与 ClickHouse Cloud 集成
介绍
ClickPipes 是一个托管集成平台,可将来自多种来源的数据摄取过程简化为只需点击几下。ClickPipes 的强大且可扩展架构专为最严苛的工作负载设计,确保性能和可靠性的一致性。ClickPipes 既可用于长期的流式数据场景,也可用于一次性的数据加载作业。
ClickPipes 既可以通过 ClickPipes UI 手动部署和管理,也可以借助 OpenAPI 和 Terraform 以编程方式进行部署和管理。

支持的数据源
| 名称 | Logo | 类型 | 状态 | 描述 |
|---|---|---|---|---|
| Apache Kafka | 流式 | 稳定 | 配置 ClickPipes,并开始将来自 Apache Kafka 的流式数据摄取到 ClickHouse Cloud。 | |
| Confluent Cloud | 流式 | 稳定 | 通过我们的直接集成,释放 Confluent 与 ClickHouse Cloud 结合的强大能力。 | |
| Redpanda |  | 流式 | 稳定 | 配置 ClickPipes,并开始将来自 Redpanda 的流式数据摄取到 ClickHouse Cloud。 |
| AWS MSK | 流式 | 稳定 | 配置 ClickPipes,并开始将来自 AWS MSK 的流式数据摄取到 ClickHouse Cloud。 | |
| Azure Event Hubs | 流式 | 稳定 | 配置 ClickPipes,并开始将来自 Azure Event Hubs 的流式数据摄取到 ClickHouse Cloud。请参阅 Azure Event Hubs FAQ 获取指导。 | |
| WarpStream | 流式 | 稳定 | 配置 ClickPipes,并开始将来自 WarpStream 的流式数据摄取到 ClickHouse Cloud。 | |
| Amazon S3 | 对象存储 | 稳定 | 配置 ClickPipes,从对象存储中摄取海量数据。 | |
| Google Cloud Storage | 对象存储 | 稳定 | 配置 ClickPipes,从对象存储中摄取海量数据。 | |
| DigitalOcean Spaces | 对象存储 | 稳定 | 配置 ClickPipes,从对象存储中摄取海量数据。 | |
| Azure Blob Storage | 对象存储 | 稳定 | 配置 ClickPipes,从对象存储中摄取海量数据。 | |
| Amazon Kinesis | 流式 | 稳定 | 配置 ClickPipes,并开始将来自 Amazon Kinesis 的流式数据摄取到 ClickHouse Cloud。 | |
| GCP Pub/Sub | 流式 | Public Beta | 配置 ClickPipes,并开始将来自 Google Cloud Pub/Sub 的流式数据摄取到 ClickHouse Cloud。 | |
| Postgres | DBMS | 稳定 | 配置 ClickPipes,并开始将来自 Postgres 的数据摄取到 ClickHouse Cloud。 | |
| MySQL | DBMS | Public Beta | 配置 ClickPipes,并开始将来自 MySQL 的数据摄取到 ClickHouse Cloud。 | |
| MongoDB | DBMS | 私有预览 | 配置 ClickPipes,并开始将来自 MongoDB 的数据摄取到 ClickHouse Cloud。 |
后续会为 ClickPipes 不断增加更多连接器,您可以通过联系我们了解更多信息。
静态 IP 列表
下表列出了 ClickPipes 用于连接到你外部服务的静态 NAT IP 地址。将为你的 ClickHouse Cloud 服务提供服务的 ClickPipes 区域对应的 IP 添加到你的 IP 允许列表中。对于对象存储管道,你还应将 ClickHouse 集群 IPs 添加到 IP 允许列表中。
对于下方 Google Cloud 表中列出的 Google Cloud 区域中的服务,只有在该服务创建于 2026 年 5 月 27 日或之后时,才会使用这些 Google Cloud IP。对于在 2026 年 5 月 27 日之前创建于这些区域的服务,则继续使用下方列出的默认区域 IP。
对于其他服务,ClickPipes 的流量将基于你的服务所在位置,从默认区域发出:
- eu-central-1:适用于所有未明确列出的欧盟区域,以及 Azure 的欧盟区域和在 2026 年 5 月 27 日之前创建的 Google Cloud 欧盟服务。
- eu-west-1:适用于在 2026 年 1 月 20 日或之后创建的 AWS
eu-west-1中的所有服务 (在此日期之前创建的服务使用eu-central-1的 IP) 。 - us-east-1:适用于 AWS
us-east-1中的所有服务。 - ap-south-1:适用于在 2025 年 6 月 25 日或之后创建的 AWS
ap-south-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - ap-northeast-2:适用于在 2025 年 11 月 14 日或之后创建的 AWS
ap-northeast-2中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - af-south-1:适用于在 2026 年 4 月 15 日或之后创建的 AWS
af-south-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - ap-east-1:适用于在 2026 年 4 月 15 日或之后创建的 AWS
ap-east-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - ap-northeast-1:适用于在 2026 年 4 月 15 日或之后创建的 AWS
ap-northeast-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - ap-southeast-1:适用于在 2026 年 3 月 18 日或之后创建的 AWS
ap-southeast-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - ap-southeast-2:适用于在 2025 年 6 月 25 日或之后创建的 AWS
ap-southeast-2中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - ap-southeast-3:适用于在 2026 年 3 月 6 日或之后创建的 AWS
ap-southeast-3中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - ca-central-1:适用于在 2026 年 4 月 15 日或之后创建的 AWS
ca-central-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - eu-north-1:适用于在 2026 年 4 月 15 日或之后创建的 AWS
eu-north-1中的所有服务 (在此日期之前创建的服务使用eu-central-1的 IP) 。 - eu-west-2:适用于在 2026 年 4 月 15 日或之后创建的 AWS
eu-west-2中的所有服务 (在此日期之前创建的服务使用eu-central-1的 IP) 。 - il-central-1:适用于在 2026 年 4 月 15 日或之后创建的 AWS
il-central-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - mx-central-1:适用于在 2026 年 5 月 19 日或之后创建的 AWS
mx-central-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - sa-east-1:适用于在 2026 年 4 月 15 日或之后创建的 AWS
sa-east-1中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - us-west-2:适用于在 2025 年 6 月 24 日或之后创建的 AWS
us-west-2中的所有服务 (在此日期之前创建的服务使用us-east-2的 IP) 。 - us-east-2:适用于所有不匹配上述规则的其他区域,包括 Azure 区域以及在 2026 年 5 月 27 日之前创建的 Google Cloud 服务。
AWS 静态 NAT IP 地址
| AWS 区域 | IP 地址 |
|---|---|
| eu-central-1 - 法兰克福 | 18.195.233.217, 3.127.86.90, 35.157.23.2, 18.197.167.47, 3.122.25.29, 52.28.148.40 |
| eu-west-1 - 爱尔兰 (自 2026 年 1 月 20 日起) | 54.228.1.92 , 54.72.101.254, 54.228.16.208, 54.76.200.104, 52.211.2.177, 54.77.10.134 |
| us-east-1 - 弗吉尼亚北部 | 54.82.38.199, 3.90.133.29, 52.5.177.8, 3.227.227.145, 3.216.6.184, 54.84.202.92, 3.131.130.196, 3.23.172.68, 3.20.208.150 |
| us-east-2 - 俄亥俄 | 3.131.130.196, 3.23.172.68, 3.20.208.150, 3.132.20.192, 18.119.76.110, 3.134.185.180 |
| ap-south-1 - 孟买 (自 2025 年 6 月 25 日起) | 13.203.140.189, 13.232.213.12, 13.235.145.208, 35.154.167.40, 65.0.39.245, 65.1.225.89 |
| ap-northeast-2 - 首尔 (自 2025 年 11 月 14 日起) | 3.38.68.69, 52.78.68.128, 13.209.152.13, 3.38.24.84, 3.37.159.31, 3.34.25.104 |
| ap-southeast-1 - 新加坡 (自 2026 年 3 月 18 日起) | 13.215.65.134, 18.139.118.108, 47.130.197.47, 54.251.134.219, 54.254.98.29, 54.255.153.106 |
| ap-southeast-2 - 悉尼 (自 2025 年 6 月 25 日起) | 3.106.48.103, 52.62.168.142, 13.55.113.162, 3.24.61.148, 54.206.77.184, 54.79.253.17 |
| af-south-1 - 开普敦 (自 2026 年 4 月 15 日起) | 13.245.187.24, 15.240.60.178, 15.240.81.191, 13.245.25.101, 13.245.91.225, 15.240.54.195 |
| ap-east-1 - 香港 (自 2026 年 4 月 15 日起) | 18.166.168.168, 43.199.224.85, 95.40.0.242, 16.162.107.229, 43.199.125.240, 54.46.86.27 |
| ap-northeast-1 - 东京 (自 2026 年 4 月 15 日起) | 54.168.88.92, 35.76.97.79, 54.64.100.89, 54.178.40.17, 52.195.101.208, 13.193.109.245 |
| ap-southeast-1 - 新加坡 (自 2026 年 3 月 18 日起) | 47.130.197.47, 54.251.134.219, 18.139.118.108, 54.255.153.106, 54.254.98.29, 13.215.65.134 |
| ap-southeast-3 - 雅加达 (自 2026 年 3 月 6 日起) | 16.78.195.195, 43.218.184.235, 16.79.88.54, 16.78.153.162, 16.79.6.125, 108.137.52.155 |
| ca-central-1 - 加拿大 (自 2026 年 4 月 15 日起) | 52.60.123.235, 3.97.222.98, 3.99.62.248, 15.223.61.186, 3.96.255.101, 3.97.29.96 |
| eu-north-1 - 斯德哥尔摩 (自 2026 年 4 月 15 日起) | 13.63.1.65, 16.171.127.30, 56.228.76.44, 13.63.101.248, 16.170.124.188, 13.60.109.201 |
| eu-west-2 - 伦敦 (自 2026 年 4 月 15 日起) | 13.134.82.158, 16.60.209.167, 18.134.221.203, 16.60.139.176, 13.43.66.75, 3.11.78.183 |
| il-central-1 - 特拉维夫 (自 2026 年 4 月 15 日起) | 16.164.25.13, 51.84.162.29, 51.85.90.183, 51.84.36.146, 51.84.72.29, 51.85.28.184 |
| mx-central-1 - 墨西哥 (自 2026 年 5 月 19 日起) | 78.12.67.220, 78.12.117.175, 78.13.186.238, 78.13.219.184, 78.13.224.212, 78.13.248.162 |
| sa-east-1 - 圣保罗 (自 2026 年 4 月 15 日起) | 18.230.164.131, 56.126.1.234, 18.230.39.24, 15.229.102.116, 18.230.174.204, 18.229.237.116 |
| us-west-2 - 俄勒冈 (自 2025 年 6 月 24 日起) | 52.42.100.5, 44.242.47.162, 52.40.44.52, 44.227.206.163, 44.246.241.23, 35.83.230.19 |
Google Cloud 静态 NAT IP 地址
| Google Cloud 区域 | IP 地址 |
|---|---|
| asia-northeast1 - 东京 (自 2026 年 5 月 27 日起) | 104.198.114.210, 35.221.66.81, 35.243.126.127, 136.110.107.86, 34.85.18.112 |
| asia-southeast1 - 新加坡 (自 2026 年 5 月 27 日起) | 34.21.197.28, 35.197.141.23, 35.197.157.90, 136.110.17.200, 35.185.179.231 |
| europe-west2 - 伦敦 (自 2026 年 5 月 27 日起) | 35.242.131.178, 34.39.77.101, 34.39.47.179, 34.89.53.234, 8.228.63.151 |
| europe-west4 - 荷兰 (自 2026 年 5 月 27 日起) | 34.34.86.3, 34.6.175.56, 34.178.6.187, 34.91.204.220, 34.12.85.206 |
| us-central1 - 爱荷华州 (自 2026 年 5 月 27 日起) | 34.28.24.54, 34.42.56.195, 34.63.141.9, 35.238.146.37, 34.10.251.49 |
| us-east1 - 南卡罗来纳州 (自 2026 年 5 月 27 日起) | 34.24.134.232, 34.24.214.165, 34.24.20.1, 35.243.193.248, 34.23.98.76 |
调整 ClickHouse 设置
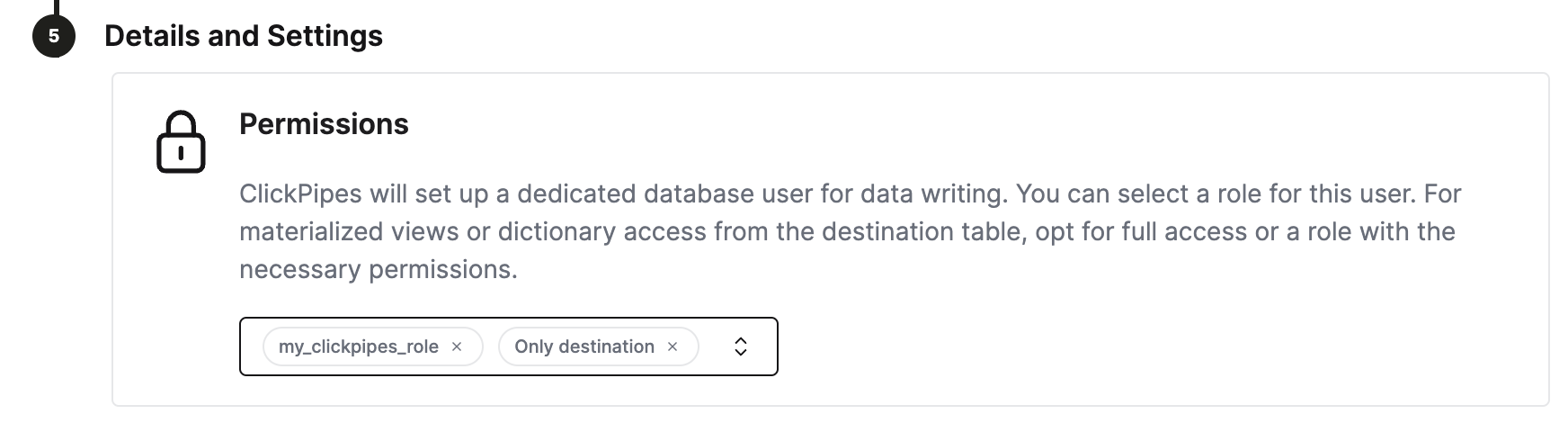
ClickHouse Cloud 为大多数用例提供了合理的默认设置。不过,如果需要为 ClickPipes 的目标表调整某些 ClickHouse 设置,为 ClickPipes 创建一个专用角色是最灵活的做法。 步骤:
- 创建自定义角色
CREATE ROLE my_clickpipes_role SETTINGS ...。有关详情,请参阅 CREATE ROLE 语法。 - 在创建 ClickPipes 时,于
Details and Settings步骤中将该自定义角色分配给 ClickPipes 用户。
调整 ClickPipes 高级设置
ClickPipes 提供了合理的默认设置,可满足大多数使用场景的需求。如果您的使用场景需要进一步精细调优,可以调整以下设置:
对象存储 ClickPipes
| Setting | Default value | Description |
|---|---|---|
Max insert bytes | 10 GB | 在单个插入批次中可处理的最大字节数。 |
Max file count | 100 | 在单个插入批次中可处理的最大文件数。 |
Max threads | auto(3) | 用于文件处理的最大并发线程数。 |
Max insert threads | 1 | 用于文件处理的最大并发插入线程数。 |
Min insert block size bytes | 1 GB | 可插入到表中的数据块的最小字节大小。 |
Max download threads | 4 | 最大并发下载线程数。 |
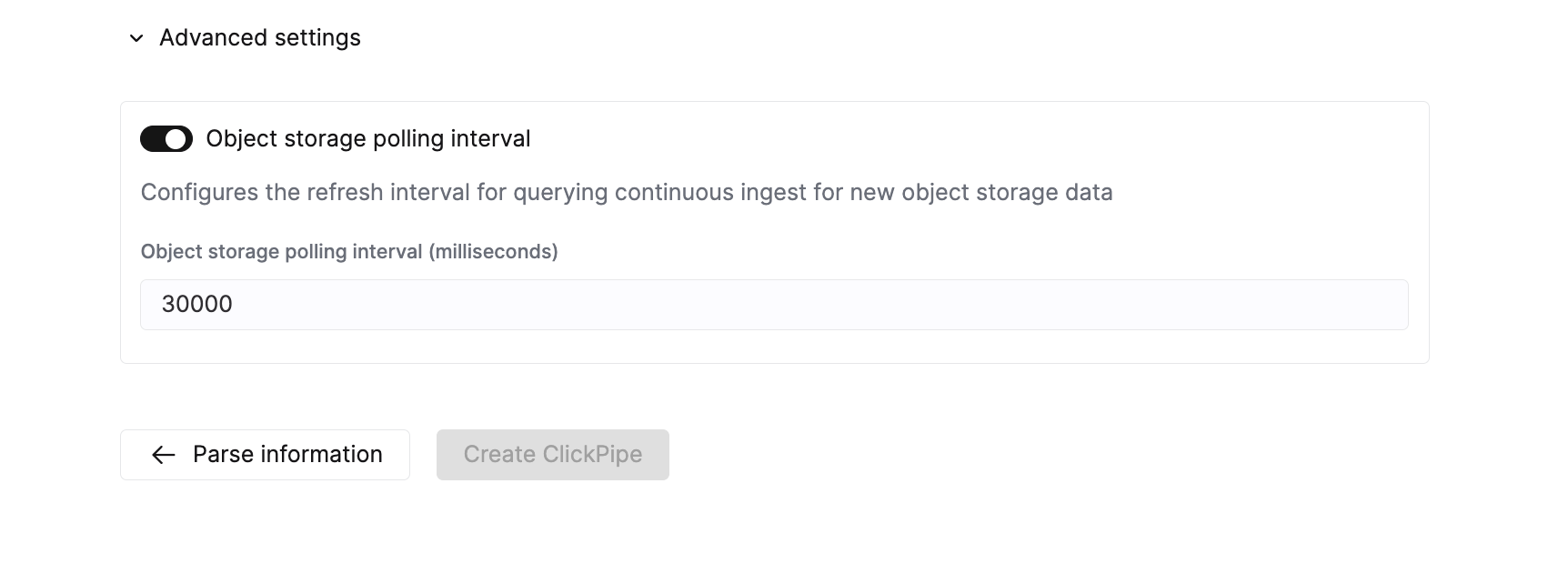
Object storage polling interval | 30 s | 配置在将数据插入 ClickHouse 集群前的最大等待时间。 |
Parallel distributed insert select | 2 | 并行分布式 INSERT SELECT 设置。 |
Parallel view processing | false | 是否启用并行而非顺序地将数据推送到附加 VIEW。详见相关设置。 |
Use cluster function | true | 是否在多个节点之间并行处理文件。 |
流式 ClickPipes
| 设置 | 默认值 | 描述 |
|---|---|---|
Streaming max insert wait time | 5 s | 配置在将数据插入 ClickHouse 集群之前的最长等待时间。 |
错误报告
ClickPipes 会根据摄取过程中遇到的错误类型,将错误分别存储在两个独立的表中。
记录错误
ClickPipes 会在目标表所在的数据库中创建一个后缀为 <destination_table_name>_clickpipes_error 的表。该表会包含由于数据格式不正确或 schema 不匹配而产生的所有错误,并保存整条无效消息。此表的生存时间 (TTL)为 7 天。
系统错误
与 ClickPipe 运行相关的错误将存储在 system.clickpipes_log 表中。该表还会记录所有与 ClickPipe 运行相关的其他错误 (如网络、连接等) 。此表的生存时间 (TTL) 为 7 天。
如果 ClickPipes 在 15 分钟内无法连接到数据源,或在 1 小时内无法连接到目标端,则该 ClickPipes 实例会停止运行,并在系统错误表中存储一条相应的消息 (前提是 ClickHouse 实例可用) 。
监控
除了控制台内的监控外,ClickPipes 还会将指标暴露到一个兼容 Prometheus 的端点,供抓取使用。这些指标会与其他 ClickHouse Cloud 服务指标一同发布,让您能够将 ClickPipes 监控集成到现有的可观测性堆栈中 (例如 Grafana 和 Datadog) 。有关可用指标的完整列表,请参阅 Monitoring ClickPipes。
常见问题解答
-
什么是 ClickPipes?
ClickPipes 是 ClickHouse Cloud 的一项功能,可帮助你轻松将 ClickHouse 服务连接到外部数据源,尤其是 Kafka。借助 ClickPipes for Kafka,你可以轻松、持续地将数据摄取到 ClickHouse 中,从而支持实时分析。
-
ClickPipes 是否支持数据转换?
是的,ClickPipes 通过提供 DDL 创建能力来支持基础的数据转换。然后,你可以在数据加载到 ClickHouse Cloud 服务中的目标表时,结合 ClickHouse 的 materialized views 功能,对数据应用更高级的转换。
-
使用 ClickPipes 是否会产生额外费用?
ClickPipes 按两个维度计费:数据摄取量和计算资源。完整的定价细节可在此页面上查看。运行 ClickPipes 还可能在目标 ClickHouse Cloud 服务上产生类似任何摄取工作负载的间接计算和存储成本。
-
在将 ClickPipes 用于 Kafka 时,有没有办法处理错误或故障?
有的,ClickPipes for Kafka 在由于任何运行问题(包括网络问题、连接问题等)导致从 Kafka 消费数据时发生故障时,会自动进行重试。对于格式错误的数据或无效的 schema,ClickPipes 会将记录存储在
record_error表中并继续处理。
