使用 ClickStack 监控 Cloudflare 日志
本指南说明如何使用 ClickPipes 将 Cloudflare 日志摄取到 ClickStack 中。Cloudflare Logpush 会将日志写入 S3,ClickPipes 则会持续将新文件摄取到 ClickHouse。与大多数使用 OpenTelemetry Collector 的 ClickStack 集成指南不同,本指南使用 ClickPipes 直接从 S3 拉取数据。
如果您想先查看这些仪表板,再配置生产环境摄取,可以使用演示数据集。
概述
Cloudflare Logpush 可将 HTTP 请求日志导出到 Amazon S3 等目标。将这些日志转发到 ClickStack 后,您可以:
- 结合其他可观测性数据分析边缘流量、缓存性能和安全事件
- 使用 ClickHouse SQL 查询日志
- 将日志保留时间延长至超出 Cloudflare 默认保留期
本指南使用 ClickPipes 持续将来自 S3 的 Cloudflare 日志文件摄取到 ClickHouse 中。S3 在 Cloudflare 和 ClickHouse 之间充当持久缓冲层,提供精确一次语义和重放能力。
Cloudflare Logpush 还支持将日志直接推送到 HTTP 端点。由于 Cloudflare 将日志导出为换行分隔的 JSON (NDJSON) ,而 ClickHouse 可通过 JSONEachRow 原生接收这种格式,因此您可以使用以下端点 URL 格式,将 Logpush 直接指向您的 ClickHouse Cloud HTTP 接口:
将 YOUR_CLICKHOUSE_HOST 替换为你的 ClickHouse Cloud 主机名,并将 BASE64_CREDENTIALS 替换为经过 Base64 编码的凭据 (echo -n 'default:YOUR_PASSWORD' | base64) 。
这种方式设置起来更简单 (无需配置 S3、SQS 或 IAM) ,但如果传输失败,Cloudflare Logpush 无法补传历史数据——因此,如果 ClickHouse 在某次推送期间不可用,这些日志将永久丢失。
与现有的 Cloudflare Logpush 集成
本节假设您已将 Cloudflare Logpush 配置为把日志导出到 S3。否则,请先参阅 Cloudflare 的 AWS S3 配置指南。
前提条件
- ClickHouse Cloud 服务已在运行 (ClickPipes 是仅限 Cloud 的功能,在 ClickStack OSS 中不可用)
- Cloudflare Logpush 正在持续将日志写入 S3 存储桶
- Cloudflare 写入日志的 S3 存储桶名称及其区域
配置 S3 身份验证
ClickPipes 需要具备读取您 S3 存储桶的权限。请参阅安全访问 S3 数据指南,配置基于 IAM 角色的访问权限或基于凭证的访问权限。
有关 ClickPipes S3 身份验证和权限的完整详情,请参阅 S3 ClickPipes 参考文档。
创建 ClickPipes 任务
- ClickHouse Cloud 控制台 → 数据源 → 创建 ClickPipe
- 来源:Amazon S3
连接:
- S3 文件路径:您的 Cloudflare 日志存储桶路径,使用通配符匹配文件。如果您在 Logpush 中启用了按天划分的子文件夹,请使用
**匹配各个子目录中的文件:- 无子目录:
https://your-bucket.s3.us-east-1.amazonaws.com/logs/* - 按日划分的子目录:
https://your-bucket.s3.us-east-1.amazonaws.com/logs/**/*
- 无子目录:
- 身份验证:选择身份验证方式,并提供凭证或 IAM 角色 ARN
摄取设置:
点击 Incoming data,然后配置:
- 开启 持续摄取
- 排序方式:按字典序
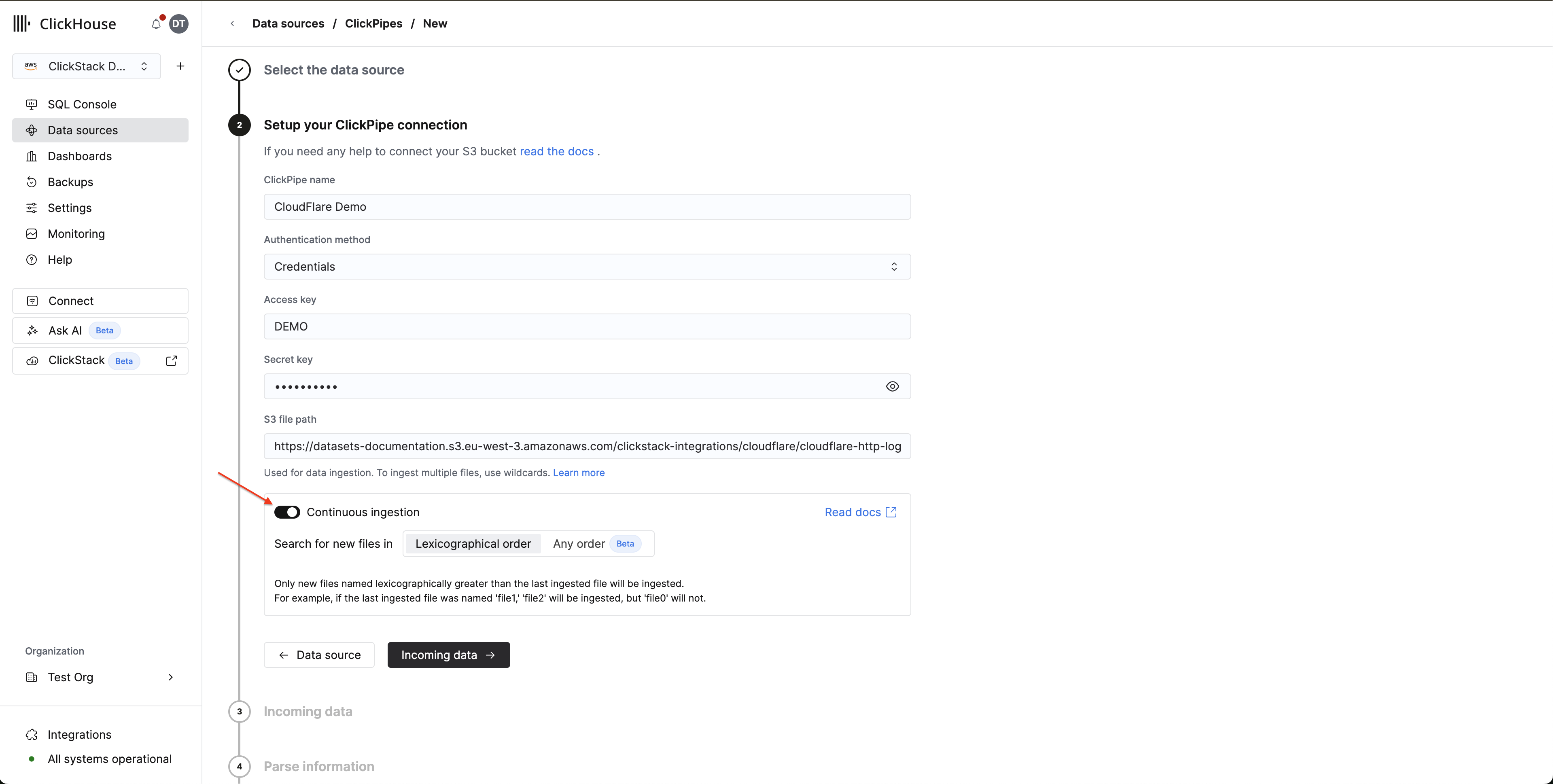
Cloudflare Logpush 以基于日期的命名方式写入文件 (例如 20250127/...) ,这天然符合字典序排列。ClickPipes 每 30 秒轮询一次新文件,并摄取所有文件名大于上一个已处理文件名的文件。
Schema 映射:
点击 Parse information。ClickPipes 会对您的日志文件进行采样并自动检测 schema。请检查映射的列并根据需要调整类型。为目标表定义排序键 — 对于 Cloudflare 日志,推荐选择 (EdgeStartTimestamp, ClientCountry, EdgeResponseStatus)。
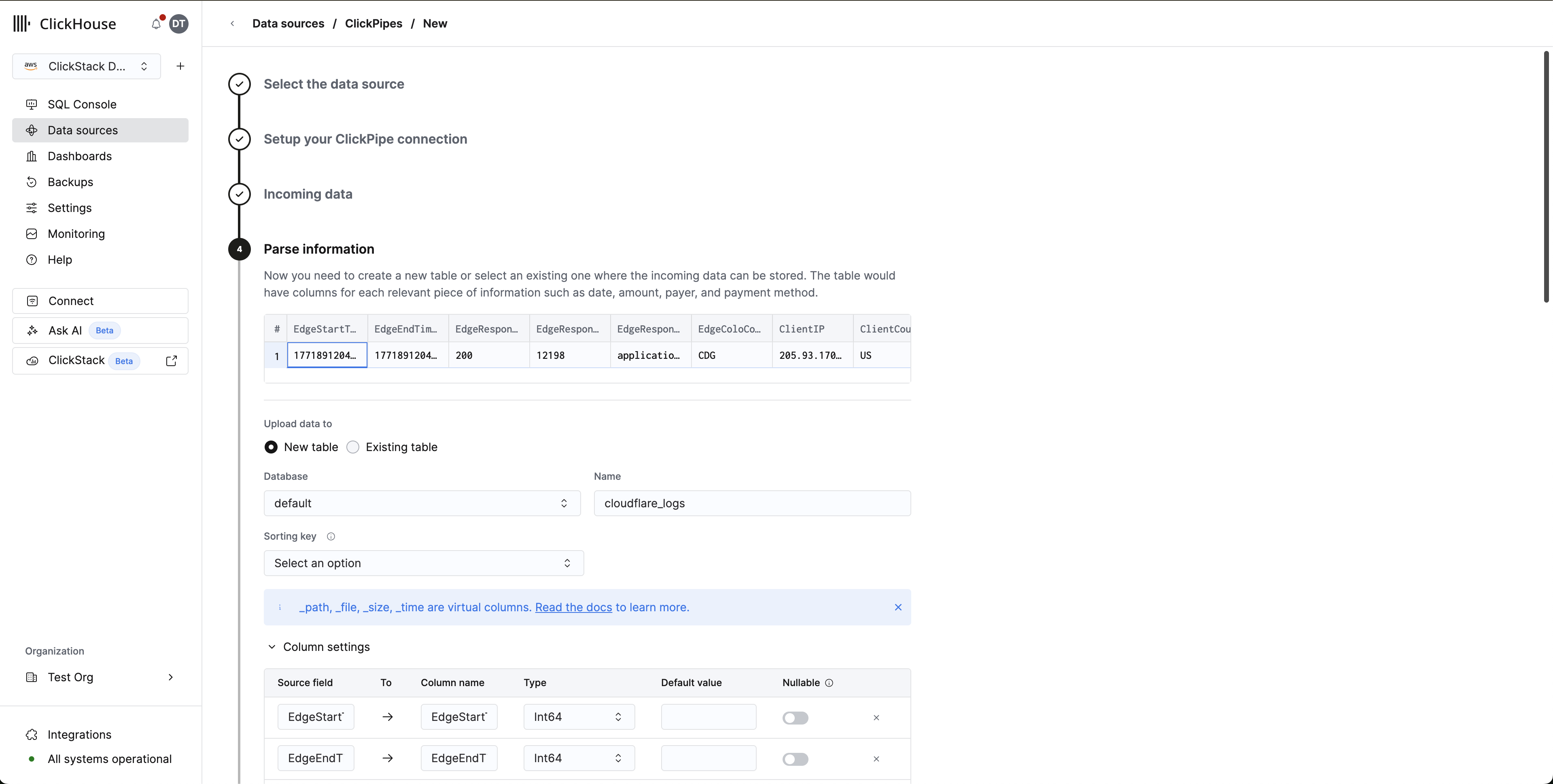
点击 Complete Setup。
首次创建时,ClickPipes 会先对指定路径中的所有现有文件执行初始加载,然后再切换到持续轮询模式。如果您的存储桶中积压了大量 Cloudflare 日志,此初始加载可能需要较长时间。
配置 HyperDX 数据源
ClickPipes 将 Cloudflare 日志摄取到一个以 Cloudflare 原生字段名称为列名的平面表中。要在 HyperDX 中查看这些日志,请配置一个自定义数据源,将 Cloudflare 的列映射到 HyperDX 的日志视图。
- 打开 HyperDX → 团队设置 → 数据源
- 点击 Add source 并配置以下设置。点击 Configure Optional Fields 以查看所有字段:
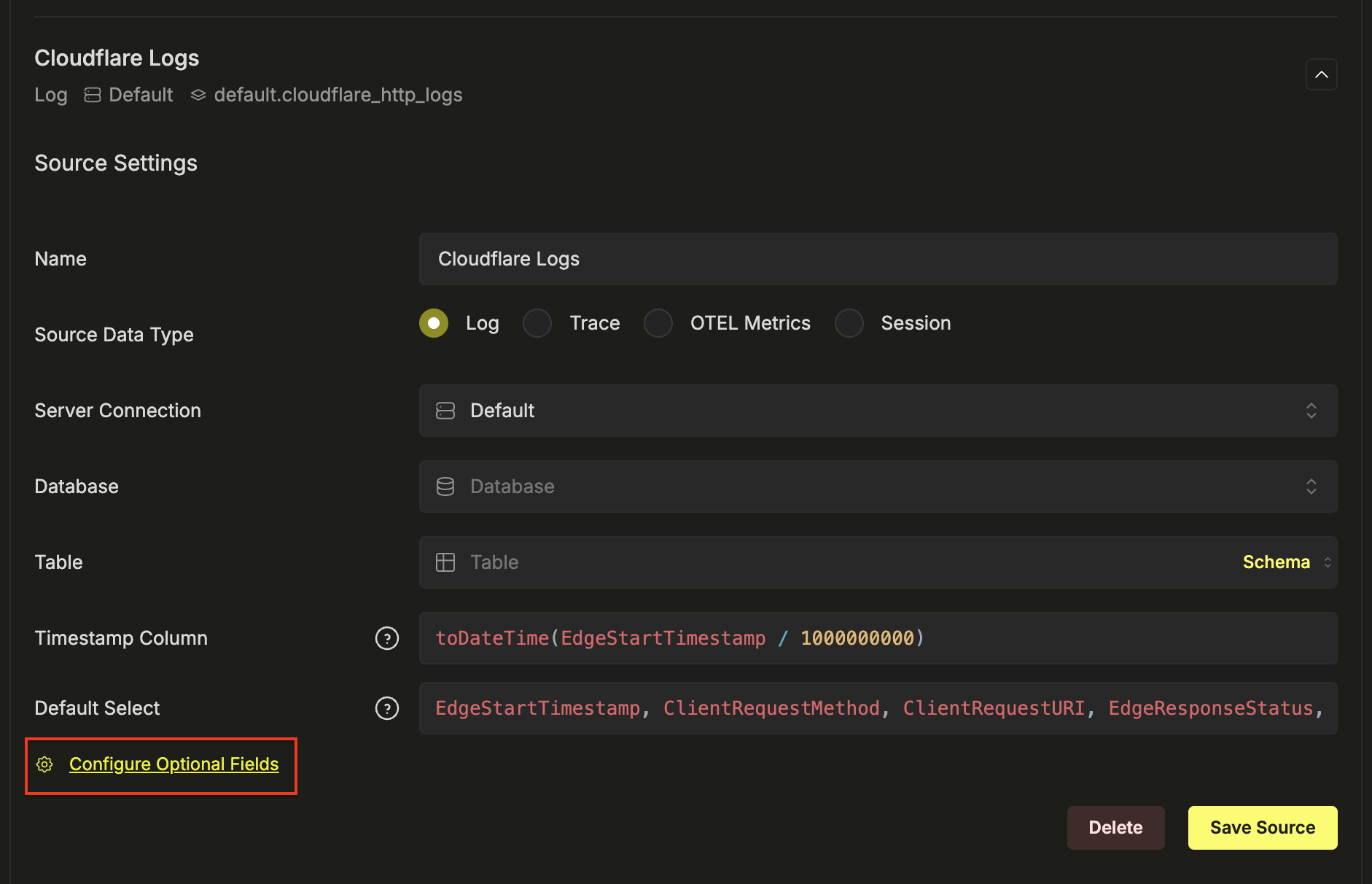
| Set | 值 |
|---|---|
| 名称 | Cloudflare 日志 |
| 数据源类型 | 日志 |
| 数据库 | default |
| 数据表 | cloudflare_http_logs |
| 时间戳列 | toDateTime(EdgeStartTimestamp / 1000000000) |
| 默认查询列 | EdgeStartTimestamp, ClientRequestMethod, ClientRequestURI, EdgeResponseStatus, ClientCountry |
| 服务名称表达式 | 'cloudflare' |
| 日志级别表达式 | multiIf(EdgeResponseStatus >= 500, 'ERROR', EdgeResponseStatus >= 400, 'WARN', 'INFO') |
| 日志正文表达式 | concat(ClientRequestMethod, ' ', ClientRequestURI, ' ', toString(EdgeResponseStatus)) |
| 日志属性表达式 | map('http.method', ClientRequestMethod, 'http.status_code', toString(EdgeResponseStatus), 'http.url', ClientRequestURI, 'client.country', ClientCountry, 'client.ip', ClientIP, 'cache.status', CacheCacheStatus, 'bot.score', toString(BotScore), 'cloudflare.ray_id', RayID, 'cloudflare.colo', EdgeColoCode) |
| 资源属性表达式 | map('cloudflare.zone', ClientRequestHost) |
| 隐式列表达式 | concat(ClientRequestMethod, ' ', ClientRequestURI) |
- 点击 Save Source
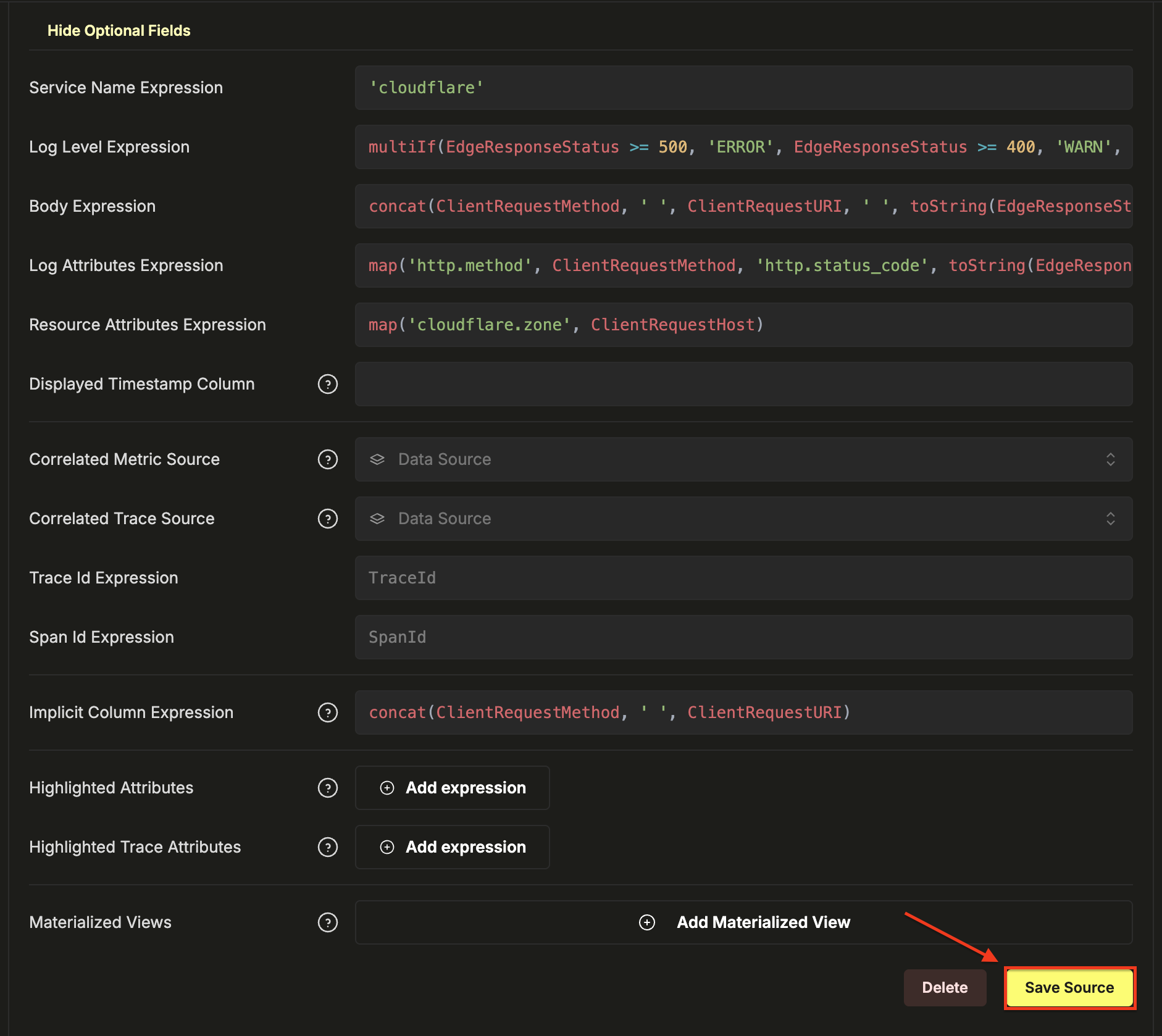
这将 Cloudflare 的原生列直接映射到 HyperDX 的日志查看器,无需任何数据转换或重复处理。Body 字段显示请求摘要,例如 GET /api/v1/users 200,所有 Cloudflare 字段均可作为可搜索属性使用。
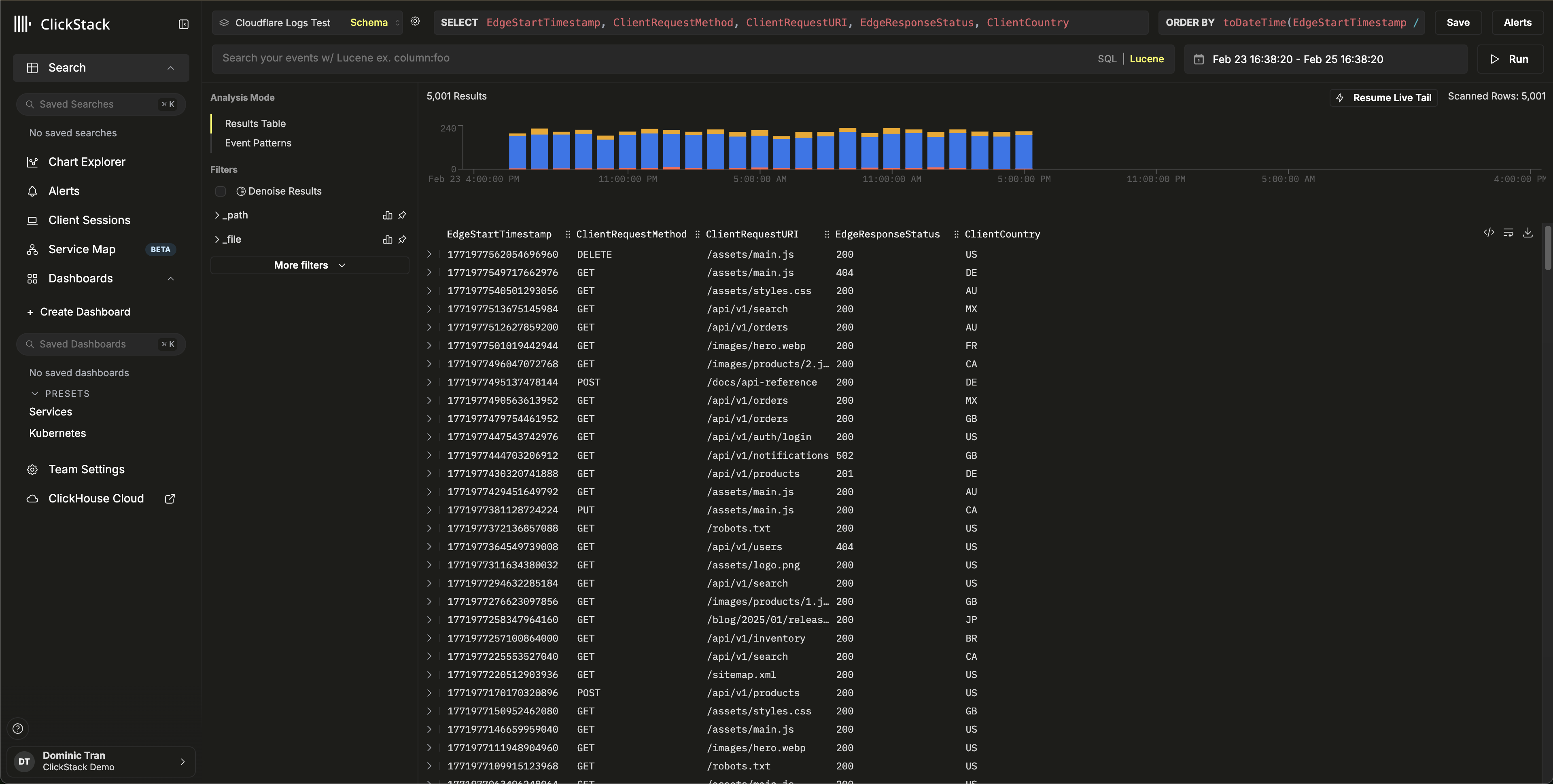
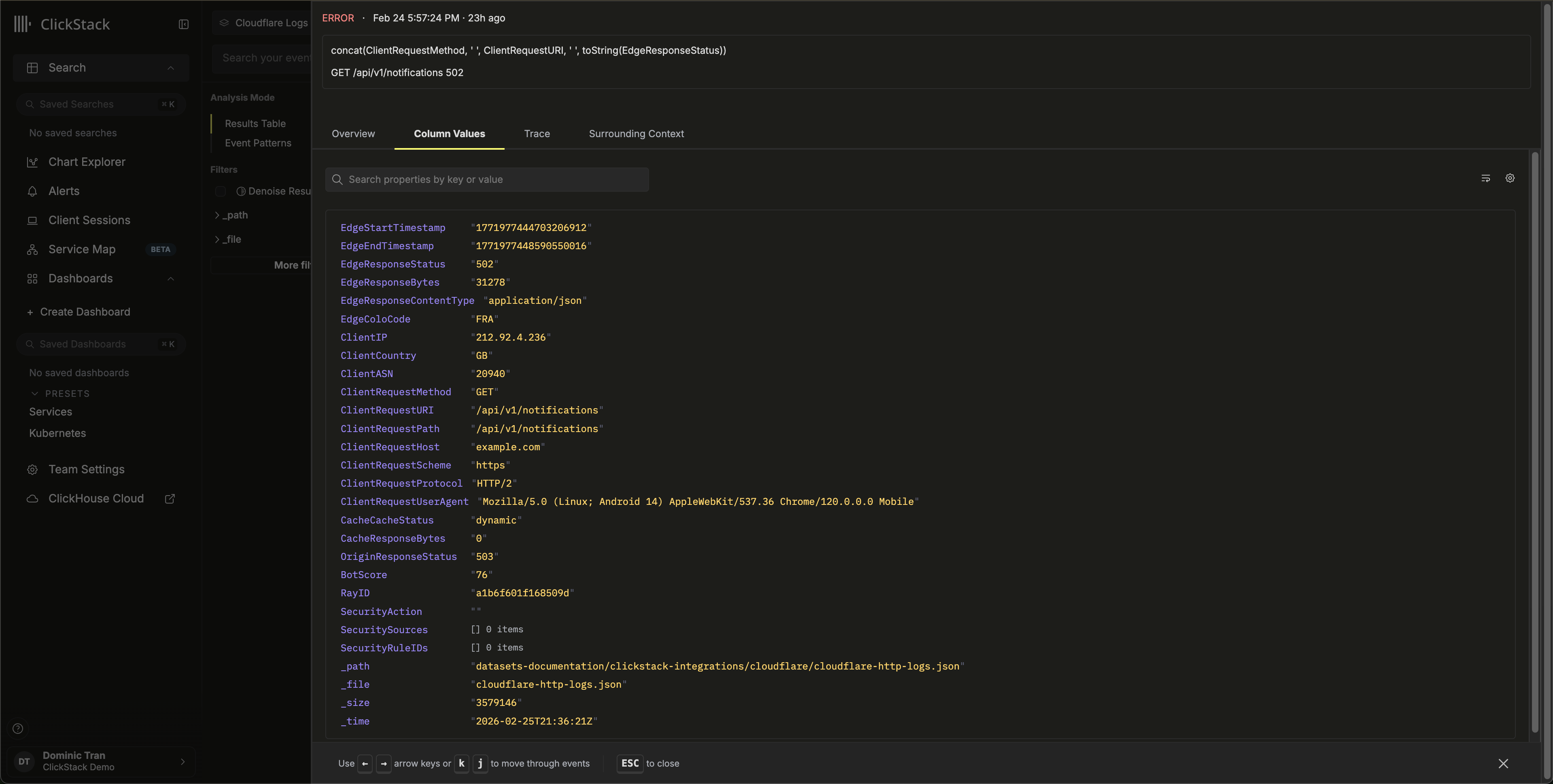
在 HyperDX 中验证数据
导航至 Search 视图,选择 Cloudflare Logs 数据源。将时间范围设置为涵盖您的数据。您应能看到包含以下内容的日志条目:
- Body 列中的请求摘要 (例如
GET /api/v1/users 200) - 按 HTTP 状态码用颜色区分的严重级别 (2xx 为 INFO,4xx 为 WARN,5xx 为 ERROR)
- 如
http.status_code、client.country、cache.status和bot.score这样的可搜索字段
演示数据集
对于希望在配置生产环境 Cloudflare Logpush 之前先测试集成的用户,我们提供了一个包含真实 HTTP 请求日志的示例数据集。
使用演示数据集启动 ClickPipes
- ClickHouse Cloud Console → Data Sources → Create ClickPipe
- Source:Amazon S3
- Authentication:Public
- S3 file path:
https://datasets-documentation.s3.eu-west-3.amazonaws.com/clickstack-integrations/cloudflare/cloudflare-http-logs.json - 点击 Incoming data
- 选择 JSON 作为格式
- 点击 Parse information,查看检测到的 schema
- 将 Table name 设置为
cloudflare_http_logs - 点击 Complete Setup
该数据集包含 5,000 条覆盖 24 小时的 HTTP 请求日志,具有真实流量模式,包括来自多个国家/地区的流量、缓存命中和未命中、API 和静态资源请求、错误响应以及安全事件。
验证演示数据
在 HyperDX 中打开 Search 视图,选择 Cloudflare Logs 数据源,并将时间范围设置为 2026-02-23 00:00:00 - 2026-02-26 00:00:00。
你应能看到包含请求摘要、可搜索的 Cloudflare 属性以及基于 HTTP 状态码的严重级别的日志条目。
HyperDX 会按浏览器本地时区显示时间戳。演示数据覆盖 2026-02-24 00:00:00 - 2026-02-25 00:00:00 (UTC)。较宽的时间范围可确保你无论位于何处都能看到演示日志。看到日志后,你可以将范围缩小到 24 小时,以获得更清晰的可视化效果。
仪表板和可视化
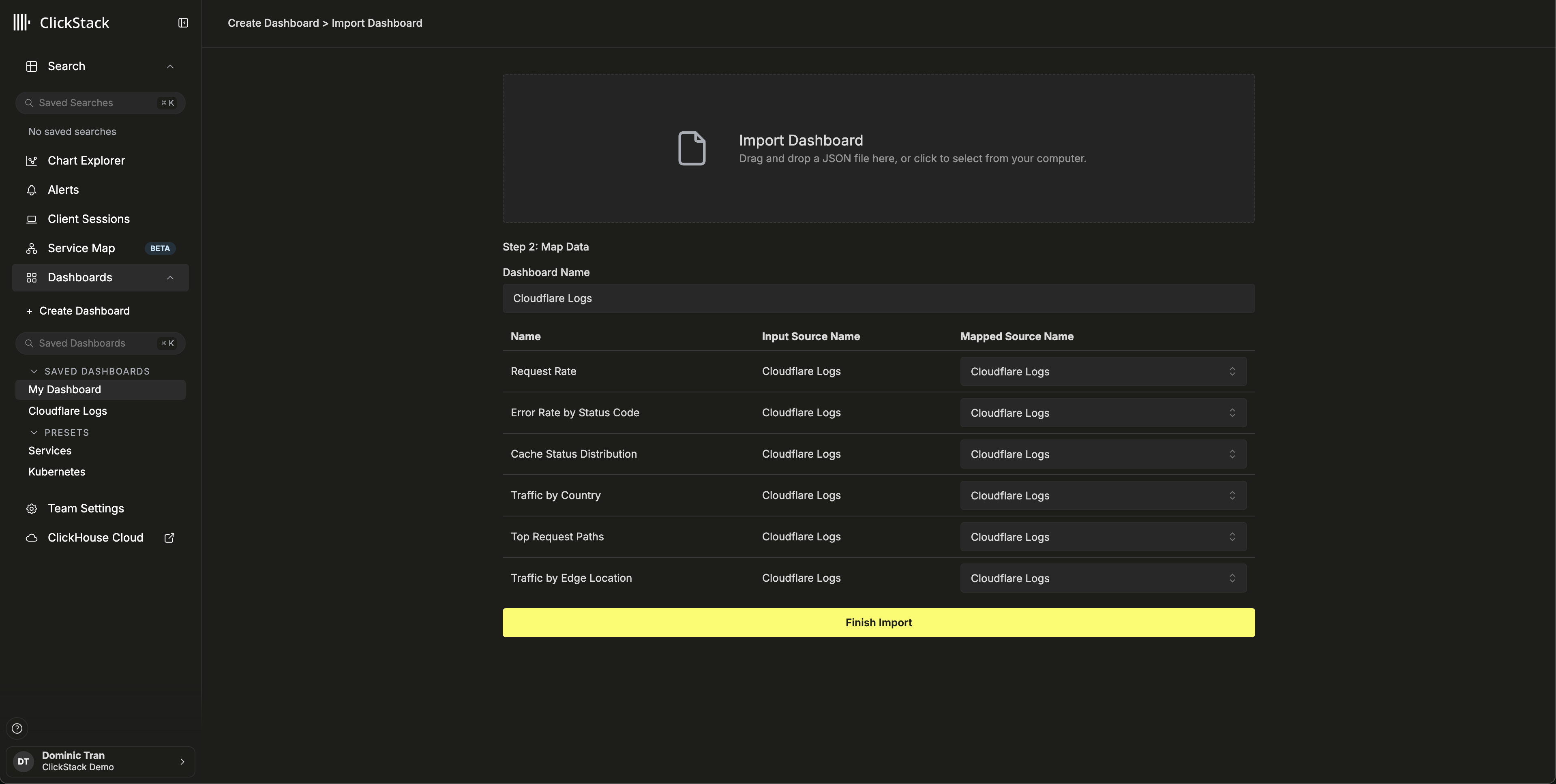
查看仪表板
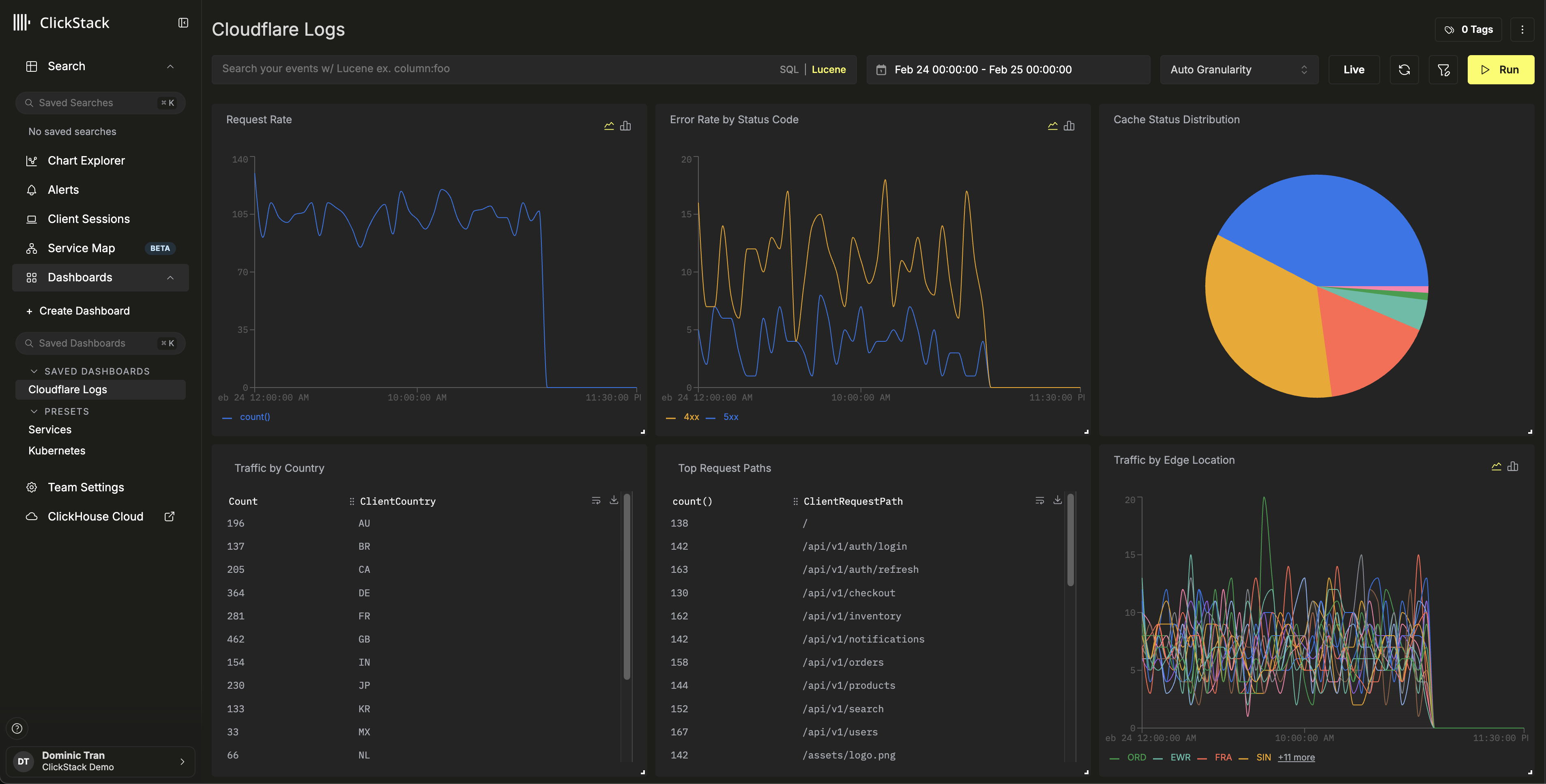
对于演示数据集,请将时间范围设置为 2026-02-24 00:00:00 - 2026-02-25 00:00:00 (UTC) (请根据本地时区进行调整) 。导入的仪表板默认不会预设时间范围。
故障排查
ClickHouse 中未显示数据
确认表已创建且包含数据:
如果表已存在但为空,请检查 ClickPipes 中是否存在错误:ClickHouse Cloud Console → Data Sources → 你的 ClickPipe → Logs。有关私有存储桶身份验证问题,请参阅 S3 ClickPipes 访问控制文档。
HyperDX 中未显示日志
如果数据已写入 ClickHouse,但在 HyperDX 中不可见,请检查数据源配置:
- 确认在 HyperDX → Team Settings → Sources 下存在
cloudflare_http_logs数据源 - 确保 Timestamp Column 设置为
toDateTime(EdgeStartTimestamp / 1000000000)—— Cloudflare 时间戳的单位为纳秒,需要进行转换 - 确认 HyperDX 中选择的时间范围覆盖这些数据。对于演示数据集,请使用 2026-02-23 00:00:00 - 2026-02-26 00:00:00
后续步骤
投入生产环境
本指南演示了如何使用公开的演示数据集摄取 Cloudflare 日志。对于生产环境部署,请将 Cloudflare Logpush 配置为写入您自己的 S3 存储桶,并为 ClickPipes 设置基于 IAM 角色的身份验证,以确保访问安全。仅选择所需的 Logpush 字段,以减少存储成本和摄取量。在 Logpush 中启用按日划分的子文件夹,以便更好地组织文件;并在 ClickPipes 路径模式中使用 **/*,以匹配各个子目录中的文件。
有关高级配置选项 (包括用于处理回填和乱序文件的基于 SQS 的无序摄取) ,请参阅 S3 ClickPipes 文档。
