从 DynamoDB 到 ClickHouse 的 CDC
本页介绍如何使用 ClickPipes 将 DynamoDB 的数据以 CDC 方式同步到 ClickHouse。此集成由两个组件构成:
- 通过 S3 ClickPipes 进行初始快照
- 通过 Kinesis ClickPipes 进行实时更新
数据将被摄取到一个 ReplacingMergeTree 表中。此表引擎在 CDC 场景中被广泛使用,以支持应用更新操作。关于这一模式的更多信息,请参阅以下博客文章:
- Change Data Capture (CDC) with PostgreSQL and ClickHouse - Part 1
- Change Data Capture (CDC) with PostgreSQL and ClickHouse - Part 2
1. 设置 Kinesis 流
首先,需要在 DynamoDB 表上启用 Kinesis 流,以实时捕获变更。我们希望在创建快照之前先完成这一步,以避免遗漏任何数据。 请参考位于 此处 的 AWS 官方指南。

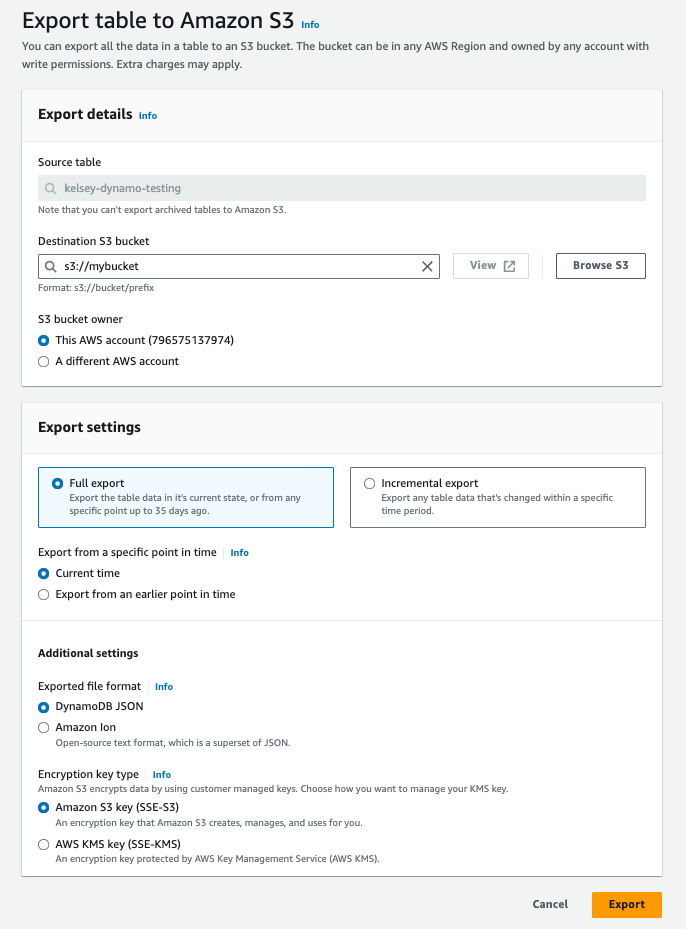
2. 创建快照
接下来,我们将创建 DynamoDB 表的快照。这可以通过使用 AWS 将数据导出到 S3 来实现。请参考位于此处的 AWS 指南。 你需要执行一次使用 DynamoDB JSON 格式的 “Full export”(完整导出)。
3. 将快照载入 ClickHouse
创建必要的表
来自 DynamoDB 的快照数据大致如下所示:
请注意,数据是嵌套格式的。在将其加载到 ClickHouse 之前,我们需要先对其进行扁平化处理。可以在 ClickHouse 中通过 materialized view 结合 JSONExtract 函数来完成这一操作。
我们需要创建三个表:
- 一个用于存储来自 DynamoDB 的原始数据的表
- 一个用于存储最终扁平化数据的表(目标表)
- 一个用于扁平化数据的 materialized view
对于上面示例的 DynamoDB 数据,对应的 ClickHouse 表结构如下:
目标表有以下几个要求:
- 该表必须是一个使用
ReplacingMergeTree引擎的表 - 表中必须有一个
version列- 在后续步骤中,我们会将来自 Kinesis 流的
ApproximateCreationDateTime字段映射到version列。
- 在后续步骤中,我们会将来自 Kinesis 流的
- 表应使用分区键作为排序键(通过
ORDER BY指定)- 具有相同排序键的行将基于
version列进行去重。
- 具有相同排序键的行将基于
创建快照 ClickPipe
现在您可以创建一个 ClickPipe,将快照数据从 S3 加载到 ClickHouse 中。请按照 S3 ClickPipe 指南此处的步骤进行,但使用以下设置:
- Ingest path:您需要在 S3 中找到导出的 json 文件路径。该路径类似于:
- Format: JSONEachRow
- Table: 你的快照表(例如在上面的示例中为
default.snapshot)
创建完成后,数据会开始写入快照表和目标表。无需等待快照加载完成即可继续下一步操作。
4. 创建 Kinesis ClickPipe
现在我们可以配置 Kinesis ClickPipe 来从 Kinesis 流中捕获实时变更。请按照 Kinesis ClickPipe 指南此处的步骤进行,但使用以下设置:
- Stream:在步骤 1 中使用的 Kinesis 流
- Table:目标表(例如上述示例中的
default.destination) - Flatten object:true
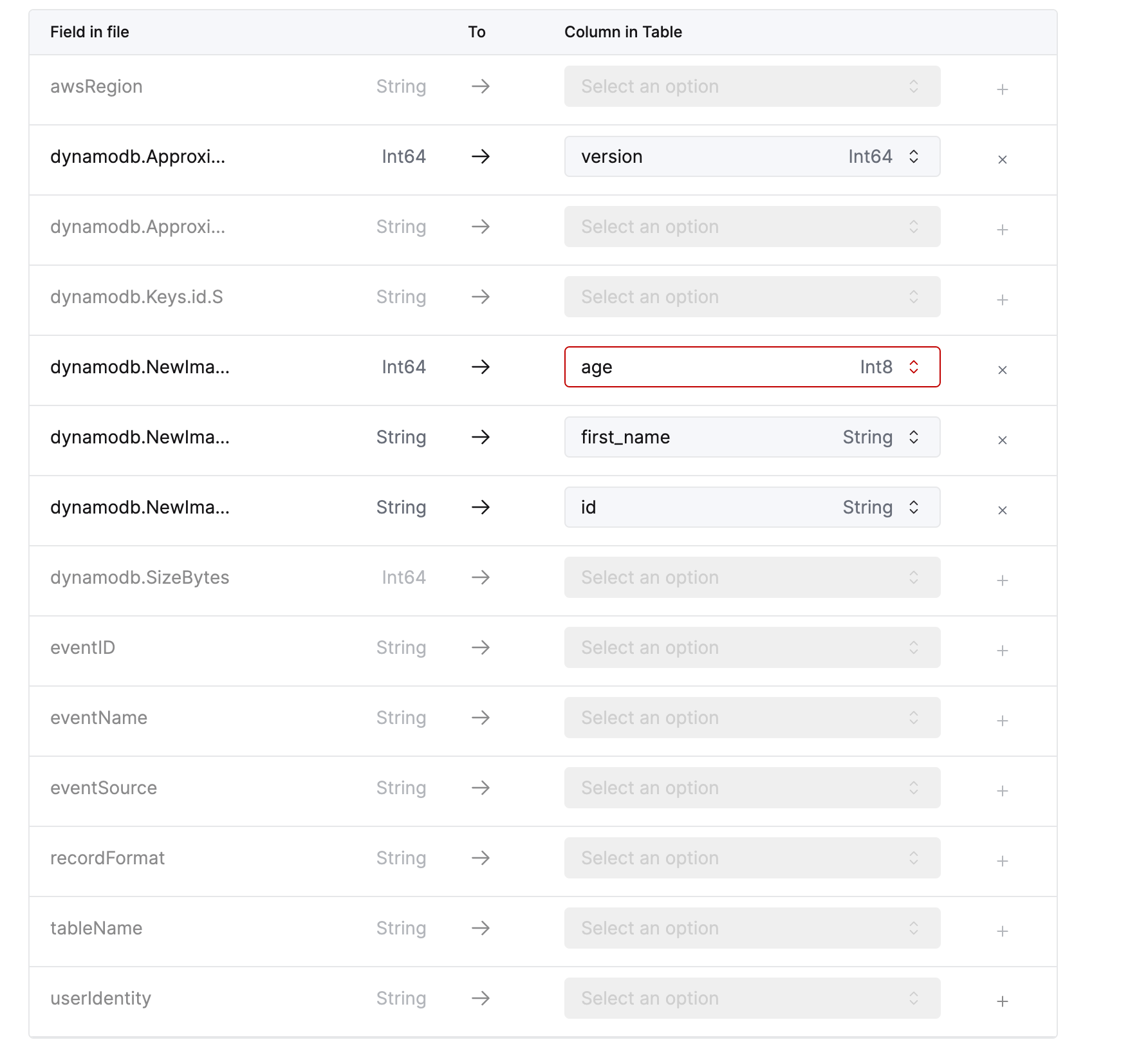
- Column mappings:
ApproximateCreationDateTime:version- 将其他字段映射到如下所示的相应目标列
5. 清理(可选)
当快照 ClickPipe 完成后,您可以删除快照表和 materialized view。
