DataStore:Pandas 兼容 API 与 SQL 优化
DataStore 是 chDB 提供的、与 pandas 兼容的 API,它将熟悉的 pandas DataFrame 接口与 SQL 查询优化的强大能力相结合,并允许你使用 pandas 风格的代码,同时获得 ClickHouse 级别的性能。
关键特性
- Pandas 兼容性:支持 209 个 pandas DataFrame 方法、56 个
.str方法、42+ 个.dt方法 - SQL 优化:操作会自动编译为优化后的 SQL 查询
- 惰性求值:仅在需要结果时才执行操作
- 630+ API 方法:用于数据操作的完备 API 接口集合
- ClickHouse 扩展:提供 pandas 中不可用的额外访问器(
.arr、.json、.url、.ip、.geo)
架构
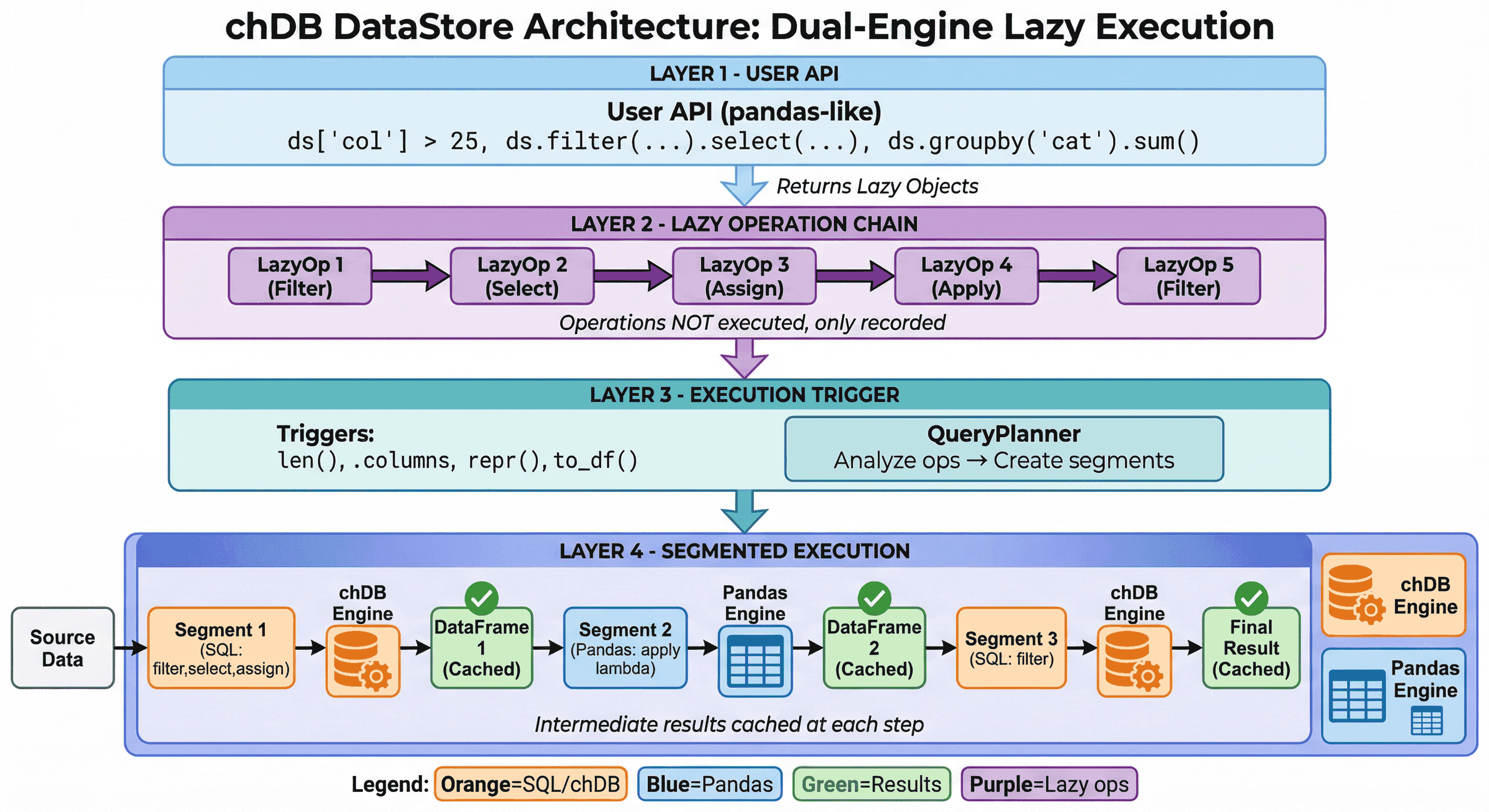
DataStore 采用具有 惰性求值 特性的 双引擎执行:
- 惰性操作链:只记录操作,而不是立即执行
- 智能引擎选择:QueryPlanner 将每个阶段路由到最优引擎(SQL 使用 chDB,复杂操作使用 Pandas)
- 中间结果缓存:在每一步缓存结果,以支持快速的迭代式探索
详情请参见 执行模型。
一行代码迁移自 Pandas
你现有的 pandas 代码可以不作任何修改直接运行,只是现在是在 ClickHouse 引擎上执行。
性能对比
与 pandas 相比,DataStore 在性能上有显著提升,尤其是在聚合和复杂处理流水线场景中:
| 操作 | Pandas | DataStore | 加速比 |
|---|---|---|---|
| GroupBy count | 347ms | 17ms | 19.93x |
| Complex pipeline | 2,047ms | 380ms | 5.39x |
| Filter+Sort+Head | 1,537ms | 350ms | 4.40x |
| GroupBy agg | 406ms | 141ms | 2.88x |
基于 10M 行数据的基准测试。详情参见 benchmark script 和 Performance Guide。
何时使用 DataStore
在以下情况下使用 DataStore:
- 处理大规模数据集(数百万行)
- 执行聚合和 groupby(分组)操作
- 从文件、数据库或 Cloud 存储中查询数据
- 构建复杂数据管道
- 希望在使用 pandas API 的同时获得更高性能
在以下情况下使用原生 SQL API:
- 更喜欢直接编写 SQL 时
- 需要对查询执行进行细粒度控制时
- 需要使用 pandas API 无法访问的 ClickHouse 特性时
功能比较
| 功能 | Pandas | Polars | DuckDB | DataStore |
|---|---|---|---|---|
| Pandas API 兼容性 | - | 部分兼容 | 否 | 完全兼容 |
| 惰性求值 | 否 | 是 | 是 | 是 |
| SQL 查询支持 | 否 | 是 | 是 | 是 |
| ClickHouse 函数 | 否 | 否 | 否 | 是 |
| 字符串/日期时间访问器 | 是 | 是 | 否 | 是 + 额外扩展 |
| 数组/JSON/URL/IP/Geo | 否 | 部分支持 | 否 | 是 |
| 直接文件查询 | 否 | 是 | 是 | 是 |
| Cloud 存储支持 | 否 | 有限支持 | 是 | 是 |
API 统计信息
| 类别 | 数量 | 覆盖率 |
|---|---|---|
| DataFrame 方法 | 209 | 覆盖 pandas 的 100% |
| Series.str 访问器 | 56 | 覆盖 pandas 的 100% |
| Series.dt 访问器 | 42+ | 覆盖 100%+(包括 ClickHouse 扩展) |
| Series.arr 访问器 | 37 | ClickHouse 特有 |
| Series.json 访问器 | 13 | ClickHouse 特有 |
| Series.url 访问器 | 15 | ClickHouse 特有 |
| Series.ip 访问器 | 9 | ClickHouse 特有 |
| Series.geo 访问器 | 14 | ClickHouse 特有 |
| API 方法总数 | 630+ | - |
文档导航
入门
- 快速开始 - 安装和基本用法
- 从 Pandas 迁移 - 分步迁移指南
API 参考
- Factory Methods - 从各种数据源创建 DataStore 的工厂方法
- Query Building - 类 SQL 风格的查询操作
- Pandas Compatibility - 全部 209 个与 pandas 兼容的方法
- Accessors - 字符串、DateTime、Array、JSON、URL、IP、Geo 访问器
- Aggregation - 聚合和窗口函数
- I/O Operations - 数据的输入/输出操作
高级主题
配置与调试
Pandas 使用指南
- Pandas Cookbook - 常用模式示例
- 关键差异 - 与 pandas 的重要区别
- 性能指南 - 优化建议
- 面向 Pandas 用户的 SQL - 理解 pandas 操作背后的 SQL
