TL;DR
ClickHouse can now query Iceberg and Delta Lake tables directly through the DataLakeCatalog engine.
It connects to catalogs like AWS Glue Catalog and Databricks Unity Catalog, detects table formats automatically, and lets you query them instantly, even across catalogs in a single query.
If your lakehouse tables are in a catalog, you can query them with ClickHouse.
ClickHouse grows beyond its own tables #
ClickHouse has evolved into a high-performance lakehouse query engine, able to query open formats like Iceberg and Delta Lake directly.
Just connect your catalog, and start querying.
In a previous post, we explored the data layer of the lakehouse: how ClickHouse reads and processes Parquet files directly, using the same parallel execution engine that powers its fastest on-disk queries.
This post moves up to the catalog layer, where metadata defines which Parquet files belong to which tables, how they’re partitioned, and how they evolve over time.
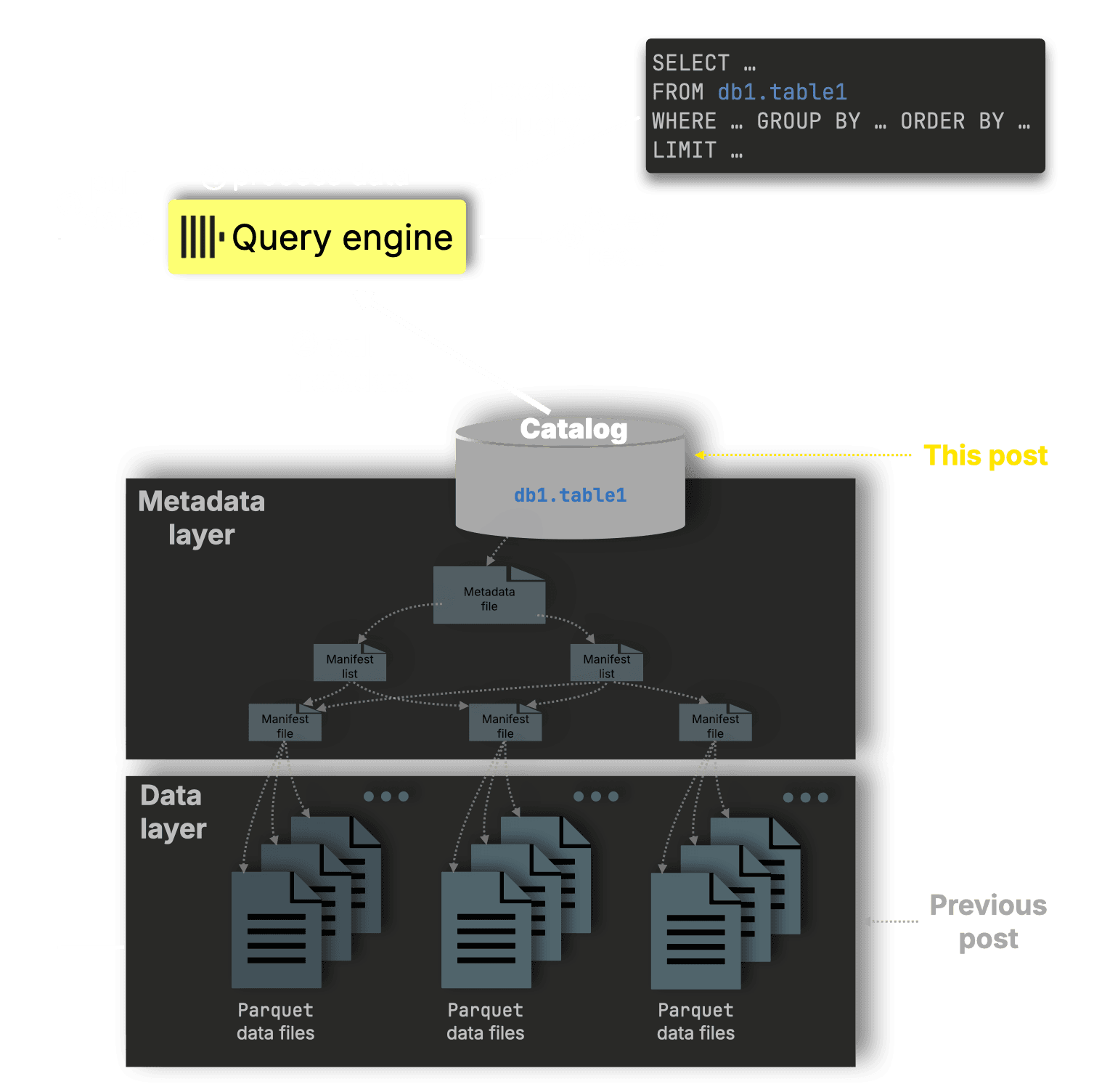
Catalogs like AWS Glue Catalog, Databricks Unity Catalog, Apache Polaris, and REST catalogs form the metadata backbone of modern data lakes.
They manage schemas, partitions, and table versions without duplicating data, making formats like Iceberg and Delta Lake behave like fully structured, queryable systems.
By connecting directly to these catalogs, ClickHouse now discovers lakehouse tables automatically, understands their structure, and queries them at full speed.
If it’s in your catalog, you can query it, instantly, with ClickHouse.
And while the DataLakeCatalog engine is open source, this post focuses on ClickHouse Cloud, where integration with Glue and Unity Catalog enters beta with ClickHouse version 25.8.
We’ll walk through how ClickHouse Cloud brings every layer together, from fast Parquet reads to full catalog integration, and show it live with quick demos on Glue and Unity Catalog. Then we’ll take it one step further, exploring federated queries across catalogs and a glimpse at what’s coming next for the lakehouse in ClickHouse Cloud.
ClickHouse Cloud is fully lakehouse-ready #
ClickHouse Cloud brings every layer of the modern analytics stack together, delivering full lakehouse readiness.
Over recent releases, we’ve rebuilt the core layers — parquet file reader, caching, and metadata — so whether your data lives in MergeTree, Iceberg, or Delta Lake, ClickHouse queries it through the same high-performance execution path.
A highly parallel, ClickHouse-native Parquet reader #
The new native Parquet reader replaces the earlier Arrow-based implementation with a ClickHouse-native one that reads Parquet data directly into the engine’s in-memory format.
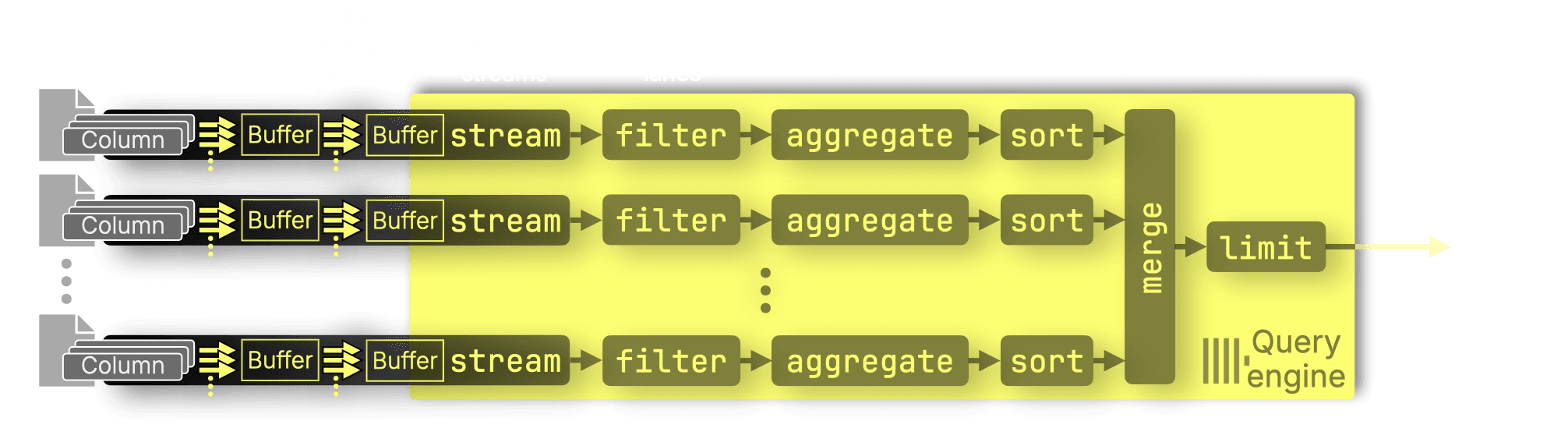
It parallelizes column reads within row groups, adds page-level filtering and PREWHERE support, and improves Parquet query speed by 1.8× on average across ClickBench.
Parallel query scaling for Iceberg, Delta Lake, and native ClickHouse tables #
Analytical queries now scale efficiently across all CPU cores and compute nodes, delivering sub-second results even on datasets with tens or hundreds of billions of rows (without any pre-aggregation).

For external Iceberg and Delta Lake tables we use the same partial-aggregation-state execution model as for native tables, with work distributed by Parquet file instead of granule, delivering consistent performance across all data sources.
We’ll be showcasing this parallel query scaling in action on massive Iceberg and Delta Lake tables in a future post, stay tuned.
Distributed cache layer for Iceberg, Delta Lake, and native ClickHouse tables #
Exclusive to ClickHouse Cloud, the distributed cache provides shared, low-latency access to hot data across all compute nodes.

It eliminates repeated S3 reads, reduces tail latency from hundreds of milliseconds to microseconds, and enables truly stateless, elastic compute that scales instantly without losing cached data.
As shown in the next section, the distributed cache also extends to external Iceberg and Delta Lake tables, caching their underlying Parquet files for even faster subsequent access.
Stateless compute for Iceberg, Delta Lake, and native ClickHouse tables #
With the Shared Catalog, ClickHouse Cloud compute nodes no longer need local disks.
Metadata is centralized, versioned, and fetched on demand, allowing instant startup, elastic scaling, and seamless querying across native and open table formats.
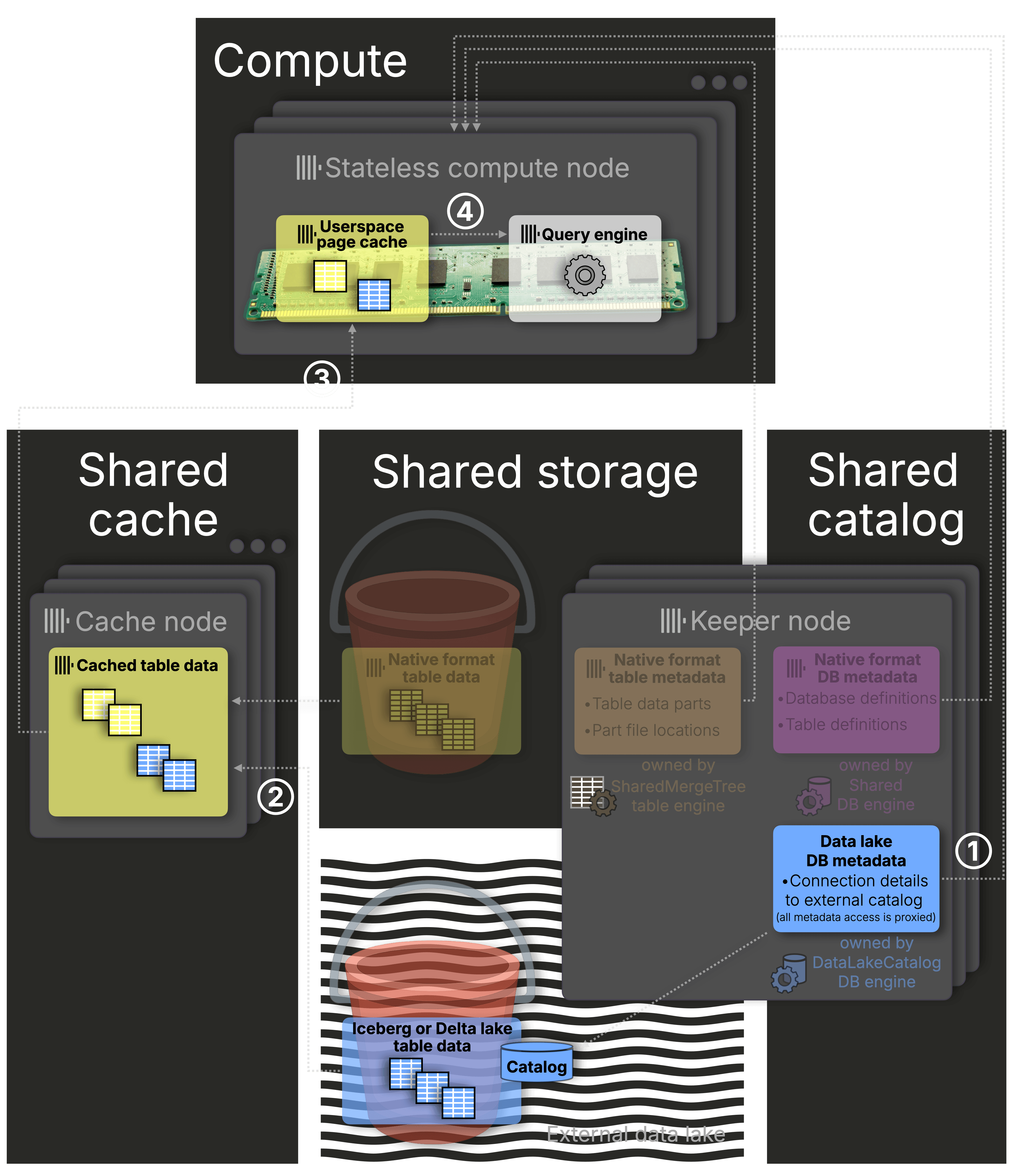
Together, these layers form the unified foundation of ClickHouse Cloud:
① Shared Catalog – instant, consistent metadata access
② Distributed Cache – fast, shared access to cold data
③ Userspace Page Cache – fine-grained, in-memory caching
④ Parallel Execution – massive, distributed query parallelism
The same performance layers apply for Iceberg and Delta Lake tables, just like with native tables.
Full Iceberg and Delta Lake compatibility #
ClickHouse now offers full support for both major open table formats, Apache Iceberg and Delta Lake.
For Iceberg, ClickHouse supports the complete v2 feature set: schema evolution, time travel, statistics-based pruning, and catalog integration (Unity, REST, Polaris, and more).
For Delta Lake, ClickHouse supports full Unity Catalog integration, Delta Kernel support, partition pruning, and schema evolution.
Together, these unlock DML compatibility and deep metadata introspection, paving the way for write support and Iceberg v3 in upcoming releases.
The DataLakeCatalog database engine #
The DataLakeCatalog database engine is the bridge between ClickHouse and your lakehouse catalogs.
It turns catalog metadata into queryable tables, allowing you to query Iceberg and Delta Lake data as if it were native.
Database engines vs. table engines in ClickHouse
In ClickHouse, table engines handle how data is stored and queried, while database engines handle how tables are organized and discovered.
This separation enables ClickHouse to specialize in both data storage and metadata management, and, as we’ll see below, allows the DataLakeCatalog database engine to automatically pick the right table engine (Iceberg or DeltaLake) from catalog metadata.
As integration with AWS Glue and Databricks Unity Catalog enters beta with the ClickHouse 25.8 release in ClickHouse Cloud, let’s look at a few quick demos.
Demo 1: Querying AWS Glue Catalog #
The first example shows how ClickHouse Cloud connects to an AWS Glue Catalog and queries Apache Iceberg tables stored in S3. In just a few steps, we’ll connect, explore the catalog, and run our first query.
What is AWS Glue Catalog? #
AWS Glue Catalog is a fully managed data catalog and ETL service that stores table metadata and makes data in Amazon S3 queryable across analytics tools.
The screenshot below shows the AWS Glue-managed table player_match_history_iceberg_p, a partitioned Apache Iceberg table storing game data for Deadlock, a video game developed by Valve, in S3:
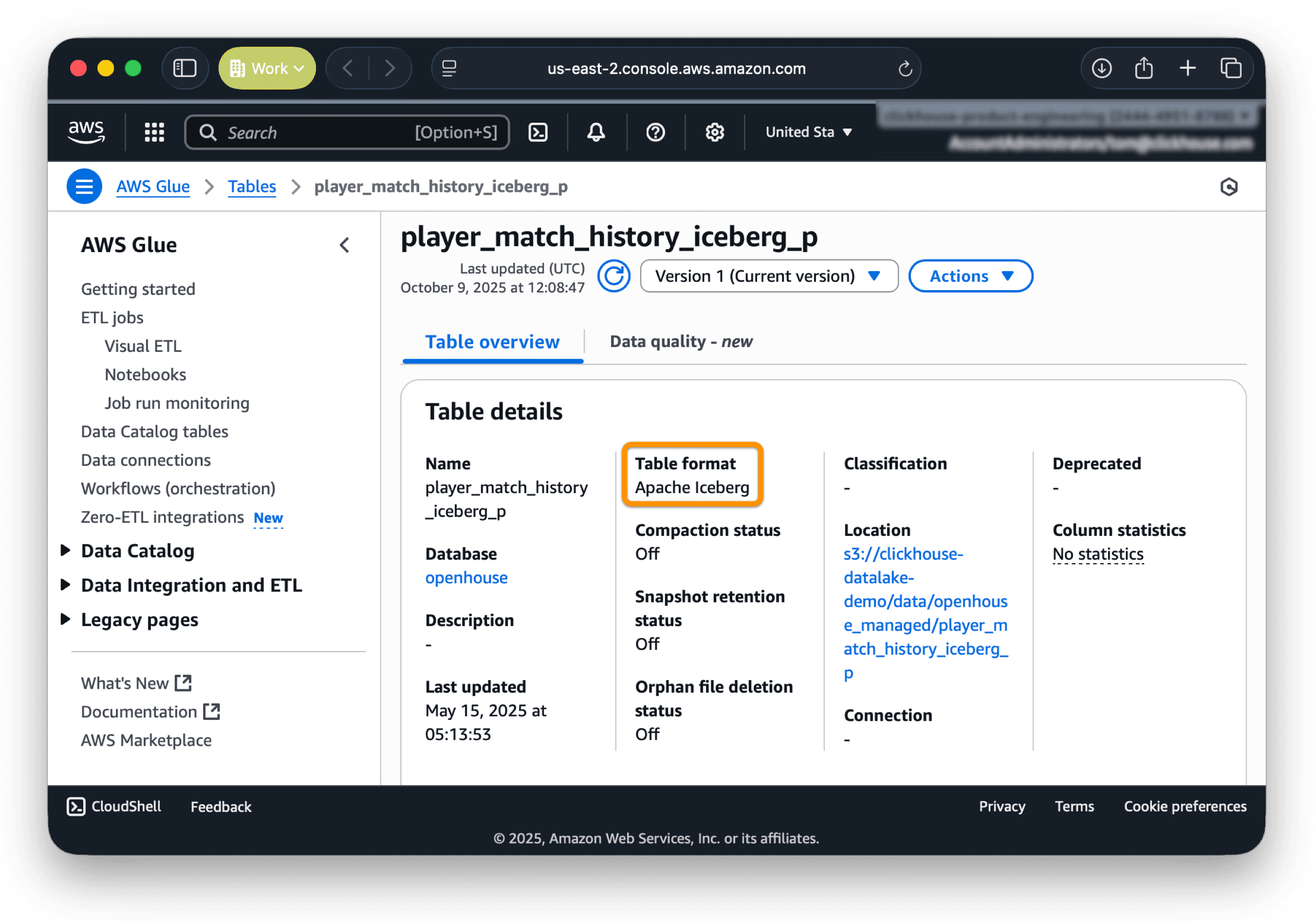
(Credit to Deadlock API as the source of this data)
Note: All queries in the examples below were run from an EC2 instance using the clickhouse-client, connected to a ClickHouse Cloud service deployed in AWS us-east-2 running ClickHouse 25.8.
Connecting ClickHouse Cloud to AWS Glue Catalog #
With ClickHouse version 25.8 in ClickHouse Cloud, you can connect to the AWS Glue Catalog instance from the example above by creating a database using the DataLakeCatalog engine:
CREATE DATABASE glue
ENGINE = DataLakeCatalog
SETTINGS
catalog_type = 'glue',
region = 'us-east-2',
aws_access_key_id = '...',
aws_secret_access_key = '...',
allow_database_glue_catalog = 1; -- beta feature in Cloud
The
gluedatabase we created in ClickHouse Cloud acts as a local proxy for the remote AWS Glue Catalog.

It behaves like a normal ClickHouse database, supporting the same metadata lookups and queries you’d use on native databases.
Exploring metadata #
Now that the AWS Glue Catalog is connected, we can run the usual metadata lookups available in any ClickHouse database, for example, listing all tables:
SHOW tables FROM glue;
┌─name──────────────────────────────────────────────────┐ │ agenthouse.player_match_history │ │ clickhouse_datalake_demo.player_match_history_delta │ │ clickhouse_datalake_demo.player_match_history_iceberg │ │ clickhouse_datalake_demo.pypi_delta_flat │ │ clickhouse_datalake_demo.pypi_delta_part │ │ clickhouse_datalake_demo.pypi_iceberg_flat │ │ clickhouse_datalake_demo.pypi_iceberg_part │ │ clickhouse_datalake_demo.pypi_parquet │ │ clickhouse_datalake_demo.pypi_test_iceberg_flat │ │ clickhouse_datalake_demo.pypi_test_iceberg_part │ │ openhouse.player_match_history_iceberg_p │ └───────────────────────────────────────────────────────┘
We can inspect the DDL of our example table directly from the connected Glue Catalog:
SHOW CREATE TABLE glue.`openhouse.player_match_history_iceberg_p`;
┌─statement──────────────────────────────────────────────────────┐ │ CREATE TABLE glue.`openhouse.player_match_history_iceberg_p` ↴│ │↳( ↴│ │↳ `account_id` Nullable(Int64), ↴│ │↳ `match_id` Nullable(Int64), ↴│ │↳ `hero_id` Nullable(Int64), ↴│ │↳ `hero_level` Nullable(Int64), ↴│ │↳ `start_time` Nullable(Int64), ↴│ │↳ `game_mode` Nullable(Int32), ↴│ │↳ `match_mode` Nullable(Int32), ↴│ │↳ `player_team` Nullable(Int32), ↴│ │↳ `player_kills` Nullable(Int64), ↴│ │↳ `player_deaths` Nullable(Int64), ↴│ │↳ `player_assists` Nullable(Int64), ↴│ │↳ `denies` Nullable(Int64), ↴│ │↳ `net_worth` Nullable(Int64), ↴│ │↳ `last_hits` Nullable(Int64), ↴│ │↳ `team_abandoned` Nullable(Bool), ↴│ │↳ `abandoned_time_s` Nullable(Int64), ↴│ │↳ `match_duration_s` Nullable(Int64), ↴│ │↳ `match_result` Nullable(Int64), ↴│ │↳ `objectives_mask_team0` Nullable(Int64), ↴│ │↳ `objectives_mask_team1` Nullable(Int64), ↴│ │↳ `created_at` Nullable(DateTime64(6)), ↴│ │↳ `event_day` Nullable(String), ↴│ │↳ `event_month` Nullable(String) ↴│ │↳) ↴│ │↳ENGINE = Iceberg('s3://clickhouse-datalake-demo/ ↴│ │↳ data/openhouse_managed/ ↴│ │ player_match_history_iceberg_p') │ └────────────────────────────────────────────────────────────────┘
Notice that the table’s engine is Iceberg, the built-in ClickHouse table engine for reading Apache Iceberg data. The data itself lives remotely in Amazon S3.
While we could have used the Iceberg engine directly by specifying the S3 path manually, the DataLakeCatalog database engine does this automatically by reading metadata from the AWS Glue Catalog.
Since the catalog entry identifies player_match_history_iceberg_p as an Iceberg table, ClickHouse transparently routes the query through its Iceberg engine, leveraging all standard Iceberg optimizations (a topic for another post).
The diagram below summarizes how this works end-to-end:
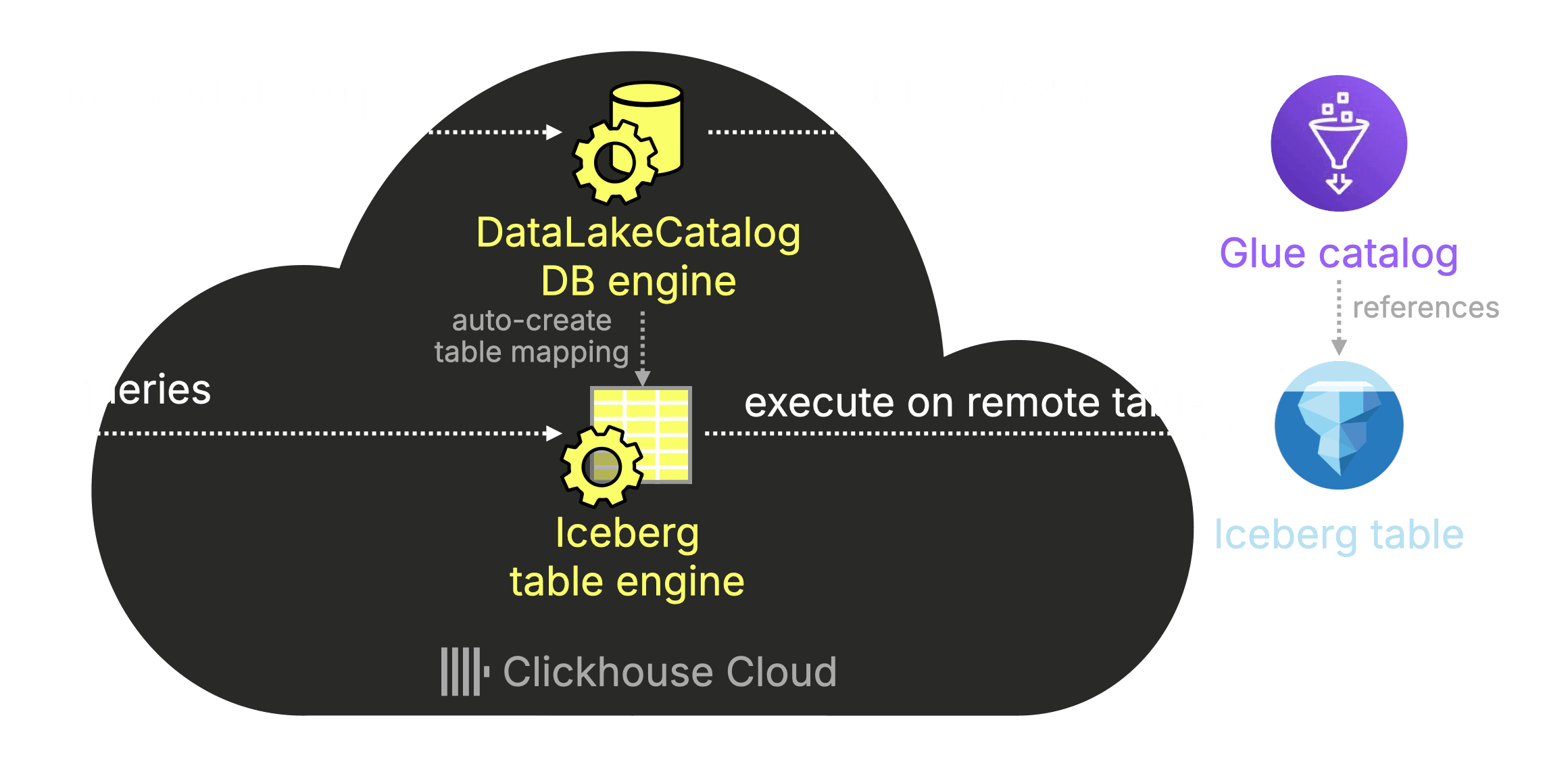
Querying Iceberg data #
Now let’s run a query over the table to return Deadlock match activity per day for March 2024:
SELECT
toDate(toDateTime(start_time)) AS day,
count() AS matches,
round(avg(match_duration_s) / 60, 1) AS avg_match_min
FROM glue.`openhouse.player_match_history_iceberg_p`
WHERE toDate(toDateTime(start_time)) BETWEEN toDate('2024-03-01') AND toDate('2024-03-31')
GROUP BY day
ORDER BY day;
┌────────day─┬─matches─┬─avg_match_min─┐ │ 2024-03-01 │ 19 │ 27.8 │ │ 2024-03-04 │ 16 │ 31.4 │ │ 2024-03-06 │ 39 │ 54.6 │ │ 2024-03-08 │ 18 │ 42.5 │ │ 2024-03-11 │ 36 │ 26.8 │ │ 2024-03-13 │ 60 │ 36.5 │ │ 2024-03-15 │ 38 │ 37.9 │ │ 2024-03-18 │ 19 │ 18.8 │ │ 2024-03-20 │ 58 │ 33.2 │ │ 2024-03-22 │ 39 │ 34.2 │ │ 2024-03-25 │ 16 │ 40.2 │ │ 2024-03-27 │ 39 │ 35.6 │ │ 2024-03-29 │ 20 │ 22.7 │ └────────────┴─────────┴───────────────┘ 13 rows in set. Elapsed: 0.347 sec. Processed 339.04 million rows, 6.35 GB (977.46 million rows/s., 18.32 GB/s.) Peak memory usage: 507.28 MiB.
Result: from zero to Iceberg in under a minute #
From zero to Iceberg in under a minute.
That’s all it took to
- Connect ClickHouse Cloud to a AWS Glue Catalog with the DataLakeCatalog engine
- Explore the catalog
- Query Iceberg data like it was native
Demo 2: Querying Unity Catalog #
Next, let’s connect to Unity Catalog, which manages Delta Lake tables (and Iceberg). The setup is just as simple, we’ll create the catalog connection, inspect metadata, and query Delta Lake data directly.
What is Unity Catalog? #
Unity Catalog is a unified governance and metadata layer that manages tables across workspaces and storage systems, including Delta Lake.
The screenshot below shows the Unity-managed table stackoverflow.posts_full, a Delta Lake table storing Stack Overflow data, registered in Databricks and ready to be queried directly from ClickHouse Cloud using the DataLakeCatalog engine:
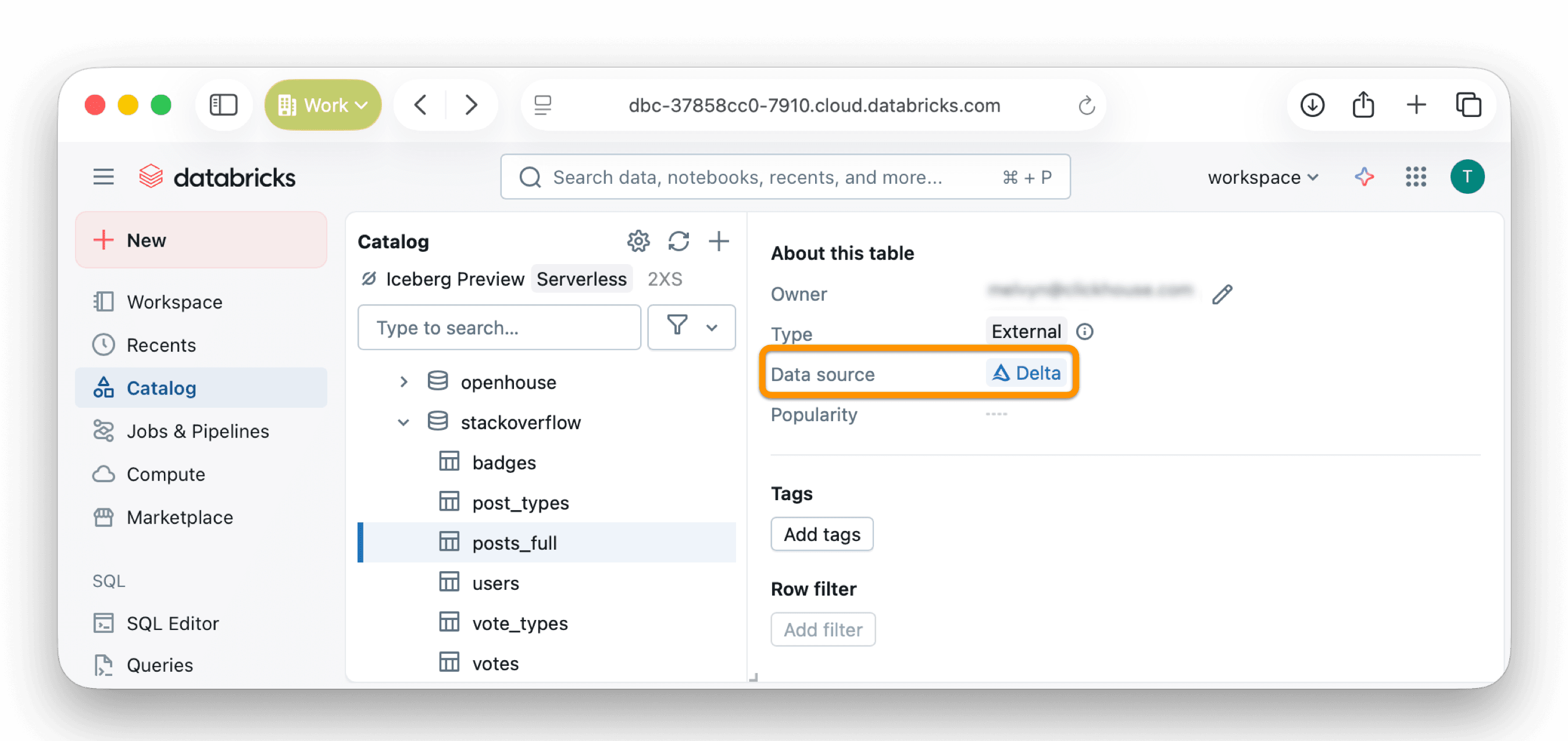
Connecting ClickHouse Cloud to Unity Catalog #
First, we connect to that external Unity Catalog similar to our AWS Glue Catalog example, by again creating a database using the DataLakeCatalog engine:
CREATE DATABASE unity
ENGINE = DataLakeCatalog('https://dbc-37858cc0-7910.cloud.databricks.com/api/2.1/unity-catalog')
SETTINGS
catalog_type = 'unity'
warehouse = 'workspace',
catalog_credential = '...',
allow_database_unity_catalog = 1; -- beta feature in Cloud
The unity database acts as a local proxy for the remote Unity Catalog:

Exploring metadata #
The created database behaves like a “normal” databases in ClickHouse and we can list all tables:
SHOW tables FROM unity;
┌─name─────────────────────┐ │ stackoverflow.badges │ │ stackoverflow.post_types │ │ stackoverflow.posts_full │ │ stackoverflow.users │ │ stackoverflow.vote_types │ │ stackoverflow.votes │ └──────────────────────────┘
Lets inspect the DDL of the stackoverflow.posts_full table:
SHOW CREATE TABLE unity.`stackoverflow.posts_full`;
┌─statement──────────────────────────────────────────────────────────────────┐ │ CREATE TABLE unity.`stackoverflow.posts_full` ↴│ │↳( ↴│ │↳ `id` Nullable(Int32), ↴│ │↳ `post_type_id` Nullable(Int32), ↴│ │↳ `accepted_answer_id` Nullable(Int32), ↴│ │↳ `creation_date` Nullable(Int64), ↴│ │↳ `score` Nullable(Int32), ↴│ │↳ `view_count` Nullable(Int32), ↴│ │↳ `body` Nullable(String), ↴│ │↳ `owner_user_id` Nullable(Int32), ↴│ │↳ `owner_display_name` Nullable(String), ↴│ │↳ `last_editor_user_id` Nullable(Int32), ↴│ │↳ `last_editor_display_name` Nullable(String), ↴│ │↳ `last_edit_date` Nullable(Int64), ↴│ │↳ `last_activity_date` Nullable(Int64), ↴│ │↳ `title` Nullable(String), ↴│ │↳ `tags` Nullable(String), ↴│ │↳ `answer_count` Nullable(Int32), ↴│ │↳ `comment_count` Nullable(Int32), ↴│ │↳ `favorite_count` Nullable(Int32), ↴│ │↳ `content_license` Nullable(String), ↴│ │↳ `parent_id` Nullable(Int32), ↴│ │↳ `community_owned_date` Nullable(Int64), ↴│ │↳ `closed_date` Nullable(Int64) ↴│ │↳) ↴│ │↳ENGINE = DeltaLake('s3://unitycatalogdemobucket/stackoverflow/posts_full') │ └────────────────────────────────────────────────────────────────────────────┘
Notice that this time the table’s engine is DeltaLake, the built-in ClickHouse table engine for reading Delta lake table data. The data resides remotely in Amazon S3.
