使用 ClickHouse Cloud 迁移到 Managed Postgres
ClickHouse Cloud 内置了一个导入向导,可将外部 PostgreSQL 数据库迁移到 Managed Postgres 服务。该向导通过五个引导步骤处理源连接、schema 导出与导入、复制设置以及表选择。
前提条件
- 可访问源 PostgreSQL 数据库,并使用具有复制特权的用户账户。
- 一个用作迁移目标的 ClickHouse Managed Postgres 服务。如果您还没有,请参阅快速入门。
- 在本地计算机上安装
pg_dump和psql。两者都随标准 PostgreSQL 客户端工具一同提供。
迁移前的注意事项
- DDL 传播:持续复制 (CDC) 会捕获 DML 操作以及
ADD COLUMN。其他 DDL 修改 (如DROP COLUMN和ALTER COLUMN) 不会传播,必须在目标端手动执行。 - 外键约束:为避免摄取因外键检查而受阻,你需要在目标角色上临时设置
session_replication_role = replica。这将在下文的第 3 步中说明。
步骤 1:连接到源数据库
打开 ClickHouse Cloud 控制台,然后选择您的 Managed Postgres 服务。
在左侧边栏中,点击 数据源。
点击 开始导入。
填写源 PostgreSQL 数据库的连接详细信息:主机、端口、用户名、密码和数据库名称。如果源数据库需要,请启用 TLS。
如果您需要与源数据库建立私有连接,可以选择 SSH tunneling 并提供所需的 SSH 详细信息。这样,迁移过程便可安全地连接到无法通过公网访问的数据库。
选择一种摄取方法:
- 初始加载 + CDC — 复制现有数据,然后使目标持续与后续变更保持同步。
- 仅初始加载 — 一次性复制,不进行持续复制。
- 仅 CDC — 跳过初始复制,仅从此时起复制新的变更。
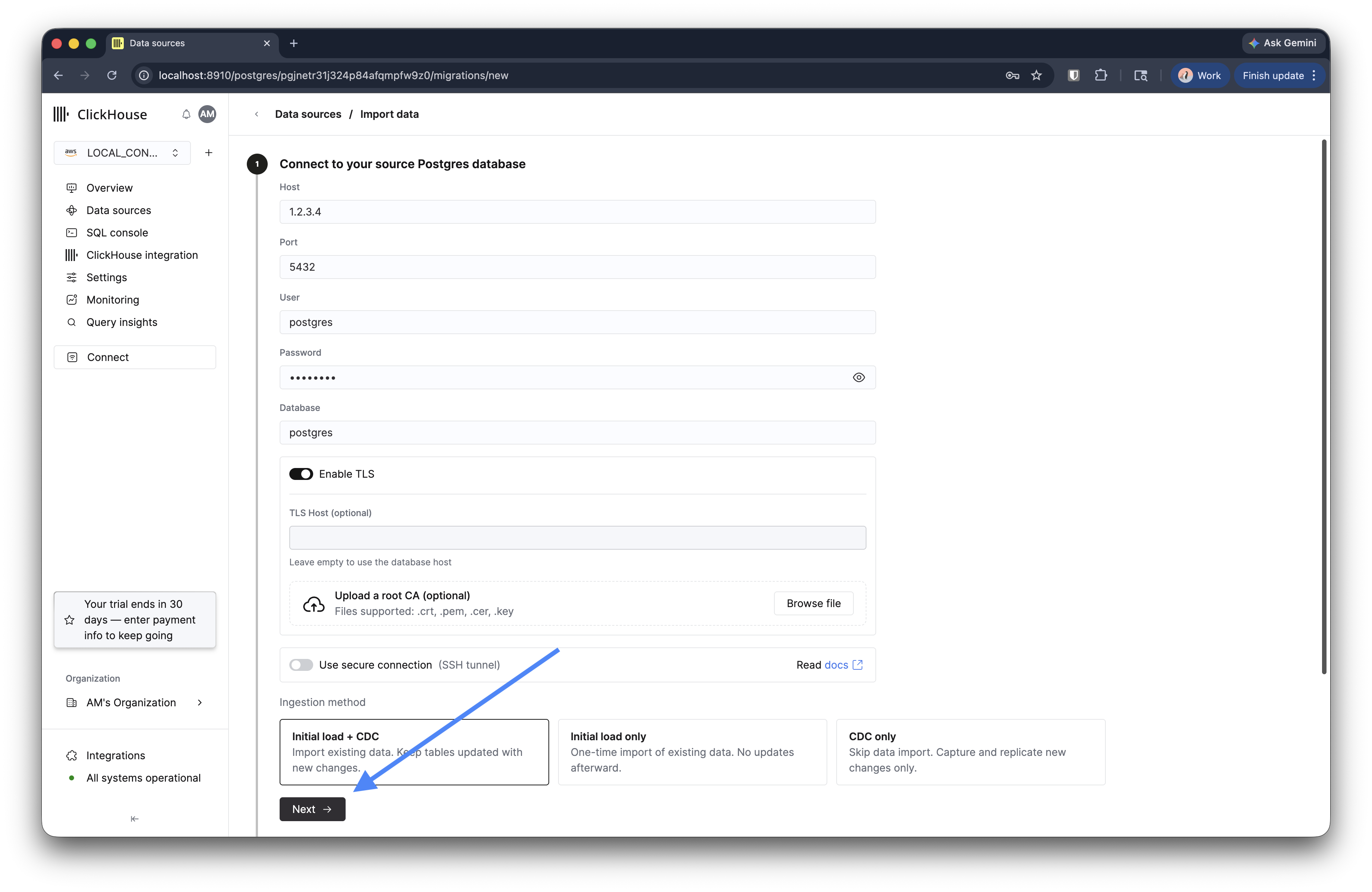
点击 下一步。
第 2 步:导出数据库 schema
向导会显示一条已预填源连接详细信息的 pg_dump 命令。请在终端中运行该命令:
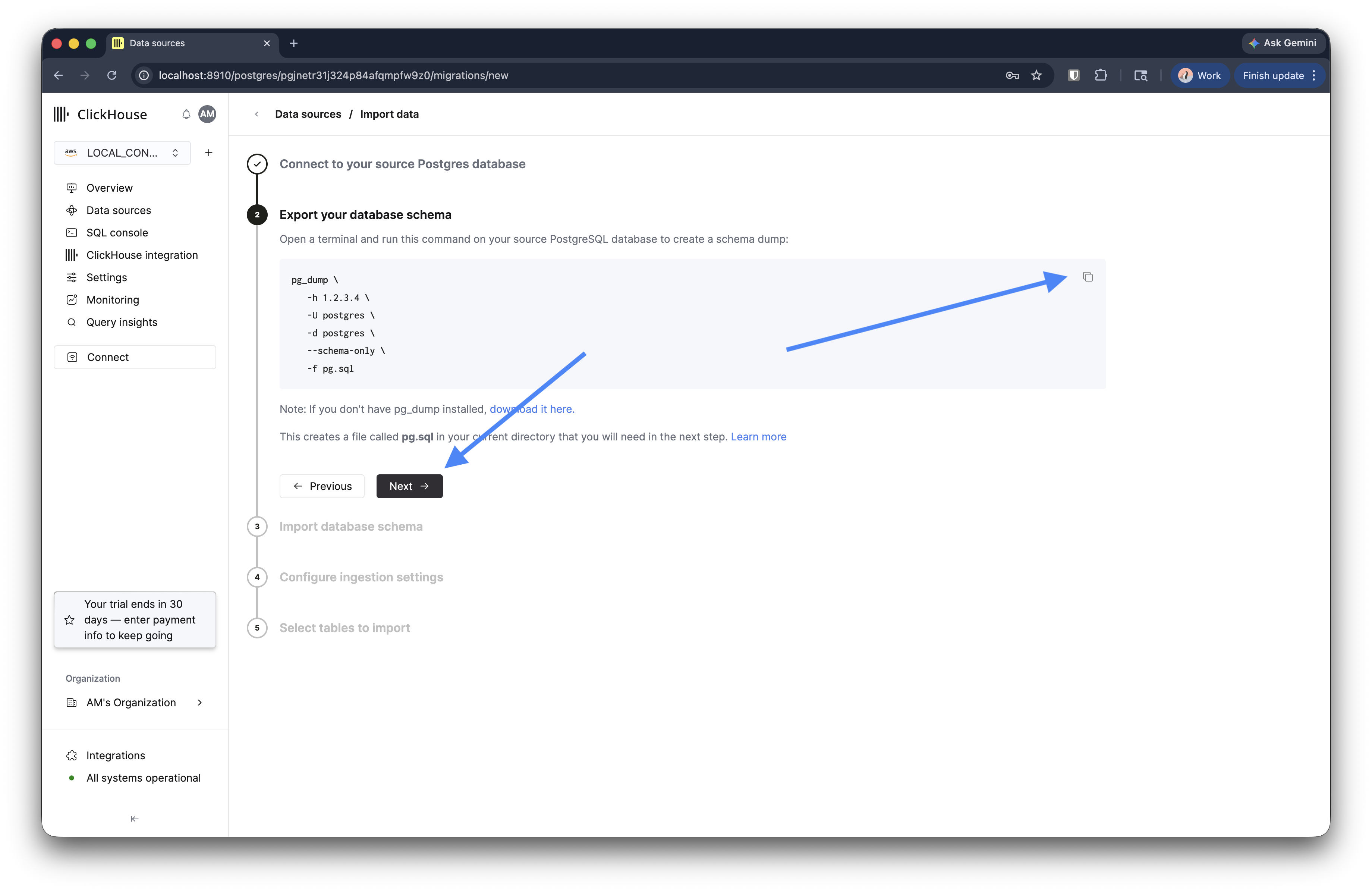
这会在当前目录下创建 pg.sql 文件。
点击 Next。
第 3 步:将 schema 导入您的 Managed Postgres 服务
从下拉列表中选择目标端数据库,或点击 创建新数据库 以预配一个数据库。
向导会显示一条 psql 命令,用于将 schema 转储导入您的 Managed Postgres 服务。请在终端中运行该命令:
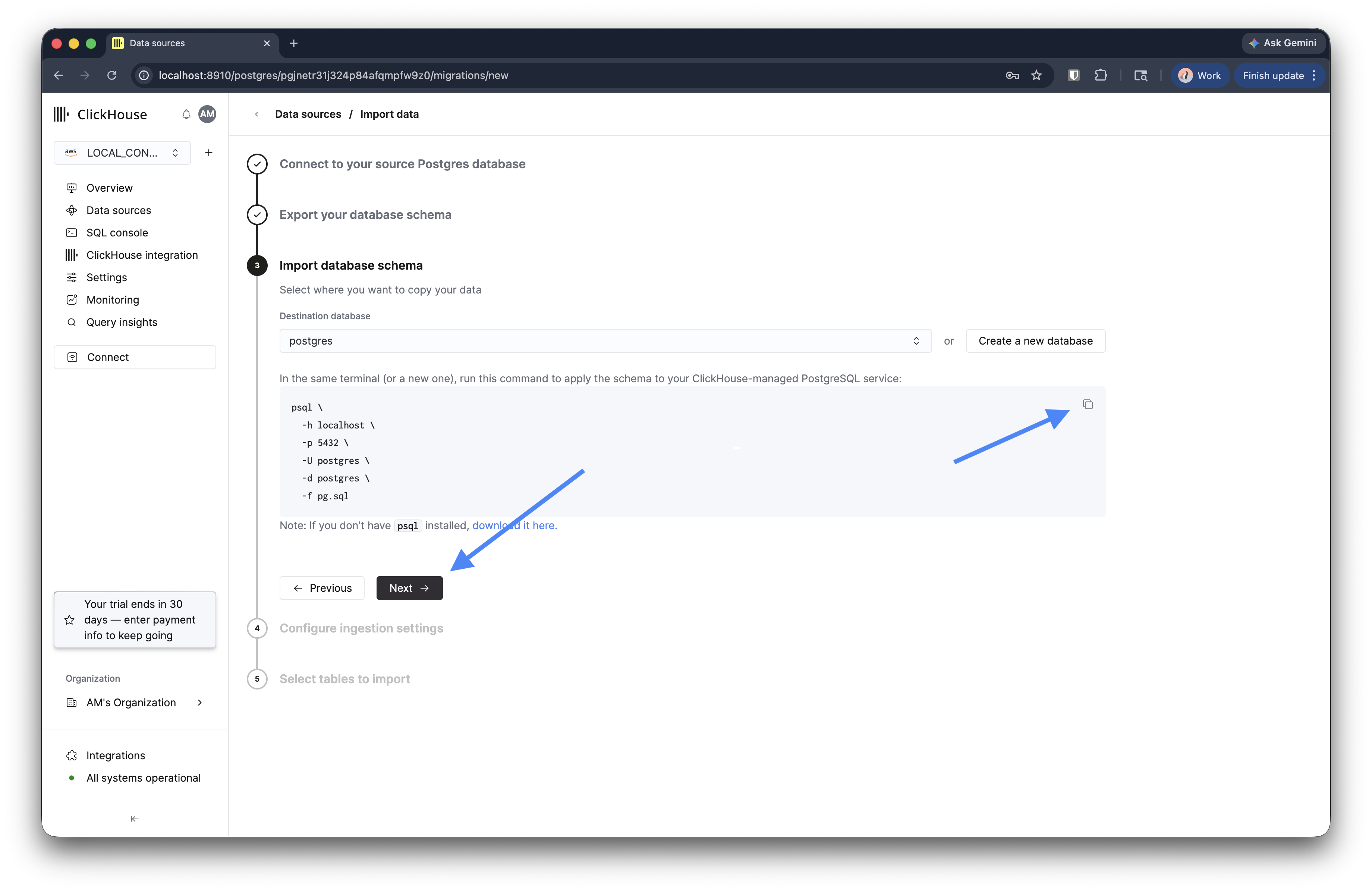

应用 schema 后,在目标角色上将 session_replication_role 设置为 replica,以防外键约束阻碍摄取:

点击 Next。
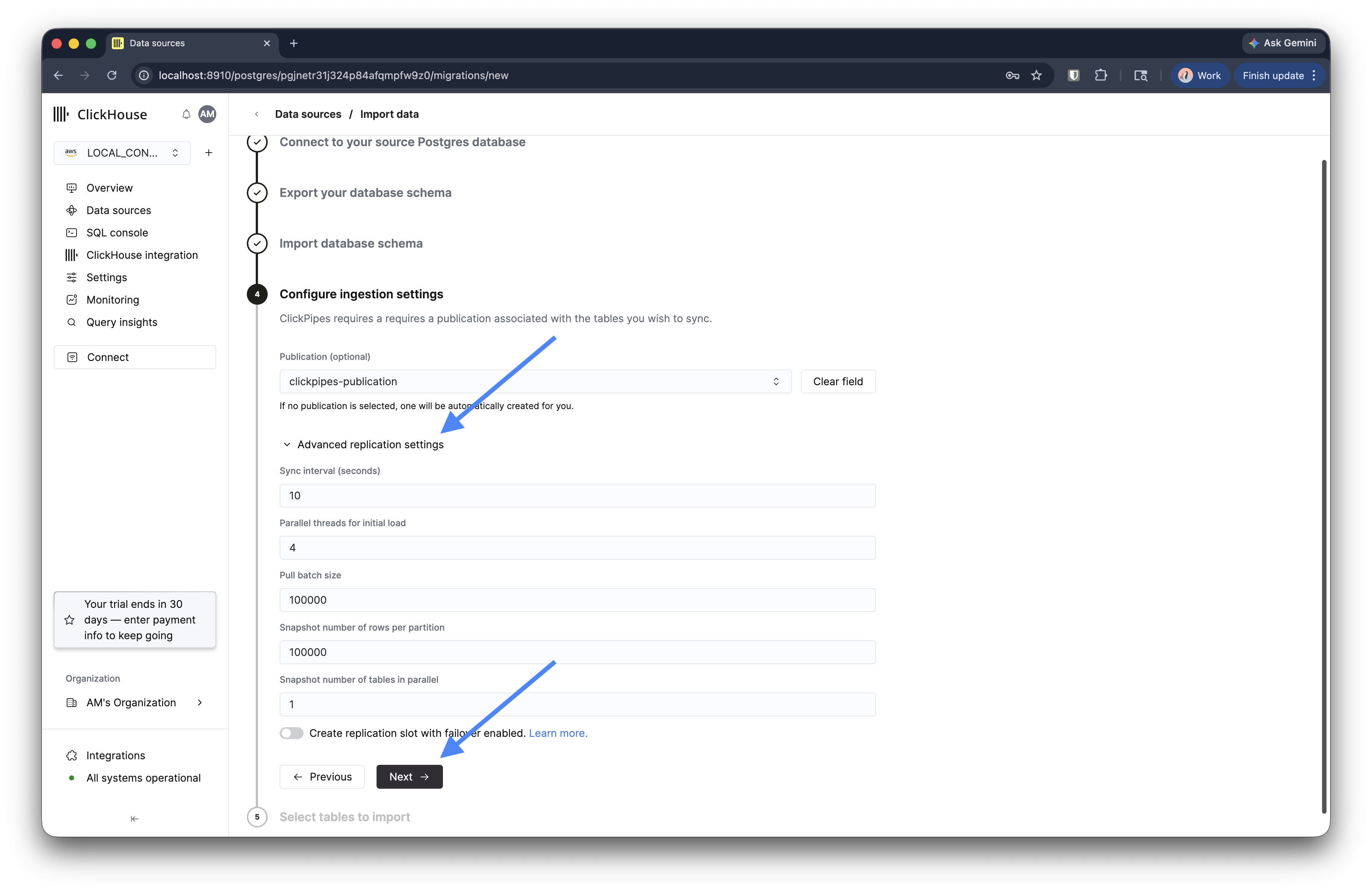
第 4 步:配置摄取设置
指定用于逻辑复制的 publication。如果将其留空,系统会自动创建一个 publication。
展开 进阶复制设置 以调整处理量:
| 设置 | 默认值 | 说明 |
|---|---|---|
| 同步间隔 (秒) | 10 | 轮询 replication slot 的频率 |
| 初始加载的并行线程数 | 4 | 批量复制阶段使用的线程数 |
| 拉取批次大小 | 100,000 | 每个复制批次拉取的行数 |
| 每个分区的快照行数 | 100000 | 大表快照的分区大小 |
| 并行创建快照的表数量 | 1 | 可并行创建快照的表数量 |
点击 Next。
第 5 步:选择表
选择要复制的表。表会按 schema 分组显示。可选择单个表,或展开某个 schema 以选择其中的所有表。
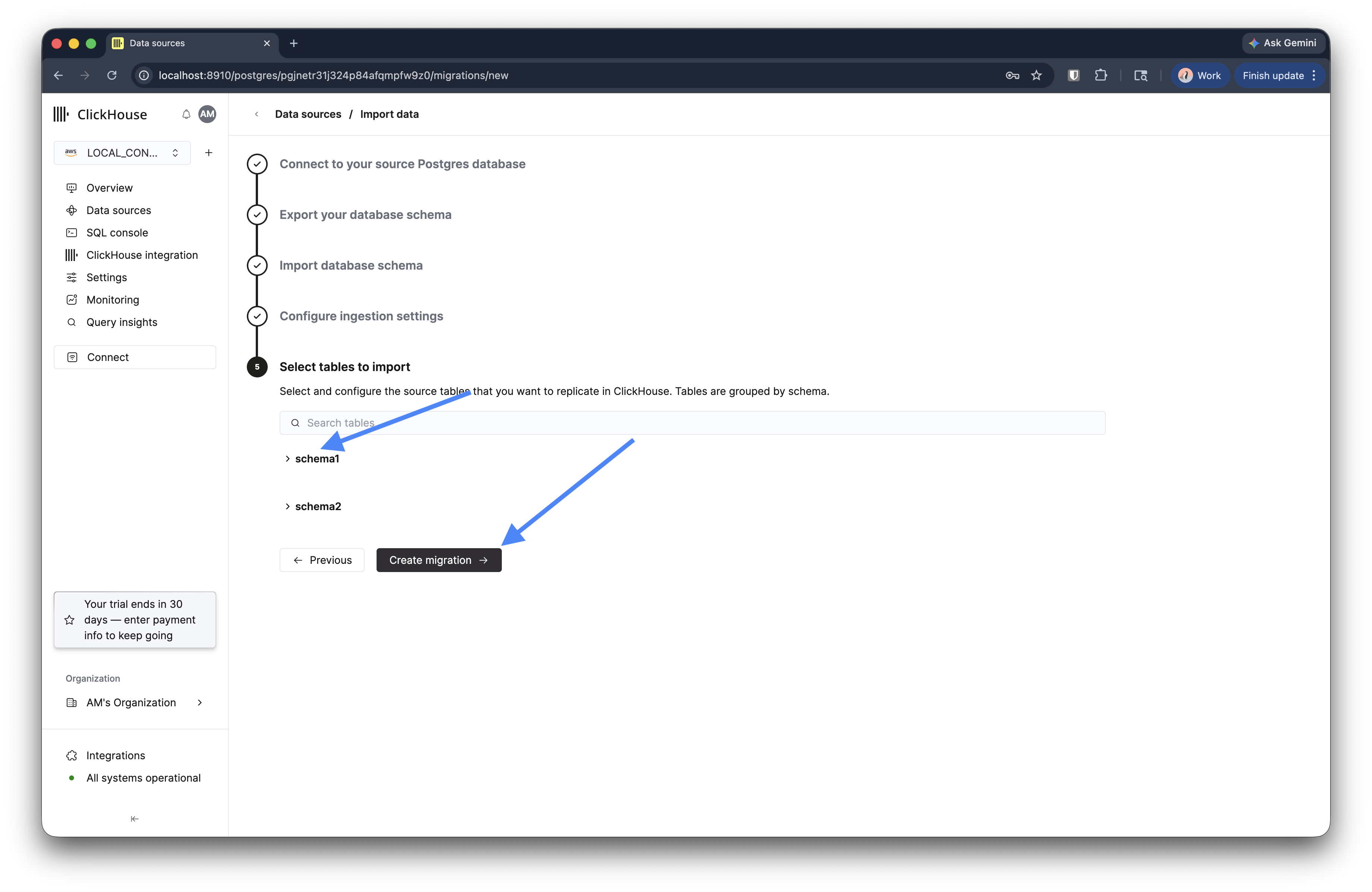
点击 Create migration。
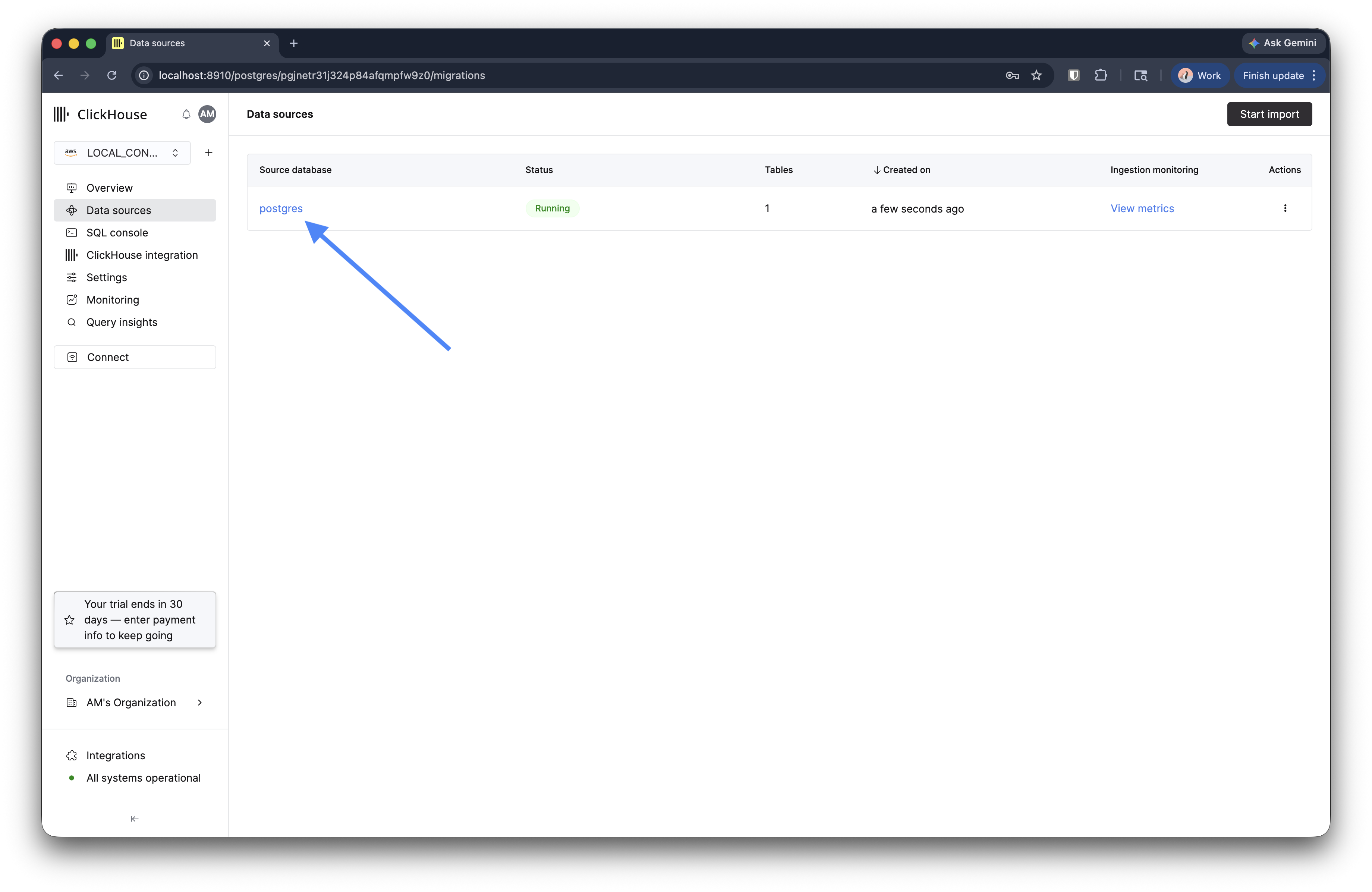
监控迁移
创建迁移后,你会在数据源中看到它,状态为 Running。
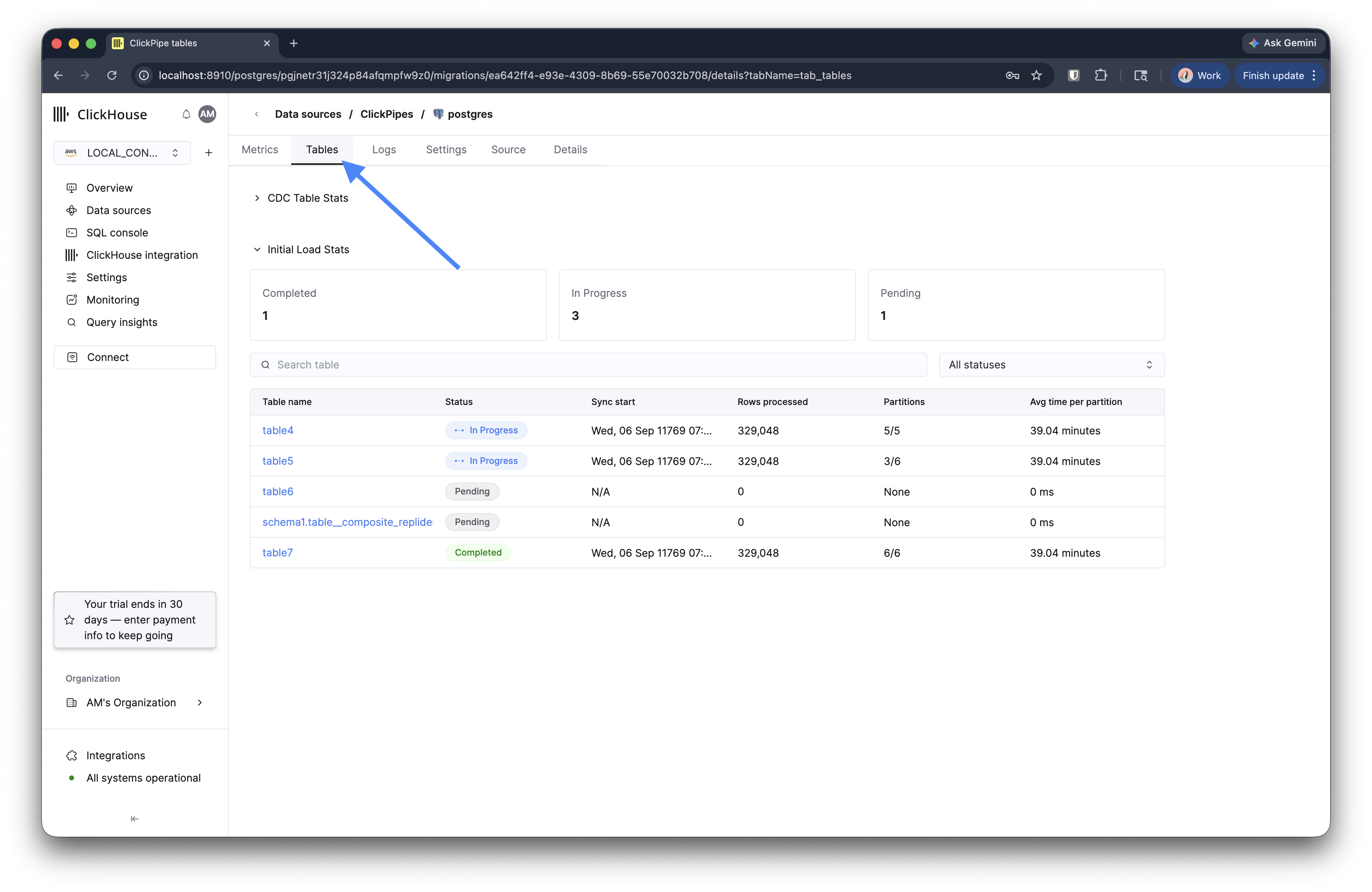
点击该迁移以打开详情页面。Tables 选项卡会显示每个表的初始加载进度,包括已处理的行、分区以及每个分区的平均耗时。Metrics 选项卡会在 CDC 开始后显示复制延迟和处理量。
迁移后任务
初始加载完成后,如果使用了 CDC,且复制延迟接近于零:
验证行数。 在切换流量之前,对源端和目标端的关键表进行抽样核对:
停止向源端写入。 暂停应用写入。要在切换期间强制设为只读模式:
确认复制已同步。 比较源端和目标端的最新一行:
重新启用约束并恢复复制角色。 重新应用在导入期间暂缓处理的所有索引、约束和触发器,然后重置目标角色:
重置序列。 使序列与各表中的当前最大值保持一致:
切换应用流量。 将应用的读写流量切换到您的 Managed Postgres 服务,并监控是否出现错误、约束违规以及复制健康状况。
清理。 完成切换并确认新服务运行正常后,从数据源中删除该迁移任务。如果您使用了 CDC,请从源端删除 replication slot 以释放资源:
