PREWHERE 优化是如何工作的?
PREWHERE 子句 是 ClickHouse 中的一种查询执行优化机制。它通过避免不必要的数据读取、在从磁盘读取非过滤列之前先过滤掉无关数据,从而减少 I/O 并提升查询速度。
本指南将介绍 PREWHERE 的工作原理、如何衡量它带来的效果,以及如何对其进行调优以获得最佳性能。
未使用 PREWHERE 优化时的查询处理
我们先来说明在不使用 PREWHERE 的情况下,对 uk_price_paid_simple 表的查询是如何处理的:

① 查询包含对 town 列的过滤条件,该列是表主键的一部分,因此也是主索引的一部分。
② 为了加速查询,ClickHouse 会将表的主索引加载到内存中。
③ 它会扫描索引条目,以识别出 town 列中哪些 granule 可能包含满足谓词条件的行。
④ 这些潜在相关的 granule 会被加载到内存中,同时还会加载查询所需的其他列中在位置上对齐的 granule。
⑤ 然后在查询执行期间应用其余的过滤条件。
可以看到,在没有 PREWHERE 的情况下,所有潜在相关的列都会在过滤之前加载,即便最终只有少量行实际匹配条件。
PREWHERE 如何提升查询效率
下列动画展示了在将 PREWHERE 子句应用到所有查询谓词后,上文中的查询是如何被处理的。
最开始的三个处理步骤与之前相同:

① 查询包含对 town 列的过滤,该列是表主键的一部分,因此也是主索引的一部分。
② 与未使用 PREWHERE 子句的情况类似,为了加速查询,ClickHouse 会将主索引加载到内存中,
③ 然后扫描索引条目,以识别 town 列中哪些 granule 可能包含满足谓词的行。
现在,由于 PREWHERE 子句的作用,下一步的处理就不同了:ClickHouse 不再一开始就读取所有相关列,而是按列逐步过滤数据,只加载真正需要的列。这会显著减少 I/O,尤其是对于宽表。
在每一步中,它只会加载那些包含至少一行在上一轮过滤中“存活”(即匹配)下来的行的 granule。结果是,为每个过滤条件需要加载和评估的 granule 数量会单调递减:
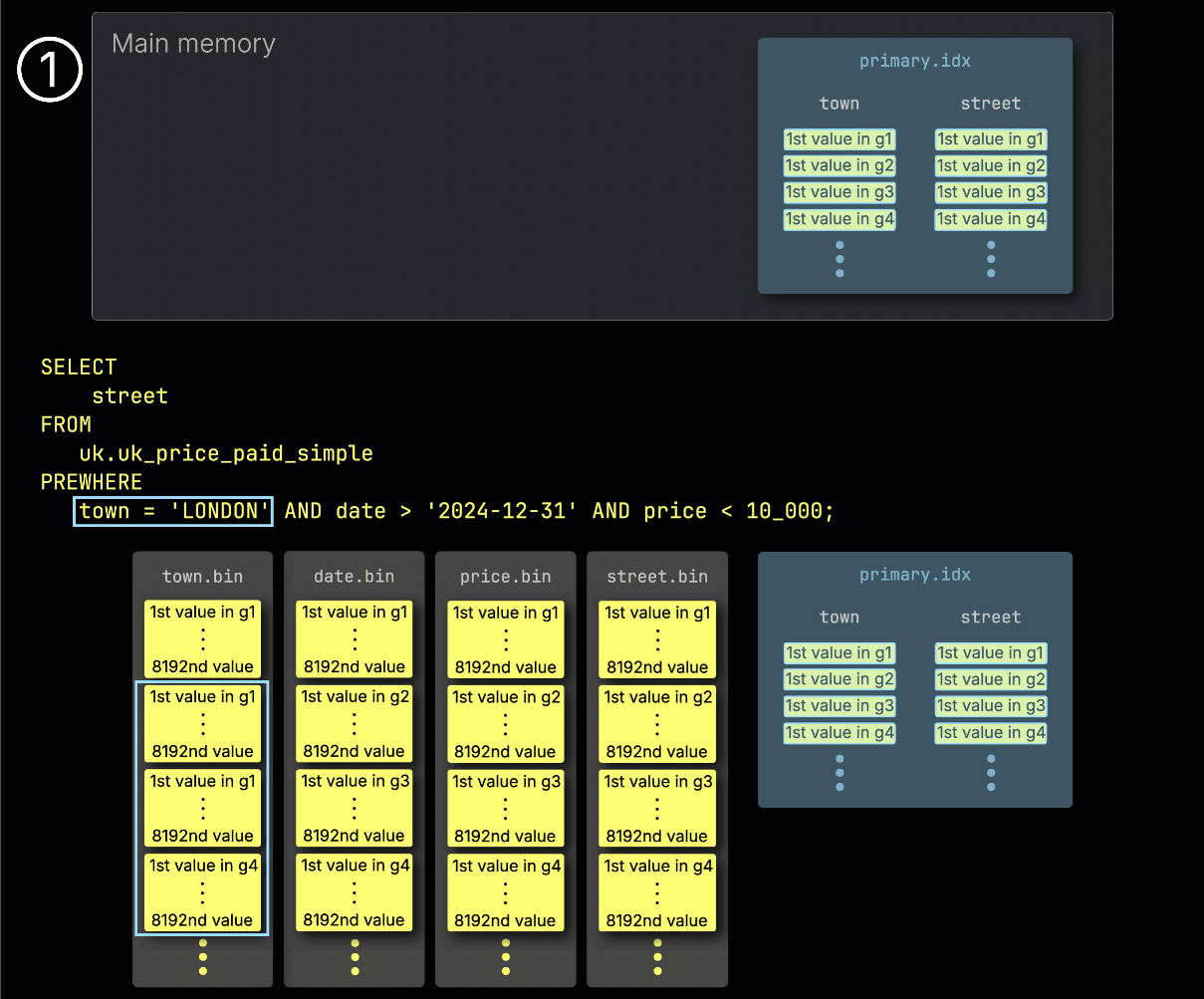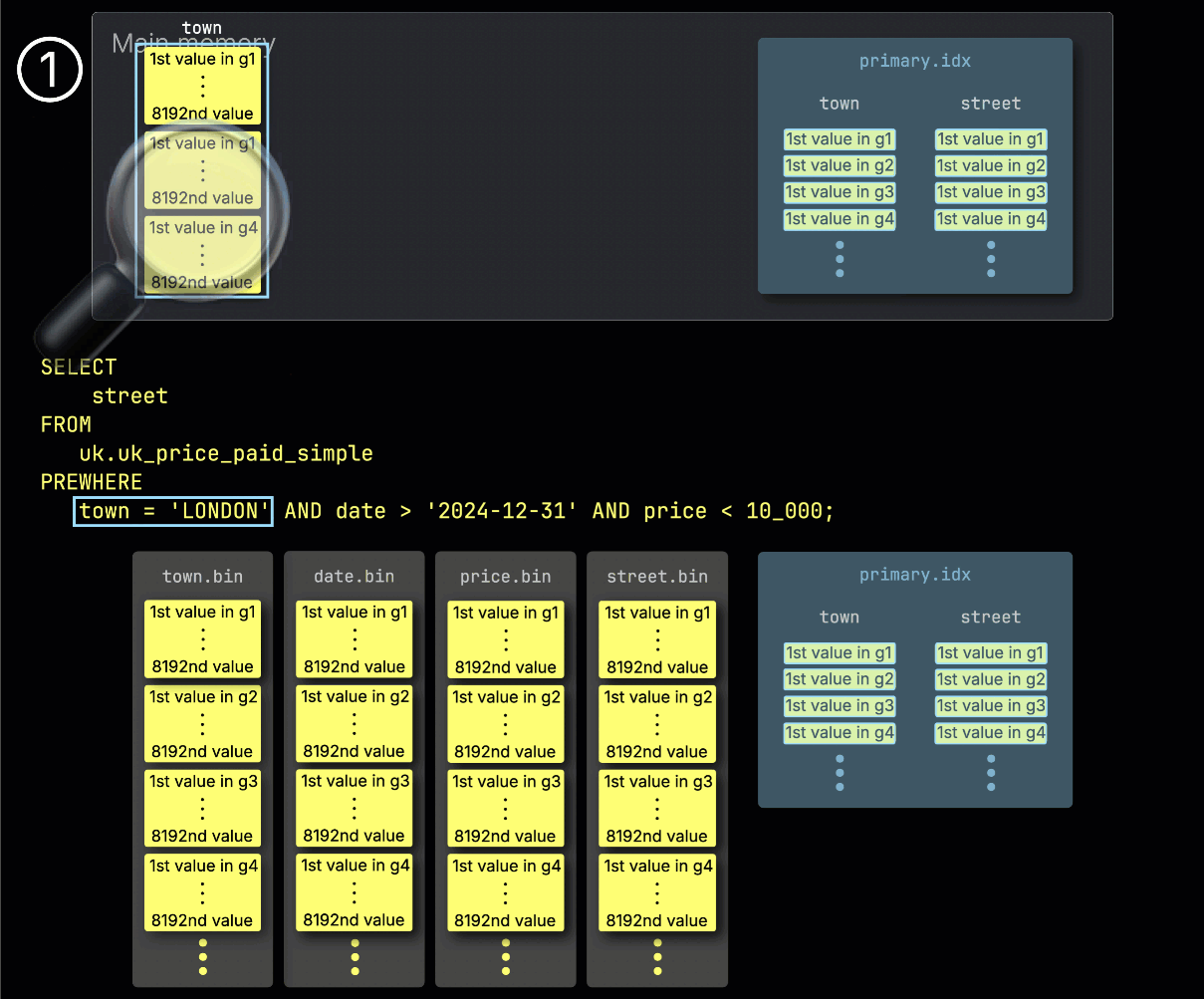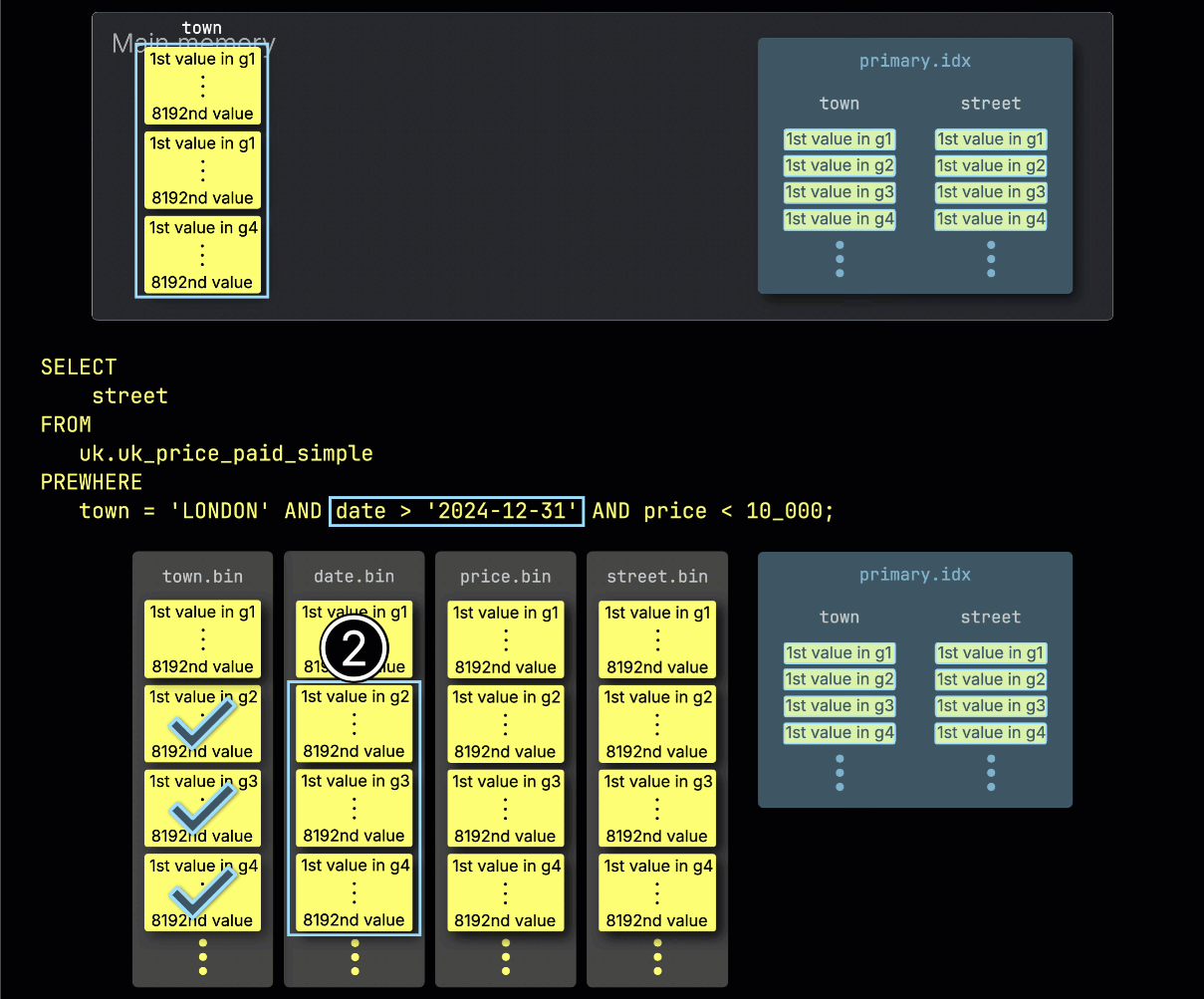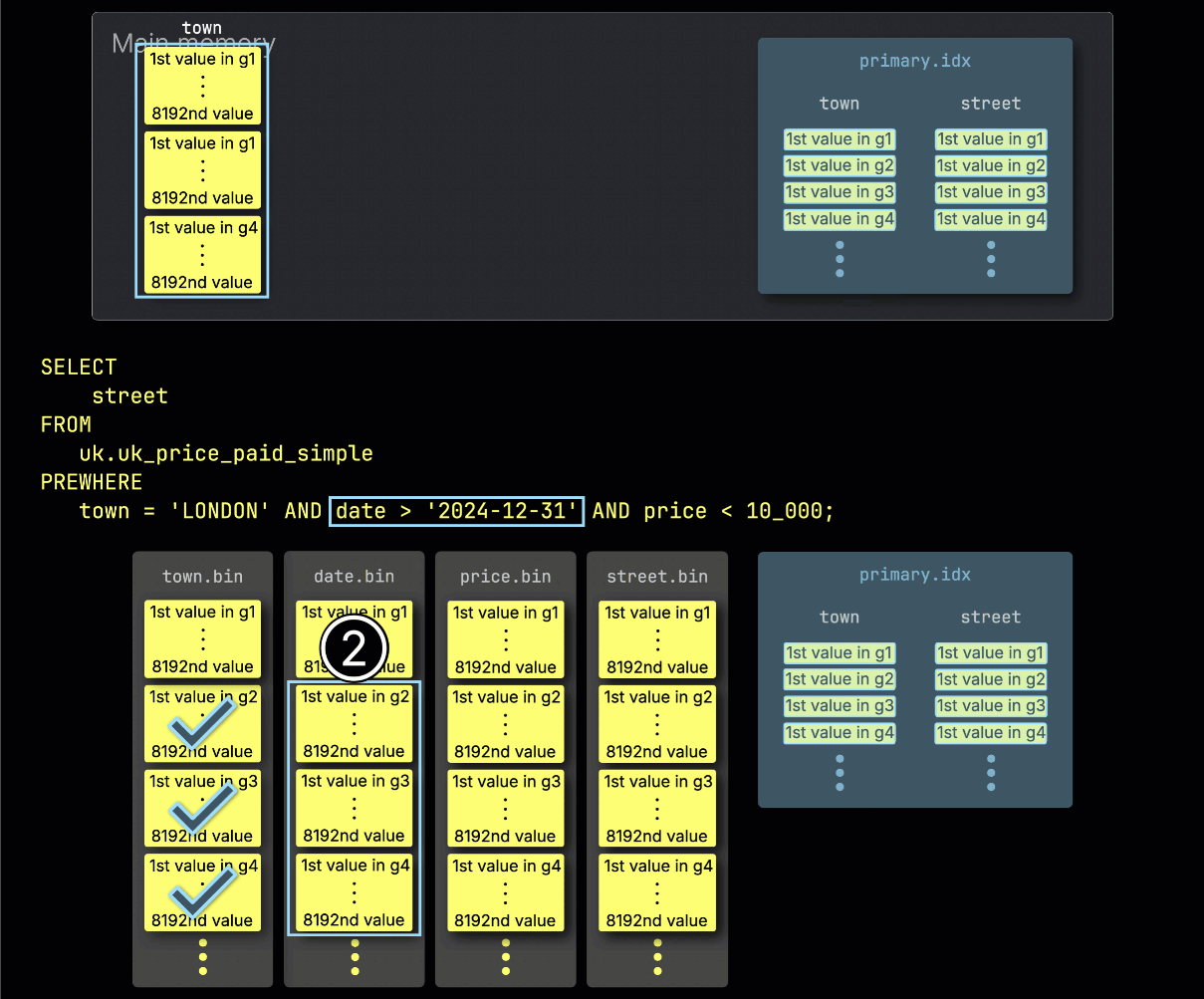
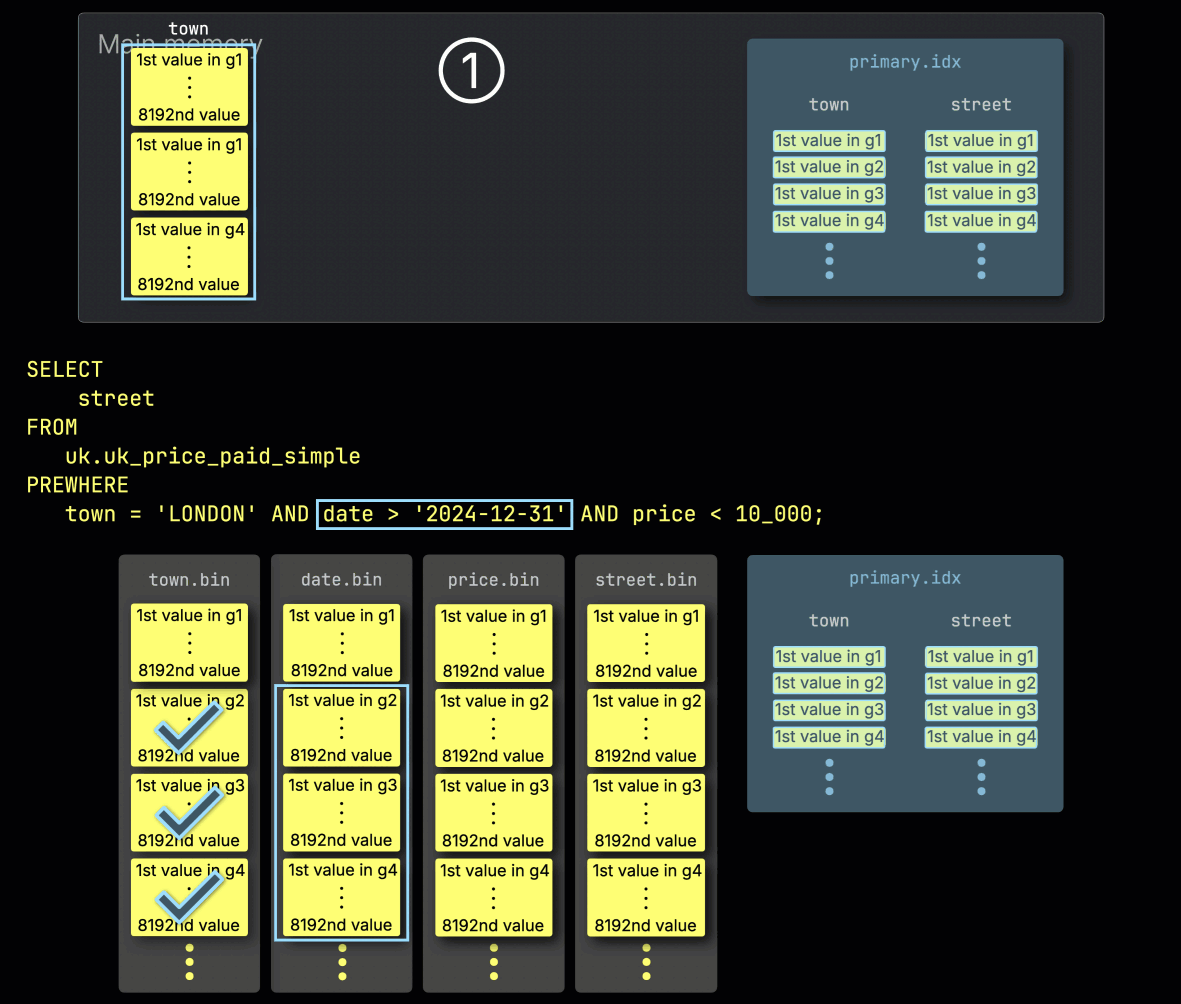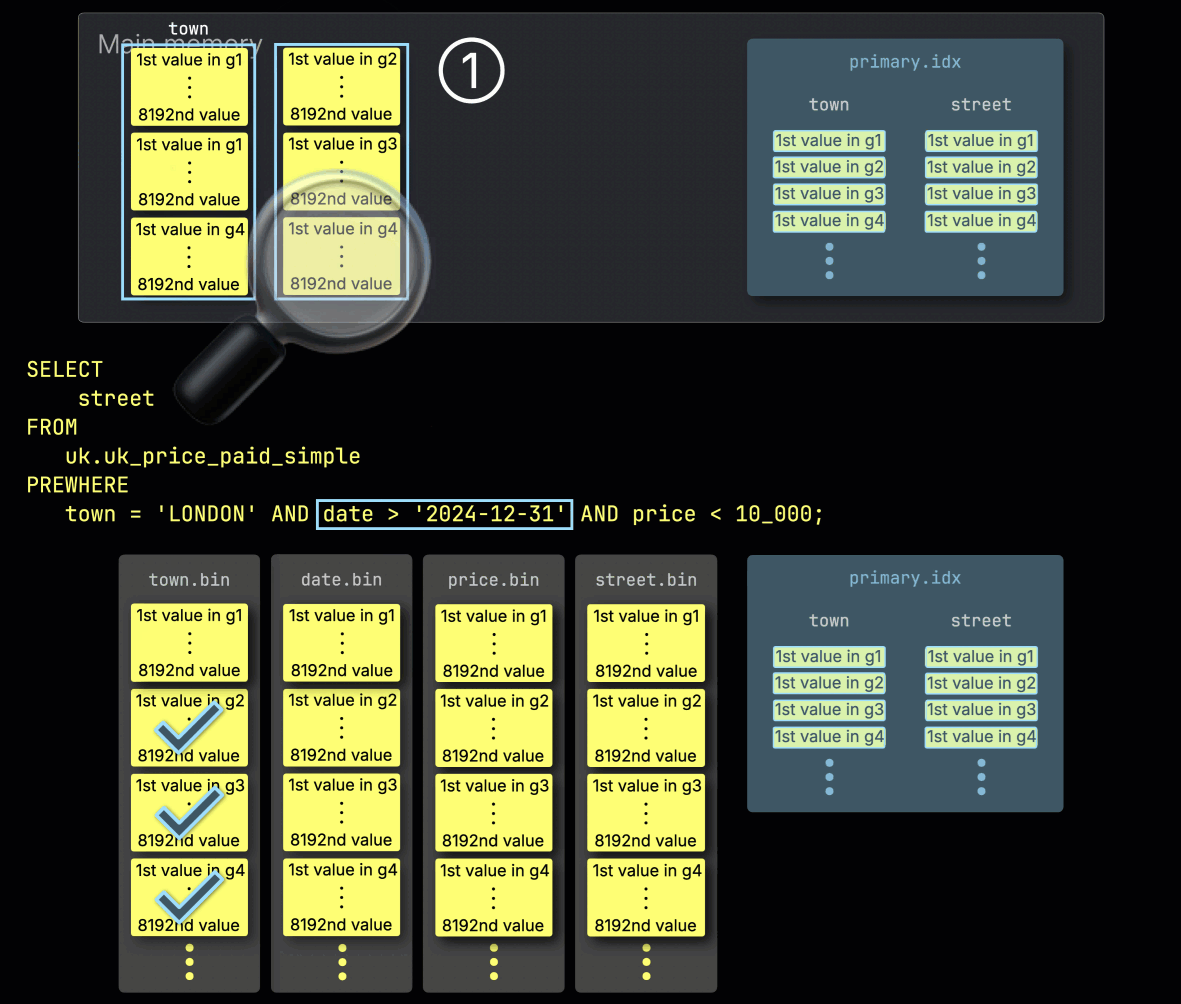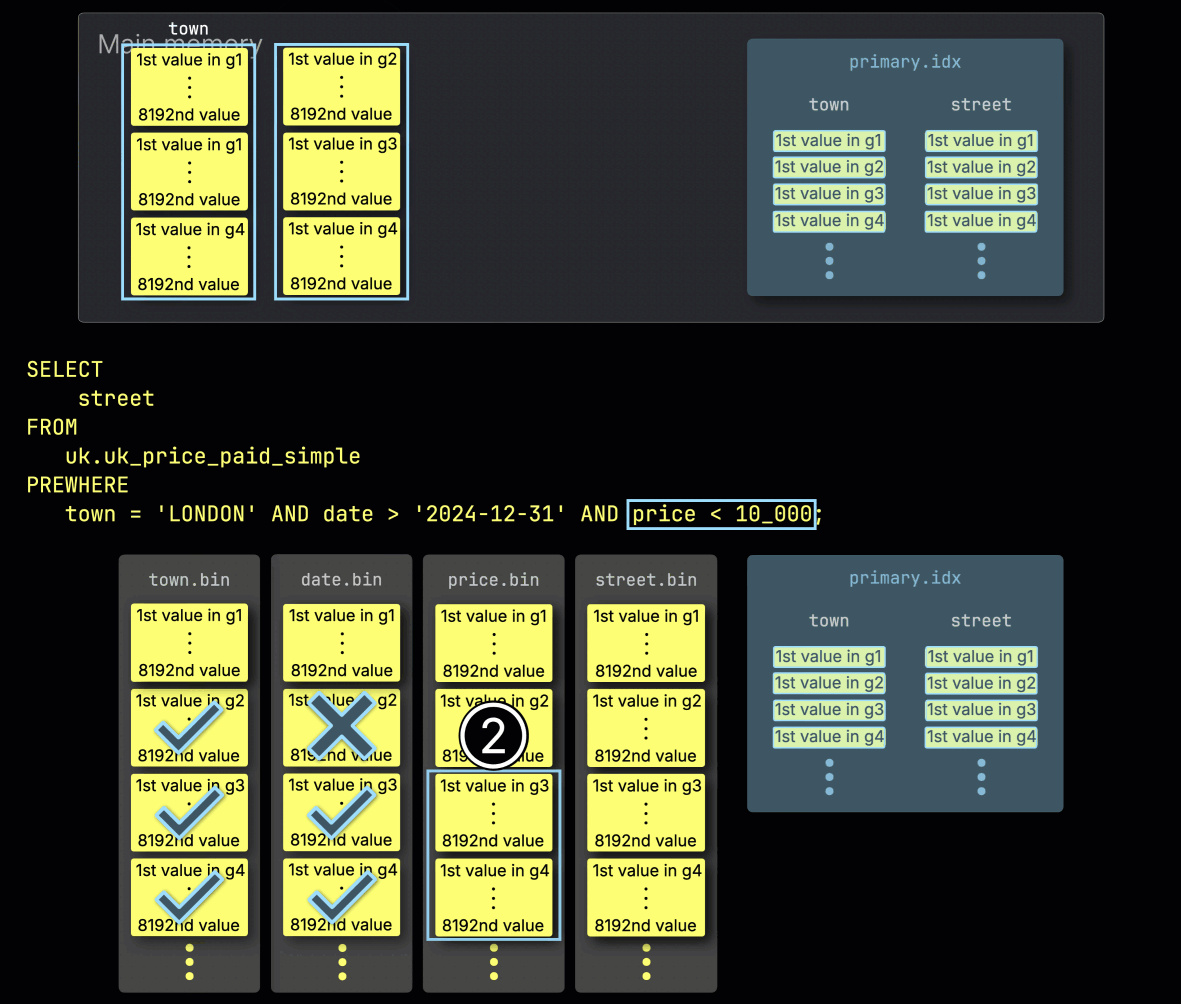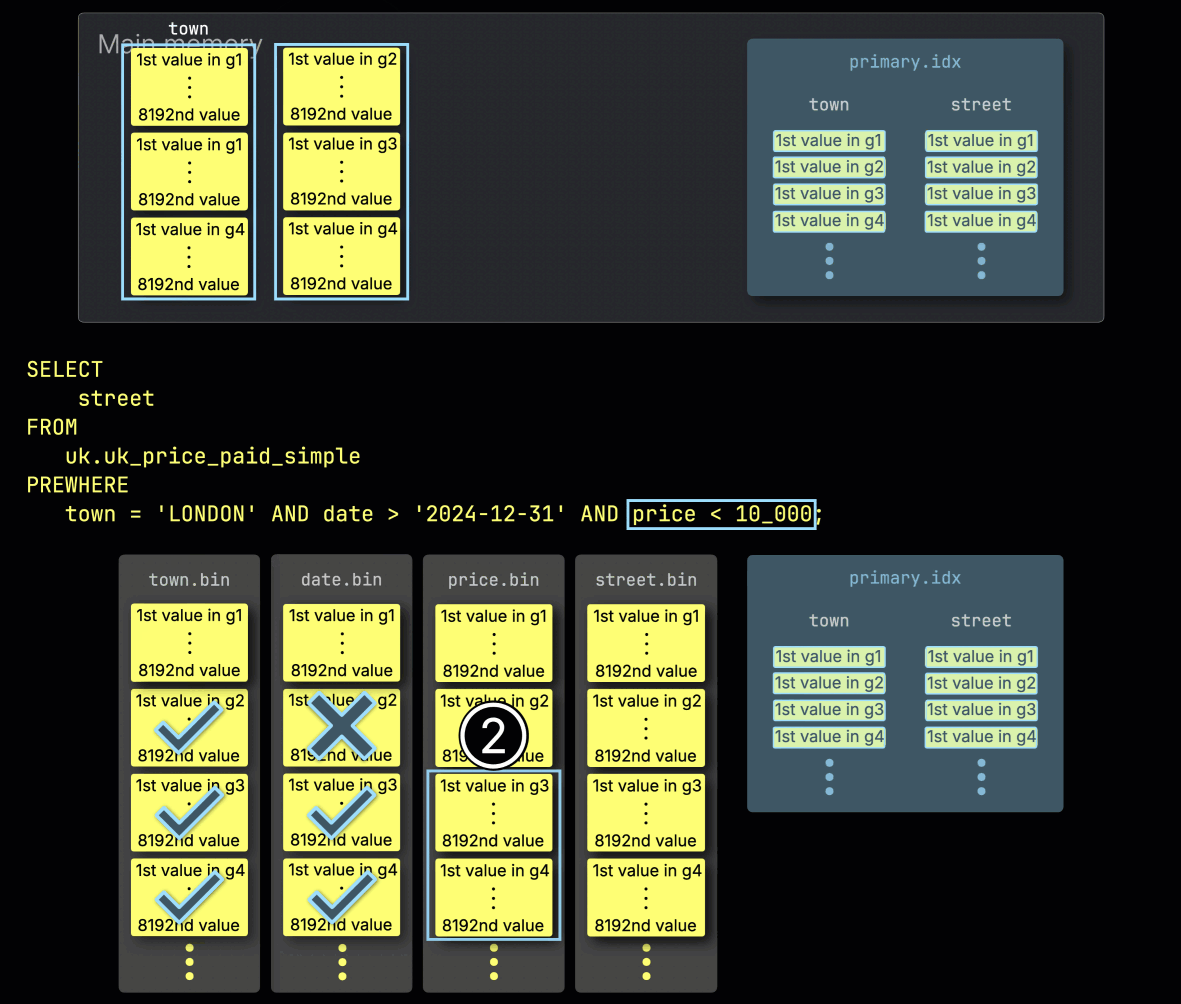
步骤 1:按 town 过滤
ClickHouse 首先通过 ① 从 town 列读取选定的 granule,并检查哪些 granule 实际上包含匹配 London 的行,来开始 PREWHERE 处理。
在我们的示例中,所有被选中的 granule 都匹配,因此 ② 会选择下一过滤列 date 中与之按位置对齐的 granule 进行处理:
步骤 2:按 date 过滤
接下来,ClickHouse ① 读取选定的 date 列 granule,以评估过滤条件 date > '2024-12-31'。
在这个例子中,有三分之二的 granule 包含匹配的行,因此 ② 只会选择下一过滤列 price 中与之按位置对齐的 granule 进行后续处理:
步骤 3:按 price 过滤
最后,ClickHouse ① 读取 price 列中前一步选出的两个 granule,以评估最后一个过滤条件 price > 10_000。
只有其中一个 granule 包含匹配的行,因此 ② 只需要加载其在 SELECT 列 street 中按位置对齐的 granule 以进行进一步处理:

在最后一步时,只会加载包含匹配行的最小集合的列 granule。这会带来更低的内存使用量、更少的磁盘 I/O,以及更快的查询执行。
请注意,在带 PREWHERE 和不带 PREWHERE 的两种查询版本中,ClickHouse 处理的行数是相同的。然而,在应用 PREWHERE 优化后,并不需要为每一行都加载所有列的值。
PREWHERE 优化会自动应用
如上例所示,可以手动添加 PREWHERE 子句。不过,你无需手动编写 PREWHERE。当将设置 optimize_move_to_prewhere 启用时(默认值为 true),ClickHouse 会自动将过滤条件从 WHERE 移动到 PREWHERE,并优先选择那些最能减少读取量的条件。
其核心思想是,较小的列扫描速度更快,到处理较大列时,大多数 granule 已经被过滤掉。由于所有列的行数相同,列的大小主要由其数据类型决定,例如,UInt8 列通常比 String 列小得多。
从版本 23.2 开始,ClickHouse 默认遵循这一策略,会按未压缩大小的升序对 PREWHERE 过滤列进行排序,以进行多阶段处理。
从版本 23.11 开始,可选的列统计信息可以进一步优化这一过程,即基于实际数据的选择性来决定过滤处理顺序,而不仅仅依赖列大小。
如何衡量 PREWHERE 的影响
要验证 PREWHERE 是否提升了查询性能,可以对比在启用和禁用 optimize_move_to_prewhere 设置时的查询表现。
首先在禁用 optimize_move_to_prewhere 设置的情况下运行查询:
在执行该查询时,ClickHouse 共读取了 23.36 MB 的列数据,处理了 231 万行记录。
接下来,我们在开启 optimize_move_to_prewhere 设置的情况下运行该查询。(请注意,此设置是可选的,因为它默认已启用):
处理的行数相同(231 万),但得益于 PREWHERE,ClickHouse 读取的列数据量减少到不到原来的三分之一——仅 6.74 MB,而非 23.36 MB——从而将总运行时间缩短了约 3 倍。
若要更深入了解 ClickHouse 在幕后如何应用 PREWHERE,请使用 EXPLAIN 和 trace 日志。
我们使用 EXPLAIN 子句检查查询的逻辑计划:
我们在这里省略了大部分查询计划输出,因为内容相当冗长。归根结底,它表明这三个列谓词都被自动下推到了 PREWHERE。
当你自己复现这一过程时,你还会在查询计划中看到,这些谓词的顺序是根据列的数据类型大小决定的。由于我们尚未启用列统计信息,ClickHouse 会使用列大小作为后备依据来确定 PREWHERE 的处理顺序。
如果你想进一步深入了解底层机制,可以让 ClickHouse 在查询执行期间返回所有 test 级别的日志记录,从而观察每一个独立的 PREWHERE 处理步骤:
关键要点
- PREWHERE 可以避免读取之后会被过滤掉的列数据,从而节省 I/O 和内存。
- 当启用
optimize_move_to_prewhere(默认启用)时,它会自动起作用。 - 过滤条件的顺序很重要:数据量小且选择性高的列应当优先放在前面。
- 使用
EXPLAIN和日志来验证是否应用了 PREWHERE,并理解其效果。 - PREWHERE 在列很多的宽表,以及对大规模数据进行高选择性过滤扫描时效果最显著。
