使用 ReplacingMergeTree 引擎
虽然事务型数据库针对事务性更新和删除型工作负载进行了优化,但 OLAP 数据库对这类操作提供的保障较少。相应地,它们针对以批次方式插入的不可变数据进行了优化,从而显著加速分析型查询。虽然 ClickHouse 通过变更提供更新操作,并提供了一种轻量级的行删除方式,但由于其列式结构,这些操作应按上述说明谨慎调度。这些操作以异步方式处理,由单线程执行,并且 (在更新的情况下) 需要在磁盘上重写数据。因此,不适合用于执行大量、细粒度的小变更。 为了在处理包含更新和删除行的流式数据时避免上述使用模式,我们可以使用 ClickHouse 表引擎 ReplacingMergeTree。
已插入行的自动 Upsert
ReplacingMergeTree 表引擎 允许对行执行更新操作,而无需使用低效的 ALTER 或 DELETE 语句。它通过允许用户插入同一行的多个副本,并将其中一条标记为最新版本来实现这一点。随后,一个后台进程会异步移除同一行的旧版本,通过仅追加的不可变插入,高效地模拟更新操作。
这一机制依赖于表引擎识别重复行的能力。它使用 ORDER BY 子句来确定唯一性,即如果两行在 ORDER BY 中指定的列上的值相同,则它们被视为重复。在定义表时可以指定一个 version 列,当两行被识别为重复时,该列用于保留该行的最新版本,即保留 version 值最大的那一行。
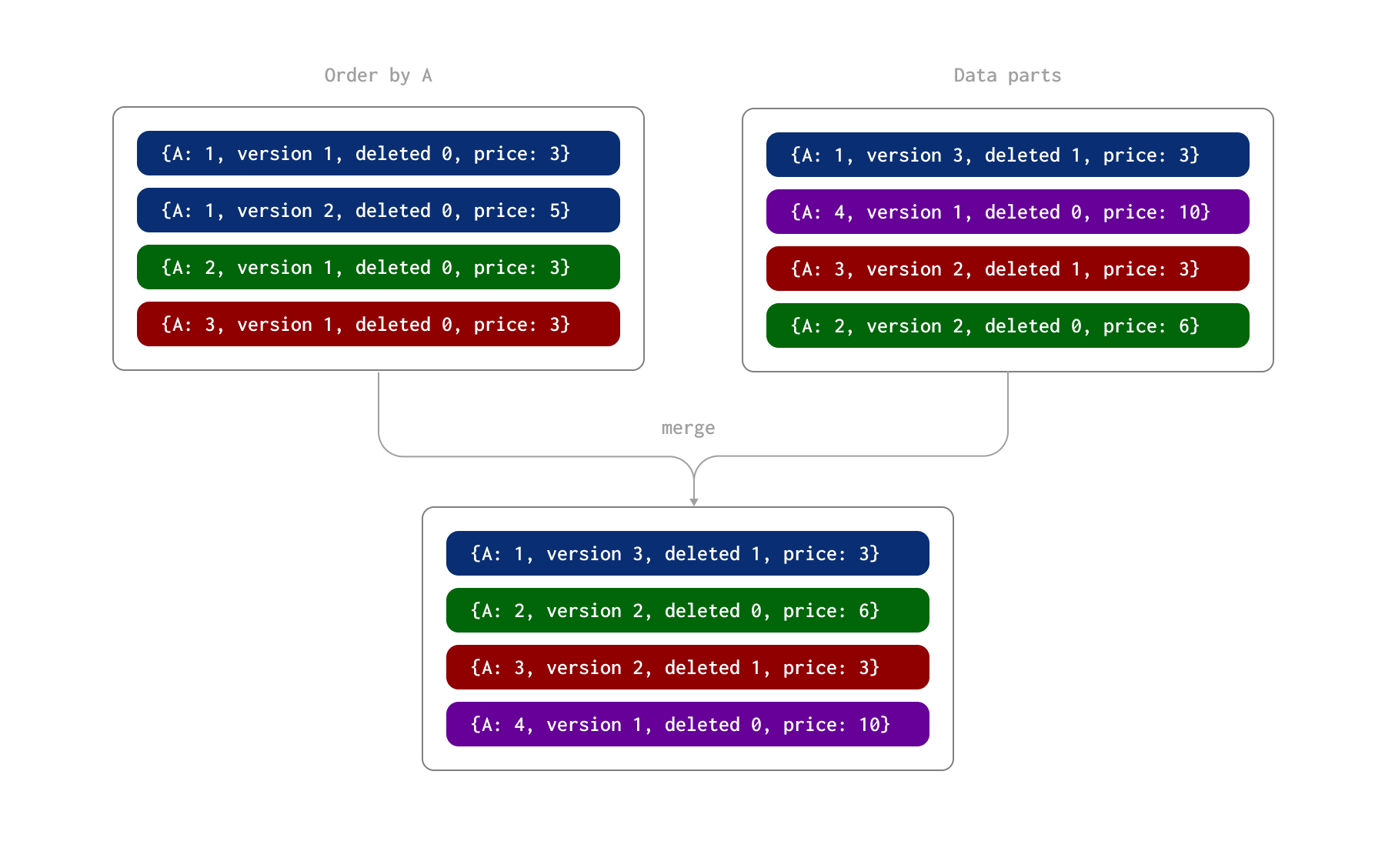
我们在下面的示例中演示这一过程。这里,行由 A 列唯一标识(该表的 ORDER BY)。我们假设这些行是以两个批次插入的,从而在磁盘上形成了两个数据 part。之后,在一个异步后台进程中,这些 part 会被合并在一起。
ReplacingMergeTree 还允许指定一个 deleted 列。该列的值可以是 0 或 1,其中值为 1 表示该行(及其重复行)已被删除,否则为 0。注意:已删除的行在合并时并不会被移除。
在这个过程中,part 合并时会发生以下情况:
- 列 A 值为 1 的行同时具有一个 version 为 2 的更新行和一个 version 为 3 的删除行(且 deleted 列的值为 1)。因此,被标记为删除的最新行会被保留。
- 列 A 值为 2 的行有两条更新行。后一条行被保留,其 price 列的值为 6。
- 列 A 值为 3 的行有一条 version 为 1 的行和一条 version 为 2 的删除行。该删除行被保留。
通过这一合并过程,最终得到四行数据,表示最终状态:
请注意,已删除的行永远不会被自动移除。可以通过执行 OPTIMIZE table FINAL CLEANUP 来强制删除它们。这需要将实验性设置 allow_experimental_replacing_merge_with_cleanup=1 打开。只有在满足以下条件时,才应执行该操作:
- 必须确保在执行该操作之后,不会再插入带有旧版本的行(针对那些即将通过 cleanup 被删除的行)。如果此类行在之后被插入,它们会被错误地保留,因为对应的已删除行已经不存在了。
- 在执行 cleanup 之前,确保所有副本已经完成同步。可以通过以下命令实现:
我们建议在确保条件 (1) 已满足后暂停插入,并保持暂停状态,直到此命令及后续清理操作全部完成。
仅当可以按照上述条件安排清理时,才建议在删除比例较低到中等(少于 10%)的表上使用 ReplacingMergeTree 处理删除操作。
提示:用户也可以对不再会发生变更的选定分区执行
OPTIMIZE FINAL CLEANUP。
选择主键/去重键
在上文中,我们强调了在使用 ReplacingMergeTree 时必须满足的一个重要附加约束:ORDER BY 中各列的取值在发生变更时必须能够在全局范围内唯一标识一行。如果是从 Postgres 这类事务型数据库迁移,那么原始的 Postgres 主键应当被包含在 ClickHouse 的 ORDER BY 子句中。
熟悉 ClickHouse 的用户已经习惯于为其表的 ORDER BY 子句选择列,以优化查询性能。一般来说,这些列应当根据常用查询选择,并按基数从低到高的顺序列出。需要特别注意的是,ReplacingMergeTree 引入了一个额外约束——这些列必须是不可变的。也就是说,如果是从 Postgres 进行复制,只有当某列在底层 Postgres 数据中不会发生变化时,才应将其加入该子句。虽然其他列可以变化,但用于唯一行标识的这些列必须保持一致。
对于分析型工作负载而言,Postgres 主键通常用途不大,因为你很少会执行单行点查。鉴于我们推荐按基数递增的顺序对列进行排序,以及ORDER BY 中靠前的列通常能更快完成匹配和过滤这一事实,Postgres 主键应当追加在 ORDER BY 的末尾(除非它本身具有分析价值)。如果在 Postgres 中主键由多个列组成,则应按其基数及其对查询价值的可能性,将这些列依次追加到 ORDER BY 中。你也可以选择通过 MATERIALIZED 列,将多个取值连接起来生成一个唯一主键。
来看 Stack Overflow 数据集中的 posts 表。
我们使用 (PostTypeId, toDate(CreationDate), CreationDate, Id) 作为 ORDER BY 键。Id 列对每条帖子记录都是唯一的,从而支持对行进行去重。根据需要,在 schema 中添加了 Version 和 Deleted 列。
查询 ReplacingMergeTree
在合并时,ReplacingMergeTree 会识别重复行,将 ORDER BY 列的值用作唯一标识,并且要么仅保留最高版本,要么在最新版本表示删除的情况下移除所有重复行。不过,这种机制只能在最终状态上趋于正确——并不能保证所有行一定都会被去重,因此不应依赖它。由于查询会同时考虑更新行和删除行,查询结果可能因此不正确。
要获得正确结果,你需要在后台合并的基础上,再在查询时执行去重并移除被标记为删除的记录。这可以通过使用 FINAL 运算符来实现。
考虑上面的 posts 表。我们可以使用常规方法加载该数据集,但在此基础上额外指定一个 deleted 列和一个 version 列,并将它们的值设为 0。出于示例目的,我们只加载 10000 行数据。
现在来确认一下行数:
现在我们来更新回答后的统计信息。我们不直接更新这些值,而是插入 5000 行新的副本,并将它们的版本号加一(这意味着表中将存在 150 行)。我们可以通过一个简单的 INSERT INTO … SELECT 语句来模拟这一点:
此外,我们通过重新插入这些行、但将 deleted 列的值设为 1,来删除 1000 条随机帖子。同样,可以通过一个简单的 INSERT INTO SELECT 来模拟这一操作。
上述操作的结果会是 16,000 行,即 10,000 + 5,000 + 1,000。实际上,这里的正确总数应该是:我们相较于原始总数只应少 1,000 行,即 10,000 - 1,000 = 9,000。
这里的结果会因已发生的合并而有所不同。我们可以看到,由于存在重复行,这里的总数不同。对该表使用 FINAL 运算符可以得到正确的结果。
FINAL 性能
在查询中使用 FINAL 运算符确实会带来一定的性能开销。
当查询没有基于主键列进行过滤时,这一点会最为明显,
因为会导致读取更多数据并增加去重的开销。如果你
在 WHERE 条件中基于主键列进行过滤,加载并传递给去重的数据量将会减少。
如果 WHERE 条件未使用主键列,在使用 FINAL 时 ClickHouse 当前不会使用 PREWHERE 优化。
该优化旨在减少为未参与过滤的列读取的行数。关于如何通过模拟 PREWHERE 从而潜在地提升性能的示例,请参见此处。
利用 ReplacingMergeTree 分区
ClickHouse 中的数据合并是在分区级别进行的。使用 ReplacingMergeTree 时,我们建议用户按照最佳实践对表进行分区,前提是能够确保该分区键对同一行不会发生变化。这样可以确保与同一行相关的更新会被发送到同一个 ClickHouse 分区。只要遵守此处概述的最佳实践,你可以复用在 Postgres 中使用的同一个分区键。
在此前提下,用户可以将设置 do_not_merge_across_partitions_select_final=1 打开,以提升 FINAL 查询性能。启用该设置后,在使用 FINAL 时,各分区会被独立合并和处理。
考虑下面这个 posts 表,其中我们没有使用分区:
为了确保 FINAL 确实需要做一些实际工作,我们更新 100 万行数据——通过插入重复行来将它们的 AnswerCount 增加 1。
使用 FINAL 计算每年的答案总和:
对于按年份分区的表重复上述步骤,并在将 do_not_merge_across_partitions_select_final 设置为 1 后再次运行上述查询。
如上所示,在本例中,分区通过允许在分区级别并行执行去重过程,显著提升了查询性能。
合并行为注意事项
ClickHouse 的合并选择机制不仅仅是简单地合并数据部分。下面我们将结合 ReplacingMergeTree 的使用场景,对这种行为进行分析,包括如何通过配置选项对旧数据启用更激进的合并,以及在数据部分较大时需要考虑的因素。
合并选择逻辑
合并的目标虽然是减少分区片段(parts)的数量,但同时也需要在这一目标与写放大成本之间取得平衡。因此,如果某些连续的分区片段在内部计算后被认为会导致过高的写放大,它们就会被排除在合并范围之外。这种行为有助于避免不必要的资源消耗并延长存储组件的使用寿命。
大数据部分的合并行为
ClickHouse 中的 ReplacingMergeTree 引擎通过合并数据部分来管理重复行,根据指定的唯一键保留每行的最新版本。然而,当某个已合并的数据部分达到 max_bytes_to_merge_at_max_space_in_pool 阈值时,即使设置了 min_age_to_force_merge_seconds,它也不会再被选中参与后续合并。结果是,自动合并将不再可靠地清理随着持续写入而累积的重复数据。
为了解决这一问题,用户可以通过执行 OPTIMIZE FINAL 手动触发合并数据部分并删除重复行。与自动合并不同,OPTIMIZE FINAL 会绕过 max_bytes_to_merge_at_max_space_in_pool 阈值,只根据可用资源(尤其是磁盘空间)来合并数据部分,直到每个分区仅剩单一数据部分。不过,这种方式在大表上可能会占用大量内存,并且在有新数据不断写入时可能需要多次重复执行。
为了在保持性能的同时获得更持久的解决方案,建议对表进行分区。分区可以帮助避免单个数据部分达到最大合并大小,从而减少频繁手动优化操作的需求。
分区以及跨分区合并
如在 Exploiting Partitions with ReplacingMergeTree 一文中所讨论的,我们推荐将表进行分区作为最佳实践。分区可以隔离数据,使合并更加高效,并避免在查询执行期间进行跨分区合并。从 23.12 版本开始,这一行为得到了增强:如果分区键是排序键的前缀,查询时将不会进行跨分区合并,从而提升查询性能。
为更优查询性能调优合并行为
默认情况下,min_age_to_force_merge_seconds 和 min_age_to_force_merge_on_partition_only 分别设置为 0 和 false,从而禁用这些特性。在这种配置下,ClickHouse 将应用标准合并行为,而不会基于分区“年龄”强制合并。
如果为 min_age_to_force_merge_seconds 指定了一个值,ClickHouse 会对超过该时间阈值的数据部分忽略常规合并启发式规则。虽然通常只有在目标是最小化数据部分总数时这一设置才更为有效,但在 ReplacingMergeTree 中,它可以通过减少查询时需要合并的数据部分数量来提升查询性能。
可以通过将 min_age_to_force_merge_on_partition_only=true 进一步调优这一行为,此时只有当分区内所有数据部分都早于 min_age_to_force_merge_seconds 时才会触发更激进的合并。该配置使得较旧的分区可以随着时间推移合并为单一数据部分,从而整合数据并维持良好的查询性能。
推荐设置
调优合并行为属于高级操作。我们建议在将这些设置用于生产负载之前,先咨询 ClickHouse 支持团队。
在大多数情况下,推荐将 min_age_to_force_merge_seconds 设置为一个较小的值——显著小于分区周期。这样可以最小化数据部分的数量,并避免在使用 FINAL 运算符执行查询时发生不必要的合并。
例如,考虑一个已被合并为单一数据部分的月度分区。如果随后有一个很小、零散的插入在该分区中创建了新的数据部分,查询性能可能会下降,因为在合并完成之前 ClickHouse 必须读取多个数据部分。通过设置 min_age_to_force_merge_seconds,可以确保这些数据部分被更激进地合并,避免查询性能下降。
