditing features at row/column levels, addressing the limited security controls in basic data lakes.
- BI Tool support: Lakehouses offer SQL interfaces and optimizations that make them compatible with standard BI tools, unlike raw data lakes that require additional processing layers before visualization.
In summary, a data lakehouse architecture unifies structured and unstructured data in one platform that is:
- Cheaper than warehouses,
- Faster than data lakes, and
- More open and adaptable than either.
Is the data lakehouse replacing the data warehouse? #
The data lakehouse is not a complete replacement for the data warehouse but a complementary evolution of the modern data stack. While both serve analytical needs, they are optimized for different priorities.
The lakehouse provides a unified and open foundation for storing and processing all types of data. It supports traditional analytics and AI workloads at scale by combining the flexibility of data lakes with the governance and performance features of data warehouses. Because it is built on open formats and decoupled components, the lakehouse makes it easier to evolve infrastructure and adopt new tools over time.
However, there are still scenarios where a dedicated data warehouse or specialized analytical database may be the better choice. Workloads that require extremely fast response times, complex concurrency management, or finely tuned performance—such as real-time reporting or interactive dashboards—can benefit from the optimized storage and execution models of a warehouse system.
In many organizations, the two coexist. The lakehouse acts as the central, scalable source of truth, while the data warehouse handles performance-critical workloads that demand sub-second query latency. This hybrid strategy combines flexibility and openness with the speed and reliability of purpose-built storage engines.
Where does ClickHouse fit in the data lakehouse architecture? #
ClickHouse serves as the high-performance analytical query engine in a modern data lakehouse architecture.
It enables organizations to analyze massive datasets quickly and efficiently, combining the openness of a data lake with the speed of a data warehouse.
As part of the lakehouse ecosystem, ClickHouse acts as a specialized processing layer that interacts directly with underlying storage and table formats — offering both flexibility and performance.
ClickHouse as the query engine layer #
ClickHouse can query Parquet files directly from cloud object storage platforms such as Amazon S3, Azure Blob Storage, or Google Cloud Storage, without requiring complex ETL or data movement.
Its columnar engine and vectorized execution model deliver sub-second query performance even on multi-terabyte datasets.
➡️ Read more: ClickHouse and Parquet — A foundation for fast Lakehouse analytics
This direct-query capability makes ClickHouse an ideal choice for organizations seeking fast, cost-efficient analytics on their existing lakehouse data.
Integration with open table formats and catalogs #
ClickHouse integrates seamlessly with open table formats such as Apache Iceberg, Delta Lake, and Apache Hudi, supporting ACID transactions, schema evolution, and time travel.
It can also connect through metadata catalogs like AWS Glue, Unity Catalog, and other services for centralized governance and schema management.
This interoperability allows ClickHouse to blend speed with structure, leveraging the strengths of open data ecosystems while maintaining vendor independence and future-proof flexibility.
Hybrid architecture: The best of both worlds #
While ClickHouse excels as a lakehouse query engine, it also offers a native storage engine optimized for ultra-low-latency workloads.
In hybrid architectures, organizations can store hot, performance-critical data directly in ClickHouse’s native format — powering real-time dashboards, operational analytics, and interactive applications.
At the same time, they can continue to query colder or historical data directly from the data lakehouse, maintaining a unified analytical environment.
This tiered approach delivers the best of both worlds:
- The sub-second speed of ClickHouse for time-sensitive analytics.
- The scalability and openness of the lakehouse for long-term storage and historical queries.
By combining these capabilities, teams can make architectural decisions based on business performance needs rather than technical trade-offs — positioning ClickHouse as both a lightning-fast analytical database and a flexible query engine for the broader data ecosystem.
Summary #
ClickHouse fits into the data lakehouse architecture as the query engine layer that powers fast analytics across open, scalable storage.
Its ability to integrate with open formats, query directly from cloud storage, and store hot data locally makes it a key enabler of modern, hybrid data strategies.