表分片和副本
本主题不适用于 ClickHouse Cloud:在 ClickHouse Cloud 中,Parallel Replicas 的作用类似于传统无共享架构 ClickHouse 集群中的多个分片,而对象存储则替代副本,以确保高可用性和容错能力。
ClickHouse 中的表分片是什么?
在传统的 无共享 (shared-nothing) ClickHouse 集群中,当满足以下两种情况之一时会采用分片:① 数据量对单个服务器来说过大,② 单个服务器处理数据过慢。下图展示的是情形 ①: uk_price_paid_simple 表的数据量超过了单机的容量:
在这种情况下,可以将数据以表分片的形式拆分到多个 ClickHouse 服务器上:
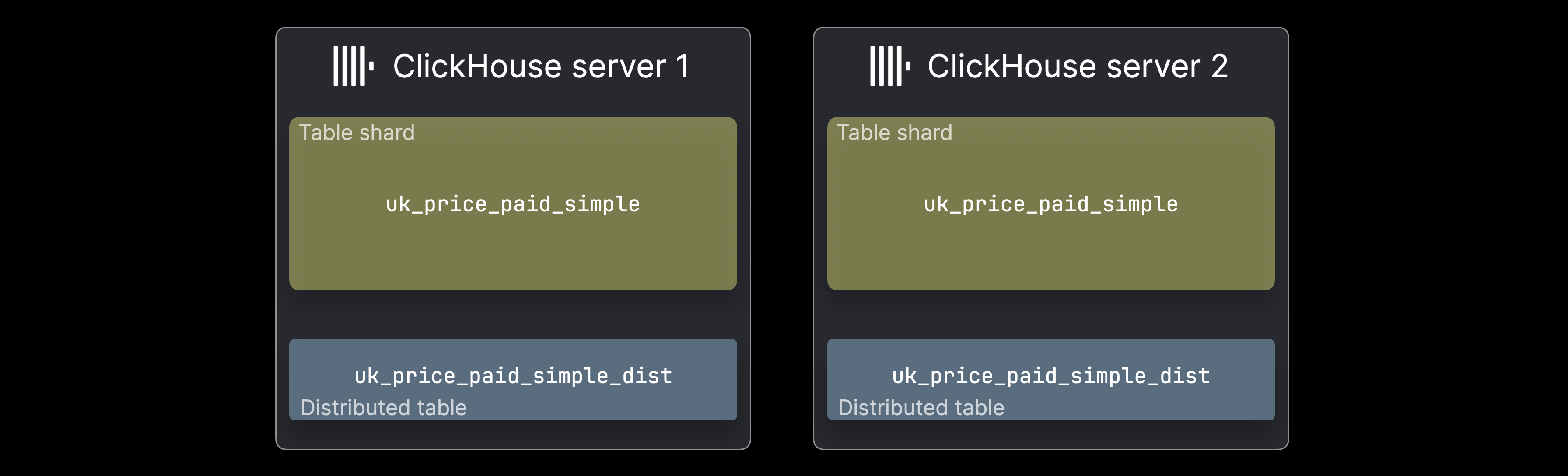
每个分片 (shard) 持有数据的一个子集,并作为一个常规的 ClickHouse 表,可以被独立查询。不过,此类查询只会处理该子集;根据数据分布情况,这在某些场景下是可以接受的。通常,会使用一个分布式表 (通常每台服务器一个) 来提供整个数据集的统一视图。分布式表本身不存储数据,而是将 SELECT 查询转发到所有分片,汇总结果,并将 INSERT 请求路由到各分片以实现数据的均匀分布。
Distributed 表创建
为了演示 SELECT 查询转发和 INSERT 路由,我们以上文 What are table parts 中的示例表为例,该表被拆分为位于两台 ClickHouse 服务器上的两个分片。首先,我们给出在此基础上创建相应 Distributed 表 的 DDL 语句:
ON CLUSTER 子句会将该 DDL 语句变为分布式 DDL 语句,并指示 ClickHouse 在 test_cluster 的集群定义中列出的所有服务器上创建该表。分布式 DDL 需要在集群架构中额外部署一个 Keeper 组件。
对于Distributed 引擎的参数,我们需要指定集群名称 (test_cluster) 、分片目标表所在的数据库名 (uk) 、分片目标表的名称 (uk_price_paid_simple) ,以及用于 INSERT 路由的 分片键 (sharding key) 。在本示例中,我们使用 rand 函数将行随机分配到各个分片。不过,依据具体使用场景,任何表达式——即使是复杂表达式——都可以用作分片键。下一节将演示 INSERT 路由的工作方式。
INSERT 路由
下图展示了在 ClickHouse 中,针对分布式表执行 INSERT 时的处理过程:
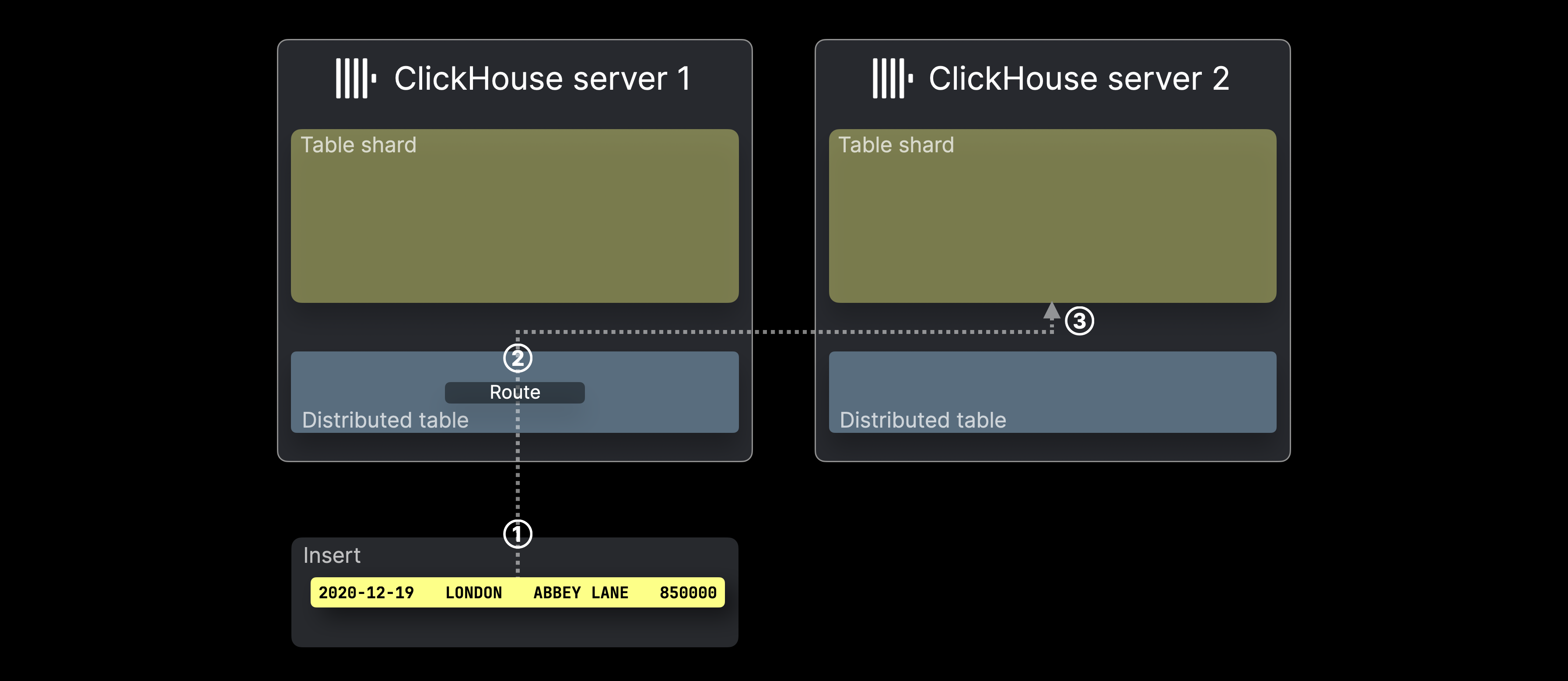
① 一条针对分布式表的 INSERT(本例中仅包含一行)会被发送到承载该表的 ClickHouse 服务器,可以直接发送,也可以通过负载均衡器转发。
② 对于 INSERT 中的每一行(本例中只有一行),ClickHouse 会计算分片键(此处为 rand()),将结果对分片服务器的数量取模,并将其作为目标服务器 ID(ID 从 0 开始,依次递增)。然后,该行会被转发,并在对应服务器的表分片中 ③ 插入。
下一节将说明 SELECT 转发的工作方式。
SELECT 转发
下图展示了在 ClickHouse 中使用分布式表处理 SELECT 查询的过程:
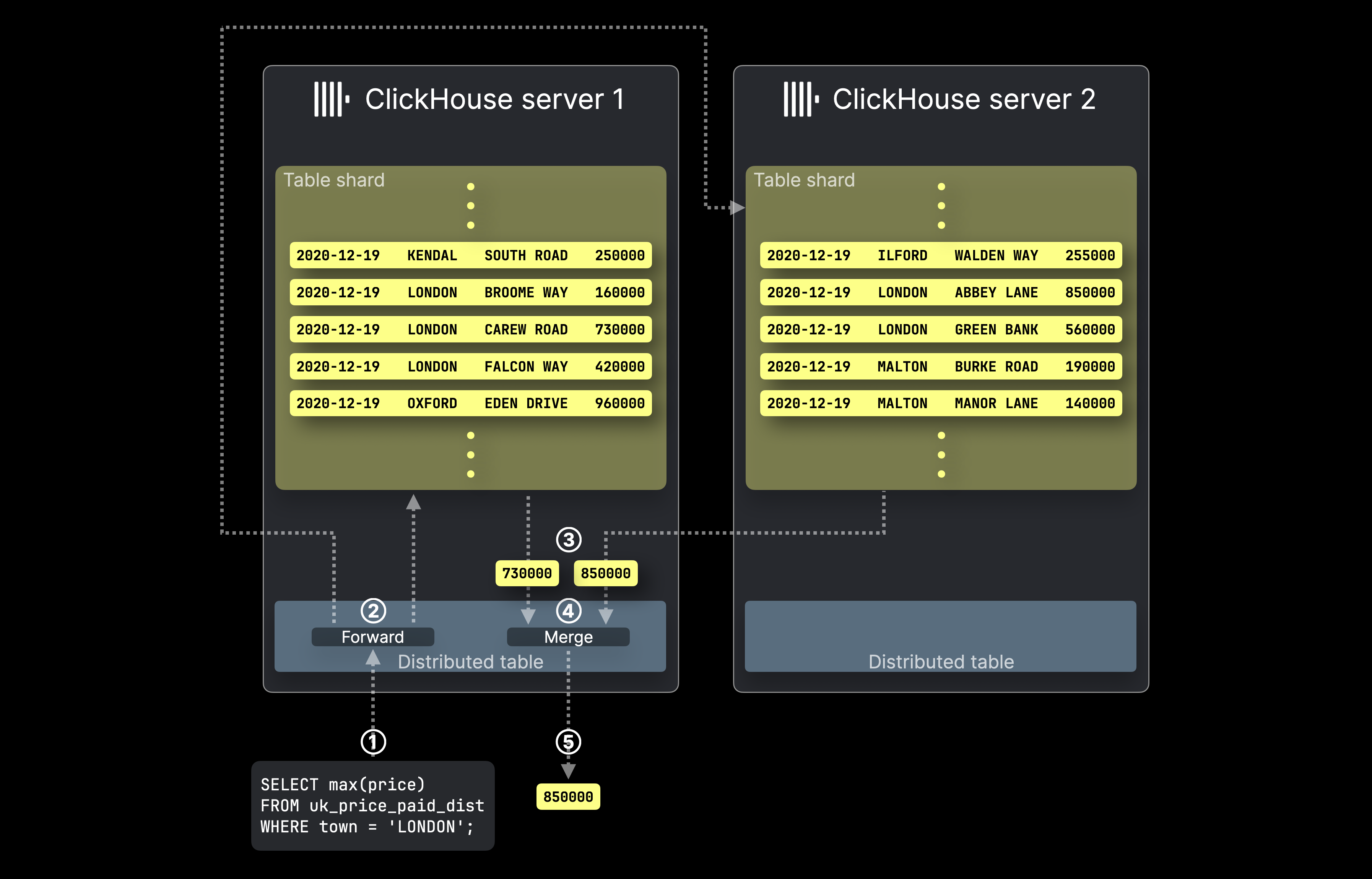
① 针对分布式表的 SELECT 聚合查询会被发送到相应的 ClickHouse 服务器,可以直接发送,也可以通过负载均衡器转发。
② Distributed 表会将查询转发到所有承载目标表分片的服务器,在这些服务器上,每个 ClickHouse 服务器都会并行计算其本地聚合结果。
然后,最初接收到该查询并承载目标分布式表的 ClickHouse 服务器会 ③ 收集所有本地结果,④ 将其合并为最终的全局结果,并在 ⑤ 将其返回给查询发起方。
ClickHouse 中的表副本是什么?
ClickHouse 中的复制通过在多台服务器上维护分片数据的副本来确保数据完整性和故障切换。由于硬件故障不可避免,复制通过确保每个分片都有多个副本来防止数据丢失。写入可以发送到任意副本,既可以直接发送,也可以通过分布式表发送,由后者为该操作选择一个副本。更改会自动传播到其他副本。在发生故障或维护时,数据仍可通过其他副本访问;一旦故障主机恢复,它会自动同步以保持最新状态。
下图展示了一个由六台服务器组成的 ClickHouse 集群,其中前文介绍的两个表分片 Shard-1 和 Shard-2 各自都有三个副本。一个查询被发送到该集群:
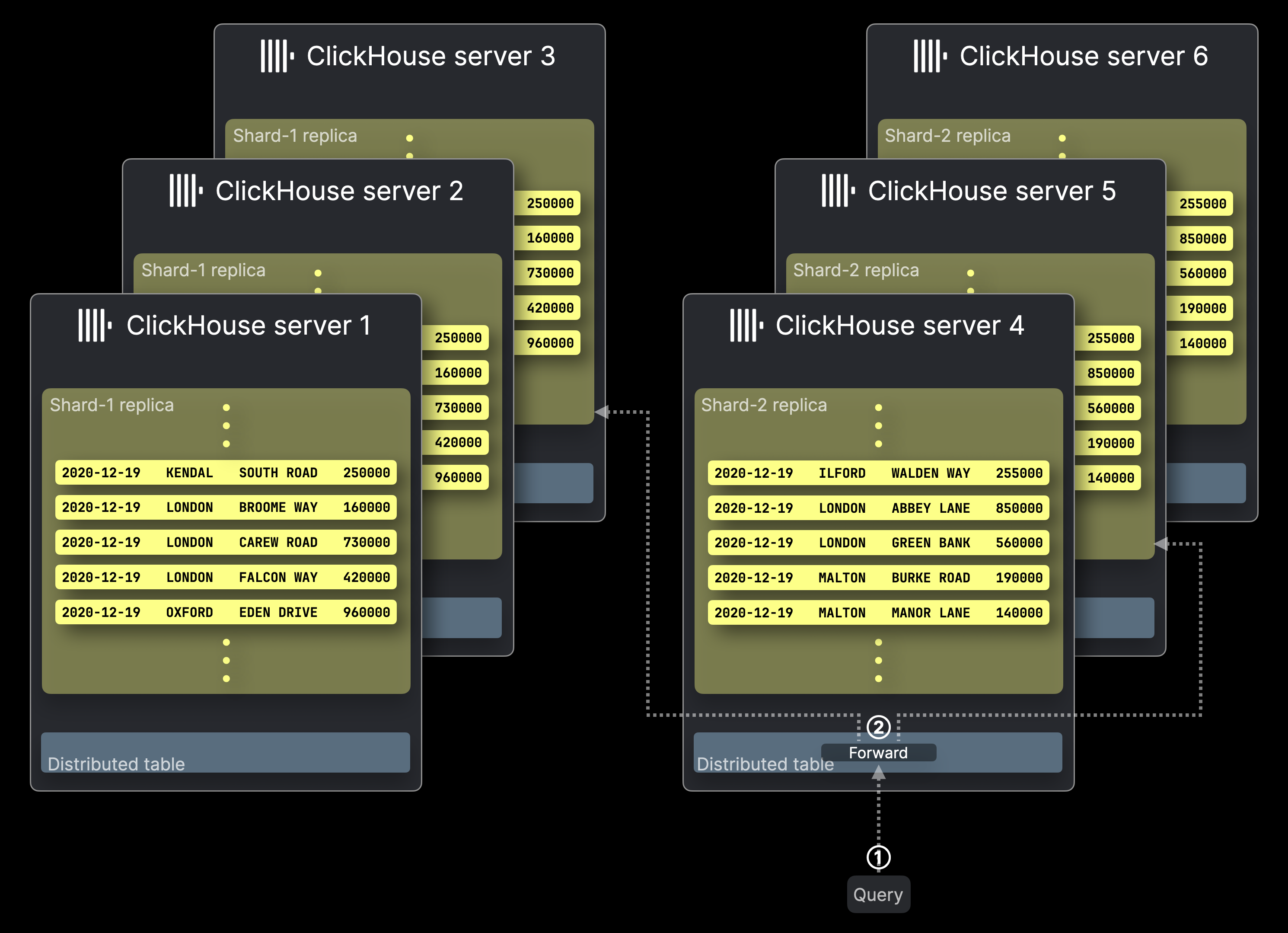
查询处理方式与没有副本的配置类似,只不过每个分片中只有一个副本会执行查询。
副本不仅能确保数据完整性和故障切换,还能让多个查询在不同副本上并行运行,从而提升查询处理吞吐量。
① 一个以分布式表为目标的查询会被发送到相应的 ClickHouse 服务器,可以直接发送,也可以通过负载均衡器发送。
② Distributed 表会将查询转发到每个分片中的一个副本,承载所选副本的每台 ClickHouse 服务器会并行计算其本地查询结果。
其余流程与无副本配置中的相同,因此未在上图中显示。最初接收到该分布式表查询的 ClickHouse 服务器会收集所有本地结果,将其合并为最终的全局结果,并将其返回给查询发送方。
请注意,ClickHouse 允许为 ② 配置查询转发策略。默认情况下——与上图不同——分布式表会在可用时优先选择本地副本,但也可以使用其他负载均衡策略。
在哪里可以了解更多信息
若想了解超出本篇高层次介绍范围的表分片和副本相关的更多细节,请查阅我们的部署与横向扩展指南。
我们也强烈推荐观看这段教程视频,以更深入地了解 ClickHouse 的分片和副本:
