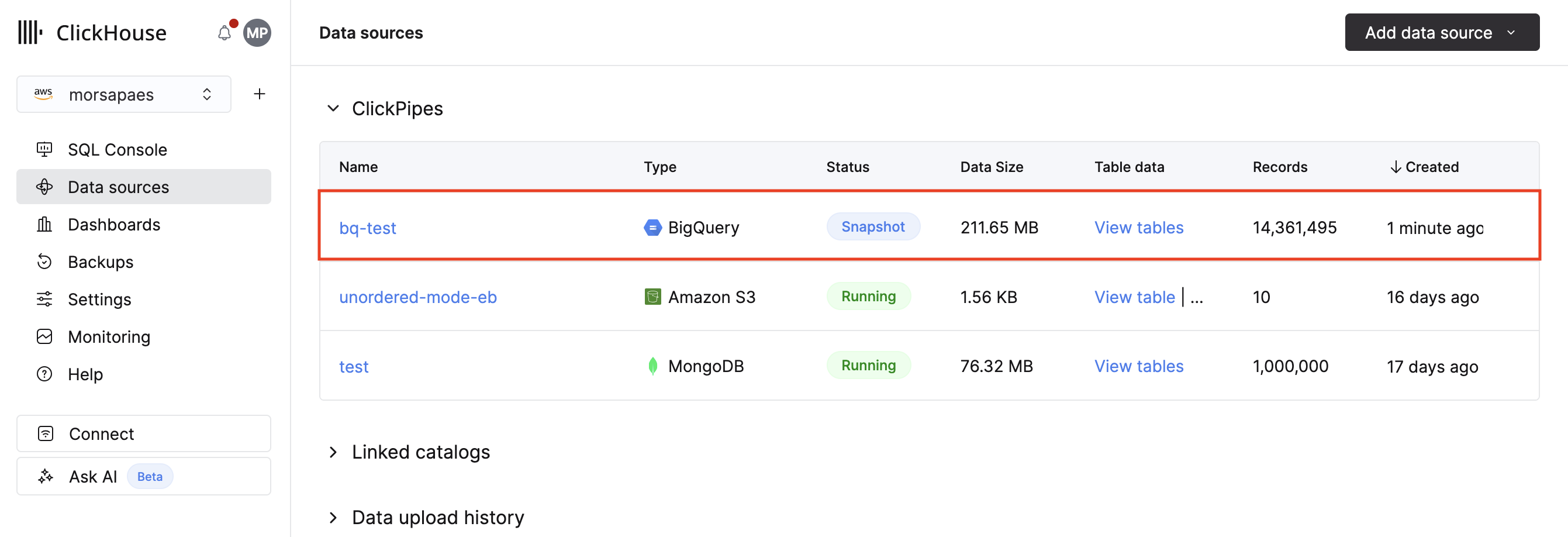
创建您的第一个 BigQuery ClickPipe
你可以在这里注册加入 Private Preview 候补名单。
BigQuery ClickPipe 为从 BigQuery 向 ClickHouse Cloud 摄取数据提供了一种全托管且高可靠性的方式。在 Private Preview 阶段,它支持 initial load (初始加载) 复制方式,帮助你批量加载 BigQuery 数据集用于探索和原型验证。未来将支持 CDC —— 在此之前,我们建议在完成初始加载 (initial load) 之后,使用 Google Cloud Storage ClickPipe 将 BigQuery 导出的数据持续同步到 ClickHouse Cloud。
可以通过 ClickPipes UI 手动部署和管理 BigQuery ClickPipes,也可以通过 OpenAPI 和 Terraform 以编程方式进行管理。
前置条件
-
你必须拥有在 GCP 项目中管理服务账号和 IAM 角色的权限,或者从管理员那里获得协助。我们建议按照官方文档创建一个具有最小必需权限集合的专用服务账号。
-
初始加载过程需要由用户提供的 Google Cloud Storage (GCS) bucket 作为中间暂存区域。我们建议按照官方文档为你的 ClickPipe 创建一个专用 bucket。未来,中间 bucket 将由 ClickPipes 提供并进行管理。
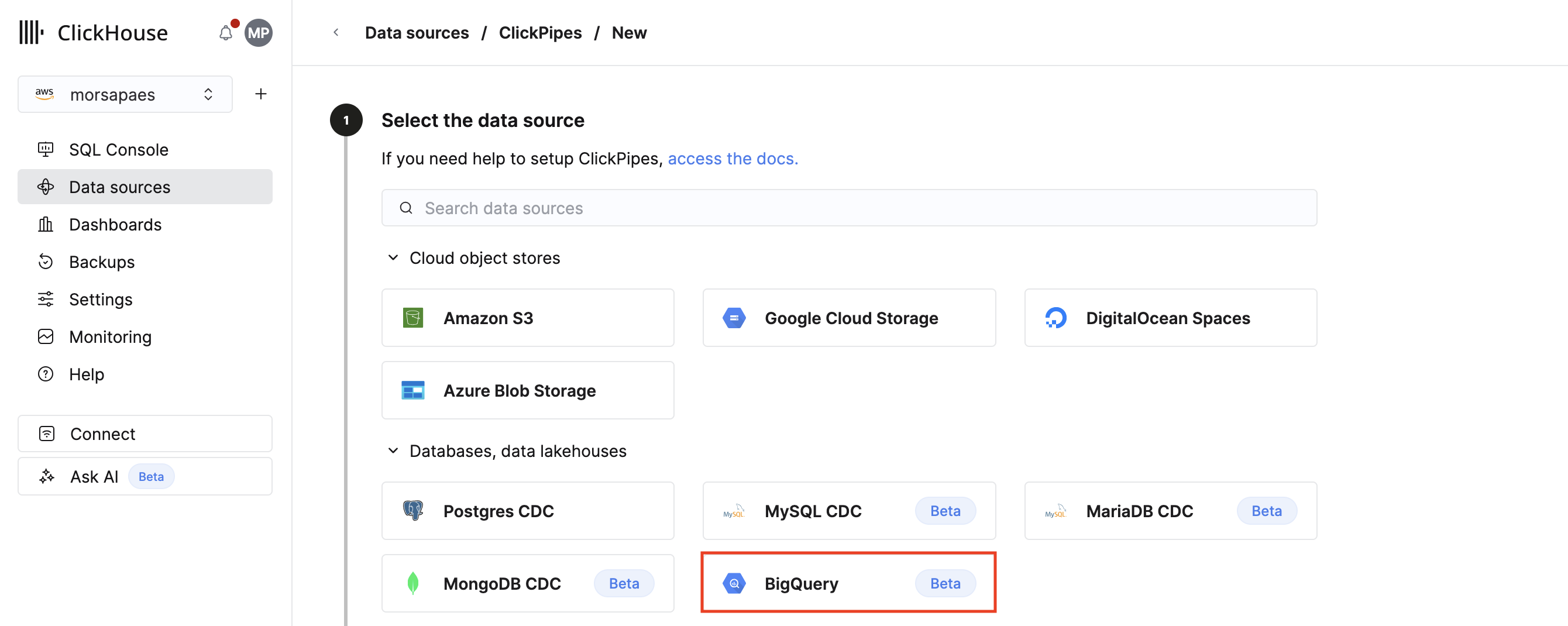
设置 ClickPipe 连接
要设置一个新的 ClickPipe,你必须提供如何连接到 BigQuery 数仓并进行身份验证的信息,以及一个用于暂存的 GCS bucket。
1. 上传为 ClickPipes 创建的服务账号对应的 .json 密钥。确保该服务账号具有最小必需的权限集合。
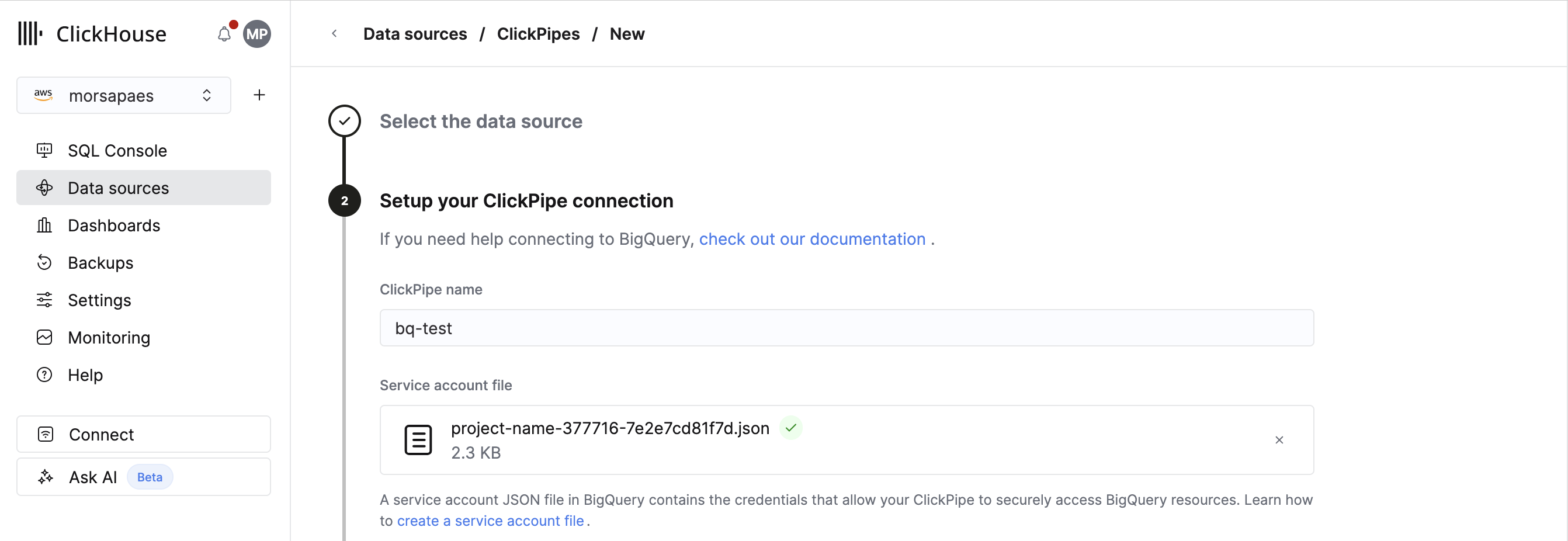
2. 选择 Replication method。在 Private Preview 中,唯一支持的选项是 Initial load only。
3. 提供在初始加载期间用于暂存数据的 GCS bucket 路径。
4. 点击 Next 进行验证。
配置 ClickPipe
根据 BigQuery 数据集的大小或你想要同步的表的总大小,你可能需要调整该 ClickPipe 的默认摄取设置。
配置表
1. 选择要将 BigQuery 表复制到的 ClickHouse 数据库。你可以选择一个已有数据库或创建一个新的数据库。
2. 选择要复制的表,以及可选的列。只会列出所提供服务账号有权访问的数据集。
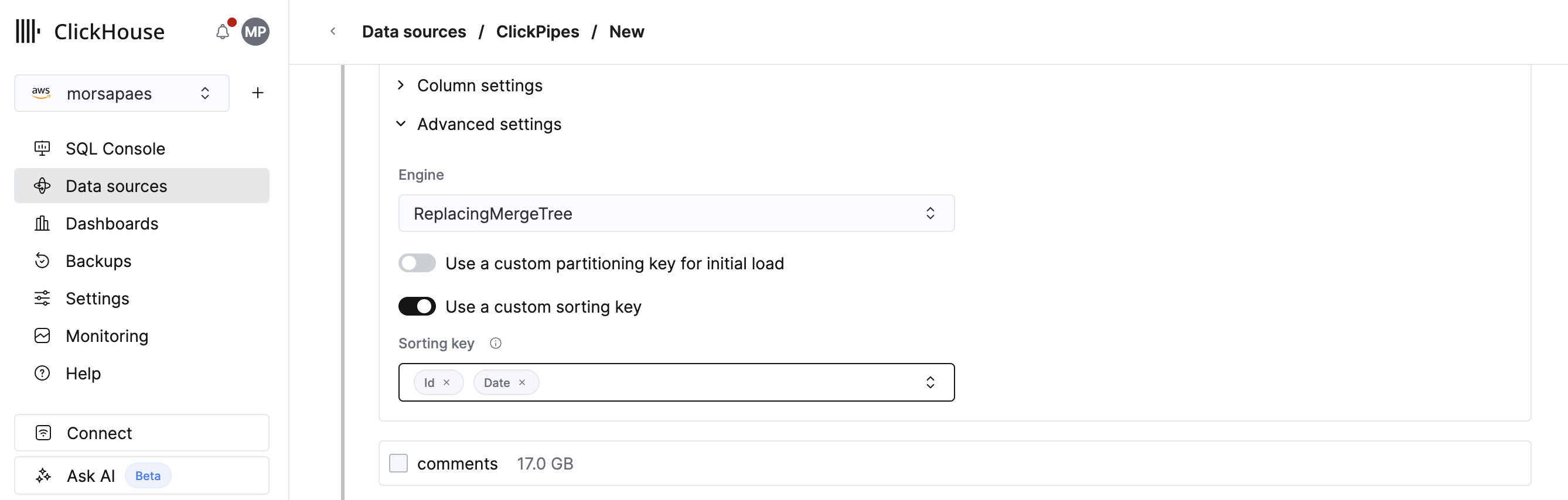
3. 对于每个选定的表,确保在 Advanced settings > Use a custom sorting key 下定义一个自定义排序键。未来,排序键将会基于上游数据库中现有的聚簇或分区键自动推断。
你必须为复制的表定义排序键,以便在 ClickHouse 中优化查询性能。否则,排序键将被设置为 tuple(),这意味着不会创建主索引,且 ClickHouse 会对该表上的所有查询执行全表扫描。
配置权限
最后,你可以为内部的 ClickPipes 用户配置权限。
Permissions: ClickPipes 将创建一个专用用户,用于向目标表写入数据。你可以为该内部用户选择一个角色,使用自定义角色或预定义角色之一:
Full access:对集群具有完全访问权限。如果你在目标表上使用 materialized views 或字典,则需要此角色。Only destination:仅对目标表具有插入权限。