什么是 ClickHouse?
ClickHouse® 是一款高性能的列式存储 SQL 数据库管理系统(DBMS),用于联机分析处理(OLAP)。它既可以作为开源软件,也可以作为云服务提供。
什么是分析?
Analytics(也称为 OLAP,即联机分析处理,Online Analytical Processing)是指在海量数据集上执行包含复杂计算(例如聚合、字符串处理、算术运算)的 SQL 查询。
与事务型查询(或 OLTP,Online Transaction Processing,即联机事务处理)不同,后者每个查询只读写少量行,因此可在毫秒级完成,而分析型查询通常需要处理数十亿乃至数万亿行数据。
在许多应用场景中,分析查询必须是“实时”的,即在不到一秒内返回结果。
行式存储 vs 列式存储
只有采用合适的数据组织方式,才能达到这样的性能水平。
数据库中的数据要么采用行式存储,要么采用列式存储。
在行式数据库中,连续的表行会一个接一个按顺序存储。这种布局可以快速检索整行数据,因为每一行的各个列值是存放在一起的。
ClickHouse 是一款列式数据库。在这类系统中,表是按列的集合来存储的,即每一列的值一个接一个按顺序存放。这种布局会让还原单行记录变得更困难(因为现在同一行的各个值之间存在间隔),但列级操作(例如过滤或聚合)会比在行式数据库中快得多。
下面通过一个在 1 亿行真实世界的匿名 Web 分析数据上运行的示例查询来最直观地说明这一差异:
你可以在 ClickHouse SQL Playground 上运行此查询,该查询从超过 100 个现有列中只选择并过滤其中少数几列,并在毫秒级内返回结果:
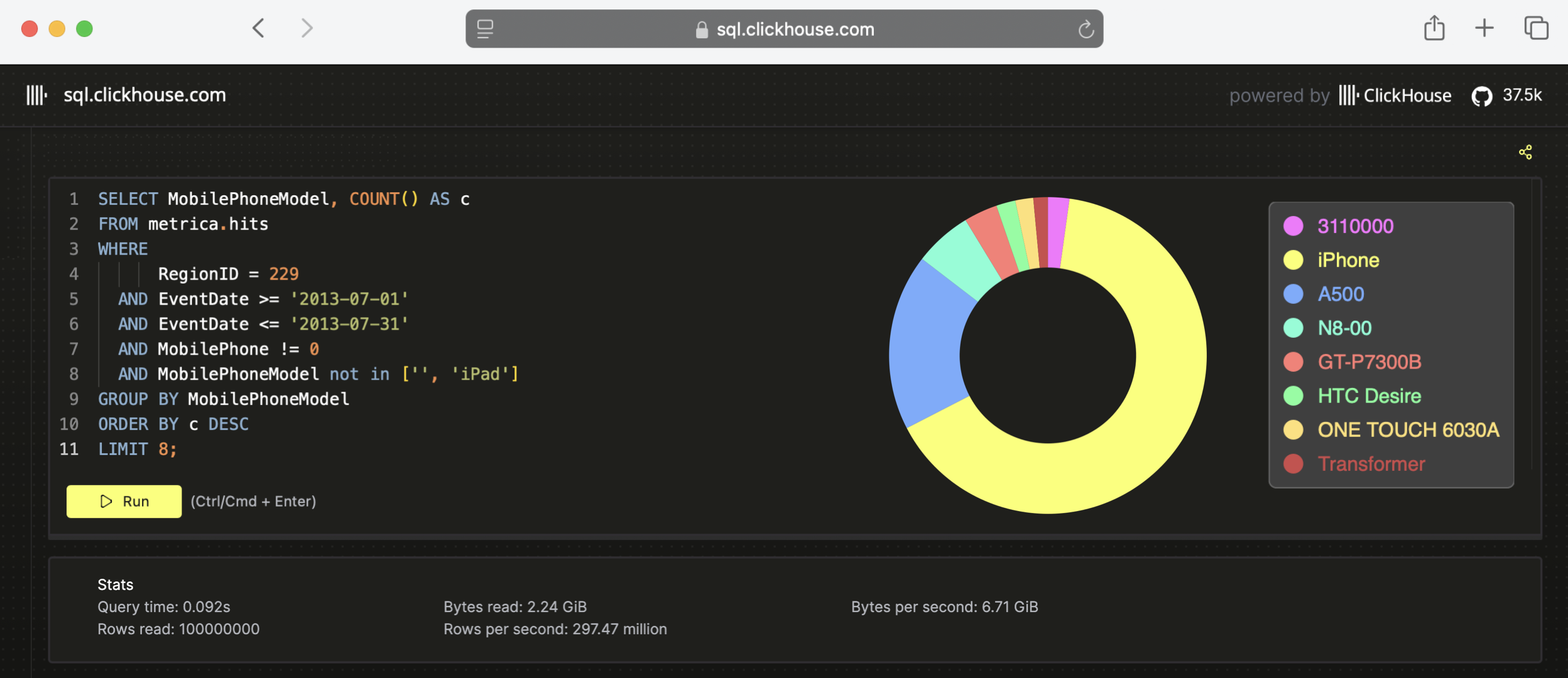
如上图的统计信息部分所示,该查询在 92 毫秒内处理了 1 亿行数据,吞吐量大约为每秒超过 10 亿行,或每秒接近 7 GB 的数据传输量。
行式 DBMS
在行式数据库中,即使上面的查询只处理现有列中的一小部分,系统仍然需要将其他现有列的数据从磁盘加载到内存中。原因在于,数据在磁盘上是以称为块的片段进行存储(通常为固定大小,例如 4 KB 或 8 KB)。块是从磁盘读取到内存的数据的最小单位。当应用程序或数据库请求数据时,操作系统的磁盘 I/O 子系统会从磁盘读取所需的块。即使只需要块的一部分,整个块也会被读入内存(这是由磁盘和文件系统的设计决定的):
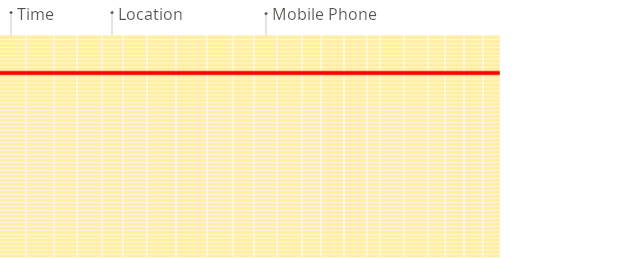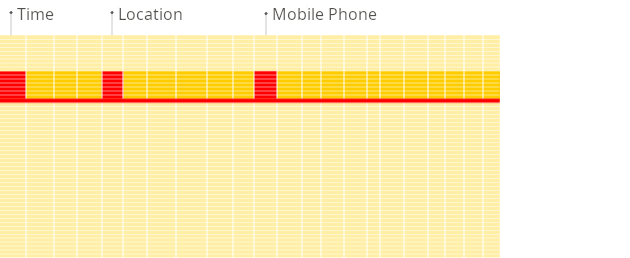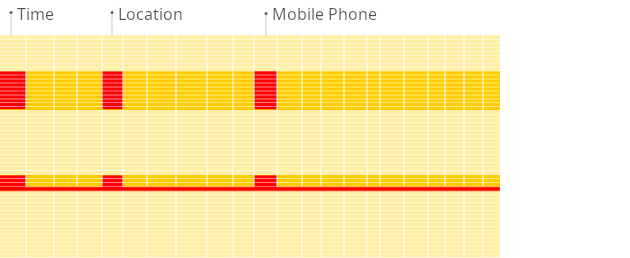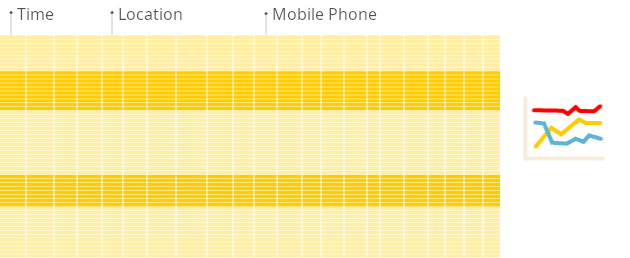
列式 DBMS
由于每一列的值在磁盘上依次顺序存储,执行上面的查询时不会加载不必要的数据。 由于按数据块进行存储并从磁盘传输到内存的方式与分析型查询的数据访问模式相匹配,查询只会从磁盘读取所需的列,从而避免为未使用的数据执行不必要的 I/O 操作。相比之下,在基于行的存储中,会读取整行数据(包括无关的列),效率要低得多:
数据复制与完整性
ClickHouse 使用异步多主复制架构,确保数据在多个节点上冗余存储。数据写入任一可用副本后,其余所有副本会在后台获取各自的副本数据。系统会在不同副本上维护完全一致的数据。在大多数故障情况下,系统能够自动完成恢复;在复杂场景下,则采用半自动方式完成恢复。
基于角色的访问控制
ClickHouse 通过 SQL 查询实现用户账号管理,并支持配置基于角色的访问控制,方式类似于 ANSI SQL 标准和主流关系型数据库管理系统中的实现。
SQL 支持
ClickHouse 支持一种基于 SQL 的声明式查询语言,在很多方面与 ANSI SQL 标准保持一致。支持的查询子句包括 GROUP BY、ORDER BY、FROM 中的子查询、JOIN 子句、IN 运算符、窗口函数 以及标量子查询。
近似计算
ClickHouse 提供了一些以精度换取性能的方式。例如,其中一些聚合函数可以近似计算不同值的数量、中位数和分位数。此外,可以在数据的一个样本上执行查询,从而快速得到近似结果。最后,可以只在有限数量的键上执行聚合,而不是对所有键进行聚合。根据键分布偏斜程度的不同,这种方式在显著减少相较于精确计算所需资源的同时,仍然可以提供相当精确的结果。
自适应 Join 算法
ClickHouse 会自适应地选择 join 算法:它首先使用快速的哈希 join,当存在多张大表时,会回退为合并 join。
卓越的查询性能
ClickHouse 以其极快的查询性能而闻名。 要了解 ClickHouse 为何如此之快,请参阅 Why is ClickHouse fast? 指南。
