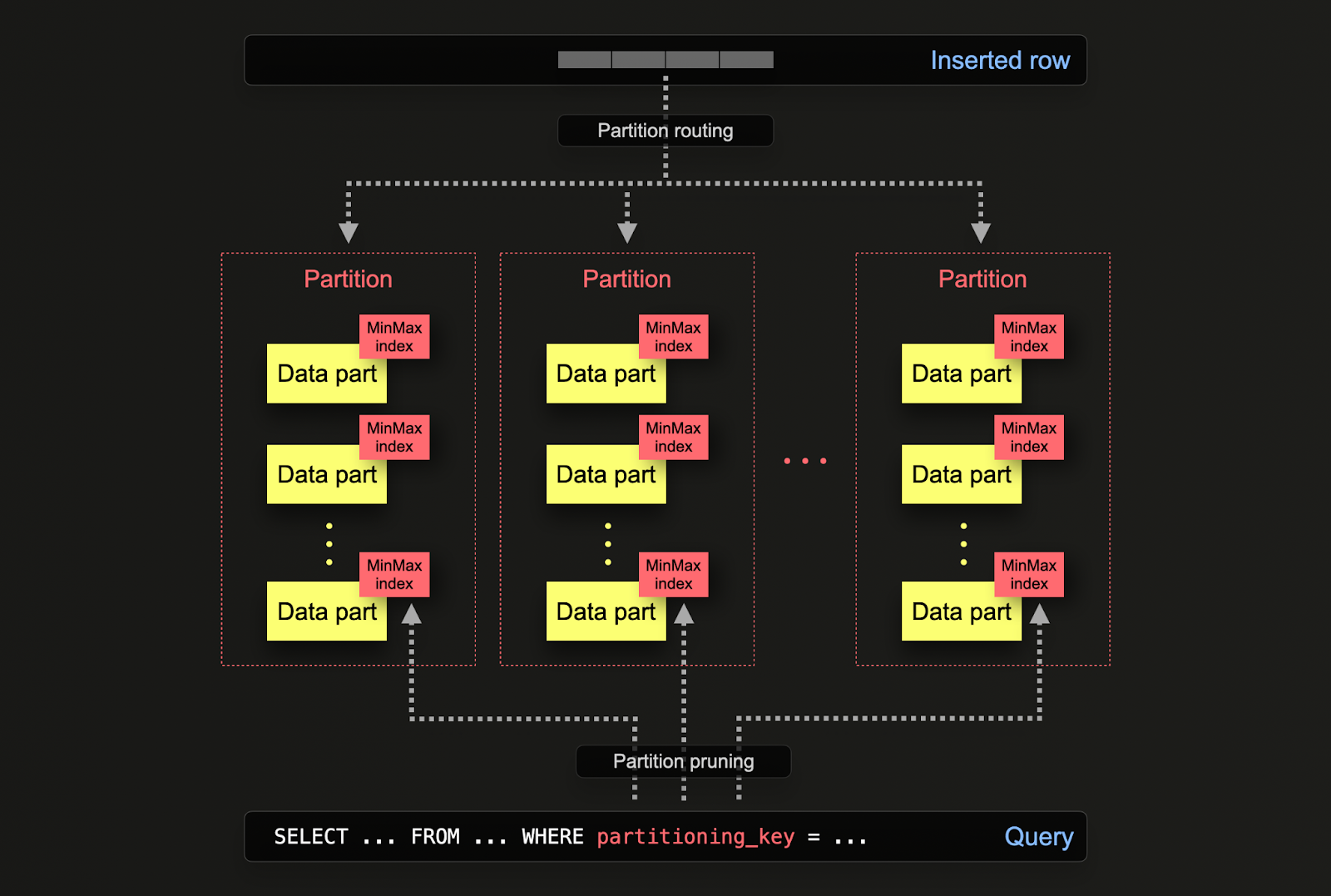
为可观测性部署 ClickHouse 通常会涉及大规模数据集,而这些数据集需要妥善管理。ClickHouse 提供了多种功能来协助进行数据管理。
在 ClickHouse 中,分区允许根据某一列或 SQL 表达式在磁盘上对数据进行逻辑划分。通过对数据进行逻辑分离,可以对每个分区独立执行操作,例如删除。这样用户就可以按时间在不同存储层之间高效移动分区(以及其数据子集),或者在集群中过期数据 / 高效删除数据。
在表初始定义时,通过 PARTITION BY 子句来指定分区方式。该子句可以包含针对一个或多个列的 SQL 表达式,其计算结果将决定每一行被写入哪个分区。
数据 part 在逻辑上通过公共文件夹名前缀与磁盘上的各个分区关联,并且可以被单独查询。以下示例中,默认的 otel_logs 表结构使用表达式 toDate(Timestamp) 按天进行分区。随着行被插入到 ClickHouse,这个表达式会针对每一行求值,并在对应分区存在时将该行路由到该分区(如果该行是该天的第一行,则会创建该分区)。
CREATE TABLE default.otel_logs
(
...
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
可以在分区上执行多种操作,包括备份、列操作、通过更新/删除按行变更数据,以及索引清理(例如二级索引)。
例如,假设我们的 otel_logs 表按天进行分区。如果使用结构化日志数据集填充该表,表中将包含多天的数据:
SELECT Timestamp::Date AS day,
count() AS c
FROM otel_logs
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-22 │ 2333977 │
│ 2019-01-23 │ 2326694 │
│ 2019-01-26 │ 1986456 │
│ 2019-01-24 │ 1896255 │
│ 2019-01-25 │ 1821770 │
└────────────┴─────────┘
5 rows in set. Elapsed: 0.058 sec. Processed 10.37 million rows, 82.92 MB (177.96 million rows/s., 1.42 GB/s.)
Peak memory usage: 4.41 MiB.
可以通过一个简单的系统表查询来查看当前分区:
SELECT DISTINCT partition
FROM system.parts
WHERE `table` = 'otel_logs'
┌─partition──┐
│ 2019-01-22 │
│ 2019-01-23 │
│ 2019-01-24 │
│ 2019-01-25 │
│ 2019-01-26 │
└────────────┘
5 rows in set. Elapsed: 0.005 sec.
我们还可以有一张名为 otel_logs_archive 的表,用于存放更早期的数据。可以按分区将数据高效迁移到该表(这只是元数据层面的变更)。
CREATE TABLE otel_logs_archive AS otel_logs
--将数据移至归档表
ALTER TABLE otel_logs
(MOVE PARTITION tuple('2019-01-26') TO TABLE otel_logs_archive
--确认数据已移动
SELECT
Timestamp::Date AS day,
count() AS c
FROM otel_logs
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-22 │ 2333977 │
│ 2019-01-23 │ 2326694 │
│ 2019-01-24 │ 1896255 │
│ 2019-01-25 │ 1821770 │
└────────────┴─────────┘
4 rows in set. Elapsed: 0.051 sec. Processed 8.38 million rows, 67.03 MB (163.52 million rows/s., 1.31 GB/s.)
Peak memory usage: 4.40 MiB.
SELECT Timestamp::Date AS day,
count() AS c
FROM otel_logs_archive
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-26 │ 1986456 │
└────────────┴─────────┘
1 row in set. Elapsed: 0.024 sec. Processed 1.99 million rows, 15.89 MB (83.86 million rows/s., 670.87 MB/s.)
Peak memory usage: 4.99 MiB.
这不同于其他技术,后者需要使用 INSERT INTO SELECT 并将数据重新写入新的目标表。
移动分区
在表之间移动分区 需要满足若干条件,其中最重要的是,表必须具有相同的结构、分区键、主键以及索引/投影。关于如何在 ALTER DDL 中指定分区的详细说明可以在此处找到。
此外,可以按分区高效地删除数据。这比其他技术(数据变更 mutations 或轻量级删除)要更加节省资源,应优先采用。
ALTER TABLE otel_logs
(DROP PARTITION tuple('2019-01-25'))
SELECT
Timestamp::Date AS day,
count() AS c
FROM otel_logs
GROUP BY day
ORDER BY c DESC
┌────────day─┬───────c─┐
│ 2019-01-22 │ 4667954 │
│ 2019-01-23 │ 4653388 │
│ 2019-01-24 │ 3792510 │
└────────────┴─────────┘
应用场景
上文展示了如何按分区高效地迁移和处理数据。在实际使用中,在可观测性场景下,你最常利用分区操作的两种典型场景是:
我们将在下文详细探讨这两种情况。
虽然分区可以帮助提高查询性能,但这在很大程度上取决于访问模式。如果查询只针对少数几个分区(理想情况下是一个),则性能有可能得到提升。仅当分区键不在主键中且你按该键进行过滤时,这通常才有意义。然而,需要扫描许多分区的查询,其性能可能比不使用分区时更差(因为可能会有更多的分区片段)。如果分区键已经是主键中的前置列,那么仅针对单个分区的收益会显著降低,甚至可以忽略不计。如果每个分区中的值是唯一的,分区还可以用于优化 GROUP BY 查询。但是,总体而言,你应确保主键已经过优化,并且仅在极少数场景下(访问模式始终针对数据中某个特定且可预测的子集)才将分区视为一种查询优化技术,例如按天分区,而大多数查询都集中在最近一天。有关此类行为的示例,请参见此文。
使用 TTL(Time-to-live)进行数据管理
Time-to-Live(TTL,生存时间)是在由 ClickHouse 驱动的可观测性解决方案中,用于高效进行数据保留与管理的关键特性,尤其适用于持续产生海量数据的场景。在 ClickHouse 中使用 TTL,可以自动使较旧的数据过期并删除,在无需人工干预的情况下实现存储资源的最优利用并保持性能稳定。此能力对于保持数据库精简、降低存储成本,以及通过聚焦最相关、最新的数据来确保查询始终快速高效至关重要。此外,它还通过系统化地管理数据生命周期,有助于遵循数据保留策略,从而提升可观测性解决方案的整体可持续性与可扩展性。
在 ClickHouse 中,TTL 可以在表级或列级进行指定。
表级 TTL
日志和追踪的默认 schema 都包含一个 TTL,用于在指定时间后自动清理数据。该配置在 ClickHouse exporter 中通过 ttl 键进行设置,例如:
exporters:
clickhouse:
endpoint: tcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1
ttl: 72h
此语法目前支持 Golang Duration 语法。我们建议用户使用 h,并确保其与分区周期保持一致。例如,如果按天分区,请确保该值是天数的倍数,例如 24h、48h、72h。 这样会自动为表添加一个 TTL 子句,例如当 ttl: 96h 时。
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
TTL toDateTime(Timestamp) + toIntervalDay(4)
SETTINGS ttl_only_drop_parts = 1
默认情况下,具有已过期 TTL 的数据会在 ClickHouse 合并数据分片 时被删除。当 ClickHouse 检测到数据已过期时,它会执行一次不在计划内的合并操作。
Scheduled TTLs
TTL 不是立即应用,而是按计划执行,如上所述。MergeTree 表设置 merge_with_ttl_timeout 用于设置在重复执行包含删除 TTL 的合并前的最小延迟时间(秒)。默认值是 14400 秒(4 小时)。但这只是最小延迟,TTL 合并被真正触发前可能需要更长时间。如果该值设置得太低,将会执行大量不在计划内的合并操作,消耗大量资源。可以通过命令 ALTER TABLE my_table MATERIALIZE TTL 强制触发 TTL 到期处理。
重要:我们推荐使用设置 ttl_only_drop_parts=1(默认模式中已应用)。启用该设置后,当一个数据分片中的所有行都已过期时,ClickHouse 会直接删除整个分片。相比于在 ttl_only_drop_parts=0 时通过资源消耗较大的 mutation 对 TTL 过期的行进行部分清理,删除整个分片可以缩短 merge_with_ttl_timeout 的时间,并降低对系统性能的影响。如果数据按与执行 TTL 过期相同的时间单位进行分区,例如按天分区,那么各个分片自然只会包含该时间区间的数据。这将确保可以高效地应用 ttl_only_drop_parts=1。
列级 TTL
上面的示例是在表级别设置数据过期。你也可以在列级别设置数据过期。随着数据变旧,可以用这种方式删除那些在排障或分析中价值不足以抵消其保留成本的列。例如,我们建议保留 Body 列,以防新增的动态元数据在插入时尚未被提取出来,比如一个新的 Kubernetes 标签。在经过一段时间(例如 1 个月)后,如果显然这些附加元数据并没有带来实际价值,那么继续保留 Body 列的意义就有限了。
下面展示了如何在 30 天后删除 Body 列。
CREATE TABLE otel_logs_v2
(
`Body` String TTL Timestamp + INTERVAL 30 DAY,
`Timestamp` DateTime,
...
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
注意
指定列级 TTL 时,用户需要自行定义表结构(schema)。这一点不能在 OTel collector 中进行配置。
重新压缩数据
虽然我们通常建议对可观测性数据集使用 ZSTD(1),但用户可以尝试不同的压缩算法或更高的压缩级别,例如 ZSTD(3)。除了在创建 schema 时进行指定外,还可以配置在经过一段预设时间后更改压缩方式。如果某种编解码器或压缩算法能带来更好的压缩率,但会导致较差的查询性能,那么这种配置可能是合适的。对于较旧的数据,由于查询不那么频繁,这种权衡是可以接受的;但对于近期数据,由于更频繁地在排障和调查中被使用,则通常不可接受。
下面给出了一个示例,我们在 4 天后使用 ZSTD(3) 对数据重新压缩,而不是将其删除。
CREATE TABLE default.otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
TTL Timestamp + INTERVAL 4 DAY RECOMPRESS CODEC(ZSTD(3))
评估性能
我们建议用户始终同时评估不同压缩级别和算法对写入和查询性能的影响。例如,delta 编码器在压缩时间戳时可能很有帮助。不过,如果时间戳是主键的一部分,那么过滤性能可能会下降。
有关配置 TTL 的更多详细信息和示例,请参见此处。关于如何为表和列添加和修改 TTL 的示例,请参见此处。关于 TTL 如何支持诸如冷热分层架构等存储层级,请参见存储层级。
存储分层
在 ClickHouse 中,用户可以在不同磁盘上创建存储分层,例如将热数据或近期数据存放在 SSD 上,而将较旧的数据存放在由 S3 支持的存储上。此架构可以让旧数据使用成本更低的存储,而这些数据由于在排障调查中使用频率较低,其查询 SLA 通常可以更宽松。
与 ClickHouse Cloud 无关
ClickHouse Cloud 使用由 S3 支持的单一数据副本,并在节点上使用基于 SSD 的缓存。因此,在 ClickHouse Cloud 中无需配置存储分层。
创建存储分层要求用户先创建磁盘,然后基于这些磁盘制定存储策略,其中的卷可以在建表时指定。数据可以根据填充率、数据部分大小和卷优先级在磁盘之间自动迁移。更多详细信息请参见此处。
虽然可以使用 ALTER TABLE MOVE PARTITION 命令在磁盘之间手动移动数据,但也可以使用 TTL 来控制数据在卷之间的迁移。完整示例请参见此处。
管理模式变更
在系统的整个生命周期中,日志和跟踪的模式不可避免地会发生变化,例如,当用户开始监控具有不同元数据或 pod(容器组)标签的新系统时。通过使用 OTel 模式生成数据,并以结构化格式捕获原始事件数据,ClickHouse 的模式将能较好地适应这些变化。然而,随着新的元数据出现以及查询访问模式发生变化,用户会希望更新模式以反映这些变化。
为在模式变更期间避免停机,用户有多种选项,我们将在下文中进行介绍。
使用默认值
可以使用 DEFAULT 值向 schema 添加列。如果在执行 INSERT 时未为该列显式指定值,则会使用配置的默认值。
可以在修改任何物化视图转换逻辑或 OTel collector 配置之前先进行 schema 更改,从而开始发送这些新列的数据。
一旦 schema 发生更改,你可以重新配置 OTel collectors。假设用户采用 "Extracting structure with SQL" 中推荐的流程,即让 OTel collectors 将数据发送到一个使用 Null 表引擎的表,并由一个物化视图负责提取目标 schema,并将结果发送到目标表进行存储,那么就可以使用 ALTER TABLE ... MODIFY QUERY 语法 来修改该视图。假设我们拥有如下的目标表及其对应的物化视图(类似于 "Extracting structure with SQL" 中使用的视图),用于从 OTel 结构化日志中提取目标 schema:
CREATE TABLE default.otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status']::UInt16 AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
假设我们希望从 LogAttributes 中提取一个名为 Size 的新列。我们可以使用 ALTER TABLE 将其添加到 schema 中,并指定默认值:
ALTER TABLE otel_logs_v2
(ADD COLUMN `Size` UInt64 DEFAULT JSONExtractUInt(Body, 'size'))
在上述示例中,我们将默认值指定为 LogAttributes 中 size 键对应的值(如果该键不存在,则为 0)。这意味着,对那些未插入该值的行访问该列的查询必须访问 Map,因此会更慢。我们也可以很容易地将其指定为一个常量,例如 0,从而降低后续针对未包含该值的行的查询成本。查询该表可以看到,该值会按预期从 Map 中填充:
SELECT Size
FROM otel_logs_v2
LIMIT 5
┌──Size─┐
│ 30577 │
│ 5667 │
│ 5379 │
│ 1696 │
│ 41483 │
└───────┘
5 rows in set. Elapsed: 0.012 sec.
为了确保今后插入的所有数据都包含该值,我们可以按下面所示使用 ALTER TABLE 语法来修改我们的物化视图:
ALTER TABLE otel_logs_mv
MODIFY QUERY
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status']::UInt16 AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
之后插入的行会在写入时自动填充 Size 列。
创建新表
作为上述流程的另一种选择,你可以直接使用新的 schema 创建一个新的目标表。然后,可以通过前面介绍的 ALTER TABLE MODIFY QUERY 修改任意物化视图以使用该新表。采用这种方式,你可以为表进行版本管理,例如 otel_logs_v3。
这种方式会让你拥有多个可查询的表。要在多个表之间进行查询,你可以使用 merge 函数,该函数接受带通配符的表名模式。下面我们通过同时查询 otel_logs 表的 v2 和 v3 版本来演示这一点:
SELECT Status, count() AS c
FROM merge('otel_logs_v[2|3]')
GROUP BY Status
ORDER BY c DESC
LIMIT 5
┌─Status─┬────────c─┐
│ 200 │ 38319300 │
│ 304 │ 1360912 │
│ 302 │ 799340 │
│ 404 │ 420044 │
│ 301 │ 270212 │
└────────┴──────────┘
5 rows in set. Elapsed: 0.137 sec. Processed 41.46 million rows, 82.92 MB (302.43 million rows/s., 604.85 MB/s.)
如果用户希望避免使用 merge 函数,同时向终端用户暴露一张汇总多张表数据的单一表,则可以使用 Merge 表引擎。示例如下:
CREATE TABLE otel_logs_merged
ENGINE = Merge('default', 'otel_logs_v[2|3]')
SELECT Status, count() AS c
FROM otel_logs_merged
GROUP BY Status
ORDER BY c DESC
LIMIT 5
┌─Status─┬────────c─┐
│ 200 │ 38319300 │
│ 304 │ 1360912 │
│ 302 │ 799340 │
│ 404 │ 420044 │
│ 301 │ 270212 │
└────────┴──────────┘
5 rows in set. Elapsed: 0.073 sec. Processed 41.46 million rows, 82.92 MB (565.43 million rows/s., 1.13 GB/s.)
每次添加新表时,都可以使用 EXCHANGE 表语法来完成更新。例如,要添加一个 v4 表,可以先创建一个新表,然后将其与上一版本的表进行原子交换。
CREATE TABLE otel_logs_merged_temp
ENGINE = Merge('default', 'otel_logs_v[2|3|4]')
EXCHANGE TABLE otel_logs_merged_temp AND otel_logs_merged
SELECT Status, count() AS c
FROM otel_logs_merged
GROUP BY Status
ORDER BY c DESC
LIMIT 5
┌─Status─┬────────c─┐
│ 200 │ 39259996 │
│ 304 │ 1378564 │
│ 302 │ 820118 │
│ 404 │ 429220 │
│ 301 │ 276960 │
└────────┴──────────┘
5 rows in set. Elapsed: 0.068 sec. Processed 42.46 million rows, 84.92 MB (620.45 million rows/s., 1.24 GB/s.)