ClickHouse automatically selected the DeltaLake engine after detecting in the catalog metadata that stackoverflow.posts_full is a Delta Lake table:
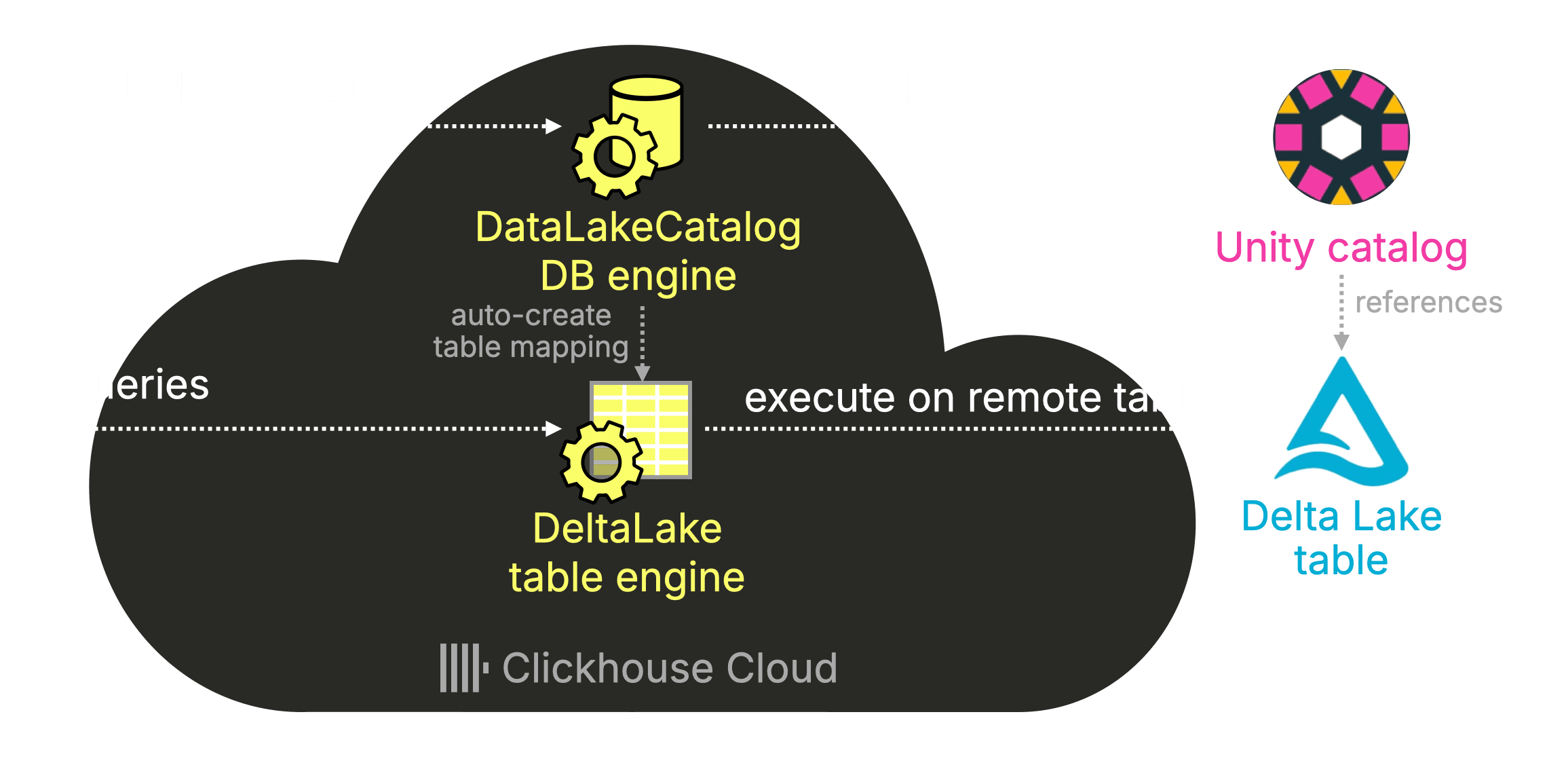
Querying Delta Lake data #
Finally we run a query over the table to return Stack Overflow “Deadlock” posts per day for March 2024:
SELECT
toDate(toDateTime(creation_date)) AS day,
uniq(id) AS posts,
sum(view_count) AS views
FROM unity.`stackoverflow.posts_full`
WHERE post_type_id = 1
AND toDate(toDateTime(creation_date)) BETWEEN toDate('2024-03-01') AND toDate('2024-03-31')
AND (
positionCaseInsensitive(coalesce(title, ''), 'Deadlock') > 0
OR positionCaseInsensitive(coalesce(body, ''), 'Deadlock') > 0
)
GROUP BY day
ORDER BY day;
┌────────day─┬─posts─┬─views─┐ │ 2024-03-01 │ 2 │ 1533 │ │ 2024-03-02 │ 1 │ 43 │ │ 2024-03-03 │ 1 │ 130 │ │ 2024-03-04 │ 2 │ 81 │ │ 2024-03-05 │ 3 │ 213 │ │ 2024-03-06 │ 3 │ 237 │ │ 2024-03-08 │ 2 │ 80 │ │ 2024-03-09 │ 2 │ 72 │ │ 2024-03-11 │ 2 │ 76 │ │ 2024-03-12 │ 2 │ 61 │ │ 2024-03-13 │ 2 │ 49 │ │ 2024-03-14 │ 1 │ 15 │ │ 2024-03-16 │ 2 │ 83 │ │ 2024-03-18 │ 1 │ 36 │ │ 2024-03-19 │ 5 │ 226 │ │ 2024-03-20 │ 3 │ 65 │ │ 2024-03-21 │ 2 │ 134 │ │ 2024-03-22 │ 3 │ 143 │ │ 2024-03-24 │ 2 │ 100 │ │ 2024-03-25 │ 4 │ 117 │ │ 2024-03-26 │ 5 │ 291 │ │ 2024-03-27 │ 3 │ 97 │ │ 2024-03-28 │ 3 │ 107 │ │ 2024-03-30 │ 2 │ 76 │ │ 2024-03-31 │ 1 │ 45 │ └────────────┴───────┴───────┘ 25 rows in set. Elapsed: 6.989 sec. Processed 59.82 million rows, 36.79 GB (8.56 million rows/s., 5.26 GB/s.) Peak memory usage: 16.56 GiB.
As we just demonstrated across two catalog types and two open table formats:
If it’s in your catalog, you can query it with ClickHouse Cloud.
But that’s only the beginning. Because ClickHouse can query data from anywhere, native or external, those same connections become the foundation for federated queries.
Demo 3: Federated query across catalogs #
So far, we’ve queried Iceberg data via AWS Glue Catalog and Delta Lake data via Unity Catalog.
Now let’s bring it all together, and show how ClickHouse can join them directly, in a single query.
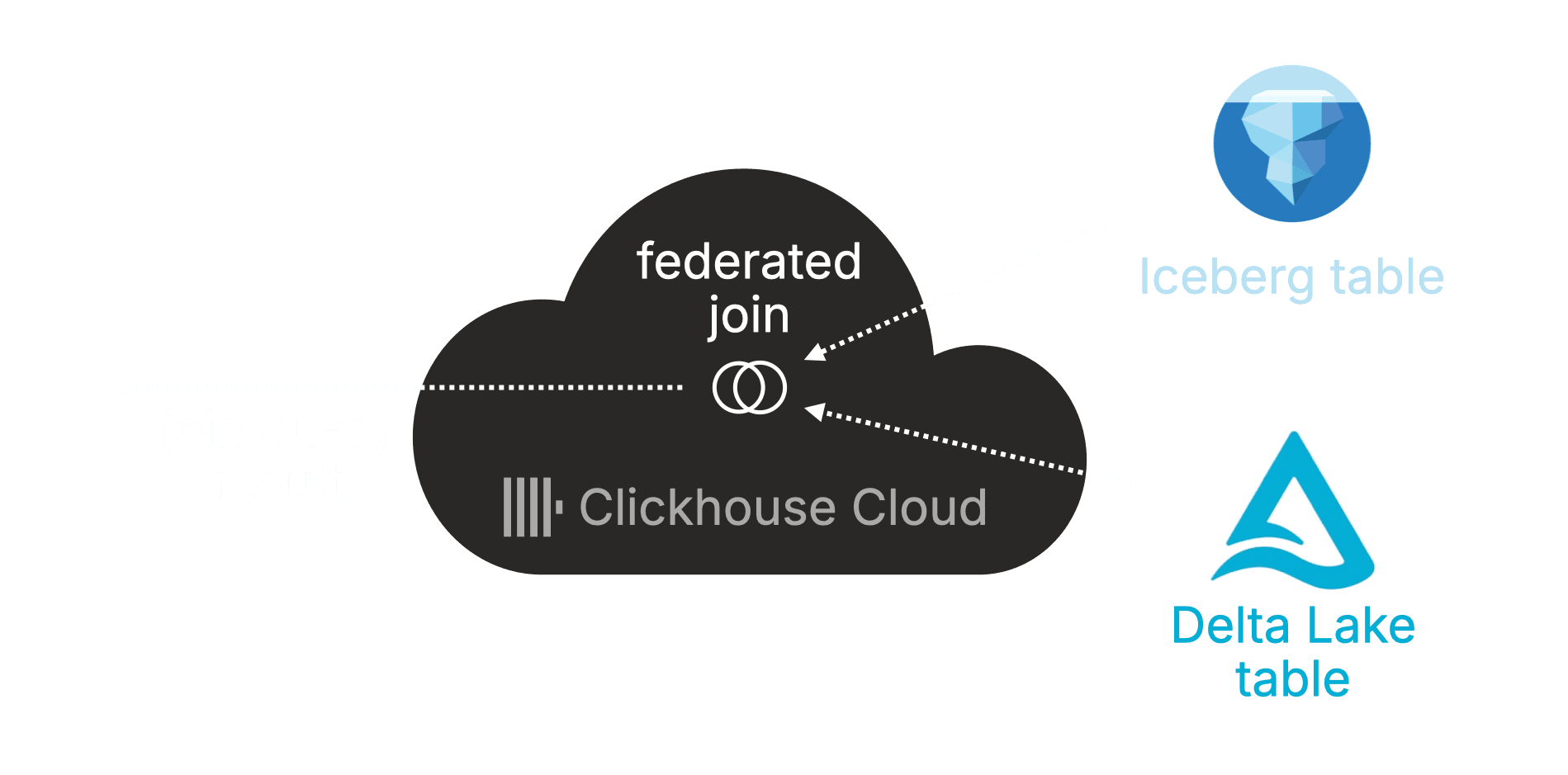
That’s true data lakehouse power.
The example below joins Deadlock match history from AWS Glue Catalog (Iceberg) with Stack Overflow posts mentioning Deadlock from Unity Catalog (Delta Lake), day by day, analyzing how gameplay and community discussion evolve together, all within ClickHouse Cloud:
WITH
so AS (
SELECT
toDate(toDateTime(creation_date)) AS day,
uniq(id) AS posts,
sum(view_count) AS views
FROM unity.`stackoverflow.posts_full`
WHERE post_type_id = 1
AND toDate(toDateTime(creation_date)) BETWEEN toDate('2024-03-01') AND toDate('2024-03-31')
AND (
positionCaseInsensitive(coalesce(title,''), 'Deadlock') > 0
OR positionCaseInsensitive(coalesce(body,''), 'Deadlock') > 0
)
GROUP BY day
),
mh AS (
SELECT
toDate(toDateTime(start_time)) AS day,
count() AS matches,
round(avg(match_duration_s)/60, 1) AS avg_match_min
FROM glue.`openhouse.player_match_history_iceberg_p`
WHERE toDate(toDateTime(start_time)) BETWEEN toDate('2024-03-01') AND toDate('2024-03-31')
GROUP BY day
)
SELECT
mh.day,
mh.matches,
mh.avg_match_min,
so.posts,
so.views,
round(1000 * so.posts / nullIf(mh.matches, 0), 3) AS posts_per_1000_matches
FROM mh
JOIN so USING (day)
ORDER BY mh.day;
┌────────day─┬─matches─┬─avg_match_min─┬─posts─┬─views─┬─posts_per_1000_matches─┐ │ 2024-03-01 │ 19 │ 27.8 │ 2 │ 1533 │ 105.263 │ │ 2024-03-04 │ 16 │ 31.4 │ 2 │ 81 │ 125 │ │ 2024-03-06 │ 39 │ 54.6 │ 3 │ 237 │ 76.923 │ │ 2024-03-08 │ 18 │ 42.5 │ 2 │ 80 │ 111.111 │ │ 2024-03-11 │ 36 │ 26.8 │ 2 │ 76 │ 55.556 │ │ 2024-03-13 │ 60 │ 36.5 │ 2 │ 49 │ 33.333 │ │ 2024-03-18 │ 19 │ 18.8 │ 1 │ 36 │ 52.632 │ │ 2024-03-20 │ 58 │ 33.2 │ 3 │ 65 │ 51.724 │ │ 2024-03-22 │ 39 │ 34.2 │ 3 │ 143 │ 76.923 │ │ 2024-03-25 │ 16 │ 40.2 │ 4 │ 117 │ 250 │ │ 2024-03-27 │ 39 │ 35.6 │ 3 │ 97 │ 76.923 │ └────────────┴─────────┴───────────────┴───────┴───────┴────────────────────────┘ 11 rows in set. Elapsed: 7.430 sec. Processed 398.86 million rows, 43.15 GB (53.68 million rows/s., 5.81 GB/s.) Peak memory usage: 16.73 GiB.
Three demos. Two catalogs. Two open table formats. One query engine.
From AWS Glue Catalog, to Unity Catalog, to native ClickHouse tables, everything’s now part of the same analytical fabric.
What’s next #
ClickHouse Cloud’s lakehouse journey continues.
We’re working on:
-
Iceberg V3 support — full compliance with the next-gen spec, introducing deletion vectors, the VARIANT data type, and advanced schema evolution
-
Write support — enabling INSERT, UPDATE, and DELETE for lakehouse tables
-
Optimization support — automatic merging of small files into larger, more efficient ones
-
And some larger things are brewing, but for now, we’ll leave you with this animation…

Try it yourself #
The DataLakeCatalog engine is available today in ClickHouse Cloud.
Connect it to AWS Glue Catalog or Unity Catalog, and your Iceberg and Delta Lake tables become instantly queryable, with the same ClickHouse experience, now across your entire lakehouse.
If your lakehouse tables are in a catalog, you can query them with ClickHouse.
And if they’re not, ClickHouse probably still can (with one of the 90+ integrations).



