ClickHouse Kafka Connect Sink
如果你需要任何帮助,请在代码仓库中提交 issue,或在 ClickHouse 公共 Slack 中提问。
ClickHouse Kafka Connect Sink 是一个 Kafka 连接器,用于将数据从 Kafka 主题投递到 ClickHouse 表中。
许可证
Kafka Connector Sink 采用 Apache 2.0 License 授权发布。
环境要求
环境中需要安装 Kafka Connect 框架 v2.7 或更高版本。
版本兼容性矩阵
| ClickHouse Kafka Connect version | ClickHouse version | Kafka Connect | Confluent platform |
|---|---|---|---|
| 1.0.0 | > 23.3 | > 2.7 | > 6.1 |
主要特性
- 内置开箱即用的精确一次(exactly-once)语义。该能力由 ClickHouse 新的核心特性 KeeperMap(由连接器用作状态存储)提供支持,并允许采用极简的架构。
- 支持第三方状态存储:当前默认使用内存(In-memory),也可以使用 KeeperMap(即将支持 Redis)。
- 深度集成:由 ClickHouse 构建、维护并提供支持。
- 持续针对 ClickHouse Cloud 进行测试。
- 支持具有显式 schema 和无 schema 的数据写入。
- 支持 ClickHouse 的所有数据类型。
安装说明
收集连接信息
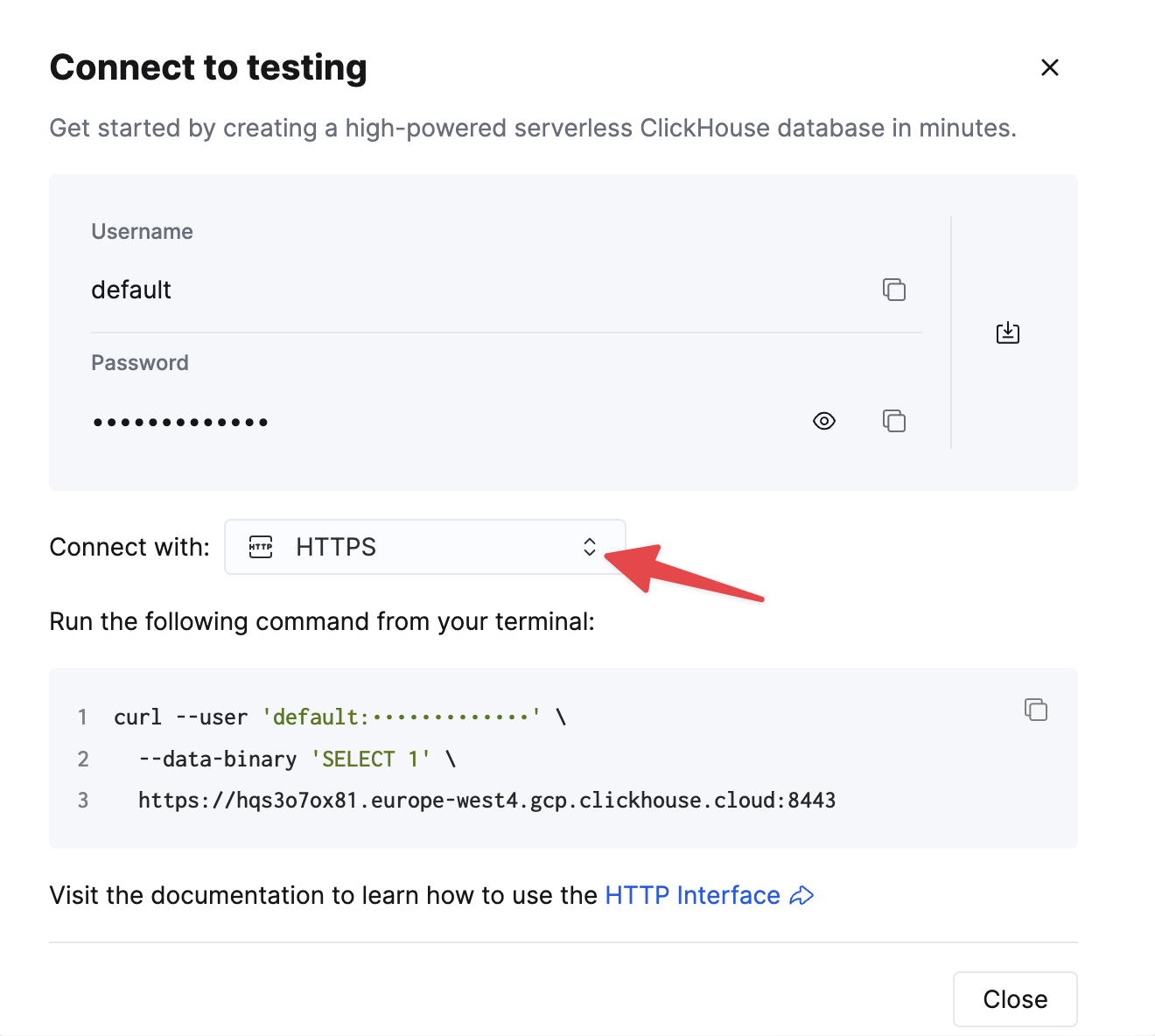
要通过 HTTP(S) 连接到 ClickHouse,您需要以下信息:
| 参数 | 说明 |
|---|---|
HOST 和 PORT | 通常,在使用 TLS 时端口为 8443,不使用 TLS 时端口为 8123。 |
DATABASE NAME | 默认提供一个名为 default 的数据库,请填写您要连接的目标数据库名称。 |
USERNAME 和 PASSWORD | 默认用户名为 default。请使用适合您使用场景的用户名。 |
您的 ClickHouse Cloud 服务的详细信息可以在 ClickHouse Cloud 控制台中查看。 选择某个服务并点击 Connect:
选择 HTTPS。连接信息会显示在示例 curl 命令中。
如果您使用的是自托管 ClickHouse,则连接信息由您的 ClickHouse 管理员进行设置。
通用安装说明
连接器以单个 JAR 文件的形式分发,其中包含运行插件所需的全部类文件。
要安装插件,请执行以下步骤:
- 从 ClickHouse Kafka Connect Sink 仓库的 Releases 页面下载包含 Connector JAR 文件的 ZIP 压缩包。
- 解压 ZIP 文件内容并将其复制到目标位置。
- 在 Connect 配置文件中,将包含插件目录的路径添加到 plugin.path 配置项中,以便 Confluent Platform 能够找到该插件。
- 在配置中提供主题名称、ClickHouse 实例主机名以及密码。
- 重启 Confluent Platform。
- 如果您使用 Confluent Platform,请登录 Confluent Control Center UI,确认 ClickHouse Sink 已出现在可用连接器列表中。
配置选项
要将 ClickHouse Sink 连接到 ClickHouse 服务器,您需要提供:
- 连接参数:主机名(必填)和端口(可选)
- 用户凭证:密码(必填)和用户名(可选)
- 连接器类:
com.clickhouse.kafka.connect.ClickHouseSinkConnector(必填) - topics 或 topics.regex:要轮询的 Kafka topic——topic 名称必须与表名匹配(必填)
- 键和值转换器:根据该 topic 上数据的类型进行设置。如果在 worker 配置中尚未定义,则为必填项。
完整的配置选项表如下:
| Property Name | Description | Default Value |
|---|---|---|
hostname (Required) | 服务器的主机名或 IP 地址 | N/A |
port | ClickHouse 端口——云环境中 HTTPS 的默认端口为 8443,自托管环境中默认使用 HTTP 时应使用 8123 | 8443 |
ssl | 启用到 ClickHouse 的 SSL 连接 | true |
jdbcConnectionProperties | 连接 ClickHouse 时使用的连接属性。必须以 ? 开头,param=value 之间使用 & 连接 | "" |
username | ClickHouse 数据库用户名 | default |
password (Required) | ClickHouse 数据库密码 | N/A |
database | ClickHouse 数据库名称 | default |
connector.class (Required) | Connector 类(显式设置并保持为默认值) | "com.clickhouse.kafka.connect.ClickHouseSinkConnector" |
tasks.max | Connector 任务数量 | "1" |
errors.retry.timeout | Kafka Connect 最大重试超时时间,以毫秒为单位。0 表示不重试。-1 表示无限重试。建议值大于 "10000" ms (10 秒) Timeout | "0" |
exactlyOnce | 是否启用 Exactly Once | "false" |
topics (Required) | 要轮询的 Kafka 主题——主题名称必须与表名一致 | "" |
key.converter (Required* - See Description) | 根据 key 的类型进行设置。如果需要传递 key(且未在 worker 配置中定义),则此项为必填。 | "org.apache.kafka.connect.storage.StringConverter" |
value.converter (Required* - See Description) | 根据主题中的数据类型进行设置。支持:JSON、String、Avro 或 Protobuf 格式。如果未在 worker 配置中定义,则此项为必填。 | "org.apache.kafka.connect.json.JsonConverter" |
value.converter.schemas.enable | Connector Value Converter 的 Schema 支持开关 | "false" |
errors.tolerance | Connector 错误容忍度。支持:none、all | "none" |
errors.deadletterqueue.topic.name | 如果设置了该项(且 errors.tolerance=all),将对失败的批次使用 DLQ(参见 Troubleshooting) | "" |
errors.deadletterqueue.context.headers.enable | 为 DLQ 添加额外的 header | "" |
clickhouseSettings | 以逗号分隔的 ClickHouse 设置列表(例如 "insert_quorum=2, etc...") | "" |
topic2TableMap | 将主题名称映射到表名的、以逗号分隔的列表(例如 "topic1=table1, topic2=table2, etc...") | "" |
tableRefreshInterval | 刷新表定义缓存的时间(单位:秒) | 0 |
keeperOnCluster | 允许为自托管实例配置 exactly-once connect_state 表的 ON CLUSTER 参数(例如 ON CLUSTER clusterNameInConfigFileDefinition)(参见 Distributed DDL Queries | "" |
bypassRowBinary | 允许对基于 Schema 的数据(Avro、Protobuf 等)禁用 RowBinary 和 RowBinaryWithDefaults 的使用——仅应在数据可能缺少列且 Nullable/Default 不可接受时使用 | "false" |
dateTimeFormats | 用于解析 DateTime64 schema 字段的日期时间格式列表,以 ; 分隔(例如 someDateField=yyyy-MM-dd HH:mm:ss.SSSSSSSSS;someOtherDateField=yyyy-MM-dd HH:mm:ss)。 | "" |
tolerateStateMismatch | 允许 Connector 丢弃"早于"当前 AFTER_PROCESSING 存储偏移量的记录(例如,如果发送了偏移量 5,而最近记录的偏移量是 250)。应在发生故障后用于修复摄取,完成后应将其改回 "false"。 | "false" |
ignorePartitionsWhenBatching | 在收集要插入的消息时忽略分区(仅当 exactlyOnce 为 false 时)。性能注意:Connector 任务越多,每个任务分配到的 Kafka 分区就越少——这可能会产生收益递减。 | "false" |
bufferCount (自 v1.3.6 起) | 刷新到 ClickHouse 之前在内存中缓冲的记录数。0 表示禁用内部缓冲。exactlyOnce=true 时不支持缓冲。 | "0" |
bufferFlushTime (自 v1.3.6 起) | 当 exactlyOnce=false 时,刷新前缓冲记录的最长时间,以 Milliseconds 为单位。0 表示禁用基于时间的刷新。默认值为 0。仅在使用基于时间的阈值时需要。仅当 bufferCount > 0 时生效。 | "0" |
reportInsertedOffsets (自 v1.3.6 起) | 启用后,当 exactlyOnce=false 时,preCommit 将仅返回成功插入的偏移量(而非 currentOffsets)。当 ignorePartitionsWhenBatching=true 时,此设置不适用,仍会返回 currentOffsets。 | "false" |
目标表
ClickHouse Connect Sink 从 Kafka 主题读取消息,并将其写入相应的表中。它只会向已存在的表写入数据。请确保在开始向目标表插入数据之前,已经在 ClickHouse 中创建了具有合适 schema 的目标表。
每个主题在 ClickHouse 中都需要一个专用的目标表。目标表名必须与源主题名一致。
预处理
如果需要在消息发送到 ClickHouse Kafka Connect Sink 之前对出站消息进行转换,请使用 Kafka Connect Transformations。
支持的数据类型
已声明 schema 时:
| Kafka Connect Type | ClickHouse Type | Supported | Primitive |
|---|---|---|---|
| STRING | String | ✅ | Yes |
| STRING | JSON. See below (1) | ✅ | Yes |
| INT8 | Int8 | ✅ | Yes |
| INT16 | Int16 | ✅ | Yes |
| INT32 | Int32 | ✅ | Yes |
| INT64 | Int64 | ✅ | Yes |
| FLOAT32 | Float32 | ✅ | Yes |
| FLOAT64 | Float64 | ✅ | Yes |
| BOOLEAN | Boolean | ✅ | Yes |
| ARRAY | Array(T) | ✅ | No |
| MAP | Map(Primitive, T) | ✅ | No |
| STRUCT | Variant(T1, T2, ...) | ✅ | No |
| STRUCT | Tuple(a T1, b T2, ...) | ✅ | No |
| STRUCT | Nested(a T1, b T2, ...) | ✅ | No |
| STRUCT | JSON. See below (1), (2) | ✅ | No |
| BYTES | String | ✅ | No |
| org.apache.kafka.connect.data.Time | Int64 / DateTime64 | ✅ | No |
| org.apache.kafka.connect.data.Timestamp | Int32 / Date32 | ✅ | No |
| org.apache.kafka.connect.data.Decimal | Decimal | ✅ | No |
-
(1) - 仅当在 ClickHouse 设置中将
input_format_binary_read_json_as_string=1打开时才支持 JSON。该设置仅对 RowBinary 格式族生效,并且会影响插入请求中的所有列,因此所有列都必须是字符串。在这种情况下,Connector 会将 STRUCT 转换为 JSON 字符串。 -
(2) - 当 struct 中包含
oneof之类的 union 时,需要将转换器配置为不在字段名上添加前缀/后缀。可以使用ProtobufConverter的generate.index.for.unions=false设置。
未声明 schema 时:
记录会被转换为 JSON,并以 JSONEachRow 格式作为一个值发送到 ClickHouse。
配置示例
以下是一些常见的配置示例,帮助你快速上手。
基本配置
这是最基础的配置示例,用于帮助你入门——它假设你在分布式模式下运行 Kafka Connect,并在启用 SSL 的情况下,在 localhost:8443 上运行一个 ClickHouse 服务器,数据为无 schema 的 JSON。
上述连接器配置需要你在工作线程配置中通过 connector.client.config.override.policy=All 启用客户端重写。更多信息,请参阅 Kafka Connect 文档。
多个 topic 的基本配置
此连接器支持从多个 topic 消费数据
带 DLQ 的基本配置
在不同数据格式下使用
Avro 模式支持
Avro 类型对照
下方的类型对照由 io.confluent.connect.avro.AvroConverter 定义,它是 Kafka Connect 官方的 Avro 序列化/反序列化实现。有关转换逻辑的更多进阶信息,请参阅 Kafka Connect 文档。
✅:支持
❌:不支持
️⚠️:部分支持
| Avro 类型 | Kafka Connect 类型 | 是否支持 | 说明 |
|---|---|---|---|
| null | N/A | ❌ | 不支持作为独立类型,但可用于联合类型 |
| boolean | BOOLEAN | ✅ | |
| int | INT8/INT16/INT32 | ✅ | 默认为 INT32。如果 schema 具有属性 connect.type=int8,则解析为 INT8 (INT16 的情况同理,即 connect.type=int16) |
| long | INT64 | ✅ | |
| float | FLOAT32 | ✅ | |
| double | FLOAT64 | ✅ | |
| bytes | BYTES | ✅ | |
| string | STRING | ✅ | |
| record | STRUCT | ✅ | |
| enum | STRING | ✅ | |
| array | ARRAY/MAP | ✅ | 默认为 ARRAY。如果该字段最初是通过 AvroData.fromConnectSchema 构造的,则解析为 MAP (源代码) |
| map | MAP | ✅ | |
| union | STRUCT/<T> | ⚠️ | 默认为 STRUCT。如果 flatten.singleton.unions=true,则解析为联合定义中的单一类型 T (参见 文档) |
| fixed | BYTES | ⚠️ | 不支持 fixed decimal 逻辑类型 (见下文) |
有关 Kafka Connect 类型与 ClickHouse 类型之间的对照,请参阅支持的数据类型。
不受支持的 Avro schema
该连接器不支持以下 Avro schema:
- 带有
decimal逻辑类型的 fixed
- Nullable 联合类型
- 记录的联合类型
Protobuf 模式支持
请注意:如果遇到类缺失问题,由于并非所有环境都自带 protobuf 转换器,您可能需要使用一个将依赖一起打包的备用 jar 发行版。
Protobuf 类型对照
下面的类型对照由 io.confluent.connect.protobuf.ProtobufConverter 定义,它是 Kafka Connect 官方提供的 Protobuf 序列化器/反序列化器实现。有关转换逻辑的进阶信息,请参阅 Kafka Connect 文档。
✅:支持
❌:不受支持
️⚠️:部分支持
| Protobuf 类型 | Kafka Connect 类型 | 是否支持 | 说明 |
|---|---|---|---|
| double | FLOAT64 | ✅ | |
| float | FLOAT32 | ✅ | |
| int32 | INT8/INT16/INT32 | ✅ | 默认为 INT32。如果 schema 指定了选项 connect.type=int8,则会解析为 INT8 (INT16 的情况同理,即 connect.type=int16) |
| sint32 | INT8/INT16/INT32 | ✅ | 默认为 INT32。如果 schema 指定了选项 connect.type=int8,则会解析为 INT8 (INT16 的情况同理,即 connect.type=int16) |
| sfixed32 | INT8/INT16/INT32 | ✅ | 默认为 INT32。如果 schema 指定了选项 connect.type=int8,则会解析为 INT8 (INT16 的情况同理,即 connect.type=int16) |
| uint32 | INT64 | ✅ | |
| fixed32 | INT64 | ✅ | |
| int64 | INT64 | ✅ | |
| uint64 | INT64 | ✅ | |
| sint64 | INT64 | ✅ | |
| fixed64 | INT64 | ✅ | |
| sfixed64 | INT64 | ✅ | |
| bool | BOOLEAN | ✅ | |
| string | STRING | ✅ | |
| bytes | BYTES | ✅ | |
| enum | INT32/STRING | ✅ | 默认为 STRING。如果 int.for.enums=true,则会解析为 INT32 (参见 schema registry 文档) |
| message | STRUCT | ⚠️ | 请参见下方的“不受支持的 schema”一节 |
| repeated T (where T is not a map entry) | ARRAY | ✅ | |
map<K, V> | MAP | ✅ | |
| oneof | STRUCT | ⚠️ | 请参见下方关于将 oneof 转换为 ClickHouse schema 的章节 |
| google.protobuf.DoubleValue | FLOAT64 | ✅ | |
| google.protobuf.FloatValue | FLOAT32 | ✅ | |
| google.protobuf.Int64Value | INT64 | ✅ | |
| google.protobuf.UInt64Value | INT64 | ✅ | |
| google.protobuf.UInt32Value | INT64 | ✅ | |
| google.protobuf.Int32Value | INT32 | ✅ | |
| google.protobuf.BoolValue | BOOLEAN | ✅ | |
| google.protobuf.StringValue | STRING | ✅ | |
| google.protobuf.BytesValue | BYTES | ✅ | |
| google.protobuf.Timestamp | org.apache.kafka.connect.data.Timestamp | ✅ | |
| google.type.Date | org.apache.kafka.connect.data.Date | ✅ | |
| google.type.TimeOfDay | org.apache.kafka.connect.data.Time | ✅ |
有关 Kafka Connect 类型与 ClickHouse 类型之间的映射关系,请参阅支持的数据类型。
关于将 oneof 字段映射为 ClickHouse 列的说明
该连接器不支持将 Protobuf 联合 (oneof) 映射为 ClickHouse 的 Variant 类型。请改为在 ClickHouse 表 schema 中,将 oneof 字段分别列为单独的 Nullable 字段。
例如:
转换为以下 ClickHouse 表定义:
不受支持的 Protobuf schema
连接器不支持以下 Protobuf schema:
- 多消息联合类型 (CH 26.1 之前的版本)
从 CH 26.1 版本起,当 allow_experimental_nullable_tuple_type=1 时,即支持此 schema (请参阅此文档页面) 。
JSON Schema 支持
字符串支持
该连接器在不同的 ClickHouse 数据格式下支持使用 String Converter:JSON、CSV 和 TSV。
内部缓冲
内部缓冲允许 sink 任务累积来自多次 poll() 调用的记录,并将其作为更大的批次刷新到 ClickHouse。在每次 poll 都会产生许多按分区划分的小批次的工作负载中,这可以提高吞吐量。
关键行为:
bufferCount控制刷新前缓冲的记录数量。bufferFlushTime设置刷新缓冲记录之前的最长等待时间 (以毫秒为单位) 。- 仅当
bufferCount > 0时,bufferFlushTime才会生效。 bufferCount=0且bufferFlushTime=0会使缓冲保持禁用状态 (默认行为) 。- 当
exactlyOnce=true时,不支持缓冲。
为什么缓冲与 exactly-once 模式不兼容:
缓冲会改变批次边界,从而破坏 ClickHouse 数据块去重以及连接器 offset 状态机。
要解决此问题,可以在连接器配置中使用 exactlyOnce=false 禁用 exactly-once 模式,或者使用 bufferCount=0 禁用缓冲。
示例:
日志
Kafka Connect Platform 会自动输出日志。 可以通过 Kafka Connect 的配置文件来配置日志的输出目标和格式。
如果使用 Confluent Platform,可以通过运行 CLI 命令查看日志:
如需了解更多详情,请参阅官方教程。
监控
ClickHouse Kafka Connect 通过 Java Management Extensions (JMX) 上报运行时指标。Kafka Connector 中默认启用 JMX。
ClickHouse 特定指标
连接器通过以下 MBean 名称暴露自定义指标:
| Metric Name | Type | Description |
|---|---|---|
receivedRecords | long | 接收的记录总数。 |
recordProcessingTime | long | 将记录分组并转换为统一结构所花费的总时间(纳秒)。 |
taskProcessingTime | long | 处理并将数据插入 ClickHouse 所花费的总时间(纳秒)。 |
Kafka 生产者/消费者指标
该连接器公开了标准的 Kafka 生产者和消费者指标,用于洞察数据流、吞吐量和性能。
Topic 级指标:
records-sent-total: 发送到该 topic 的记录总数bytes-sent-total: 发送到该 topic 的字节总数record-send-rate: 每秒发送记录的平均速率byte-rate: 每秒发送字节的平均速率compression-rate: 实际达到的压缩比
分区级指标:
records-sent-total: 发送到该分区的记录总数bytes-sent-total: 发送到该分区的字节总数records-lag: 该分区当前的滞后records-lead: 该分区当前的领先replica-fetch-lag: 副本拉取的滞后信息
节点级连接指标:
connection-creation-total: 到该 Kafka 节点建立的连接总数connection-close-total: 关闭的连接总数request-total: 发送到该节点的请求总数response-total: 从该节点接收的响应总数request-rate: 平均每秒请求速率response-rate: 平均每秒响应速率
这些指标有助于监控:
- 吞吐量:跟踪数据摄取速率
- 滞后:识别瓶颈和处理延迟
- 压缩:衡量数据压缩效率
- 连接健康状况:监控网络连通性和稳定性
Kafka Connect 框架指标
该连接器集成了 Kafka Connect 框架,并公开了用于任务生命周期和错误跟踪的指标。
任务状态指标:
task-count: 连接器中任务的总数running-task-count: 当前正在运行的任务数量paused-task-count: 当前被暂停的任务数量failed-task-count: 已失败的任务数量destroyed-task-count: 已销毁的任务数量unassigned-task-count: 未分配的任务数量
任务状态值包括:running、paused、failed、destroyed、unassigned
错误指标:
deadletterqueue-produce-failures: DLQ 写入失败的次数deadletterqueue-produce-requests: DLQ 写入尝试总数last-error-timestamp: 最近一次错误的时间戳records-skip-total: 因错误被跳过的记录总数records-retry-total: 被重试的记录总数errors-total: 遇到的错误总数
性能指标:
offset-commit-failures: 提交 offset 失败的次数offset-commit-avg-time-ms: 提交 offset 的平均耗时offset-commit-max-time-ms: 提交 offset 的最大耗时put-batch-avg-time-ms: 处理一个批次的平均耗时put-batch-max-time-ms: 处理一个批次的最大耗时source-record-poll-total: 轮询到的记录总数
监控最佳实践
- 监控 Consumer 滞后情况:跟踪每个分区的
records-lag以识别处理瓶颈 - 跟踪错误率:关注
errors-total和records-skip-total以发现数据质量问题 - 观察任务健康状况:监控任务状态指标以确保任务正常运行
- 测量吞吐量:使用
records-send-rate和byte-rate跟踪摄取性能 - 监控连接健康状况:检查节点级连接指标以发现网络问题
- 跟踪压缩效率:使用
compression-rate来优化数据传输
有关 JMX 指标的详细定义以及 Prometheus 集成,请参阅 jmx-export-connector.yml 配置文件。
限制
- 不支持删除操作。
- 批大小由 Kafka Consumer 的属性决定。
- 当使用 KeeperMap 实现 exactly-once 语义且 offset 被更改或回退时,需要删除 KeeperMap 中该特定 topic 的内容。(有关更多详细信息,请参阅下文的故障排除指南)
性能调优与吞吐量优化
本节介绍 ClickHouse Kafka Connect Sink 的性能调优策略。在处理高吞吐量场景,或者需要优化资源利用率并最小化滞后时,性能调优尤为重要。
何时需要进行性能调优?
在以下场景中通常需要进行性能调优:
- 高吞吐量工作负载:当从 Kafka topic 处理每秒数百万条事件时
- Consumer 滞后:当连接器无法跟上数据生产速率,导致滞后不断增加时
- 资源受限:当需要优化 CPU、内存或网络使用时
- 多 topic 场景:当同时从多个高吞吐量 topic 中消费数据时
- 小消息大小:当处理大量小消息并且可以从服务端批量处理获益时
在以下情况下通常不需要性能调优:
- 处理的量处于低到中等水平(< 10,000 条消息/秒)
- Consumer 的滞后稳定且在你的用例可接受范围内
- 默认的连接器设置已经满足你的吞吐量需求
- 你的 ClickHouse 集群可以轻松处理当前的写入负载
理解数据流
在进行调优之前,首先需要理解数据在 connector 中的流转方式:
- Kafka Connect 框架在后台从 Kafka topic 中拉取消息
- **Connector 轮询(poll)**框架内部缓冲区中的消息
- **Connector 按批处理(batch)**消息,批次大小取决于每次轮询返回的数量
- ClickHouse 接收通过 HTTP/S 发送的批量写入请求
- ClickHouse 处理插入请求(同步或异步)
上述各个阶段都可以进行性能优化。
调优 Kafka Connect 批量大小
第一层优化是控制 connector 每批次从 Kafka 接收的数据量。
Fetch 设置
Kafka Connect(框架)在后台、独立于 connector,从 Kafka topic 中获取消息:
fetch.min.bytes:在框架将数据传递给 connector 之前必须累积的最小数据量(默认:1 字节)fetch.max.bytes:单次请求中可获取的最大数据量(默认:52428800 / 50 MB)fetch.max.wait.ms:如果未达到fetch.min.bytes,在返回数据前等待的最长时间(默认:500 ms)
在 Confluent Cloud 中,调整这些设置需要通过 Confluent Cloud 提交支持工单。
Poll 设置
Connector 从框架的缓冲区轮询消息:
max.poll.records:单次轮询返回的最大记录数(默认:500)max.partition.fetch.bytes:每个分区可获取的最大数据量(默认:1048576 / 1 MB)
在 Confluent Cloud 上,调整这些设置需要通过 Confluent Cloud 提交工单给支持团队。
高吞吐量的推荐配置
为了在 ClickHouse 中获得最佳性能,建议使用较大的批次:
上述属性要求您在工作线程配置中通过 connector.client.config.override.policy=All 启用客户端配置重写。更多信息,请参阅 Kafka Connect 文档。
重要提示: Kafka Connect 的 fetch 设置针对的是压缩后的数据,而 ClickHouse 接收的是未压缩的数据。请根据压缩比来平衡这些设置。
权衡取舍:
- 更大的批次 = 更好的 ClickHouse 摄取性能、更少的parts、更低的开销
- 更大的批次 = 更高的内存占用、端到端延迟可能增加
- 批次过大 = 存在超时、OutOfMemory 错误或超过
max.poll.interval.ms的风险
更多详情: Confluent 文档 | Kafka 文档
异步插入
当连接器发送相对较小的批次,或者您希望通过将批处理责任转移到 ClickHouse 来进一步优化摄取时,异步插入是一项强大的功能。
何时使用异步插入
在以下情况下考虑启用异步插入:
- 大量小批次:连接器频繁发送小批次(每批次 < 1000 行)
- 高并发:多个连接器任务同时写入同一张表
- 分布式部署:在不同主机上运行多个连接器实例
- 数据分片创建开销:遇到"数据分片过多"错误
- 混合工作负载:将实时摄取与查询工作负载相结合
在以下情况下不要使用异步插入:
- 已经以受控频率发送大批次(每批次 > 10,000 行)
- 需要立即的数据可见性(查询必须立即看到数据)
- 使用
wait_for_async_insert=0的精确一次语义与您的需求冲突 - 用例可以从客户端批处理改进中获益
异步插入的工作原理
启用异步插入后,ClickHouse 将:
- 从连接器接收插入查询
- 将数据写入内存缓冲区(而不是立即写入磁盘)
- 向连接器返回成功(如果
wait_for_async_insert=0) - 当满足以下条件之一时将缓冲区刷新到磁盘:
- 缓冲区达到
async_insert_max_data_size(默认值:100 MB) - 自首次插入以来经过
async_insert_busy_timeout_ms毫秒(默认值:1000 毫秒) - 累积的查询数量达到最大值(
async_insert_max_query_number,默认值:100)
- 缓冲区达到
这显著减少了创建的parts数量并提高了整体吞吐量。
启用异步插入
将异步插入设置添加到 clickhouseSettings 配置参数:
关键设置:
async_insert=1:启用异步插入wait_for_async_insert=1(推荐):连接器会在确认之前等待数据刷新到 ClickHouse 存储,以提供投递保证。wait_for_async_insert=0:连接器在写入缓冲后立即确认。性能更好,但在刷新前如果服务器崩溃,数据可能会丢失。
调优异步插入行为
可以对异步插入的刷新策略进行精细调优:
Common tuning parameters:
async_insert_max_data_size(默认值:104857600 / 100 MB):触发刷新前的最大缓冲区大小async_insert_busy_timeout_ms(默认值:1000):触发刷新前的最长等待时间(毫秒)async_insert_stale_timeout_ms(默认值:0):自上次插入以来触发刷新前的时间(毫秒)async_insert_max_query_number(默认值:100):触发刷新前的最大查询次数
权衡:
- 优点:更少的数据分片,更好的合并性能,更低的 CPU 开销,在高并发下具备更高吞吐量
- 注意事项:数据无法被立即查询,端到端延迟略有增加
- 风险:如果
wait_for_async_insert=0,服务器崩溃时可能发生数据丢失;缓冲区过大时可能导致内存压力
具有 exactly-once 语义的异步插入
当在异步插入中使用 exactlyOnce=true 时:
重要:在使用 exactly-once 时,始终将 wait_for_async_insert 设为 1,以确保只在数据持久化后才提交 offset。
有关异步插入的更多信息,请参阅 ClickHouse 异步插入(async inserts)文档。
连接器并行度
提高并行度以提升吞吐量:
每个连接器的任务数
每个 task 处理一部分 topic 分区。task 越多,并行度越高,但要注意:
- 最大有效 task 数量 = topic 分区数
- 每个 task 都维护各自与 ClickHouse 的连接
- task 越多,开销越大,资源争用的可能性越高
建议:将 tasks.max 初始设置为 topic 分区数,然后根据 CPU 和吞吐量指标再进行调整。
在批量处理时忽略分区
默认情况下,连接器会按分区对消息进行批量处理。为了提高吞吐量,可以跨分区进行批量处理:
警告:仅在 exactlyOnce=false 时使用。此设置可以通过创建更大的批次来提高吞吐量,但会失去分区级顺序保证。
多个高吞吐量主题
如果你的连接器被配置为订阅多个主题,你使用 topic2TableMap 将主题映射到表,并且在插入阶段出现瓶颈导致消费者出现滞后,可以考虑改为为每个主题创建一个单独的连接器。
出现这种情况的主要原因是,目前批次会串行插入到每一个表中。
建议:对于多个高吞吐量主题,为每个主题部署一个独立的连接器实例,以最大化并行写入吞吐量。
ClickHouse 表引擎注意事项
根据你的使用场景选择合适的 ClickHouse 表引擎:
MergeTree: 适用于大多数场景,在查询性能和写入性能之间取得平衡ReplicatedMergeTree: 实现高可用所必需,但会引入复制开销- 带合适
ORDER BY的*MergeTree: 可针对查询模式进行优化
需要考虑的设置:
连接器级别的插入设置:
连接池和超时设置
连接器会维护到 ClickHouse 的 HTTP 连接池。对于高延迟网络,请调整超时时间:
socket_timeout(默认:30000 ms):读取操作的最长等待时间connection_timeout(默认:10000 ms):建立连接的最长等待时间
如果在处理大批量数据时出现超时错误,请适当增大这些数值。
性能监控与故障排查
监控以下关键指标:
- 消费者延迟 (Consumer lag):使用 Kafka 监控工具按分区跟踪延迟
- 连接器指标:通过 JMX 监控
receivedRecords、recordProcessingTime、taskProcessingTime(参见 Monitoring) - ClickHouse 指标:
system.asynchronous_inserts:监控异步插入缓冲区使用情况system.parts:监控分片数量,用于发现合并问题system.merges:监控进行中的合并system.events:跟踪InsertedRows、InsertedBytes、FailedInsertQuery
常见性能问题:
| 症状 | 可能原因 | 解决方案 |
|---|---|---|
| 消费者延迟较高 | 批次过小 | 增加 max.poll.records,启用异步写入 |
| "Too many parts" 错误 | 小批量且频繁的写入 | 启用异步写入,增大批次大小 |
| 超时错误 | 批次过大、网络较慢 | 减小批次大小,增大 socket_timeout,检查网络 |
| CPU 使用率高 | 过多的小分片 | 启用异步写入,调高合并相关设置 |
| OutOfMemory 错误 | 批次大小过大 | 减小 max.poll.records、max.partition.fetch.bytes |
| 任务负载不均 | 分区分布不均 | 重新均衡分区或调整 tasks.max |
最佳实践总结
- 先使用默认配置,然后根据实际性能进行度量和调优
- 优先使用较大批次:在可能的情况下,每次写入以 10,000–100,000 行为目标
- 在发送大量小批次或处于高并发场景时,优先使用异步写入
- 在需要 exactly-once(精确一次)语义时始终使用
wait_for_async_insert=1 - 水平扩展:将
tasks.max增加到与分区数相同 - 高流量 topic 建议为每个 topic 使用一个独立的连接器,以获得最大吞吐量
- 持续监控:跟踪消费者延迟、分片数量以及合并活动
- 充分测试:在生产部署前,始终在真实负载下测试配置变更
示例:高吞吐量配置
下面是一个为高吞吐量优化的完整示例:
上述连接器配置要求你通过 connector.client.config.override.policy=All 在 worker 配置中启用客户端重写。更多信息请参阅 Kafka Connect 文档。
此配置:
- 每次轮询最多处理 10,000 条记录
- 跨分区进行批处理,以支持更大的批量写入
- 使用 16 MB 缓冲区的异步插入
- 运行 8 个并行任务(与分区数量匹配)
- 针对吞吐量进行了优化,而非严格顺序
故障排查
"State mismatch for topic [someTopic] partition [0]"
当 KeeperMap 中存储的 offset 与 Kafka 中存储的 offset 不一致时,就会出现这种情况,通常发生在某个 topic 被删除 或 offset 被手动调整之后。 要修复此问题,需要删除该特定 topic 和分区对应存储的旧值:
此类调整可能会对 exactly-once 语义产生影响。
"What errors will the connector retry?"
目前的重点是识别可以视为短暂且可重试的错误,包括:
ClickHouseException- 这是一个由 ClickHouse 抛出的通用异常。 通常在服务器过载时抛出,以下错误码被认为是典型的短暂性错误:- 3 - UNEXPECTED_END_OF_FILE
- 107 - FILE_DOESNT_EXIST
- 159 - TIMEOUT_EXCEEDED
- 164 - READONLY
- 202 - TOO_MANY_SIMULTANEOUS_QUERIES
- 203 - NO_FREE_CONNECTION
- 209 - SOCKET_TIMEOUT
- 210 - NETWORK_ERROR
- 241 - MEMORY_LIMIT_EXCEEDED
- 242 - TABLE_IS_READ_ONLY
- 252 - TOO_MANY_PARTS
- 285 - TOO_FEW_LIVE_REPLICAS
- 319 - UNKNOWN_STATUS_OF_INSERT
- 425 - SYSTEM_ERROR
- 999 - KEEPER_EXCEPTION
SocketTimeoutException- 在 socket 超时时抛出。UnknownHostException- 在无法解析主机名时抛出。IOException- 在出现网络问题时抛出。
"所有数据都是空值/0"
很可能是你数据中的字段与表中的字段不匹配——这在使用 CDC(以及 Debezium 格式)时尤其常见。
一个常见的解决方案是在连接器配置中添加 flatten 转换:
这会将你的数据从嵌套 JSON 转换为扁平化 JSON(使用 _ 作为分隔符)。表中的字段将采用 "field1_field2_field3" 的格式(例如 "before_id"、"after_id" 等)。
"我想在 ClickHouse 中使用我的 Kafka 键"
Kafka 键默认不会存储在 value 字段中,但你可以使用 KeyToValue 转换将键移动到 value 字段中(存放在名为 _key 的新字段下):
