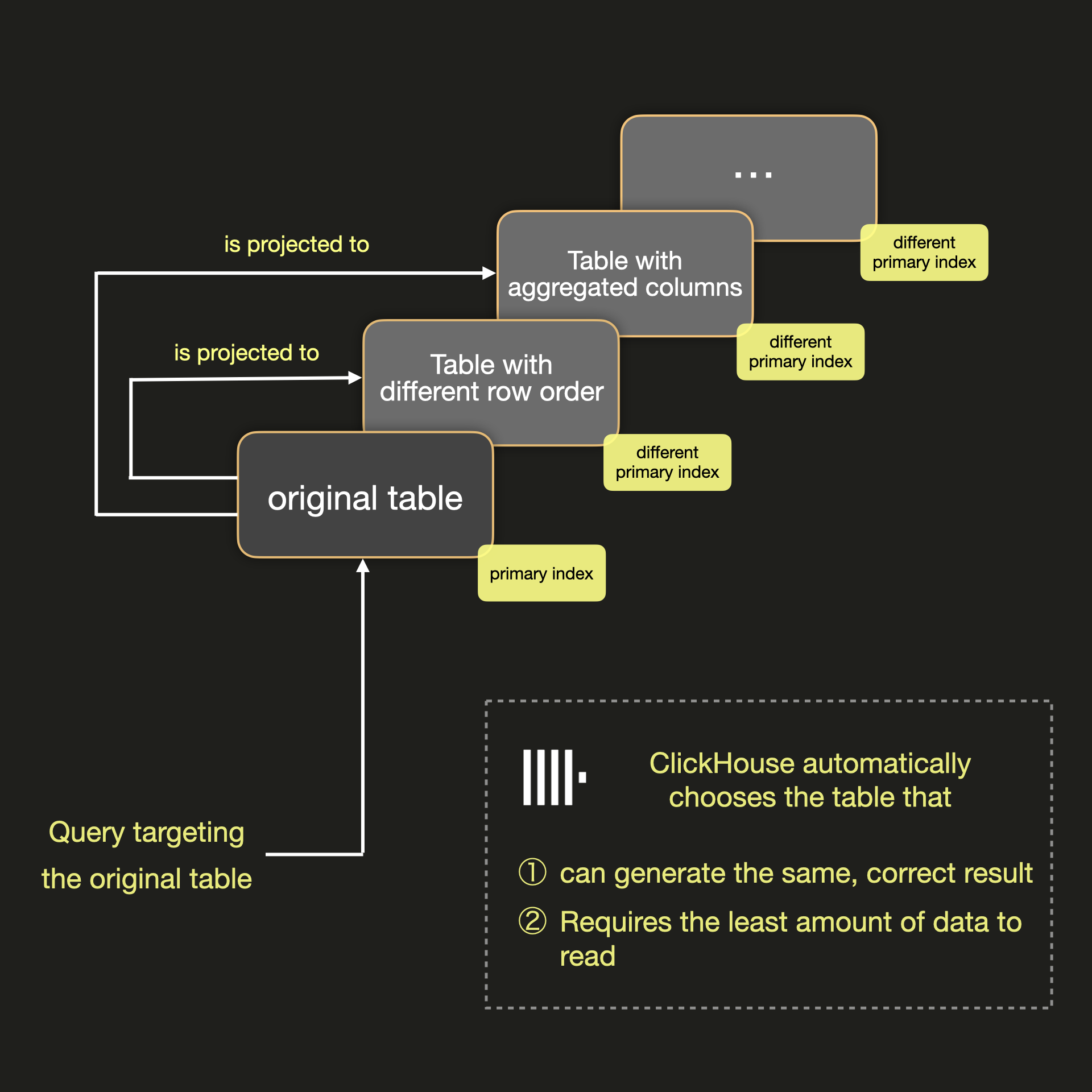
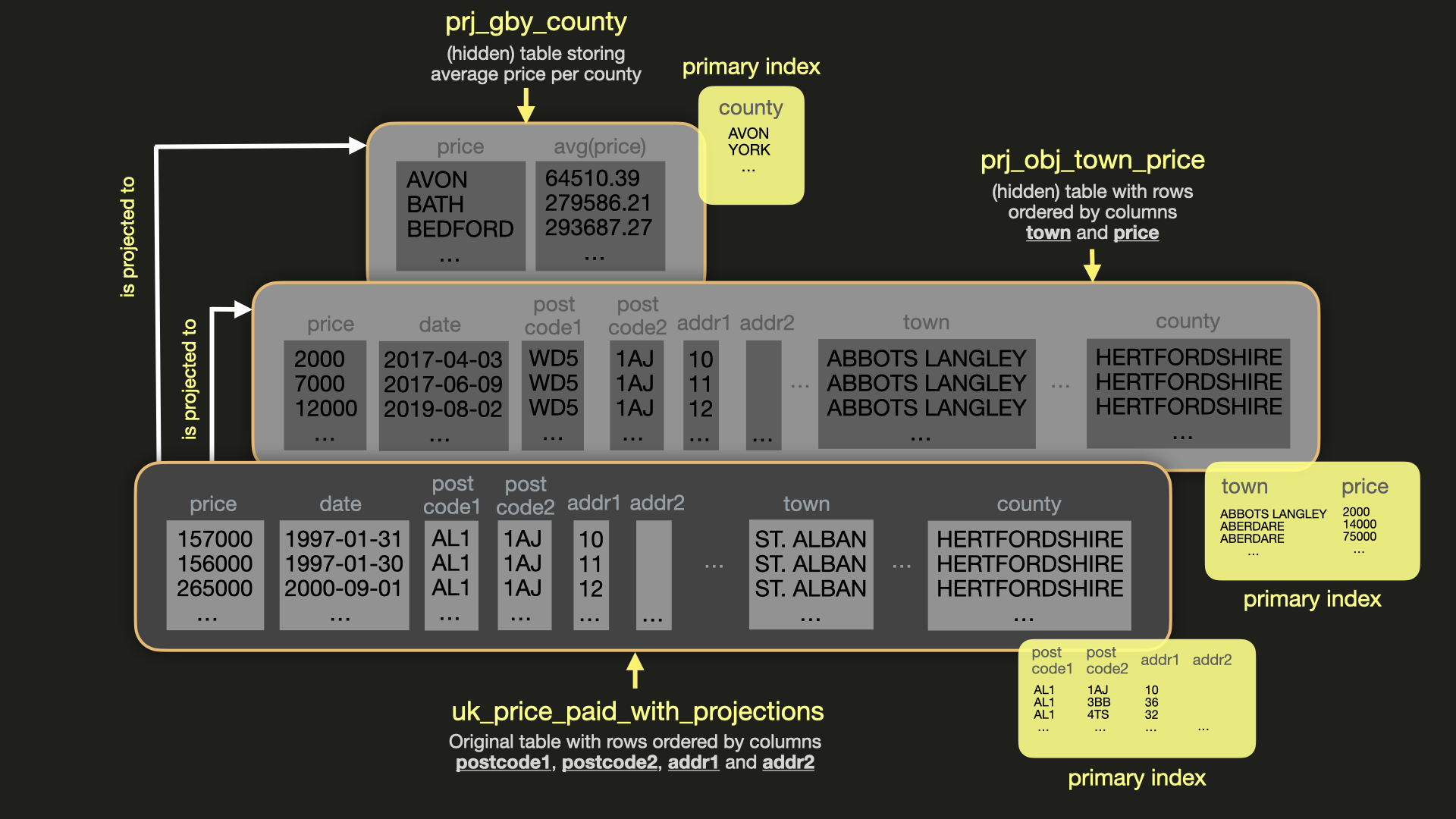
在本示例中,我们将使用 New York Taxi Data
数据集(可在 sql.clickhouse.com 获取),该数据集按 pickup_datetime 排序。
现在我们来编写一个简单的查询语句,找出所有乘客
给司机小费超过 200 美元的行程 ID:
SELECT
tip_amount,
trip_id,
dateDiff('minutes', pickup_datetime, dropoff_datetime) AS trip_duration_min
FROM nyc_taxi.trips WHERE tip_amount > 200 AND trip_duration_min > 0
ORDER BY tip_amount, trip_id ASC
请注意,由于我们正在对未包含在 ORDER BY 中的 tip_amount 进行过滤,ClickHouse
不得不执行一次全表扫描。我们来加速这个查询。
为了保留原始表及其结果,我们将创建一个新表,并使用 INSERT INTO SELECT 来复制数据:
CREATE TABLE nyc_taxi.trips_with_projection AS nyc_taxi.trips;
INSERT INTO nyc_taxi.trips_with_projection SELECT * FROM nyc_taxi.trips;
要添加投影,我们使用 ALTER TABLE 语句和 ADD PROJECTION 语句:
ALTER TABLE nyc_taxi.trips_with_projection
ADD PROJECTION prj_tip_amount
(
SELECT *
ORDER BY tip_amount, dateDiff('minutes', pickup_datetime, dropoff_datetime)
)
ALTER TABLE nyc.trips_with_projection MATERIALIZE PROJECTION prj_tip_amount
现在已经添加了投影,我们再运行一次该查询:
SELECT
tip_amount,
trip_id,
dateDiff('minutes', pickup_datetime, dropoff_datetime) AS trip_duration_min
FROM nyc_taxi.trips_with_projection WHERE tip_amount > 200 AND trip_duration_min > 0
ORDER BY tip_amount, trip_id ASC
请注意,我们显著减少了查询时间,且需要扫描的行数也更少了。
我们可以通过查询 system.query_log 表来确认上面的查询确实使用了我们创建的投影:
SELECT query, projections
FROM system.query_log
WHERE query_id='<query_id>'
SELECT
tables,
query,
query_duration_ms::String || ' ms' AS query_duration,
formatReadableQuantity(read_rows) AS read_rows,
projections
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND (tables = ['default.uk_price_paid_with_projections'])
ORDER BY initial_query_start_time DESC
LIMIT 2
FORMAT Vertical
第 1 行:
──────
tables: ['uk.uk_price_paid_with_projections']
query: SELECT
county,
avg(price)
FROM uk_price_paid_with_projections
GROUP BY county
ORDER BY avg(price) DESC
LIMIT 3
query_duration: 5 毫秒
read_rows: 132.00
projections: ['uk.uk_price_paid_with_projections.prj_gby_county']
第 2 行:
──────
tables: ['uk.uk_price_paid_with_projections']
query: SELECT
county,
price
FROM uk_price_paid_with_projections
WHERE town = 'LONDON'
ORDER BY price DESC
LIMIT 3
SETTINGS log_queries=1
query_duration: 11 毫秒
read_rows: 229 万
projections: ['uk.uk_price_paid_with_projections.prj_obj_town_price']
返回 2 行。耗时:0.006 秒。
为了保持原始表及其性能不受影响,我们再次使用 CREATE AS 和 INSERT INTO SELECT 创建该表的副本。
CREATE TABLE uk.uk_price_paid_with_projections_v2 AS uk.uk_price_paid;
INSERT INTO uk.uk_price_paid_with_projections_v2 SELECT * FROM uk.uk_price_paid;
让我们基于 toYear(date)、district 和 town 这三个维度创建一个聚合 Projection:
ALTER TABLE uk.uk_price_paid_with_projections_v2
ADD PROJECTION projection_by_year_district_town
(
SELECT
toYear(date),
district,
town,
avg(price),
sum(price),
count()
GROUP BY
toYear(date),
district,
town
)
SELECT
toYear(date) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM uk.uk_price_paid_with_projections_v2
GROUP BY year
ORDER BY year ASC
SETTINGS optimize_use_projections=0
SELECT
toYear(date) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM uk.uk_price_paid_with_projections_v2
GROUP BY year
ORDER BY year ASC
SELECT
toYear(date) AS year,
round(avg(price)) AS price,
bar(price, 0, 2000000, 100)
FROM uk.uk_price_paid_with_projections_v2
WHERE town = 'LONDON'
GROUP BY year
ORDER BY year ASC
SETTINGS optimize_use_projections=0
SELECT
toYear(date) AS year,
round(avg(price)) AS price,
bar(price, 0, 2000000, 100)
FROM uk.uk_price_paid_with_projections_v2
WHERE town = 'LONDON'
GROUP BY year
ORDER BY year ASC
SELECT
town,
district,
count() AS c,
round(avg(price)) AS price,
bar(price, 0, 5000000, 100)
FROM uk.uk_price_paid_with_projections_v2
WHERE toYear(date) >= 2020
GROUP BY
town,
district
HAVING c >= 100
ORDER BY price DESC
LIMIT 100
SETTINGS optimize_use_projections=0
SELECT
town,
district,
count() AS c,
round(avg(price)) AS price,
bar(price, 0, 5000000, 100)
FROM uk.uk_price_paid_with_projections_v2
WHERE toYear(date) >= 2020
GROUP BY
town,
district
HAVING c >= 100
ORDER BY price DESC
LIMIT 100
CREATE TABLE page_views
(
id UInt64,
event_date Date,
user_id UInt32,
url String,
region String,
PROJECTION region_proj
(
SELECT _part_offset ORDER BY region
),
PROJECTION user_id_proj
(
SELECT _part_offset ORDER BY user_id
)
)
ENGINE = MergeTree
ORDER BY (event_date, id)
SETTINGS
index_granularity = 1, -- one row per granule
max_bytes_to_merge_at_max_space_in_pool = 1; -- disable merge
然后向表中插入数据:
INSERT INTO page_views VALUES (
1, '2025-07-01', 101, 'https://example.com/page1', 'europe');
INSERT INTO page_views VALUES (
2, '2025-07-01', 102, 'https://example.com/page2', 'us_west');
INSERT INTO page_views VALUES (
3, '2025-07-02', 106, 'https://example.com/page3', 'us_west');
INSERT INTO page_views VALUES (
4, '2025-07-02', 107, 'https://example.com/page4', 'us_west');
INSERT INTO page_views VALUES (
5, '2025-07-03', 104, 'https://example.com/page5', 'asia');
注意
注意:该表为了演示使用了自定义设置,例如单行 granule(粒度单元)以及禁用 part 合并,这些设置不建议在生产环境中使用。
此设置会产生:
五个独立的 part(每插入一行生成一个 part)
每行一个主键索引条目(在基础表和每个 projection 中)
每个 part 都只包含一行
在此设置下,我们运行一个同时按 region 和 user_id 进行过滤的查询。
由于基础表的主键索引是基于 event_date 和 id 构建的,
在这里帮不上忙,因此 ClickHouse 会改为使用: