Postgres 查询洞察
查询洞察会从你的 Managed Postgres 实例中采集每条 语句 的遥测数据,并按影响程度对各类查询 模式进行排序,让你无需离开云控制台,就能从“p99 正在逐步升高”快速定位到“这种模式 正在落盘”。
这些数据来自 pg_stat_ch,
这是一个开源的 Postgres 扩展,可将每条 语句 的计数器流式传输到
ClickHouse Cloud。遥测数据在离开数据库之前,会先在 Postgres 内部完成规范化处理
—— 字面量会被移除并替换为占位符,因此你查询的具体值
不会进入遥测流。
打开查询洞察
在 Cloud Console 中打开你的 Managed Postgres 实例,然后点击左侧边栏中的 查询洞察。该页面分为四个区域,顺序也与实际使用顺序一致:
- 一个将数据库健康检查汇总在单个屏幕中的 概览。
- 一个 慢模式 表,汇总数据库运行过的每种查询模式,并可按你怀疑的问题维度排序。
- 一个 最近查询 面板,按时间倒序列出各次独立执行。
- 一个 详情弹出面板,汇总单个模式的所有计数器。
使用顶部的 时间范围 选择器,可在最近 15 分钟、1 小时、1 天、1 周或 1 个月之间切换。聚合时间桶大小会自动调整 —— 最近 15 分钟或 1 小时使用 1 分钟时间桶, 最近 1 天使用 5 分钟时间桶,最近 1 周或 1 个月使用 1 小时时间桶 —— 这样可让 图表保持流畅响应。
概览
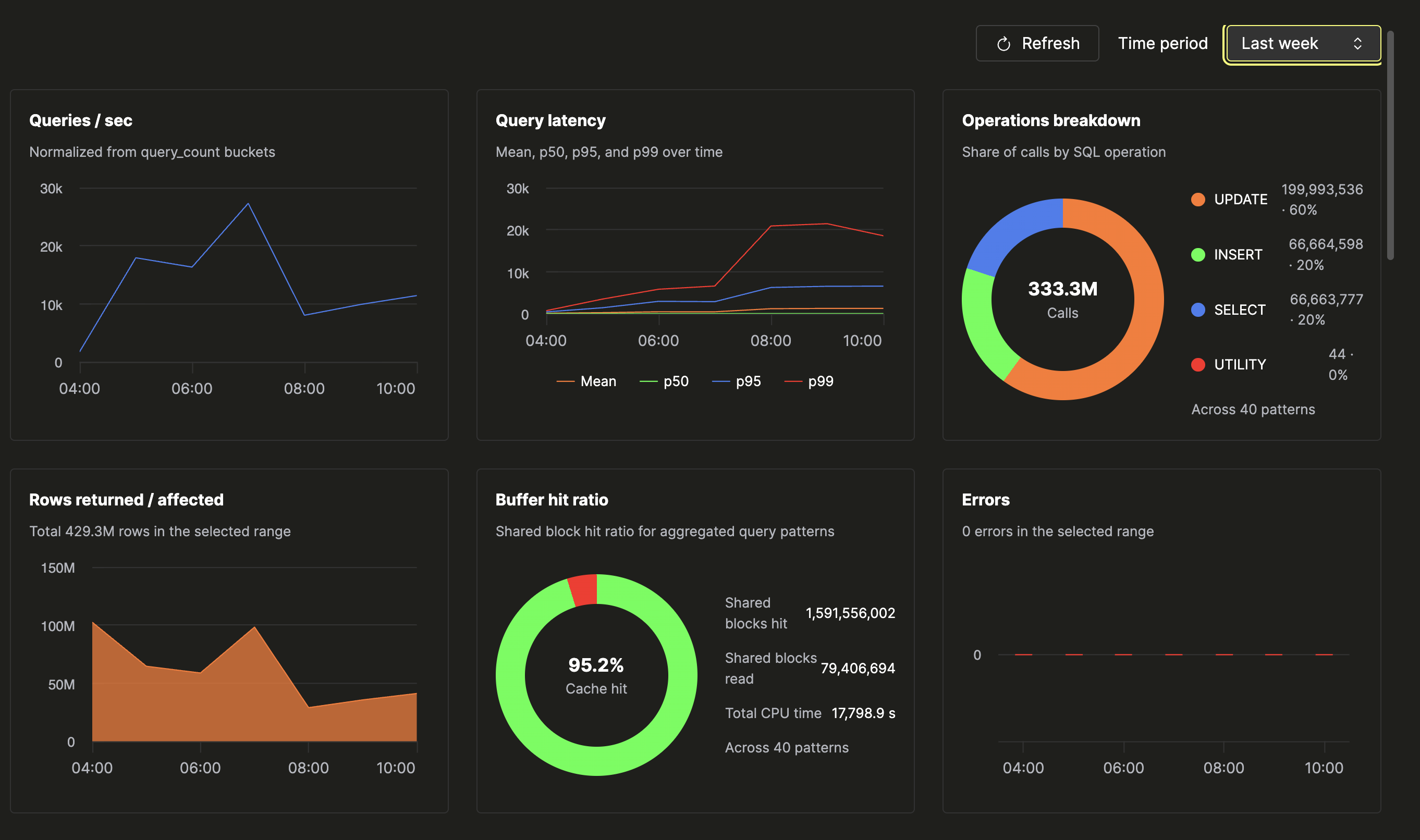
概览由一个 3×2 网格中的六个面板组成:
| 面板 | 显示内容 |
|---|---|
| 查询 / 秒 | 在所选时间窗口内折算为速率的查询量。 |
| 查询延迟 | 在一张图上显示均值、p50、p95 和 p99,便于查看尾部延迟何时开始偏离中位数。 |
| 操作明细 | 一个环形图,展示你的工作负载实际由 SELECT、INSERT、UPDATE 及其他操作构成的占比。 |
| 返回 / 影响的行数 | 该工作负载在时间窗口内处理的总行数。 |
| 缓冲区命中率 | 一个环形图,对比共享块命中数与共享块读取数,图例中显示总 CPU 时间。 |
| 错误 | 按时间拆分的错误总数。 |
通过这一屏,你就能判断数据库是否健康。健康的实例 通常具有熟悉的形态——缓冲区命中率保持在百分之九十几的高位,查询量 随应用流量同步变化,错误率保持平稳或为零,且各分位数 延迟彼此走势接近。
慢查询模式
当概览显示存在问题时,就应从模式表开始排查。每个规范化后的查询模式各占一行,并且会去除字面量,因此同一语句的多次执行会归并到同一行。
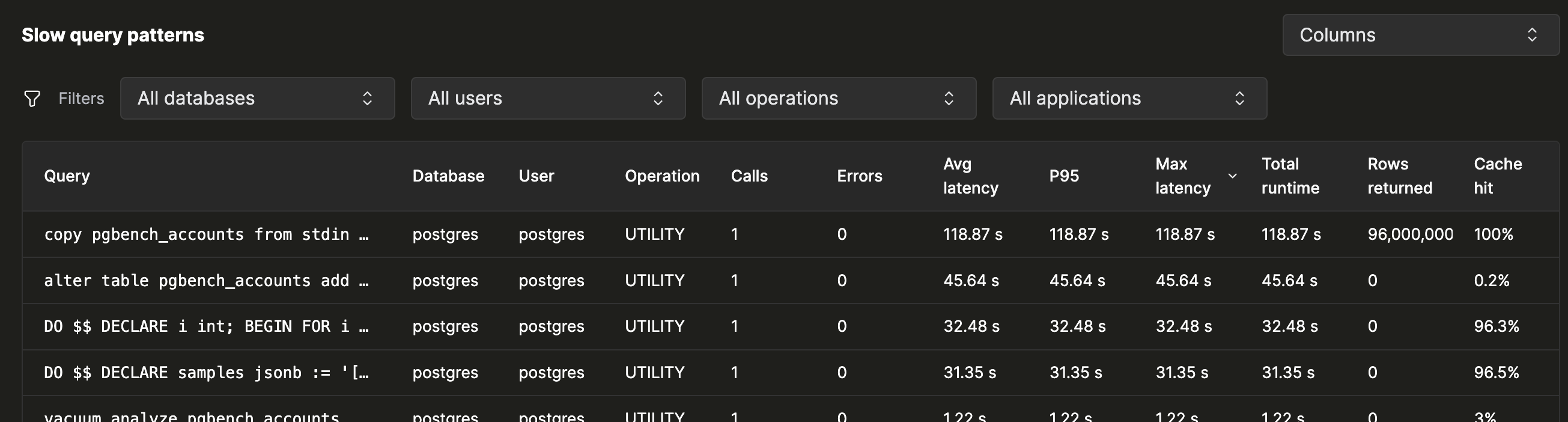
按你怀疑的问题排序
该表默认按 总运行时间 降序排序——按这种方式排序时, 排在最前面的模式通常就是“什么最耗时?” 这个问题的答案。但它不一定是单次最慢的模式。一个每天运行 八百万次、每次耗时十二毫秒的查询,可能比一个只运行一次、 耗时三秒的查询影响更大。
每种排序都提供了不同的观察视角:
- 总运行时间 —— 数据库消耗挂钟时间最多的模式。
- CPU 时间 —— 计算密集型模式。
- 调用次数 —— 高频模式。
- 错误 —— 反复失败的模式。
- 平均值 / P50 / P95 / P99 / 最大延迟 —— 按百分位查看异常值。
- 返回行数、读取块数、命中块数、WAL 字节数 — 通过执行引擎、缓存或 预写日志传输数据量最多的模式。
点击 列 按钮可切换显示更多列。 模式表总共显示 19 列,包括百分位数 明细、缓存命中率以及各模式的 CPU 时间。
缩小表格范围
将表格过滤到你正在排查的工作负载范围:
- 数据库
- 用户
- 操作 (
SELECT,INSERT,UPDATE,DELETE, …) - 应用程序 — 来自 connection string 的
application_name
“只看 orders 服务在 sales 数据库上执行了什么操作”
就变成了两个下拉菜单。过滤器的值会根据你的
实例实际运行过的内容自动填充。
最近查询
在模式表下方,最近查询面板按时间倒序列出每次单独的执行记录——每条已执行的 语句占一行,而不是每个模式占一行。当你需要查看原始事件流 而非聚合结果时,可使用此面板;例如,用来抽查某个修复是否已生效,或找出某个错误确切触发的时间点。
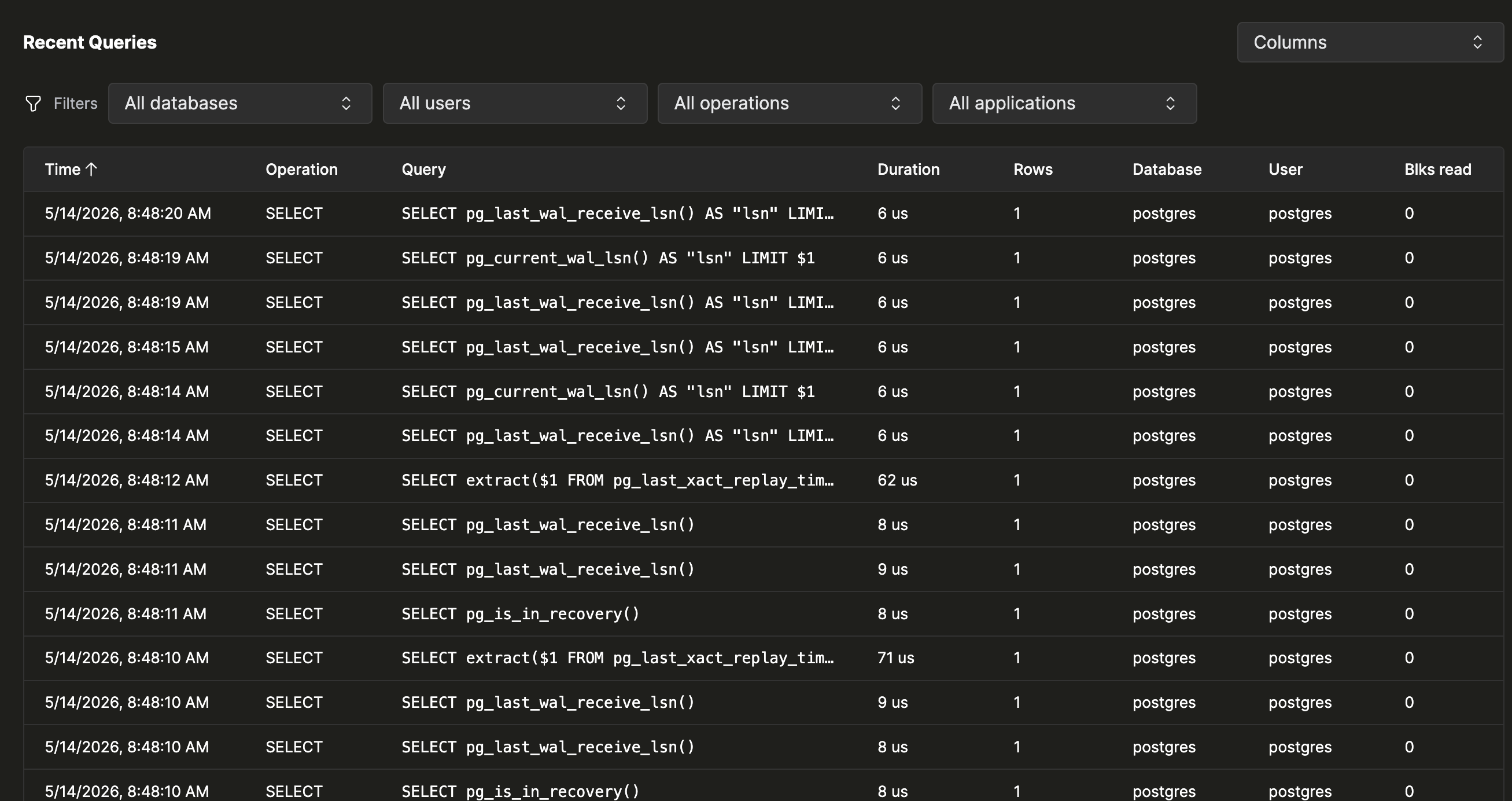
默认列为 Time、Operation、Query、Duration、Rows、 Database、User 和 Blks read。打开 Columns 选择器可查看 Application、Blks hit、CPU user、CPU sys 和 PID。该表支持 与模式表相同的 Database、User、Operation 和 Application 过滤器,并且可按 Time、Duration、Rows、Blks read 和 CPU time 排序。
单击任意一行,即可打开与模式表相同的详情弹出面板, 但范围仅限于该次执行对应的模式。
详情弹出面板
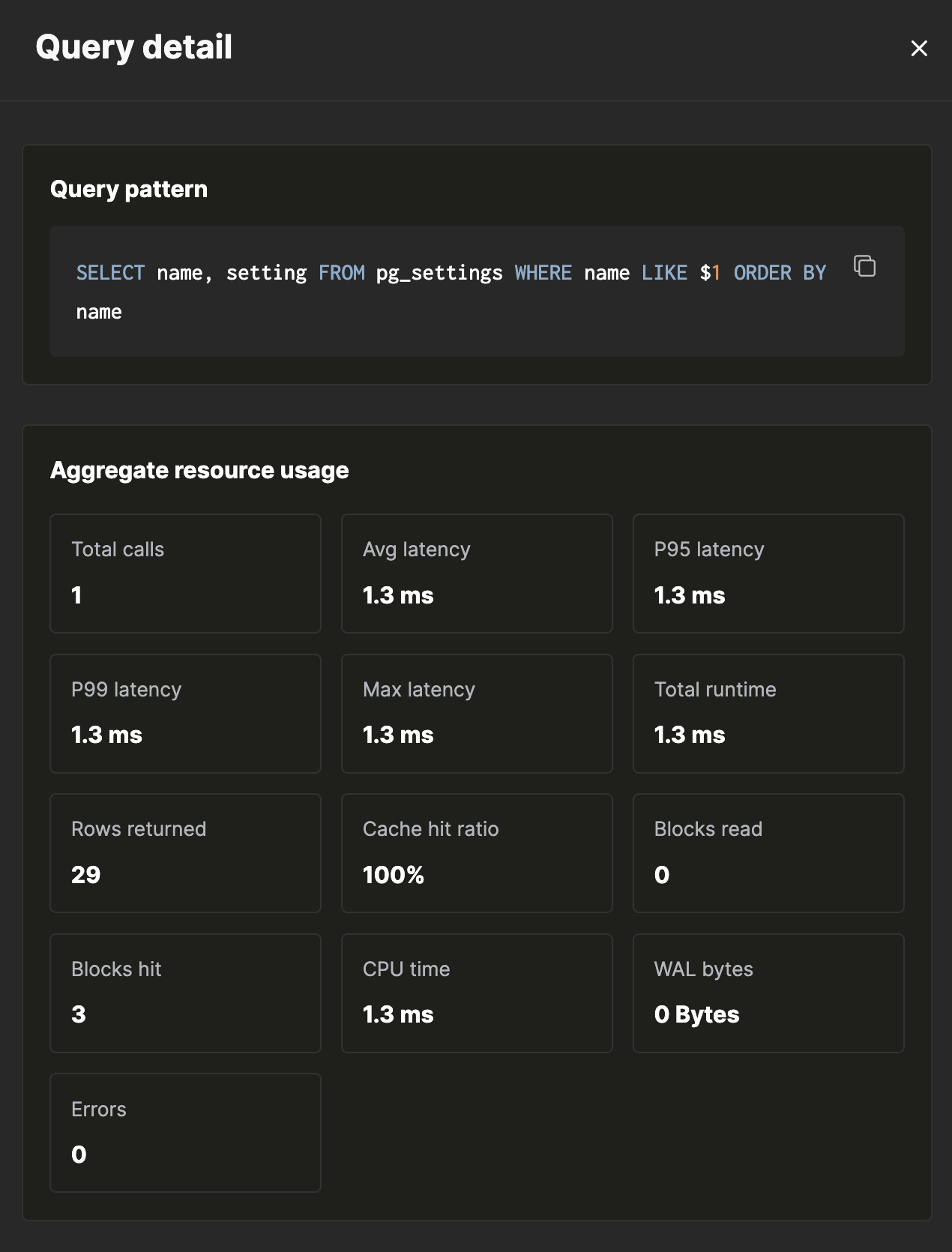
点击 patterns 或 recent queries 表中的任意一行后,右侧会打开 查询详情 弹出面板。该面板会汇总所选时间范围内该模式的每一次执行,并聚合用于解释其为何变慢的各项计数器。
该弹出面板采用单页滚动布局,包含五个部分:
- 查询模式 — 规范化后的 SQL,其中字面量会替换为
$1、$2、…,并提供复制到剪贴板按钮。 - 聚合资源使用情况 — 一个包含 13 个统计卡片的网格,涵盖总 调用次数、平均/P95/P99/最大延迟、总运行时间、返回行数、缓存 命中率、读取块数、命中块数、CPU 时间、WAL 字节数以及错误数。
- 查询上下文 — 该模式对应的数据库、用户、操作和应用程序。
- 重点执行 — 错误、明显偏慢的执行,以及 返回结果集较大的执行,会显示在完整的最近执行列表之前。
- 最近执行 — 同一模式的各次单独执行, 并附带每次执行的计数器。
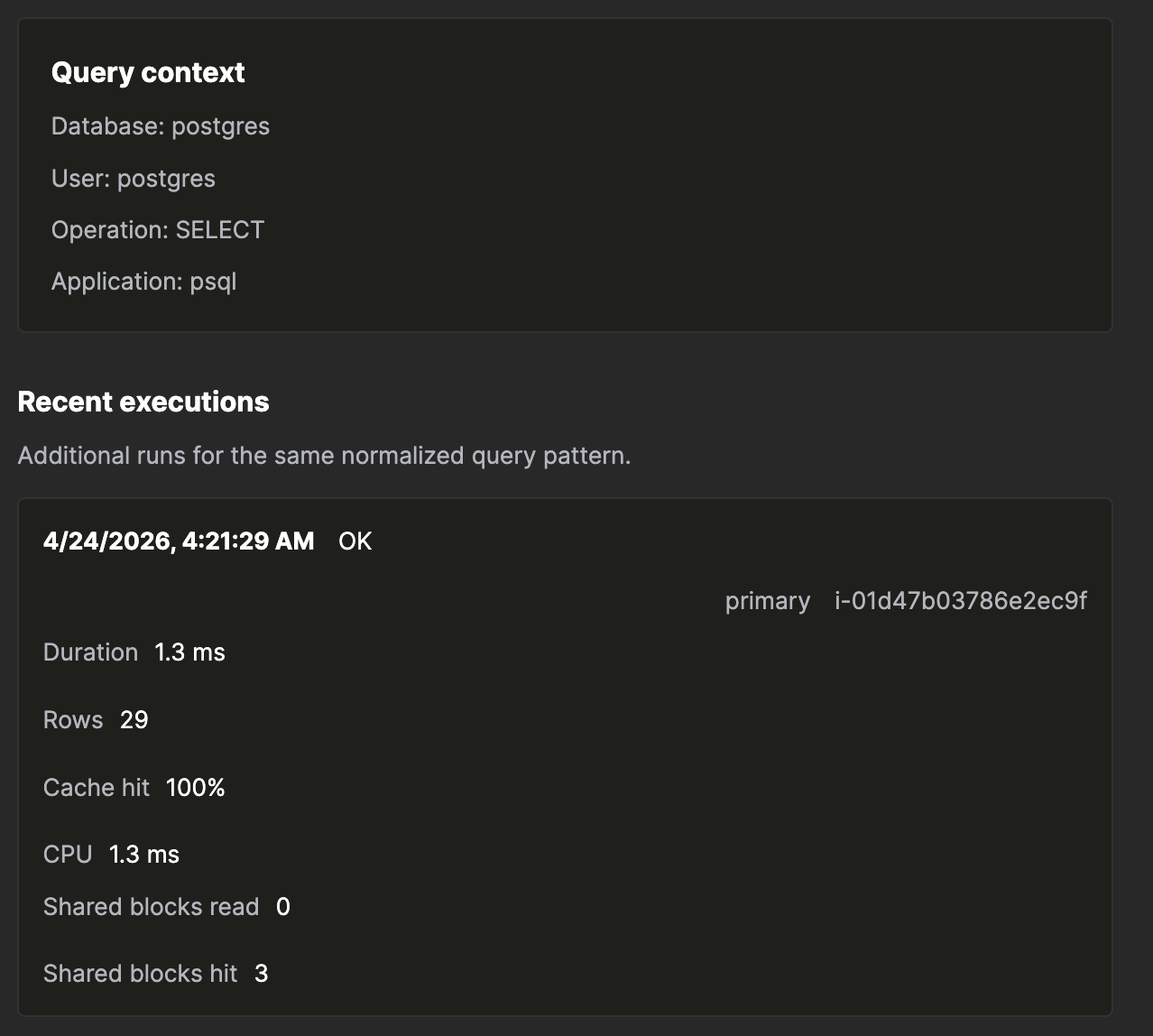
单次执行计数器
展开最近一次执行,即可看到精确定位时间消耗去向的各项计数器:
- 共享块 — read 和 hit 始终显示;written 和 dirtied 仅在非零时显示。
- 本地和临时块操作 — 临时块操作为非零,表示排序或 哈希操作已溢写到磁盘。
- 读取 / 写入时间 — I/O 时间,与 CPU 时间分开统计。
- CPU 时间 — 分别显示用户态和系统态时间。
- 并行工作线程 — 计划数与实际启动数对比。
- JIT — JIT 编译总耗时和函数数量。
- WAL — 字节数和记录数。
诊断慢查询模式所需的全部信息都集中在一个地方,一个 屏幕内即可查看。
工作原理
在 Postgres 中、在线路传输之前完成规范化
pg_stat_ch 会在解析分析阶段挂钩,将每个字面量替换为
占位符 ($1、$2、…) ,并将生成的模式缓存到一个按 queryid 键控的、
每个后端独有的 LRU 中。当执行器完成该语句时,附加到事件上的就是这个
缓存的模式。带具体值的原始语句绝不会离开数据库。
尽量不干扰数据库
生产端每条语句大约会带来 3% 的额外开销。入队路径 在共享内存环形缓冲区上使用非阻塞的 try-lock。在压力较大 时,该扩展会丢弃事件并通过计数器记录,而不是向 Postgres 施加背压。
原始事件,而非聚合
pg_stat_ch 会为每条已执行的语句生成一个原始事件 (包括顶层和
嵌套语句) ,并受采样限制。UI 中的每个百分位、排名和细分
都是对同一事件流执行的 ClickHouse 查询。
与客户使用的引擎相同
Insights 的后端是 ClickHouse Cloud。 对于繁忙的 Postgres 实例,按查询记录的遥测数据每天可达数百万行; 列式压缩让按次执行的详细数据能够以较低成本保留数月, 而对数十亿行数据进行亚秒级聚合, 则能让你在按一周或一个月的时间范围切片分析时,UI 依然保持流畅交互。
开源
pg_stat_ch 采用 Apache 2.0 许可证。它可对接任意 Postgres,并将数据发送到任意
ClickHouse。源码和问题反馈见
github.com/clickhouse/pg_stat_ch。
相关页面
- 监控仪表板 — 内置的资源与活动图表
- Prometheus 端点 — 将主机级指标抓取到您自己的可观测性栈中
- 扩展 — Managed Postgres 实例上可用的扩展
- GitHub 上的
pg_stat_ch— 为 Query Insights 提供支持的开源扩展
