使用 Jupyter Notebook 和 chDB 探索数据
在本指南中,您将学习如何借助 chDB(一个由 ClickHouse 驱动的快速进程内 SQL OLAP 引擎),在 Jupyter Notebook 中探索 ClickHouse Cloud 上的数据集。
前置条件:
- 一个虚拟环境
- 一个可用的 ClickHouse Cloud 服务,以及您的连接信息
提示
如果您还没有 ClickHouse Cloud 账号,可以注册
试用,并获得 300 美元的免费额度开始使用。
您将学到:
- 使用 chDB 从 Jupyter Notebook 连接到 ClickHouse Cloud
- 查询远程数据集并将结果转换为 Pandas DataFrame
- 将云端数据与本地 CSV 文件结合进行分析
- 使用 matplotlib 可视化数据
我们将使用 UK Property Price 数据集,该数据集是 ClickHouse Cloud 提供的入门数据集之一。
它包含 1995 年到 2024 年间英国房屋成交价格的数据。
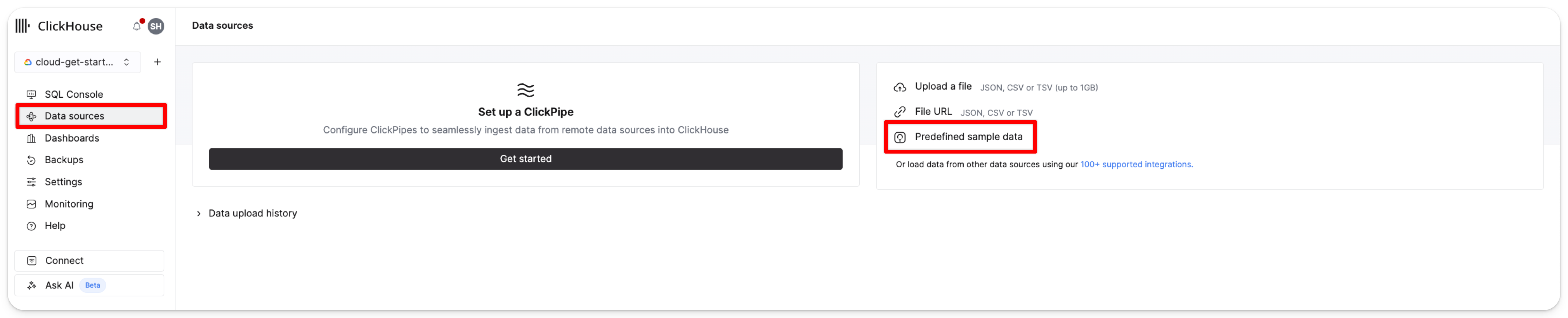
要将此数据集添加到现有的 ClickHouse Cloud 服务中,请使用您的账户信息登录 console.clickhouse.cloud。
在左侧菜单中,点击 Data sources,然后点击 Predefined sample data:
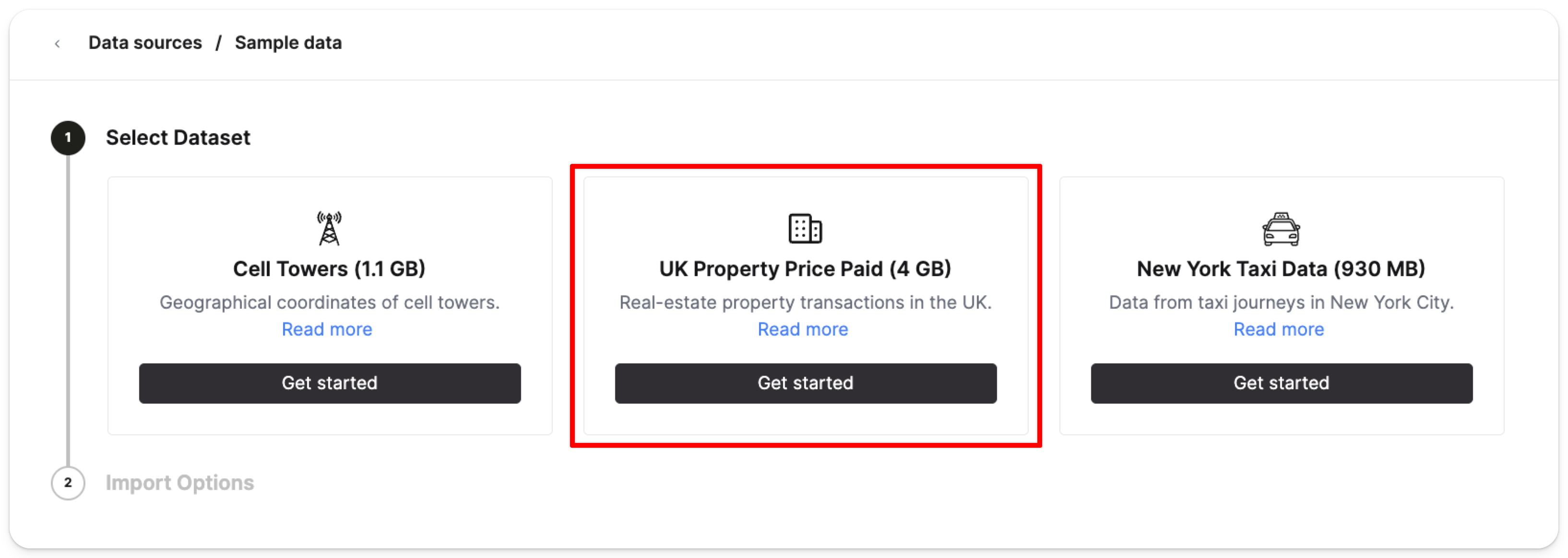
在 UK property price paid data (4GB) 卡片中选择 Get started:
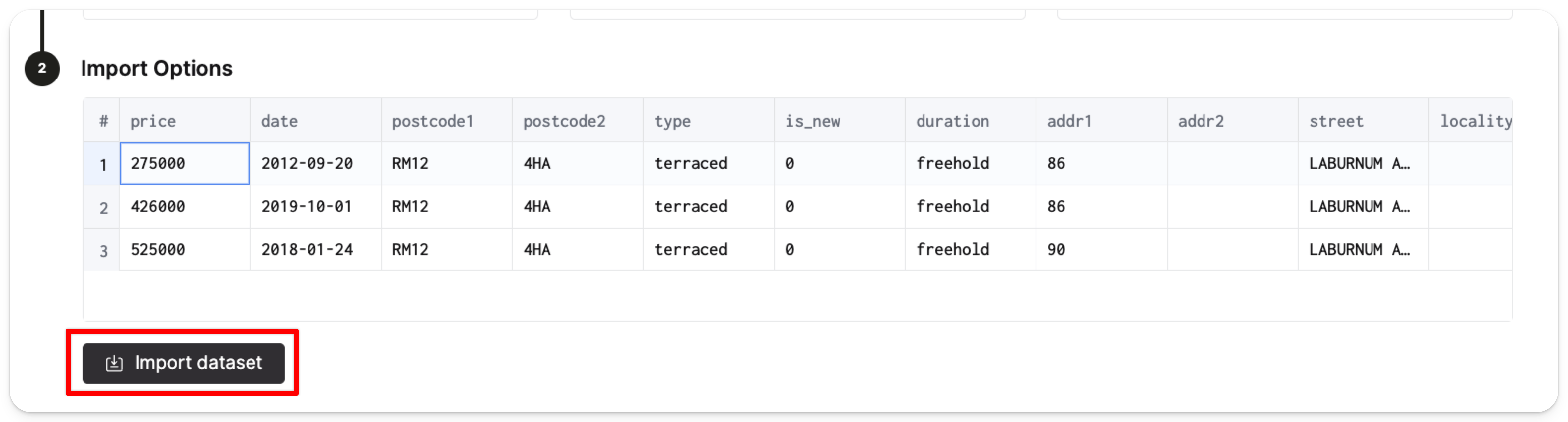
然后点击 Import dataset:
ClickHouse 将在 default 数据库中自动创建 pp_complete 表,并向该表填充 2,892 万行价格数据。
为降低凭证泄露的可能性,建议您将 Cloud 用户名和密码作为环境变量添加到本地机器。
在终端中运行以下命令,将用户名和密码添加为环境变量:
export CLICKHOUSE_USER=default
export CLICKHOUSE_PASSWORD=your_actual_password
注意
上述环境变量仅在当前终端会话期间有效。
要使其永久生效,请将它们添加到你的 shell 配置文件中。
现在激活你的虚拟环境。
在虚拟环境中运行以下命令来安装 Jupyter Notebook:
使用以下命令启动 Jupyter Notebook:
会打开一个新的浏览器窗口,其中显示位于 localhost:8888 的 Jupyter 界面。
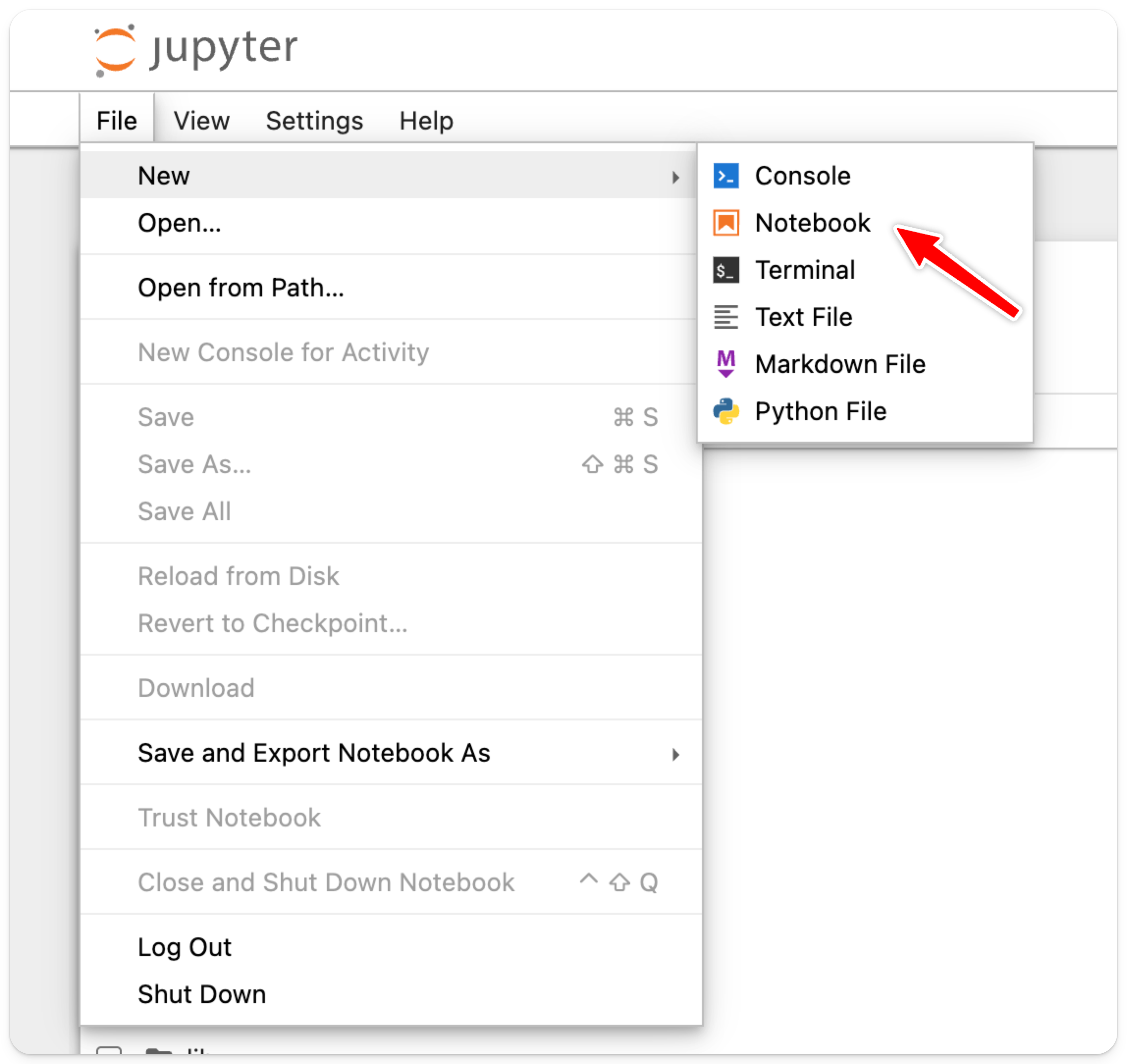
点击 File > New > Notebook 来创建一个新的 Notebook。
此时会提示你选择一个内核。
选择任意可用的 Python 内核,在本示例中我们选择 ipykernel:
在一个空白单元格中,你可以输入以下命令来安装 chDB,我们将使用它来连接远程的 ClickHouse Cloud 实例:
现在可以导入 chDB,并运行一个简单的查询,以检查一切是否已正确设置:
import chdb
result = chdb.query("SELECT 'Hello, ClickHouse!' as message")
print(result)
探索数据
在已经完成 UK price paid 数据集的配置,并在 Jupyter notebook 中成功运行 chDB 之后,我们现在可以开始探索这些数据。
假设我们希望查看英国某个地区(例如首都伦敦)的房价随时间的变化情况。
ClickHouse 的 remoteSecure 函数可以让你轻松从 ClickHouse Cloud 中获取数据。
你可以让 chDB 在进程内返回这些数据,并将其转换为一个 Pandas 数据帧——这是一种方便且熟悉的数据处理方式。
编写如下查询,从你的 ClickHouse Cloud 服务中获取 UK price paid 数据,并将其转换为一个 pandas.DataFrame:
import os
from dotenv import load_dotenv
import chdb
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# Load environment variables from .env file
load_dotenv()
username = os.environ.get('CLICKHOUSE_USER')
password = os.environ.get('CLICKHOUSE_PASSWORD')
query = f"""
SELECT
toYear(date) AS year,
avg(price) AS avg_price
FROM remoteSecure(
'****.europe-west4.gcp.clickhouse.cloud',
default.pp_complete,
'{username}',
'{password}'
)
WHERE town = 'LONDON'
GROUP BY toYear(date)
ORDER BY year;
"""
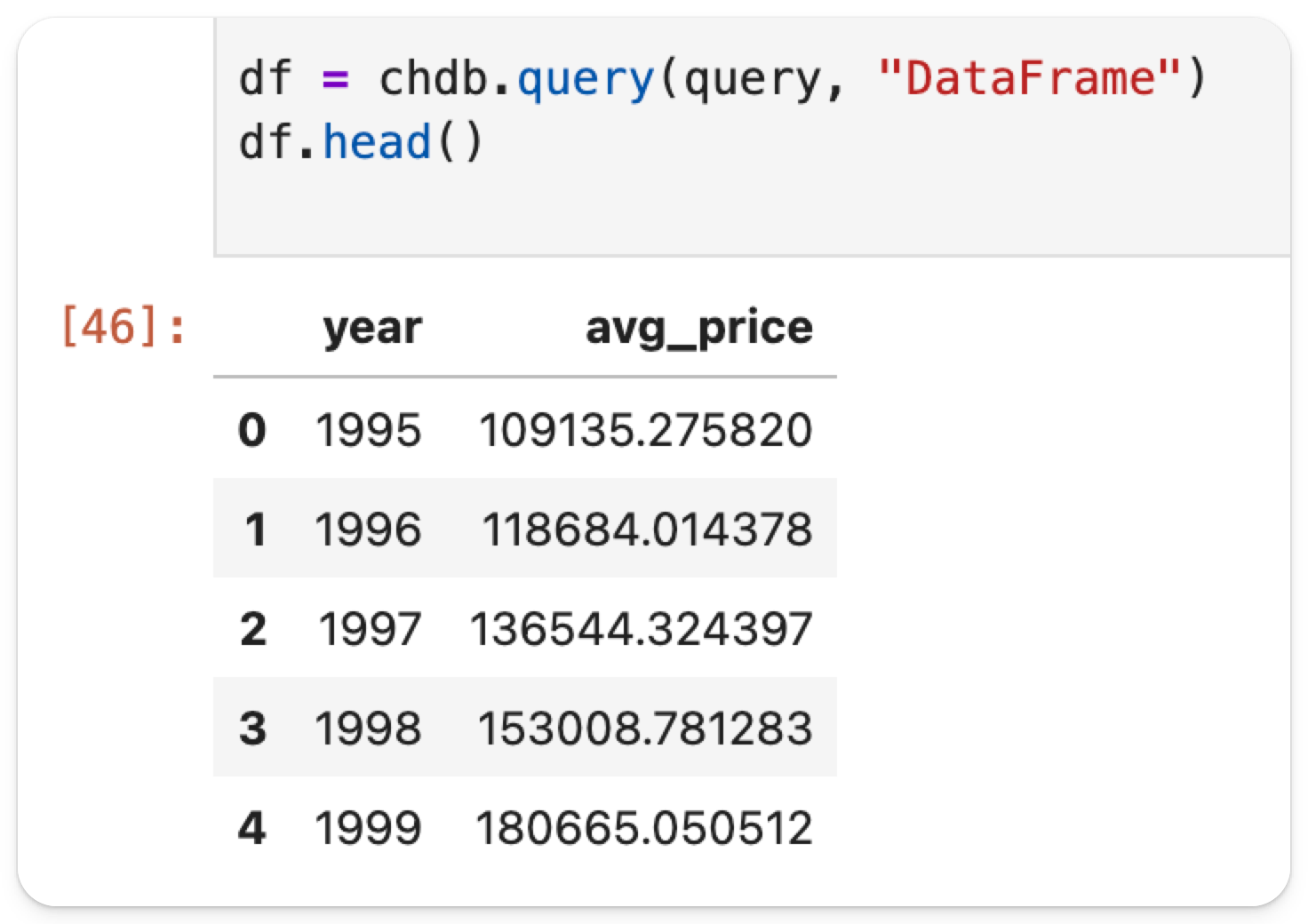
df = chdb.query(query, "DataFrame")
df.head()
在上面的代码片段中,chdb.query(query, "DataFrame") 会运行指定的查询,并将结果以 Pandas DataFrame 的形式输出到终端。
在该查询中,我们使用 remoteSecure 函数连接到 ClickHouse Cloud。
remoteSecure 函数接收如下参数:
- 连接字符串
- 要使用的数据库和数据表名称
- 你的用户名
- 你的密码
作为安全方面的最佳实践,你应优先使用环境变量来传递用户名和密码参数,而不是直接在函数中明文指定,尽管如果你愿意,这也是可行的。
remoteSecure 函数会连接到远程的 ClickHouse Cloud 服务,执行查询并返回结果。
根据数据量大小,这可能需要几秒钟。
在这个示例中,我们返回的是每年的平均价格,并通过 town='LONDON' 进行过滤。
然后结果将作为一个 DataFrame 存储在名为 df 的变量中。
df.head 只会显示返回数据的前几行:
在新的单元格中运行以下命令以检查各列的数据类型:
year uint16
avg_price float64
dtype: object
请注意,虽然在 ClickHouse 中 date 的类型是 Date,但在结果 DataFrame 中其类型是 uint16。
chDB 在返回 DataFrame 时会自动推断最合适的类型。
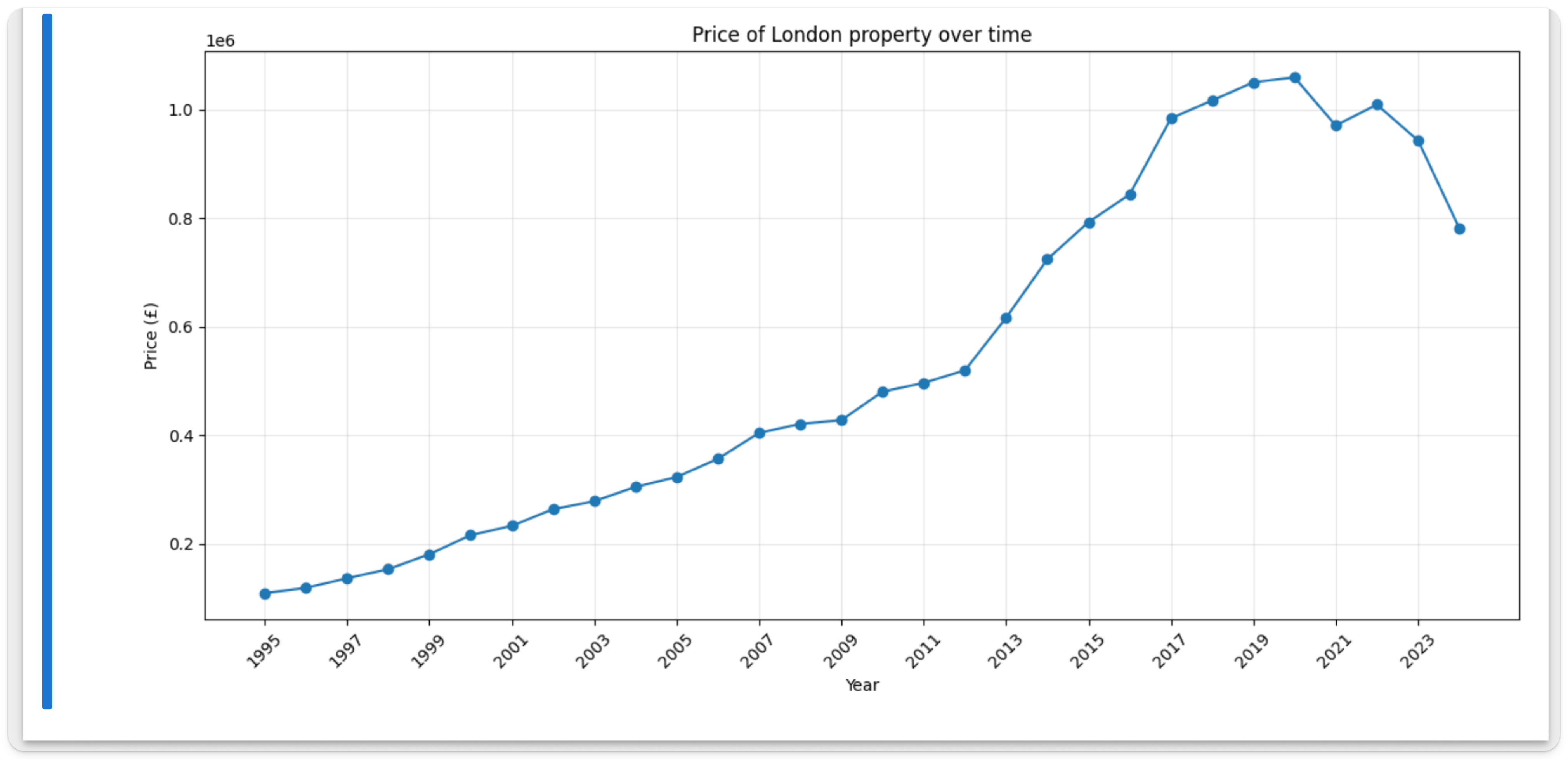
现在我们已经以熟悉的形式获得了数据,让我们来探索一下伦敦房产价格是如何随时间变化的。
在一个新的单元格中运行以下命令,使用 matplotlib 构建一个简单的伦敦房价随时间变化图:
plt.figure(figsize=(12, 6))
plt.plot(df['year'], df['avg_price'], marker='o')
plt.xlabel('Year')
plt.ylabel('Price (£)')
plt.title('Price of London property over time')
# Show every 2nd year to avoid crowding
years_to_show = df['year'][::2] # Every 2nd year
plt.xticks(years_to_show, rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
或许并不意外,伦敦的房价随着时间大幅上涨。
一位数据科学同事给我们发来一个包含更多住房相关变量的 .csv 文件,他想了解
伦敦售出的房屋数量是如何随时间变化的。
让我们将其中一些变量与房价一起绘制出来,看看能否发现任何相关性。
你可以使用 file 表引擎直接读取本地机器上的文件。
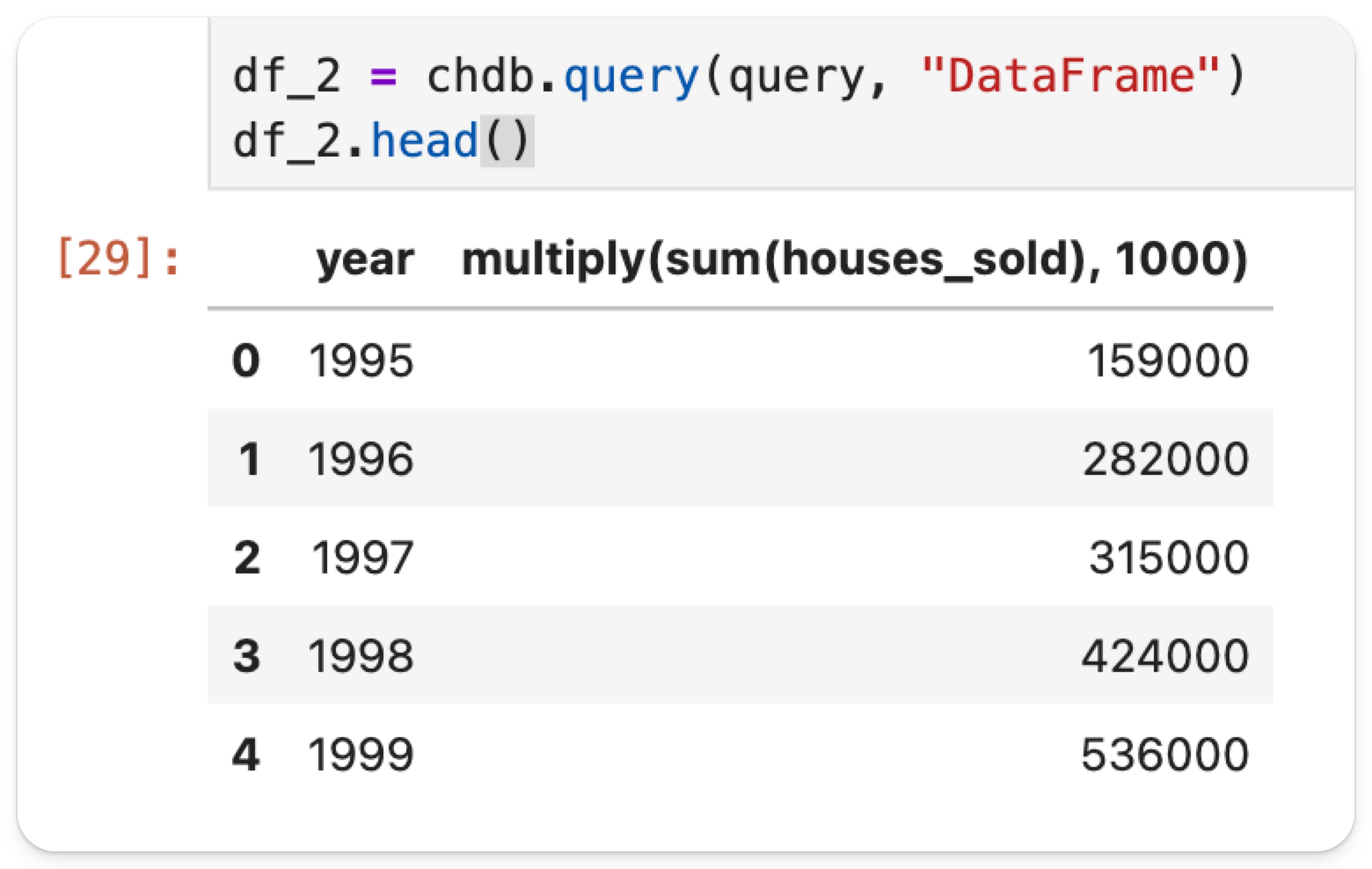
在一个新的单元格中运行以下命令,从本地 .csv 文件创建一个新的 DataFrame。
query = f"""
SELECT
toYear(date) AS year,
sum(houses_sold)*1000
FROM file('/Users/datasci/Desktop/housing_in_london_monthly_variables.csv')
WHERE area = 'city of london' AND houses_sold IS NOT NULL
GROUP BY toYear(date)
ORDER BY year;
"""
df_2 = chdb.query(query, "DataFrame")
df_2.head()
Details
在单个步骤中从多个数据源读取
你也可以在单个步骤中从多个数据源读取。可以使用下面带有
JOIN 的查询来实现:
query = f"""
SELECT
toYear(date) AS year,
avg(price) AS avg_price, housesSold
FROM remoteSecure(
'****.europe-west4.gcp.clickhouse.cloud',
default.pp_complete,
'{username}',
'{password}'
) AS remote
JOIN (
SELECT
toYear(date) AS year,
sum(houses_sold)*1000 AS housesSold
FROM file('/Users/datasci/Desktop/housing_in_london_monthly_variables.csv')
WHERE area = 'city of london' AND houses_sold IS NOT NULL
GROUP BY toYear(date)
ORDER BY year
) AS local ON local.year = remote.year
WHERE town = 'LONDON'
GROUP BY toYear(date)
ORDER BY year;
"""
尽管我们缺少 2020 年之后的数据,但仍然可以针对 1995 至 2019 年,对这两个数据集进行对比绘图。
在一个新的单元格中运行以下命令:
# Create a figure with two y-axes
fig, ax1 = plt.subplots(figsize=(14, 8))
# Plot houses sold on the left y-axis
color = 'tab:blue'
ax1.set_xlabel('Year')
ax1.set_ylabel('Houses Sold', color=color)
ax1.plot(df_2['year'], df_2['houses_sold'], marker='o', color=color, label='Houses Sold', linewidth=2)
ax1.tick_params(axis='y', labelcolor=color)
ax1.grid(True, alpha=0.3)
# Create a second y-axis for price data
ax2 = ax1.twinx()
color = 'tab:red'
ax2.set_ylabel('Average Price (£)', color=color)
# Plot price data up until 2019
ax2.plot(df[df['year'] <= 2019]['year'], df[df['year'] <= 2019]['avg_price'], marker='s', color=color, label='Average Price', linewidth=2)
ax2.tick_params(axis='y', labelcolor=color)
# Format price axis with currency formatting
ax2.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, p: f'£{x:,.0f}'))
# Set title and show every 2nd year
plt.title('London Housing Market: Sales Volume vs Prices Over Time', fontsize=14, pad=20)
# Use years only up to 2019 for both datasets
all_years = sorted(list(set(df_2[df_2['year'] <= 2019]['year']).union(set(df[df['year'] <= 2019]['year']))))
years_to_show = all_years[::2] # Every 2nd year
ax1.set_xticks(years_to_show)
ax1.set_xticklabels(years_to_show, rotation=45)
# Add legends
ax1.legend(loc='upper left')
ax2.legend(loc='upper right')
plt.tight_layout()
plt.show()
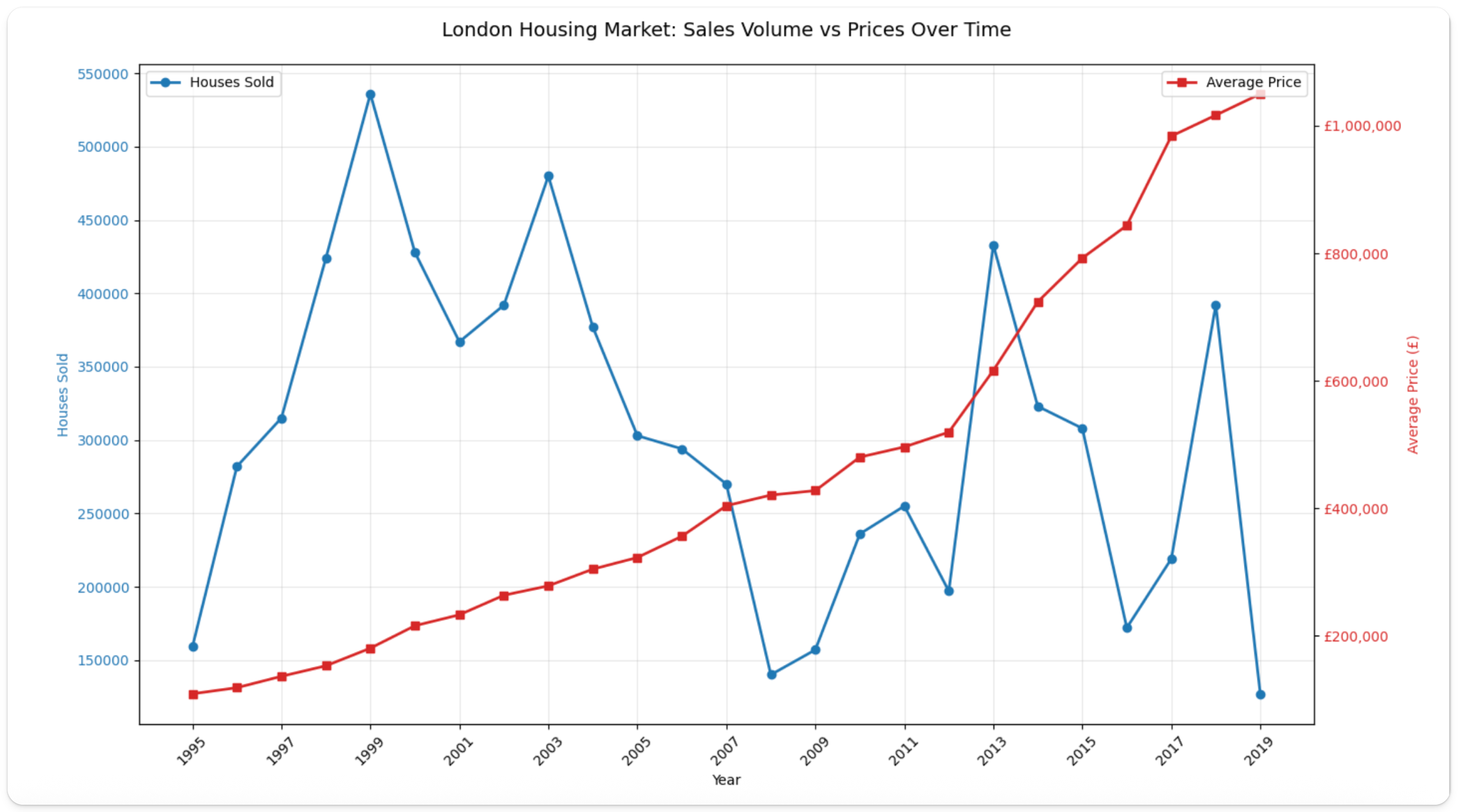
从图中可以看到,1995 年的销售量约为 160,000,随后迅速攀升,并在 1999 年达到约 540,000 的峰值。
此后,销量在 2000 年代中期急剧下滑,在 2007–2008 年金融危机期间大幅下跌,降至约 140,000。
另一方面,价格则从 1995 年约 £150,000 起,持续、稳定增长,到 2005 年达到约 £300,000。
2012 年之后增速显著加快,从约 £400,000 急剧上升,到 2019 年超过 £1,000,000。
与销售量不同,价格几乎未受到 2008 年危机的影响,并一直保持上升趋势。真是惊人!
本指南演示了如何通过 chDB 将 ClickHouse Cloud 与本地数据源连接起来,在 Jupyter Notebook 中实现无缝的数据探索。
借助英国房产价格数据集,我们展示了如何使用 remoteSecure() 函数查询远程 ClickHouse Cloud 数据,使用 file() 表引擎读取本地 CSV 文件,并将结果直接转换为 Pandas DataFrame 以便进行分析和可视化。
通过 chDB,数据科学家可以在使用熟悉的 Python 工具(如 Pandas 和 matplotlib)的同时,利用 ClickHouse 强大的 SQL 能力,从而轻松整合多种数据源进行全面分析。
尽管许多在伦敦工作的数据科学家短期内可能仍然买不起自己的房子或公寓,但至少他们还能分析一下那个把自己挤出市场的房市!