We're excited to announce the availability of Managed ClickStack for ClickHouse Cloud in beta.
Managed ClickStack makes it easier than ever to take advantage of ClickHouse for observability, delivering fast queries and powerful analytics across logs, metrics, traces, and session replays without the overhead of running infrastructure.
With market-leading cost efficiency at its core, Managed ClickStack provides a simple path to production-grade observability at any scale - whether you're already using ClickHouse Cloud for real-time analytics or warehousing, coming from ClickStack Open Source or just starting to explore the benefits of ClickHouse for observability.
Built on ClickHouse Cloud, Managed ClickStack is priced on infrastructure, not events. Store full-fidelity, high-cardinality OpenTelemetry data indefinitely for less than three cents per gigabyte per month, with no per-user, per-host, or other extraneous fees. Scale your logs, metrics and traces without reduced retention periods, sampling or rollups. Scale ingest and query independently, pay only for what you use, and get ClickHouse Cloud reliability out of the box. The result is a managed observability platform that completely changes the economics of observability, while readying users for emerging agentic workloads and consolidating observability with other use cases where it belongs.
We remain fully committed to ClickStack Open Source and will continue to invest in new features, performance improvements, and tooling for the community. Users who choose to run ClickStack self-managed will continue to have full access to the same open source foundation that powers Managed ClickStack.
To get started with Managed ClickStack, new users can begin with a ClickHouse Cloud trial, which includes $300 of credits - enough for about ~10TB of OTel data based on our recommended sizing. Create a service, select ‘ClickStack’ and you’ll be guided through loading your data, with step-by-step instructions provided as part of the onboarding flow.
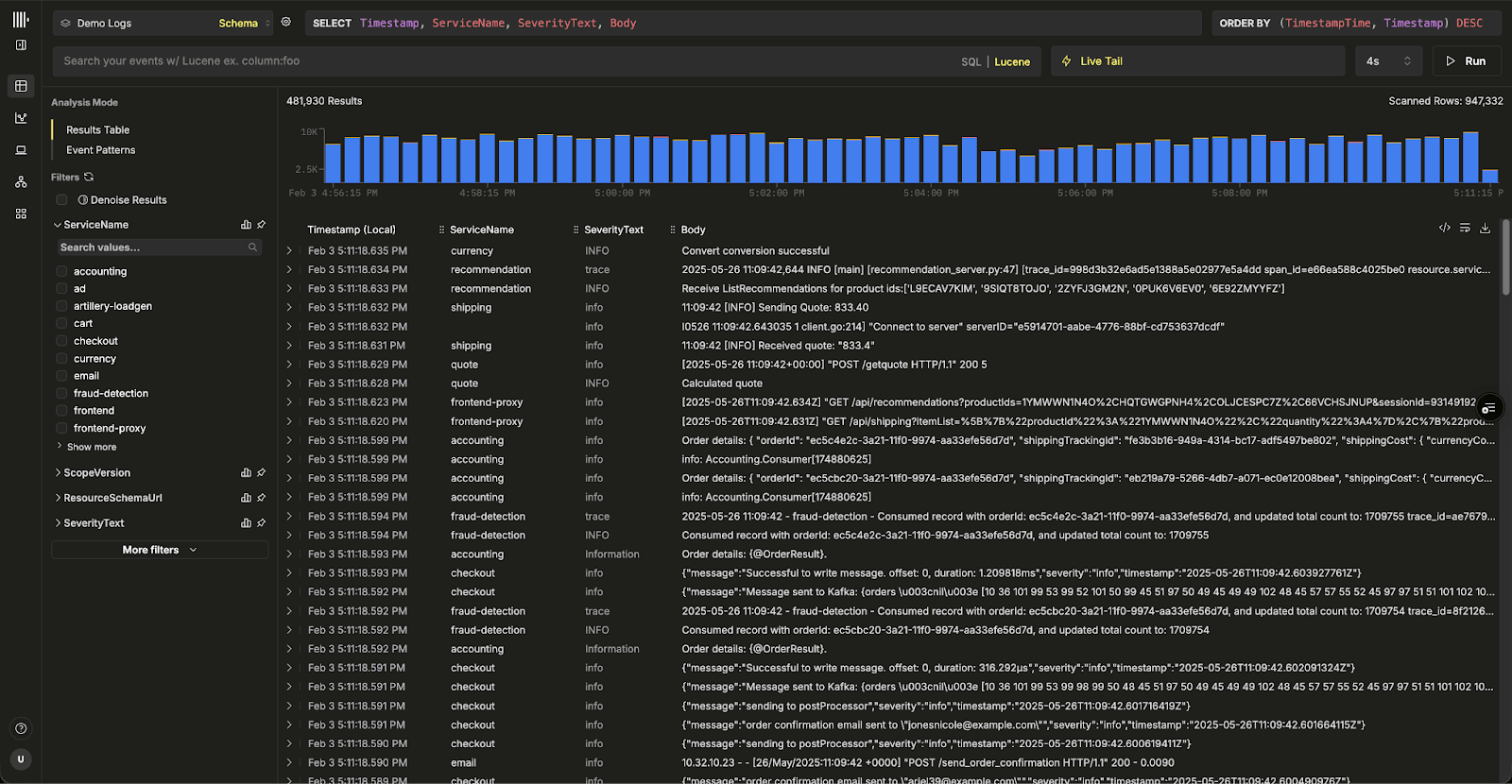
In this initial beta release, Managed ClickStack includes guided ingestion for OpenTelemetry and Vector, with more options to follow. Users are also free to use any of the supported ClickHouse Cloud ingestion methods. While ClickStack is optimized for OpenTelemetry schemas and provides the fastest path to value out of the box, it is not limited to them. Any event-based data with a timestamp can be ingested and explored in the ClickStack UI (HyperDX). Existing ClickHouse Cloud users can enable ClickStack on new or existing services and follow the same process to start using Managed ClickStack immediately.
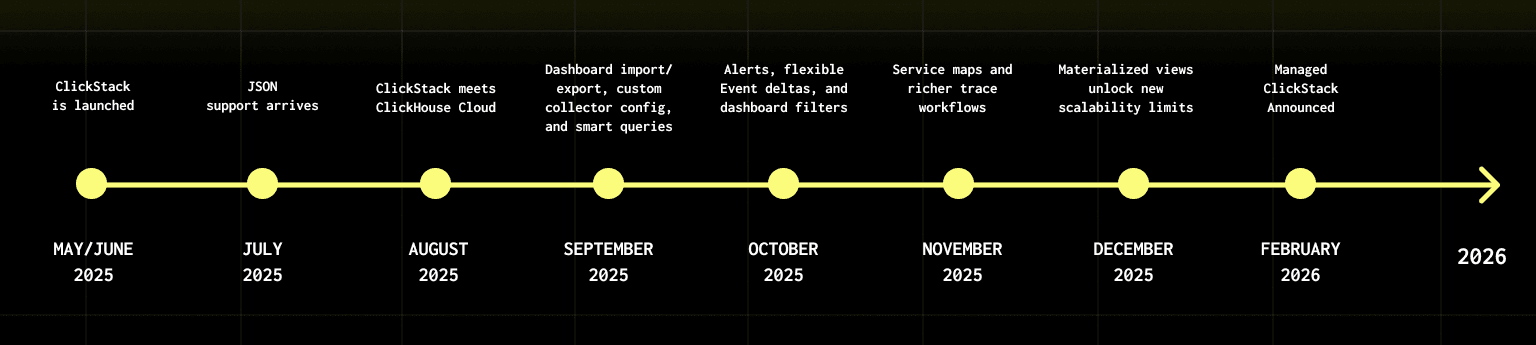
When we launched ClickStack last year, we did so with the goal of democratizing access to ClickHouse for observability. ClickHouse had already proven itself as an almost de facto store for observability data, showing that columnar databases are a natural fit for the workload - as demonstrated by users already running observability on ClickHouse at unprecedented scale.
ClickStack set out to make this accessible to everyone by providing a more opinionated, OpenTelemetry-based observability stack with the ClickStack UI (HyperDX) built in. By standardizing on OpenTelemetry and pairing them with a purpose-built UI, ClickStack made it dramatically easier to adopt ClickHouse for logs, metrics, traces, and session replays, and to benefit from the performance and cost advantages of a columnar store without building everything from scratch.
Teams have begun running ClickStack at larger and larger scales, retaining more data, increasing cardinality, and moving away from the sampling and short retention windows that had become the norm in observability. For many users, this shift was transformational, changing the economics of their observability. Meanwhile, we've been busy adding new features and making sure that ClickStack scales better than ever, bringing improved cost efficiency and performance by adding support for features like materialized views.
As usage has grown, so has the demand for a managed experience. Many teams want the benefits of ClickStack and ClickHouse without operating the underlying infrastructure themselves. Others are already using ClickHouse Cloud for analytics, warehousing, or AI workloads and wanted to **consolidate observability into the same platform, avoiding data silos and duplication **while unlocking deeper correlation across their datasets - aligning with our vision that observability is really just another data problem.
Managed ClickStack is the natural next step in this journey. By running ClickStack on ClickHouse Cloud, we can deliver the same open source foundation with a simpler operational model, and access to capabilities like separation of storage and compute, low-cost object storage for long-term retention, and enterprise-grade reliability and security out of the box.
While "separation of storage and compute" and "object storage" might seem like implementation details for many, they change the cost economics of observability.
Most managed observability platforms price around constraints. Some charge per gigabyte ingested. Others rely on more punitive user-based or host-based pricing. In practice, this forces teams to constantly decide what they can afford to monitor, how long they can retain data, and where they need to sample or drop signals to stay within budget. Cost becomes a limiting factor on observability itself.
ClickHouse has already shown that this does not need to be the case. With columnar storage and aggressive compression, it is common to achieve 10–15x compression on observability data, while still supporting fast aggregations and high-cardinality queries. This alone fundamentally improves the economics of storing logs, metrics, and traces over long periods of time.
Managed ClickStack takes this a step further. Building on ClickHouse Cloud’s separation of storage and compute changes the pricing model entirely. Observability data is stored in low-cost object storage, with intelligent local and distributed caching handled automatically by ClickHouse Cloud. There are no hot or cold tiers, and no artificial boundaries based on data age. Data is treated consistently regardless of how old it is. What gets cached and queried efficiently is driven purely by access patterns, not by retention policies.
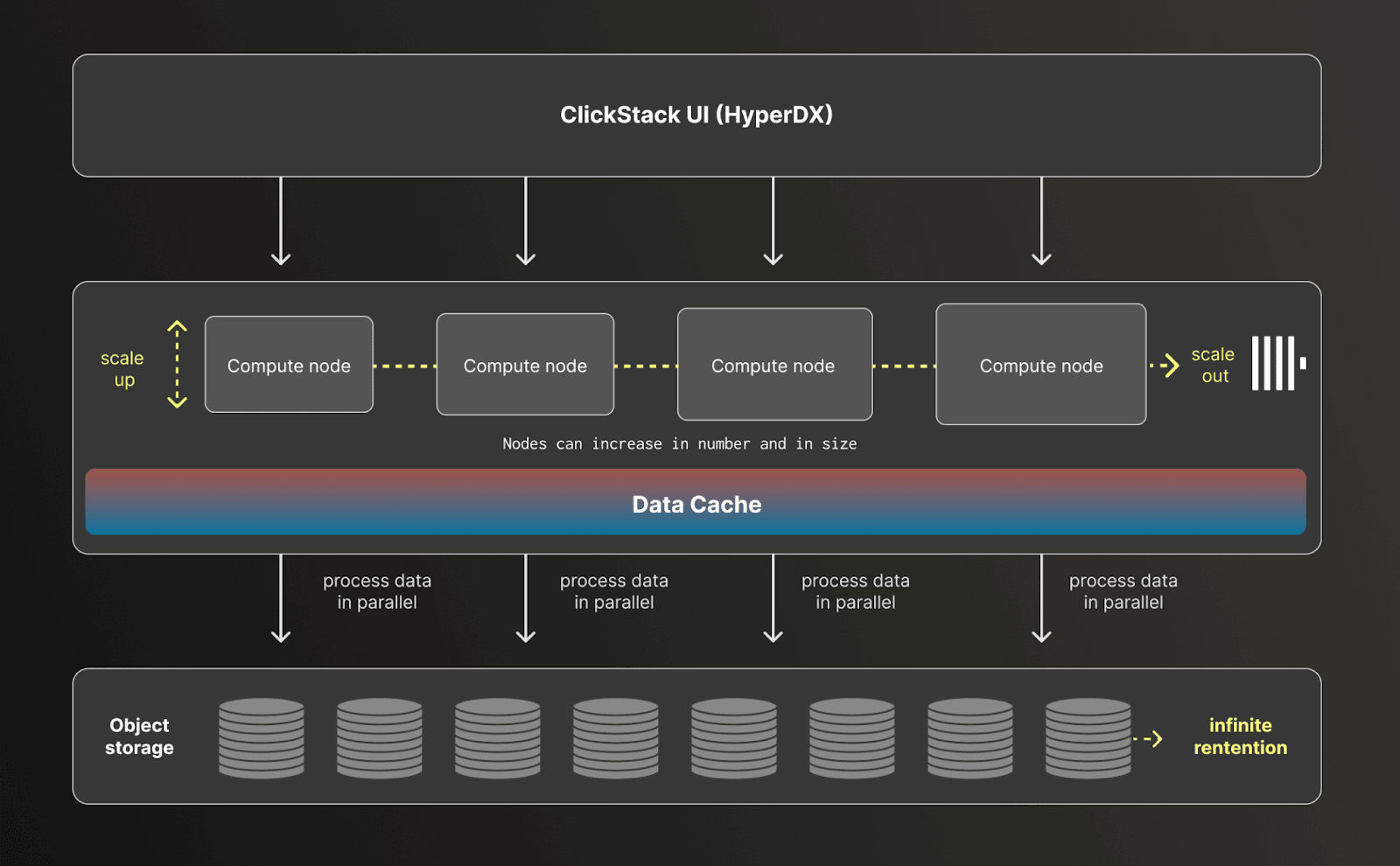
This means retention effectively stops being a meaningful cost dimension. High-cardinality OpenTelemetry data can be retained for years at less than a cent per gigabyte per month, without sampling, rollups, or forced data expiration. Frequently accessed data is cached automatically and queried at low latency. Less frequently accessed data remains fully queryable, with predictable performance and cost.
Efficient and tunable compute
With storage and retention no longer a cost constraint, the remaining variable becomes compute - you still need resources to ingest and query data. Here users further benefit from the separation of storage and compute, as ingest and query workloads are fully isolated and can be scaled independently.
Ingest compute runs continuously to deliver consistent throughput, with each core capable of sustaining up to 20MB/s of writes in our benchmarks. In practice, this translates to users paying less than 1 cent per GB per month for ingest compute.
Meanwhile, independent query compute can be shaped to match how observability data is used. Small, always-on pools can power dashboards and alerts over recent data. Larger pools can be spun up on demand for investigations or historical analysis, then scaled down or idled when no longer needed. Because compute is isolated and elastic, users only pay for query resources they use - a concept users coming from cloud data warehousing will be familiar with.
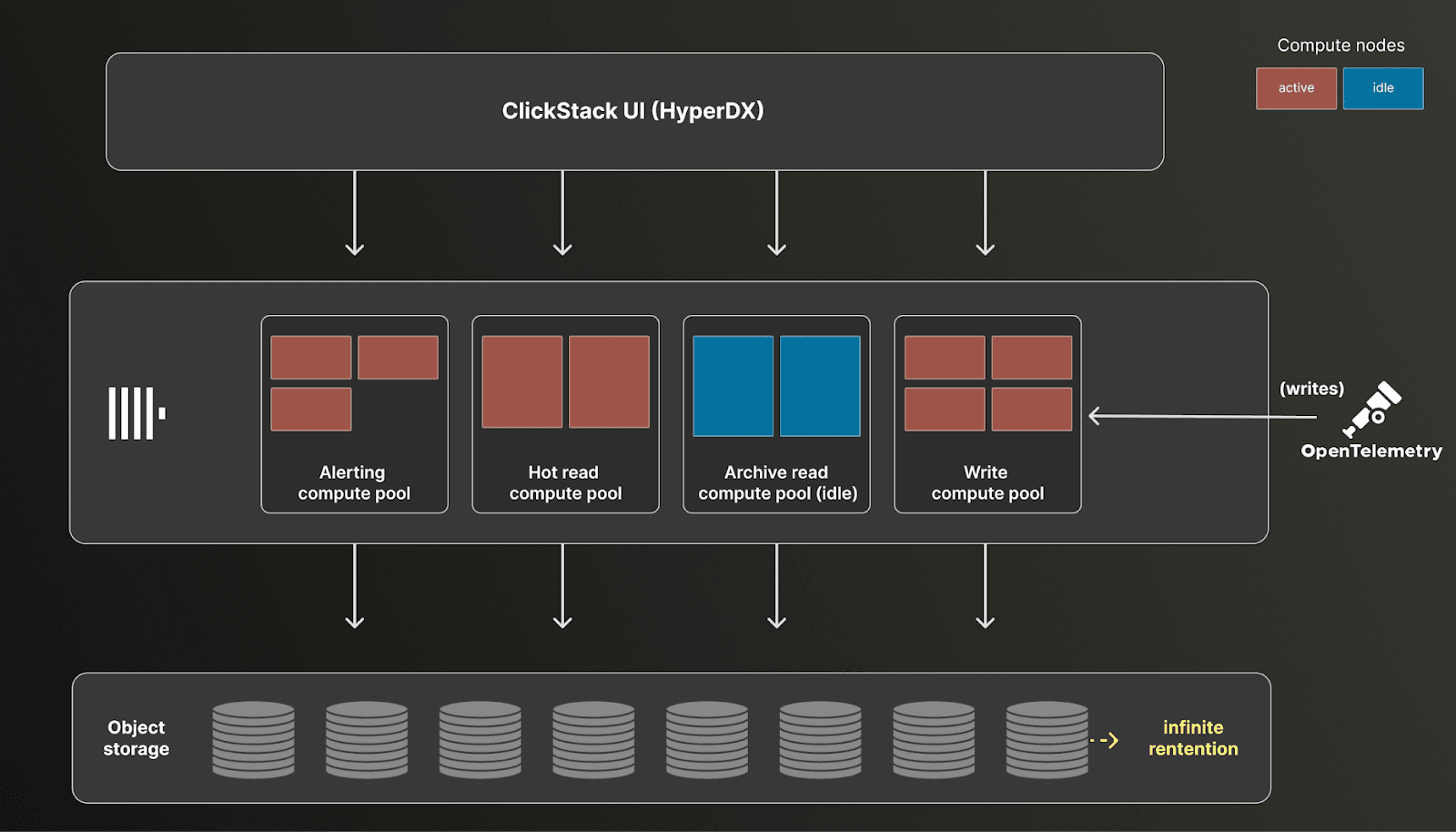
The result is you no longer need to choose between cost, retention, or visibility. You can ingest everything, retain everything, and query everything, while keeping costs transparent and predictable.
Unifying datastores and unlocking agentic workloads
While cost efficiency is a critical driver for observability, it is only one part of a much larger shift. ClickHouse already powers real-time application analytics and business intelligence workloads at scale. Over time, we believe these datasets will increasingly converge, and that the systems used to store and analyze them will consolidate as well. ClickHouse is uniquely positioned to support this shift.
The ability to correlate observability data with business and application data unlocks powerful new questions. Teams can go beyond detecting incidents to understanding their real impact, such as attributing outages to revenue loss, user churn, or degraded customer experience. Even simpler correlations, joining logs or traces with application or product data, become easier and more efficient when everything lives in a single database.
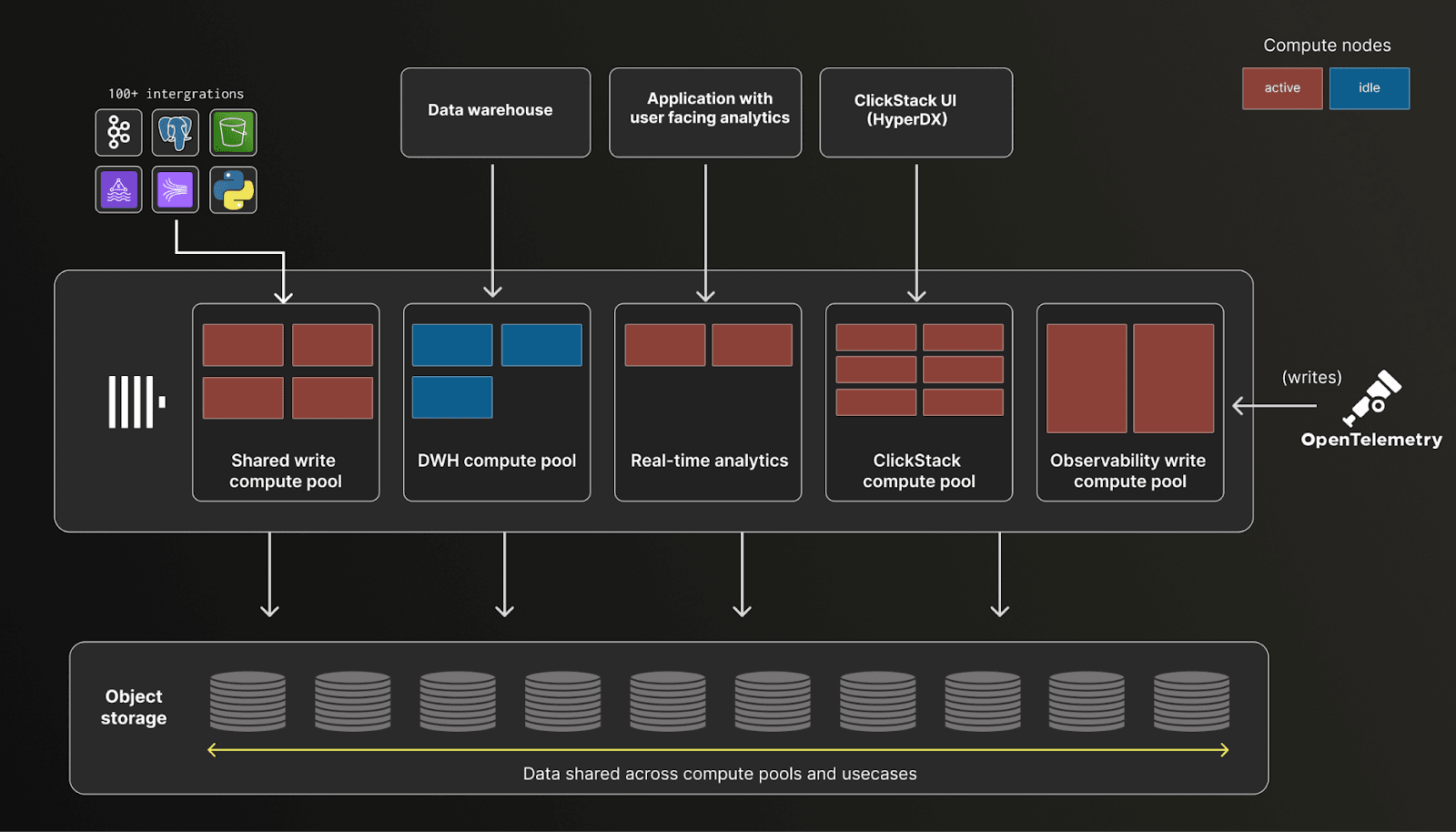
In the above, compute pools are used to service different use cases, rather than individual query types. For example, you might have a dedicated compute pool for observability and ClickStack workloads, another for real-time analytics, and a separate data warehousing pool that remains idle until needed. Additional workloads can be supported by introducing new compute pools as required. Within each use case, it is also common for multiple compute pools to emerge, each sized and tuned for different workload characteristics. All compute pools can access all of the data for correlation provided access policies permit.
Separation of storage and compute is also essential in delivering this use case consolidation effectively. Multiple workloads can safely query the same underlying data while using isolated compute resources tuned for their specific needs. Observability, analytics, BI, and investigation workloads no longer need separate systems or duplicated data, reducing both operational complexity and cost.
Historically, asking these complex questions required deep cross-domain knowledge, strong SQL experience and familiarity with multiple datasets - a rare persona for many businesses. However, with the emergence of agentic workloads and AI-driven data interaction, natural language interfaces make it far easier to ask sophisticated cross-domain questions across unified datasets.
SQL plays a central role here. Large language models already have a strong built-in understanding of SQL and can generate efficient queries with minimal context. SQL remains the most expressive and precise language for querying structured data, making it a natural foundation for agentic analytics. As query volumes increase and latency expectations tighten, ClickHouse’s performance characteristics become even more important.
Looking ahead, we believe this convergence of observability, analytics, and agentic interaction represents a major shift in how teams work with data. As we explore agentic capabilities across ClickStack and the broader ClickHouse Cloud platform, users who consolidate their data and workloads on ClickHouse will be well positioned to take advantage of what comes next. Stay tuned for more announcements in 2026 as we expand our Agentic Data Stack across both ClickHouse Cloud and ClickStack.
New users can sign up for ClickHouse Cloud, create a service, and connect their telemetry source to their ClickHouse instance, with ClickStack available directly in the console. Existing users can open ClickStack straight from their console immediately on any service.
This beta is the first step toward making Managed ClickStack broadly available. Over the coming months, we’ll expand capabilities, refine defaults, and roll out additional tooling as the offering matures.
We’d love to hear from you as we build. Join the ClickHouse Slack and hop into the #olly-clickstack channel to share feedback, ask questions, or follow along with updates about anything ClickStack related.



