集成 Azure Synapse 与 ClickHouse
ClickHouse Supported
Azure Synapse 是一项集成式分析服务,结合了大数据、数据科学和数据仓库能力,可实现快速的大规模数据分析。 在 Synapse 中,Spark 池提供按需、可扩展的 Apache Spark 集群,让您能够执行复杂的数据转换、机器学习任务,以及与外部系统的集成。
本文将介绍在 Azure Synapse 中使用 Apache Spark 时,如何集成 ClickHouse Spark 连接器。
添加 连接器 依赖项
Azure Synapse 支持三个级别的包管理:
- 默认包
- Spark 池级
- 会话级
按照 Apache Spark 池库管理指南进行操作,并将以下必需依赖项添加到 Spark 应用程序中
clickhouse-spark-runtime-{spark_version}_{scala_version}-{connector_version}.jar- 官方 Maven 仓库clickhouse-jdbc-{java_client_version}-all.jar- 官方 Maven 仓库
请参阅我们的 Spark 连接器 Compatibility Matrix 文档,了解哪些版本适合您的需求。
将 ClickHouse 添加为目录
可以通过多种方式将 Spark 配置添加到会话中:
- 使用随会话一起加载的自定义配置文件
- 通过 Azure Synapse UI 添加配置
- 在 Synapse 笔记本中添加配置
请按照管理 Apache Spark 配置 中的说明操作,并添加连接器所需的 Spark 配置。
例如,您可以在笔记本中使用以下设置来配置 Spark 会话:
请确保它会如下所示,位于第一个单元中:
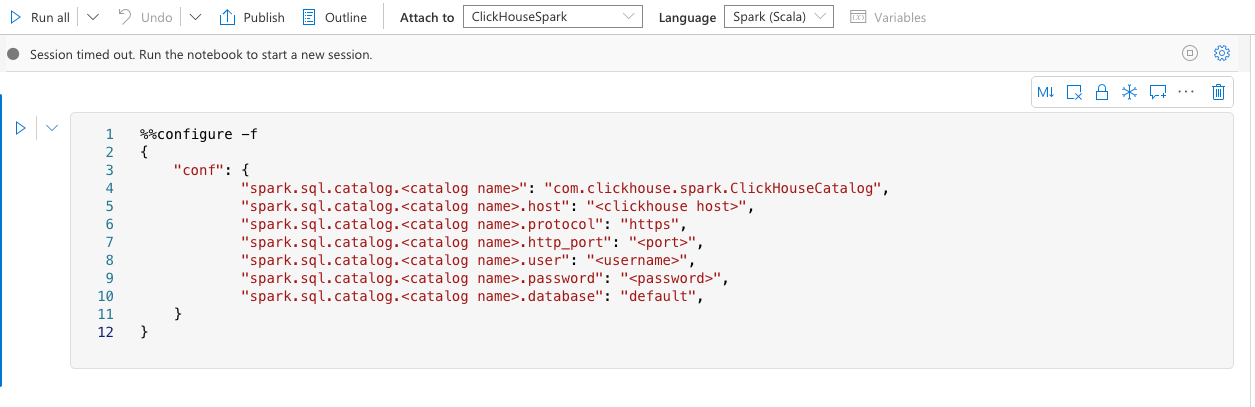
如需了解更多设置,请访问 ClickHouse Spark 配置页面。
信息
使用 ClickHouse Cloud 时,请务必设置所需的 Spark 配置。
设置验证
要验证依赖项和配置是否已成功完成设置,请访问当前会话的 Spark UI,并进入 Environment 选项卡。
在该页面中,查找与 ClickHouse 相关的设置:

