Introduction #
In this article, we dive into the world of MLOps and explore Feature Stores: the different types, why you may need one, and the main components. Considering this, we present how ClickHouse can be used to power a feature store and, thus, the model lifecycle, providing performance and flexibility.
This blog is mostly introductory on the topic and designed to act as a precursor to subsequent examples of training ML models using features residing in ClickHouse. As evidence of the potential here, we do present our recent integration with Featureform - an open-source “virtual” feature store, which we will use for future examples.
What is a Feature? #
Before addressing what a feature store is, it might be helpful to clarify what a feature is.
Put simply, a feature is some property of an entity that has predictive power for a Machine Learning (ML) model. An entity, in this sense, is a collection of features as well as a class or label representing a real-world concept. The features should, if of sufficient quality and if such a relationship exists, be useful in predicting the entity's class. For example, a bank transaction could be considered an entity. This may contain features such as the amount transacted and purchase/seller involved, with the class describing whether the transaction was fraudulent.

Developing features usually requires some prior data engineering steps and data transformation logic before they are available for use. They can then be used when either training a model or inferring results (making predictions) from it. In the former case, many features (and entities) will be combined and exposed as training data (usually of significant size) and used to train a model. In the latter inference case, the model is invoked with features that include data only available at prediction time e.g. the transaction details in the case of fraud prediction. Other features may originate from the same sources as the training data, but consist of the latest values e.g. the users account balance.
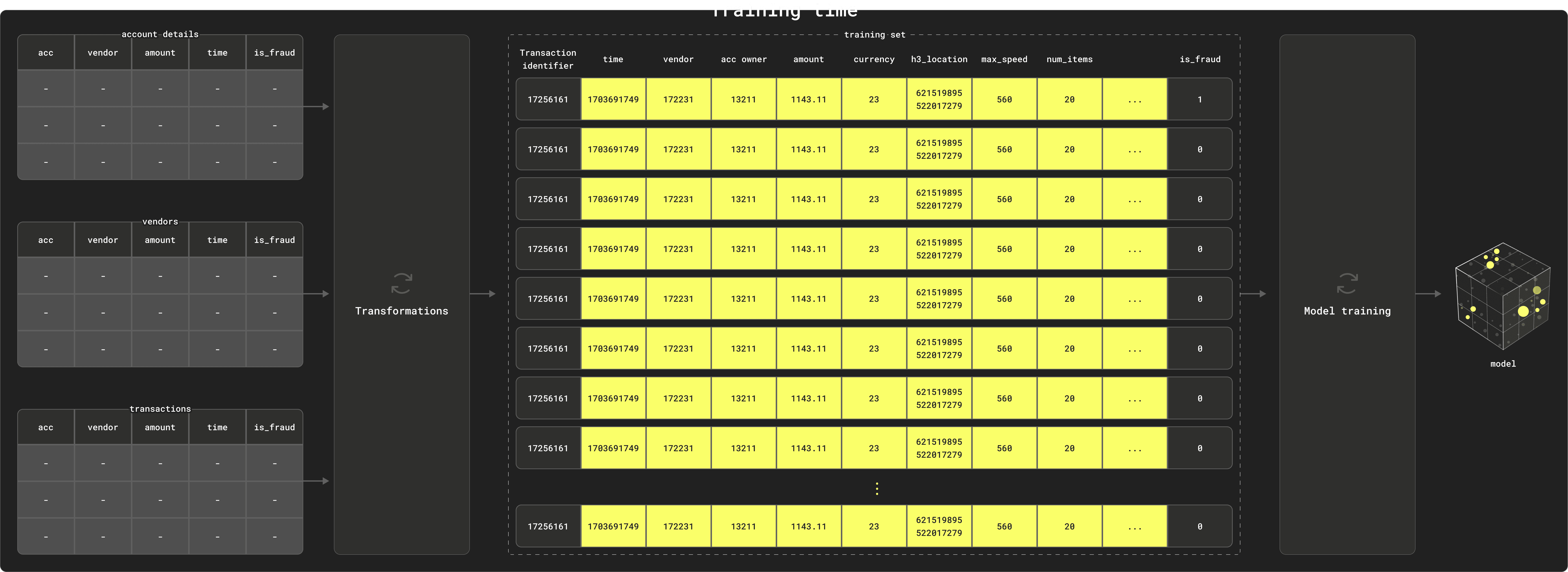
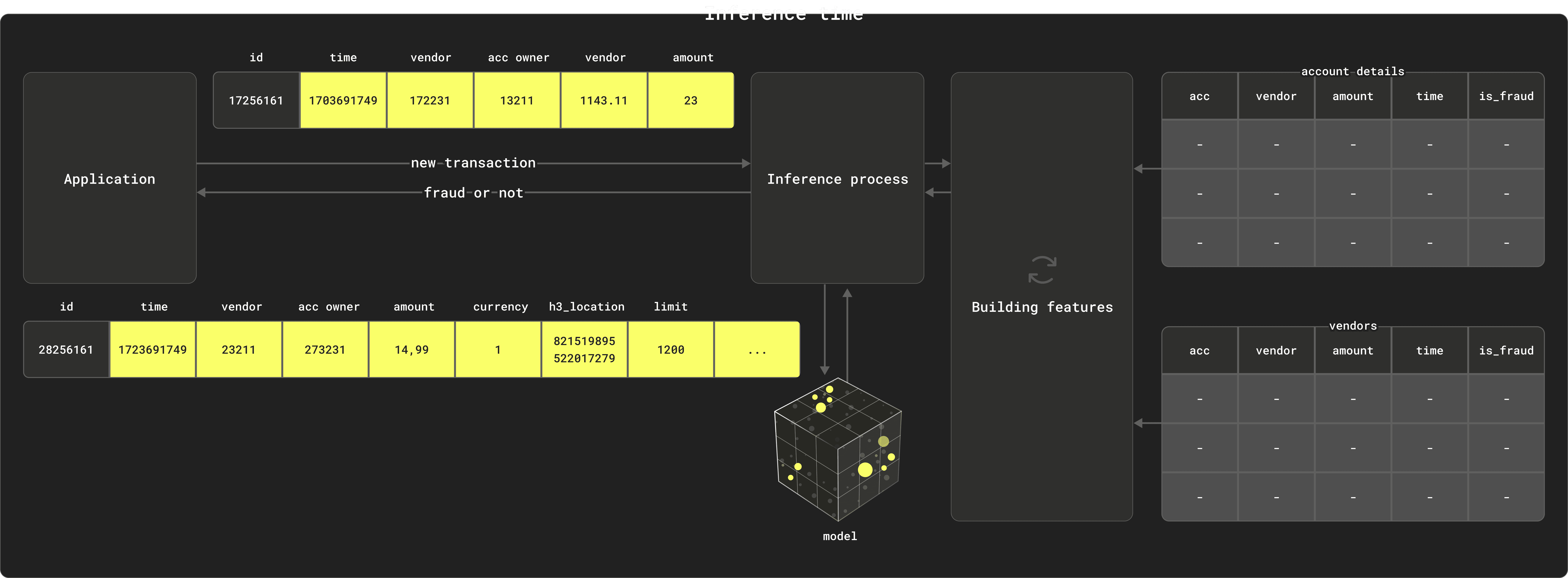
The above assumes features can always be built as required at inference time with similar transformations used at training time. This is sometimes not possible due to latency requirements, and thus often the latest version of some features need to be cached and pre-processed in an “online” store.
Training a model that predicts with any accuracy will nearly always (deep learning sometimes aside) require the data scientist to carefully select features that are correlated with the class being predicted.
What is a Feature Store? #
In its simplest form, a feature store is a centralized repository for storing and managing feature data and acting as the source of truth.
By providing APIs that allow the storage, versioning, and retrieval of features, feature stores aim to provide a consistent view of features for training and inference from development to production environments. Whether a custom-built in-house solution or off-the-shelf product, actual product-level features provided by a feature store will vary, with some providing a complete data platform capable of aggregating data into features and even providing a compute engine for the training of models - see Types of Feature Store below. Others provide a lighter-weight abstraction, managing metadata and versioning but deferring training and data/feature storage to other platforms and databases with which they integrate.
Irrespective of how many capabilities are inherent to the feature store, all provide abstractions to the underlying data with which data scientists and engineers will be familiar. As well as delivering data as versioned entities, features, and classes, most expose concepts of feature groups, training sets, batching, streaming, and point-in-time queries (such as the ability to identify the values for a feature at either a specific point, e.g. the latest value).
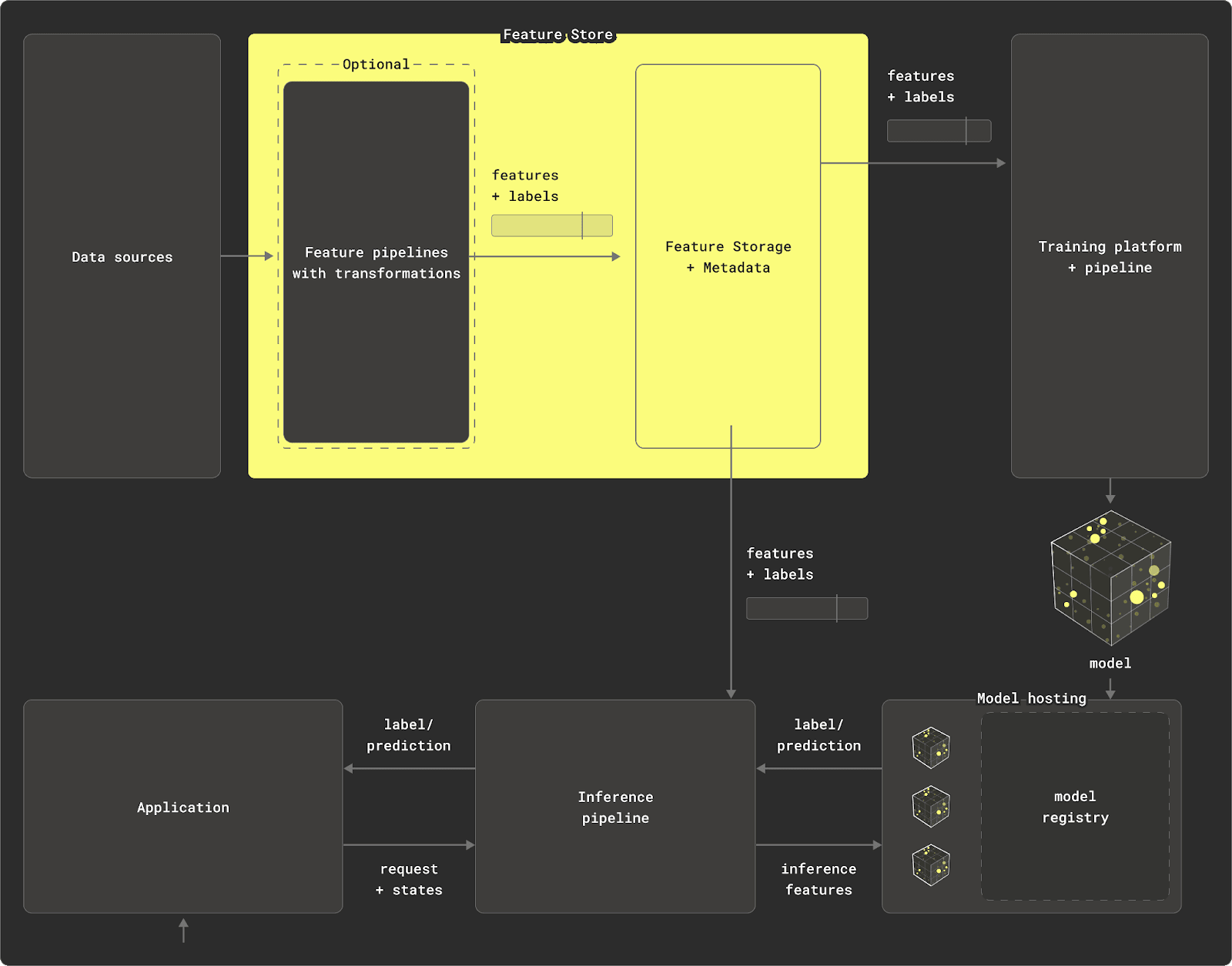
Why might you use one? #
In theory, a feature store ties disparate systems and capabilities together to form a complete ML data layer, capable of both acting as the source of truth for training data and also being used to provide context when predictions are being made.
