ClickHouse 如何并行执行查询
ClickHouse 为速度而生。它以高度并行的方式执行查询,利用所有可用的 CPU 核心,将数据分布到各个处理通道,并且经常将硬件推至其性能极限。
本指南将介绍 ClickHouse 中查询并行机制的工作原理,以及如何对其进行调优或监控,以提升大规模工作负载下的性能。
我们使用 uk_price_paid_simple 数据集上的一个聚合查询来说明关键概念。
分步解析:ClickHouse 如何并行化聚合查询
当 ClickHouse ① 在带有表主键过滤条件的情况下运行聚合查询时,它会 ② 将主索引加载到内存中,以 ③ 确定哪些 granule(数据粒度单元)需要被处理、哪些可以安全跳过:
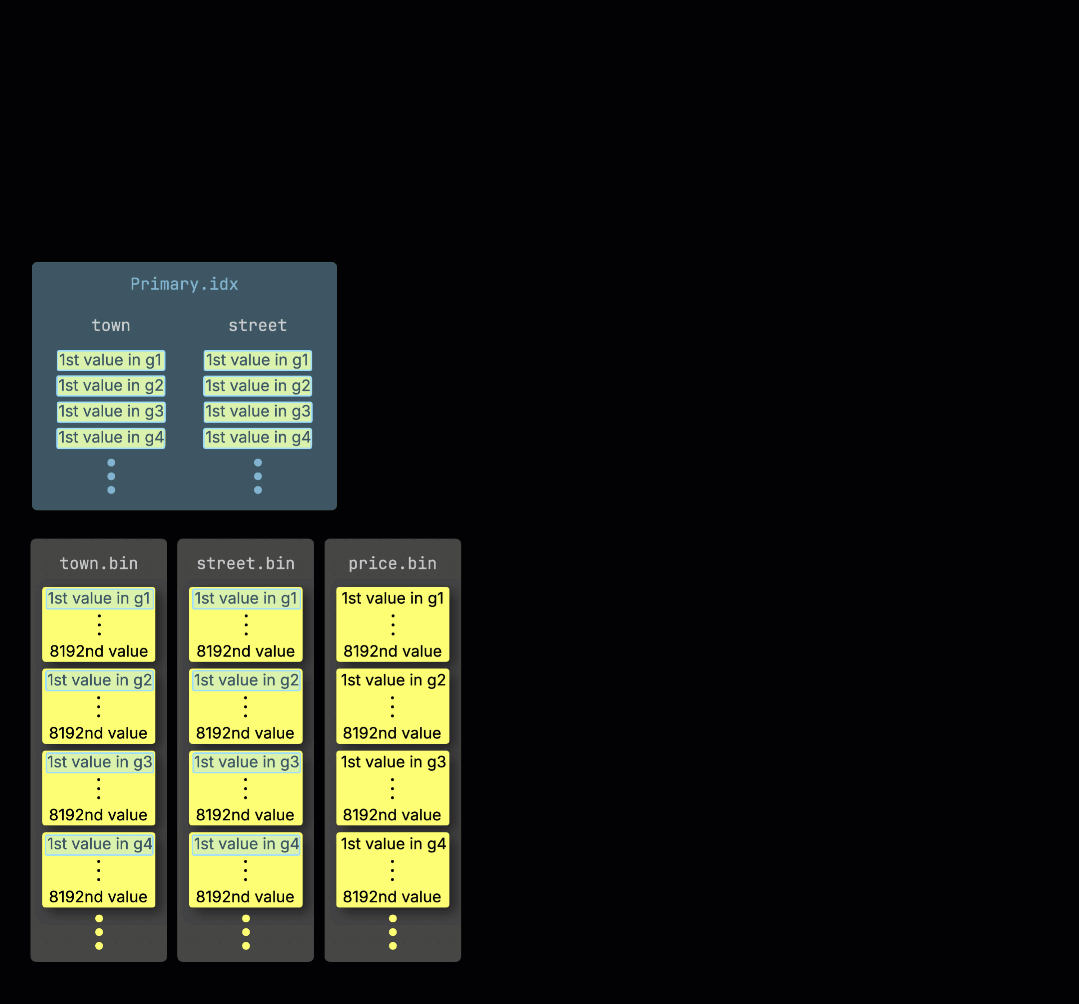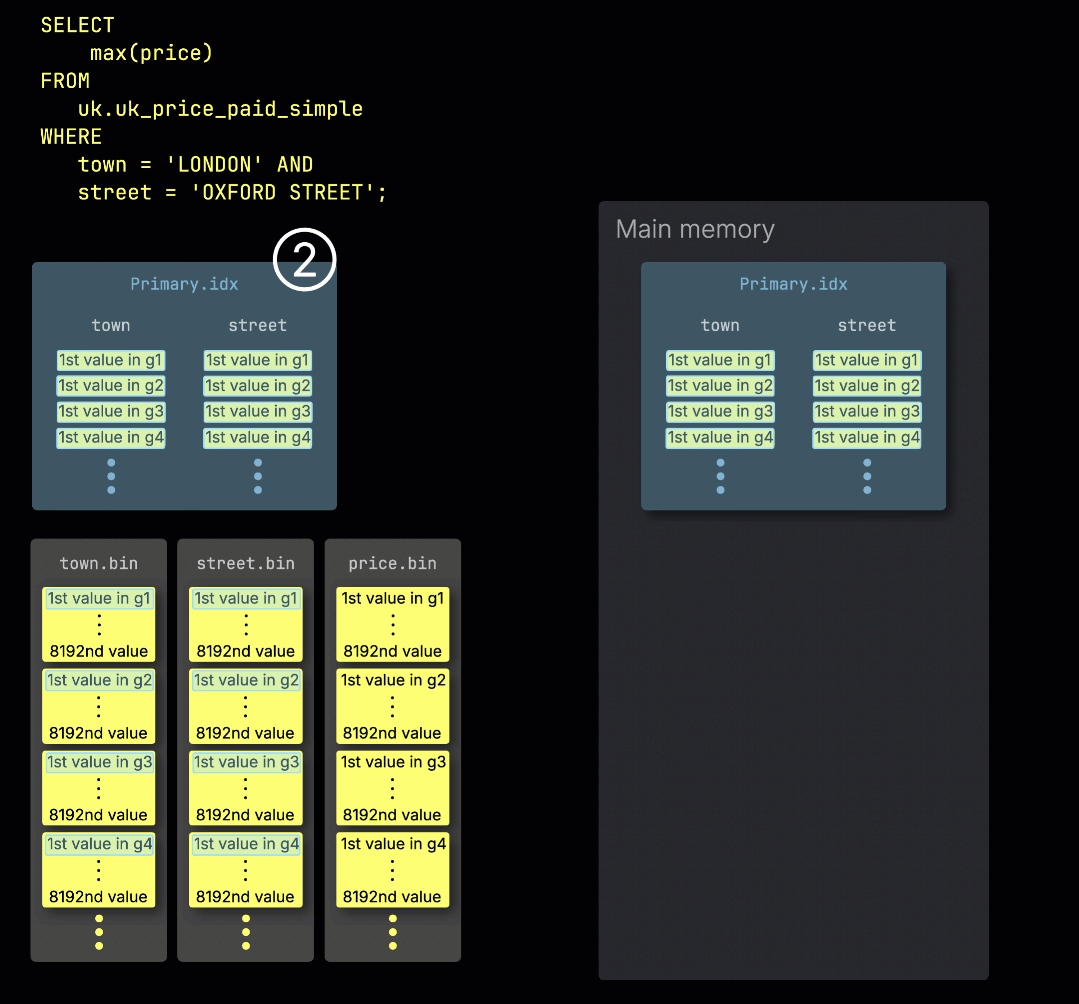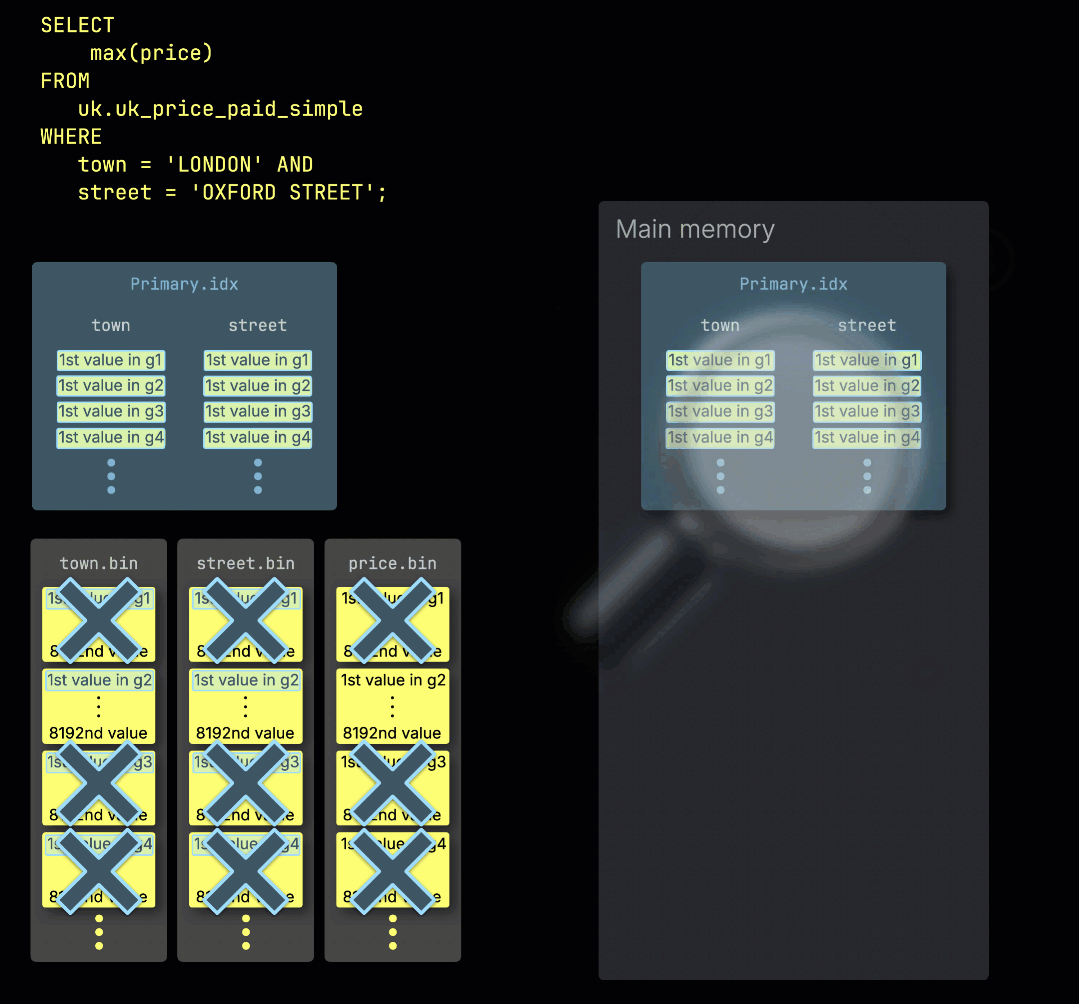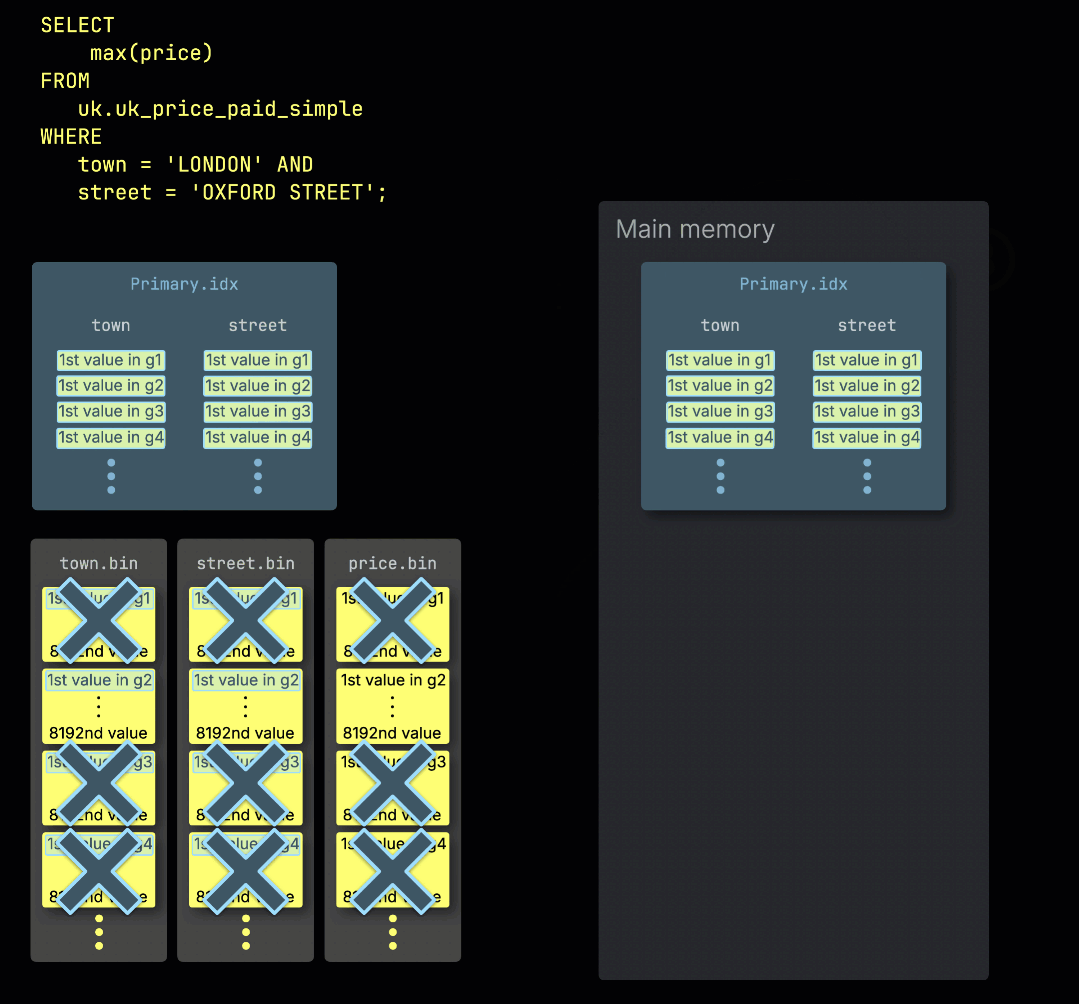
在处理通道之间分配工作
选定的数据随后被动态分布到 n 个并行的处理通道中,这些通道按数据块以流式方式逐块处理并计算数据,最终生成结果:
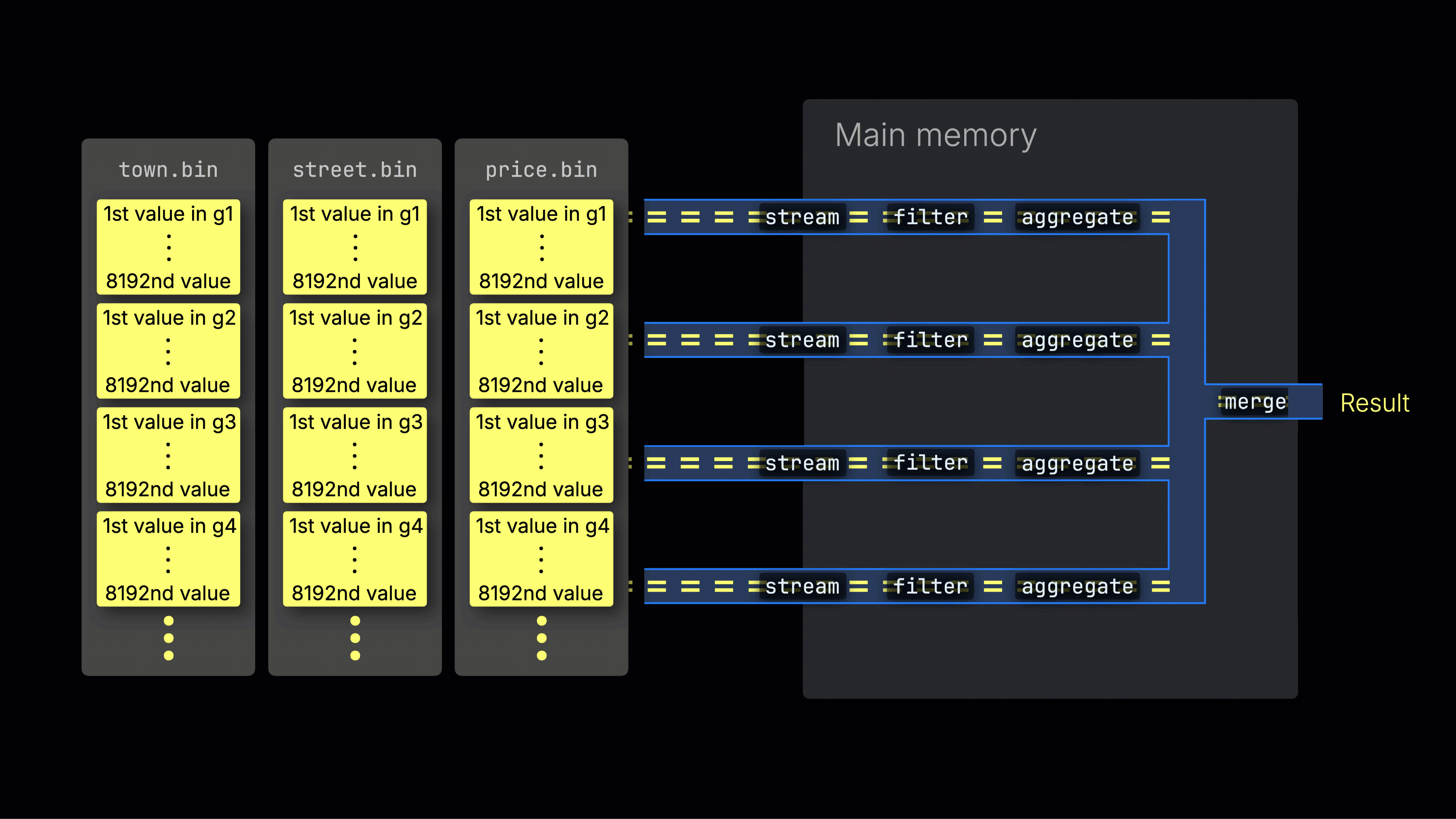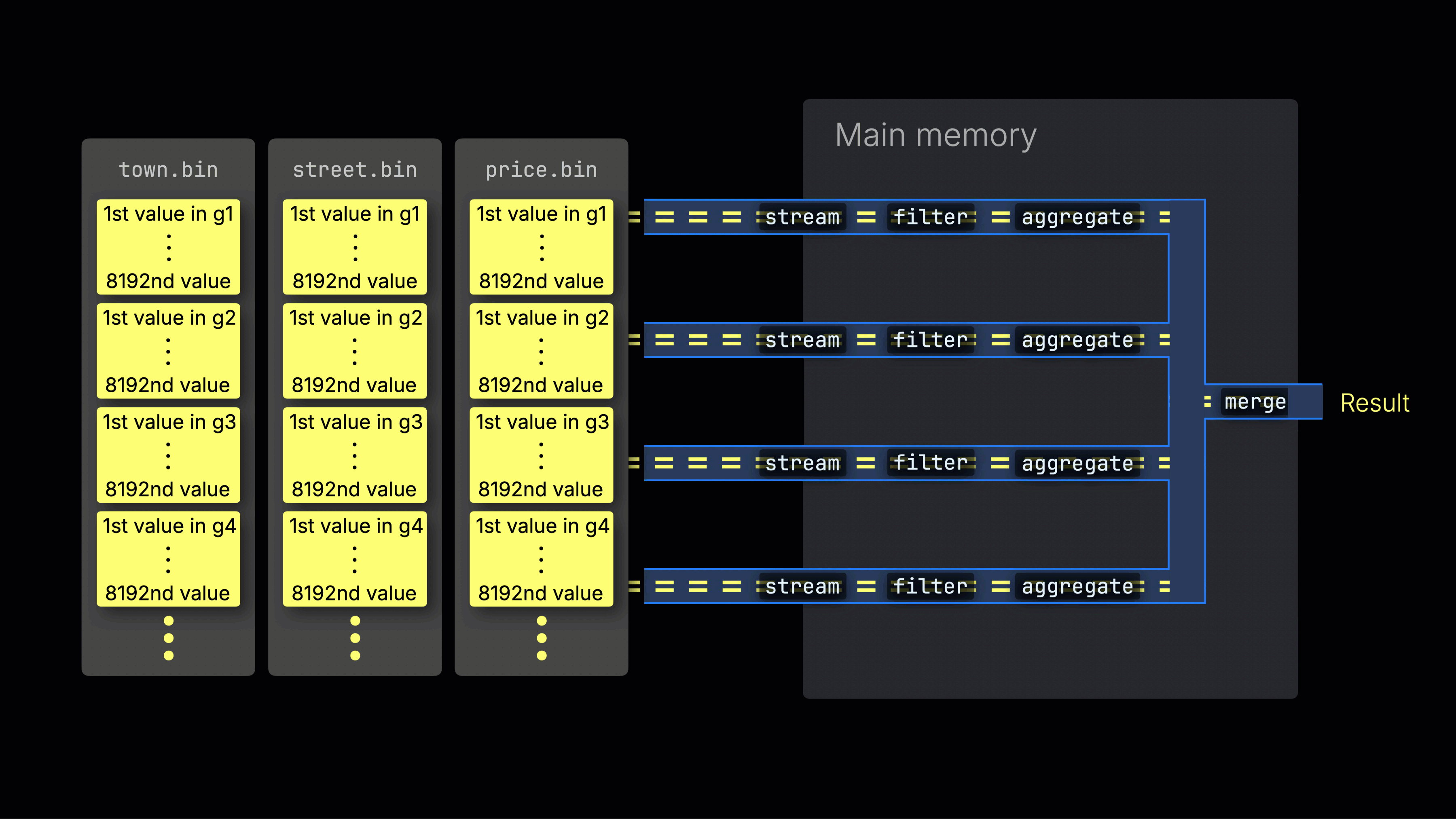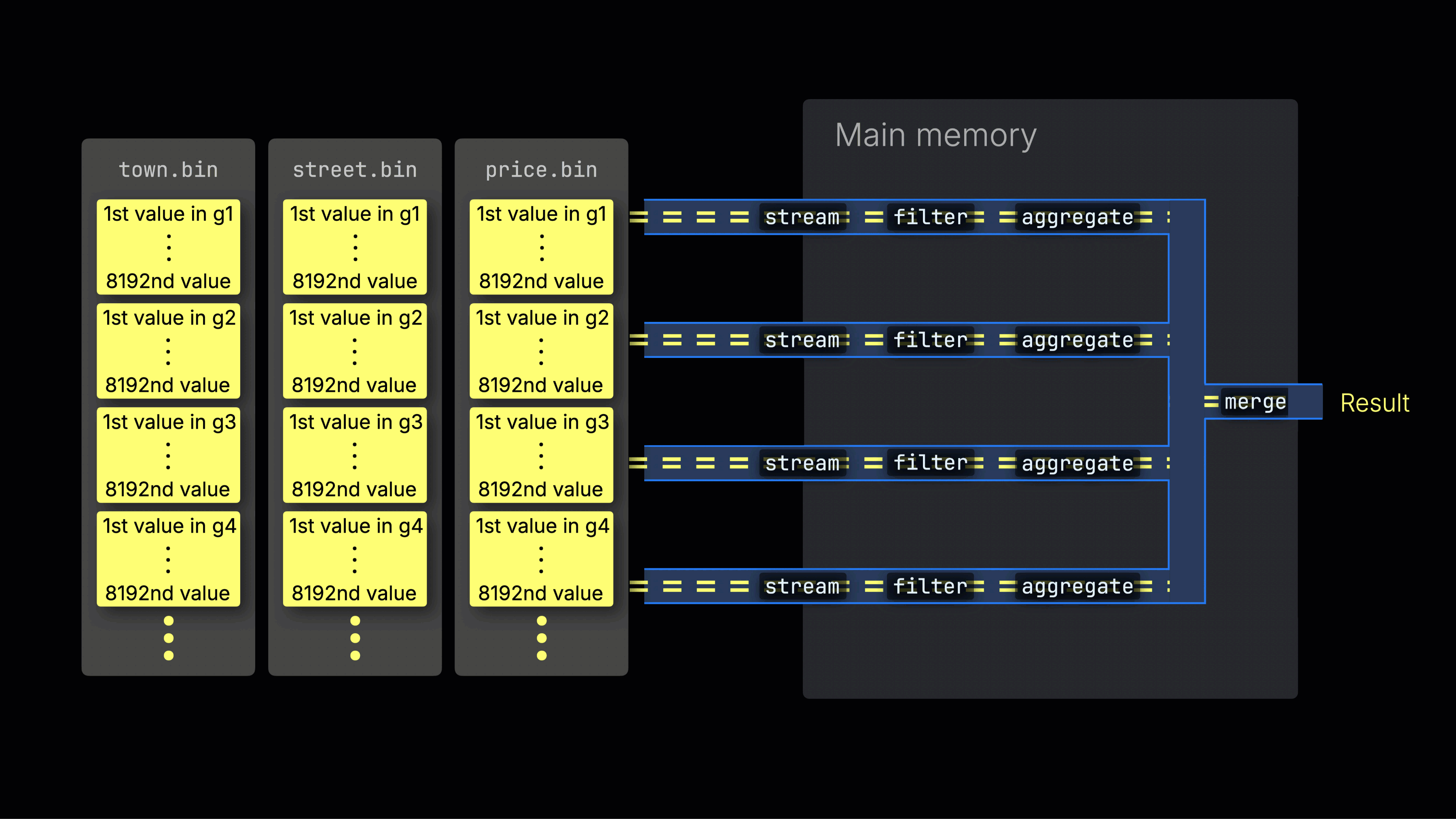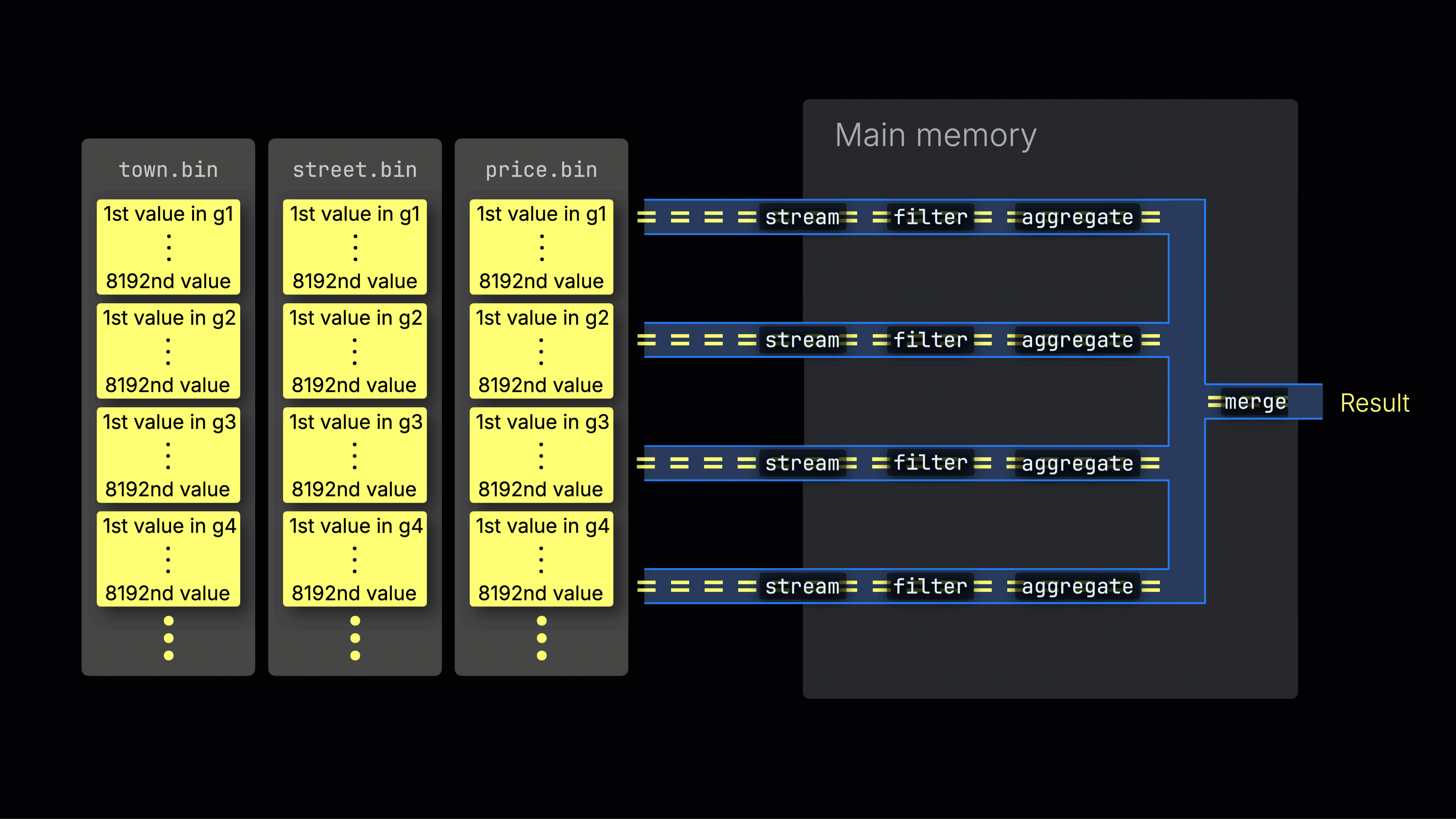
n 个并行处理通道的数量由 max_threads 设置控制,默认情况下与服务器上 ClickHouse 可用的单个 CPU 的核心(线程)数量相匹配。在上面的示例中,我们假设有 4 个核心。
在一台具有 8 个核心的机器上,查询处理吞吐量大致会提升一倍(但内存使用也会相应增加),因为会有更多通道并行处理数据:
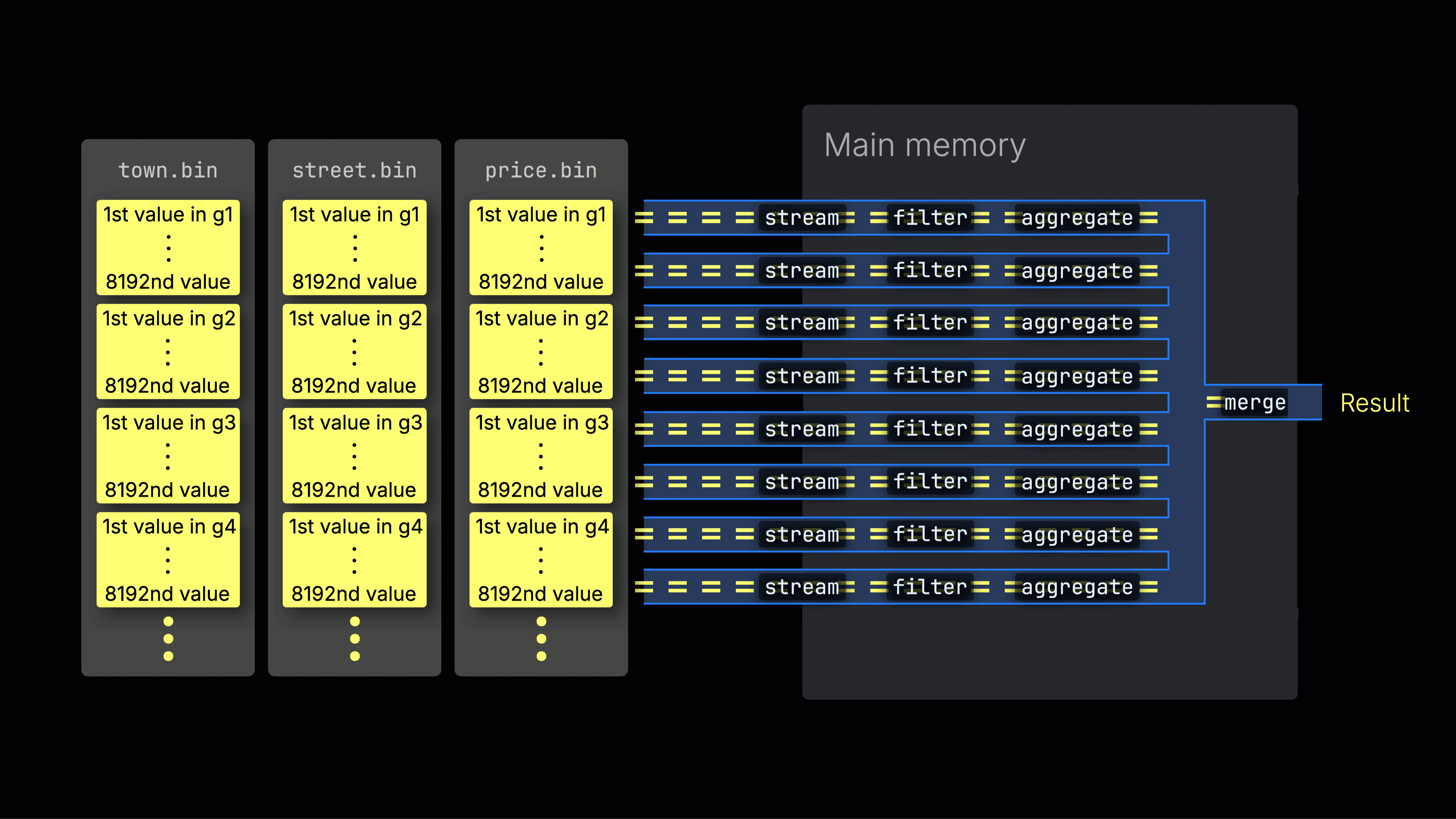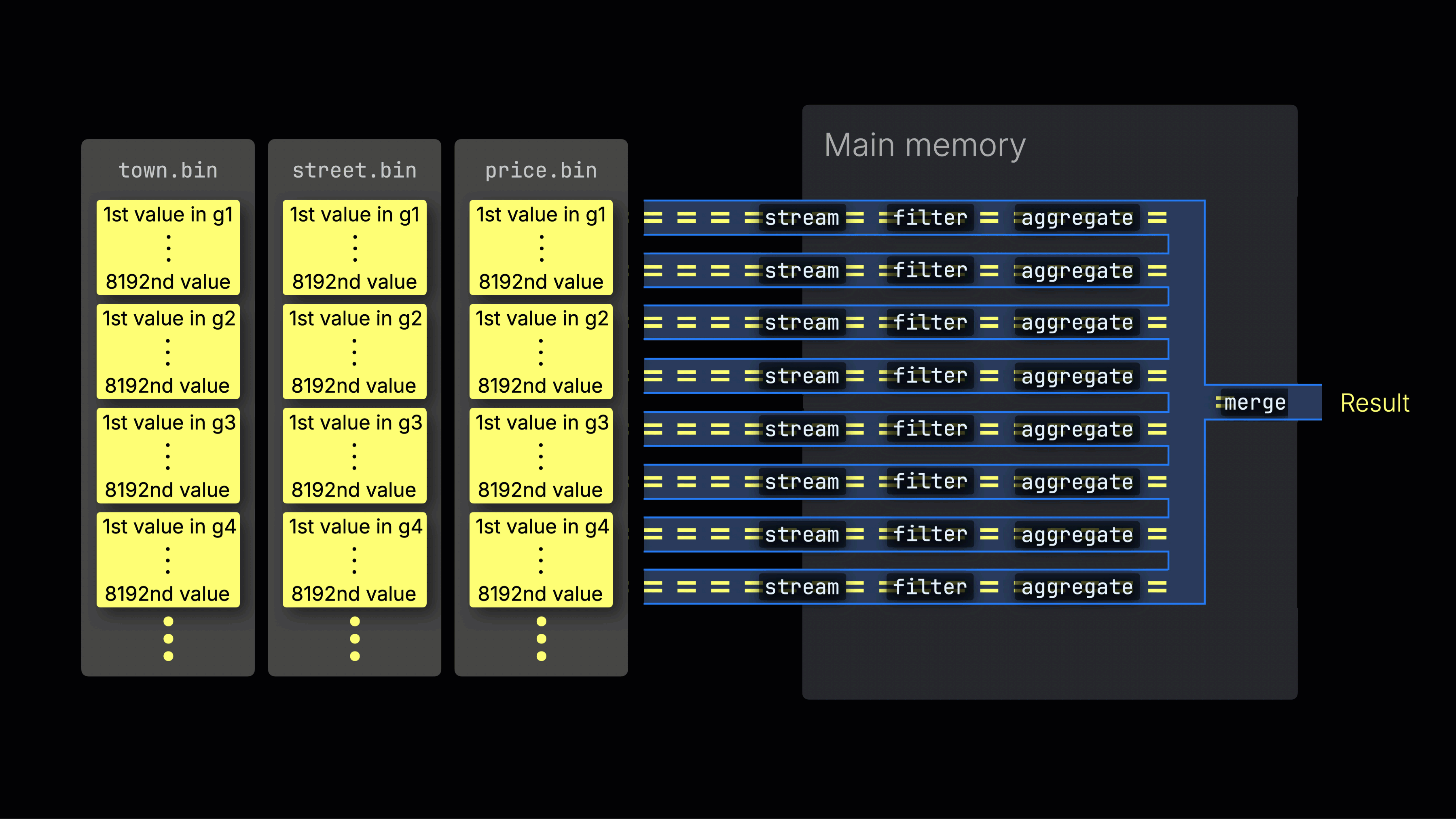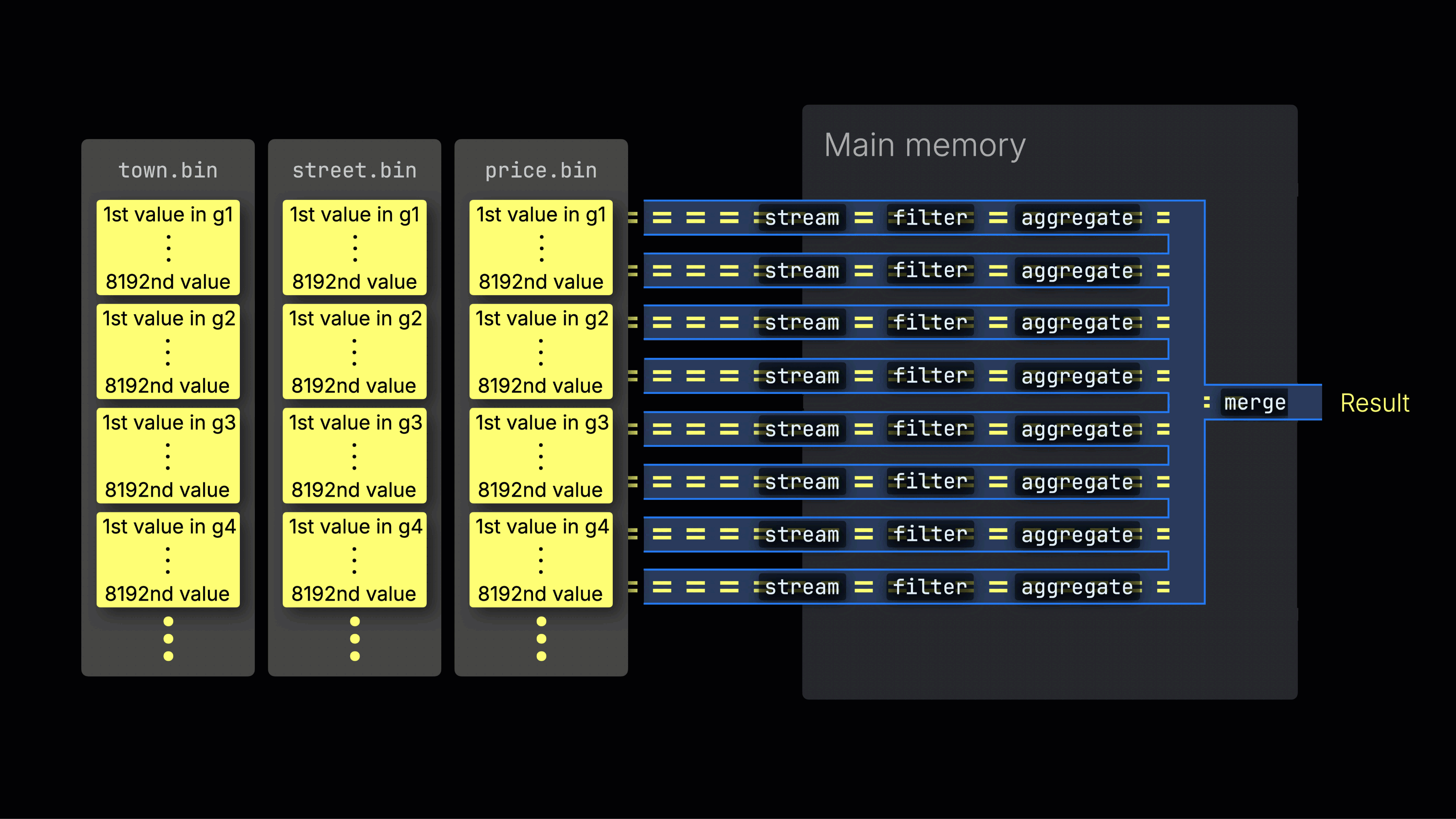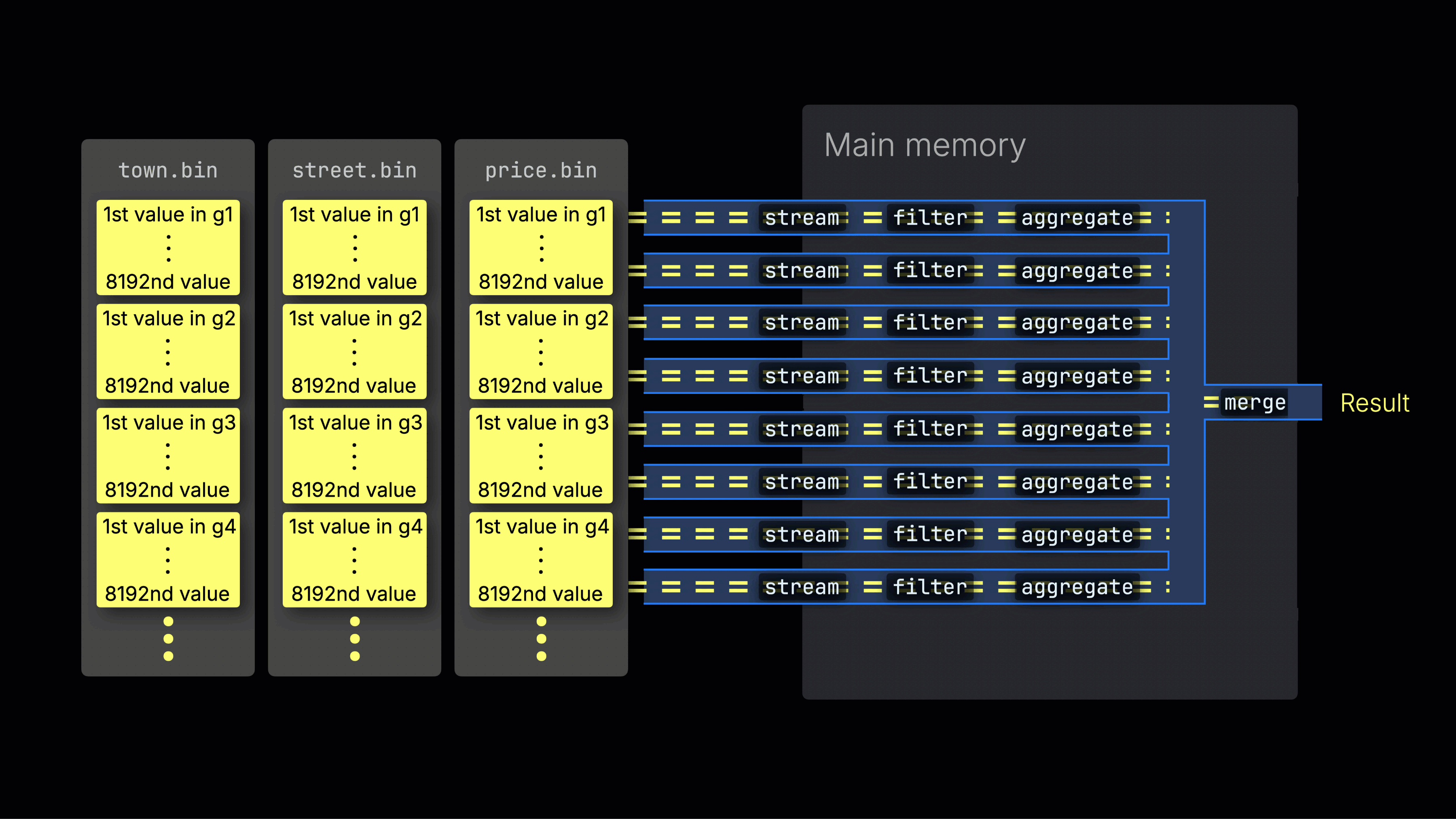
高效的通道分配是最大化 CPU 利用率并缩短整体查询时间的关键。
在分片表上处理查询
当表数据以分片的形式分布在多台服务器上时,每台服务器都会并行处理自己的分片。在每台服务器内部,本地数据会通过并行处理通道进行处理,就像前文所描述的那样:
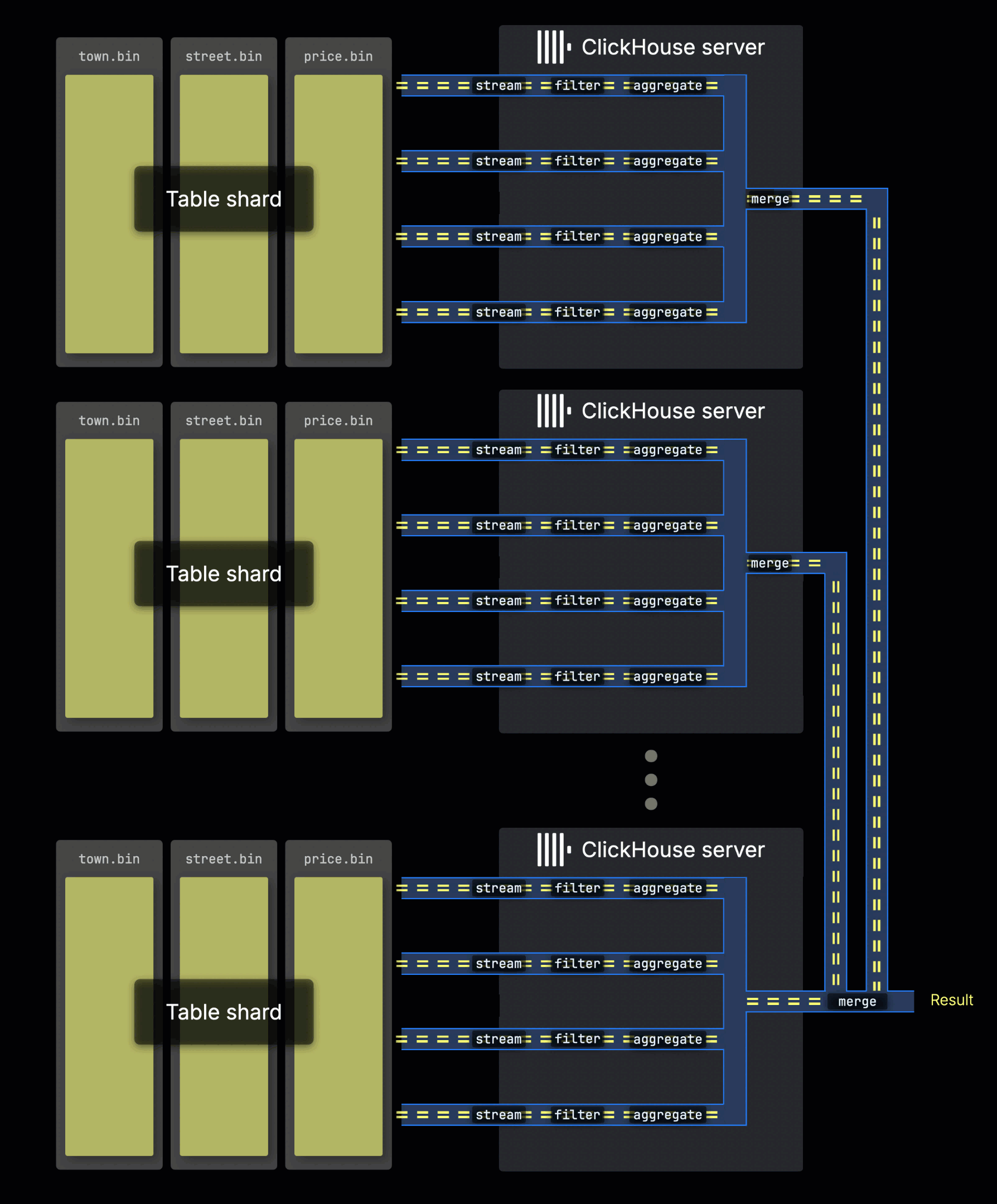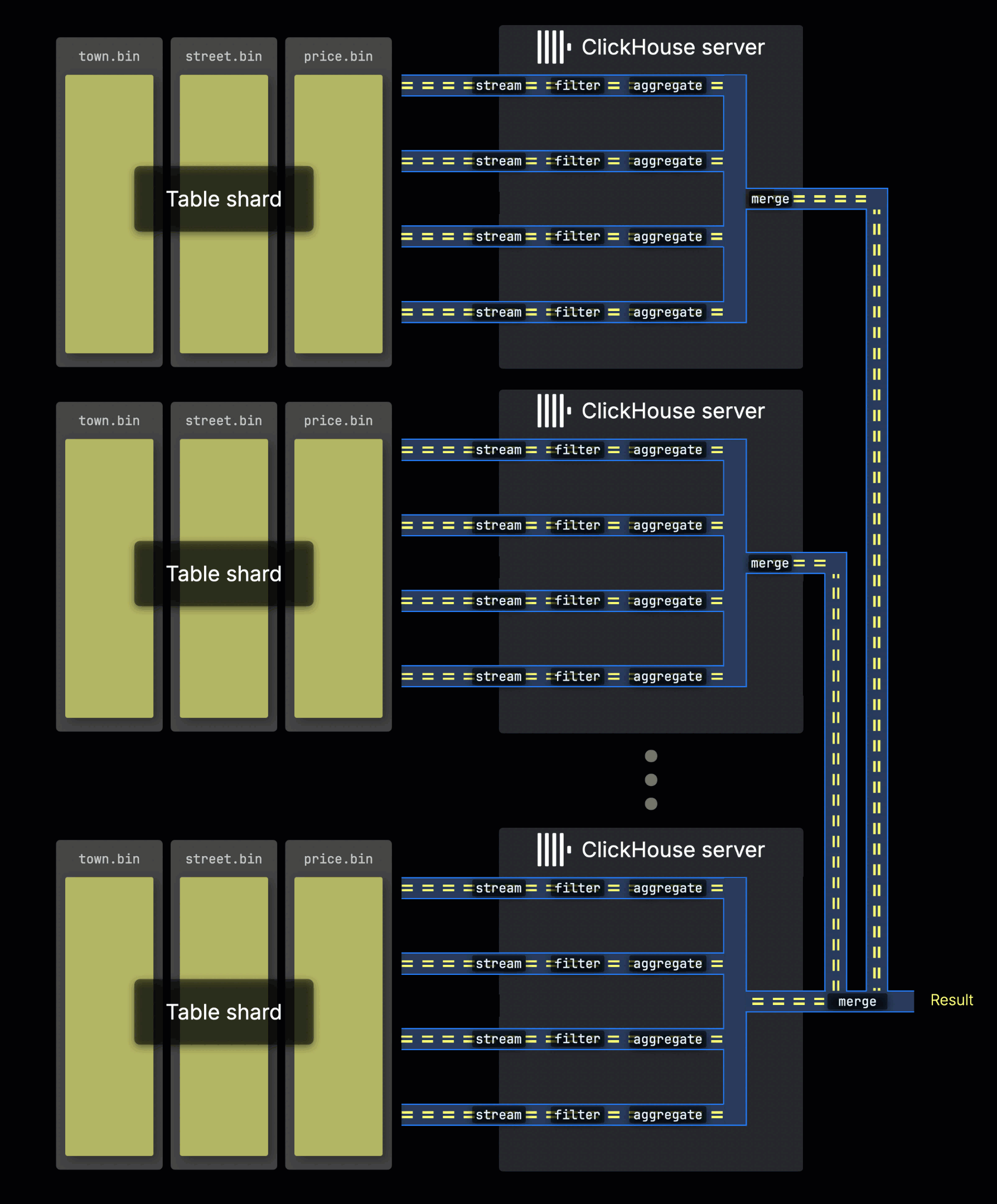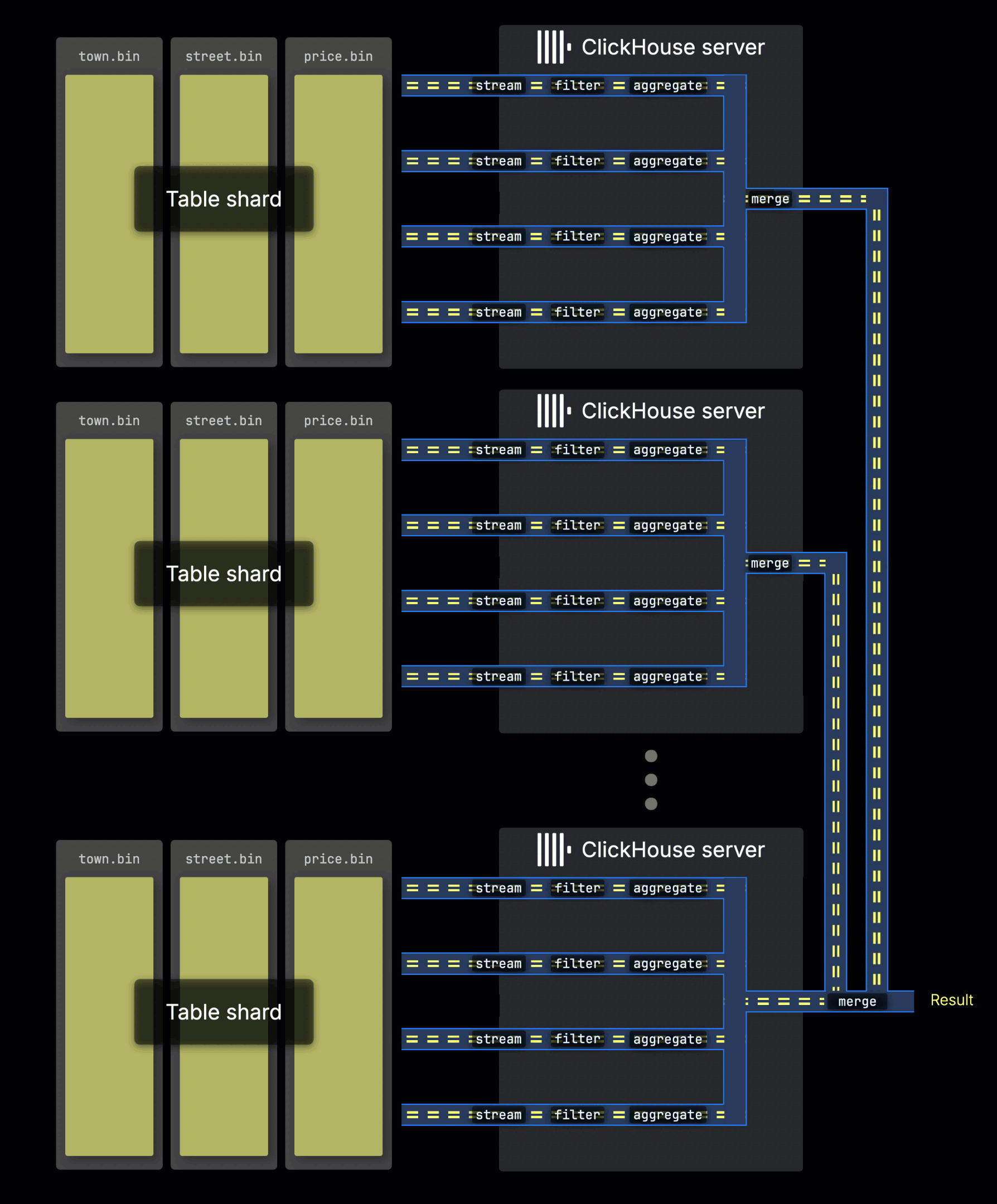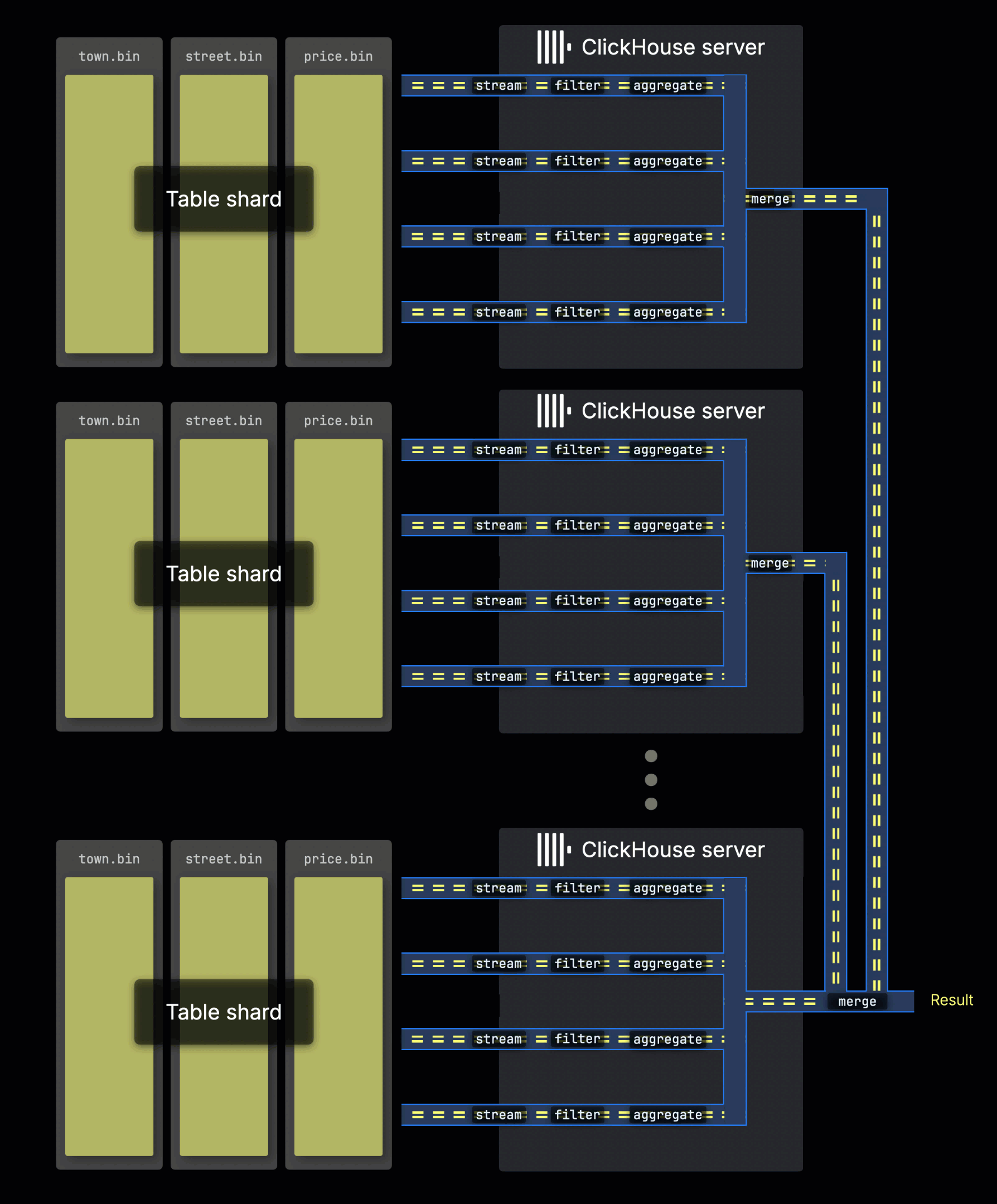
最先接收到查询的那台服务器会收集来自各个分片的所有子结果,并将它们合并为最终的全局结果。
将查询负载分布到多个分片上,可以实现并行度的横向扩展,尤其适用于高吞吐量环境。
在 ClickHouse Cloud 中,同样的并行能力是通过并行副本实现的,其工作方式类似于共享无关集群中的分片。每个 ClickHouse Cloud 副本(无状态计算节点)都会并行处理一部分数据,并像独立分片一样对最终结果作出贡献。
监控查询并行度
使用这些工具来验证你的查询是否充分利用了可用的 CPU 资源,并在没有充分利用时进行诊断。
我们在一台具有 59 核 CPU 的测试服务器上运行这项测试,这使得 ClickHouse 能够充分展示其查询并行能力。
为了观察示例查询是如何执行的,我们可以指示 ClickHouse 服务器在聚合查询期间返回所有 trace 级别的日志条目。为了便于演示,我们移除了查询的谓词——否则只会处理 3 个 granule,这些数据不足以让 ClickHouse 利用多条并行处理通道:
我们可以看到:
- ① ClickHouse 需要在 3 个数据范围中读取 3,609 个 granule(在 trace 日志中以 mark 表示)。
- ② 在具有 59 个 CPU 核心的情况下,它会将这项工作分配到 59 个并行处理流中——每条“通道”一个。
或者,我们可以使用 EXPLAIN 子句来检查该聚合查询的 physical operator plan,也称为“query pipeline”:
注意:请自下而上阅读上面的算子计划。每一行代表物理执行计划中的一个阶段,从最底部的从存储读取数据开始,到最顶部的最终处理步骤结束。标记为 × 59 的算子会在 59 条并行处理通道上,并发地作用于互不重叠的数据区域。这反映了 max_threads 的取值,并展示了查询的每个阶段是如何在 CPU 核心之间并行化的。
ClickHouse 的内嵌 Web UI(在 /play 端点可用)可以将上面的物理计划渲染为图形化展示。在本例中,我们将 max_threads 设置为 4 以保持可视化紧凑,只展示 4 条并行处理通道:

注意:请从左到右阅读该可视化。每一行代表一条并行处理通道,它以数据块为单位进行流式处理,并应用过滤、聚合以及最终处理阶段等转换。在本例中,你可以看到与 max_threads = 4 设置对应的四条并行通道。
在处理通道之间进行负载均衡
请注意,物理计划中的 Resize 算子会重新分区并重新分发数据块流到各个处理通道,以保持它们的利用率均衡。当不同数据范围中满足查询谓词的行数相差较大时,这种再平衡尤为重要,否则某些通道可能会过载,而其他通道则处于空闲状态。通过重新分配工作量,较快的通道可以有效帮助较慢的通道,从而优化整体查询执行时间。
为什么 max_threads 并不总是被严格遵守
如上所述,n 条并行处理通道的数量由 max_threads 参数控制,其默认值等于 ClickHouse 在该服务器上可用的 CPU 内核数量:
然而,根据所选用于处理的数据量大小,max_threads 的配置值可能会被忽略:
如上方执行计划片段所示,即使将 max_threads 设置为 59,ClickHouse 也只使用 30 条并发流来扫描数据。
现在我们来运行这个查询:
如上面的输出所示,查询处理了约 231 万行数据并读取了 13.66 MB 的数据。这是因为在索引分析阶段,ClickHouse 选择了 282 个 granule(粒度单元) 进行处理,每个 granule 包含 8,192 行,合计约 231 万行:
无论将 max_threads 配置为多少值,ClickHouse 只会在确实有足够数据值得这么做时,才分配额外的并行处理通道。max_threads 中的 “max” 表示的是上限,而不是实际一定会使用的线程数量。
这里的 “足够数据” 主要由两个设置决定,它们定义了每个处理通道应处理的最少行数(默认 163,840)和最少字节数(默认 2,097,152):
对于 shared-nothing 集群:
对于具有共享存储的集群(例如 ClickHouse Cloud):
- merge_tree_min_rows_for_concurrent_read_for_remote_filesystem
- merge_tree_min_bytes_for_concurrent_read_for_remote_filesystem
此外,还存在一个由以下设置控制的读取任务大小的硬性下限:
我们不建议在生产环境中修改这些设置。这里展示它们仅用于说明为什么 max_threads 并不总是决定实际的并行度。
出于演示目的,我们来查看在重写这些设置以强制使用最大并发时的物理计划:
现在,ClickHouse 使用 59 个并发流来扫描数据,完全遵循配置的 max_threads。
这表明,对于小数据集上的查询,ClickHouse 会有意限制并发度。仅在测试环境中临时覆盖这些设置——不要在生产环境中这样做——因为这可能导致执行效率低下或资源争用。
关键要点
- ClickHouse 使用与
max_threads绑定的处理通道来并行执行查询。 - 实际的通道数量取决于被选中用于处理的数据量大小。
- 使用
EXPLAIN PIPELINE和跟踪日志来分析通道的使用情况。
在哪里可以了解更多信息
如果你希望更深入地了解 ClickHouse 如何并行执行查询,以及它如何在大规模场景下实现高性能,可以查阅以下资源:
-
查询处理层 – VLDB 2024 论文(网页版) - 对 ClickHouse 内部执行模型的详细解析,包括调度、流水线处理以及算子设计。
-
Partial aggregation states explained - 深入剖析 partial aggregation states 如何在多个处理通道之间实现高效的并行执行。
-
一段视频教程,详细讲解 ClickHouse 查询处理的所有步骤:
