你可以将 S3 中的数据写入 ClickHouse,也可以将 S3 用作导出目标,从而与“数据湖”(Data Lake)架构进行集成。此外,S3 还可以作为“冷”存储层,并有助于实现存储与计算的分离。在下文中,我们使用纽约市出租车数据集演示在 S3 与 ClickHouse 之间迁移数据的过程,说明关键配置参数,并给出性能优化建议。
S3 表函数
s3 表函数允许在 S3 兼容存储中读取和写入文件。该语法的大致结构如下:
s3(path, [aws_access_key_id, aws_secret_access_key,] [format, [structure, [compression]]])
其中:
- path — 带有文件路径的 Bucket URL。仅在只读模式下支持以下通配符:
*、?、{abc,def} 和 {N..M},其中 N、M 为数字,'abc'、'def' 为字符串。更多信息,参见在 path 中使用通配符的文档。
- format — 文件的格式。
- structure — 表的结构。格式为
'column1_name column1_type, column2_name column2_type, ...'。
- compression — 可选参数。支持的参数值:
none、gzip/gz、brotli/br、xz/LZMA、zstd/zst。默认情况下,会根据文件扩展名自动检测压缩类型。
在路径表达式中使用通配符可以引用多个文件,并为并行处理创造条件。
准备工作
在 ClickHouse 中创建表之前,您可能需要先仔细查看一下 S3 存储桶中的数据。您可以直接在 ClickHouse 中使用 DESCRIBE 语句来完成这一操作:
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames');
DESCRIBE TABLE 语句的输出应当显示 ClickHouse 将如何自动推断这些数据,就如同在 S3 存储桶中看到的一样。请注意,它还会自动识别 gzip 压缩格式并进行解压:
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') SETTINGS describe_compact_output=1
┌─name──────────────────┬─type───────────────┐
│ trip_id │ Nullable(Int64) │
│ vendor_id │ Nullable(Int64) │
│ pickup_date │ Nullable(Date) │
│ pickup_datetime │ Nullable(DateTime) │
│ dropoff_date │ Nullable(Date) │
│ dropoff_datetime │ Nullable(DateTime) │
│ store_and_fwd_flag │ Nullable(Int64) │
│ rate_code_id │ Nullable(Int64) │
│ pickup_longitude │ Nullable(Float64) │
│ pickup_latitude │ Nullable(Float64) │
│ dropoff_longitude │ Nullable(Float64) │
│ dropoff_latitude │ Nullable(Float64) │
│ passenger_count │ Nullable(Int64) │
│ trip_distance │ Nullable(String) │
│ fare_amount │ Nullable(String) │
│ extra │ Nullable(String) │
│ mta_tax │ Nullable(String) │
│ tip_amount │ Nullable(String) │
│ tolls_amount │ Nullable(Float64) │
│ ehail_fee │ Nullable(Int64) │
│ improvement_surcharge │ Nullable(String) │
│ total_amount │ Nullable(String) │
│ payment_type │ Nullable(String) │
│ trip_type │ Nullable(Int64) │
│ pickup │ Nullable(String) │
│ dropoff │ Nullable(String) │
│ cab_type │ Nullable(String) │
│ pickup_nyct2010_gid │ Nullable(Int64) │
│ pickup_ctlabel │ Nullable(Float64) │
│ pickup_borocode │ Nullable(Int64) │
│ pickup_ct2010 │ Nullable(String) │
│ pickup_boroct2010 │ Nullable(String) │
│ pickup_cdeligibil │ Nullable(String) │
│ pickup_ntacode │ Nullable(String) │
│ pickup_ntaname │ Nullable(String) │
│ pickup_puma │ Nullable(Int64) │
│ dropoff_nyct2010_gid │ Nullable(Int64) │
│ dropoff_ctlabel │ Nullable(Float64) │
│ dropoff_borocode │ Nullable(Int64) │
│ dropoff_ct2010 │ Nullable(String) │
│ dropoff_boroct2010 │ Nullable(String) │
│ dropoff_cdeligibil │ Nullable(String) │
│ dropoff_ntacode │ Nullable(String) │
│ dropoff_ntaname │ Nullable(String) │
│ dropoff_puma │ Nullable(Int64) │
└───────────────────────┴────────────────────┘
为了与基于 S3 的数据集进行交互,我们准备一个标准的 MergeTree 表作为目标表。以下语句在默认数据库中创建一个名为 trips 的表。请注意,我们选择对上面推断出的部分数据类型做了一些修改,特别是不使用 Nullable() 数据类型修饰符,因为它可能会导致不必要的额外数据存储以及一定的性能开销:
CREATE TABLE trips
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` String,
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` String,
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
请注意在 pickup_date 字段上使用了分区。通常分区键用于数据管理,但稍后我们将使用这个键来实现向 S3 的并行写入。
我们的出租车数据集中的每一条记录都对应一次出租车行程。该匿名化数据包含 2000 万条记录,压缩存储在 S3 bucket https://datasets-documentation.s3.eu-west-3.amazonaws.com/ 下的 nyc-taxi 目录中。数据为 TSV 格式,每个文件大约包含 100 万行。
从 S3 读取数据
我们可以将 S3 中的数据作为数据源进行查询,而无需在 ClickHouse 中进行持久化。在下面的查询中,我们抽取 10 行数据作为样本。请注意,这里没有提供凭据,因为该存储桶是公开可访问的:
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames')
LIMIT 10;
请注意,我们不需要显式列出列名,因为 TabSeparatedWithNames 格式会在第一行中包含列名。其他格式(例如 CSV 或 TSV)在执行此查询时将返回自动生成的列名,例如 c1、c2、c3 等。
查询还支持虚拟列,例如 _path 和 _file,它们分别提供有关存储桶路径和文件名的信息。例如:
SELECT _path, _file, trip_id
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_0.gz', 'TabSeparatedWithNames')
LIMIT 5;
┌─_path──────────────────────────────────────┬─_file──────┬────trip_id─┐
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999902 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999919 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999944 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999969 │
│ datasets-documentation/nyc-taxi/trips_0.gz │ trips_0.gz │ 1199999990 │
└────────────────────────────────────────────┴────────────┴────────────┘
确认此示例数据集中的行数。注意这里使用了通配符进行文件展开,因此会包含全部二十个文件。此查询大约需要 10 秒,具体时间取决于 ClickHouse 实例上的 CPU 核心数量:
SELECT count() AS count
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames');
┌────count─┐
│ 20000000 │
└──────────┘
虽然直接从 S3 读取数据在采样数据和执行临时的探索性查询时很有用,但并不适合经常这样做。当需要进行更严肃的分析时,请将数据导入 ClickHouse 中的 MergeTree 表。
使用 clickhouse-local
clickhouse-local 程序使您无需部署和配置 ClickHouse 服务器即可对本地文件进行快速处理。任何使用 s3 表函数的查询都可以通过该工具执行。例如:
clickhouse-local --query "SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') LIMIT 10"
从 S3 插入数据
为了充分发挥 ClickHouse 的全部能力,接下来我们将在实例中读取并插入这些数据。
我们将 s3 函数与一个简单的 INSERT 语句结合使用来完成此操作。请注意,我们不需要显式列出列名,因为目标表已经定义了所需的结构。这要求列的顺序与表的 DDL 语句中指定的顺序一致:列会根据它们在 SELECT 子句中的位置进行映射。插入全部 1000 万行数据可能需要几分钟,具体取决于 ClickHouse 实例的情况。下面的示例仅插入 100 万行,以确保能够快速得到响应。可根据需要调整 LIMIT 子句或列选择来导入数据子集:
INSERT INTO trips
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames')
LIMIT 1000000;
使用 ClickHouse Local 进行远程写入
如果网络安全策略阻止您的 ClickHouse 集群发起出站连接,您可以使用 clickhouse-local 将 S3 中的数据插入到 ClickHouse 中。下面的示例中,我们从一个 S3 存储桶读取数据,并使用 remote 函数将其插入到 ClickHouse 中:
clickhouse-local --query "INSERT INTO TABLE FUNCTION remote('localhost:9000', 'default.trips', 'username', 'password') (*) SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz', 'TabSeparatedWithNames') LIMIT 10"
注意
若要通过安全的 SSL 连接执行上述操作,请使用 remoteSecure 函数。
导出数据
可以使用 s3 表函数向 S3 中的文件写入数据。这需要相应的权限。我们在请求中传递所需的凭据,但请参阅 管理凭据 页面了解更多选项。
在下面的简单示例中,我们将该表函数用作目标而不是源。这里我们从 trips 表向一个 bucket 流式写入 10,000 行数据,指定使用 lz4 压缩和 CSV 输出格式:
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
SELECT *
FROM trips
LIMIT 10000;
注意这里文件的格式是根据文件扩展名自动推断出来的。我们也不需要在 s3 表函数中指定列——这同样可以从 SELECT 中推断出来。
拆分大文件
您通常不会希望将数据导出为单个文件。大多数工具(包括 ClickHouse)在读写多个文件时会获得更高的吞吐性能,因为可以利用并行处理。我们可以多次执行 INSERT 命令,每次只处理数据的一个子集。ClickHouse 提供了一种使用 PARTITION 键自动拆分文件的机制。
在下面的示例中,我们通过对 rand() 函数取模运算来创建十个文件。请注意生成的分区 ID 是如何体现在文件名中的。这样会生成十个带有数字后缀的文件,例如 trips_0.csv.lz4、trips_1.csv.lz4 等等:
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips_{_partition_id}.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
PARTITION BY rand() % 10
SELECT *
FROM trips
LIMIT 100000;
或者,我们也可以使用数据中的某个字段。对于这个数据集,payment_type 是一个自然的分区键,其基数为 5。
INSERT INTO FUNCTION
s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/csv/trips_{_partition_id}.csv.lz4',
's3_key',
's3_secret',
'CSV'
)
PARTITION BY payment_type
SELECT *
FROM trips
LIMIT 100000;
利用集群
上述函数都仅限在单个节点上执行。读取速度会随 CPU 核心数线性提升,直到其他资源(通常是网络)达到饱和,从而支持用户进行纵向扩展。然而,这种方式存在局限性。尽管您在执行 INSERT INTO SELECT 查询时,可以通过插入到分布式表来缓解部分资源压力,但仍然只由单个节点负责读取、解析和处理数据。为了解决这一问题并实现读取的横向扩展,我们提供了 s3Cluster 函数。
接收查询的节点(称为发起者节点 initiator)会与集群中的每个节点建立连接。用于确定需要读取哪些文件的 glob 模式会被解析为一组文件。发起者节点将文件分发给集群中的节点,这些节点作为工作节点(workers)运行。工作节点在完成当前读取后,会请求更多文件进行处理。该过程确保我们可以对读取进行横向扩展。
s3Cluster 函数的格式与单节点版本相同,只是需要指定一个目标集群来标识工作节点:
s3Cluster(cluster_name, source, [access_key_id, secret_access_key,] format, structure)
cluster_name — 用于构建远程和本地服务器地址集合及连接参数的集群名称。source — 指向单个文件或一组文件的 URL。仅在只读模式下支持以下通配符:*、?、{'abc','def'} 和 {N..M},其中 N、M 为数字,abc、def 为字符串。更多信息参见 路径中的通配符。access_key_id 和 secret_access_key — 指定在给定端点上使用的凭证密钥。可选。format — 文件的格式。structure — 表的结构。格式为 'column1_name column1_type, column2_name column2_type, ...'。
与其他任意 s3 函数一样,如果 bucket 为非安全(公开)或通过环境(例如 IAM 角色)提供访问权限,则凭证为可选项。但与 s3 函数不同的是,自 22.3.1 起,必须在请求中显式指定 structure,即不会自动推断表结构(schema)。
在大多数情况下,该函数将作为 INSERT INTO SELECT 的一部分使用。在这种场景下,通常会向一个分布式表写入数据。下面通过一个简单示例进行说明,其中 trips_all 是一个分布式表。尽管此表使用 events 集群,但读写操作使用的节点之间无需保证一致性:
INSERT INTO default.trips_all
SELECT *
FROM s3Cluster(
'events',
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_*.gz',
'TabSeparatedWithNames'
)
写入会在发起者节点上执行。这意味着虽然每个节点都会参与读取,但生成的行会被路由回发起者节点,由其负责分发。在高吞吐量场景中,这可能会成为瓶颈。为了解决这一问题,请为 s3cluster 函数设置参数 parallel_distributed_insert_select。
S3 表引擎
虽然 s3 函数允许对存储在 S3 中的数据执行即席查询,但在语法上比较冗长。S3 表引擎让你无需反复指定 bucket 的 URL 和凭证。为此,ClickHouse 提供了 S3 表引擎。
CREATE TABLE s3_engine_table (name String, value UInt32)
ENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, [compression])
[SETTINGS ...]
path — 带文件路径的 bucket URL。只读模式下支持以下通配符:*、?、{abc,def} 和 {N..M},其中 N、M 为数字,'abc'、'def' 为字符串。更多信息请参阅此处。format — 文件的格式。aws_access_key_id, aws_secret_access_key - AWS 账户中用户的长期凭证。可以使用这些凭证对请求进行身份验证。该参数为可选项。如果未指定凭证,则使用配置文件中的值。更多信息请参阅管理凭证。compression — 压缩类型。支持的值:none、gzip/gz、brotli/br、xz/LZMA、zstd/zst。该参数为可选项。默认情况下,会根据文件扩展名自动检测压缩类型。
读取数据
在以下示例中,我们创建一个名为 trips_raw 的表,使用位于 https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/ 存储桶中的前十个 TSV 文件。每个文件都包含 100 万行数据:
CREATE TABLE trips_raw
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_date` Date,
`dropoff_datetime` DateTime,
`store_and_fwd_flag` UInt8,
`rate_code_id` UInt8,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`fare_amount` Float32,
`extra` Float32,
`mta_tax` Float32,
`tip_amount` Float32,
`tolls_amount` Float32,
`ehail_fee` Float32,
`improvement_surcharge` Float32,
`total_amount` Float32,
`payment_type_` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4),
`trip_type` UInt8,
`pickup` FixedString(25),
`dropoff` FixedString(25),
`cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3),
`pickup_nyct2010_gid` Int8,
`pickup_ctlabel` Float32,
`pickup_borocode` Int8,
`pickup_ct2010` String,
`pickup_boroct2010` FixedString(7),
`pickup_cdeligibil` String,
`pickup_ntacode` FixedString(4),
`pickup_ntaname` String,
`pickup_puma` UInt16,
`dropoff_nyct2010_gid` UInt8,
`dropoff_ctlabel` Float32,
`dropoff_borocode` UInt8,
`dropoff_ct2010` String,
`dropoff_boroct2010` FixedString(7),
`dropoff_cdeligibil` String,
`dropoff_ntacode` FixedString(4),
`dropoff_ntaname` String,
`dropoff_puma` UInt16
) ENGINE = S3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{0..9}.gz', 'TabSeparatedWithNames', 'gzip');
请注意使用 {0..9} 模式将范围限定为前十个文件。创建完成后,我们就可以像查询其他表一样查询此表:
SELECT DISTINCT(pickup_ntaname)
FROM trips_raw
LIMIT 10;
┌─pickup_ntaname───────────────────────────────────┐
│ Lenox Hill-Roosevelt Island │
│ Airport │
│ SoHo-TriBeCa-Civic Center-Little Italy │
│ West Village │
│ Chinatown │
│ Hudson Yards-Chelsea-Flatiron-Union Square │
│ Turtle Bay-East Midtown │
│ Upper West Side │
│ Murray Hill-Kips Bay │
│ DUMBO-Vinegar Hill-Downtown Brooklyn-Boerum Hill │
└──────────────────────────────────────────────────┘
插入数据
S3 表引擎支持并行读取。仅当表定义中不包含通配符模式时才支持写入。因此,上面的表将无法进行写入。
为了演示写入操作,创建一个指向可写的 S3 bucket 的表:
CREATE TABLE trips_dest
(
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`tip_amount` Float32,
`total_amount` Float32
) ENGINE = S3('<bucket path>/trips.bin', 'Native');
INSERT INTO trips_dest
SELECT
trip_id,
pickup_date,
pickup_datetime,
dropoff_datetime,
tip_amount,
total_amount
FROM trips
LIMIT 10;
SELECT * FROM trips_dest LIMIT 5;
┌────trip_id─┬─pickup_date─┬─────pickup_datetime─┬────dropoff_datetime─┬─tip_amount─┬─total_amount─┐
│ 1200018648 │ 2015-07-01 │ 2015-07-01 00:00:16 │ 2015-07-01 00:02:57 │ 0 │ 7.3 │
│ 1201452450 │ 2015-07-01 │ 2015-07-01 00:00:20 │ 2015-07-01 00:11:07 │ 1.96 │ 11.76 │
│ 1202368372 │ 2015-07-01 │ 2015-07-01 00:00:40 │ 2015-07-01 00:05:46 │ 0 │ 7.3 │
│ 1200831168 │ 2015-07-01 │ 2015-07-01 00:01:06 │ 2015-07-01 00:09:23 │ 2 │ 12.3 │
│ 1201362116 │ 2015-07-01 │ 2015-07-01 00:01:07 │ 2015-07-01 00:03:31 │ 0 │ 5.3 │
└────────────┴─────────────┴─────────────────────┴─────────────────────┴────────────┴──────────────┘
请注意,行只能插入到新文件中。不存在合并周期或文件拆分操作。一旦文件写入完成,后续插入将会失败。用户在此有两种选择:
- 指定设置
s3_create_new_file_on_insert=1。这会在每次插入时创建一个新文件。每个文件名末尾都会追加一个数值后缀,并且该数值会随每次插入操作单调递增。对于上面的示例,后续插入将会创建一个 trips_1.bin 文件。
- 指定设置
s3_truncate_on_insert=1。这会在插入时截断文件,即操作完成后,文件中只包含新插入的行。
这两个设置的默认值都是 0,因此会强制用户显式设置其中一个。当两者都被设置时,s3_truncate_on_insert 将优先生效。
关于 S3 表引擎的一些说明:
- 与传统的
MergeTree 系列表不同,删除一个 S3 表不会删除其底层数据。
- 此表类型的完整设置可以在此处找到。
- 使用此引擎时需注意以下限制:
- 不支持 ALTER 查询
- 不支持 SAMPLE 操作
- 不存在索引的概念,即无主键索引或跳过索引。
管理凭证
在前面的示例中,我们在 s3 函数或 S3 表定义中传递了凭证。虽然这在偶尔使用时可能可以接受,但在生产环境中,用户需要不那么显式的认证机制。为此,ClickHouse 提供了多种选项:
-
在 config.xml 或 conf.d 下的等效配置文件中指定连接详细信息。下面显示了一个示例文件的内容,假设是使用 debian 软件包进行安装。
ubuntu@single-node-clickhouse:/etc/clickhouse-server/config.d$ cat s3.xml
<clickhouse>
<s3>
<endpoint-name>
<endpoint>https://dalem-files.s3.amazonaws.com/test/</endpoint>
<access_key_id>key</access_key_id>
<secret_access_key>secret</secret_access_key>
<!-- <use_environment_credentials>false</use_environment_credentials> -->
<!-- <header>Authorization: Bearer SOME-TOKEN</header> -->
</endpoint-name>
</s3>
</clickhouse>
对于任何请求,只要其 URL 以上述端点为精确前缀,就会使用这些凭证。另外,请注意,在此示例中可以声明 Authorization 请求头,作为访问密钥 ID 和秘密访问密钥的替代方案。支持的完整设置列表可在此处找到。
-
上面的示例强调了配置参数 use_environment_credentials 的可用性。此配置参数也可以在全局 s3 级别进行设置:
<clickhouse>
<s3>
<use_environment_credentials>true</use_environment_credentials>
</s3>
</clickhouse>
此设置会启用从环境中获取 S3 凭证的尝试,从而允许通过 IAM 角色进行访问。具体而言,将按以下顺序进行检索:
- 查找环境变量
AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY 和 AWS_SESSION_TOKEN
- 在 $HOME/.aws 中进行检查
- 通过 AWS Security Token Service 获取临时凭证,即通过
AssumeRole API
- 检查 ECS 环境变量
AWS_CONTAINER_CREDENTIALS_RELATIVE_URI 或 AWS_CONTAINER_CREDENTIALS_FULL_URI 以及 AWS_ECS_CONTAINER_AUTHORIZATION_TOKEN 中的凭证。
- 如果 AWS_EC2_METADATA_DISABLED 未设置为 true,则通过 Amazon EC2 实例元数据 获取凭证。
- 对于特定端点,也可以使用相同的前缀匹配规则来设置这些相同的配置。
有关如何使用 S3 函数优化读取和写入操作,请参阅专门的性能指南。
S3 存储调优
在内部实现中,ClickHouse MergeTree 使用两种主要的存储格式:Wide 和 Compact。当前实现采用 ClickHouse 的默认行为(通过设置 min_bytes_for_wide_part 和 min_rows_for_wide_part 进行控制),但我们预计在未来版本中,对于 S3 的行为会有所差异,例如提高 min_bytes_for_wide_part 的默认值,以鼓励更多采用 Compact 格式,从而减少文件数量。在仅使用 S3 存储时,您现在可能希望调整这些设置。
基于 S3 的 MergeTree
s3 函数及其相关的表引擎允许我们使用熟悉的 ClickHouse 语法查询 S3 中的数据。不过,在数据管理特性和性能方面,它们存在一定局限:不支持主索引、不支持缓存,而且文件写入需要由用户自行管理。
ClickHouse 意识到,S3 是一种极具吸引力的存储方案,尤其适用于对“冷”数据查询性能要求不高、并且用户希望实现存储与计算分离的场景。为此,ClickHouse 支识将 S3 作为 MergeTree 引擎的底层存储。这使你既能利用 S3 的扩展性和成本优势,又能获得 MergeTree 引擎在写入和查询方面的性能表现。
存储层级
ClickHouse 存储卷允许将物理磁盘从 MergeTree 表引擎中抽象出来。任何单个卷可以由按顺序排列的一组磁盘组成。除了主要用于将多个块设备统一用于数据存储之外,这种抽象还允许使用其他类型的存储,包括 S3。根据存储策略和写满率 (fill rate) ,可以在不同卷之间迁移 ClickHouse 的数据分区片段,从而形成存储层级 (storage tiers) 的概念。
存储层级支持冷热分层架构:最新的数据通常也是查询最频繁的数据,只需要占用少量高性能存储空间,例如 NVMe SSD。随着数据变旧,针对查询时间的 SLA 要求会放宽,查询频率也会下降。这部分“长尾”数据可以存放在速度较慢、性能较低的存储上,例如 HDD,或对象存储 (如 S3) 。
创建磁盘
要将一个 S3 bucket 作为磁盘使用,首先必须在 ClickHouse 配置文件中声明它。可以扩展 config.xml,或者更推荐在 conf.d 目录下提供一个新文件。下面是一个 S3 磁盘声明的示例:
<clickhouse>
<storage_configuration>
...
<disks>
<s3>
<type>s3</type>
<endpoint>https://sample-bucket.s3.us-east-2.amazonaws.com/tables/</endpoint>
<access_key_id>your_access_key_id</access_key_id>
<secret_access_key>your_secret_access_key</secret_access_key>
<region></region>
<metadata_path>/var/lib/clickhouse/disks/s3/</metadata_path>
</s3>
<s3_cache>
<type>cache</type>
<disk>s3</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
...
</storage_configuration>
</clickhouse>
与此磁盘定义相关的完整设置列表可以在此处找到。请注意,可以使用管理凭证中描述的相同方法在此处管理凭证,即在上述设置块中将 use_environment_credentials 设置为 true 以使用 IAM 角色。
创建存储策略
配置完成后,此“磁盘”可以被策略中声明的存储卷使用。对于下面的示例,我们假设 S3 是我们唯一的存储。这不考虑更复杂的冷热分层架构,在这些架构中,数据可以基于 TTL 规则和写满率进行迁移。
<clickhouse>
<storage_configuration>
<disks>
<s3>
...
</s3>
<s3_cache>
...
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
创建表
假设你已将磁盘配置为使用具有写权限的 bucket,你应该可以像下面示例那样创建一个表。为简洁起见,我们只使用 NYC 出租车数据集中的部分列,并将数据以流式方式直接写入以 S3 为后端的表中:
CREATE TABLE trips_s3
(
`trip_id` UInt32,
`pickup_date` Date,
`pickup_datetime` DateTime,
`dropoff_datetime` DateTime,
`pickup_longitude` Float64,
`pickup_latitude` Float64,
`dropoff_longitude` Float64,
`dropoff_latitude` Float64,
`passenger_count` UInt8,
`trip_distance` Float64,
`tip_amount` Float32,
`total_amount` Float32,
`payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime
SETTINGS storage_policy='s3_main'
INSERT INTO trips_s3 SELECT trip_id, pickup_date, pickup_datetime, dropoff_datetime, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, passenger_count, trip_distance, tip_amount, total_amount, payment_type FROM s3('https://ch-nyc-taxi.s3.eu-west-3.amazonaws.com/tsv/trips_{0..9}.tsv.gz', 'TabSeparatedWithNames') LIMIT 1000000;
取决于硬件配置,后一次插入 100 万行数据可能需要几分钟才能完成。你可以通过 system.processes 表来查看进度。你也可以在不超过 1000 万行的前提下自由调整行数,并尝试运行一些示例查询。
SELECT passenger_count, avg(tip_amount) AS avg_tip, avg(total_amount) AS avg_amount FROM trips_s3 GROUP BY passenger_count;
修改表
有时你可能需要修改某个特定表的存储策略。虽然可以这样做,但会有一定限制。新的目标策略必须包含先前策略中的所有磁盘和卷,也就是说,不会通过迁移数据来满足策略变更。在验证这些约束时,将通过名称来识别卷和磁盘,任何试图违反约束的操作都会导致错误。不过,如果你沿用前面示例中的配置,则可以进行如下变更。
<policies>
<s3_main>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3_main>
<s3_tiered>
<volumes>
<hot>
<disk>default</disk>
</hot>
<main>
<disk>s3</disk>
</main>
</volumes>
<move_factor>0.2</move_factor>
</s3_tiered>
</policies>
ALTER TABLE trips_s3 MODIFY SETTING storage_policy='s3_tiered'
在这里,我们在新的 s3_tiered 策略中复用主卷,并引入一个新的热卷。这里使用的是默认磁盘,它只是一个通过参数 <path> 配置的单一磁盘。请注意,我们的卷名称和磁盘并未改变。新插入到该表的数据将会写入默认磁盘,直到其达到 move_factor * disk_size,此时数据将被迁移到 S3。
处理复制
可以通过使用 ReplicatedMergeTree 表引擎实现基于 S3 磁盘的复制。有关详细信息,请参阅使用 S3 对象存储在两个 AWS 区域之间复制单个分片指南。
读与写
以下说明涵盖了 ClickHouse 与 S3 交互的实现细节。虽然主要只是提供信息,但在优化性能时可能会有所帮助:
- 默认情况下,查询处理流水线任意阶段可使用的查询处理线程最大数量等于 CPU 核心数。某些阶段比其他阶段更易并行化,因此该值只是一个上限。由于数据是以流式方式从磁盘读取,多个查询阶段可能会同时执行,因此查询实际使用的线程数可能会超过该值。可通过设置 max_threads 进行修改。
- 默认情况下,对 S3 的读取是异步的。该行为由设置
remote_filesystem_read_method 决定,其默认值为 threadpool。在处理请求时,ClickHouse 会按条带(stripe)读取粒度(granule)。每个条带可能包含许多列。一个线程会逐个读取其粒度对应的列。与同步地逐列读取相比,系统会在等待数据之前,为所有列提前发起预取(prefetch)。与对每一列进行同步等待相比,这种方式能显著提升性能。在大多数情况下,无需更改该设置——参见 Optimizing for Performance。
- 写入操作是并行执行的,最多使用 100 个并发文件写入线程。
max_insert_delayed_streams_for_parallel_write 的默认值为 1000,用于控制并行写入的 S3 blob 数量。由于每个正在写入的文件都需要一个缓冲区(约 1MB),这在实际中限制了单次 INSERT 的内存消耗。在服务器内存较低的场景下,适当降低该值可能更为合适。
将 S3 对象存储用作 ClickHouse 磁盘
如果你需要关于创建 bucket 和 IAM 角色的分步指南,请参阅《如何创建 AWS IAM 用户和 S3 bucket》。
以下示例基于以服务方式安装的 Linux Deb 软件包,并使用默认的 ClickHouse 目录。
- 在 ClickHouse 的
config.d 目录下创建一个新文件,用于保存存储配置。
vim /etc/clickhouse-server/config.d/storage_config.xml
- 在存储配置中添加以下内容,并将其中的 bucket 路径、access key 和 secret key 替换为前面步骤中获得的值
<clickhouse>
<storage_configuration>
<disks>
<s3_disk>
<type>s3</type>
<endpoint>https://mars-doc-test.s3.amazonaws.com/clickhouse3/</endpoint>
<access_key_id>ABC123</access_key_id>
<secret_access_key>Abc+123</secret_access_key>
<metadata_path>/var/lib/clickhouse/disks/s3_disk/</metadata_path>
</s3_disk>
<s3_cache>
<type>cache</type>
<disk>s3_disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3_disk</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
注意
<disks> 标签内的 s3_disk 和 s3_cache 是任意标签名称。它们可以设置为其他名称,但在 <policies> 标签下的 <disk> 标签中引用该磁盘时,必须使用相同的标签名称。
<S3_main> 标签同样是任意的,它是策略名称,在 ClickHouse 中创建资源时,将作为标识符所对应的存储目标使用。
上面展示的配置适用于 ClickHouse 22.8 或更高版本,如果您使用的是更早的版本,请参阅 storing data 文档。
有关使用 S3 的更多信息:
集成指南:S3 Backed MergeTree
- 将该文件的所有者更新为
clickhouse 用户和用户组
chown clickhouse:clickhouse /etc/clickhouse-server/config.d/storage_config.xml
- 重启 ClickHouse 实例以使更改生效。
service clickhouse-server restart
- 使用 ClickHouse 客户端登录,例如执行以下命令
clickhouse-client --user default --password ClickHouse123!
- 创建表并指定新的 S3 存储策略
CREATE TABLE s3_table1
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS storage_policy = 's3_main';
- 验证该表已使用正确的策略创建
SHOW CREATE TABLE s3_table1;
┌─statement────────────────────────────────────────────────────
│ CREATE TABLE default.s3_table1
(
`id` UInt64,
`column1` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS storage_policy = 's3_main', index_granularity = 8192
└──────────────────────────────────────────────────────────────
- 向表中插入测试行
INSERT INTO s3_table1
(id, column1)
VALUES
(1, 'abc'),
(2, 'xyz');
INSERT INTO s3_table1 (id, column1) FORMAT Values
Query id: 0265dd92-3890-4d56-9d12-71d4038b85d5
Ok.
2 rows in set. Elapsed: 0.337 sec.
- 查看数据行
┌─id─┬─column1─┐
│ 1 │ abc │
│ 2 │ xyz │
└────┴─────────┘
2 rows in set. Elapsed: 0.284 sec.
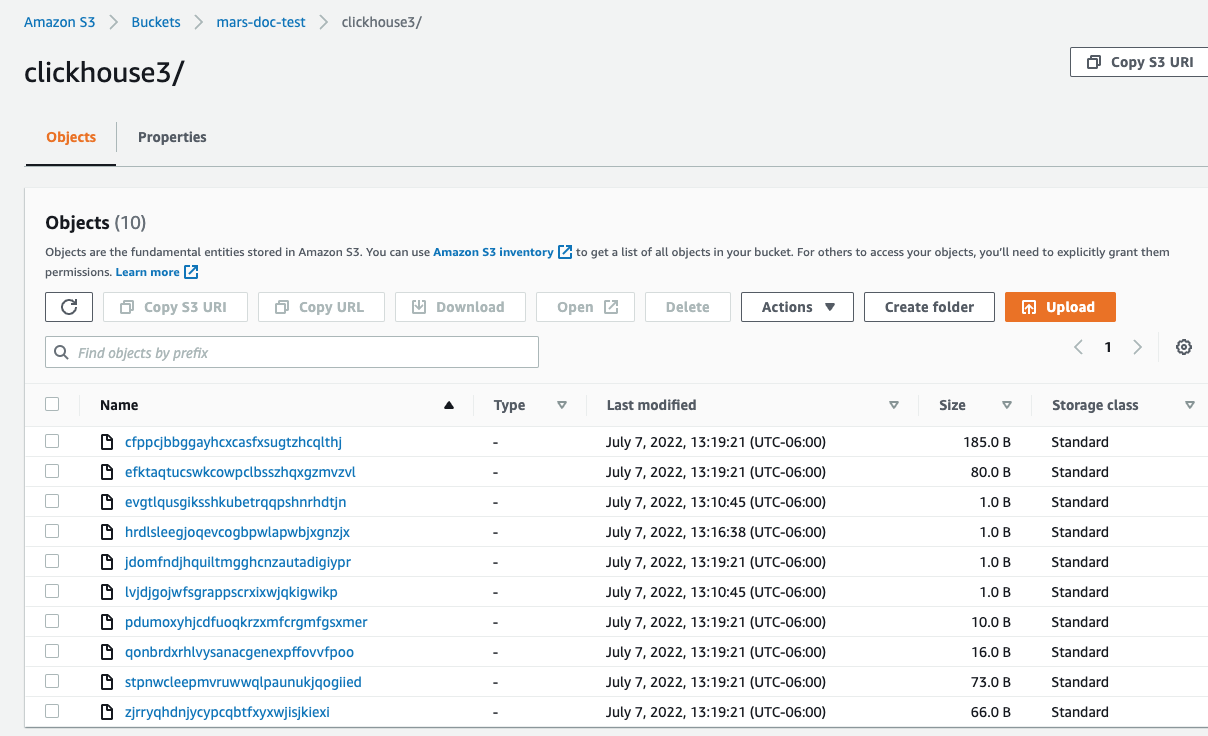
- 在 AWS 控制台中,进入 Buckets 页面,选择新创建的 bucket 和对应的文件夹。
你应该会看到类似下图的内容:
使用 S3 对象存储在两个 AWS 区域之间复制单个分片
提示
ClickHouse Cloud 默认使用对象存储,如果你在 ClickHouse Cloud 上运行,则无需执行本步骤。
规划部署
本教程基于在 AWS EC2 中部署两个 ClickHouse Server 节点和三个 ClickHouse Keeper 节点。ClickHouse 服务器的数据存储使用 S3。在两个 AWS 区域中,每个区域部署一个 ClickHouse Server 和一个 S3 存储桶(S3 bucket),以支持灾难恢复。
ClickHouse 表会在两个服务器之间复制,因此也会在两个区域之间复制。
安装软件
ClickHouse 服务器节点
在 ClickHouse 服务器节点上执行部署步骤时,请参考安装说明。
部署 ClickHouse
在两台主机上部署 ClickHouse,在示例配置中,这两台主机命名为 chnode1、chnode2。
将 chnode1 部署在一个 AWS 区域,将 chnode2 部署在另一个区域。
部署 ClickHouse Keeper
在三台主机上部署 ClickHouse Keeper,在示例配置中,它们命名为 keepernode1、keepernode2 和 keepernode3。keepernode1 可以部署在与 chnode1 相同的区域,keepernode2 与 chnode2 在同一区域,而 keepernode3 可以部署在任一区域,但需位于该区域中与 ClickHouse 节点不同的可用区。
在 ClickHouse Keeper 节点上执行部署步骤时,请参考安装说明。
创建 S3 存储桶
创建两个 S3 存储桶,分别位于你部署 chnode1 和 chnode2 的两个区域中。
如果你需要有关创建存储桶和 IAM 角色的分步说明,请展开 Create S3 buckets and an IAM role 并按照说明操作:
创建 S3 存储桶和 IAM 用户
本文演示了如何配置 AWS IAM 用户、创建 S3 存储桶以及配置 ClickHouse 使用该存储桶作为 S3 磁盘的基础知识。
You should work with your security team to determine the permissions to be used, and consider these as a starting point.
创建 AWS IAM 用户
在以下步骤中,您将创建一个服务账户用户(而非登录用户)。
-
登录 AWS IAM 管理控制台。
-
在 Users 菜单中选择 Create user
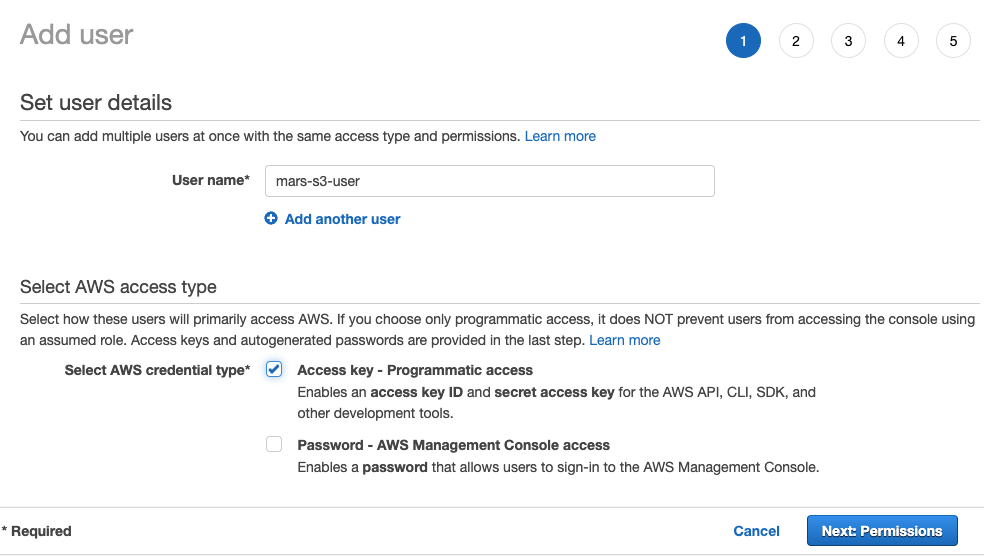
- 输入用户名,将凭证类型设置为
Access key - Programmatic access,然后单击 Next: Permissions
- 不要将该用户添加到任何用户组,然后选择
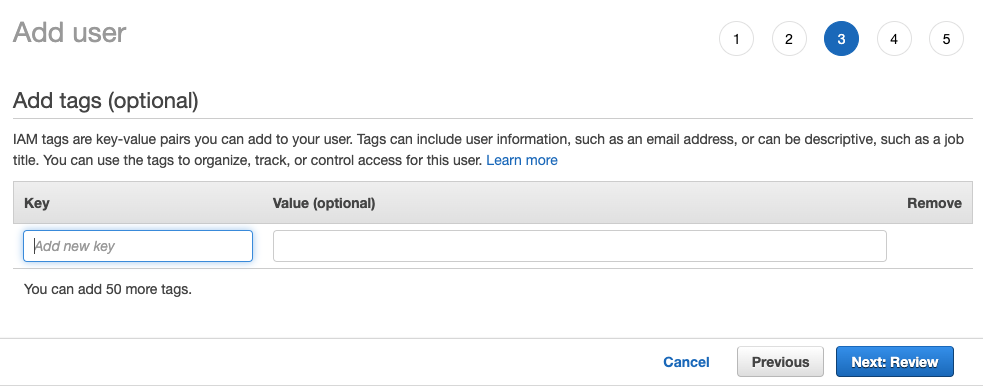
Next: Tags
- 除非您需要添加任何标签,否则选择
Next: Review
- 选择
Create User
注意
可以忽略指出用户没有权限的警告消息;将在下一节中为该用户授予存储桶权限
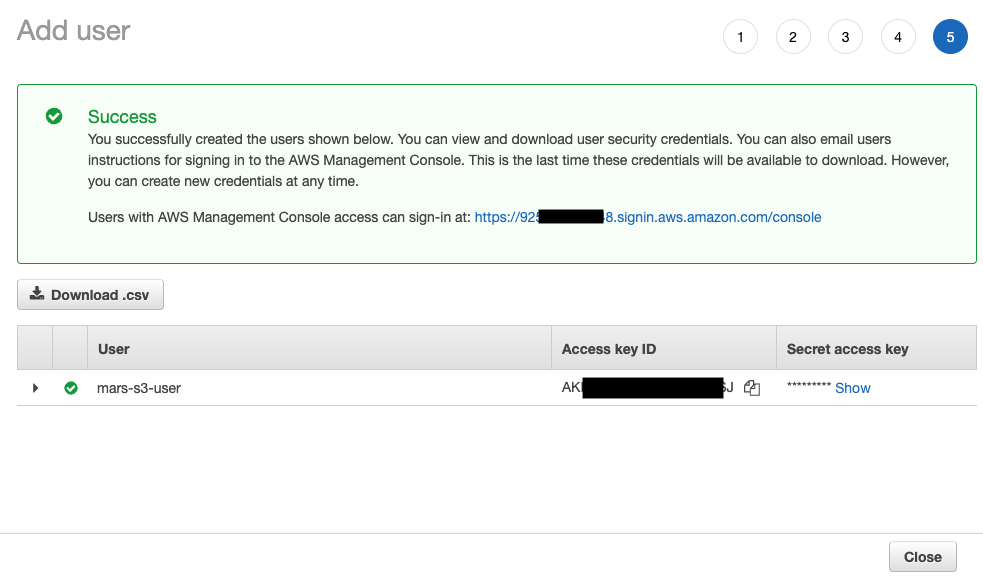
- 用户已创建;单击
show 并复制 access key 和 secret key。
注意
将密钥保存到其他位置;这是唯一可以获取密钥的时机。
- 点击关闭,然后在“用户”页面中找到该用户。
- 复制 ARN,并保存以便在配置存储桶访问策略时使用。
创建 S3 存储桶
- 在 S3 存储桶部分选择
Create bucket
- 输入存储桶名称,其余选项保持默认即可。
注意
存储桶名称必须在整个 AWS 范围内唯一,而不仅仅是在组织内唯一,否则将产生错误。
- 保持
Block all Public Access 处于启用状态;无需开启公共访问。
- 在页面底部选择
Create Bucket
-
选择该链接,复制 ARN,并保存以便在配置存储桶访问策略时使用。
-
存储桶创建完成后,在 S3 存储桶列表中找到新创建的 S3 存储桶并选择链接
- 选择
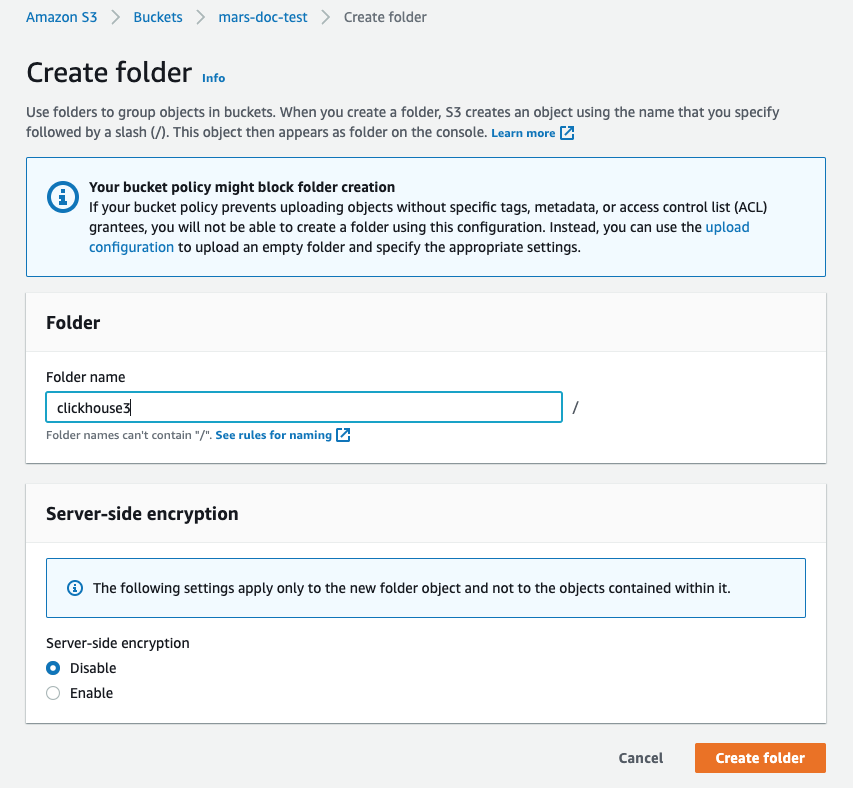
Create folder
- 输入将作为 ClickHouse S3 磁盘目标的文件夹名称,然后选择
Create folder
- 文件夹现在应该在存储桶列表中可见
- 选中新建文件夹的复选框,点击
Copy URL,并将复制的 URL 保存下来,以便在下一节的 ClickHouse 存储配置中使用。
- 选择
Permissions 选项卡,然后在 Bucket Policy 部分点击 Edit 按钮
- 添加存储桶策略,示例如下:
{
"Version" : "2012-10-17",
"Id" : "Policy123456",
"Statement" : [
{
"Sid" : "abc123",
"Effect" : "Allow",
"Principal" : {
"AWS" : "arn:aws:iam::921234567898:user/mars-s3-user"
},
"Action" : "s3:*",
"Resource" : [
"arn:aws:s3:::mars-doc-test",
"arn:aws:s3:::mars-doc-test/*"
]
}
]
}
|Parameter | Description | Example Value |
|----------|-------------|----------------|
|Version | Version of the policy interpreter, leave as-is | 2012-10-17 |
|Sid | User-defined policy id | abc123 |
|Effect | Whether user requests will be allowed or denied | Allow |
|Principal | The accounts or user that will be allowed | arn:aws:iam::921234567898:user/mars-s3-user |
|Action | What operations are allowed on the bucket| s3:*|
|Resource | Which resources in the bucket will operations be allowed in | "arn:aws:s3:::mars-doc-test", "arn:aws:s3:::mars-doc-test/*" |