While the exact capabilities they provide vary, the objectives remain the same:
- improve collaboration and reusability between data scientists and data engineers by centralizing features and their transformation logic
- reduce model iteration time during both experimentation and deployment by allowing feature re-use at both training and inference time
- governance and compliance through rules and versioning which can restrict model access to sensitive data (and features)
- improve model performance and reliability by abstracting the complexity of data engineering from data scientists and ensuring they work with only quality consistent features delivered through an API.
While these represent a very high-level overview of some of the problems a feature store solves, the predominant benefit here is the ability to share features across teams and utilize the same data for training and inference.
Feature stores also address a number of other challenges present in MLOps, such as how to backfill feature data, handle incremental updates to the source data (to update features), or monitor new data for drift. More recently, they have also integrated vector databases to act as the orchestration layer for RAG pipelines or to help find similar features using embeddings - a useful capability during some model training.
So, do you actually need one? #
When deciding whether to use an off-the-shelf feature store or build your own, the decision will likely depend on a few factors (in our opinion):
-
Existing tooling - If you use a complete ML platform, the chances are you don't need a feature store. Most of these capabilities are a subset of such a platform. However, these platforms are often the least flexible and the most costly and complex to adopt. Conversely, if you're using a collection of disparate systems and tooling to achieve different parts of your ML training and inference process, it may make sense.
-
Complexity and size - While ML model training doesn't need to be fundamental to your business, you probably need a decent number of datasets, models, and data scientists to justify the additional complexity. While it may be possible to work in an ad-hoc way for smaller use cases, moving larger more mission-critical models to production will require greater governance and stronger pipelines.
-
The benefits of abstractions - The abstractions offered by a feature store will benefit some teams more than others. If you have data scientists and data engineers with very distinct roles, the separation of concerns that can be possible with a feature store may be attractive. In this case, engineers can deliver features to data scientists through a simple API (in a terminology they understand), with the latter abstracted from the feature preparation processes.
Conversely, if your data scientists are comfortable with feature engineering, the abstractions offered probably offer less benefit. For example, assuming your data resides in a SQL-compatible database or data lake (accessible through a query engine), transformations could be managed through tooling such as dbt. This will require your data scientists to query tables directly in SQL but is likely to be sufficient, with dbt offering versioning and documentation of your transformations. However, this does leave you needing to address many of the other challenges of ML ops with specific point solutions.
Components of a Feature Store #
Before we explore how ClickHouse might fit into a feature store, understanding the common components is helpful for context. Typically, a feature store will consist of up to 4 main components:
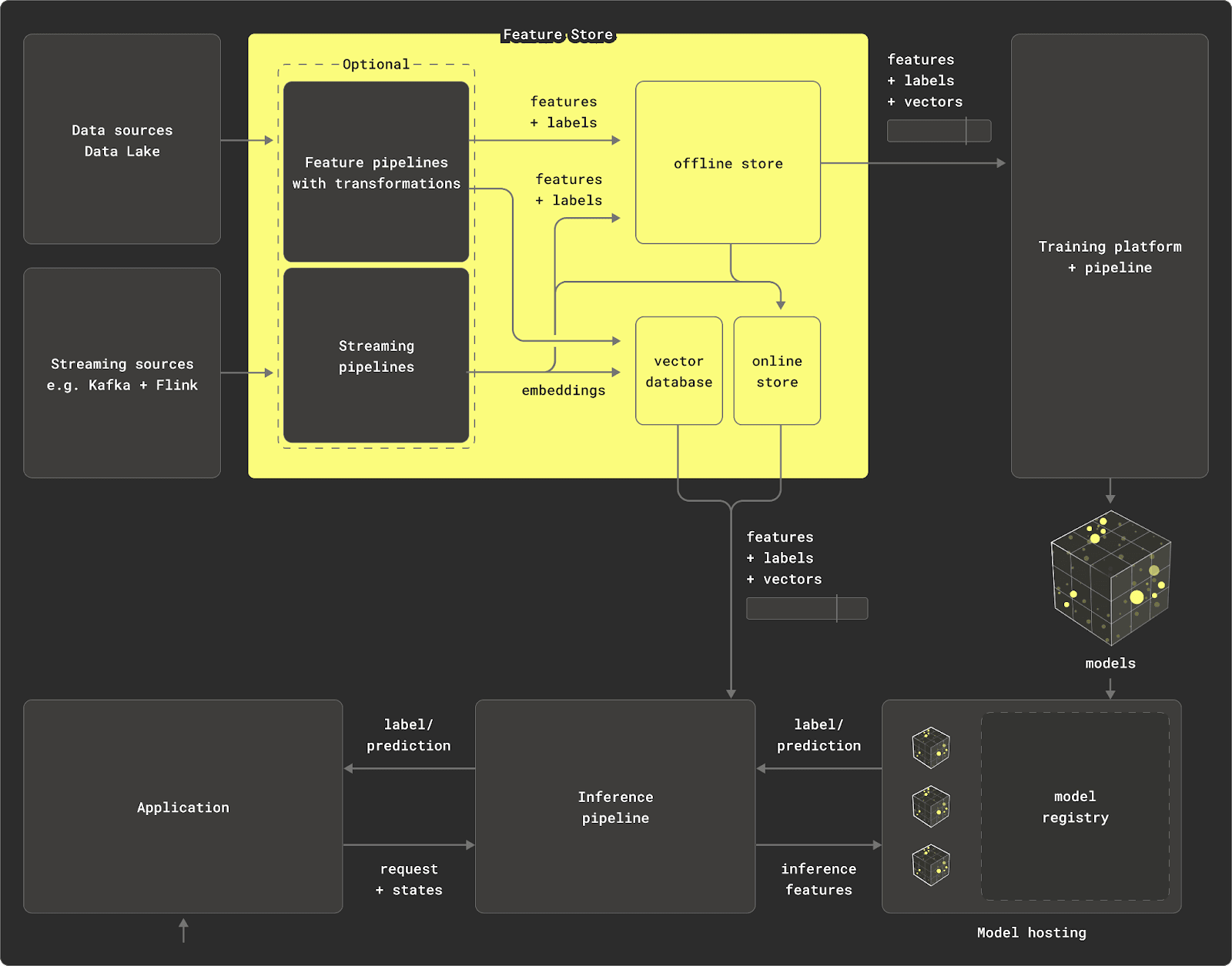
- Data source - While this can be as simple as a CSV file, it is often a database or data lake with files in a format like Iceberg and accessible through a query engine.
- Transformation engine (optional) - Raw data needs to be transformed into features. In a simple case, a feature can be correlated with a column's values. More likely, it is the result of a transformation process involving joins, aggregations, and expressions changing the structure and/or type of column values. Some feature stores (see Types of Feature Store) might provide built-in capabilities to achieve this; others may offload the work to local Python functions or, for larger datasets, the database (maybe even using dbt under the hood) via materializations, or a processing engine such as Spark. With ClickHouse, this is achievable through Materialized Views. Features that are continuously subject to update often require some form of streaming pipeline, typically implemented with tooling such as Flink or Spark Streaming. Normally, some form of directed acyclic graph (DAG) is required, if these transformations are chained, and dependencies need to be tracked.
- Offline (Training) Store - The offline store holds the features resulting from the previous transformation pipeline. These features are typically grouped as entities and associated with a label (the target prediction). Usually, models need to consume these features selectively, either iteratively or through aggregations, potentially multiple times and in random order. Models often require more than one feature, requiring features to be grouped together in a "feature group" - usually by an entity ID and time dimension. This requires the offline store to be able to deliver the correct version of a feature and label for a specific point in time. This "point-in-time correctness” is often fundamental to models, which need to be trained incrementally.
- Online (Interference) Store - Once a model has been trained, it can be deployed and used for making predictions. This inference process requires information that is only available at the moment of prediction, e.g. the user's ID for a transaction. However, it can also require features for the prediction, which may be precomputed, e.g. features representing historical purchases. These are often too expensive to compute at inference time, even for ClickHouse. These features need to be served in latency-sensitive situations, based on the most recent version of the data, especially in scenarios, where predictions need to be made in real-time, such as fraud detection. Features may be materialized from the offline store to the online store for serving.
The above omits a few components, which, while not necessarily part of the feature store, are heavily connected and required in any ML pipeline:
- Training engine & model hosting - Any pipeline requires a compute framework and engine for training models using the features in the offline store. This model, in turn, needs to be versioned and hosted such that it can be invoked to make inferences. A model registry can be an important component of this, providing model lineage, versioning, tagging, and annotations.
- Vector database - We have explored vector search and its applications in RAG workflows in previous blog posts. While not traditionally a component of a feature store, they share similarities to online stores. Typically, a vector embedding will be associated with an entity present in the store. The database can then be deployed in classical RAG workflows or to identify similar features - a capability useful in training and inference time.
All of the above requires some form of state management, e.g. to track feature versions. This is typically local to the store and will usually be small relative to the source data and features themselves.
Types of Feature Store #
Not all feature stores provide the above components directly, varying in their flexibility and features provided. For example, some may have an existing transformation engine and deploy a database such as Postgres for the offline store or Redis for the online component. Therefore, a degree of architectural flexibility and openness is required for ClickHouse to be integrated into a feature store.
We explore the differences below and how they may coexist with ClickHouse. For a more detailed description of the differences between a virtual feature store and the alternatives, literal and physical stores, we recommend the excellent blog by Featureform.
Physical store #
A physical store provides a more integrated solution, computing and storing the features. This type of store is common amongst proprietary vendors, such as Tecton, and usually consists of a transformation engine with integrated online and offline stores, as well as some streaming capabilities. Typically, they integrate with external data stores and can push some work to these, e.g. for data subset selection. In this case, the user is investing in a complete solution with limited flexibility. This lack of flexibility would have historically been compensated with greater performance. The user also has to learn significantly fewer technologies than with a literal store at the cost of potential vendor lock-in.
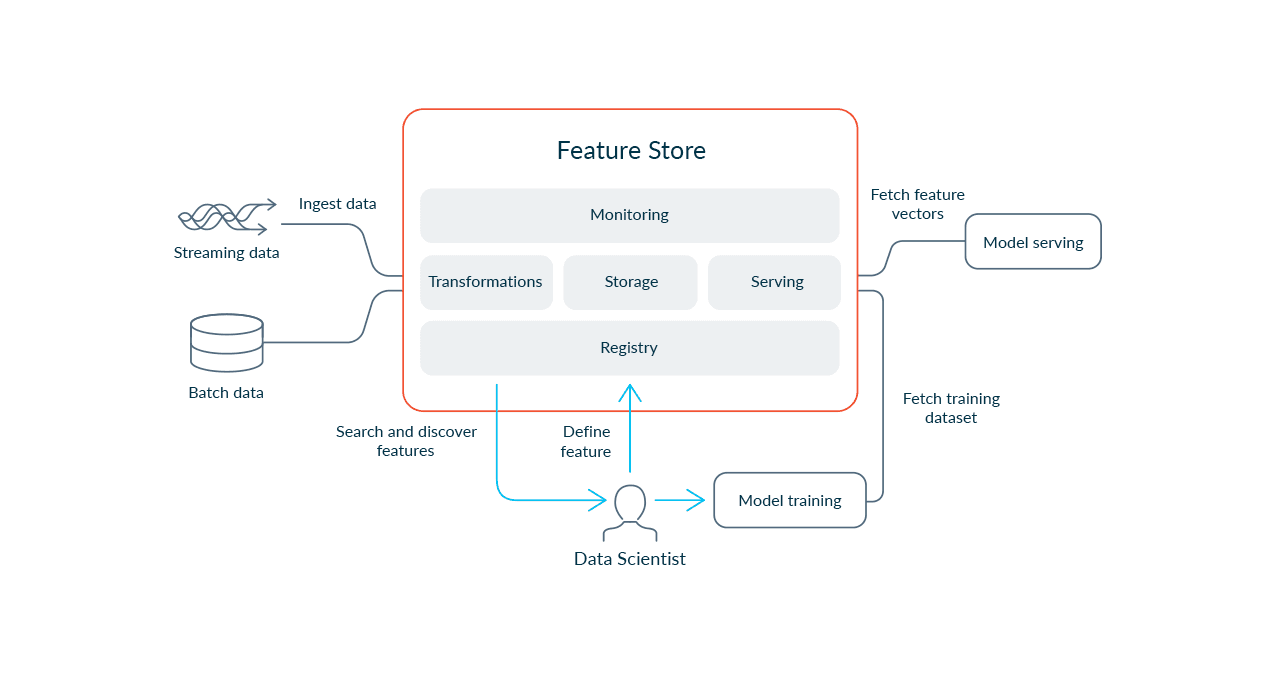 Tecton architecture - Credit: https://www.tecton.ai/
Tecton architecture - Credit: https://www.tecton.ai/
In this architecture, ClickHouse acts as a source repository for training data with few other opportunities for integration.
Literal store #
In a literal store, features are processed externally to the store, which acts as a centralized repository only. Features are usually sent to the offline store, and the process of materializing these into the online store is left to the user. These features are then served for inference with the point-in-time correctness capability typically exposed as described above. A feature store, in this sense, is an actual data store with a limited scope of only storing and serving features while sitting on top of an actual real data store. This classic implementation of this architecture is Feast. This approach offers the most flexibility but places the greatest burden on the adopter to build the transformation pipelines created to generate features from sources. Here, the user has to learn and connect a wide range of technologies to build a robust MLOps pipeline.
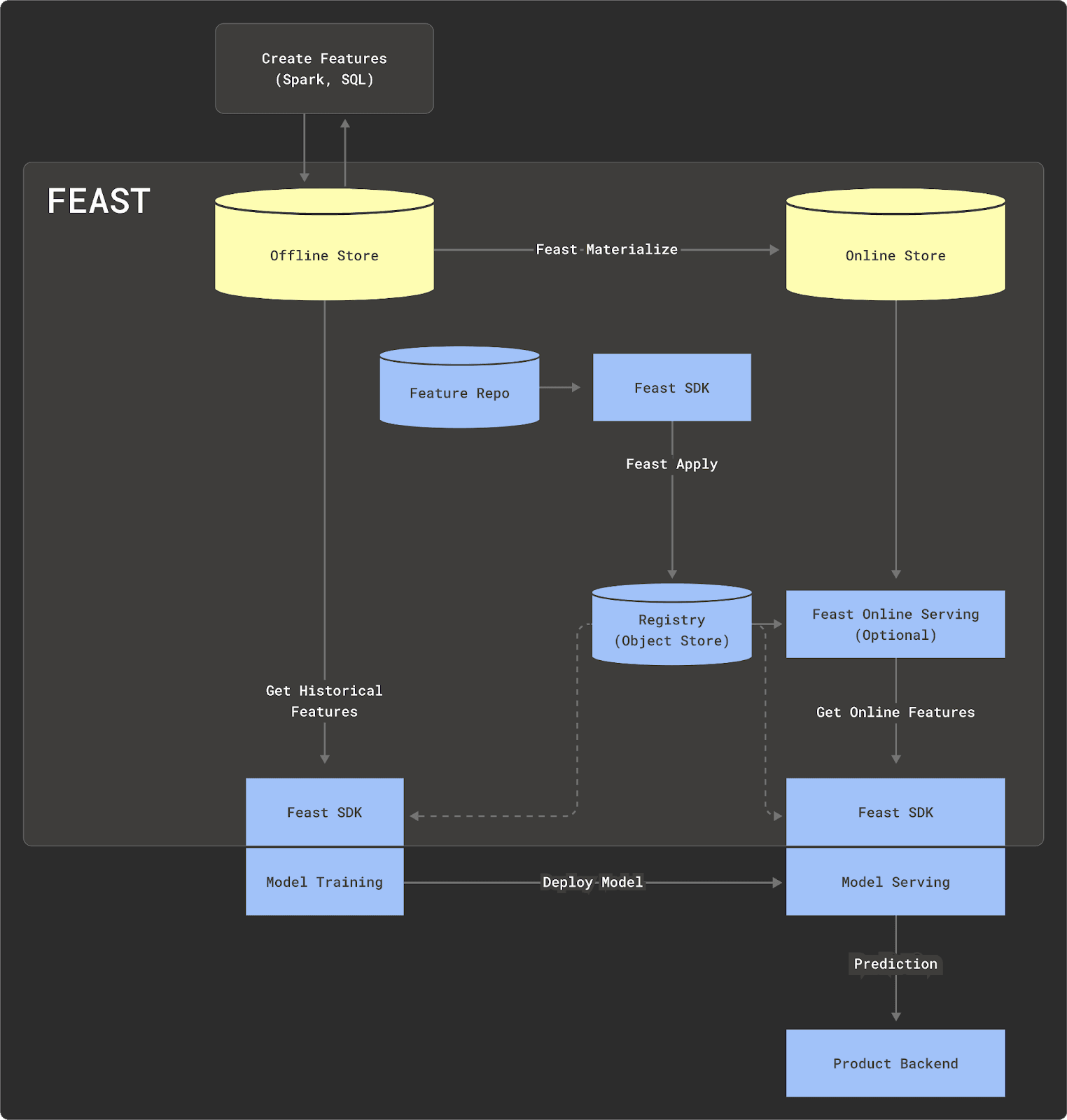 Feast architecture - Original: https://feast.dev/
Feast architecture - Original: https://feast.dev/
While ClickHouse could potentially be used as the storage engine for a literal store, this feature store type fails to fully utilize the capabilities of ClickHouse. ClickHouse can be used for more than just the storage and serving of features. While a literal store user could potentially use ClickHouse for transformations external to the store, it does not provide an integrated experience.
Virtual store #
Featureform is an open-source project describing itself as a "virtual feature store." Featureform presents the concept of a virtual store as a balance between the above architectures. In this case, the user can utilize any storage, transformation, and streaming engine of their choice in their infrastructure. The feature store is responsible for managing transformations and the persistence and versioning of features, but acts as an orchestrator only. This plug-in architecture leaves the adopter to choose their preferred technology for each component, allowing them to get the benefits of an integrated experience like a physical store while also maintaining the flexibility associated with a literal store. In this sense, a virtual store can be thought of as a workflow management and coordination layer, ensuring the best technology is used for each role while using the same abstractions data scientists and engineers are used to.
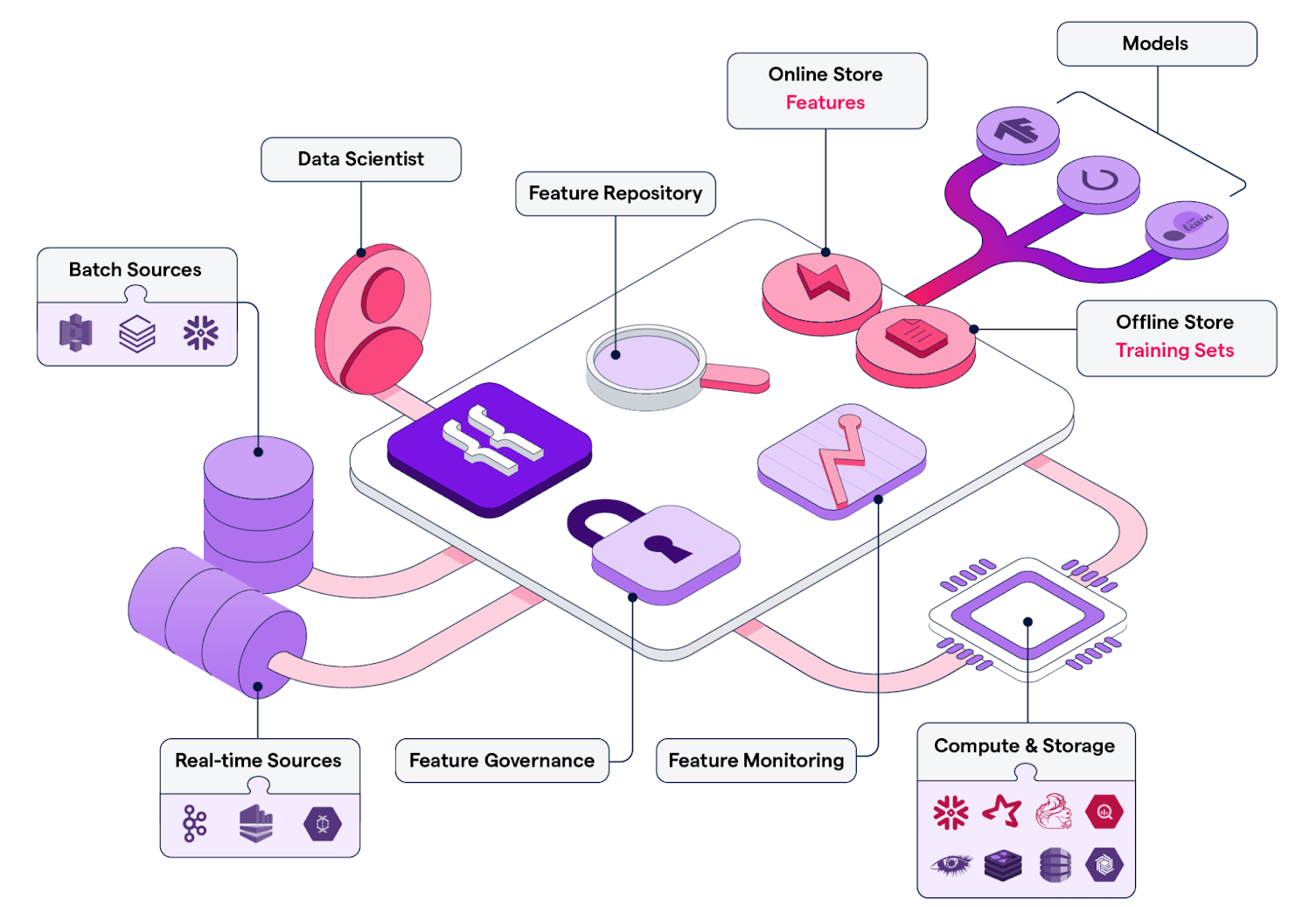 Featureform architecture - Credit: https://www.featureform.com/
Featureform architecture - Credit: https://www.featureform.com/
A virtual store with ClickHouse #
A traditional implementation of this architecture may have sacrificed some of the performance of a physical store to deliver an equivalent layer of coordination and management whilst retaining the same flexibility of a literal store. This flexibility additionally comes at some deployment cost, with a heterogeneous architecture inherently having a greater DevOps overhead. However, by powering significant components of the architecture with ClickHouse, users can achieve superior performance to a more heterogeneous architecture and reduce the management overhead. Expensive operations such as feature scaling and correlation matrix calculations can be performed in seconds on PiB datasets. Flexibility is also still preserved - if users wish to replace ClickHouse, they are free to do so while still retaining the consistent versioning scheme and centralized tracking of the feature definitions.
Feature Stores and ClickHouse #
As a real-time data warehouse, ClickHouse can fulfill the role of a number of the components - potentially significantly simplifying the feature store architecture.
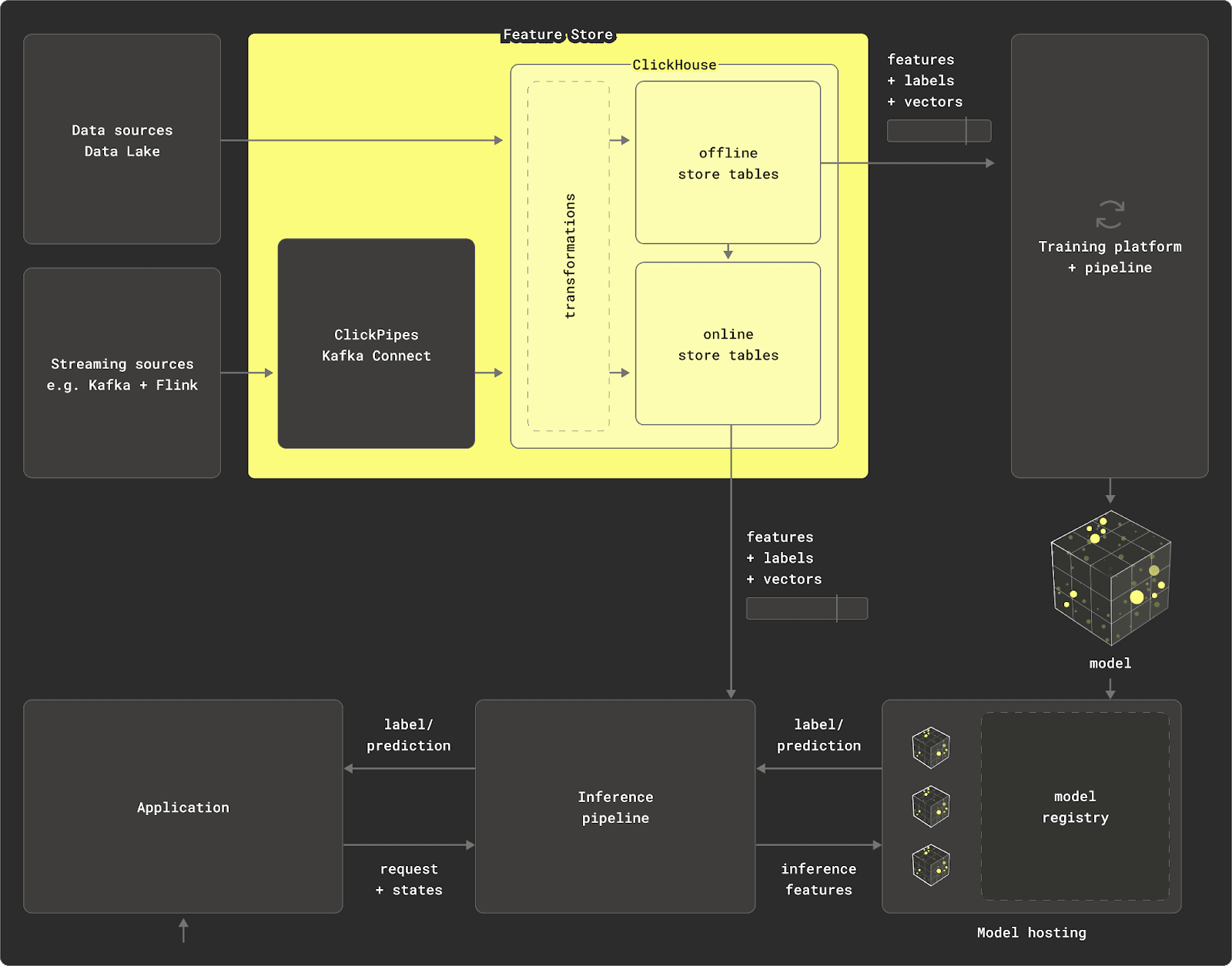
Specifically, ClickHouse can act as a:
-
Data source - With the ability to query or ingest data in over 70 different file formats, including data lake formats such as Iceberg and Delta Lake, ClickHouse makes an ideal long-term store holding or querying data. By separating storage and compute using object storage, ClickHouse Cloud additionally allows data to be held indefinitely - with compute scaled down or made completely idle to minimize costs. Flexible codecs, coupled with column-oriented storage and ordering of data on disk, maximize compression rates, thus minimizing the required storage. Users can easily combine ClickHouse with data lakes, with built-in functions to query data in place on object storage.
-
Transformation engine - SQL provides a natural means of declaring data transformations. When extended with ClickHouse’s analytical and statistical functions, these transformations become succinct and optimized. As well as applying to either ClickHouse tables, in cases where ClickHouse is used as a data store, table functions allow SQL queries to be written against data stored in formats such as Parquet, on-disk or object storage, or even other data stores such as Postgres and MySQL. A completely parallelization query execution engine, combined with a column-oriented storage format, allows ClickHouse to perform aggregations over PBs of data in seconds - unlike transformations on in memory dataframes, users are not memory-bound. Furthermore, materialized views allow data to be transformed at insert time, thus overloading compute to data load time from query time. These views can exploit the same range of analytical and statistical functions ideal for data analysis and summarization. Should any of ClickHouse’s existing analytical functions be insufficient or custom libraries need to be integrated, users can also utilize User Defined Functions (UDFs).
While users can transform data directly in ClickHouse or prior to insertion using SQL queries, ClickHouse can also be used in programming environments such as Python via chDB. This allows embedded ClickHouse to be exposed as a Python module and used to transform and manipulate large data frames within notebooks. This allows transformation work to be performed client-side by data engineers, with results potentially materialized as feature tables in a centralized ClickHouse instance.
-
Offline store - With the above capabilities to read data from multiple sources and apply transformations via SQL, the results of these queries can also be persisted in ClickHouse via
INSERT INTO SELECTstatements. With transformations often grouped by an entity ID and returning a number of columns as results, ClickHouse’s schema inference can automatically detect the required types from these results and produce an appropriate table schema to store them. Functions for generating random numbers and statistical sampling allow data to be efficiently iterated and scaled at millions or rows per second for feeding to model training pipelines.Often, features are represented in tables with a timestamp indicating the value for an entity and feature at a specific point in time. As described earlier, training pipelines often need the state of features at specific points in time and in groups. ClickHouse’s sparse indices allow fast filtering of data to satisfy point-in-time queries and feature selection filters. While other technologies such as Spark, Redshift, and BigQuery rely on slow stateful windowed approaches to identify the state of features at a specific point in time, ClickHouse supports the ASOF (as-of-this-time) LEFT JOIN query and argMax function. As well as simplifying syntax, this approach is highly performant on large datasets through the use of a sort and merge algorithm. This allows feature groups to be built quickly, reducing data preparation time prior to training.
