数据湖入门
通过动手实践了解如何查询数据湖表、使用 MergeTree 为其加速,并将结果写回 Iceberg。所有步骤均使用公共数据集,且同时适用于 Cloud 和 OSS。
本指南中的截图来自 ClickHouse Cloud 的 SQL 控制台。所有查询都适用于 Cloud 和自管理部署。
直接查询 Iceberg 数据
最快的上手方式是使用 icebergS3() 表函数——将其指向 S3 中的 Iceberg 表即可立即执行查询,无需任何配置。
查看 Schema:
运行查询:
ClickHouse 直接从 S3 读取 Iceberg 元数据并自动推断 schema。同样的方法也适用于 deltaLake()、hudi() 和 paimon()。
了解更多: 直接查询开放表格式 涵盖全部四种格式、用于分布式读取的集群变体以及存储后端选项 (S3、Azure、HDFS、本地) 。

连接到目录
大多数组织通过数据目录管理 Iceberg 表,以集中管理表元数据并实现数据发现。ClickHouse 支持使用 DataLakeCatalog 数据库引擎连接到您的目录,将所有目录表作为 ClickHouse 数据库对外暴露。这是扩展性更强的方案——每当新的 Iceberg 表被创建时,无需任何额外操作即可在 ClickHouse 中直接访问。
以下是连接到 AWS Glue 的示例:
每种目录类型都需要各自的连接设置——请参阅 Catalogs 指南,获取支持的目录及其配置选项的完整列表。
浏览表并进行查询:
<database>.<table> 两侧需要加反引号,因为 ClickHouse 原生不支持多个命名空间。
了解更多: 连接到数据目录 介绍了包含 Delta 和 Iceberg 示例的完整 Unity Catalog 配置流程。
执行查询
无论您使用上述哪种方法——表函数、表引擎还是目录——相同的 ClickHouse SQL 语法均适用:
查询语法完全相同——仅 FROM 子句有所变化。无论数据源如何,所有 ClickHouse SQL 函数、JOIN 操作和聚合运算均以相同方式运行。
将子集加载到 ClickHouse
直接查询 Iceberg 固然方便,但性能受限于网络吞吐量和文件布局。对于分析型工作负载,建议将数据加载到原生 MergeTree 表中。
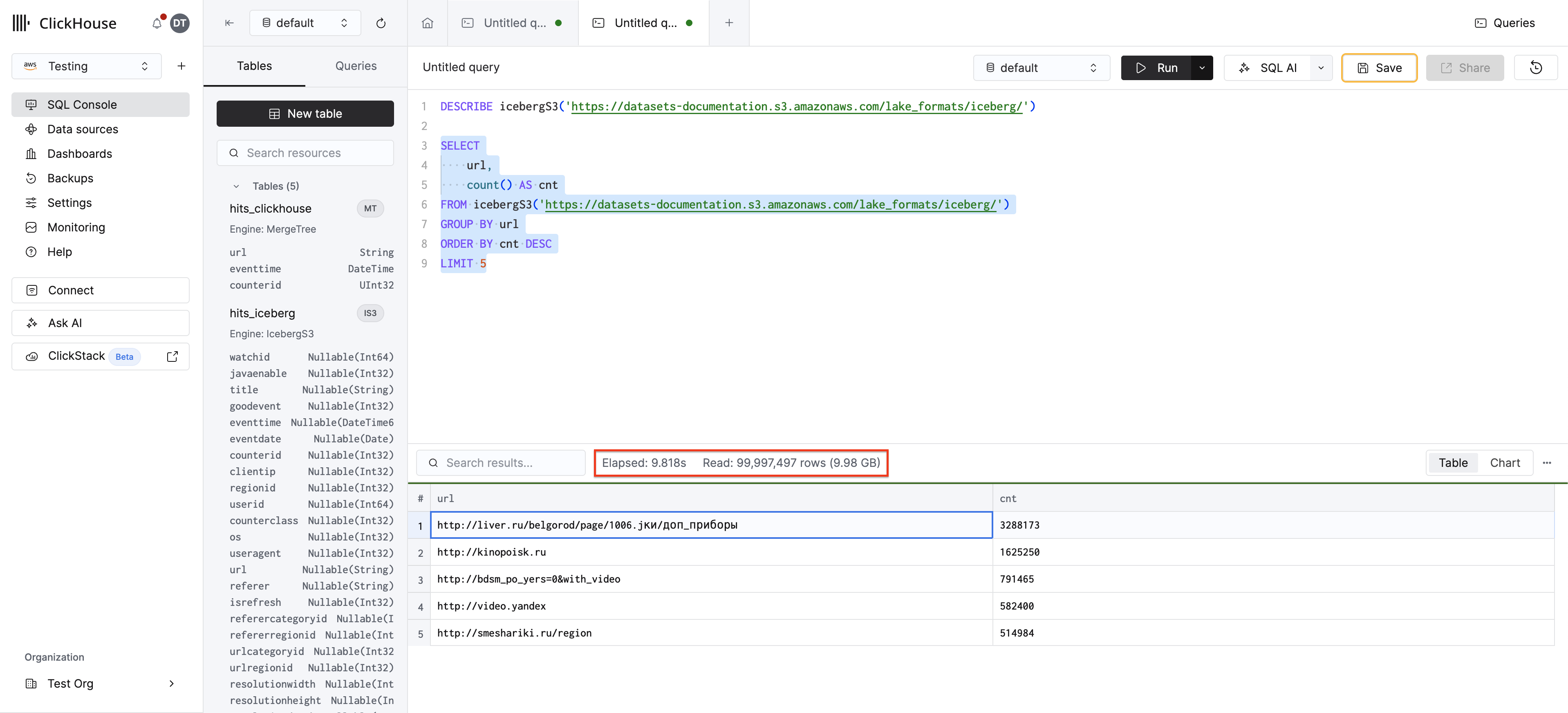
首先,对 Iceberg 表运行过滤查询以获取基准数据:
此查询会扫描 S3 中的完整数据集,因为 Iceberg 无法识别 counterid 过滤条件——预计需要数秒钟。
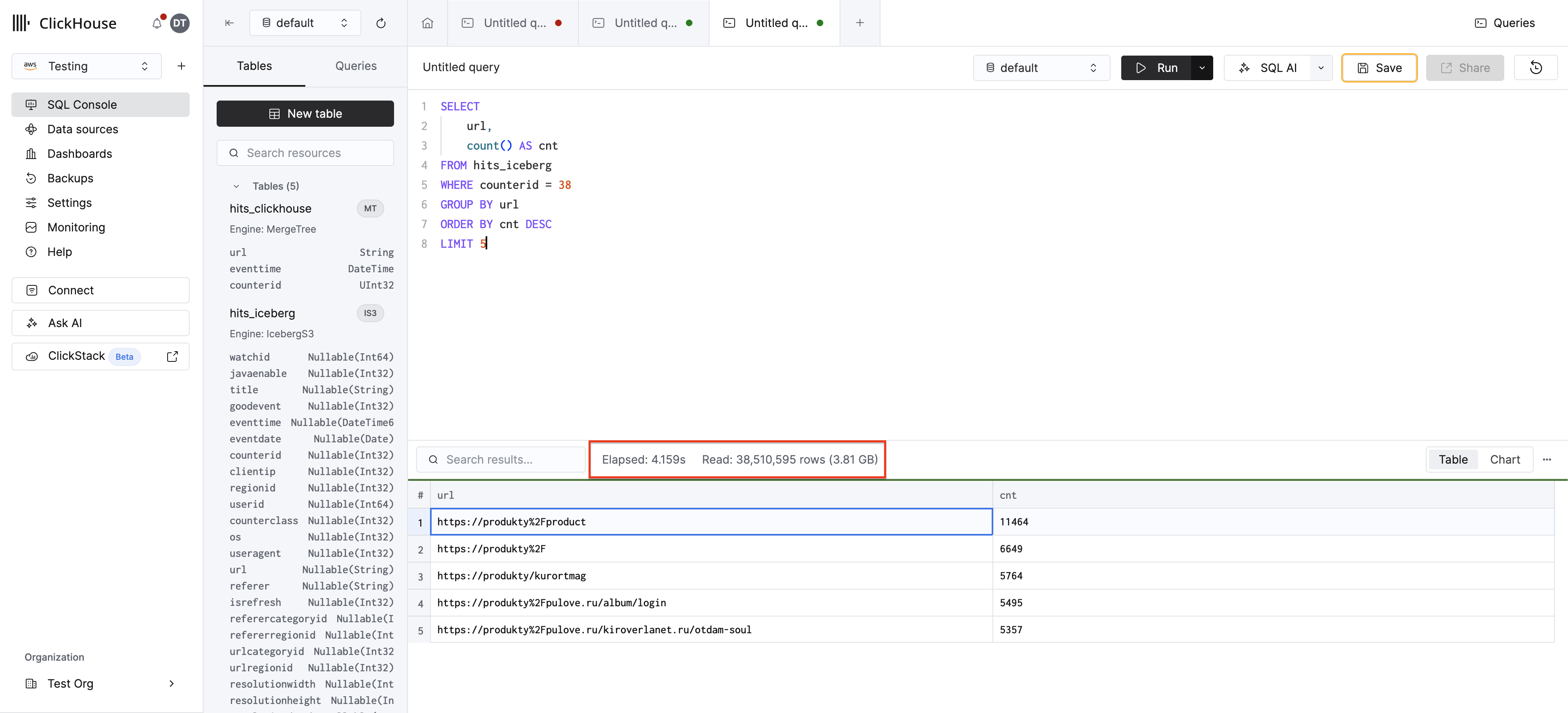
现在创建一个 MergeTree 表并加载数据:
对 MergeTree 表重新运行相同的查询:
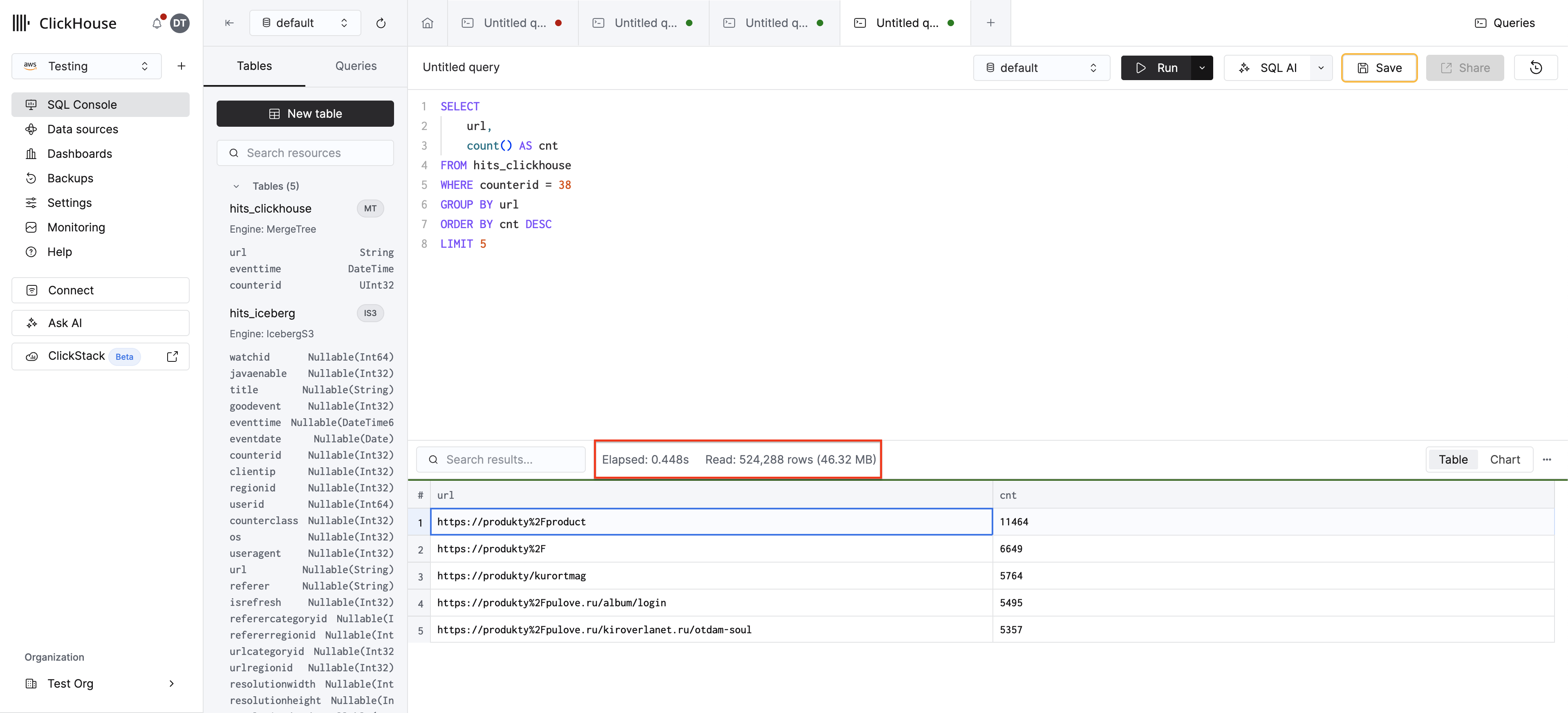
由于 counterid 是 ORDER BY 键中的第一列,ClickHouse 的稀疏主索引可直接跳转至相关粒度——仅读取 counterid = 38 对应的行,而无需扫描全部 1 亿行。这将带来显著的性能提升。
加速分析指南通过 LowCardinality 类型、全文索引和优化排序键进一步深入探讨,在包含 2.83 亿行的数据集上实现了 约 40 倍的性能提升。
了解更多: 使用 MergeTree 加速分析 涵盖了 Schema 优化、全文索引以及完整的优化前后性能对比。
写回 Iceberg
ClickHouse 还可以将数据写回 Iceberg 表,从而支持反向 ETL 工作流——将聚合结果或数据子集发布,以供其他工具 (Spark、Trino、DuckDB 等) 消费。
创建用于输出的 Iceberg 表:
写入聚合结果:
生成的 Iceberg 表可被任何兼容 Iceberg 的引擎读取。
了解更多: 将数据写入开放表格式 介绍了如何使用 UK Price Paid 数据集写入原始数据和聚合结果,包括将 ClickHouse 类型映射到 Iceberg 时的 schema 设计注意事项。
后续步骤
现在您已经了解了完整的工作流程,可以进一步深入了解各个方面:
