Postgres ClickPipe 中的并行快照
本文说明了 Postgres ClickPipe 中的并行快照/初始加载机制的工作原理,并介绍了可用于控制该机制的快照参数。
概览
初始加载是 CDC ClickPipe 的第一阶段,在这一阶段,ClickPipe 会先将源数据库中各个表的历史数据同步到 ClickHouse,然后再启动 CDC。在很多情况下,开发者会以单线程方式执行这一过程——例如使用 pg_dump 或 pg_restore,或者使用单个线程从源数据库读取数据并写入 ClickHouse。 然而,Postgres ClickPipe 可以将该过程并行化,从而显著提升初始加载速度。
Postgres 中的 CTID 列
在 Postgres 中,表中的每一行都有一个名为 CTID 的唯一标识符。这是一个系统列,默认情况下对用户不可见,但可以用来唯一标识表中的行。CTID 是块号与块内偏移量的组合,这使得可以高效地访问行。
逻辑分区
Postgres ClickPipe 使用 CTID 列对源表进行逻辑分区。它首先对源表执行 COUNT(*),然后通过一个使用窗口函数进行分区的查询来获取每个分区的 CTID 范围。这样 ClickPipe 就可以并行读取源表,每个分区由一个独立的线程进行处理。
下面我们来讨论这些设置:
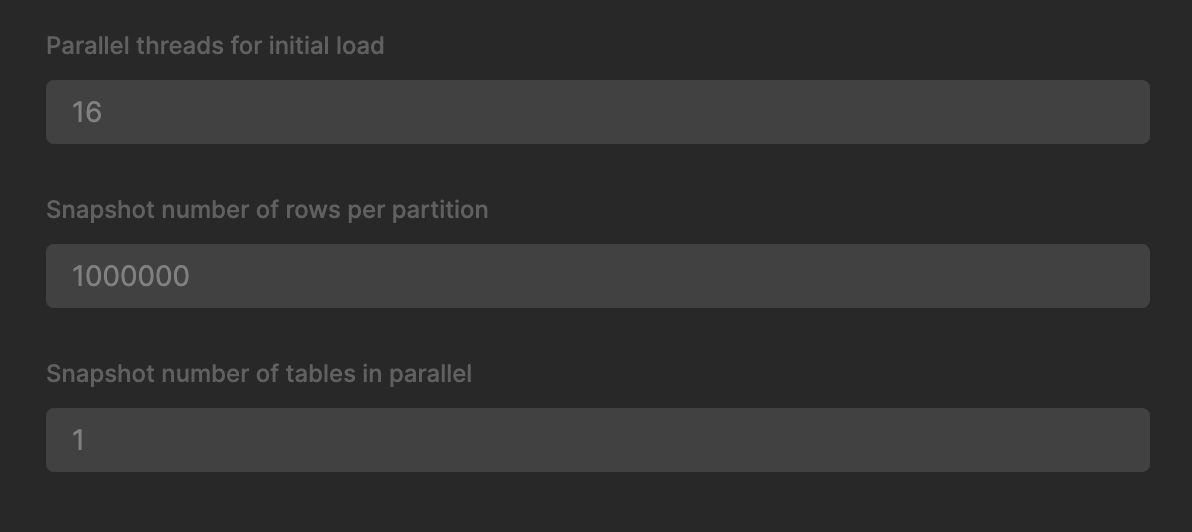
每个分区的快照行数
此设置控制一个分区包含多少行。ClickPipe 会按该大小将源表分块读取,并根据设置的初始加载并行度并行处理这些分块。默认值为每个分区 100,000 行。
初始加载并行度
此设置用于控制同时并行处理的分区数量。默认值为 4,这意味着 ClickPipe 将并行读取源表的 4 个分区。可以提高该值以加快初始加载速度,但建议根据源实例的规格将其保持在合理范围内,以避免给源数据库带来过大压力。ClickPipe 会根据源表的大小和每个分区的行数自动调整分区数量。
并行快照的表数量
虽然与并行快照本身并没有直接关系,但此设置控制在初始加载期间可以同时处理多少张表。默认值为 1。请注意,这是叠加在分区并行度之上的设置,因此如果你有 4 个分区和 2 张表,ClickPipe 将会并行读取 8 个分区。
在 Postgres 中监控并行快照
您可以分析 pg_stat_activity 来查看并行快照的实际运行情况。ClickPipe 会创建多个到源数据库的连接,每个连接读取源表的不同分区。如果您看到具有不同 CTID 范围的 FETCH 查询,这意味着 ClickPipe 正在读取源表。您也可以在这里看到 COUNT(*) 以及用于分区的查询。
限制
- 创建 ClickPipe 之后,快照参数无法修改。如果想要更改这些参数,必须创建一个新的 ClickPipe。
- 向现有的 ClickPipe 添加表时,无法更改快照参数。ClickPipe 会对新表使用现有参数。
- 分区键列不应包含
NULL,因为分区逻辑会跳过这些值。