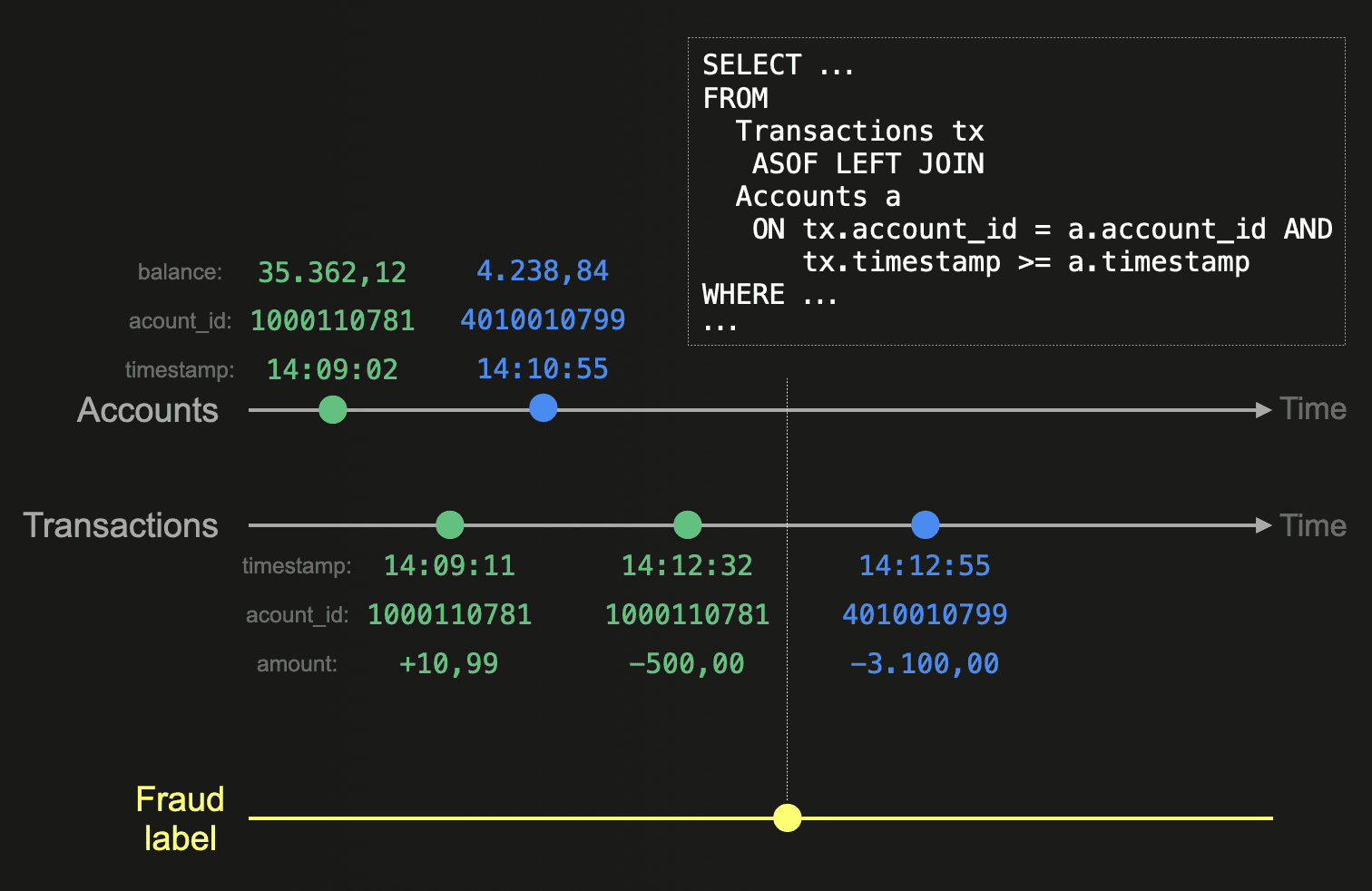
All of this work can be pushed down to ClickHouse, parallelized, and executed across a cluster. This allows the offline store to scale to PBs while the feature store itself remains a lightweight coordination layer.
-
Online store - As a real-time analytics database, ClickHouse can serve highly concurrent query workloads at low latency. While this requires data to be typically denormalized, this aligns with the storage of feature groups used at both training and inference time. Importantly, ClickHouse is able to deliver this query performance while being subject to high write workloads thanks to its log-structured merge tree. These properties are required in an online store to keep features up-to-date. Since the features are already available within the offline store, they can easily be materialized to new tables within either the same ClickHouse cluster or a different instance via existing capabilities e.g. remoteSecure.
Integrations with Kafka, through either an exactly-once Kafka Connect offering or via ClickPipes in ClickHouse Cloud, also make consuming streaming data from streaming sources simple and reliable.
For use cases requiring very high request concurrency i.e. thousands per second, and very low latency, we recommend users still consider a dedicated data store e.g. Redis, designed for these workloads.
- Vector database - ClickHouse has built-in support for vector embeddings through floating point arrays. These can be searched and compared through distance functions, allowing ClickHouse to be used as a vector database. This linear comparison can be easily scaled and parallelized for larger datasets. Additionally, ClickHouse has maturing support for Approximate Nearest Neighbour (ANN) indices, as well as hyperplane indexes using pure-SQL, as required for larger vector datasets.
By satisfying each of the above roles, ClickHouse can dramatically simplify the feature store architecture. Aside from the simplification of operations, this architecture allows features to be built and deployed faster. A single instance of ClickHouse can be scaled vertically to handle PBs of data, with additional instances simply added for high availability. This minimizes the movement of data between data stores, minimizing the typical network bottlenecks. ClickHouse Cloud expands on this further by storing only a single copy of the data in object storage and allowing nodes to be scaled vertically or horizontally dynamically in response to load as required.
The above architecture still requires several key components not satisfied by ClickHouse: a streaming engine such as Kafka + Flink and a framework to provide compute for model training. A means of hosting models is also required. For simplicity, we assume the use of a cloud-hosted solution to these, such as Confluent and Amazon SageMaker.
ClickHouse Featureform Integration #
To realize our vision of a virtual feature store, super-charged by ClickHouse, we identified Featureform as the ideal solution with which to integrate. As well as being open-source, thus allowing us to easily contribute, Featureform also offers mature (by design) integration points for offline stores, online stores, and vector databases.
For our initial integration, we have added ClickHouse as an offline store. This represents the largest effort of work and allows ClickHouse to be used as a data source and for the main store for features and training sets. Users can also exploit ClickHouse to power transformations when creating feature groups and inserting data from other sources.
This represents our first effort to integrate with Featureform. Expect to be able to use ClickHouse as an online store and vector database soon!
Conclusion #
In this blog we introduced the concept of a feature store and its use in MLOps workflows. We explored why you might use a feature store, main types of feature stores, and their core architectural components. With this foundation, we presented how ClickHouse as a high performance real-time data warehouse can be used to power multiple components of a “virtual” feature store, announcing the recent integration with Featureform as an example.
In our next blog in this series, we will explore the integration and training of a model using Featureform and AWS Sagemaker with data and features held in ClickHouse!



