ClickHouse 与 Databricks 集成
ClickHouse Spark connector 可与 Databricks 无缝集成。本指南介绍适用于 Databricks 的平台特定设置、安装和使用方式。
适用于 Databricks 的 API 选择
默认情况下,Databricks 使用 Unity Catalog,这会阻止 Spark catalog 注册。在这种情况下,必须使用 TableProvider API(基于格式的访问方式)。
但是,如果通过创建一个访问模式为 No isolation shared 的集群来禁用 Unity Catalog,则可以改用 Catalog API。Catalog API 提供集中式配置以及原生的 Spark SQL 集成。
| Unity Catalog 状态 | 推荐 API | 说明 |
|---|---|---|
| 启用(默认) | TableProvider API(基于格式) | Unity Catalog 会阻止 Spark catalog 注册 |
| 禁用(No isolation shared) | Catalog API | 需要访问模式为 "No isolation shared" 的集群 |
在 Databricks 中安装
选项 1:通过 Databricks UI 上传 JAR
-
构建或下载运行时 JAR:
-
将 JAR 上传到 Databricks 工作区:
- 转到 Workspace → 导航到目标文件夹
- 单击 Upload → 选择该 JAR 文件
- JAR 将存储在工作区中
-
在集群上安装该库:
- 转到 Compute → 选择集群
- 单击 Libraries 选项卡
- 单击 Install New
- 选择 DBFS 或 Workspace → 导航到已上传的 JAR 文件
- 单击 Install
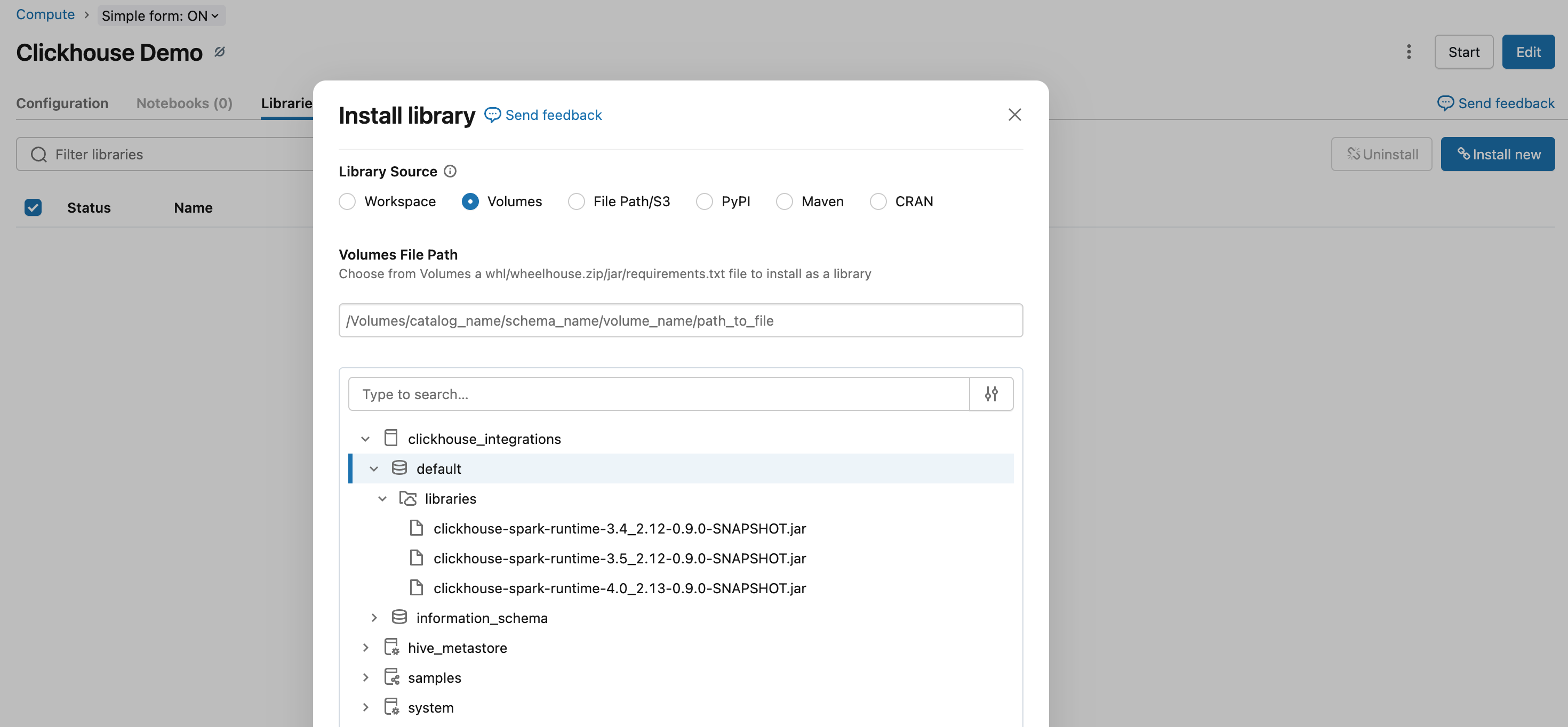
- 重启集群以加载该库
方案 2:通过 Databricks CLI 安装
选项 3:Maven 坐标(推荐)
-
进入您的 Databricks 工作区:
- 前往 Compute → 选择目标集群
- 单击 Libraries 选项卡
- 单击 Install New
- 选择 Maven 选项卡
-
添加 Maven 坐标:
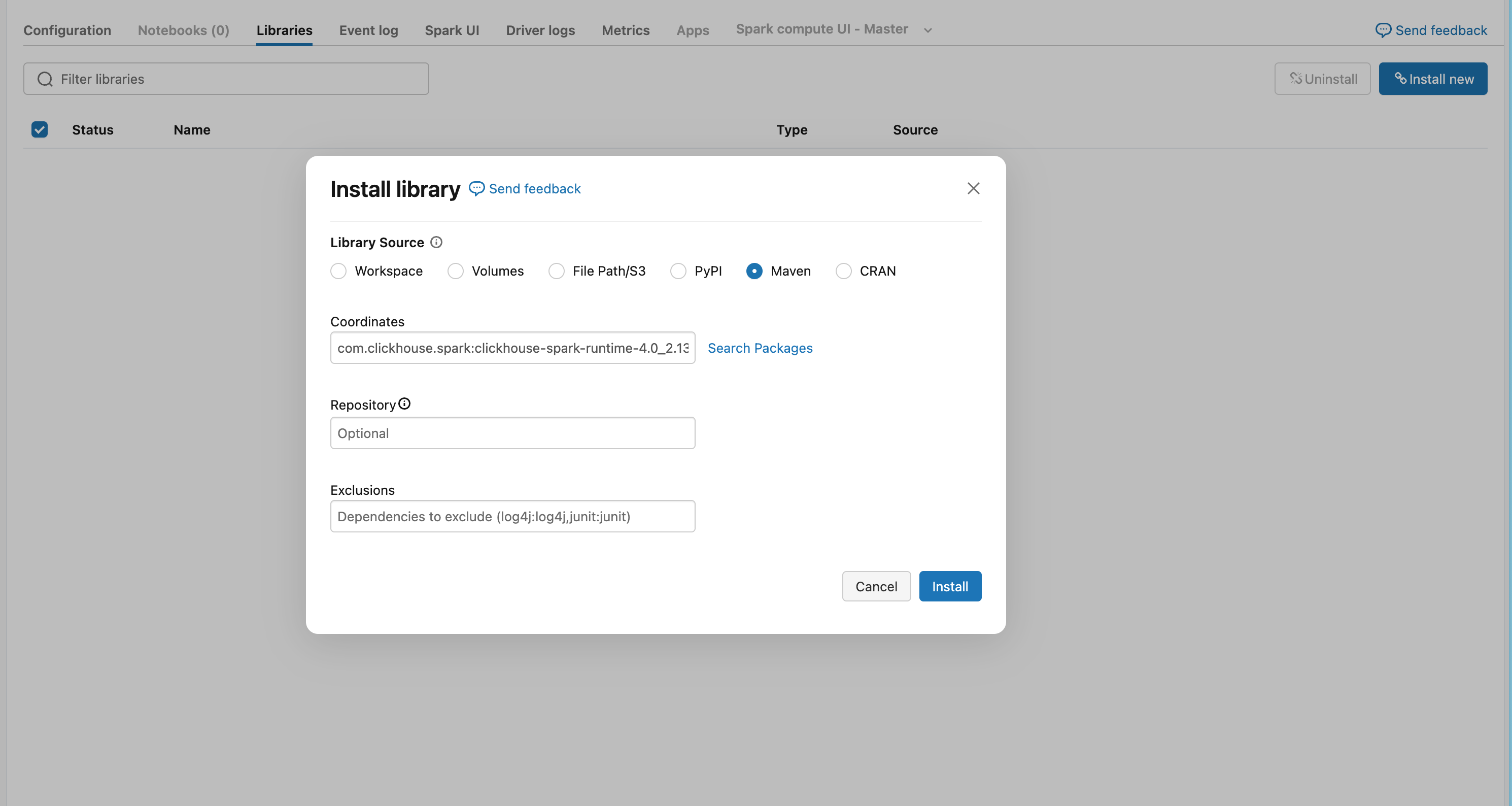
- 单击 Install,然后重启集群以加载该库
使用 TableProvider API
在启用 Unity Catalog(默认)时,必须使用 TableProvider API(基于格式的访问方式),因为 Unity Catalog 会阻止通过 Spark catalog 进行注册。如果您通过使用访问模式为 "No isolation shared" 的集群禁用了 Unity Catalog,则可以改用 Catalog API。
读取数据
- Python
- Scala
写入数据
- Python
- Scala
此示例假定已在 Databricks 中预先配置好 secret scope(机密作用域)。有关配置步骤,请参阅 Databricks 的 Secret 管理文档。
Databricks 特有注意事项
访问模式要求
ClickHouse Spark Connector 需要使用 Dedicated(原 Single User)访问模式。当启用 Unity Catalog 时,不支持 Standard(原 Shared)访问模式,因为在该配置下 Databricks 会阻止外部 DataSource V2 连接器。
| 访问模式 | Unity Catalog | 是否支持 |
|---|---|---|
| Dedicated(Single User) | 启用 | ✅ 是 |
| Dedicated(Single User) | 禁用 | ✅ 是 |
| Standard(Shared) | 启用 | ❌ 否 |
| Standard(Shared) | 禁用 | ✅ 是 |
机密管理
使用 Databricks 的 secret scopes 安全存储 ClickHouse 凭证:
有关配置的说明,请参阅 Databricks 的 Secret 管理文档。
ClickHouse Cloud 连接
从 Databricks 连接到 ClickHouse Cloud 时:
- 使用 HTTPS 协议(
protocol: https,http_port: 8443) - 启用 SSL(
ssl: true)
示例
完整工作流示例
- Python
- Scala
相关文档
- Spark 原生连接器指南 - 完整连接器文档
- TableProvider API 文档 - 基于格式的访问详细说明
- Catalog API 文档 - 基于目录的访问详细说明
