本节通过常见场景示例说明如何使用不同的性能优化技术,例如 analyzer、query profiling 或 avoid nullable Columns,从而提升 ClickHouse 查询性能。
思考性能优化的最佳时机,是在你第一次向 ClickHouse 摄取数据之前设计好数据模式时。
但老实说,很难准确预测数据会增长到什么规模,或者未来会执行哪些类型的查询。
如果你已经有一个现有部署,并且有一些想要优化的查询,那么第一步就是理解这些查询当前的性能表现,以及为什么有的查询只需几毫秒即可完成,而有的则需要更长时间。
ClickHouse 提供了一套丰富的工具,帮助你了解查询是如何执行的,以及在执行过程中消耗了哪些资源。
在本节中,我们将介绍这些工具以及如何使用它们。
总体考量
要理解查询性能,我们先来看一下在 ClickHouse 中执行查询时会发生什么。
下面的内容经过有意简化,并做了一些取舍;目的不是用细节淹没你,而是让你快速掌握基本概念。更多信息可以阅读查询分析器。
从一个非常宏观的角度来看,当 ClickHouse 执行查询时,会经历以下阶段:
查询会被解析和分析,并生成一个通用的查询执行计划。
对查询执行计划进行优化,剔除不必要的数据,并基于查询计划构建查询流水线(query pipeline)。
数据会被并行读取和处理。在这个阶段,ClickHouse 实际执行诸如过滤、聚合和排序等查询操作。
结果会被合并、排序并格式化为最终结果,然后发送给客户端。
在实际运行中,还会有许多优化参与其中,我们会在本指南后续部分进一步讨论。但就目前而言,这些主要概念已经足以帮助我们理解当 ClickHouse 执行查询时,幕后都在发生什么。
在有了这种宏观认识之后,我们接下来看看 ClickHouse 提供了哪些工具,以及如何使用这些工具来跟踪影响查询性能的各项指标。
数据集
我们将使用一个真实示例来说明我们是如何处理查询性能的。
这里我们使用 NYC Taxi 数据集,其中包含纽约市出租车行程数据。首先,我们在未做任何优化的情况下开始摄取 NYC Taxi 数据集。
下面是从一个 S3 存储桶创建表并插入数据的命令。请注意,我们是有意从数据中推断表结构,这样的做法并未进行优化。
-- Create table with inferred schema
CREATE TABLE trips_small_inferred
ORDER BY () EMPTY
AS SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/clickhouse-academy/nyc_taxi_2009-2010.parquet');
-- Insert data into table with inferred schema
INSERT INTO trips_small_inferred
SELECT *
FROM s3Cluster
('default','https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/clickhouse-academy/nyc_taxi_2009-2010.parquet');
让我们来看一下由数据自动推断得到的表结构。
--- Display inferred table schema
SHOW CREATE TABLE trips_small_inferred
Query id: d97361fd-c050-478e-b831-369469f0784d
CREATE TABLE nyc_taxi.trips_small_inferred
(
`vendor_id` Nullable(String),
`pickup_datetime` Nullable(DateTime64(6, 'UTC')),
`dropoff_datetime` Nullable(DateTime64(6, 'UTC')),
`passenger_count` Nullable(Int64),
`trip_distance` Nullable(Float64),
`ratecode_id` Nullable(String),
`pickup_location_id` Nullable(String),
`dropoff_location_id` Nullable(String),
`payment_type` Nullable(Int64),
`fare_amount` Nullable(Float64),
`extra` Nullable(Float64),
`mta_tax` Nullable(Float64),
`tip_amount` Nullable(Float64),
`tolls_amount` Nullable(Float64),
`total_amount` Nullable(Float64)
)
ORDER BY tuple()
找出慢查询
查询日志
默认情况下,ClickHouse 会在 查询日志 中收集并记录每条已执行查询的信息。这些数据存储在表 system.query_log 中。
对于每条已执行的查询,ClickHouse 会记录统计信息,例如查询执行时间、读取的行数,以及资源使用情况,如 CPU、内存使用情况或文件系统缓存命中次数。
因此,在排查慢查询时,查询日志是一个很好的起点。你可以轻松发现执行时间较长的查询,并查看每条查询的资源使用信息。
让我们在 NYC taxi 数据集上找出执行时间最长的前五条查询。
-- Find top 5 long running queries from nyc_taxi database in the last 1 hour
SELECT
type,
event_time,
query_duration_ms,
query,
read_rows,
tables
FROM clusterAllReplicas(default, system.query_log)
WHERE has(databases, 'nyc_taxi') AND (event_time >= (now() - toIntervalMinute(60))) AND type='QueryFinish'
ORDER BY query_duration_ms DESC
LIMIT 5
FORMAT VERTICAL
Query id: e3d48c9f-32bb-49a4-8303-080f59ed1835
Row 1:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:36
query_duration_ms: 2967
query: WITH
dateDiff('s', pickup_datetime, dropoff_datetime) as trip_time,
trip_distance / trip_time * 3600 AS speed_mph
SELECT
quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM
nyc_taxi.trips_small_inferred
WHERE
speed_mph > 30
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 2:
──────
type: QueryFinish
event_time: 2024-11-27 11:11:33
query_duration_ms: 2026
query: SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM
nyc_taxi.trips_small_inferred
WHERE
pickup_datetime >= '2009-01-01' AND pickup_datetime < '2009-04-01'
GROUP BY
payment_type
ORDER BY
trip_count DESC;
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 3:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:17
query_duration_ms: 1860
query: SELECT
avg(dateDiff('s', pickup_datetime, dropoff_datetime))
FROM nyc_taxi.trips_small_inferred
WHERE passenger_count = 1 or passenger_count = 2
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 4:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:31
query_duration_ms: 690
query: SELECT avg(total_amount) FROM nyc_taxi.trips_small_inferred WHERE trip_distance > 5
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
Row 5:
──────
type: QueryFinish
event_time: 2024-11-27 11:12:44
query_duration_ms: 634
query: SELECT
vendor_id,
avg(total_amount),
avg(trip_distance),
FROM
nyc_taxi.trips_small_inferred
GROUP BY vendor_id
ORDER BY 1 DESC
FORMAT JSON
read_rows: 329044175
tables: ['nyc_taxi.trips_small_inferred']
字段 query_duration_ms 表示该特定查询实际执行所花费的时间。查看查询日志中的结果,可以看到第一个查询运行耗时 2967ms,仍有优化空间。
你可能还希望了解哪些查询正在给系统带来压力,例如通过找出消耗内存或 CPU 最高的查询来分析。
-- Top queries by memory usage
SELECT
type,
event_time,
query_id,
formatReadableSize(memory_usage) AS memory,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')] AS userCPU,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')] AS systemCPU,
(ProfileEvents['CachedReadBufferReadFromCacheMicroseconds']) / 1000000 AS FromCacheSeconds,
(ProfileEvents['CachedReadBufferReadFromSourceMicroseconds']) / 1000000 AS FromSourceSeconds,
normalized_query_hash
FROM clusterAllReplicas(default, system.query_log)
WHERE has(databases, 'nyc_taxi') AND (type='QueryFinish') AND ((event_time >= (now() - toIntervalDay(2))) AND (event_time <= now())) AND (user NOT ILIKE '%internal%')
ORDER BY memory_usage DESC
LIMIT 30
让我们将发现的这些长时间运行查询单独拿出来,多次重新执行,以便了解其响应时间表现。
此时,为了提高结果的可复现性,务必将 enable_filesystem_cache 设置为 0 来关闭文件系统缓存。
-- Disable filesystem cache
set enable_filesystem_cache = 0;
-- Run query 1
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) as trip_time,
trip_distance / trip_time * 3600 AS speed_mph
SELECT
quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM
nyc_taxi.trips_small_inferred
WHERE
speed_mph > 30
FORMAT JSON
----
1 row in set. Elapsed: 1.699 sec. Processed 329.04 million rows, 8.88 GB (193.72 million rows/s., 5.23 GB/s.)
Peak memory usage: 440.24 MiB.
-- Run query 2
SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM
nyc_taxi.trips_small_inferred
WHERE
pickup_datetime >= '2009-01-01' AND pickup_datetime < '2009-04-01'
GROUP BY
payment_type
ORDER BY
trip_count DESC;
---
4 rows in set. Elapsed: 1.419 sec. Processed 329.04 million rows, 5.72 GB (231.86 million rows/s., 4.03 GB/s.)
Peak memory usage: 546.75 MiB.
-- Run query 3
SELECT
avg(dateDiff('s', pickup_datetime, dropoff_datetime))
FROM nyc_taxi.trips_small_inferred
WHERE passenger_count = 1 or passenger_count = 2
FORMAT JSON
---
1 row in set. Elapsed: 1.414 sec. Processed 329.04 million rows, 8.88 GB (232.63 million rows/s., 6.28 GB/s.)
Peak memory usage: 451.53 MiB.
为了便于阅读,将结果汇总在下表中。
| Name | Elapsed | Rows processed | Peak memory |
|---|
| Query 1 | 1.699 sec | 3.2904 亿 | 440.24 MiB |
| Query 2 | 1.419 sec | 3.2904 亿 | 546.75 MiB |
| Query 3 | 1.414 sec | 3.2904 亿 | 451.53 MiB |
下面我们更具体地看看这些查询分别完成了什么工作。
- Query 1 计算平均时速超过 30 英里的行程的距离分布。
- Query 2 统计每周行程的数量和平均费用。
- Query 3 计算数据集中每次行程的平均用时。
这些查询本身都没有进行非常复杂的处理,唯一的例外是第一个查询,它在每次执行时都会在查询过程中动态计算行程时间。不过,这些查询中每一个都需要超过一秒钟才能执行完成,而在 ClickHouse 的世界里,这已经是非常长的时间了。我们也可以注意到这些查询的内存使用情况:每个查询大约消耗 400 MB 内存,这已经相当可观。此外,每个查询似乎都读取了相同数量的行(即 3.2904 亿)。我们先快速确认一下这个表中到底有多少行数据。
-- Count number of rows in table
SELECT count()
FROM nyc_taxi.trips_small_inferred
Query id: 733372c5-deaf-4719-94e3-261540933b23
┌───count()─┐
1. │ 329044175 │ -- 329.04 million
└───────────┘
该表包含 3.2904 亿行数据,因此每次查询都会对该表执行一次全表扫描。
Explain 语句
现在我们有了一些长时间运行的查询,让我们来了解它们是如何执行的。为此,ClickHouse 支持 EXPLAIN 语句命令。这是一个非常有用的工具,可以提供查询执行各个阶段的详细视图,而无需实际运行查询。虽然对于非 ClickHouse 专家来说可能会感到复杂,但它仍然是深入了解查询执行方式的必备工具。
文档提供了详细的指南,介绍了 EXPLAIN 语句是什么以及如何使用它来分析查询执行。我们不再重复该指南中的内容,而是专注于几个有助于发现查询执行性能瓶颈的命令。
Explain indexes = 1
让我们从 EXPLAIN indexes = 1 开始检查查询计划。查询计划是一个树形结构,显示查询将如何执行。在其中,您可以看到查询子句的执行顺序。EXPLAIN 语句返回的查询计划可以从下往上阅读。
让我们尝试使用第一个长时间运行的查询。
EXPLAIN indexes = 1
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) AS trip_time,
(trip_distance / trip_time) * 3600 AS speed_mph
SELECT quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM nyc_taxi.trips_small_inferred
WHERE speed_mph > 30
Query id: f35c412a-edda-4089-914b-fa1622d69868
┌─explain─────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY)) │
2. │ Aggregating │
3. │ Expression (Before GROUP BY) │
4. │ Filter (WHERE) │
5. │ ReadFromMergeTree (nyc_taxi.trips_small_inferred) │
└─────────────────────────────────────────────────────┘
输出结果一目了然。查询首先从 nyc_taxi.trips_small_inferred 表中读取数据,然后应用 WHERE 子句,基于计算值对行进行过滤。过滤后的数据被准备好用于聚合,并计算分位数。最后,对结果进行排序并输出。
在这里可以注意到,没有使用主键,这很合理,因为在创建表时并未定义任何主键。因此,ClickHouse 会对该查询执行对整张表的全表扫描。
Explain Pipeline
EXPLAIN Pipeline 展示了该查询的具体执行策略。通过它可以看到,ClickHouse 实际是如何执行之前所看到的通用查询计划的。
EXPLAIN PIPELINE
WITH
dateDiff('s', pickup_datetime, dropoff_datetime) AS trip_time,
(trip_distance / trip_time) * 3600 AS speed_mph
SELECT quantiles(0.5, 0.75, 0.9, 0.99)(trip_distance)
FROM nyc_taxi.trips_small_inferred
WHERE speed_mph > 30
Query id: c7e11e7b-d970-4e35-936c-ecfc24e3b879
┌─explain─────────────────────────────────────────────────────────────────────────────┐
1. │ (Expression) │
2. │ ExpressionTransform × 59 │
3. │ (Aggregating) │
4. │ Resize 59 → 59 │
5. │ AggregatingTransform × 59 │
6. │ StrictResize 59 → 59 │
7. │ (Expression) │
8. │ ExpressionTransform × 59 │
9. │ (Filter) │
10. │ FilterTransform × 59 │
11. │ (ReadFromMergeTree) │
12. │ MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread) × 59 0 → 1 │
在这里,我们可以看到用于执行该查询的线程数量为 59 个,这表明并行度很高。这加快了查询执行速度,而在较小的机器上执行则会耗时更长。大量并行运行的线程数量也可以解释该查询为何会使用如此多的内存。
理想情况下,您应以同样的方式排查所有慢查询,以识别不必要的复杂查询计划,并了解每个查询读取的行数以及其消耗的资源。
方法论
在生产环境的部署中识别存在问题的查询可能会比较困难,因为在任意时刻,你的 ClickHouse 部署上都可能正在执行大量查询。
如果你已经知道是哪些用户、数据库或表出现了问题,可以使用 system.query_logs 中的 user、tables 或 databases 字段来缩小搜索范围。
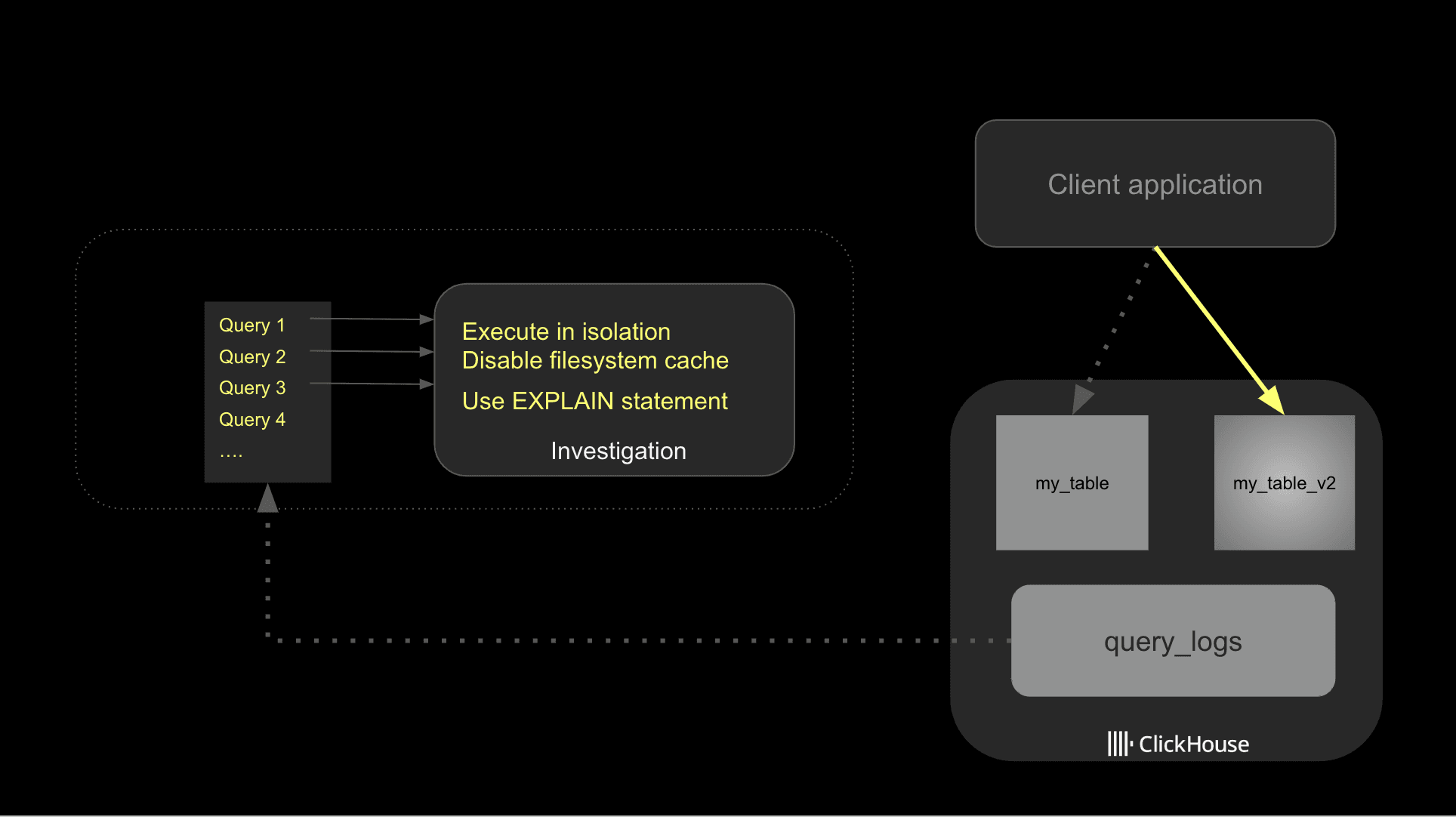
一旦确定了想要优化的查询,就可以开始着手优化它们。开发人员在这个阶段常犯的一个错误是同时更改多项内容,随意做一些即席实验,往往得到参差不齐的结果,更重要的是,没能清楚弄明白究竟是什么让查询变快了。
查询优化需要有结构化的方法。我不是在说要做非常高级的基准测试,而是要有一个简单的流程,用来理解你的更改是如何影响查询性能的,这会大有裨益。
先从查询日志中找出慢查询,然后分别、独立地研究潜在的改进点。在测试查询时,确保禁用文件系统缓存。
ClickHouse 在不同阶段利用 caching 来加速查询性能。对于查询性能而言,这当然是有益的,但在排查问题时,它可能会掩盖潜在的 I/O 瓶颈或糟糕的表结构。因此,建议在测试期间关闭文件系统缓存。请确保在生产环境中重新启用它。
一旦确定了潜在的优化方案,建议你逐项实施,以便更好地跟踪它们对性能的影响。下面的图展示了整体方法。
最后,要留意离群值;某条查询偶尔运行缓慢是很常见的情况,可能是因为用户尝试执行了一条即席的高开销查询,或者系统因为其他原因处于高压状态。你可以按字段 normalized_query_hash 分组,来识别那些被定期执行的高开销查询。这些通常就是最值得你深入调查的对象。
基础优化
既然我们已经搭好了用于测试的框架,就可以开始进行优化了。
最好的起点是查看数据是如何存储的。与任何数据库一样,我们读取的数据越少,查询执行得就越快。
根据你摄取数据的方式,你可能利用了 ClickHouse 的功能,基于摄取的数据推断表结构。虽然这在入门阶段非常实用,但如果你希望优化查询性能,就需要重新审视数据表结构,使其尽可能贴合你的具体用例。
Nullable
如最佳实践文档中所述,应尽可能避免使用 Nullable 列。经常使用它们很有诱惑力,因为它们可以让数据摄取机制更加灵活,但每次都需要处理一个额外的列,会对性能产生负面影响。
执行一条用于统计 NULL 值行数的 SQL 查询,可以很容易找出表中哪些列实际上需要使用 Nullable 类型。
-- Find non-null values columns
SELECT
countIf(vendor_id IS NULL) AS vendor_id_nulls,
countIf(pickup_datetime IS NULL) AS pickup_datetime_nulls,
countIf(dropoff_datetime IS NULL) AS dropoff_datetime_nulls,
countIf(passenger_count IS NULL) AS passenger_count_nulls,
countIf(trip_distance IS NULL) AS trip_distance_nulls,
countIf(fare_amount IS NULL) AS fare_amount_nulls,
countIf(mta_tax IS NULL) AS mta_tax_nulls,
countIf(tip_amount IS NULL) AS tip_amount_nulls,
countIf(tolls_amount IS NULL) AS tolls_amount_nulls,
countIf(total_amount IS NULL) AS total_amount_nulls,
countIf(payment_type IS NULL) AS payment_type_nulls,
countIf(pickup_location_id IS NULL) AS pickup_location_id_nulls,
countIf(dropoff_location_id IS NULL) AS dropoff_location_id_nulls
FROM trips_small_inferred
FORMAT VERTICAL
Query id: 4a70fc5b-2501-41c8-813c-45ce241d85ae
Row 1:
──────
vendor_id_nulls: 0
pickup_datetime_nulls: 0
dropoff_datetime_nulls: 0
passenger_count_nulls: 0
trip_distance_nulls: 0
fare_amount_nulls: 0
mta_tax_nulls: 137946731
tip_amount_nulls: 0
tolls_amount_nulls: 0
total_amount_nulls: 0
payment_type_nulls: 69305
pickup_location_id_nulls: 0
dropoff_location_id_nulls: 0
我们只有两列存在 null 值:mta_tax 和 payment_type。其余字段不应该使用 Nullable 列类型。
低基数(Low cardinality)
对于 String 类型列,一个简单易行的优化是充分利用 LowCardinality 数据类型。正如低基数文档中所述,ClickHouse 会对 LowCardinality 列应用字典编码,从而显著提升查询性能。
判断哪些列适合作为 LowCardinality 的一个简单经验法则是:任何唯一值少于 10,000 个的列,都是理想候选。
你可以使用下面的 SQL 查询来查找唯一值数量较少的列。
-- Identify low cardinality columns
SELECT
uniq(ratecode_id),
uniq(pickup_location_id),
uniq(dropoff_location_id),
uniq(vendor_id)
FROM trips_small_inferred
FORMAT VERTICAL
Query id: d502c6a1-c9bc-4415-9d86-5de74dd6d932
Row 1:
──────
uniq(ratecode_id): 6
uniq(pickup_location_id): 260
uniq(dropoff_location_id): 260
uniq(vendor_id): 3
在基数较低的情况下,这四列 ratecode_id、pickup_location_id、dropoff_location_id 和 vendor_id 非常适合使用 LowCardinality 类型。
优化数据类型
ClickHouse 支持丰富的数据类型。请务必为你的用例选择尽可能小且合适的数据类型,以优化性能并减少磁盘上的数据存储空间。
对于数值类型,你可以在数据集中检查最小值和最大值,以确认当前的数据类型精度是否符合数据集的实际范围。
-- Find min/max values for the payment_type field
SELECT
min(payment_type),max(payment_type),
min(passenger_count), max(passenger_count)
FROM trips_small_inferred
Query id: 4306a8e1-2a9c-4b06-97b4-4d902d2233eb
┌─min(payment_type)─┬─max(payment_type)─┐
1. │ 1 │ 4 │
└───────────────────┴───────────────────┘
对于日期,你应选择既符合数据集特性、又最适合支持你计划执行查询的精度。
应用这些优化
让我们创建一个新表来使用优化后的 schema,并重新摄取这些数据。
-- Create table with optimized data
CREATE TABLE trips_small_no_pk
(
`vendor_id` LowCardinality(String),
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
`ratecode_id` LowCardinality(String),
`pickup_location_id` LowCardinality(String),
`dropoff_location_id` LowCardinality(String),
`payment_type` Nullable(UInt8),
`fare_amount` Decimal32(2),
`extra` Decimal32(2),
`mta_tax` Nullable(Decimal32(2)),
`tip_amount` Decimal32(2),
`tolls_amount` Decimal32(2),
`total_amount` Decimal32(2)
)
ORDER BY tuple();
-- Insert the data
INSERT INTO trips_small_no_pk SELECT * FROM trips_small_inferred
我们使用新表再次运行这些查询,以检查是否有改进。
| Name | Run 1 - Elapsed | Elapsed | Rows processed | Peak memory |
|---|
| Query 1 | 1.699 sec | 1.353 sec | 329.04 million | 337.12 MiB |
| Query 2 | 1.419 sec | 1.171 sec | 329.04 million | 531.09 MiB |
| Query 3 | 1.414 sec | 1.188 sec | 329.04 million | 265.05 MiB |
我们注意到查询时间和内存使用都有所改善。得益于数据模式中的优化,我们减少了用于表示我们数据的总体数据量,从而降低了内存占用并缩短了处理时间。
让我们检查一下这些表的大小,以对比其中的差异。
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes) AS size) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes) AS usize) AS uncompressed,
sum(rows) AS rows
FROM system.parts
WHERE (active = 1) AND ((`table` = 'trips_small_no_pk') OR (`table` = 'trips_small_inferred'))
GROUP BY
database,
`table`
ORDER BY size DESC
Query id: 72b5eb1c-ff33-4fdb-9d29-dd076ac6f532
┌─table────────────────┬─compressed─┬─uncompressed─┬──────rows─┐
1. │ trips_small_inferred │ 7.38 GiB │ 37.41 GiB │ 329044175 │
2. │ trips_small_no_pk │ 4.89 GiB │ 15.31 GiB │ 329044175 │
└──────────────────────┴────────────┴──────────────┴───────────┘
新表相比之前的表小了很多。可以看到,该表的磁盘空间占用减少了约 34%(从 7.38 GiB 降至 4.89 GiB)。
主键的重要性
ClickHouse 中的主键与大多数传统数据库系统中的工作方式不同。在那些系统中,主键用于保证唯一性和数据完整性。任何插入重复主键值的尝试都会被拒绝,并且通常会创建基于 B-tree 或哈希的索引用于快速查找。
在 ClickHouse 中,主键的作用不同;它不强制唯一性,也不用于数据完整性。相反,它旨在优化查询性能。主键定义了数据在磁盘上的存储顺序,并实现为稀疏索引,索引中存储指向每个 granule 第一行的指针。
在 ClickHouse 中,granule 是查询执行期间读取的数据的最小单元。它们最多包含由 index_granularity 决定的固定行数,默认值为 8192 行。Granule 在存储上是连续的,并按主键排序。
选择一组合适的主键对于性能非常重要,而且一种很常见的做法是将相同的数据存储在不同的表中,并使用不同的主键集合来加速一组特定的查询。
ClickHouse 支持的其他选项,例如 Projection(投影)或物化视图,可以让你在相同数据上使用不同的主键集合。本系列博客的第二部分将更详细地讨论这一点。
选择主键
选择正确的主键集合是一个复杂的话题,可能需要权衡和试验,才能找到最佳组合。
目前,我们将遵循以下简单的实践准则:
- 使用在大多数查询中过滤时会用到的字段
- 优先选择基数较低的列
- 在主键中考虑时间相关的组件,因为在时间戳数据集中按时间过滤非常常见。
在我们的示例中,我们将尝试使用以下主键:passenger_count、pickup_datetime 和 dropoff_datetime。
passenger_count 的基数较小(24 个唯一值),并且在我们的慢查询中会被使用。我们还添加时间戳字段(pickup_datetime 和 dropoff_datetime),因为它们经常用于过滤。
创建一个带有这些主键的新表并重新摄取数据。
CREATE TABLE trips_small_pk
(
`vendor_id` UInt8,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`passenger_count` UInt8,
`trip_distance` Float32,
`ratecode_id` LowCardinality(String),
`pickup_location_id` UInt16,
`dropoff_location_id` UInt16,
`payment_type` Nullable(UInt8),
`fare_amount` Decimal32(2),
`extra` Decimal32(2),
`mta_tax` Nullable(Decimal32(2)),
`tip_amount` Decimal32(2),
`tolls_amount` Decimal32(2),
`total_amount` Decimal32(2)
)
PRIMARY KEY (passenger_count, pickup_datetime, dropoff_datetime);
-- Insert the data
INSERT INTO trips_small_pk SELECT * FROM trips_small_inferred
然后重新运行查询。我们汇总三次实验的结果,以观察在耗时、处理行数和内存占用方面的改进情况。
| Query 1 |
|---|
| 第 1 次运行 | 第 2 次运行 | 第 3 次运行 |
|---|
| 耗时 | 1.699 秒 | 1.353 秒 | 0.765 秒 |
| 处理行数 | 3.2904 亿 | 3.2904 亿 | 3.2904 亿 |
| 峰值内存占用 | 440.24 MiB | 337.12 MiB | 444.19 MiB |
| Query 2 |
|---|
| 第 1 次运行 | 第 2 次运行 | 第 3 次运行 |
|---|
| 耗时 | 1.419 秒 | 1.171 秒 | 0.248 秒 |
| 处理行数 | 3.2904 亿 | 3.2904 亿 | 4146 万 |
| 峰值内存占用 | 546.75 MiB | 531.09 MiB | 173.50 MiB |
| 查询 3 |
|---|
| 运行 1 | 运行 2 | 运行 3 |
|---|
| 耗时 | 1.414 秒 | 1.188 秒 | 0.431 秒 |
| 处理行数 | 329.04 百万行 | 329.04 百万行 | 276.99 百万行 |
| 峰值内存 | 451.53 MiB | 265.05 MiB | 197.38 MiB |
我们可以看到,在执行时间和内存使用方面整体都有显著改善。
查询 2 从主键中获益最大。我们来看看当前生成的查询计划与之前有何不同。
EXPLAIN indexes = 1
SELECT
payment_type,
COUNT() AS trip_count,
formatReadableQuantity(SUM(trip_distance)) AS total_distance,
AVG(total_amount) AS total_amount_avg,
AVG(tip_amount) AS tip_amount_avg
FROM nyc_taxi.trips_small_pk
WHERE (pickup_datetime >= '2009-01-01') AND (pickup_datetime < '2009-04-01')
GROUP BY payment_type
ORDER BY trip_count DESC
Query id: 30116a77-ba86-4e9f-a9a2-a01670ad2e15
┌─explain──────────────────────────────────────────────────────────────────────────────────────────────────────────┐
1. │ Expression ((Projection + Before ORDER BY [lifted up part])) │
2. │ Sorting (Sorting for ORDER BY) │
3. │ Expression (Before ORDER BY) │
4. │ Aggregating │
5. │ Expression (Before GROUP BY) │
6. │ Expression │
7. │ ReadFromMergeTree (nyc_taxi.trips_small_pk) │
8. │ Indexes: │
9. │ PrimaryKey │
10. │ Keys: │
11. │ pickup_datetime │
12. │ Condition: and((pickup_datetime in (-Inf, 1238543999]), (pickup_datetime in [1230768000, +Inf))) │
13. │ Parts: 9/9 │
14. │ Granules: 5061/40167 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
由于有主键,仅选中了表中的一部分 granule。这一点本身就能大幅提升查询性能,因为 ClickHouse 需要处理的数据量大大减少。
下一步
希望本指南能够帮助你更好地理解如何在 ClickHouse 中分析慢查询,以及如何让它们运行得更快。若想进一步深入这一主题,你可以阅读 query analyzer 和 profiling,以更好地理解 ClickHouse 究竟是如何执行你的查询的。
随着你对 ClickHouse 特性愈发熟悉,建议继续阅读 partitioning keys 和 data skipping indexes,以了解更多可用于加速查询的高级技术。