使用analyzer理解查询执行
ClickHouse 可以以极高的速度处理查询,但查询的执行过程并不那么简单。下面我们来看看一个 SELECT 查询是如何执行的。为便于说明,我们先在 ClickHouse 的一张表中插入一些数据:
CREATE TABLE session_events(
clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type String
) ORDER BY (timestamp);
INSERT INTO session_events SELECT * FROM generateRandom('clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type Enum(\'type1\', \'type2\')', 1, 10, 2) LIMIT 1000;
现在我们已经在 ClickHouse 中存有一些数据,接下来希望执行一些查询并了解它们的执行过程。查询的执行会被分解为许多步骤。查询执行的每个步骤都可以通过对应的 EXPLAIN 查询进行分析和诊断。这些步骤汇总在下图中:
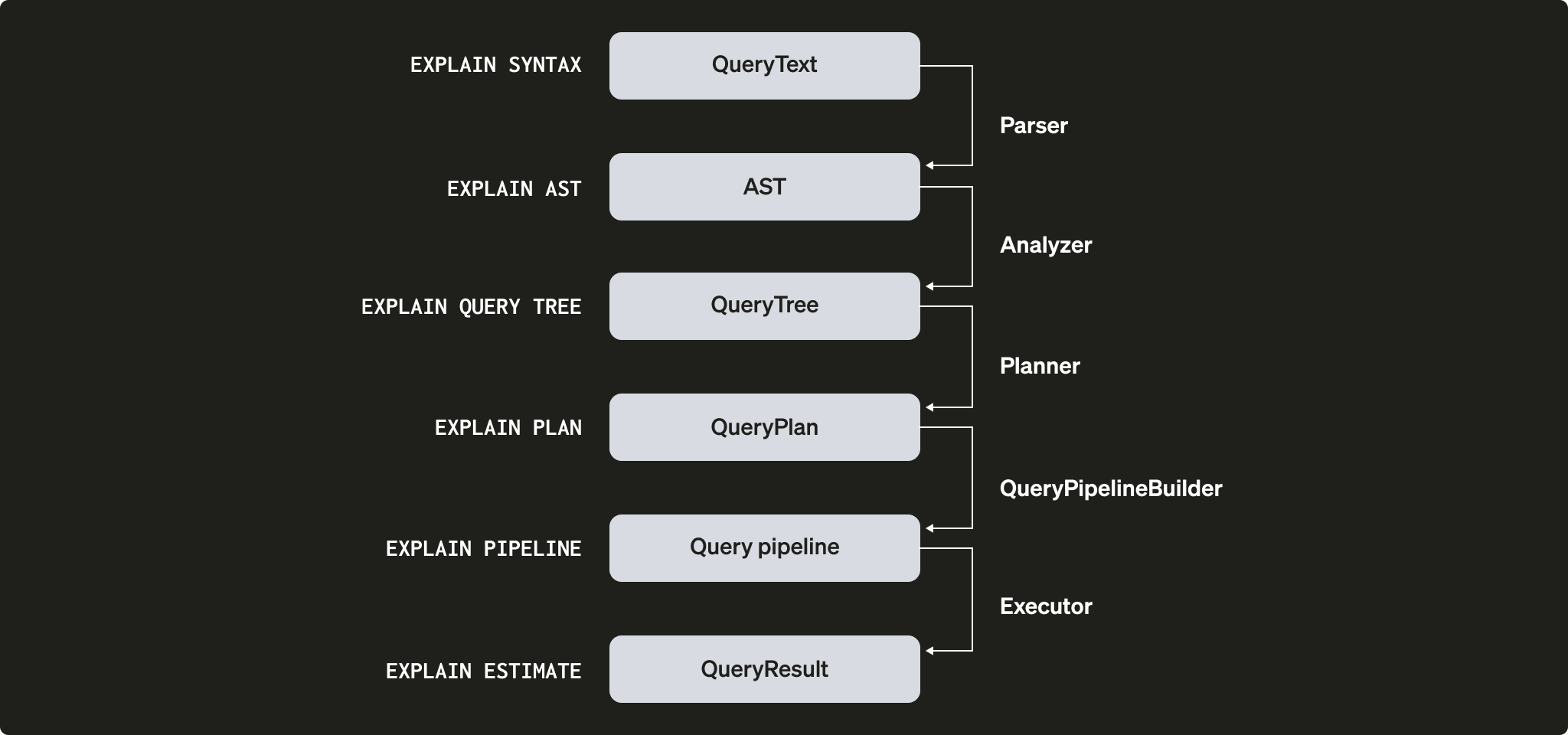
现在让我们看看在查询执行过程中,各个实体是如何协同工作的。我们将选取几个查询,然后使用 EXPLAIN 语句对它们进行分析。
解析器
解析器的目标是将查询文本转换为 AST(抽象语法树)。可以通过 EXPLAIN AST 将此步骤可视化:
EXPLAIN AST SELECT min(timestamp), max(timestamp) FROM session_events;
┌─explain────────────────────────────────────────────┐
│ SelectWithUnionQuery (children 1) │
│ ExpressionList (children 1) │
│ SelectQuery (children 2) │
│ ExpressionList (children 2) │
│ Function min (alias minimum_date) (children 1) │
│ ExpressionList (children 1) │
│ Identifier timestamp │
│ Function max (alias maximum_date) (children 1) │
│ ExpressionList (children 1) │
│ Identifier timestamp │
│ TablesInSelectQuery (children 1) │
│ TablesInSelectQueryElement (children 1) │
│ TableExpression (children 1) │
│ TableIdentifier session_events │
└────────────────────────────────────────────────────┘
输出是一个抽象语法树(AST),可以按如下方式进行可视化展示:
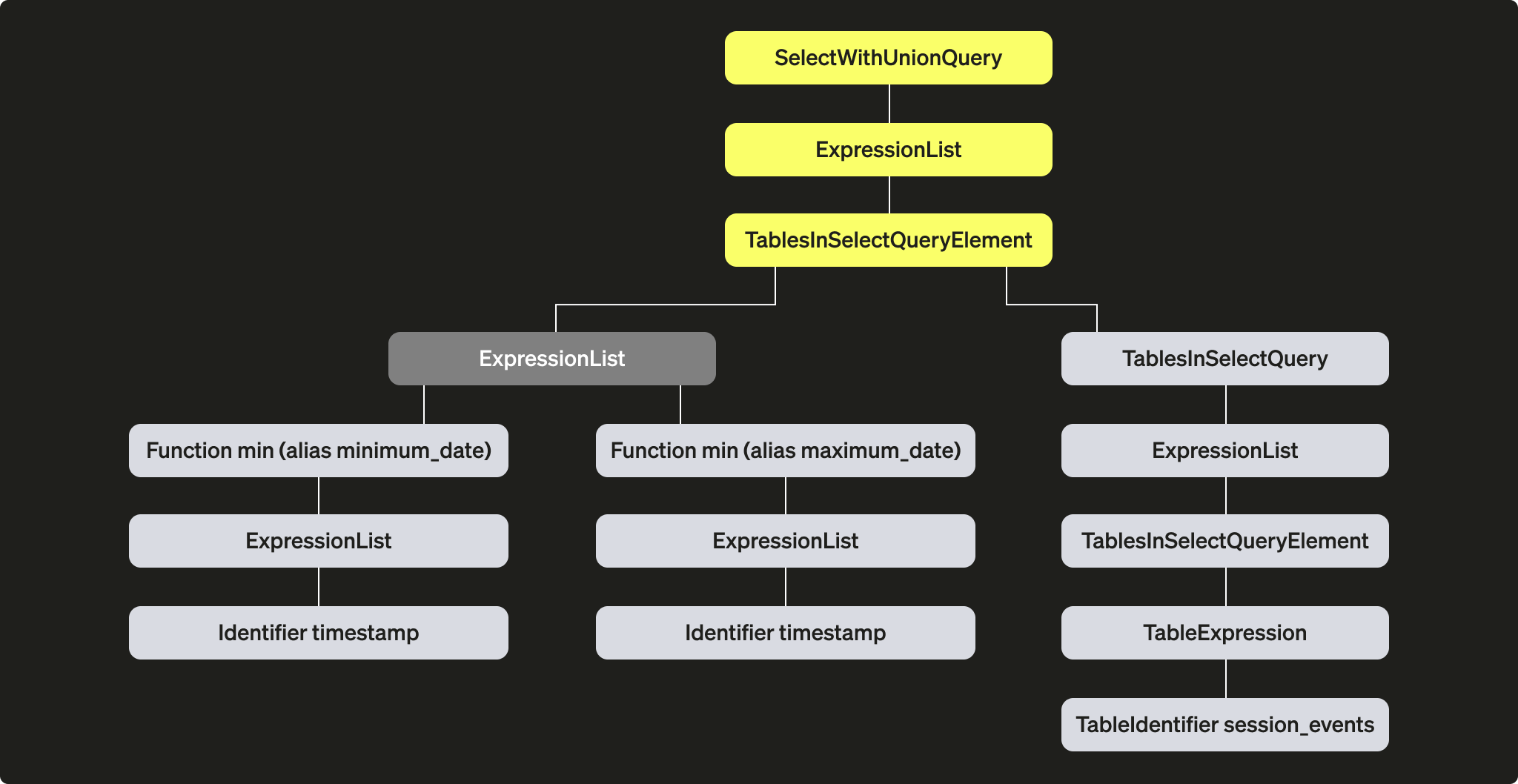
每个节点都有相应的子节点,整棵树表示查询的整体结构。它是一种用于辅助处理查询的逻辑结构。对于最终用户而言(除非对查询执行感兴趣),它并不是特别有用;该工具主要供开发人员使用。
Analyzer
ClickHouse 当前为 Analyzer 提供了两种架构。你可以通过设置 enable_analyzer=0 使用旧架构。新架构默认启用。鉴于一旦新 analyzer 达到 GA 阶段,旧架构将被弃用,这里我们只介绍新架构。
新架构应当提供一个更好的框架来提升 ClickHouse 的性能。不过,由于它是查询处理流程中的基础组件,也可能对某些查询产生负面影响,而且存在已知的不兼容性。你可以通过在查询或用户级别修改 enable_analyzer 设置,切换回旧的 analyzer。
Analyzer 是查询执行中的一个重要步骤。它接受 AST 并将其转换为查询树(query tree)。查询树相对于 AST 的主要优势在于,许多组件会被解析(resolved),例如具体的存储。我们也能知道要从哪张表读取数据,别名也会被解析,树本身还知道所使用的各种数据类型。基于这些优势,analyzer 可以应用各种优化。这些优化是通过一系列“pass”来实现的。每个 pass 会寻找不同类型的优化。你可以在这里查看所有 pass,下面让我们使用之前的查询来看一下它在实践中的表现:
EXPLAIN QUERY TREE passes=0 SELECT min(timestamp) AS minimum_date, max(timestamp) AS maximum_date FROM session_events SETTINGS allow_experimental_analyzer=1;
┌─explain────────────────────────────────────────────────────────────────────────────────┐
│ QUERY id: 0 │
│ PROJECTION │
│ LIST id: 1, nodes: 2 │
│ FUNCTION id: 2, alias: minimum_date, function_name: min, function_type: ordinary │
│ ARGUMENTS │
│ LIST id: 3, nodes: 1 │
│ IDENTIFIER id: 4, identifier: timestamp │
│ FUNCTION id: 5, alias: maximum_date, function_name: max, function_type: ordinary │
│ ARGUMENTS │
│ LIST id: 6, nodes: 1 │
│ IDENTIFIER id: 7, identifier: timestamp │
│ JOIN TREE │
│ IDENTIFIER id: 8, identifier: session_events │
│ SETTINGS allow_experimental_analyzer=1 │
└────────────────────────────────────────────────────────────────────────────────────────┘
EXPLAIN QUERY TREE passes=20 SELECT min(timestamp) AS minimum_date, max(timestamp) AS maximum_date FROM session_events SETTINGS allow_experimental_analyzer=1;
┌─explain───────────────────────────────────────────────────────────────────────────────────┐
│ QUERY id: 0 │
│ PROJECTION COLUMNS │
│ minimum_date DateTime │
│ maximum_date DateTime │
│ PROJECTION │
│ LIST id: 1, nodes: 2 │
│ FUNCTION id: 2, function_name: min, function_type: aggregate, result_type: DateTime │
│ ARGUMENTS │
│ LIST id: 3, nodes: 1 │
│ COLUMN id: 4, column_name: timestamp, result_type: DateTime, source_id: 5 │
│ FUNCTION id: 6, function_name: max, function_type: aggregate, result_type: DateTime │
│ ARGUMENTS │
│ LIST id: 7, nodes: 1 │
│ COLUMN id: 4, column_name: timestamp, result_type: DateTime, source_id: 5 │
│ JOIN TREE │
│ TABLE id: 5, alias: __table1, table_name: default.session_events │
│ SETTINGS allow_experimental_analyzer=1 │
└───────────────────────────────────────────────────────────────────────────────────────────┘
通过对比两次执行,你可以看到别名和投影是如何被解析的。
规划器
规划器接收一个查询树,并基于它构建查询计划。查询树告诉我们针对某个特定查询“要做什么”,而查询计划则告诉我们“将如何去做”。额外的优化会作为查询计划的一部分执行。你可以使用 EXPLAIN PLAN 或 EXPLAIN 来查看查询计划(EXPLAIN 会执行 EXPLAIN PLAN)。
EXPLAIN PLAN WITH
(
SELECT count(*)
FROM session_events
) AS total_rows
SELECT type, min(timestamp) AS minimum_date, max(timestamp) AS maximum_date, count(*) /total_rows * 100 AS percentage FROM session_events GROUP BY type
┌─explain──────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ ReadFromMergeTree (default.session_events) │
└──────────────────────────────────────────────────┘
虽然这已经为我们提供了一些信息,但我们还可以获取更多。比如,我们可能想知道需要在哪一列之上创建投影的列名。你可以在查询中添加一个请求头:
EXPLAIN header = 1
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
┌─explain──────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Header: type String │
│ minimum_date DateTime │
│ maximum_date DateTime │
│ percentage Nullable(Float64) │
│ Aggregating │
│ Header: type String │
│ min(timestamp) DateTime │
│ max(timestamp) DateTime │
│ count() UInt64 │
│ Expression (Before GROUP BY) │
│ Header: timestamp DateTime │
│ type String │
│ ReadFromMergeTree (default.session_events) │
│ Header: timestamp DateTime │
│ type String │
└──────────────────────────────────────────────────┘
你已经知道需要为最后一个 Projection 创建的列名(minimum_date、maximum_date 和 percentage),但你可能还希望查看所有需要执行的操作的详细信息。你可以通过将 actions 设置为 1 来实现。
EXPLAIN actions = 1
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
┌─explain────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Actions: INPUT :: 0 -> type String : 0 │
│ INPUT : 1 -> min(timestamp) DateTime : 1 │
│ INPUT : 2 -> max(timestamp) DateTime : 2 │
│ INPUT : 3 -> count() UInt64 : 3 │
│ COLUMN Const(Nullable(UInt64)) -> total_rows Nullable(UInt64) : 4 │
│ COLUMN Const(UInt8) -> 100 UInt8 : 5 │
│ ALIAS min(timestamp) :: 1 -> minimum_date DateTime : 6 │
│ ALIAS max(timestamp) :: 2 -> maximum_date DateTime : 1 │
│ FUNCTION divide(count() :: 3, total_rows :: 4) -> divide(count(), total_rows) Nullable(Float64) : 2 │
│ FUNCTION multiply(divide(count(), total_rows) :: 2, 100 :: 5) -> multiply(divide(count(), total_rows), 100) Nullable(Float64) : 4 │
│ ALIAS multiply(divide(count(), total_rows), 100) :: 4 -> percentage Nullable(Float64) : 5 │
│ Positions: 0 6 1 5 │
│ Aggregating │
│ Keys: type │
│ Aggregates: │
│ min(timestamp) │
│ Function: min(DateTime) → DateTime │
│ Arguments: timestamp │
│ max(timestamp) │
│ Function: max(DateTime) → DateTime │
│ Arguments: timestamp │
│ count() │
│ Function: count() → UInt64 │
│ Arguments: none │
│ Skip merging: 0 │
│ Expression (Before GROUP BY) │
│ Actions: INPUT :: 0 -> timestamp DateTime : 0 │
│ INPUT :: 1 -> type String : 1 │
│ Positions: 0 1 │
│ ReadFromMergeTree (default.session_events) │
│ ReadType: Default │
│ Parts: 1 │
│ Granules: 1 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
现在您可以查看所有正在使用的输入、函数、别名和数据类型。规划器将应用的部分优化可在此处查看。
查询管道
查询管道是基于查询计划生成的。查询管道与查询计划非常相似,不同之处在于它不是树形结构,而是图结构。它可以直观展示 ClickHouse 将如何执行查询以及会使用哪些资源。分析查询管道对于定位输入/输出层面的瓶颈非常有帮助。下面我们拿之前的查询来看看其查询管道的执行情况:
EXPLAIN PIPELINE
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type;
┌─explain────────────────────────────────────────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform × 2 │
│ (Aggregating) │
│ Resize 1 → 2 │
│ AggregatingTransform │
│ (Expression) │
│ ExpressionTransform │
│ (ReadFromMergeTree) │
│ MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread) 0 → 1 │
└────────────────────────────────────────────────────────────────────────────┘
括号内的是查询计划步骤,旁边的是处理器。虽然这些信息已经很有价值,但既然这是一个图结构,我们也希望能以图的形式进行可视化。我们可以将 graph 设置为 1,并将输出格式指定为 TSV:
EXPLAIN PIPELINE graph=1 WITH
(
SELECT count(*)
FROM session_events
) AS total_rows
SELECT type, min(timestamp) AS minimum_date, max(timestamp) AS maximum_date, count(*) /total_rows * 100 AS percentage FROM session_events GROUP BY type FORMAT TSV;
digraph
{
rankdir="LR";
{ node [shape = rect]
subgraph cluster_0 {
label ="Expression";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n5 [label="ExpressionTransform × 2"];
}
}
subgraph cluster_1 {
label ="Aggregating";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n3 [label="AggregatingTransform"];
n4 [label="Resize"];
}
}
subgraph cluster_2 {
label ="Expression";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n2 [label="ExpressionTransform"];
}
}
subgraph cluster_3 {
label ="ReadFromMergeTree";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n1 [label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
}
}
}
n3 -> n4 [label=""];
n4 -> n5 [label="× 2"];
n2 -> n3 [label=""];
n1 -> n2 [label=""];
}
接着可以复制该输出并粘贴到这里,即可生成如下图:
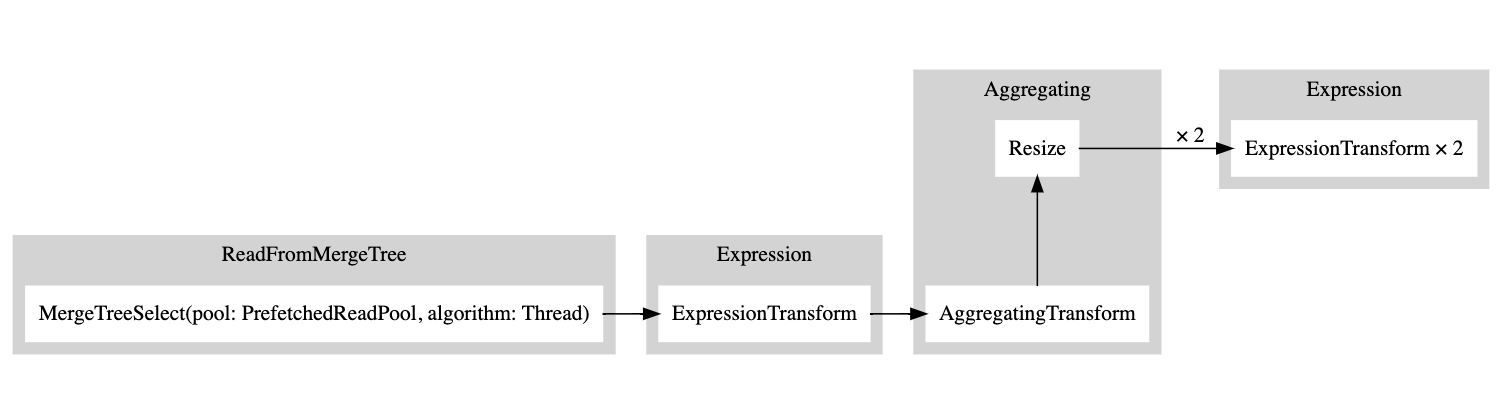
白色矩形表示一个 pipeline 节点,灰色矩形表示查询计划步骤,而带有数字的 x 表示当前使用的输入/输出数量。如果不想以紧凑格式查看它们,可以添加 compact=0:
EXPLAIN PIPELINE graph = 1, compact = 0
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
FORMAT TSV
digraph
{
rankdir="LR";
{ node [shape = rect]
n0[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n1[label="ExpressionTransform"];
n2[label="AggregatingTransform"];
n3[label="Resize"];
n4[label="ExpressionTransform"];
n5[label="ExpressionTransform"];
}
n0 -> n1;
n1 -> n2;
n2 -> n3;
n3 -> n4;
n3 -> n5;
}

为什么 ClickHouse 在从表中读取数据时没有使用多线程?让我们尝试向表中添加更多数据:
INSERT INTO session_events SELECT * FROM generateRandom('clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type Enum(\'type1\', \'type2\')', 1, 10, 2) LIMIT 1000000;
现在再次运行一下我们的 EXPLAIN 查询:
EXPLAIN PIPELINE graph = 1, compact = 0
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
FORMAT TSV
digraph
{
rankdir="LR";
{ node [shape = rect]
n0[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n1[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n2[label="ExpressionTransform"];
n3[label="ExpressionTransform"];
n4[label="StrictResize"];
n5[label="AggregatingTransform"];
n6[label="AggregatingTransform"];
n7[label="Resize"];
n8[label="ExpressionTransform"];
n9[label="ExpressionTransform"];
}
n0 -> n2;
n1 -> n3;
n2 -> n4;
n3 -> n4;
n4 -> n5;
n4 -> n6;
n5 -> n7;
n6 -> n7;
n7 -> n8;
n7 -> n9;
}

因此,执行器决定不并行执行这些操作,因为数据量还不够大。通过增加更多行之后,执行器就决定使用多线程进行处理,如图所示。
执行器
最后,查询执行的最终一步由执行器完成。它会接收查询流水线并将其执行。根据你是在执行 SELECT、INSERT 还是 INSERT SELECT,会使用不同类型的执行器。
