Быстрый старт для Managed Postgres
ClickHouse Managed Postgres — это Postgres корпоративного уровня на базе NVMe-хранилища, обеспечивающий до 10 раз более высокую производительность для рабочих нагрузок, ограниченных дисковой подсистемой, по сравнению с сетевыми хранилищами, такими как EBS. Этот быстрый старт разделен на две части:
- Часть 1: Начните работу с NVMe Postgres и оцените его производительность
- Часть 2: Откройте возможности Real-time аналитики, интегрировав ClickHouse
Managed Postgres в настоящее время доступен в нескольких регионах AWS и бесплатен в течение периода закрытой предварительной версии.
В этом руководстве по быстрому старту вы:
- Создадите экземпляр Managed Postgres с производительностью на базе NVMe
- Загрузите 1 миллион тестовых событий и увидите скорость NVMe в действии
- Выполните запросы и оцените производительность с низкой задержкой
- Реплицируете данные в ClickHouse для Real-time аналитики
- Будете выполнять запросы к ClickHouse напрямую из Postgres с помощью
pg_clickhouse
Часть 1: Начало работы с NVMe Postgres
Создайте базу данных
Чтобы создать новый сервис Managed Postgres, нажмите кнопку New service в списке сервисов в Cloud Console. После этого вы сможете выбрать Postgres в качестве типа базы данных.
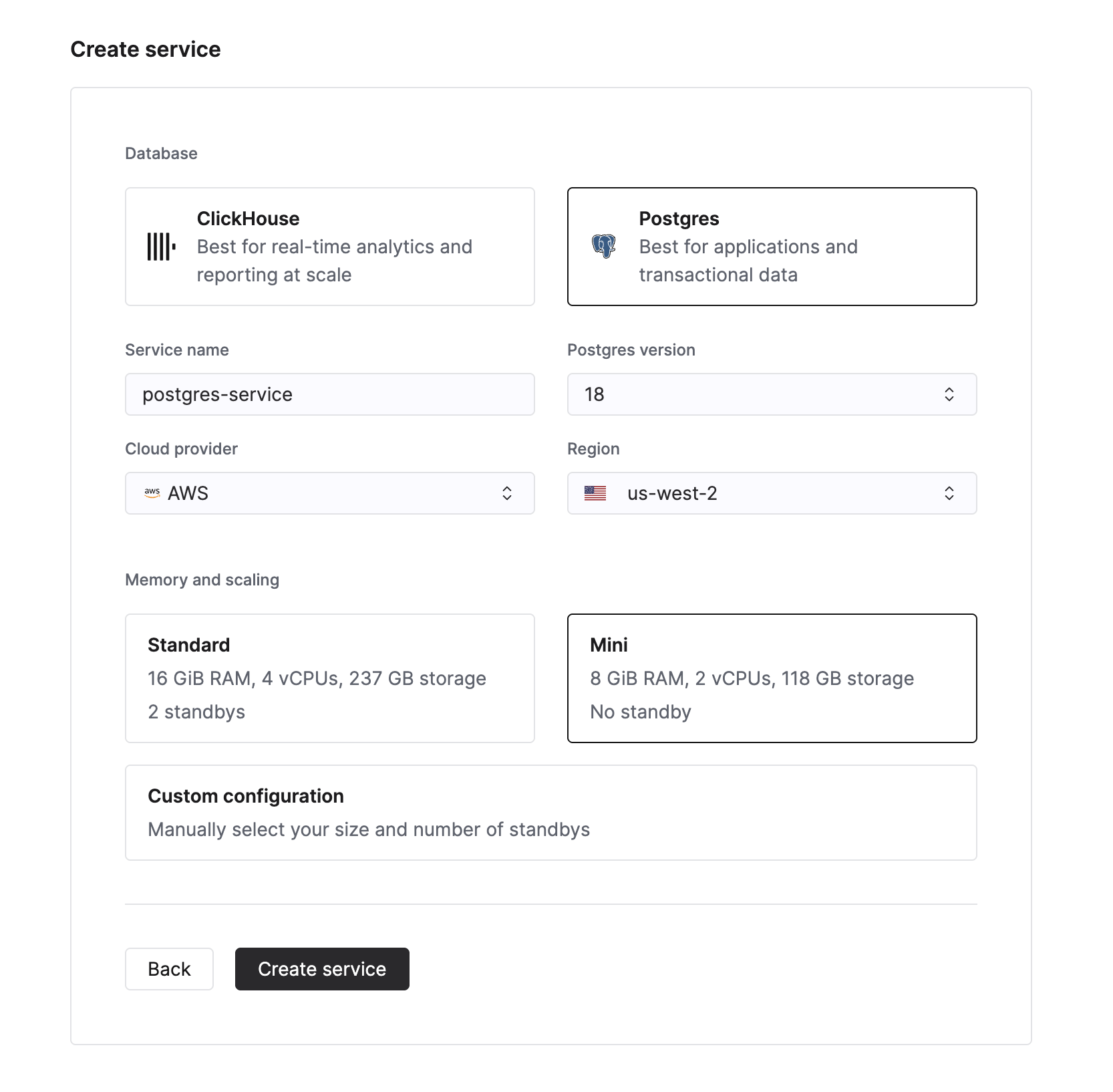
Введите имя экземпляра базы данных и нажмите Create service. Вы будете перенаправлены на страницу обзора.
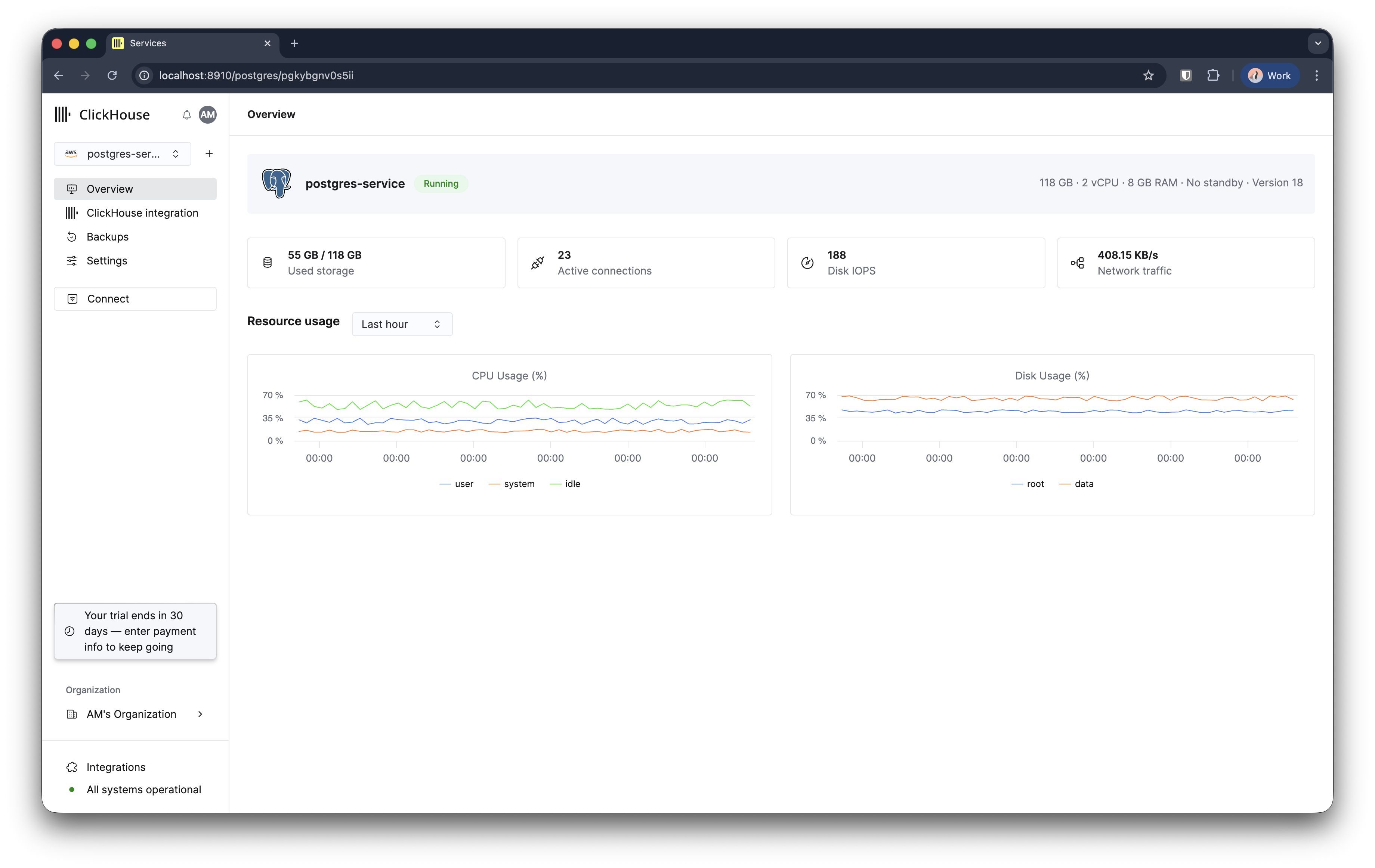
Ваш экземпляр Managed Postgres будет подготовлен и через 3–5 минут будет готов к использованию.
Подключитесь к базе данных
В левой боковой панели вы увидите кнопку Connect. Нажмите на неё, чтобы просмотреть параметры подключения и строки подключения в нескольких форматах.
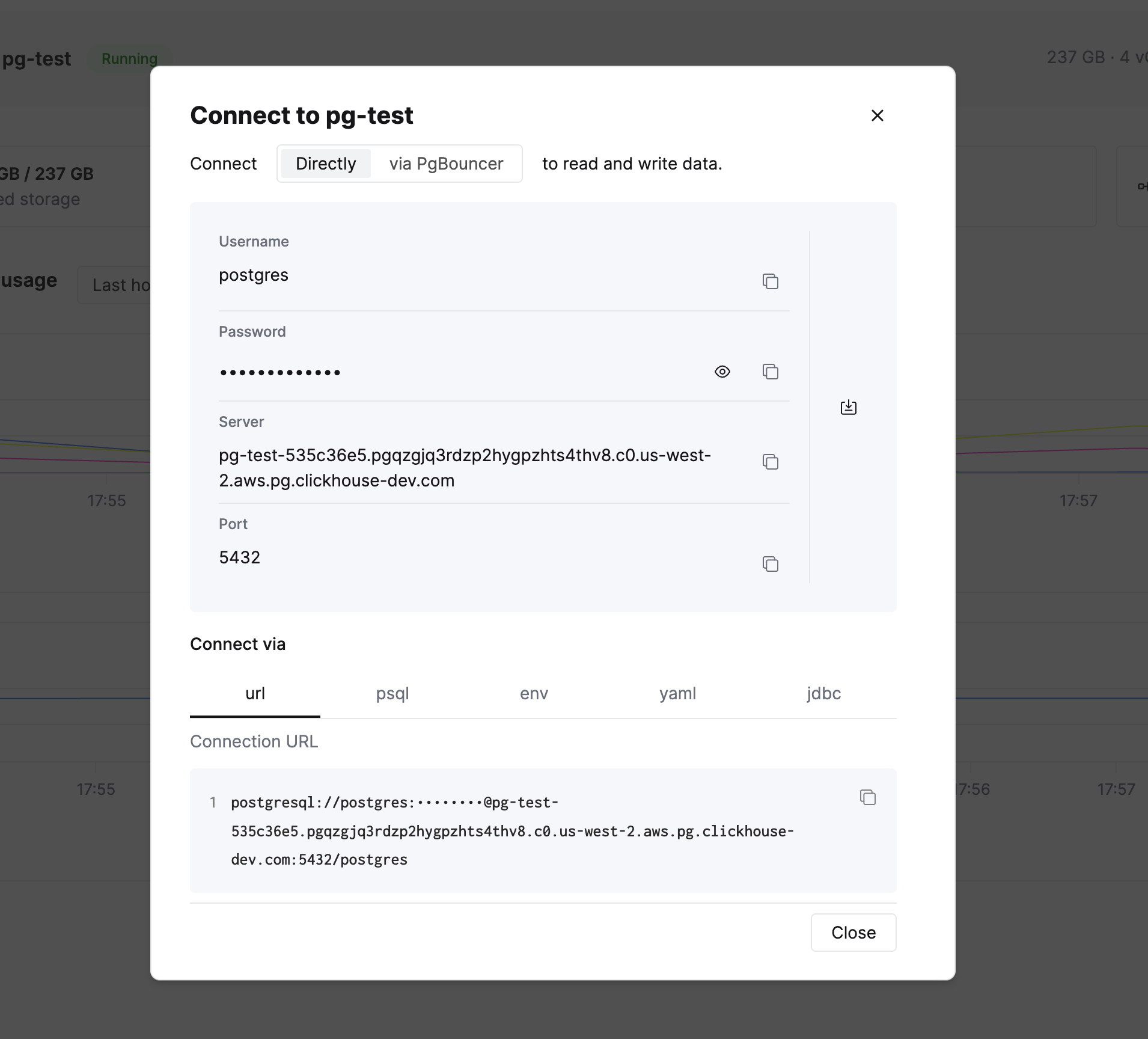
Скопируйте строку подключения для psql и подключитесь к базе данных. Вы также можете использовать любой клиент, совместимый с Postgres, например DBeaver или любую прикладную библиотеку.
Оцените производительность NVMe
Давайте посмотрим на производительность NVMe в реальной работе. Сначала включите вывод времени выполнения в psql, чтобы измерять время выполнения запросов:
Создайте две тестовые таблицы для событий и пользователей:
Теперь вставьте 1 миллион событий и оцените скорость NVMe:
1 миллион строк с данными JSONB был вставлен менее чем за 4 секунды. В традиционных облачных базах данных, использующих сетевое хранилище, такое как EBS, та же операция обычно занимает в 2–3 раза больше времени из-за сетевой задержки при двустороннем обмене (round-trip latency) и ограничения IOPS. NVMe-хранилище устраняет эти узкие места, так как хранилище физически подключено к вычислительным ресурсам.
Производительность зависит от размера экземпляра, текущей нагрузки и характеристик данных.
Вставьте 1 000 пользователей:
Выполнение запросов к данным
Теперь давайте выполним несколько запросов, чтобы увидеть, насколько быстро Postgres отвечает при использовании NVMe‑накопителя.
Выполните агрегацию 1 миллиона событий по типу:
Запрос с фильтрацией по JSONB и диапазону дат:
Свяжите события с пользователями:
На этом этапе у вас есть полностью работоспособная, высокопроизводительная база данных Postgres, готовая к обслуживанию транзакционных нагрузок.
Перейдите к Части 2, чтобы узнать, как нативная интеграция с ClickHouse может значительно ускорить вашу аналитику.
Часть 2: Добавление аналитики в реальном времени с помощью ClickHouse
Хотя Postgres отлично подходит для транзакционных нагрузок (OLTP), ClickHouse специально создан для аналитических запросов (OLAP) по большим наборам данных. Интегрируя эти системы, вы получаете лучшее из обоих миров:
- Postgres для транзакционных данных вашего приложения (операции insert, update, точечные выборки)
- ClickHouse для аналитики по миллиардам строк с задержкой менее секунды
В этом разделе показано, как реплицировать ваши данные из Postgres в ClickHouse и прозрачно выполнять по ним запросы.
Настройка интеграции с ClickHouse
Теперь, когда у нас есть таблицы и данные в Postgres, давайте реплицируем таблицы в ClickHouse для аналитики. Начните с нажатия ClickHouse integration в боковой панели. Затем нажмите Replicate data in ClickHouse.
