使用 ClickHouse 实现可观测性
引言
本指南面向希望使用 ClickHouse 构建自有、基于 SQL 的可观测性解决方案的用户,重点关注日志和追踪(traces)。内容涵盖构建自有方案的各个方面,包括对数据摄取的考虑、根据访问模式优化表结构,以及从非结构化日志中提取结构化信息。
仅使用 ClickHouse 本身并不能开箱即用地提供可观测性解决方案。不过,它可以作为高效的可观测性数据存储引擎,具备无与伦比的压缩率和极快的查询响应时间。要在可观测性方案中使用 ClickHouse,还需要配套的用户界面和数据采集框架。我们目前推荐使用 Grafana 对可观测性信号进行可视化,并使用 OpenTelemetry 进行数据采集(两者均为官方支持的集成)。

虽然我们推荐使用 OpenTelemetry(OTel)项目进行数据采集,但也可以使用其他框架和工具构建类似架构,例如 Vector 和 Fluentd(参见使用 Fluent Bit 的示例)。也存在其他可视化工具,包括 Superset 和 Metabase。
为什么使用 ClickHouse?
任何集中式可观测性存储最重要的特性,是它能够快速聚合、分析并检索来自不同来源的大量日志数据。这种集中化简化了故障排查,使定位服务中断的根本原因更加容易。
随着用户对价格愈发敏感,并发现这些开箱即用方案的成本相较其带来的价值而言既高又难以预测,具备成本高效且成本可预测、并在查询性能可接受前提下的日志存储,就显得前所未有地重要。
凭借卓越的性能和成本效率,ClickHouse 已成为可观测性产品中日志与追踪存储引擎的事实标准。
更具体地说,以下特性使得 ClickHouse 非常适合作为可观测性数据的存储引擎:
- 压缩 - 可观测性数据通常包含一些字段,其取值来自有限集合,例如 HTTP 状态码或服务名称。ClickHouse 的列式存储按排序后的方式保存值,使得这类数据可以获得极高的压缩比——尤其是在结合多种为时序数据优化的专用编解码器时。与其他通常需要与原始数据体积(通常是 JSON 格式)相当存储空间的数据存储不同,ClickHouse 对日志和追踪数据的平均压缩率可高达 14 倍。除了为大型可观测性集群带来显著的存储节省之外,这种压缩也有助于加速查询,因为需要从磁盘读取的数据更少。
- 快速聚合 - 可观测性解决方案通常大量依赖通过图表对数据进行可视化,例如展示错误率的折线图或展示流量来源的柱状图。聚合(即 GROUP BY)是驱动这些图表的基础,并且在用于问题诊断的工作流中应用筛选条件时,查询必须保持快速且响应灵敏。ClickHouse 的列式格式结合向量化查询执行引擎,非常适合快速聚合;稀疏索引则可在响应用户操作时快速过滤数据。
- 快速线性扫描 - 尽管其他技术依赖倒排索引来实现日志的快速查询,但这几乎不可避免地导致磁盘和资源使用率偏高。ClickHouse 在提供倒排索引作为额外可选索引类型的同时,其线性扫描具备高度并行化能力,并会使用机器上所有可用核心(除非另有配置)。这使得系统可以(在压缩后)以每秒数十 GB 的速度扫描数据以匹配记录,并配合高度优化的文本匹配操作符。
- 熟悉的 SQL - SQL 是所有工程师都熟悉的通用语言。经过 50 多年的发展,它已经被证明是数据分析的事实标准语言,并且仍然是第三大最流行的编程语言。可观测性本质上只是另一个数据问题,而 SQL 正是解决这类问题的理想工具。
- 分析函数 - ClickHouse 在 ANSI SQL 的基础上扩展了分析函数,旨在让 SQL 查询更简单、更易编写。这些函数对执行根因分析的用户至关重要,因为他们需要对数据进行多维切分和组合。
- 二级索引 - ClickHouse 支持二级索引,例如 Bloom 过滤器,用于加速特定类型的查询。可以在列级别按需启用这些索引,从而为用户提供精细化控制,并允许他们评估成本与性能之间的权衡。
- 开源与开放标准 - 作为一款开源数据库,ClickHouse 采用 OpenTelemetry 等开放标准。能够参与并积极贡献到这些项目中具有很大吸引力,同时还能避免供应商锁定带来的挑战。
何时应在可观测性场景中使用 ClickHouse
在可观测性数据方面使用 ClickHouse,意味着你需要采用基于 SQL 的可观测性方案。我们推荐阅读这篇博客文章以了解基于 SQL 的可观测性的历史,但简而言之:
如果符合以下情况,基于 SQL 的可观测性适合你:
- 你或你的团队成员熟悉 SQL (或希望学习 SQL)
- 你倾向于遵循像 OpenTelemetry 这样的开放标准,以避免厂商锁定并实现可扩展性。
- 你愿意运行一个从采集、存储到可视化,都由开源创新驱动的生态系统。
- 你预期需要管理的可观测性数据量会增长到中等或大规模 (甚至超大规模)
- 你希望掌控 TCO (总拥有成本) ,并避免可观测性成本失控。
- 你无法接受或不希望为了控制成本而将可观测性数据的保留期限制得很短。
如果符合以下情况,基于 SQL 的可观测性可能不适合你:
- 学习 (或生成) SQL 对于你或你的团队成员没有吸引力。
- 你正在寻找一个开箱即用的、端到端的可观测性方案。
- 你的可观测性数据量太小,不足以带来明显差异 (例如 <150 GiB) ,并且预计不会增长。
- 你的用例以指标为主且需要 PromQL。在这种情况下,你仍然可以在使用 Prometheus 处理指标的同时,使用 ClickHouse 存储日志和链路追踪数据,并在展示层通过 Grafana 进行统一。
- 你更倾向于等待整个生态系统进一步成熟,以及基于 SQL 的可观测性更加开箱即用。
日志与追踪
可观测性场景通常包含三个核心支柱:Logging、Tracing 和 Metrics,每一类都有不同的数据类型和访问模式。
我们目前推荐使用 ClickHouse 存储两类可观测性数据:
- Logs(日志) - 日志是对系统内发生事件的带时间戳记录,用于捕获软件运行各个方面的详细信息。日志中的数据通常是非结构化或半结构化的,可能包括错误信息、用户活动日志、系统变更以及其他事件。日志对于故障排查、异常检测,以及理解导致系统问题的一系列具体事件至关重要。
- Traces(链路追踪) - Traces 捕获请求在分布式系统中穿越不同服务时的完整过程,详细记录这些请求的路径和性能。链路追踪中的数据高度结构化,由 span 和 trace 组成,用于映射请求所经历的每一步,并包含相应的时间信息。Traces 为系统性能提供有价值的洞察,有助于识别瓶颈、定位延迟问题,并优化微服务的整体效率。
虽然 ClickHouse 可以用于存储 metrics 数据,但在 ClickHouse 中,这一支柱目前尚不够成熟,对 Prometheus 数据格式和 PromQL 等特性的支持仍在完善中。
分布式追踪
分布式追踪是可观测性中的关键特性。分布式追踪(通常简称为 trace)用于描绘请求在系统中的完整路径。请求源自终端用户或应用程序,并在系统中扩散,通常表现为在各个微服务之间的一系列操作流转。通过记录这一序列,并支持对后续事件进行关联,可观测性平台用户或 SRE 能够在不受架构复杂度或是否采用无服务器架构影响的情况下,对应用流程中的问题进行诊断。
每个 trace 由多个 span 组成,其中与请求关联的初始 span 被称为 root span。root span 捕获整个请求从开始到结束的过程。位于 root 之下的后续 span 提供了该请求在执行过程中各个步骤或操作的详细信息。如果没有追踪,在分布式系统中诊断性能问题会变得极其困难。通过详细记录请求在系统中流转时发生的事件序列,追踪可以简化分布式系统的调试过程,并帮助更好地理解其行为。
大多数可观测性厂商会将这类信息以瀑布图的形式可视化,相对时间通过按比例缩放的水平条形来展示。例如,在 Grafana 中:
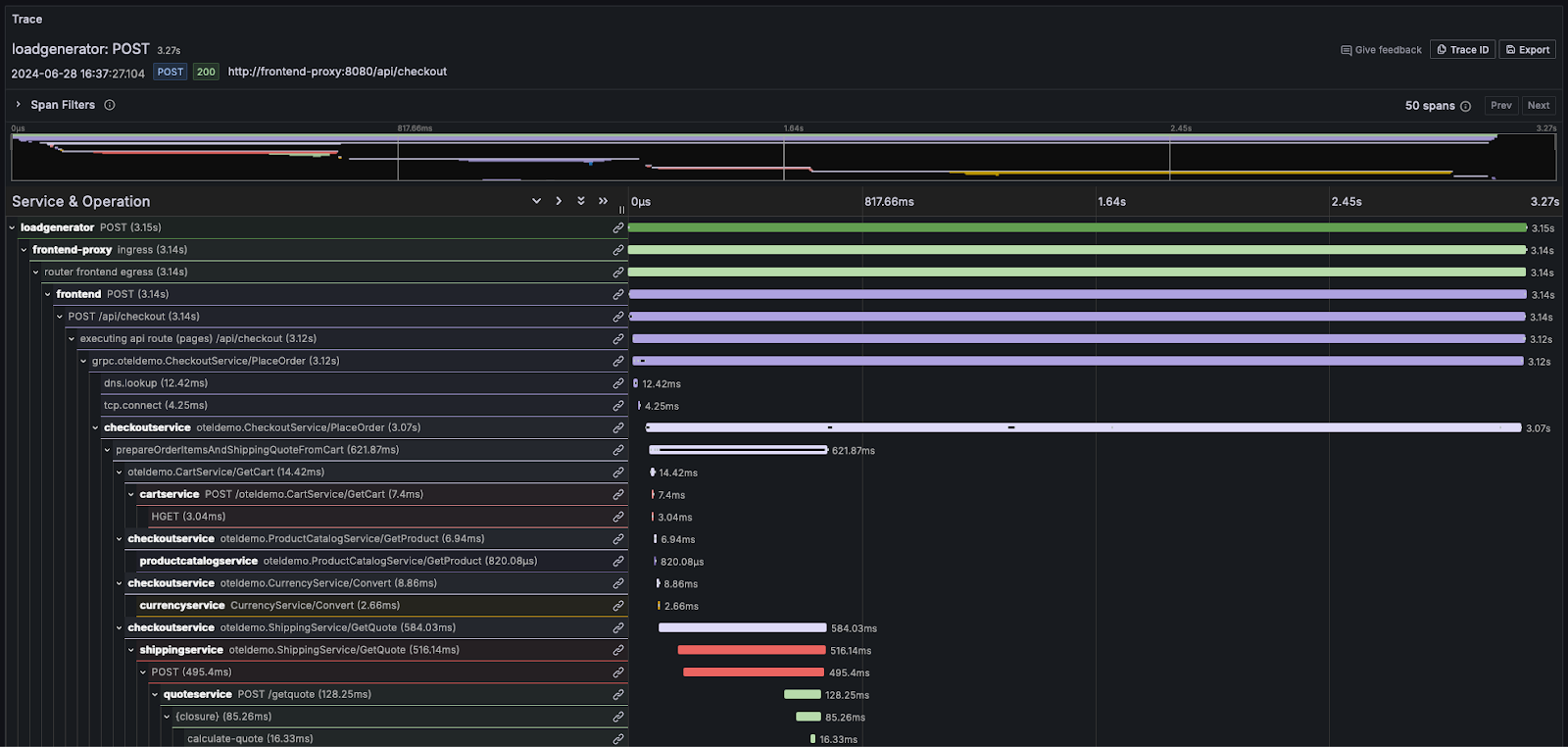
对于需要深入理解日志和 trace 概念的用户,我们强烈推荐阅读 OpenTelemetry 文档。
