设置查询 API 端点
Query API Endpoints 功能允许您在 ClickHouse Cloud 控制台中直接基于任意已保存的 SQL 查询创建一个 API 端点。之后,您可以通过 HTTP 调用这些 API 端点来执行已保存的查询,而无需通过原生驱动连接到 ClickHouse Cloud 服务。
先决条件
在继续之前,请确保你已经具备:
- 一个具有相应权限的 API key
- 一个 Admin Console 角色
如果你还没有 API key,可以按照本指南创建一个 API key。
要查询一个 API endpoint,API key 需要具备 Member 组织角色以及 Query Endpoints 服务访问权限。数据库角色会在你创建 endpoint 时进行配置。
创建一个已保存查询
如果你已经有一个已保存查询,可以跳过此步骤。
打开一个新的查询选项卡。作为示例,我们将使用 youtube dataset,该数据集包含大约 45 亿条记录。 按照 "Create table" 一节中的步骤,在你的 Cloud 服务上创建表并向其中插入数据。
LIMIT 限制行数示例数据集教程会插入大量数据——46.5 亿行,这可能需要一些时间来插入。
出于本指南的目的,我们建议使用 LIMIT 子句插入较少量的数据,
例如 1000 万行。
作为示例查询,我们将返回在用户输入的 year 参数对应年份中,每个视频平均观看次数最高的前 10 名上传者。
请注意,此查询包含一个参数 (year) ,在上面的代码片段中已高亮显示。
你可以使用花括号 { } 加上参数类型来指定查询参数。
SQL 控制台查询编辑器会自动检测 ClickHouse 查询参数表达式,并为每个参数提供一个输入框。
让我们快速运行一次此查询,通过在 SQL 编辑器右侧的查询变量输入框中指定年份 2010 来确保它可以正常工作:
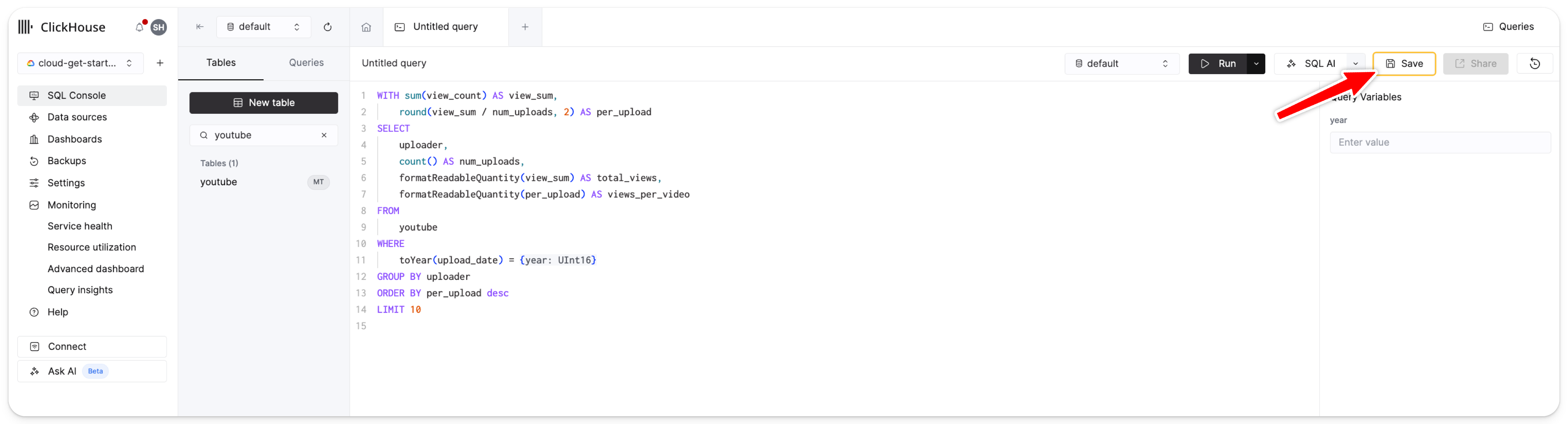
接下来,将该查询保存下来:
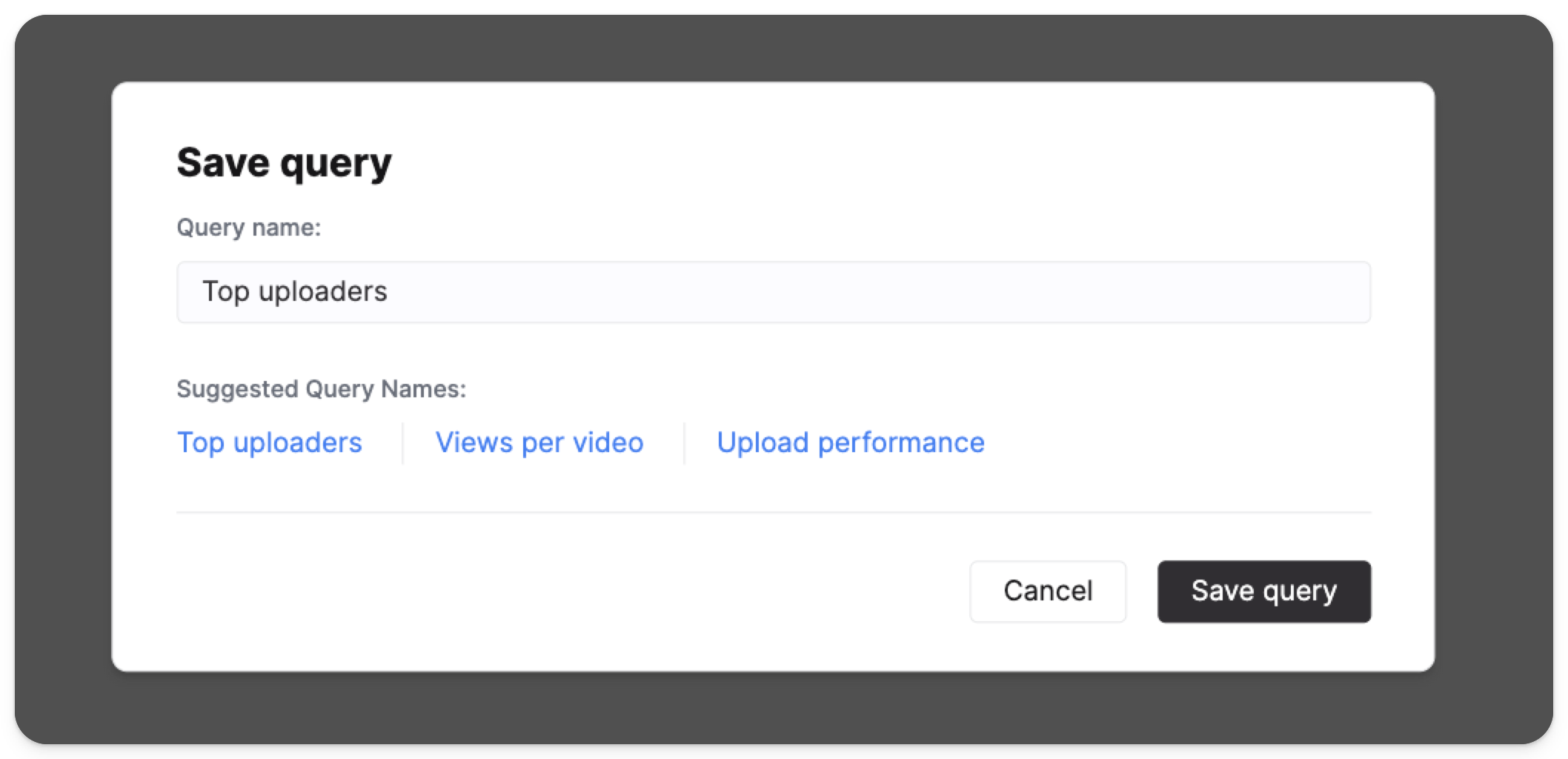
有关已保存查询的更多文档,请参见 "Saving a query" 一节。
配置查询 API endpoint
可以在查询视图中直接配置 Query API endpoints,只需点击 Share 按钮并选择 API Endpoint。
系统会提示你指定哪些 API key 可以访问该 endpoint:
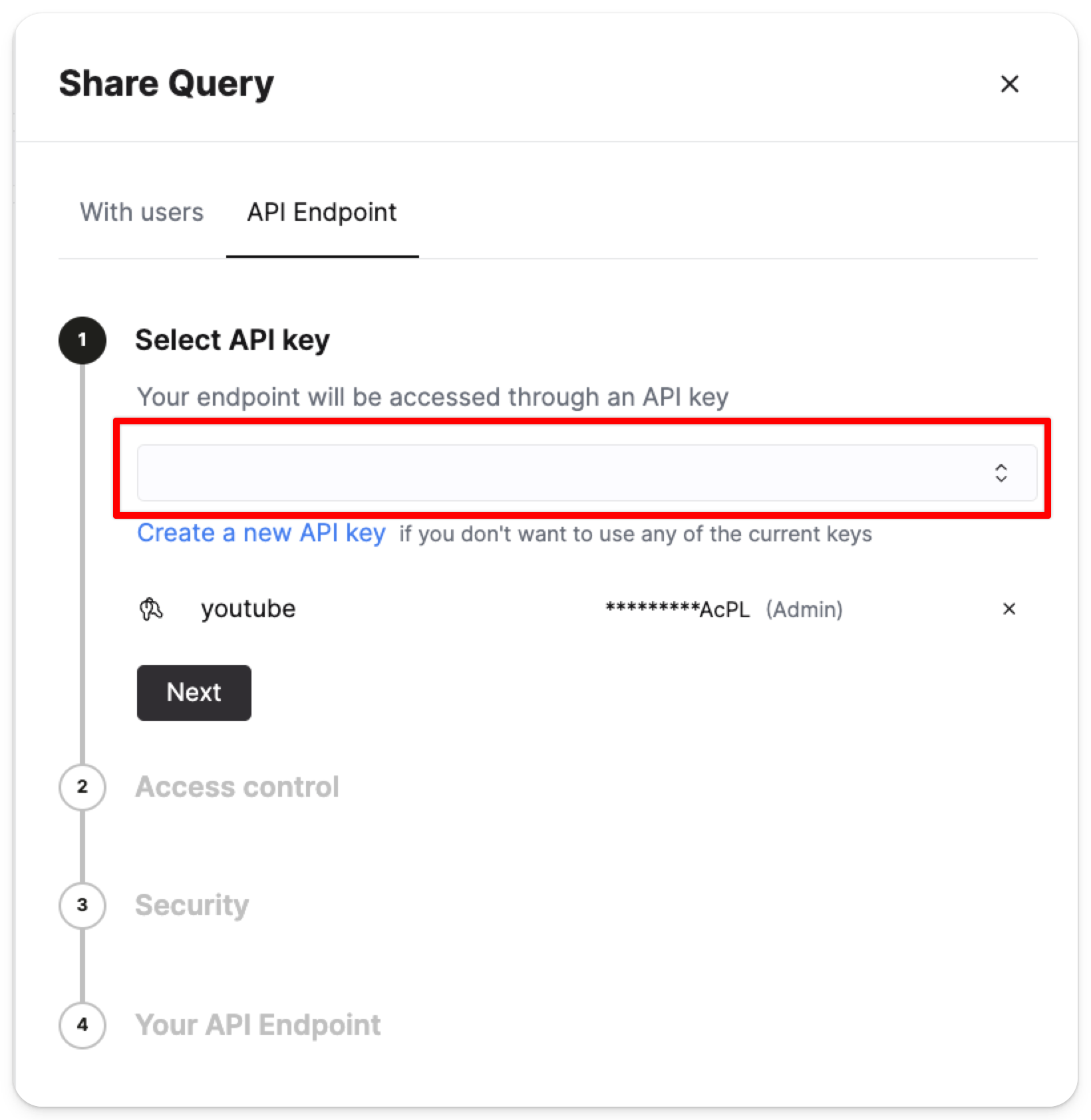
选择 API key 后,你将被要求:
- 选择用于运行查询的 Database 角色 (
Full access、Read only或Create a custom role) - 指定允许跨域资源共享 (CORS) 的域名
选择这些选项后,查询 API endpoint 会被自动创建。
界面中会显示一个示例 curl 命令,以便你发送测试请求:
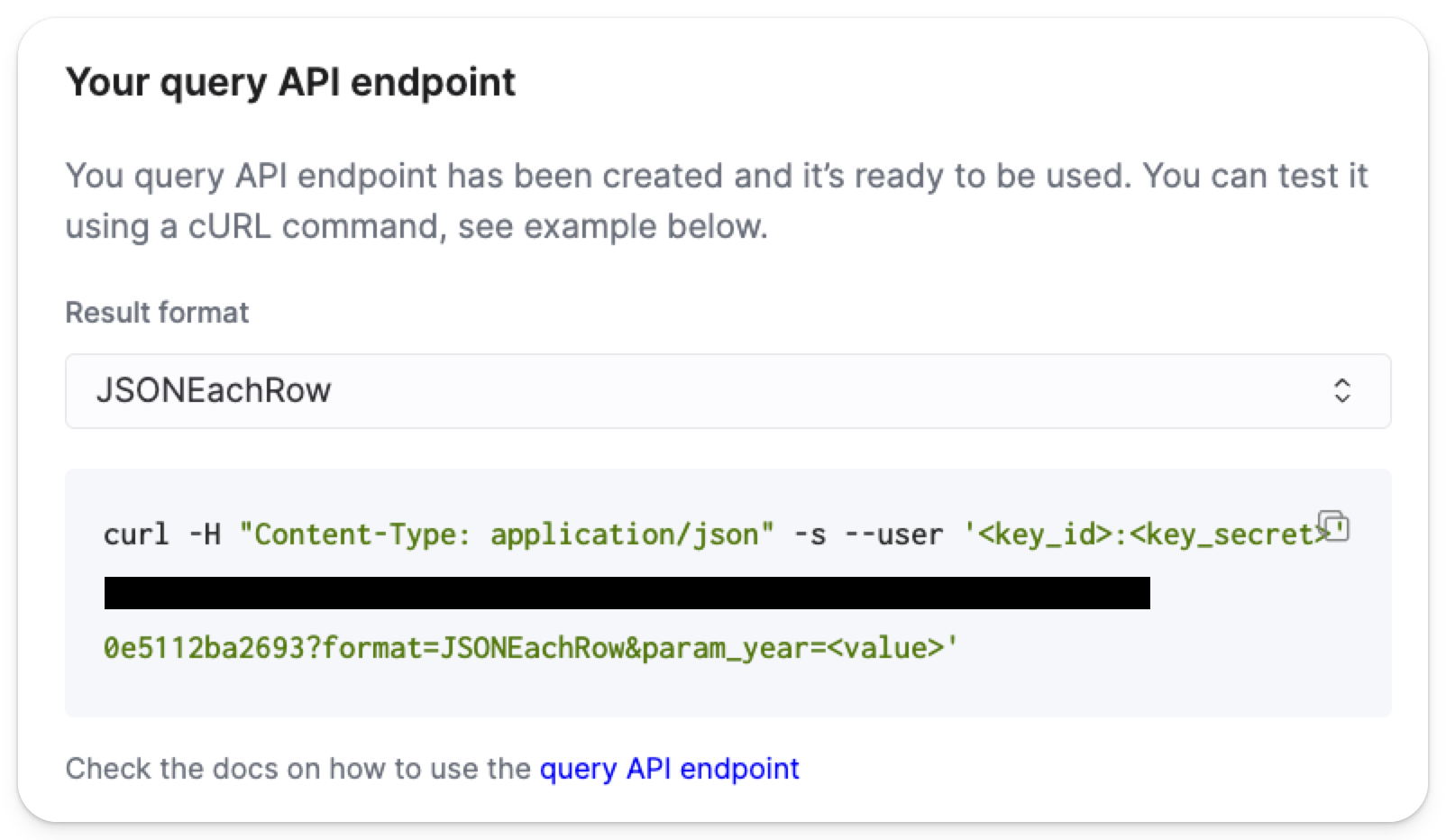
为了方便起见,界面中显示的 curl 命令如下所示:
Query API 参数
查询中的查询参数可以使用 {parameter_name: type} 这种语法来指定。这些参数会被自动检测到,示例请求载荷中会包含一个 queryVariables 对象,你可以通过该对象传递这些参数。
测试与监控
创建 Query API endpoint 之后,你可以使用 curl 或任何其他 HTTP 客户端测试它是否正常工作:
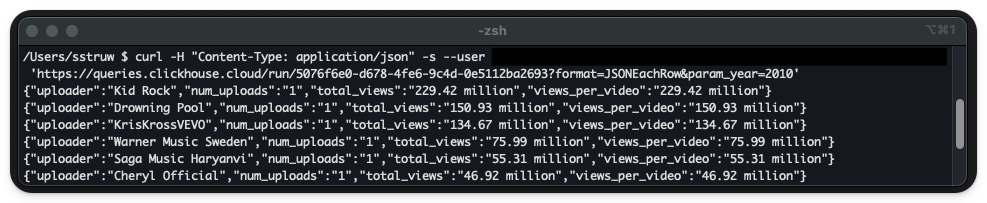
在你发送第一条请求之后,Share 按钮右侧应会立即出现一个新按钮。点击它将打开一个包含该查询监控数据的侧边浮层:
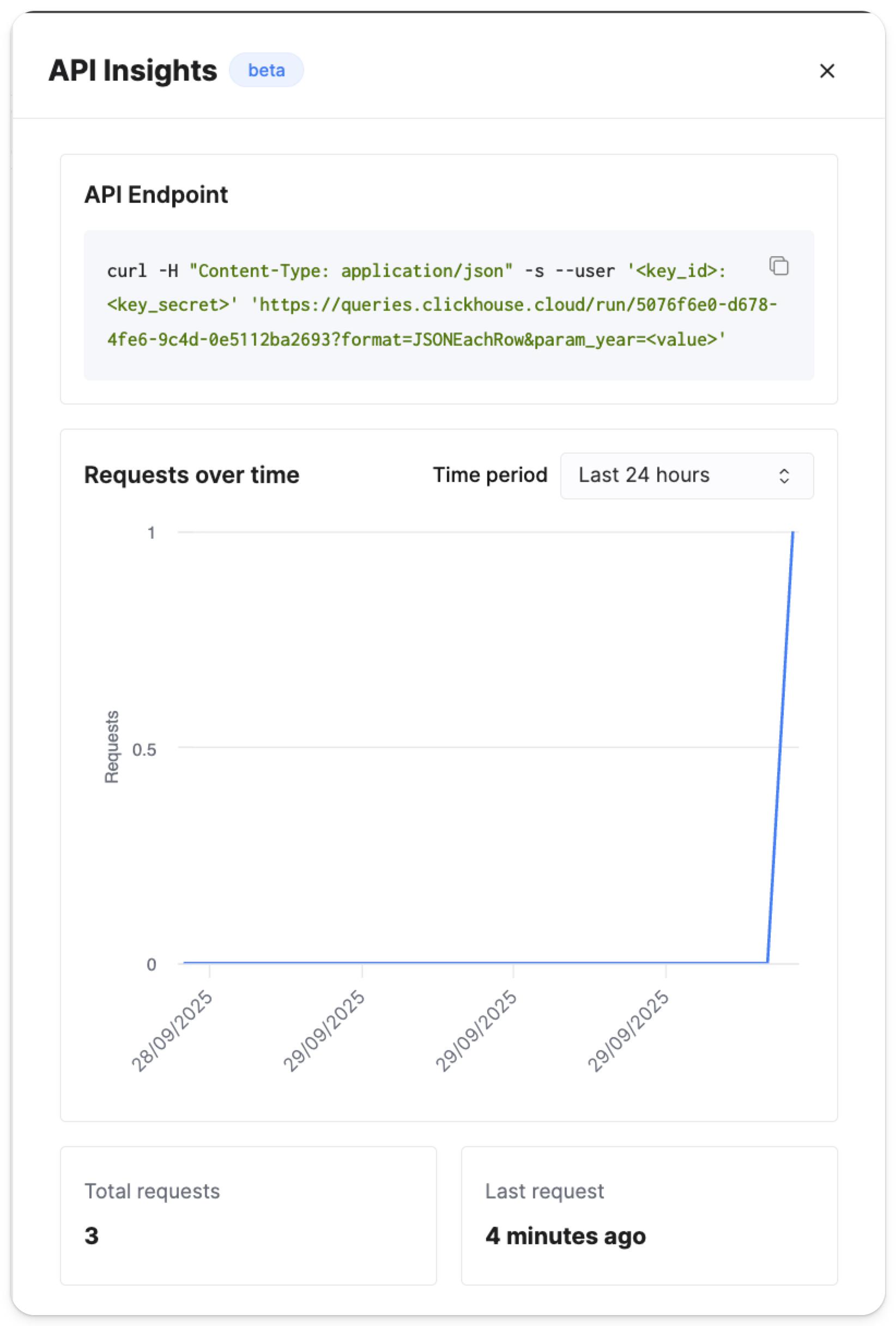
实现细节
该端点会在已保存的 Query API 端点上执行查询。 它支持多版本、灵活的响应格式、参数化查询,以及可选的流式响应(仅限版本 2)。
端点:
HTTP 方法
| Method | Use Case | Parameters |
|---|---|---|
| GET | 带参数的简单查询 | 通过 URL 参数传递查询变量(?param_name=value) |
| POST | 复杂查询或需要使用请求体时 | 在请求体中传递查询变量(queryVariables 对象) |
何时使用 GET:
- 无复杂嵌套数据的简单查询
- 参数可以方便地进行 URL 编码
- 可以利用 HTTP GET 语义带来的缓存优势
何时使用 POST:
- 复杂的查询变量(数组、对象、长字符串)
- 出于安全/隐私考虑优先使用请求体时
- 需要进行文件流式上传或大体量数据传输时
身份验证
必需: 是
方法: 使用 OpenAPI Key/Secret 的 Basic Auth
权限: 对查询端点具有相应权限
请求配置
URL 参数
| 参数 | 是否必需 | 描述 |
|---|---|---|
queryEndpointId | 是 | 要执行的查询端点的唯一标识符 |
查询参数
| 参数 | 是否必需 | 描述 | 示例 |
|---|---|---|---|
format | 否 | 响应格式(支持所有 ClickHouse 格式) | ?format=JSONEachRow |
param_:name | 否 | 当请求体为流式数据时使用的查询变量。将 :name 替换为你的变量名 | ?param_year=2024 |
request_timeout | 否 | 查询超时时间(毫秒)(默认值:30000) | ?request_timeout=60000 |
:clickhouse_setting | 否 | 任意受支持的 ClickHouse 设置项 | ?max_threads=8 |
请求头
| Header | Required | Description | Values |
|---|---|---|---|
x-clickhouse-endpoint-version | No | 指定端点版本号 | 1 或 2(默认为最近一次保存的版本) |
x-clickhouse-endpoint-upgrade | No | 触发端点版本升级(与版本请求头配合使用) | 1 表示升级 |
请求体
参数
| 参数 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
queryVariables | object | 否 | 在查询中使用的变量 |
format | string | 否 | 响应格式 |
支持的格式
| 版本 | 支持的格式 |
|---|---|
| Version 2 | 所有 ClickHouse 所支持的格式 |
| Version 1(功能受限) | TabSeparated TabSeparatedWithNames TabSeparatedWithNamesAndTypes JSON JSONEachRow CSV CSVWithNames CSVWithNamesAndTypes |
响应
成功
状态: 200 OK
查询已成功执行。
错误代码
| 状态码 | 描述 |
|---|---|
400 Bad Request | 请求格式不正确 |
401 Unauthorized | 缺少身份验证或权限不足 |
404 Not Found | 未找到指定的查询接口 |
错误处理最佳实践
- 确保在请求中包含有效的身份验证凭据
- 在发送前校验
queryEndpointId和queryVariables - 实现健壮的错误处理机制,并返回适当的错误信息
升级端点版本
要从版本 1 升级到版本 2:
- 添加
x-clickhouse-endpoint-upgrade请求头并设置为1 - 添加
x-clickhouse-endpoint-version请求头并设置为2
即可使用版本 2 的功能,包括:
- 支持所有 ClickHouse 格式
- 响应流式传输
- 更高的性能和更丰富的功能
示例
基本请求
API 端点的 SQL 查询:
版本 1
- cURL
- JavaScript
版本 2
- GET(cURL)
- POST (cURL)
- JavaScript
Request with query variables and version 2 on JSONCompactEachRow format
Query API Endpoint SQL:
- GET (cURL)
- POST (cURL)
- JavaScript
Request with array in the query variables that inserts data into a table
Table SQL:
Query API Endpoint SQL:
- cURL
- JavaScript
Request with ClickHouse settings max_threads set to 8
Query API Endpoint SQL:
- GET (cURL)
- POST (cURL)
- JavaScript
Request and parse the response as a stream`
Query API Endpoint SQL:
- TypeScript
Insert a stream from a file into a table
Create a file ./samples/my_first_table_2024-07-11.csv with the following content:
Create Table SQL:
Query API Endpoint SQL:
