Managed Postgres 快速入门
ClickHouse Managed Postgres 是采用 NVMe 存储的企业级 Postgres,与 EBS 等网络附加存储相比,可将磁盘 I/O 受限工作负载的性能最高提升 10 倍。本快速入门分为两个部分:
- Part 1: 开始使用 NVMe Postgres 并体验其性能
- Part 2: 通过与 ClickHouse 集成解锁实时分析
Managed Postgres 目前已在 AWS 的多个区域提供,并且在私有预览期间免费。
在本快速入门中,您将:
- 创建一个采用 NVMe 存储、具备高性能的 Managed Postgres 实例
- 加载 100 万条样本事件,并亲身体验 NVMe 速度
- 运行查询并体验低延迟性能
- 将数据复制到 ClickHouse 以进行实时分析
- 使用
pg_clickhouse直接从 Postgres 查询 ClickHouse
第一部分:NVMe Postgres 入门
创建数据库
要创建新的 Managed Postgres 服务,请在 Cloud Console 的服务列表中点击 New service 按钮。随后,您可以选择 Postgres 作为数据库类型。
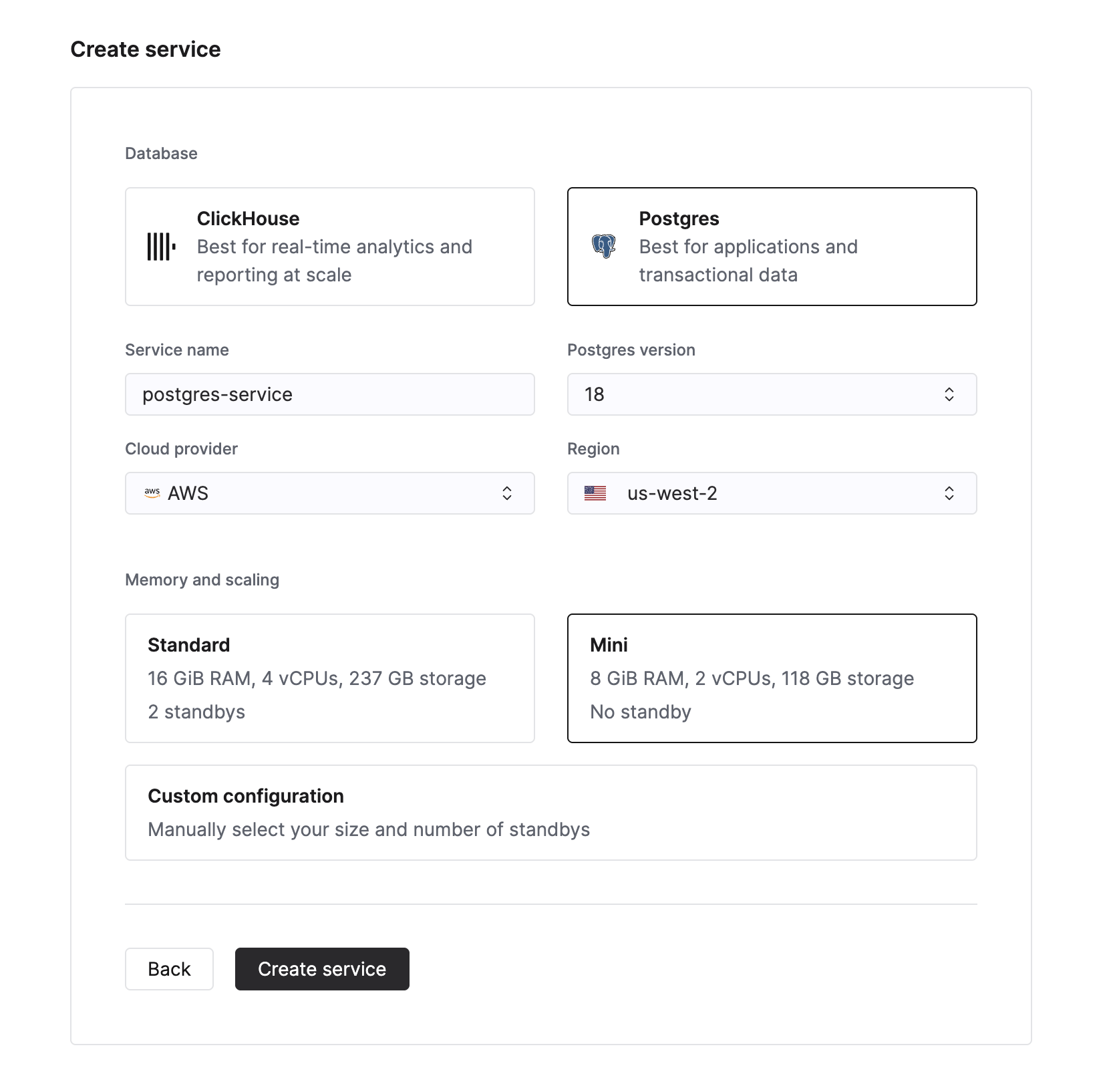
为数据库实例输入名称,并点击 Create service。系统会跳转到概览页面。
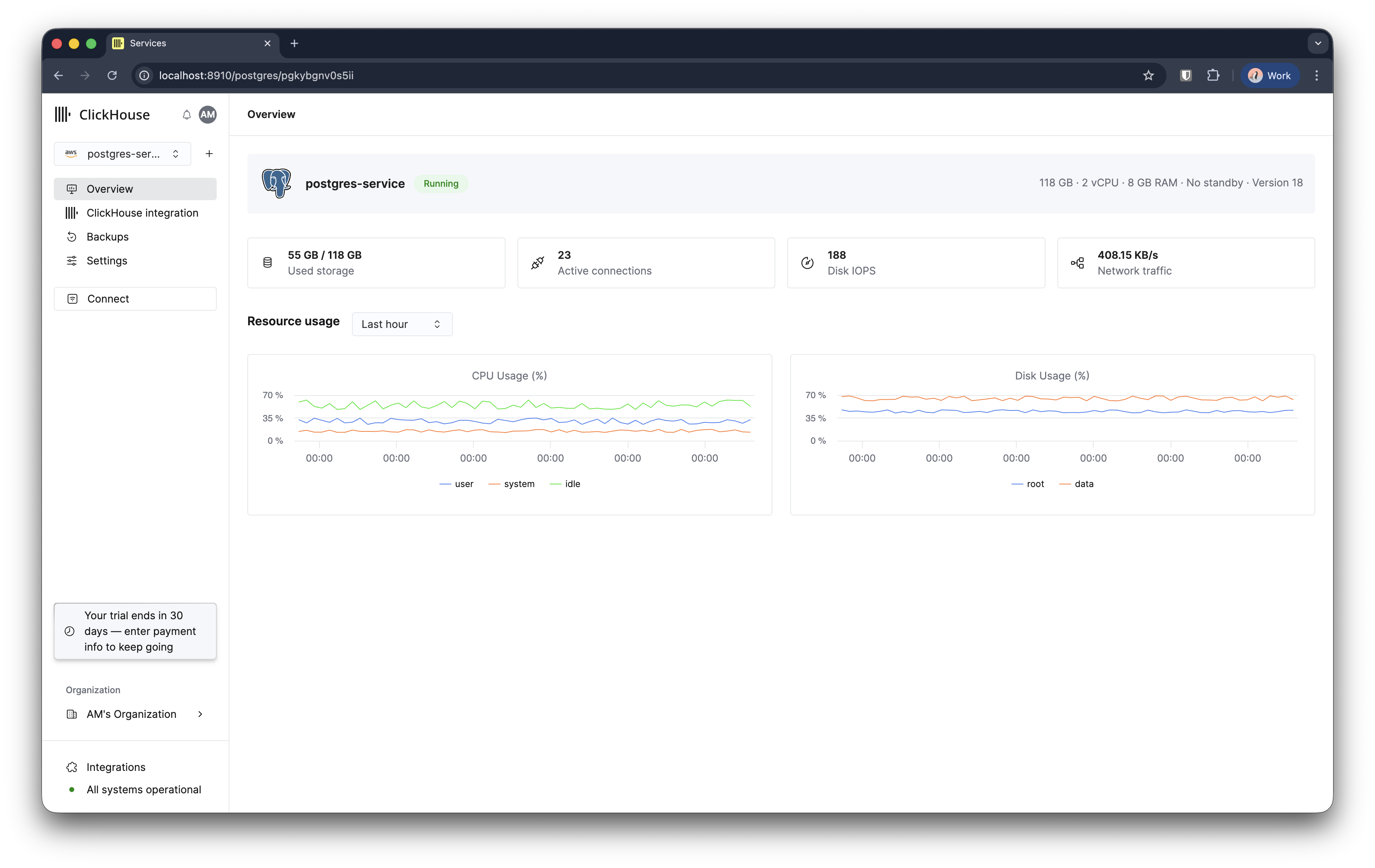
您的 Managed Postgres 实例将在 3-5 分钟内完成创建并可投入使用。
连接到你的数据库
在左侧侧边栏中,你会看到一个 Connect 按钮。点击它以查看你的连接信息以及多种格式的连接字符串。
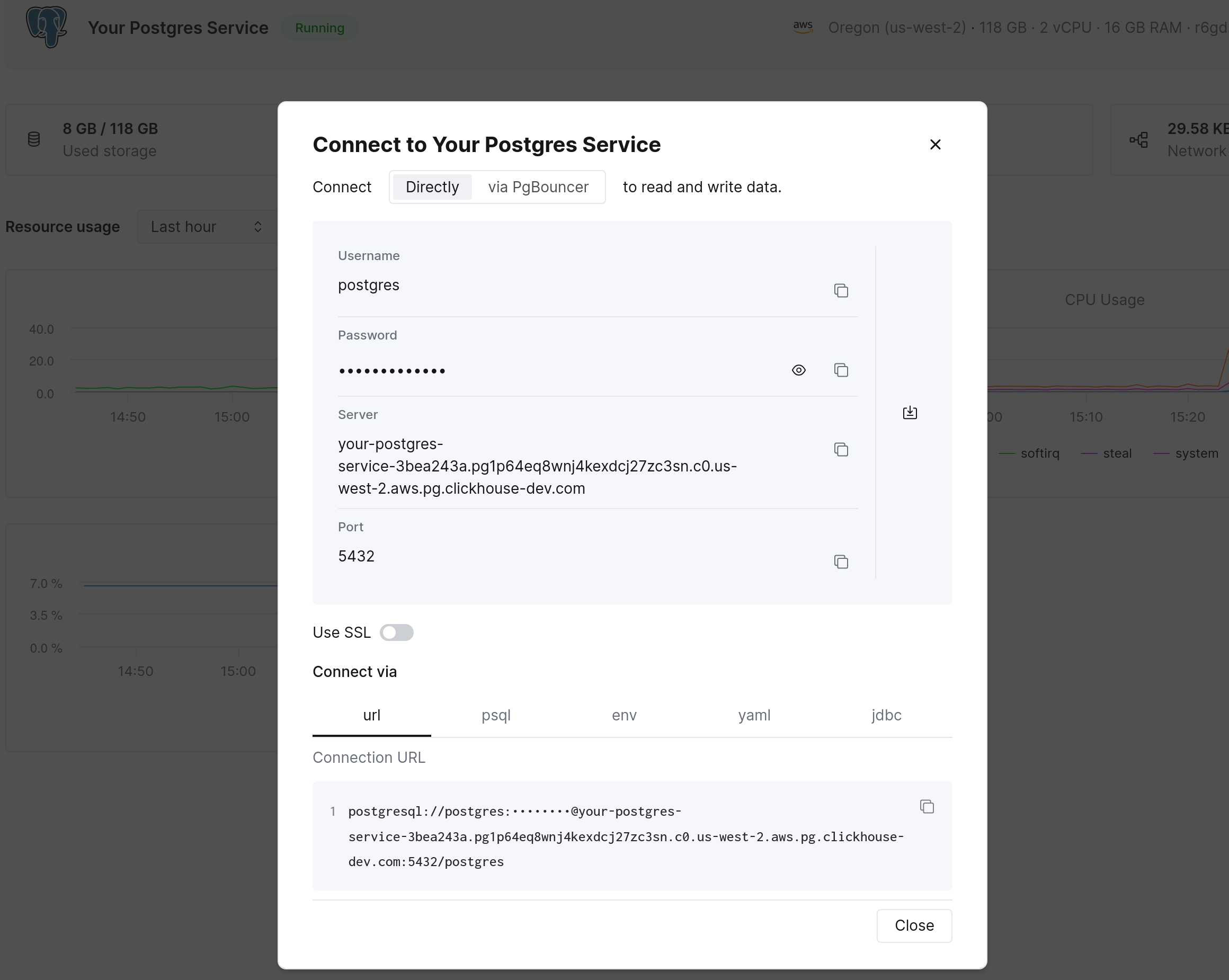
复制 psql 连接字符串并连接到你的数据库。你也可以使用任何兼容 Postgres 的客户端(例如 DBeaver),或任意应用程序库。
体验 NVMe 性能
让我们来实际感受一下基于 NVMe 的性能表现。首先,在 psql 中启用计时,以便测量查询执行时间:
创建两个示例表 events 和 users:
现在插入 100 万条事件,观察 NVMe 的性能表现:
在不到 4 秒内插入 100 万行 JSONB 数据。在使用类似 EBS 这类网络附加存储的传统云数据库中,由于网络往返延迟和 IOPS 限流,相同操作通常需要耗时 2-3 倍。NVMe 存储通过将存储与计算节点物理直连来消除这些瓶颈。
实际性能会根据实例规格、当前负载以及数据特性而有所不同。
插入 1,000 个用户:
对数据运行查询
现在我们来运行一些查询,看看在使用 NVMe 存储时 Postgres 的响应速度有多快。
将 100 万条事件按类型聚合:
带 JSONB 过滤和日期范围的查询:
将事件与用户关联:
现在,您已经拥有一个功能完备、高性能的 Postgres 数据库,可以用于承载事务型工作负载。
继续阅读第 2 部分,了解 ClickHouse 原生集成如何大幅提升您的分析能力。
第 2 部分:使用 ClickHouse 添加实时分析
虽然 Postgres 在事务型工作负载(OLTP)方面表现优异,但 ClickHouse 是专门为大型数据集上的分析型查询(OLAP)而构建的。将两者集成使用,即可兼具这两种数据库的优势:
- Postgres 用于应用程序的事务型数据(插入、更新、点查询)
- ClickHouse 用于在数十亿行数据上实现亚秒级分析
本节将介绍如何将 Postgres 数据复制到 ClickHouse,并无缝地对其进行查询。
配置与 ClickHouse 的集成
现在我们已经在 Postgres 中有了表和数据,接下来将这些表复制到 ClickHouse 用于分析。首先在侧边栏中点击 ClickHouse integration。然后点击 Replicate data in ClickHouse。
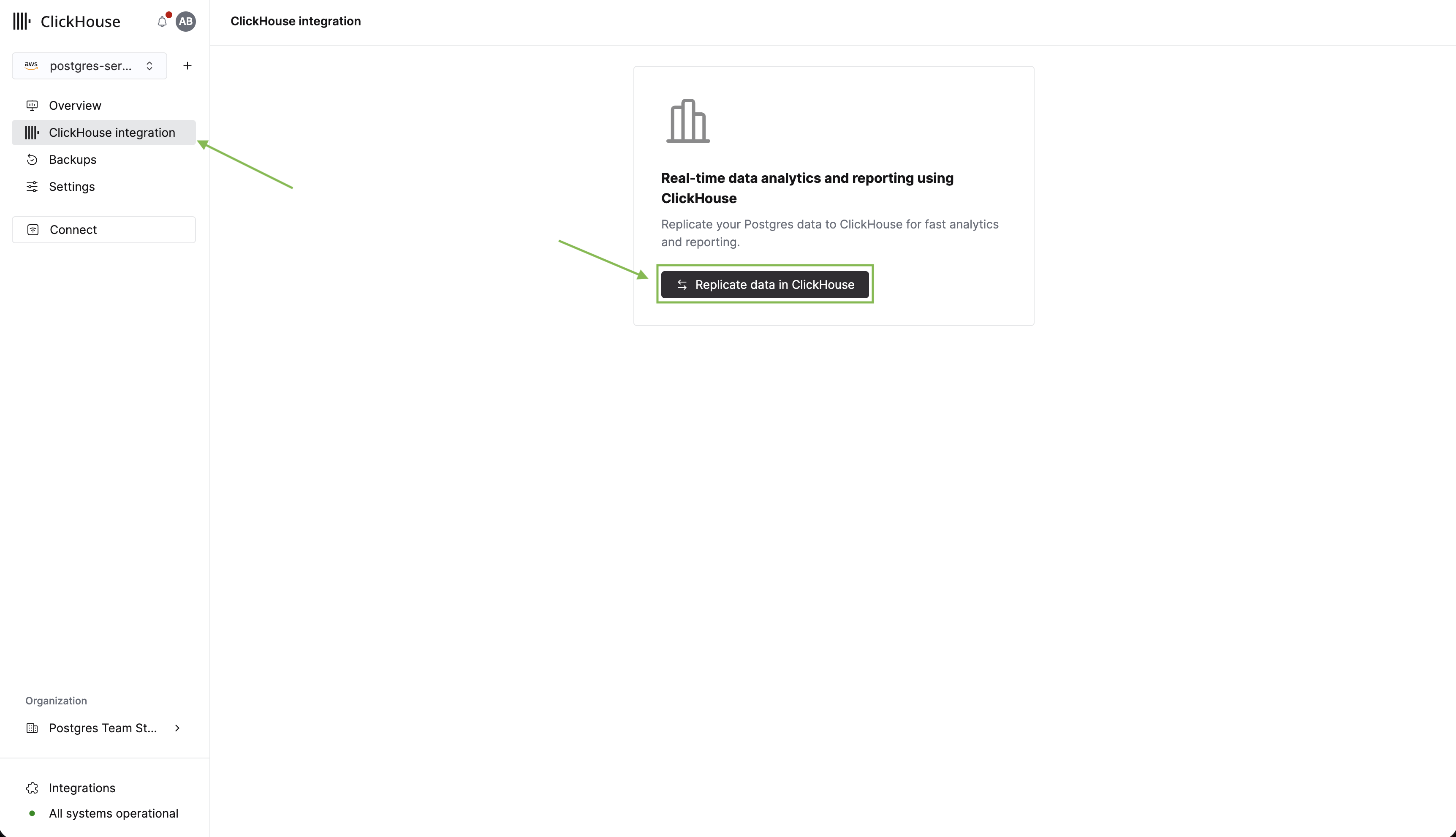
在接下来的表单中,您可以为集成输入一个名称,并选择一个已有的 ClickHouse 实例作为复制目标。如果您还没有 ClickHouse 实例,可以直接在此表单中创建一个。
在继续之前,确保您选择的 ClickHouse 服务处于 Running 状态。
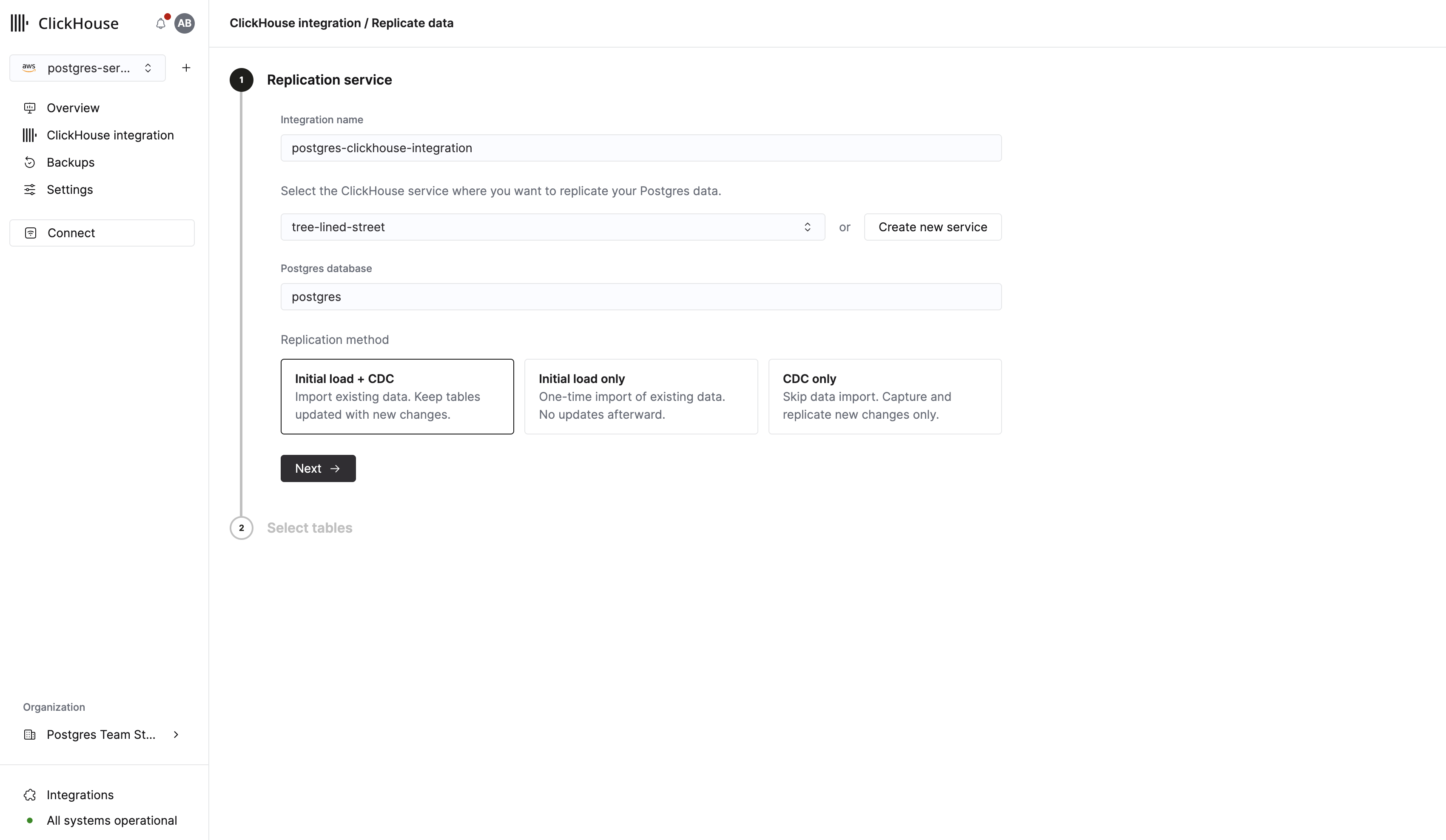
点击 Next 进入表选择器。在这里,您需要:
- 选择要复制到的 ClickHouse 数据库。
- 展开 public schema,并选择我们之前创建的 users 和 events 表。
- 点击 Replicate data to ClickHouse。
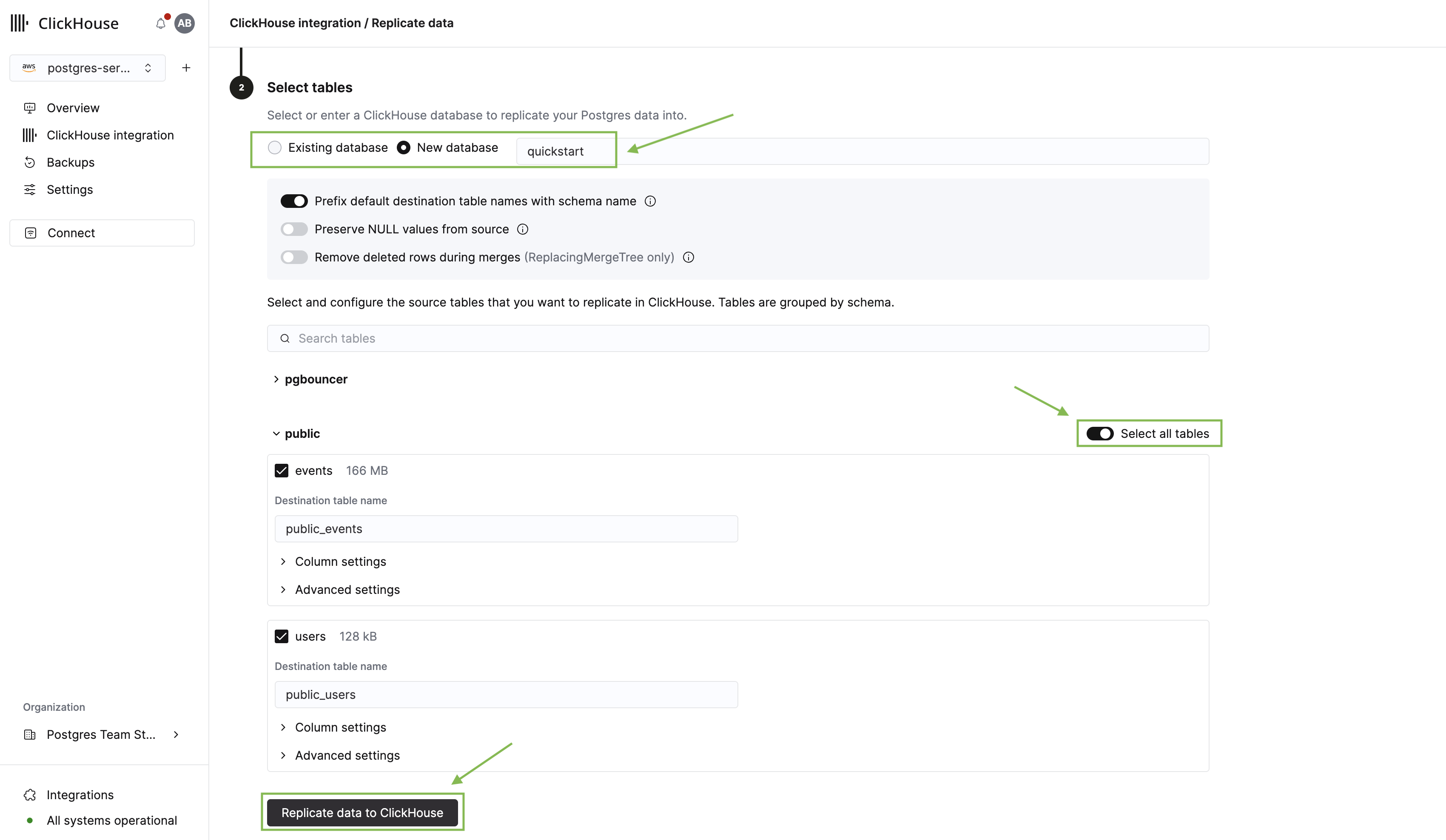
复制过程将开始,页面会跳转到集成概览。由于这是第一个集成,初始化基础设施可能需要 2–3 分钟。同时,我们来看看新的 pg_clickhouse 扩展。
从 Postgres 查询 ClickHouse
pg_clickhouse 扩展允许你在 Postgres 中使用标准 SQL 直接查询 ClickHouse 中的数据。这意味着你的应用可以将 Postgres 用作覆盖事务型和分析型数据的统一查询层。详见完整文档。
启用该扩展:
然后,创建到 ClickHouse 的外部服务器 (foreign server) 连接。使用 http 驱动并将端口设置为 8443,以建立安全连接:
将 <clickhouse_cloud_host> 替换为您的 ClickHouse 主机名,将 <database_name> 替换为您在复制配置时选择的数据库。您可以在 ClickHouse 服务的侧边栏中点击 Connect 来找到该主机名。
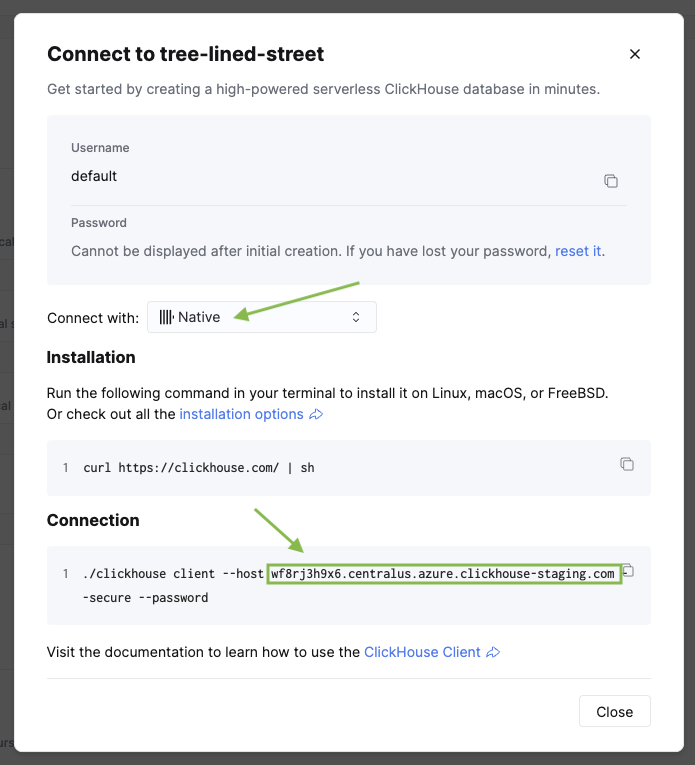
现在,我们将 Postgres 用户映射到 ClickHouse 服务的凭据:
现在将 ClickHouse 表导入到 Postgres 的一个 schema 中:
将 <database_name> 替换为你在创建服务器时使用的同一数据库名称。
现在你可以在 Postgres 客户端中查看所有 ClickHouse 表:
查看分析数据的实际效果
现在回到集成页面查看一下。此时你应该会看到初始复制过程已经完成。点击集成名称来查看详细信息。

点击服务名称,会打开 ClickHouse 控制台,在那里你可以看到已复制的表。
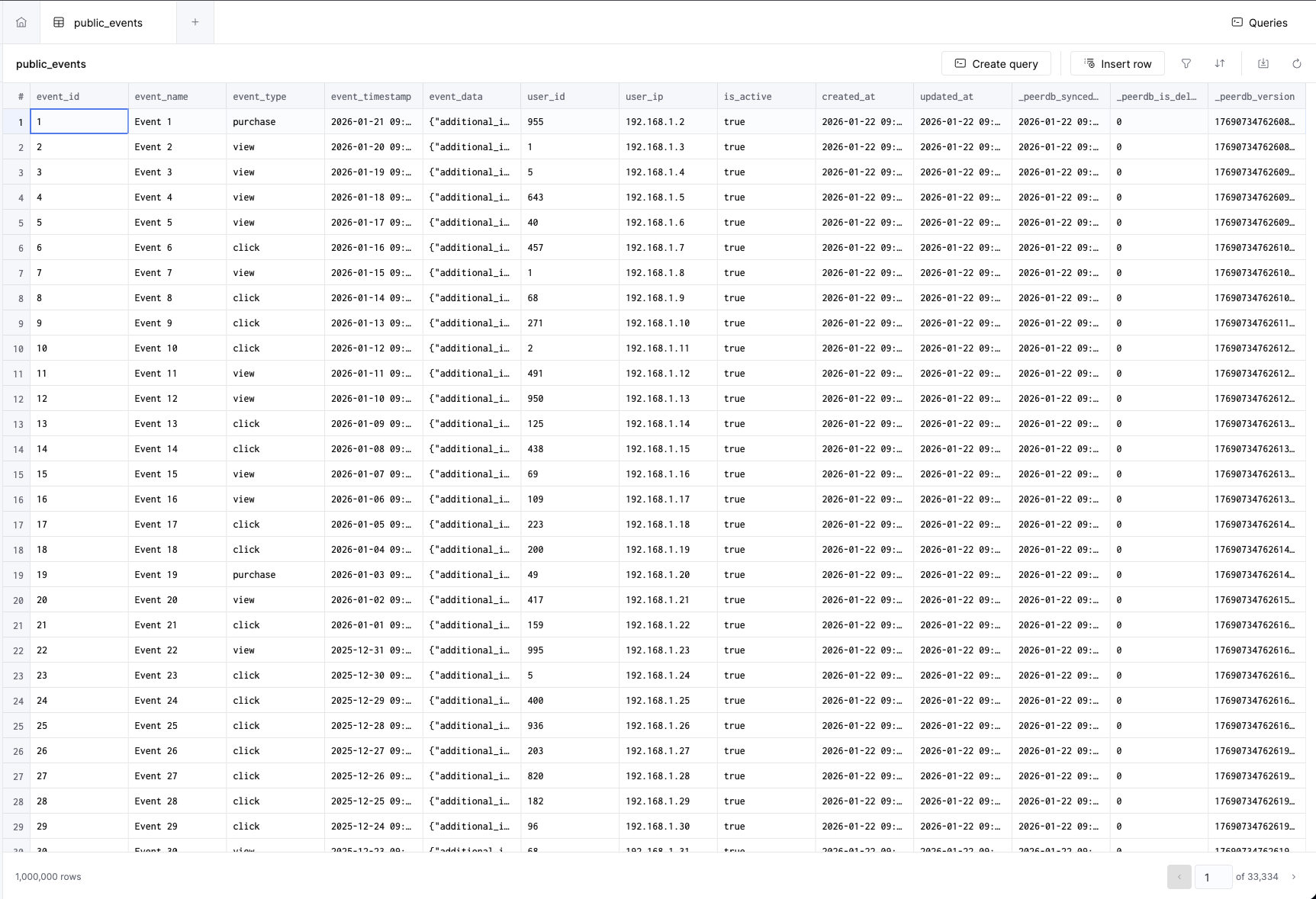
对比 Postgres 与 ClickHouse 的性能
现在我们来运行一些分析型查询,并比较 Postgres 与 ClickHouse 之间的性能。注意,副本表使用命名约定 public_<table_name>。
查询 1:按活跃度排序的用户
此查询通过多个聚合找到最活跃的用户:
查询 2:按国家和平台统计用户参与度
此查询将 events 表与 users 表进行关联,并计算参与度指标:
性能对比:
| 查询 | Postgres (NVMe) | ClickHouse (通过 pg_clickhouse) | 加速比 |
|---|---|---|---|
| 活跃用户排行(5 个聚合) | 555 ms | 164 ms | 3.4x |
| 用户参与度(JOIN + 聚合) | 1,246 ms | 170 ms | 7.3x |
即使在这个只有 100 万行的数据集上,ClickHouse 在带有 JOIN 和多重聚合的复杂分析查询方面也能提供 3–7 倍的性能提升。随着规模增大(超过 1 亿行),差异会更加显著,此时借助 ClickHouse 的列式存储和向量化执行,可以实现 10–100 倍的加速。
查询时间会因实例规格、服务之间的网络延迟、数据特性以及当前负载而变化。
清理
要删除在本快速入门中创建的资源:
- 首先,从 ClickHouse 服务中删除 ClickPipe 集成
- 然后,从 Cloud 控制台中删除 Managed Postgres 实例
