去重策略(使用 CDC)
由于 ClickHouse 的数据存储结构以及复制机制,从 Postgres 复制到 ClickHouse 的更新和删除操作会在 ClickHouse 中产生重复行。本页介绍导致这种情况发生的原因,以及在 ClickHouse 中用于处理重复数据的策略。
数据是如何进行复制的?
PostgreSQL 逻辑解码
ClickPipes 使用 Postgres Logical Decoding 来读取 Postgres 中发生的变更。Postgres 中的 logical decoding 过程使得像 ClickPipes 这样的客户端能够以人类可读的格式接收变更,即一系列 INSERT、UPDATE 和 DELETE 操作。
ReplacingMergeTree
ClickPipes 使用 ReplacingMergeTree 引擎将 Postgres 表映射到 ClickHouse。ClickHouse 在追加写(append-only)负载下性能最佳,因此不建议频繁执行 UPDATE 操作。这正是 ReplacingMergeTree 尤其强大的用武之处。
使用 ReplacingMergeTree 时,更新会被表示为插入一条具有更高版本(_peerdb_version)的行,而删除则表示为插入一条具有更高版本且将 _peerdb_is_deleted 标记为 true 的行。ReplacingMergeTree 引擎会在后台对数据进行去重和合并,并为给定主键(id)保留该行的最新版本,从而以版本化插入的方式高效处理 UPDATE 和 DELETE 操作。
下面是一个由 ClickPipes 执行的 CREATE TABLE 语句示例,用于在 ClickHouse 中创建该表。
示例说明
下图演示了使用 ClickPipes 在 PostgreSQL 和 ClickHouse 之间同步 users 表的一个基础示例。
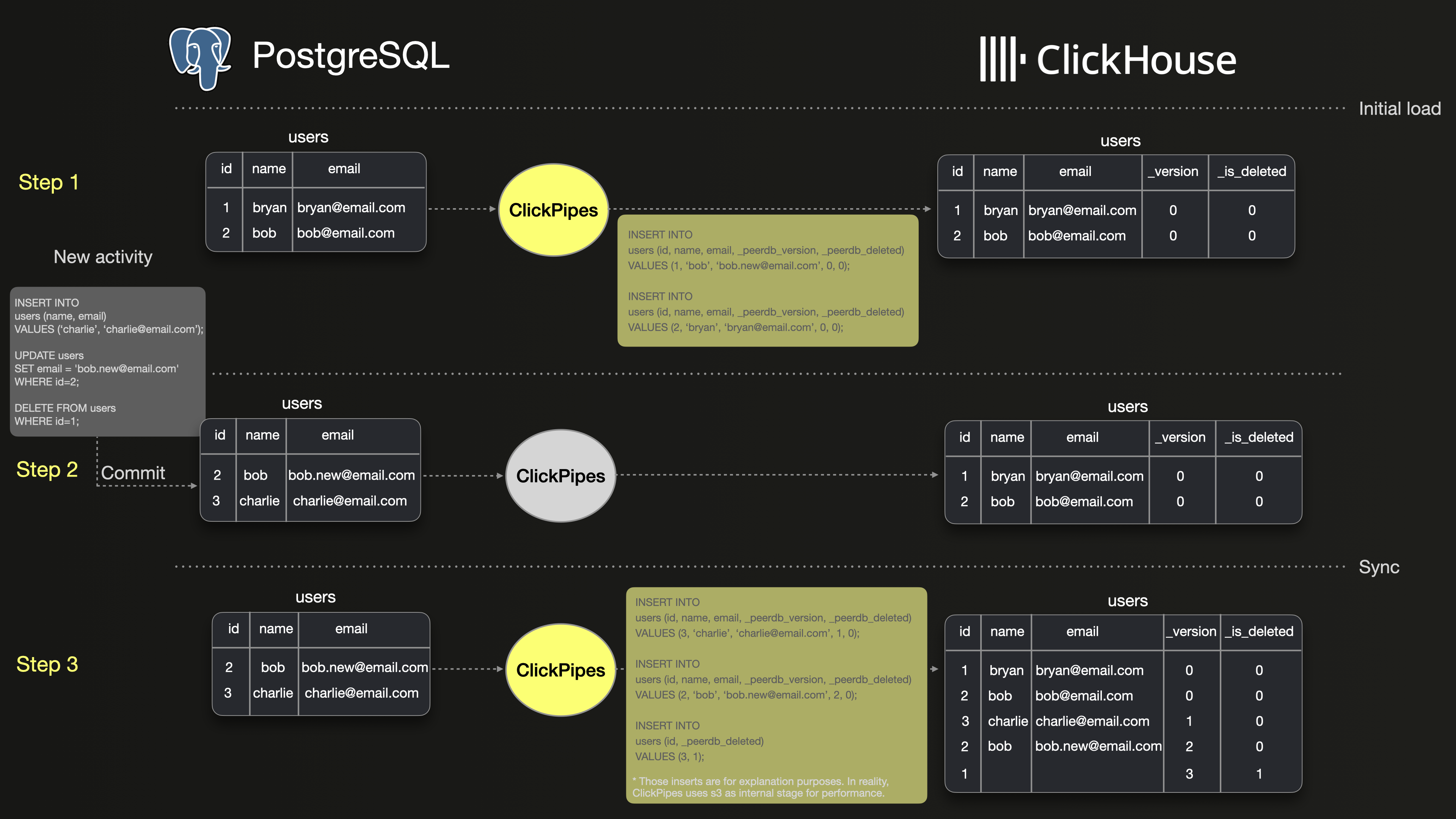
步骤 1 显示的是 PostgreSQL 中 2 行数据的初始快照,以及 ClickPipes 将这 2 行数据初始加载到 ClickHouse 的过程。可以看到,这两行都被原样复制到了 ClickHouse 中。
步骤 2 显示了对 users 表的三个操作:插入一行新数据、更新一行已有数据,以及删除另一行数据。
步骤 3 展示了 ClickPipes 如何将这些 INSERT、UPDATE 和 DELETE 操作以版本化插入的方式复制到 ClickHouse。UPDATE 表现为 ID 为 2 的行的新版本,而 DELETE 表现为 ID 为 1 的新版本,并通过 _is_deleted 标记为 true。因此,ClickHouse 中比 PostgreSQL 多出三行数据。
因此,运行类似 SELECT count(*) FROM users; 这样简单的查询时,ClickHouse 和 PostgreSQL 中的结果可能会有所不同。根据ClickHouse 合并文档的说明,过期的行版本最终会在合并过程中被丢弃。然而,这一合并发生的时间是不可预测的,这意味着在合并发生之前,ClickHouse 中的查询结果可能会不一致。
我们如何才能确保在 ClickHouse 和 PostgreSQL 中得到完全一致的查询结果?
使用 FINAL 关键字进行去重
在 ClickHouse 查询中,推荐的去重方式是使用 FINAL 修饰符。这可以确保只返回去重后的行。
让我们来看一下如何将它应用到三种不同的查询中。
注意以下查询中的 WHERE 子句,用于过滤被删除的行。
- 简单计数查询:统计帖子数量。
这是可以运行的最简单查询,用于检查同步是否正确完成。两个查询应该返回相同的计数结果。
- 带有 JOIN 的简单聚合:累计浏览次数最多的前 10 个用户。
这是一个对单表进行聚合的示例。如果这里存在重复数据,将会严重影响 sum 函数结果的准确性。
FINAL 设置项
与其在查询中为每个表名单独添加 FINAL 修饰符,你可以使用 FINAL 设置项,将其自动应用到查询中的所有表。
此设置项可以针对单个查询生效,也可以作用于整个会话。
ROW policy
隐藏多余的 _peerdb_is_deleted = 0 过滤条件的一个简单方法是使用 ROW policy。下面是一个示例,演示如何创建一个 ROW policy,在对 votes 表的所有查询中排除已删除的行。
行级策略会应用到一组用户和角色上。在本示例中,它适用于所有用户和角色。也可以将其调整为仅适用于特定用户或角色。
像在 Postgres 中一样查询
将分析型数据集从 PostgreSQL 迁移到 ClickHouse 时,通常需要修改应用程序中的查询,以适应两者在数据处理和查询执行方式上的差异。
本节将介绍在保持原有查询不变的前提下,对数据进行去重的技术。
视图
Views 是在查询中隐藏 FINAL 关键字的一种很好方式,因为它们本身不存储任何数据,只是在每次访问时简单地从另一张表中读取数据。
下面是在 ClickHouse 中为我们数据库的每张表创建视图的示例,这些视图使用 FINAL 关键字,并过滤掉已删除的行。
然后,我们可以像在 PostgreSQL 中那样,使用相同的查询来查询这些视图。
可刷新materialized view
另一种方法是使用可刷新materialized view,通过定期调度执行查询,对行进行去重,并将结果写入目标表。每次按计划刷新时,目标表都会被最新的查询结果替换。
这种方法的主要优势在于,包含 FINAL 关键字的查询仅在刷新时执行一次,此后针对目标表的查询无需再使用 FINAL。
不过,其缺点是目标表中的数据只能保证与最近一次刷新时的数据保持一致。对于许多使用场景而言,从几分钟到几小时不等的刷新间隔通常已经足够。
然后即可像往常一样对表 deduplicated_posts 进行查询。
