This blog post is part of a series:
- Join Types supported in ClickHouse
- ClickHouse Joins Under the Hood - Hash Join, Parallel Hash Join, Grace Hash Join
- ClickHouse Joins Under the Hood - Full Sorting Merge Join, Partial Merge Join
- Choosing the Right Join Algorithm
This post finishes our exploration of the 6 different join algorithms that have been developed for ClickHouse. As a reminder: These algorithms dictate the manner in which a join query is planned and executed. ClickHouse can be configured to adaptively choose and dynamically change the join algorithm to use at runtime, depending on resource availability and usage. However, ClickHouse also allows users to specify the desired join algorithm themselves. This chart gives an overview of these algorithms based on their relative memory consumption and execution time:
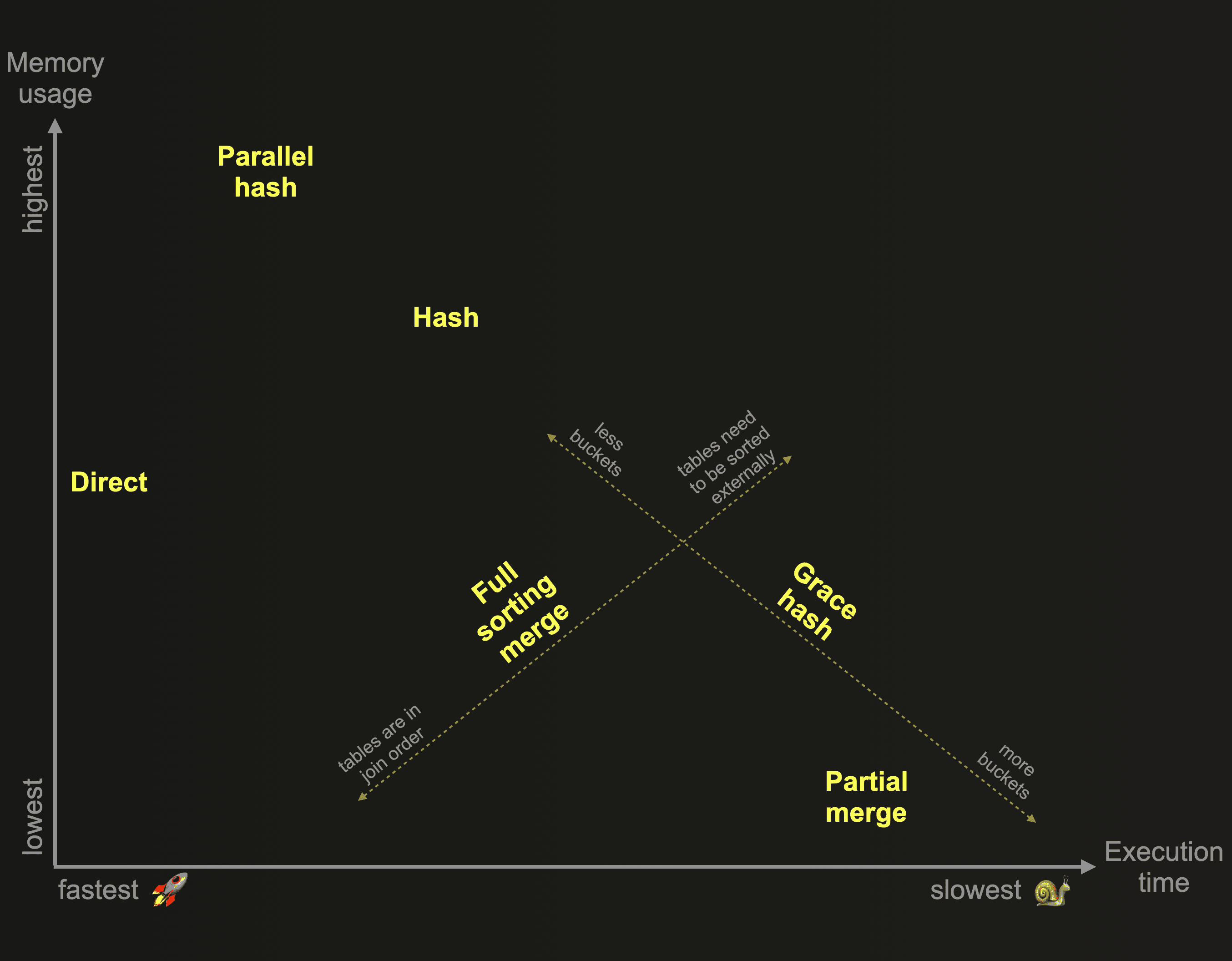
In our second post, we described and compared in detail the three ClickHouse join algorithms from the chart above that are based on in-memory hash tables:
As a reminder: Hash join and parallel hash join are fast but memory-bound. The joined data from the right-hand side table needs to fit into memory. Grace hash join is a non-memory bound version that spills data temporarily to disk, without requiring any sorting of the data. This overcomes some of the performance challenges of other join algorithms that spill data to disk and require prior sorting of the data.
In the third post we explored and compared the two algorithms from the chart above that are based on external sorting:
As a reminder: The Full sorting merge join is non-memory bound and based on in-memory or external sorting, and can take advantage of the physical row order of the joined tables and skip the sorting phase. In such cases, the join performance can be competitive with some of the hash join algorithms from the chart above, while generally requiring significantly less main memory. The partial merge join is optimized for minimizing memory usage when large tables are joined, and always fully sorts the right table first via external sorting. The left table is also always sorted, block-wise in-memory. The join matching process runs more efficiently if the physical row order of the left table matches the join key sorting order.
We kept the best for the end and will finish our exploration of the ClickHouse join algorithms in this post by describing ClickHouse’s fastest join algorithm from the chart above:
- Direct join
The direct join algorithm can be applied when the underlying storage for the right-hand side table supports low latency key-value requests. Especially with large right tables, direct join beats all other ClickHouse join algorithms with a significant improvement in execution time.
Test Setup #
We are using the same two tables and the same ClickHouse Cloud service instance that we introduced in the second post.
For all example query runs we use the default setting of max_threads. The node executing the queries has 30 CPU cores and therefore a default max_threads setting of 30. For all query pipeline visualizations, in order to keep them succinct and readable, we artificially limit the level of parallelism used within the ClickHouse query pipeline with the setting max_threads = 2.
Direct Join #
Description #
The direct join algorithm can be applied when the underlying storage for the right-hand side table supports low latency key-value requests. ClickHouse has three table engines providing this: Join (that is basically a pre-calculated hash table), EmbeddedRocksDB and Dictionary. We will describe the direct join algorithm here based on dictionaries, but the mechanics are the same for all three engines.
Dictionaries are a key feature of ClickHouse providing in-memory key-value representation of data from various internal and external sources, optimized for super-low latency lookup queries.
This is handy in various scenarios e.g., for enriching ingested data on the fly without slowing down the ingestion process, as well as for improving the performance of queries in general with JOINs particularly benefiting.
We sketch the direct join algorithm's query pipeline below:
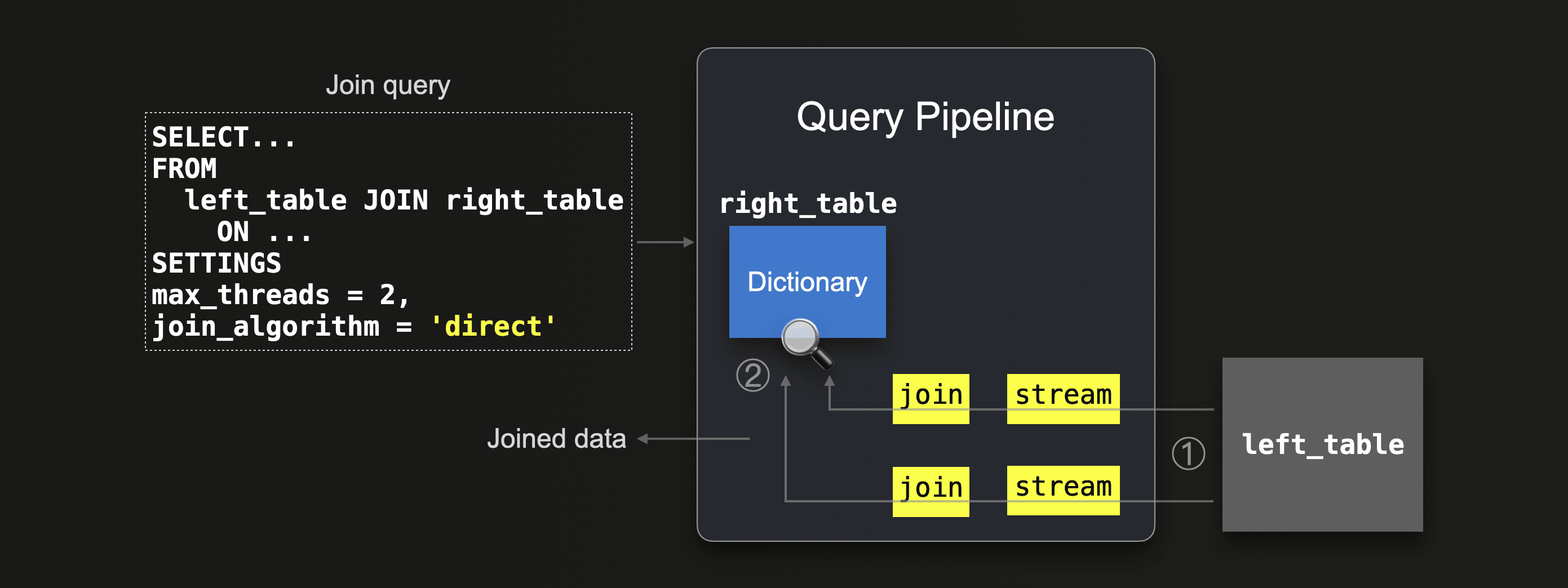 The direct join algorithm requires that the right table is backed by a dictionary, such that the to-be-joined data from that table is already present in memory in the form of a low-latency key-value data structure. Then ① all data from the left table is streamed in parallel by 2 streams (because
The direct join algorithm requires that the right table is backed by a dictionary, such that the to-be-joined data from that table is already present in memory in the form of a low-latency key-value data structure. Then ① all data from the left table is streamed in parallel by 2 streams (because max_threads = 2) into the query engine and the rows are ② joined in parallel by two join stages by doing lookups into the underlying dictionary of the right table.
Supported join types #
Only LEFT ANY join type is supported. Note that the join key needs to match the key attribute of the underlying key-value storage.
Examples #
In order to demonstrate the direct join, we need to create a dictionary first. For this, we need to choose a layout that determines the way how the dictionary content is stored in memory. We will use the flat option, and for comparison, also the hashed layout. Both layouts require the key attribute’s data type to be compatible with the UInt64 type. The flat layout provides the best performance among all layout options and allocates an in-memory array with room for as many entries as the largest value of the key attribute. For example, if the largest value is 100k, then the array will have room for 100k entries. This data layout allows extremely fast key-value lookups with O(1) time complexity as only a simple array offset lookup is required. The offset is simply the value of the provided key, with the entry at that offset position within the array containing the corresponding values. This is well suited for our actors and roles data where we have dense and monotonically increasing values starting at 0 in the key columns (id and actor_id, respectively) in our source tables. Therefore each allocated array entry will be used. With the hashed layout the dictionary content is stored in a hash table. The hashed layout is more generally applicable. E.g. no unnecessary space gets allocated in memory for non dense key attribute values not starting at 0. However, as we will see later, access speeds are 2-5 times slower.
We create a dictionary with a flat layout that loads the content from the roles table completely into memory for low latency key-value lookups. We are using actor_id as the key attribute. Note that we use the max_array_size setting for specifying the initial and max array size (the default value of 500,000 would be too small). We also disable content updates of the dictionary by setting LIFETIME to 0:
CREATE DICTIONARY imdb_large.roles_dict_flat
(
created_at DateTime,
actor_id UInt32,
movie_id UInt32,
role String
)
PRIMARY KEY actor_id
SOURCE(CLICKHOUSE(db 'imdb_large' table 'roles'))
LIFETIME(0)
LAYOUT(FLAT(INITIAL_ARRAY_SIZE 1_000_000 MAX_ARRAY_SIZE 1_000_000));
Next, we create a similar dictionary but with a hashed layout:
CREATE DICTIONARY imdb_large.roles_dict_hashed
(
created_at DateTime,
actor_id UInt32,
movie_id UInt32,
role String
)
PRIMARY KEY actor_id
SOURCE(CLICKHOUSE(db 'imdb_large' table 'roles'))
LIFETIME(0)
LAYOUT(hashed());
Note that in ClickHouse Cloud, the dictionaries will automatically be created on all nodes. For OSS, this behavior is possible if using a Replicated database. Other configurations will require the creation of the dictionary on all nodes manually or through the use of the ON CLUSTER clause.
We query the dictionaries system table for checking some metrics:
SELECT
name,
status,
formatReadableSize(bytes_allocated) AS memory_allocated,
formatReadableTimeDelta(loading_duration) AS loading_duration
FROM system.dictionaries
WHERE startsWith(name, 'roles_dict_')
ORDER BY name;
┌─name──────────────┬─status─┬─memory_allocated─┬─loading_duration─┐
│ roles_dict_flat │ LOADED │ 1.52 GiB │ 12 seconds │
│ roles_dict_hashed │ LOADED │ 128.00 MiB │ 6 seconds │
└───────────────────┴────────┴──────────────────┴──────────────────┘
The loading_duration column shows how long it took to load the source table content into the memory layout of the dictionaries. The status indicates that the loading is finished. And we can see how much main memory space is allocated for the dictionaries.
Creating a dictionary with the above dictionary DDL automatically creates a table with a dictionary table engine backed by the dictionary. We verify that by querying the tables system table:
SELECT
name,
engine
FROM system.tables
WHERE startsWith(name, 'roles_dict_')
ORDER BY name;
┌─name──────────────┬─engine─────┐
│ roles_dict_flat │ Dictionary │
│ roles_dict_hashed │ Dictionary │
└───────────────────┴────────────┘
With such a table the dictionary can be worked with as a first-class table entity and data read directly using familiar SELECT clauses.
Note that in contrast to normal (MergeTree engine family) ClickHouse tables, the key attribute is (automatically) unique in a dictionary. For example, the roles table contains many rows with the same actor_id value, since generally an actor/actress has more than one role. When these rows are loaded into the dictionary with the actor_id as the key attribute, then rows with the same key value overwrite each other. Effectively only the data from the last row inserted for a specific actor_id, is contained in the dictionary.
We can verify this by selecting the count from both the dictionary’s roles source table and the automatically created dictionary table:
SELECT formatReadableQuantity(count()) as count FROM roles;
┌─count──────────┐
│ 100.00 million │
└────────────────┘
SELECT formatReadableQuantity(count()) as count FROM roles_dict_flat;
┌─count────────┐
│ 1.00 million │
└──────────────┘
1 million is exactly the amount of unique actors in the actors table. Meaning that the roles dictionary contains the data from one role per actor/actress:
SELECT formatReadableQuantity(count()) as count FROM actors;
┌─count────────┐
│ 1.00 million │
└──────────────┘
Now we use the dictionary for enriching the rows from the actors table with info from the roles table. Note that we are using the dictGet function for performing the low-latency key-value lookups. For each row from the actors table, we perform a lookup in the dictionary with the value from the id column and request the created_at, movie_id, and role values in the form of a tuple:
WITH T1 AS (
SELECT
id,
first_name,
last_name,
gender,
dictGet('roles_dict_flat', ('created_at', 'movie_id', 'role'), id) as t
FROM actors)
SELECT
id,
first_name,
last_name,
gender,
id AS actor_id,
t.1 AS created_at,
t.2 AS movie_id,
t.3 AS role
FROM T1
LIMIT 1
FORMAT Vertical;
Row 1:
──────
id: 393216
first_name: Wissia
last_name: Breitenreiter
gender: F
actor_id: 393216
created_at: 2023-05-12 13:03:09
movie_id: 373614
role: Gaston Binet
1 row in set. Elapsed: 0.019 sec. Processed 327.68 thousand rows, 12.74 MB (17.63 million rows/s., 685.25 MB/s.)
Note that if the dictionary doesn’t contain a key entry for a specific actor id value, then the configured default values are returned for the requested attributes. Also because, as mentioned above, the dictionary deduplicates the loaded data based on the actor_id column, effectively only the first found match is returned. Therefore the behavior of the query above is equivalent to the LEFT ANY JOIN.
There is an easier and much more compact way in ClickHouse to formulate the above query. We showed earlier that when a dictionary with a specific name is created, ClickHouse automatically creates a table of the same name backed by the dictionary via the dictionary table engine. This table allows us to express the same logic as the query above by using a join query with the direct join algorithm:
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
LIMIT 1
SETTINGS join_algorithm='direct'
FORMAT Vertical;
Row 1:
──────
id: 393216
first_name: Wissia
last_name: Breitenreiter
gender: F
actor_id: 393216
created_at: 2023-05-12 13:03:09
movie_id: 373614
role: Gaston Binet
1 row in set. Elapsed: 0.023 sec. Processed 327.68 thousand rows, 12.74 MB (14.28 million rows/s., 555.30 MB/s.)
Internally, ClickHouse is implementing the join using efficient key-value lookups into the dictionary backing the right-hand side table. This is similar to the query above using the dictGet function for lookups. We can verify this by introspecting the query plan for the join query, using the EXPLAIN PLAN clause:
EXPLAIN PLAN
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct';
┌─explain───────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ FilledJoin (JOIN) │
│ Expression ((Convert JOIN columns + Before JOIN)) │
│ ReadFromMergeTree (imdb_large.actors) │
└───────────────────────────────────────────────────────┘
We can see that ClickHouse is using a special FilledJoin step indicating that nothing needs to be done to prepare or load the right-hand side table, as its content is already existing in memory in the form of a very fast key-value lookup data structure. Ready and ideal for executing the join.
For comparison, we can introspect the query plan for the same join query using a hash algorithm:
EXPLAIN PLAN
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='hash';
┌─explain──────────────────────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Join (JOIN FillRightFirst) │
│ Expression (Before JOIN) │
│ ReadFromMergeTree (imdb_large.actors) │
│ Expression ((Joined actions + (Rename joined columns + (Projection + Before ORDER BY)))) │
│ ReadFromMergeTree (imdb_large.roles) │
└──────────────────────────────────────────────────────────────────────────────────────────────
Now we see a JOIN FillRightFirst step indicating that data from the right hand side table will be loaded into memory (into a hash table) first, before the hash join can be executed.
We are now going to compare the execution times for the same join query using the
- hash algorithm
- parallel hash algorithm
- direct algorithm with a right table backed by a dictionary with a hashed layout
- direct algorithm with a right table backed by a dictionary with a flat layout
Note that as mentioned above, a direct join with a dictionary-backed right-hand side table is effectively a LEFT ANY JOIN. For a fair comparison, we, therefore, use this join type for the query runs with hash algorithms.
We run the hash join:
SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='hash'
FORMAT Null;
0 rows in set. Elapsed: 1.133 sec. Processed 101.00 million rows, 3.67 GB (89.13 million rows/s., 3.24 GB/s.)
We run the parallel hash join:
SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='parallel_hash'
FORMAT Null;
0 rows in set. Elapsed: 0.690 sec. Processed 101.00 million rows, 3.67 GB (146.38 million rows/s., 5.31 GB/s.)
We run the direct join with the right-hand side table having an underlying dictionary with a hashed memory layout:
SELECT *
FROM actors AS a
JOIN roles_dict_hashed AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
0 rows in set. Elapsed: 0.113 sec. Processed 1.00 million rows, 38.87 MB (8.87 million rows/s., 344.76 MB/s.)
Finally, we run the direct join with the right-hand side table having an underlying dictionary with a flat memory layout:
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
0 rows in set. Elapsed: 0.044 sec. Processed 1.00 million rows, 38.87 MB (22.97 million rows/s., 892.85 MB/s.)
Now let’s check runtime statistics for the last four query runs:
SELECT
query,
query_duration_ms,
(query_duration_ms / 1000)::String || ' s' AS query_duration_s,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND (hasAll(tables, ['imdb_large.actors', 'imdb_large.roles']) OR arrayExists(t -> startsWith(t, 'imdb_large.roles_dict_'), tables))
ORDER BY initial_query_start_time DESC
LIMIT 4
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
query_duration_ms: 44
query_duration_s: 0.044 s
memory_usage: 83.66 MiB
read_rows: 1.00 million
read_data: 37.07 MiB
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles_dict_hashed AS r ON a.id = r.actor_id
SETTINGS join_algorithm='direct'
FORMAT Null;
query_duration_ms: 113
query_duration_s: 0.113 s
memory_usage: 102.90 MiB
read_rows: 1.00 million
read_data: 37.07 MiB
Row 3:
──────
query: SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='parallel_hash'
FORMAT Null;
query_duration_ms: 689
query_duration_s: 0.689 s
memory_usage: 4.78 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
Row 4:
──────
query: SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
SETTINGS join_algorithm='hash'
FORMAT Null;
query_duration_ms: 1084
query_duration_s: 1.084 s
memory_usage: 4.44 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
The direct join run from Row 1, with the right-hand side table backed by a dictionary with a flat memory layout, is ~15 times faster than the parallel hash join run from Row 3, ~25 times faster than the hash join run from Row 4, and ~2.5 times faster than the direct join run from Row 2 where the right-hand side table is backed by a dictionary with a hashed memory layout. That is fast!
The main reason for this, is the fact that the data for the right-hand side table is already in memory. Conversely, the hash and parallel hash algorithms need to load the data into memory first. Furthermore, as mentioned earlier, the in-memory array of the dictionary with the flat layout allows extremely fast key-value lookups with O(1) time complexity as only a simple array offset lookup is required.
Note that the memory_usage column from the query_log system table does not account for the memory allocated by the dictionary itself. Therefore, for a fair peak memory consumption comparison, we need to add the corresponding values from the dictionaries system table’s bytes_allocated column - see our query on that system table above. We do this further down in the summary section of this post. As you will see, even with the bytes_allocated for the dictionaries added to the memory_usage of the direct join runs, the peak memory consumption is significantly lower compared to the hash and parallel hash join runs.
Query pipeline #
Lets introspect the actual query pipeline for the direct join query with max_threads set to 2:
clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles_dict_flat AS r ON a.id = r.actor_id
SETTINGS max_threads = 2, join_algorithm = 'direct';" | dot -Tpdf > pipeline.pdf
We have annotated the pipeline with the same circled numbers used in the abstract diagram above, slightly simplified the names of the main stages, and added the dictionary and the left table in order to align the two diagrams:
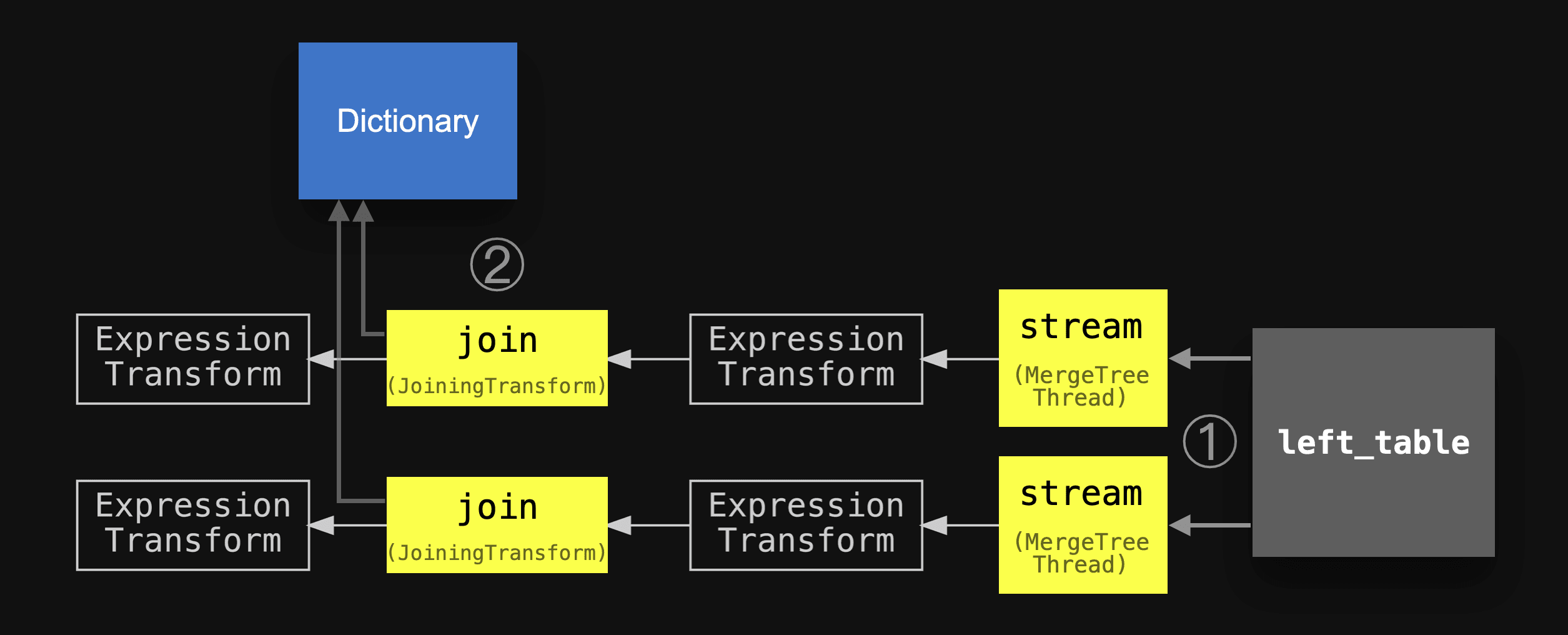
We see that the real query pipeline matches our abstract version above.
Summary #
This blog post described ClickHouse’s fastest join algorithm: the Direct Join. This algorithm is applicable when the underlying storage for the right-hand side table supports low latency key-value requests. Especially with large right-hand side tables, the direct join beats all other ClickHouse join algorithms with a significant improvement in execution time.
The below chart summarizes and compares the memory usage and execution times of this post’s join query runs. For this, we always ran the same query joining the same data, with the larger table on the right-hand side on a node with 30 CPU cores (and therefore max_threads set to 30):
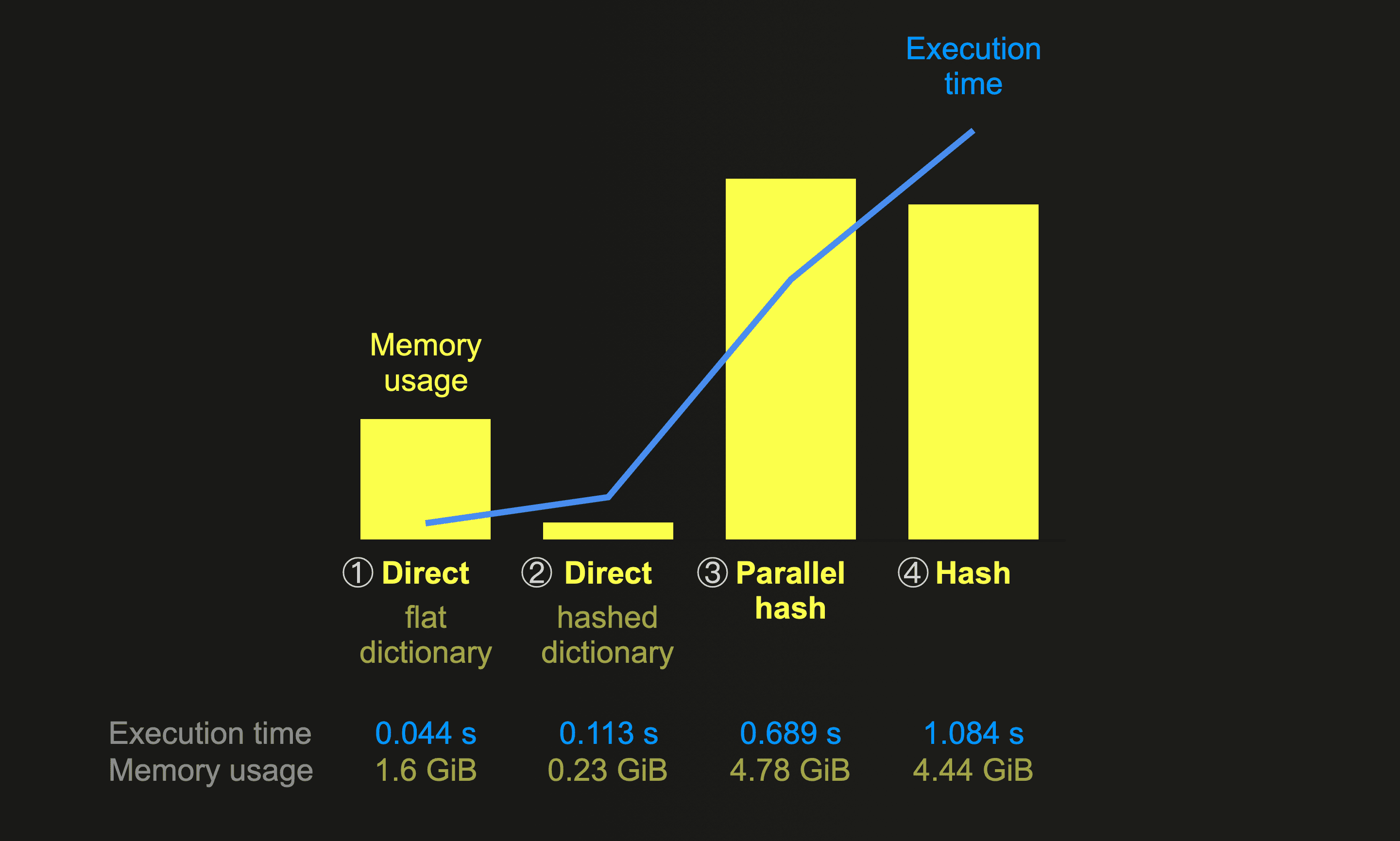 The chart above is quite clear. The
The chart above is quite clear. The direct join is as fast as it gets. ① With a right-hand side table backed by a dictionary with a flat memory layout, the algorithm is ~25 times faster than hash join, ~15 times faster than the parallel hash, and ~2.5 times faster than the ② direct join with the right-hand side table backed by a dictionary with a hashed memory layout. Regardless of dictionary layout type, the overall peak memory consumption (which includes the bytes_allocated for the dictionaries added to the memory_usage of the direct join runs) is lower compared to the hash algorithm runs.
This finishes our three part deep dive on the 6 ClickHouse join algorithms.
In the next post of this series, we will summarize and directly compare all 6 ClickHouse join algorithms. We will also provide a handy decision tree + join types support overview that you can use for deciding which join algorithm fits best into your specific scenario.
Stay tuned!



