异步插入(async_insert)
在客户端无法进行批量处理时,ClickHouse 中的异步插入提供了一种强大的替代方案。这在可观测性工作负载中尤为重要,因为数百甚至数千个 agent 会持续发送数据——日志、指标、追踪数据 (traces) ——通常以小而实时的负载形式发送。在这类环境中在客户端缓冲数据会增加复杂度,需要一个集中式队列来确保可以发送足够大的批次。
不推荐在同步模式下发送大量小批次,这会导致创建大量 parts。这将导致查询性能下降,并产生 "too many part" 错误。
异步插入通过将批处理的责任从客户端转移到服务器来实现:将传入数据写入内存缓冲区,然后根据可配置阈值刷新到存储中。此方法显著降低了 parts 创建的开销,减少 CPU 使用率,并确保在高并发下摄取仍然高效。
核心行为通过 async_insert 设置进行控制。
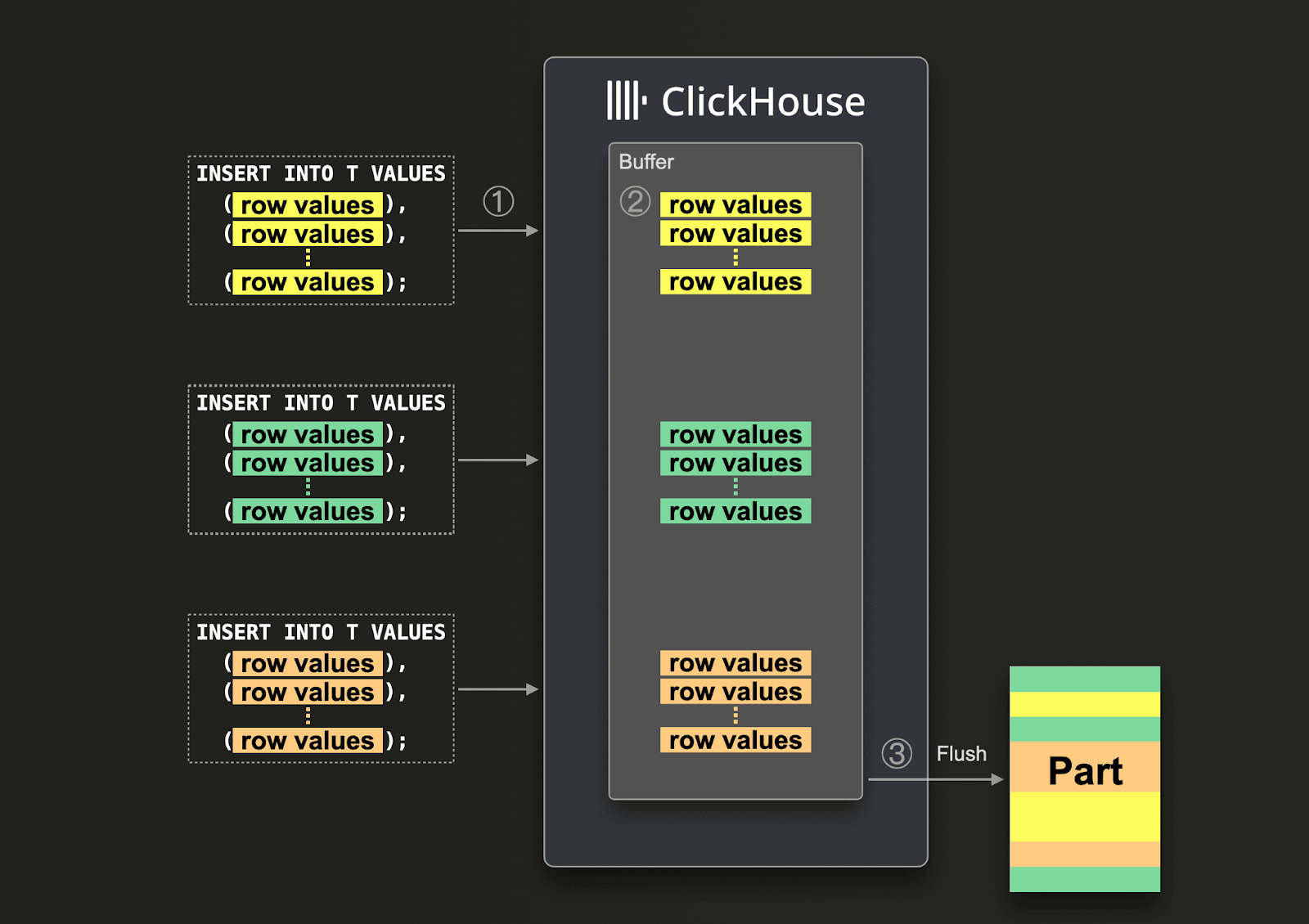
异步插入同时支持 HTTP 和原生 TCP 接口。
启用 (async_insert = 1) 后,插入会被缓冲,只有在满足以下任一刷新条件时才会写入磁盘:
- 缓冲区达到指定的数据大小 (
async_insert_max_data_size,默认为 100 MiB) 。 - 达到时间阈值 (
async_insert_busy_timeout_ms,默认为 200 毫秒,在 Cloud 中为 1000 毫秒) 。 - 累积的插入查询数量达到上限 (
async_insert_max_query_number,默认为 450) 。
先达到的阈值会触发刷新。
这一批处理过程对客户端是透明的,有助于 ClickHouse 高效合并来自多个源的插入流量。但在刷新发生之前,这些数据无法被查询。需要注意的是,对于每种插入形态 (insert shape) 与设置组合会有多个缓冲区,在集群中,缓冲区按节点维护——从而在多租户环境中实现细粒度控制。其余插入机制与同步插入中描述的相同。
选择返回模式
异步插入的行为可通过 wait_for_async_insert 设置进行进一步细化。
当设置为 1 (默认值) 时,ClickHouse 仅在数据成功刷新到磁盘后才确认插入。这确保了强持久性保证,并使错误处理变得简单:如果在刷新期间出现问题,错误会返回给客户端。此模式推荐用于大多数生产场景,尤其是在必须可靠跟踪插入失败时。
基准测试表明,它在并发规模下表现良好——无论你运行的是 200 还是 500 个客户端——这得益于自适应插入和稳定的 parts 创建行为。
将 wait_for_async_insert = 0 设置为 0 会开启 “fire-and-forget” (“发出即忘”) 模式。在该模式下,服务器在数据被缓冲后立即确认插入,而不会等待其写入存储。
这提供了超低延迟的插入和最大吞吐量,非常适合高速度、低重要性的数据。然而,这也带来了权衡:无法保证数据一定被持久化,错误只会在刷新时才暴露,并且失败的插入没有死信队列——要追踪失败,事后需要检查服务器日志和系统表。仅当你的工作负载可以容忍数据丢失时才使用此模式。
基准测试还表明,当缓冲刷新不频繁 (例如每 30 秒一次) 时,可以显著减少 parts 数量并降低 CPU 使用率,但静默失败的风险依然存在。
我们强烈建议,如果使用异步插入,应设置 async_insert=1,wait_for_async_insert=1。使用 wait_for_async_insert=0 风险极高,因为你的 INSERT 客户端可能不知道是否发生了错误,并且在 ClickHouse 服务器需要减慢写入速度并施加一定背压以保证服务可靠性的情况下,如果客户端持续快速写入,还可能导致潜在的过载。
自适应异步插入
从 24.2 版本开始,ClickHouse 默认使用自适应刷新超时 (async_insert_use_adaptive_busy_timeout) 。不再采用固定的刷新时间间隔,而是根据传入数据速率,在最小值 (async_insert_busy_timeout_min_ms,默认 50 毫秒) 和最大值 (async_insert_busy_timeout_max_ms,默认 200 毫秒,在 Cloud 上为 1000 毫秒) 之间动态调整超时时间。
当数据频繁到达时,超时时间会更接近最小值,以便更快刷新并降低端到端延迟。当数据较为稀疏时,它会逐渐接近最大值,以积累更大的批次。这在默认模式 (wait_for_async_insert=1) 下尤其有用,因为如果使用固定且较高的超时时间,即使数据已经可以刷新,客户端也会被迫在整个时间间隔内一直阻塞。
错误处理
schema 验证和数据解析发生在缓冲区刷新时,而不是在收到 insert 请求时进行。如果某个 insert 查询中的任意一行存在解析错误或类型错误,该查询的数据都不会被刷新——整个查询的载荷都会被拒绝。在默认模式 (wait_for_async_insert=1) 下,错误会返回给客户端。在 fire-and-forget 模式下,错误会写入服务器日志以及 system.asynchronous_inserts 表。
每次刷新都会针对缓冲区中每个不同的分区键值至少创建一个 part。即使是没有分区键的表,如果缓冲数据超过 max_insert_block_size (默认约 100 万行) ,单次刷新也可能生成多个 parts。
即使使用异步 insert,如果分区键具有较高的基数,您仍然可能遇到“Too many parts”错误。
去重与可靠性
默认情况下,ClickHouse 会对同步插入执行自动去重,这使得在失败场景下重试是安全的。然而,对于异步插入,这一功能是禁用的,除非显式启用 (如果你有依赖的物化视图,则不应启用——见相关 issue) 。
在实践中,如果开启了去重并对同一插入执行重试——例如由于超时或网络中断——ClickHouse 可以安全地忽略重复记录。这有助于保持幂等性并避免数据被重复写入。
启用异步插入
可以为特定用户或特定查询启用异步插入:
-
在用户级别启用异步插入。此示例使用用户
default,如果你创建了其他用户,请将其替换为相应的用户名: -
你可以在插入查询中通过
SETTINGS子句指定异步插入相关设置: -
在使用 ClickHouse 编程语言客户端时,你也可以通过连接参数指定异步插入相关设置。
例如,以下是在使用 ClickHouse Java JDBC 驱动程序连接到 ClickHouse Cloud 时,在 JDBC 连接字符串中进行设置的方式:
异步插入不适用于 INSERT INTO ... SELECT 查询。当插入包含 SELECT 子句时,无论 async_insert 设置如何,该查询始终会同步执行。
关闭时刷新缓冲区
要刷新所有待处理的异步插入缓冲区 (例如在平滑关闭期间或维护前) ,请运行:
这可确保在服务器停止前,所有缓冲数据都会写入存储。
与缓冲表的比较
异步插入是 Buffer 表 的现代替代方案。关键差异:
- 无需 DDL 修改。 异步插入对用户是透明的——你只需启用一项设置,而不必创建额外的表。
- 按形态缓冲。 异步插入会按每种唯一的查询形态和设置组合分别维护独立缓冲区,从而支持更细粒度的刷新策略。Buffer 表则是每个目标表只使用一个缓冲区。
- 持久性。 在默认模式下 (
wait_for_async_insert=1) ,会先确认数据已写入磁盘,然后客户端才会收到确认。Buffer 表则类似“发出即忘”——如果发生崩溃,缓冲中的数据会丢失。 - 集群行为。 在集群中,异步插入的缓冲区按节点分别维护。Buffer 表则需要在每个节点上显式创建。