- 保存策略配置。
然后将配置文件放置在 /etc/clickhouse-server/config.d/ 中。以下是其中一个存储桶的示例配置文件,另一个与其类似,只是其中高亮显示的三行不同:
<clickhouse>
<storage_configuration>
<disks>
<s3_disk>
<type>s3</type>
<!--highlight-start-->
<endpoint>https://docs-clickhouse-s3.s3.us-east-2.amazonaws.com/clickhouses3/</endpoint>
<access_key_id>ABCDEFGHIJKLMNOPQRST</access_key_id>
<secret_access_key>Tjdm4kf5snfkj303nfljnev79wkjn2l3knr81007</secret_access_key>
<!--highlight-end-->
<metadata_path>/var/lib/clickhouse/disks/s3_disk/</metadata_path>
</s3_disk>
<s3_cache>
<type>cache</type>
<disk>s3_disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3_disk</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
注意
本指南中的许多步骤会要求你将配置文件放到 /etc/clickhouse-server/config.d/ 中。该目录是 Linux 系统中用于存放用于覆盖默认配置的配置文件的默认位置。将这些文件放入该目录后,ClickHouse 会使用其中的内容覆盖默认配置。通过将这些文件放在该覆盖目录中,可避免在升级过程中丢失配置。
当以独立模式(与 ClickHouse 服务器分离)运行 ClickHouse Keeper 时,其配置存放在单个 XML 文件中。在本教程中,该文件为 /etc/clickhouse-keeper/keeper_config.xml。这三个 Keeper 服务器使用相同的配置文件,只有一个设置不同:<server_id>。
server_id 表示要分配给使用该配置文件的主机的 ID。 在下面的示例中,server_id 为 3,如果继续向下查看文件中的 <raft_configuration> 部分,你会看到服务器 3 的主机名是 keepernode3。ClickHouse Keeper 进程正是通过这种方式来确定在选举 leader 以及执行其他操作时需要连接的其他服务器。
<clickhouse>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-keeper/clickhouse-keeper.log</log>
<errorlog>/var/log/clickhouse-keeper/clickhouse-keeper.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<listen_host>0.0.0.0</listen_host>
<keeper_server>
<tcp_port>9181</tcp_port>
<!--highlight-next-line-->
<server_id>3</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>warning</raft_logs_level>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>keepernode1</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>keepernode2</hostname>
<port>9234</port>
</server>
<!--highlight-start-->
<server>
<id>3</id>
<hostname>keepernode3</hostname>
<port>9234</port>
</server>
<!--highlight-end-->
</raft_configuration>
</keeper_server>
</clickhouse>
将 ClickHouse Keeper 的配置文件复制到相应位置(记得设置 <server_id>):
sudo -u clickhouse \
cp keeper.xml /etc/clickhouse-keeper/keeper.xml
定义集群
ClickHouse 集群在配置文件的 <remote_servers> 部分中定义。在此示例中定义了一个名为 cluster_1S_2R 的集群,它由一个分片和两个副本组成。这两个副本位于主机 chnode1 和 chnode2 上。
<clickhouse>
<remote_servers replace="true">
<cluster_1S_2R>
<shard>
<replica>
<host>chnode1</host>
<port>9000</port>
</replica>
<replica>
<host>chnode2</host>
<port>9000</port>
</replica>
</shard>
</cluster_1S_2R>
</remote_servers>
</clickhouse>
在使用集群时,定义宏来为 DDL 查询自动填充集群、分片 (shard) 和副本 (replica) 设置会非常方便。此示例允许你在未显式提供 shard 和 replica 相关信息的情况下使用复制表引擎。创建表之后,你可以通过查询 system.tables 查看 shard 和 replica 宏是如何被使用的。
<clickhouse>
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
<macros>
<cluster>cluster_1S_2R</cluster>
<shard>1</shard>
<replica>replica_1</replica>
</macros>
</clickhouse>
注意
上述宏适用于 chnode1,在 chnode2 上需将 replica 设置为 replica_2。
禁用零拷贝复制
在 ClickHouse 22.7 及更早版本中,对于 S3 和 HDFS 磁盘,allow_remote_fs_zero_copy_replication 的默认值为 true。在本文描述的灾难恢复场景中,应将该设置改为 false,而在 22.8 及更高版本中,该设置的默认值已经为 false。
该设置应为 false 的原因有两点:1)此功能尚未达到生产就绪;2)在灾难恢复场景下,数据和元数据都需要存储在多个地域。请将 allow_remote_fs_zero_copy_replication 设置为 false。
<clickhouse>
<merge_tree>
<allow_remote_fs_zero_copy_replication>false</allow_remote_fs_zero_copy_replication>
</merge_tree>
</clickhouse>
ClickHouse Keeper 负责在各个 ClickHouse 节点之间协调数据复制。要让 ClickHouse 识别这些 ClickHouse Keeper 节点,需要在每个 ClickHouse 节点上添加一份配置文件。
<clickhouse>
<zookeeper>
<node index="1">
<host>keepernode1</host>
<port>9181</port>
</node>
<node index="2">
<host>keepernode2</host>
<port>9181</port>
</node>
<node index="3">
<host>keepernode3</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>
在 AWS 中配置安全设置时,请参阅网络端口列表,从而确保各服务器之间以及你与服务器之间能够正常通信。
三台服务器都必须监听网络连接,以便它们能够彼此之间以及与 S3 通信。默认情况下,ClickHouse 仅在本机回环地址上监听,因此必须更改此设置。相关配置位于 /etc/clickhouse-server/config.d/。下面是一个示例,用于将 ClickHouse 和 ClickHouse Keeper 配置为在所有 IPv4 接口上监听。有关更多信息,请参阅文档或默认配置文件 /etc/clickhouse/config.xml。
<clickhouse>
<listen_host>0.0.0.0</listen_host>
</clickhouse>
启动服务器
运行 ClickHouse Keeper
在每台 Keeper 服务器上,运行适用于所用操作系统的命令,例如:
sudo systemctl enable clickhouse-keeper
sudo systemctl start clickhouse-keeper
sudo systemctl status clickhouse-keeper
检查 ClickHouse Keeper 状态
使用 netcat 向 ClickHouse Keeper 发送命令。例如,执行 mntr 命令会返回 ClickHouse Keeper 集群的状态。如果你在每个 Keeper 节点上运行该命令,你会看到其中一个是 leader,另外两个是 follower:
echo mntr | nc localhost 9181
zk_version v22.7.2.15-stable-f843089624e8dd3ff7927b8a125cf3a7a769c069
zk_avg_latency 0
zk_max_latency 11
zk_min_latency 0
zk_packets_received 1783
zk_packets_sent 1783
# highlight-start
zk_num_alive_connections 2
zk_outstanding_requests 0
zk_server_state leader
# highlight-end
zk_znode_count 135
zk_watch_count 8
zk_ephemerals_count 3
zk_approximate_data_size 42533
zk_key_arena_size 28672
zk_latest_snapshot_size 0
zk_open_file_descriptor_count 182
zk_max_file_descriptor_count 18446744073709551615
# highlight-start
zk_followers 2
zk_synced_followers 2
# highlight-end
运行 ClickHouse 服务器
在每台 ClickHouse 服务器上运行:
sudo service clickhouse-server start
验证 ClickHouse 服务器
当你添加集群配置时,定义了一个在两个 ClickHouse 节点上复制的单分片(shard)。在此验证步骤中,你将检查 ClickHouse 启动时是否成功构建了该集群,并使用该集群创建一个复制表。
这些测试将验证数据是否在两台服务器之间正确复制,以及数据是否存储在 S3 存储桶而非本地磁盘中。
-
从纽约市出租车数据集添加数据:
INSERT INTO trips
SELECT trip_id,
pickup_date,
pickup_datetime,
dropoff_datetime,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
passenger_count,
trip_distance,
tip_amount,
total_amount,
payment_type
FROM s3('https://ch-nyc-taxi.s3.eu-west-3.amazonaws.com/tsv/trips_{0..9}.tsv.gz', 'TabSeparatedWithNames') LIMIT 1000000;
-
验证数据已存储在 S3 中。
此查询显示磁盘上的数据大小,以及用于决定使用哪个磁盘的存储策略。
SELECT
engine,
data_paths,
metadata_path,
storage_policy,
formatReadableSize(total_bytes)
FROM system.tables
WHERE name = 'trips'
FORMAT Vertical
Query id: af7a3d1b-7730-49e0-9314-cc51c4cf053c
Row 1:
──────
engine: ReplicatedMergeTree
data_paths: ['/var/lib/clickhouse/disks/s3_disk/store/551/551a859d-ec2d-4512-9554-3a4e60782853/']
metadata_path: /var/lib/clickhouse/store/e18/e18d3538-4c43-43d9-b083-4d8e0f390cf7/trips.sql
storage_policy: s3_main
formatReadableSize(total_bytes): 36.42 MiB
1 row in set. Elapsed: 0.009 sec.
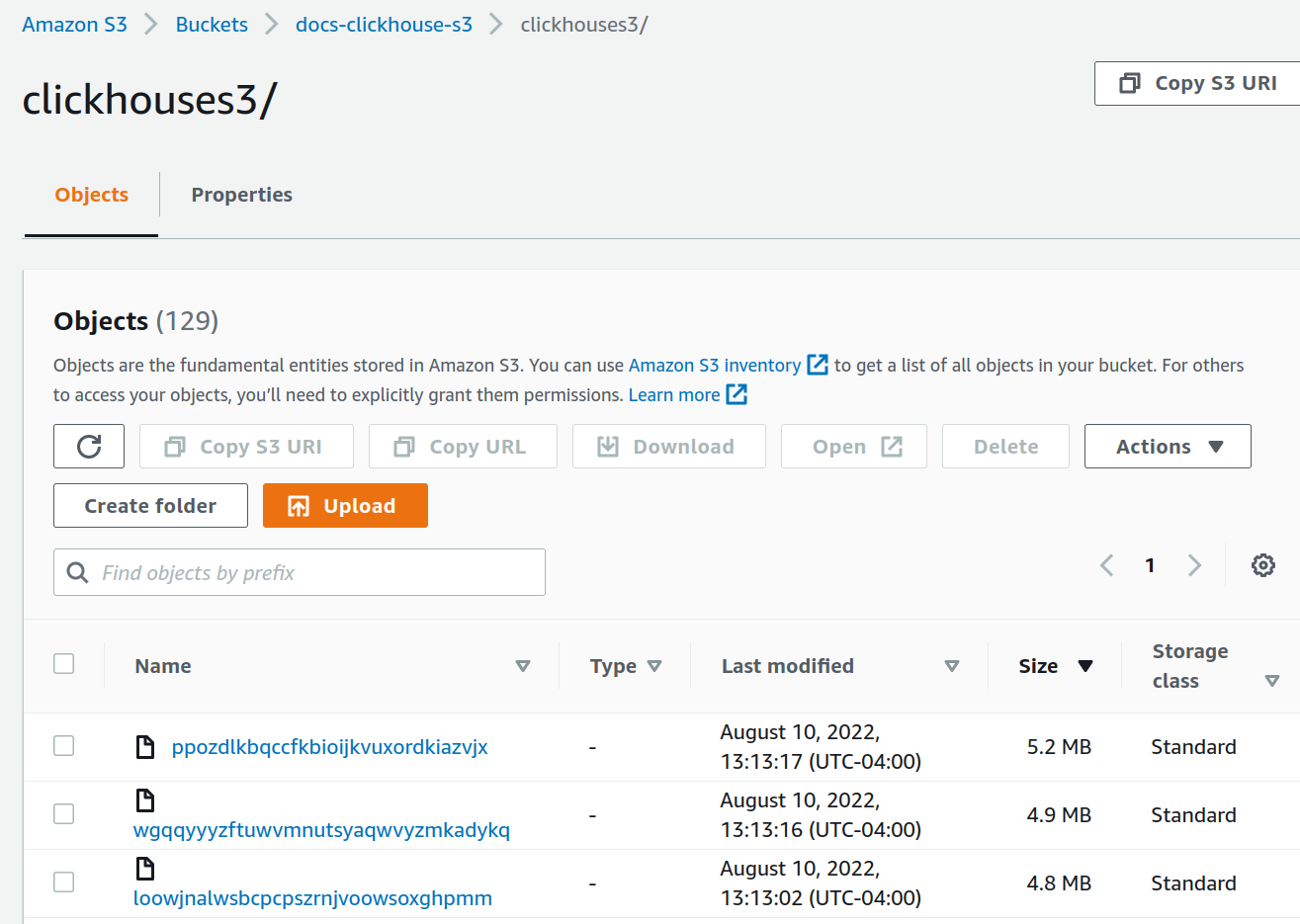
检查本地磁盘上的数据大小。从上面的查询结果可以看到,存储的数百万行数据在磁盘上的大小为 36.42 MiB。这些数据应当位于 S3 上,而不是本地磁盘上。上述查询还告知我们数据和元数据在本地磁盘上的存储路径。检查本地数据:
root@chnode1:~# du -sh /var/lib/clickhouse/disks/s3_disk/store/551
536K /var/lib/clickhouse/disks/s3_disk/store/551
在每个 S3 Bucket 中检查 S3 数据(未显示合计值,但在插入完成后,两个 Bucket 中大约都存储了 36 MiB):
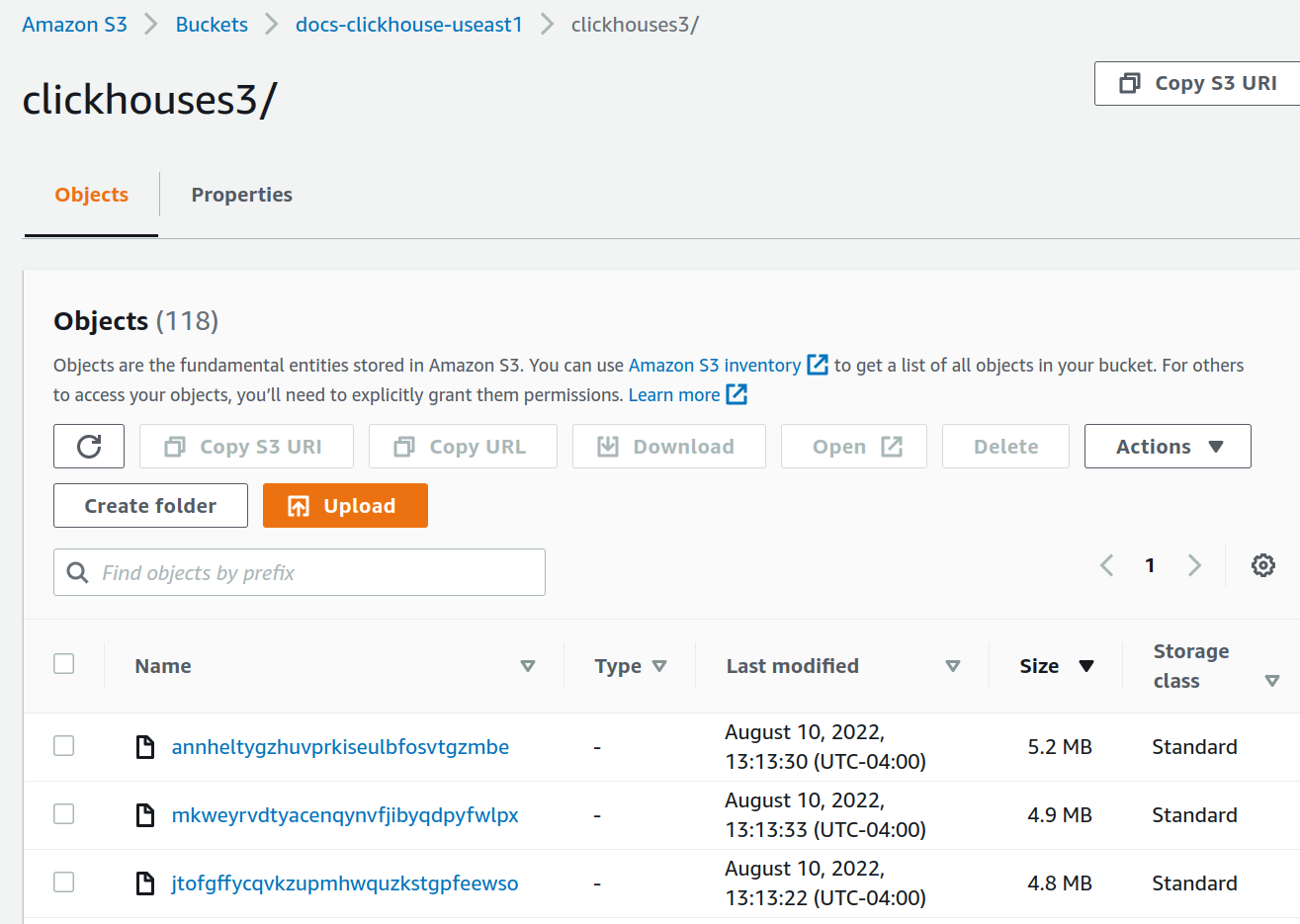
S3Express
S3Express 是 Amazon S3 中一种新的高性能、单可用区存储类别(storage class)。
你可以参考这篇 博客,了解我们在 ClickHouse 中测试 S3Express 的经验。
注意
S3Express 将数据存储在单个可用区(AZ)中。这意味着一旦该 AZ 宕机,数据将不可用。
S3 磁盘
使用以 S3Express bucket 作为存储后端的方式创建表,包括以下步骤:
- 创建一个
Directory 类型的 bucket
- 配置合适的 bucket 策略,为 S3 用户授予所有所需权限(例如使用
"Action": "s3express:*" 即可简单地允许不受限制的访问)
- 在配置存储策略(storage policy)时,请提供
region 参数
存储配置与普通 S3 相同,例如可以如下所示:
<storage_configuration>
<disks>
<s3_express>
<type>s3</type>
<endpoint>https://my-test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com/store/</endpoint>
<region>eu-north-1</region>
<access_key_id>...</access_key_id>
<secret_access_key>...</secret_access_key>
</s3_express>
</disks>
<policies>
<s3_express>
<volumes>
<main>
<disk>s3_express</disk>
</main>
</volumes>
</s3_express>
</policies>
</storage_configuration>
然后在这个新存储上创建一张表:
CREATE TABLE t
(
a UInt64,
s String
)
ENGINE = MergeTree
ORDER BY a
SETTINGS storage_policy = 's3_express';
S3 存储
同样支持 S3 存储,但仅适用于 Object URL 路径。例如:
SELECT * FROM s3('https://test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com/file.csv', ...)
还需要在配置中指定 bucket 所在的 region:
<s3>
<perf-bucket-url>
<endpoint>https://test-bucket--eun1-az1--x-s3.s3express-eun1-az1.eu-north-1.amazonaws.com</endpoint>
<region>eu-north-1</region>
</perf-bucket-url>
</s3>
可以将备份存储在我们之前创建的磁盘上:
BACKUP TABLE t TO Disk('s3_express', 't.zip')
┌─id───────────────────────────────────┬─status─────────┐
│ c61f65ac-0d76-4390-8317-504a30ba7595 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
RESTORE TABLE t AS t_restored FROM Disk('s3_express', 't.zip')
┌─id───────────────────────────────────┬─status───┐
│ 4870e829-8d76-4171-ae59-cffaf58dea04 │ RESTORED │
└──────────────────────────────────────┴──────────┘