TL;DR
ClickHouse Cloud compute is now fully stateless. This post introduces the final piece that made it possible: a new in-memory database engine powered by a Shared Catalog that removes the last dependency on local disks.
We’ll walk through how we got here, what the Shared Catalog unlocks, and how this powers stateless compute over anything, including data lakes.
Stateless compute, complete #
ClickHouse Cloud no longer needs disks. Compute nodes don’t store anything locally. No syncing. No warm-up. Just fast, elastic, stateless compute that spins up, runs your query, and disappears.
That’s not a prototype. That’s today.
Since launching ClickHouse Cloud in October 2022, we’ve been stripping away every last bit of local state from the compute layer. In this post, we’ll walk you through that journey, stage by stage, and show how we got to fully stateless compute.
The final building block is a Shared Catalog that decouples database metadata from disk.
This unlocks immediate benefits, all of which we’ll explore in more detail later:
-
New DDL capabilities, including atomic INSERT … SELECT, cross-db renames, and UNDROP
-
Resilient DROP operations that don’t depend on active compute nodes
-
Built for fast, no-warm-up provisioning, laying the foundation for low-latency scale-out, scale-up, and rapid wake-ups.
-
Stateless compute across both native and open formats, including Iceberg and Delta Lake
This is the architecture that now powers ClickHouse Cloud deployments.
Let’s rewind to where it started: Nodes with everything stored locally.
Stage 0: Where ClickHouse started #
ClickHouse began with a classic shared-nothing architecture that tightly coupled storage and compute. Each server stores and accesses its own data on local disk, and scale-out is achieved through sharding.
The diagram below shows how query processing works in this setup.
As we walk through each stage of the architecture, we’ll progressively adapt this diagram, until we reach the fully stateless, cloud-native end state.

① DDL statements and catalog lookups: handled by the Atomic database engine
In earlier ClickHouse versions, DDL statements and metadata queries like SHOW TABLES or SHOW CREATE TABLE were handled by the Atomic database engine, which became the default in version 20.10 (replacing the earlier Ordinary engine).
Atomic assigns each table a persistent UUID, decoupling data from names and enabling safe, atomic DDL operations. It stores all metadata (definitions are saved as .sql files) on local disk, tying every compute node to persistent state.
(Not shown in the diagram: In clusters, DDL statements like CREATE, DROP, ALTER, and RENAME can be broadcast using the ON CLUSTER clause, coordinated via Keeper. This mechanism appends DDL commands to a DDL log/queue, not tied to any specific database engine. However, Keeper doesn’t store the full metadata state, so when a new node joins, it won’t know what happened before and requires manual setup to recreate tables.)
This worked fine in small clusters, but made it hard to scale dynamically. To go stateless, we had to remove this local dependency.
② Data storage: handled by a MergeTree table engine
Everything related to table data itself (inserts, deletes, updates) is handled by a table engine from the MergeTree family, which organizes data on disk as a collection of immutable data parts.
The ReplicatedMergeTree table engine enables high availability by automatically replicating data to other nodes, coordinated via a replication log in Keeper.
③ In-memory query execution: using the OS page cache
For SQL SELECT queries, all necessary data is processed entirely in memory. If it isn’t already cached, it’s read from local disk and transparently placed into the OS page cache. From there, data is streamed into the query engine and processed in a highly parallel fashion, leveraging CPU and memory bandwidth for maximum performance.
This setup made sense for single-node or small-cluster deployments, but tightly coupling metadata and data to local disks became a bottleneck in the cloud. To break that coupling, and support stateless compute, we had to rethink how ClickHouse manages metadata and data at every layer.
But first, let’s clarify a foundational concept that underpins everything we’re about to walk through.
How metadata and data are managed #
Before we dive into the evolution of stateless compute in ClickHouse Cloud, it’s worth clarifying a key concept: the separation between database engines and table engines.
-
A database engine manages database and table definitions. It handles DDL operations like CREATE, DROP, and RENAME, and powers metadata lookups like SHOW TABLES. In clusters, depending on the engine, it may also replicate DDL changes across nodes.
-
A table engine manages the table’s actual data: how it’s stored, indexed, read, and written. This includes operations like INSERT, DELETE, and UPDATE, and access to storage, local or remote.
Decoupling metadata management from data storage enables greater flexibility, scalability, and specialization at each layer. This separation is core to ClickHouse Cloud’s architecture, especially in the journey toward stateless compute.
As we’ll see, making compute fully stateless required innovation on both sides: table engines that decouple data, and database engines that decouple metadata.
Let’s walk through that evolution, stage by stage, by decoupling data, cache, and metadata.
Stage 1: Decoupling data with SharedMergeTree #
The first major step toward stateless compute was separating data storage from compute. It started with SharedMergeTree, a table engine for object storage, and Replicated, a database engine that simplified bootstrapping.
Here’s how each layer contributed:
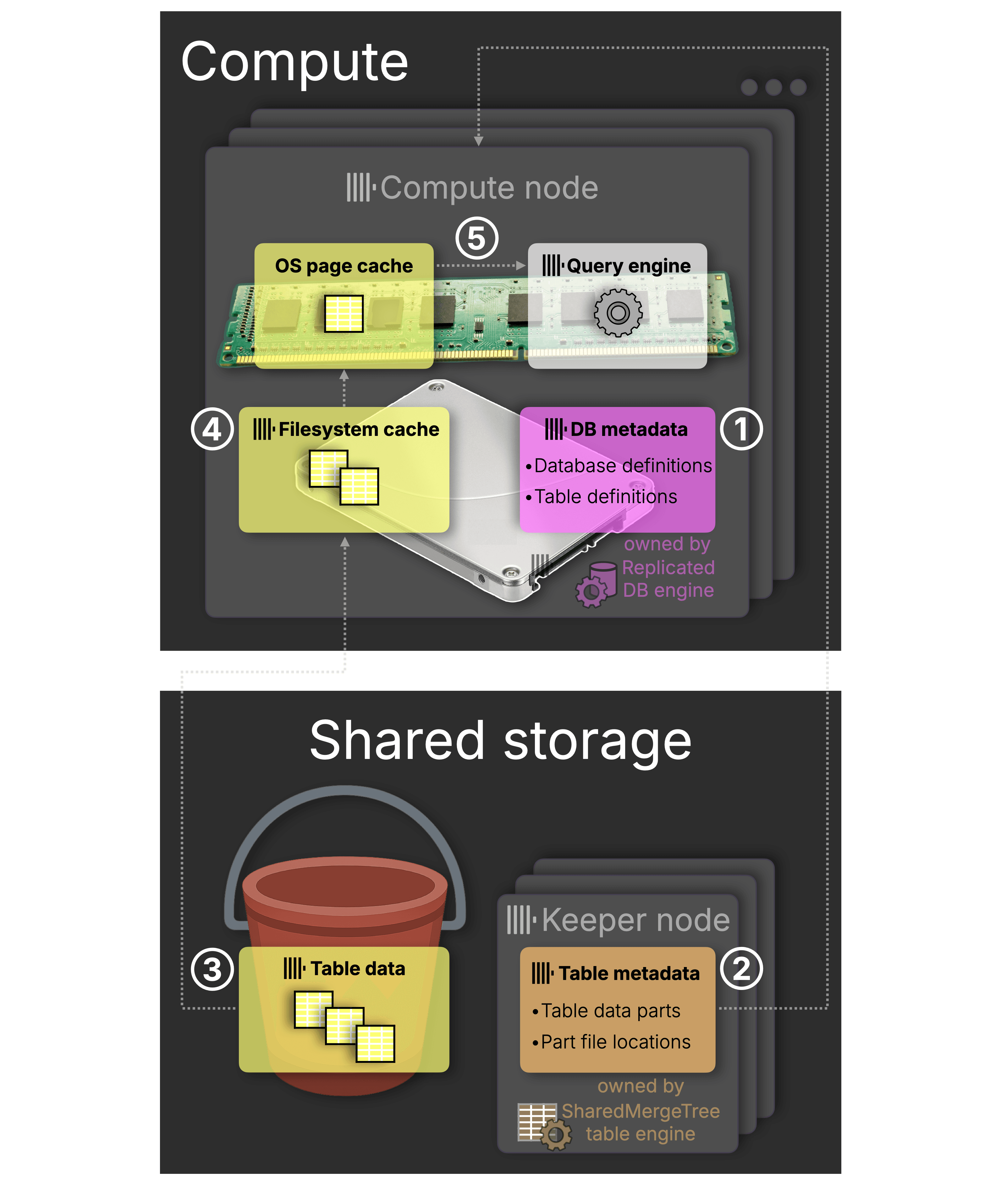
① DDL statements and catalog lookups: handled by the Replicated database engine
Separating storage from compute enables each to scale independently. To support elastic compute in ClickHouse Cloud, where nodes can be added or swapped at will, we introduced a new database engine in version 21.3: Replicated. It first appeared experimentally before ClickHouse Cloud, and was later refined and made production-ready for the cloud.
Replicated builds on the Atomic engine by still storing metadata locally as .sql files, but also replicates metadata changes, like CREATE, DROP, or RENAME, across nodes via a DDL log written to Keeper, automatically and without requiring the ON CLUSTER clause.
(Note: The Replicated engine uses a DDL log in Keeper to replicate metadata changes. The diagram omits this for clarity. Also not shown: table metadata is cached on disk, and both accessed table and database metadata are transparently cached in memory via the OS page cache for fast access.)
Unlike the previous mechanism with a simple, length-limited DDL log, the Replicated database engine stores the full metadata state per database in Keeper, allowing new nodes to fully bootstrap themselves (per pre-created database) without further manual setup.
② Table metadata access: handled by the SharedMergeTree table engine
Table storage is decoupled from compute with the SharedMergeTree table engine, which coordinates access to shared object storage through a table metadata layer in Keeper. This layer tracks which data parts exist for each table and where the corresponding files are located in object storage.
Milestone: When ClickHouse Cloud launched, we started with ReplicatedMergeTree. All new services have used SharedMergeTree for some time, but as we publish this post, all existing services have been migrated too. Shared storage is now the foundation across the board.
③ Shared table data: stored in object storage
With the SharedMergeTree table engine, table data is no longer tied to local disk. Instead, it’s stored in shared object storage, durable, virtually unlimited, and accessible from any compute node. This enables elastic scaling, fault tolerance, and simplified operations, as compute nodes no longer need to replicate or manage local copies of data.
Under the hood: To deliver the performance users expect from ClickHouse, we go far beyond basic object storage access. The system performs aggressive retries, splits large objects into parallel chunks, and uses multi-threaded reads with asynchronous prefetching, all to maximize throughput and resilience. (For more on the read-side optimizations, see the talk Reading from object storage 100× faster.)
④ Query acceleration: via filesystem cache to hide object storage latency
Object storage is durable and scalable, but has high access latency. To shield queries from this latency, ClickHouse Cloud introduced a local filesystem cache: when data is streamed from object storage, it is cached locally for future reuse. This cache works in tandem with the OS page cache, enabling memory-speed execution on repeated queries.
⑤ Query execution: in memory using the OS page cache
Just like on classic shared-nothing servers, ClickHouse Cloud processes data entirely in memory. It’s streamed through the OS page cache into the query engine for fast, parallel execution.
While local filesystem caching sped up repeated queries, it only benefited the same compute node that ran them. But in a world of elastic compute, caching tied to a single node was no longer enough.
Stage 2: Decoupling cache with a distributed cache #
Caching hot data close to the query engine is one of the most effective ways to speed up analytics. But so far in ClickHouse Cloud, that caching happened locally, tied to a specific compute node. To make caching cloud-native and elastic, we needed to go further. So we built a distributed cache.
The diagram below shows how the distributed cache fits into the ClickHouse Cloud architecture, decoupling hot data from compute and making it instantly accessible across all nodes.
To make each stage easier to follow, we highlight the new components in full color, and dim those we’ve already explained. You’ll see this pattern continue in the next stages as the architecture evolves.

① Shared hot data: cached in a distributed cache service
The distributed cache is a shared network service that stores accessed table data across dedicated cache nodes. Compute nodes fetch needed data from it in parallel, avoiding object storage latency and making previously cached data instantly reusable, even across different nodes.
② In-memory execution: accelerated by a userspace page cache
Local RAM is still the fastest layer, so caching hot data in memory is essential for query speed. Since ClickHouse Cloud compute nodes no longer use local disks for caching, and thus can’t rely on the OS page cache, we introduced the userspace page cache: an in-memory layer for caching data read from the distributed cache.
With hot data caching now fully decoupled from compute, one dependency remained: database metadata still lived on local disk. To complete the stateless architecture, we had to rethink that too.
Stage 3: Decoupling metadata with a Shared Catalog #
The Replicated database engine made it easier to elastically add or swap compute nodes in ClickHouse Cloud. Nodes could automatically bootstrap their view of what tables exist in a database. But it still wasn’t fully cloud-native:
-
Tied to local disk and manual orchestration: Metadata was stored on local filesystems, and databases had to be pre-created on each node.
-
Fragile failure recovery: Crashes could leave behind orphaned or inconsistent metadata.
-
Missing scalable DDL support: DROP required all nodes to be online, and features like cross-database RENAME or atomic INSERT … SELECT were hard to implement cleanly, so we didn’t.
Therefore, just like with the SharedMergeTree table engine, we went back to the drawing board and designed a new cloud-native, stateless Shared database engine, powered by a Shared Catalog.
Before diving into how the Shared database engine and catalog work, the next diagram shows how they fit into the larger system: decoupling database metadata from local disk and enabling truly stateless compute nodes:
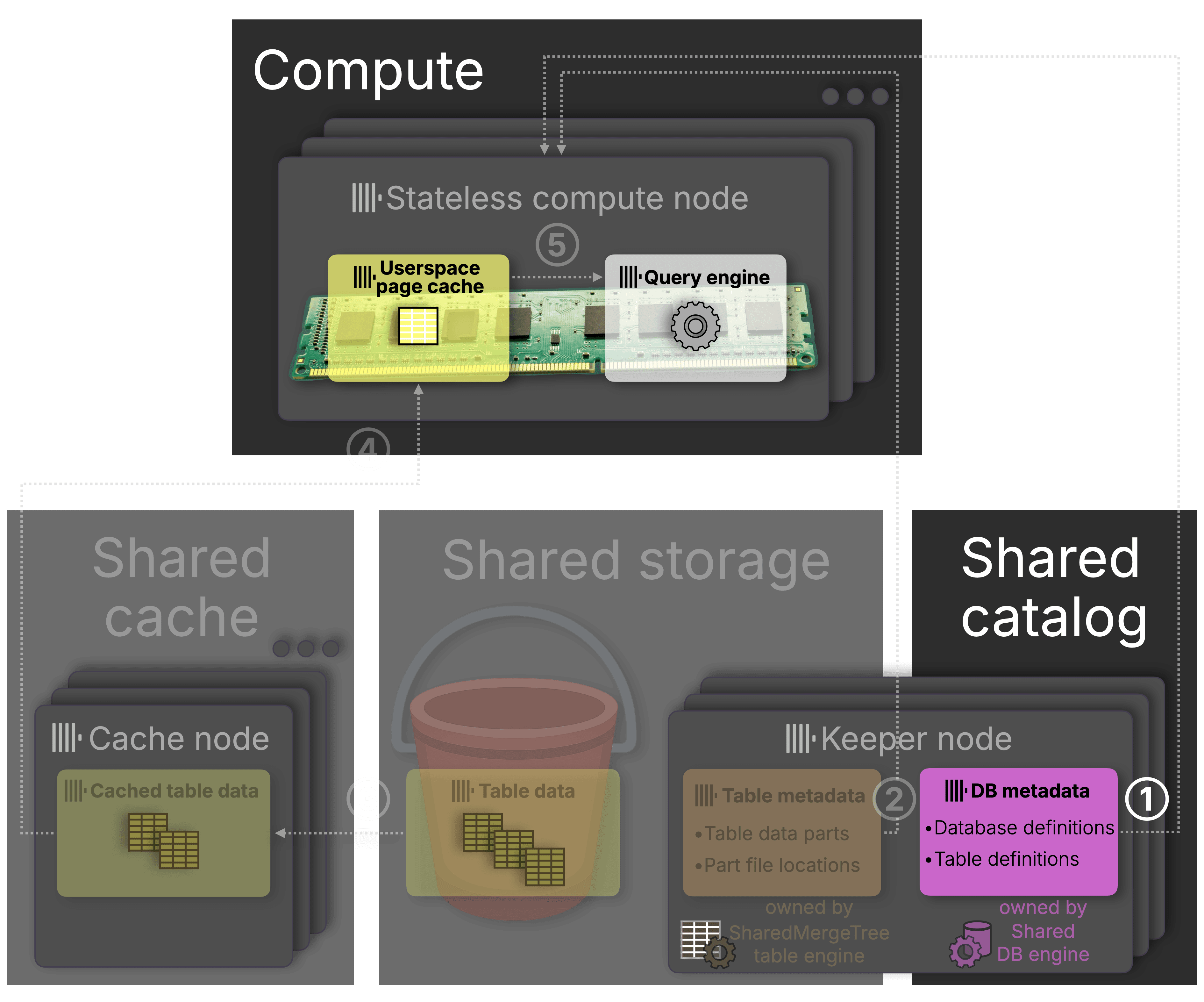
The Shared database engine remains responsible for ① handling all DDL statements and catalog lookups, now backed by the Shared Catalog rather than local files.
This architectural shift unlocks the next key principle behind the Shared engine: fully stateless, diskless compute.
Truly stateless: no disks, no problem
The database metadata managed by the old Replicated engine was the last reason compute nodes needed local disks. The new Shared database engine removes that dependency entirely: it’s a purely in-memory engine. With that, compute nodes no longer require disks at all, just CPU and memory.
Centralized metadata: replicated and versioned in Keeper
The Shared database engine stores all database and table definitions in a central Shared Catalog backed by Keeper. Instead of writing to local disk, it maintains a single versioned global state shared across all compute nodes.
Each node tracks only the last applied version and, on startup, fetches the latest state, no local files, no manual setup, just fast, consistent bootstrapping.
(While not shown in the diagram, metadata is also transparently cached in memory. This accelerates metadata queries like SHOW TABLES or DESCRIBE. We’ll revisit this in the animated “Architecture in action” section below.)
With this shift, ClickHouse Cloud compute became truly stateless. And the benefits go far beyond diskless bootstraps.
What the Shared Catalog unlocks #
With metadata now centralized and versioned, we could rethink how DDL works at scale. The result? A new model for coordination and object lifecycles, enabling:
-
Cloud-scale DDL, even under high concurrency
-
Resilient deletion and new DDL operations
-
Fast spin-up and wake-ups as stateless nodes now launch with no disk dependencies
-
Stateless compute across both native and open formats, including Iceberg and Delta Lake
We’ll walk through each of these next.
Heads-up: Things get deep from here
The next two sections take a deep dive into how the shared database engine and catalog actually work, covering coordination, consistency, and all the gnarly edge cases we had to solve.
If you’re curious how the magic happens under the hood, read on and enjoy!
If you’re just here for the high-level takeaways, feel free to skip ahead, we won’t be offended.
1. Cloud-scale DDL through fine-grained coordination #
The first capability this unlocks: cloud-scale DDL coordination, even under high concurrency and node churn.
The challenge: Fast, consistent coordination of metadata across many nodes #
Different clients may send DDL commands concurrently to different nodes, so the system must maintain a consistent global metadata state, both across all existing nodes and for any new nodes that join (whether scaling vertically or horizontally). This coordination must be (1) fast and (2) support high concurrency.
A straightforward approach is to use a global lock: whichever node holds it first fetches the latest metadata state to avoid conflicts (e.g., renaming a database just dropped by another node), applies its DDL changes, then releases the lock. While correct, this serializes all DDLs, which is not optimal and fails to meet both (1) fast coordination and (2) high concurrency.
Selective invalidation: a smarter solution #
Rather than using global locks, we use a smarter approach: each type of DDL command only invalidates a specific subset of other concurrently issued DDLs, those that might conflict, until those nodes fetch and apply the latest state.
How Keeper guarantees correctness under concurrency #
The Shared Catalog makes this work by applying all DDL updates through Keeper’s consensus algorithm, which guarantees linearizable writes. Each compute node sends its DDL changes as a multi-write transaction. Keeper ensures that one node’s transaction is always applied first. If another node submits a conflicting change, its multi-write request will fail because it references outdated object versions. The node can then fetch and apply the updated state first. This guarantees consistency without sacrificing concurrency.
The architecture in action #
The following animation sketches our approach. It shows the global state of the Shared Catalog, which is stored in Keeper. This state consists of three main Keeper nodes:
/uuids: maps UUIDs to object metadata (e.g. CREATE queries, versions)/names: maps object names to UUIDs (for lookup and rename)/replicas: tracks each compute node’s latest applied metadata version
The global DB metadata state version is the Znode-version of the /uuids node. This is the single source of truth.
Above the Shared Catalog, you’ll see three compute nodes, each with its local in-memory DB metadata. These nodes subscribe to catalog changes and stay up to date using Keeper’s watch-based notification mechanism.

① Node 3 receives and runs a DDL command
Node 3 receives a DDL command to create table tbl in db2, where one column val uses a DEFAULT expression, computed at insert time via a dictionary lookup in the existing dic dictionary from db1.
To run this, Node 3’s DDL execution thread sends a Keeper multi-request that:
-
② Validates dependencies: Checks that all required objects (db1, dic, db2) exist and are at the expected version. If another node had just renamed or dropped one, the version check would fail, and the operation would return an error to the user. However, in the meantime, the node fetches and applies the updated metadata state in the background, so it’s ready to rerun the operation if the user retries.
-
③ Bumps versions: Increments the version of each dependent object. This acts as a fine-grained lock: only the specific objects touched by the DDL command have their versions incremented. Other nodes modifying those same objects will detect a version mismatch and abort. The rest of the global state remains untouched, enabling high concurrency.
-
④ Applies the change: Writes the new table tbl to the global state and increments the global metadata version (e.g., from 5 to 6), notifying all other nodes (via Keeper watch notification, see below).
⑤ Background threads update states on all compute nodes
Every compute node runs a background thread that listens for changes via Keeper’s watch mechanism. When it sees that the global state version bumped (e.g., from 5 to 6), it:
- Fetches the new state from Keeper.
- Merges changes into local memory.
- Updates its
/replicasversion in Keeper to signal it’s up-to-date.
In our case, node 3 made the change, so it doesn’t merge changes; only the version marker needs updating.
Guaranteeing DDL visibility across nodes: The distributed_ddl_output_mode setting controls what the DDL execution thread does after applying changes (step ④). For example, it can wait until all (or all active) compute nodes have updated their local metadata, i.e., completed the final update step (⑤) with their separate background threads, before returning success to the client. The maximum wait time is governed by the distributed_ddl_task_timeout setting.
For simplicity, we glossed over some internal details in Step ④. Each object goes through a lifecycle of stages, like “intention to create” → “created”, which are stored in the object’s stage field (as just sketched in the animation above). In the next section, we’ll explain why this staged approach matters, and what it enables.
2. Reliable deletion and DDL, through a staged metadata lifecycle #
The Shared database engine introduces a staged object lifecycle, a new internal mechanism that tracks each object’s state explicitly. This solves long-standing problems with reliable deletion, recovery, and cross-object consistency that arose from older engines tightly coupling compute and metadata.
Let’s start with deletion. In earlier engines, it was tightly coupled to node liveness:
-
MergeTree table engine: The node running the DROP command was responsible for deleting the data immediately, since data was stored on local disk.
-
SharedMergeTree table engine: In a multi-node setup using shared storage, the last node to replicate the DROP was responsible for deleting the data. Because SharedMergeTree uses shared storage, this deferral ensures that data is only deleted once it’s no longer needed by any node.
This was fragile in compute-compute separation setups. If one service issued a DROP, the table was logically removed for that service, but physical deletion was delayed until all nodes acknowledged it. If even one node (or another service) was idle or stuck, deletion stalled, sometimes for weeks.
The staged design solves this by making deletion lifecycle-aware and handled asynchronously by independent background threads. Let’s walk through the lifecycle.
Understanding the object lifecycle #
Each object in the Shared Catalog progresses through a small set of well-defined stages (tracked in an object’s stage field, as seen in the “Architecture in action” animation above), ensuring safe transitions from creation to deletion:
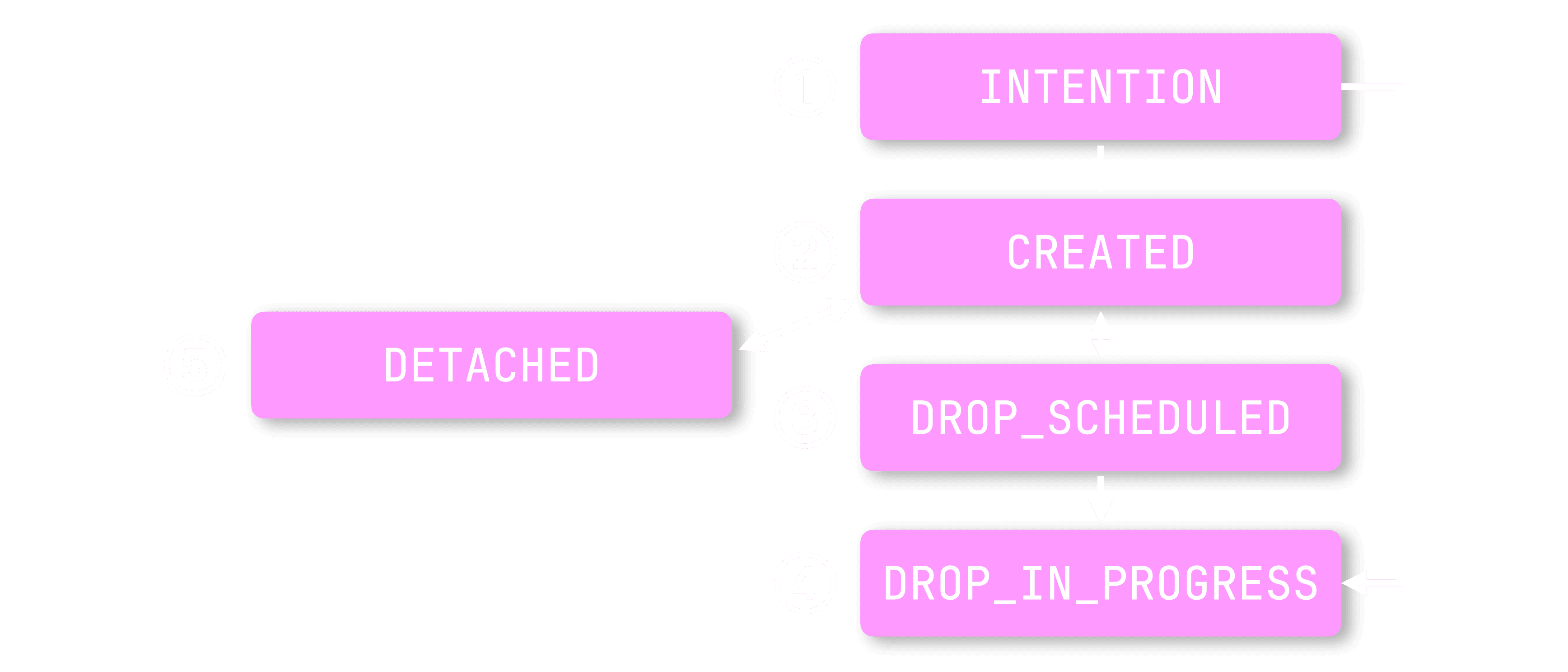
① INTENTION: Prepare to create
This is the initial stage for any object. For example, when a CREATE TABLE is issued, the DDL execution thread writes the new table’s metadata (e.g. the create_query statement) to Keeper with the stage set to INTENTION. At this point, the table doesn’t yet exist.
-
If creation succeeds, the stage is updated to ② CREATED.
-
If it fails, the stage is set to ④ DROP_IN_PROGRESS, and the metadata is cleaned up.
No more orphaned metadata: If the DDL thread crashes (e.g. due to a node failure or Keeper disconnect), the object stays in INTENTION. A separate background cleanup thread monitors such cases and deletes metadata that remains stuck in this stage for too long.
This guarantees no metadata is left behind, unlike the Replicated database engine, where orphaned entries could linger in Keeper indefinitely.
② CREATED: Object is live
This is the normal, active stage for a metadata object after successful creation.
-
A DETACH command moves the object to stage ⑤ DETACHED, and an ATTACH command moves it back to CREATED.
-
A DROP command transitions it to ③ DROP_SCHEDULED, where deletion is handled asynchronously, and an UNDROP command moves it back to CREATED (see below).
③ DROP_SCHEDULED: Soft-deleted, grace-period active
The object (e.g., a table) is no longer visible to compute nodes; it has been logically dropped.
-
After a configurable timeout (e.g., 8 hours), a background deletion thread, running independently of any compute node, physically removes the object’s data.
-
This delayed deletion allows the table to be safely UNDROPped during the grace period, since both its metadata and data still exist. If UNDROP succeeds, the object returns to stage ② CREATED.
Truly decoupled deletion: The system no longer depends on any specific node to finish the deletion job, avoiding the liveness issues of prior engines.
④ DROP_IN_PROGRESS: Final deletion in progress
This is the point of no return, the object can no longer be revived. It signals that the background deletion thread is actively removing the object: first, its data from object storage, then its metadata from Keeper.
New DDL operations powered by lifecycle stages #
This staged model enables clean, reliable implementations of DDL features that were previously fragile or hard to implement cleanly.
UNDROP:
Tables in DROP_SCHEDULED can be safely recovered while both metadata and data still exist.
Atomic CREATE TABLE AS SELECT (CTAS):
Previously, CTAS could leave behind partially created tables if the SELECT failed. Now:
-
Start with the table in the INTENTION stage
-
Fill it with data
-
Promote it to CREATED if successful
-
Otherwise, discard it by moving to DROP_IN_PROGRESS
Result: all-or-nothing semantics, no manual cleanup.
Cross-database RENAME:
Older engines stored metadata in per-database logs, making cross-db operations hard to coordinate. The Shared Catalog solves this with single-source metadata and multi-write transactions via Keeper.
All of these benefit from the same guarantee: lifecycle-aware metadata ensures clean transitions, no matter how distributed your workload.
But lifecycle coordination is just one part of what the Shared Catalog enables. It also removes the last bottleneck to instant provisioning, letting compute nodes spin up faster than ever.
3. Provisioning built for speed (and getting faster) #
Reducing startup latency has been the goal since day one of ClickHouse Cloud, and this release lays the foundation for making it a reality. With the Shared Catalog in place, compute nodes no longer depend on local disks or manual orchestration. They can spin up cleanly from anywhere, with nothing to sync to disk.
4. Stateless compute across both native and open formats #
The Shared Catalog powers more than just internal metadata. It also backs integration database engines like DataLakeCatalog, enabling stateless compute nodes to connect seamlessly to external catalogs like Hive, AWS Glue, Unity, or Polaris. These integrations allow ClickHouse to list and query external open table formats like Iceberg and Delta Lake directly.
The same performance layers still apply, just like with native tables:
① Shared catalog powers seamless metadata access to external tables.
② Distributed cache accelerates access to cold data in remote object storage.
③ Userspace page cache ensures ④ highly parallel, in-memory query execution.

The same performance layers we built for native tables now boost data lake queries, too, and ClickHouse Cloud compute nodes are ready to query anything instantly. Whether it’s your own MergeTree tables or external Iceberg or Delta Lake tables, the engine and execution path stay the same.
Where we go from here #
The Shared Catalog was the final building block. With it, we didn’t just complete the stateless architecture, we unlocked a broad set of architectural improvements:
-
Elasticity: No-warm-up provisioning and diskless scale-out and scale-up, with stateless compute nodes that launch from anywhere.
-
Resilience: DROP operations that complete cleanly, even if nodes go down.
-
Correctness: Atomic DDL like INSERT … SELECT, UNDROP, and cross-database RENAME, guaranteed to succeed or roll back cleanly.
-
Openness: Stateless compute across both native tables and open formats like Iceberg and Delta Lake.
Stateless compute, complete.
And we’re just getting started.
Imagine a swarm of stateless workers, spinning up instantly to accelerate your queries. Or imagine a truly serverless experience, where you don’t even have to think about clusters or machines. Just send your query and get results, fast.

That’s where we’re headed. With the Shared Catalog in place, we’ve built a truly stateless engine ready for the next chapter. Stay tuned.