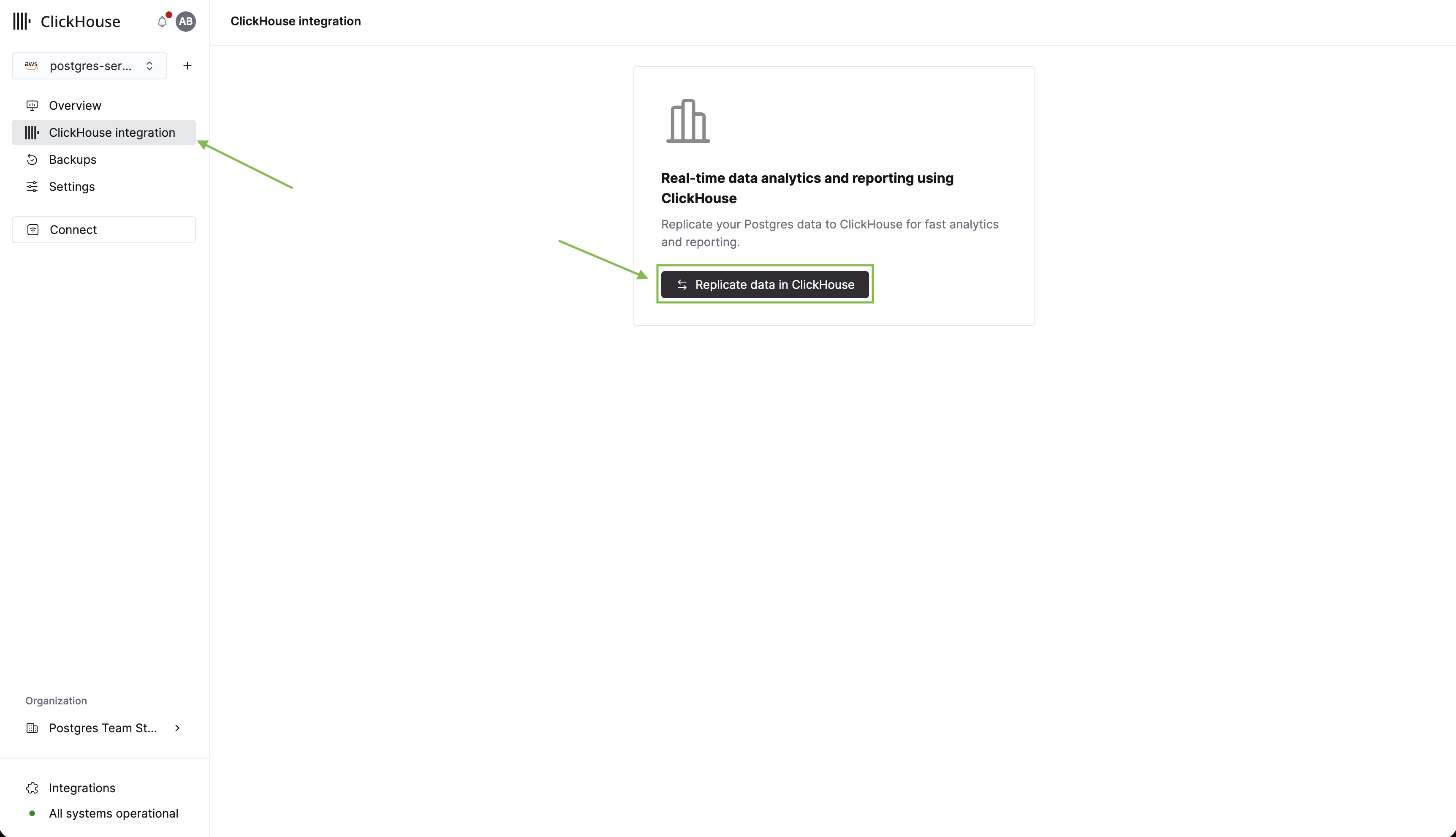
В появившейшейся форме вы можете задать имя интеграции и выбрать существующий экземпляр ClickHouse, в который будет выполняться репликация. Если у вас ещё нет экземпляра ClickHouse, вы можете создать его напрямую из этой формы.
Перед продолжением убедитесь, что выбранный сервис ClickHouse находится в состоянии Running.
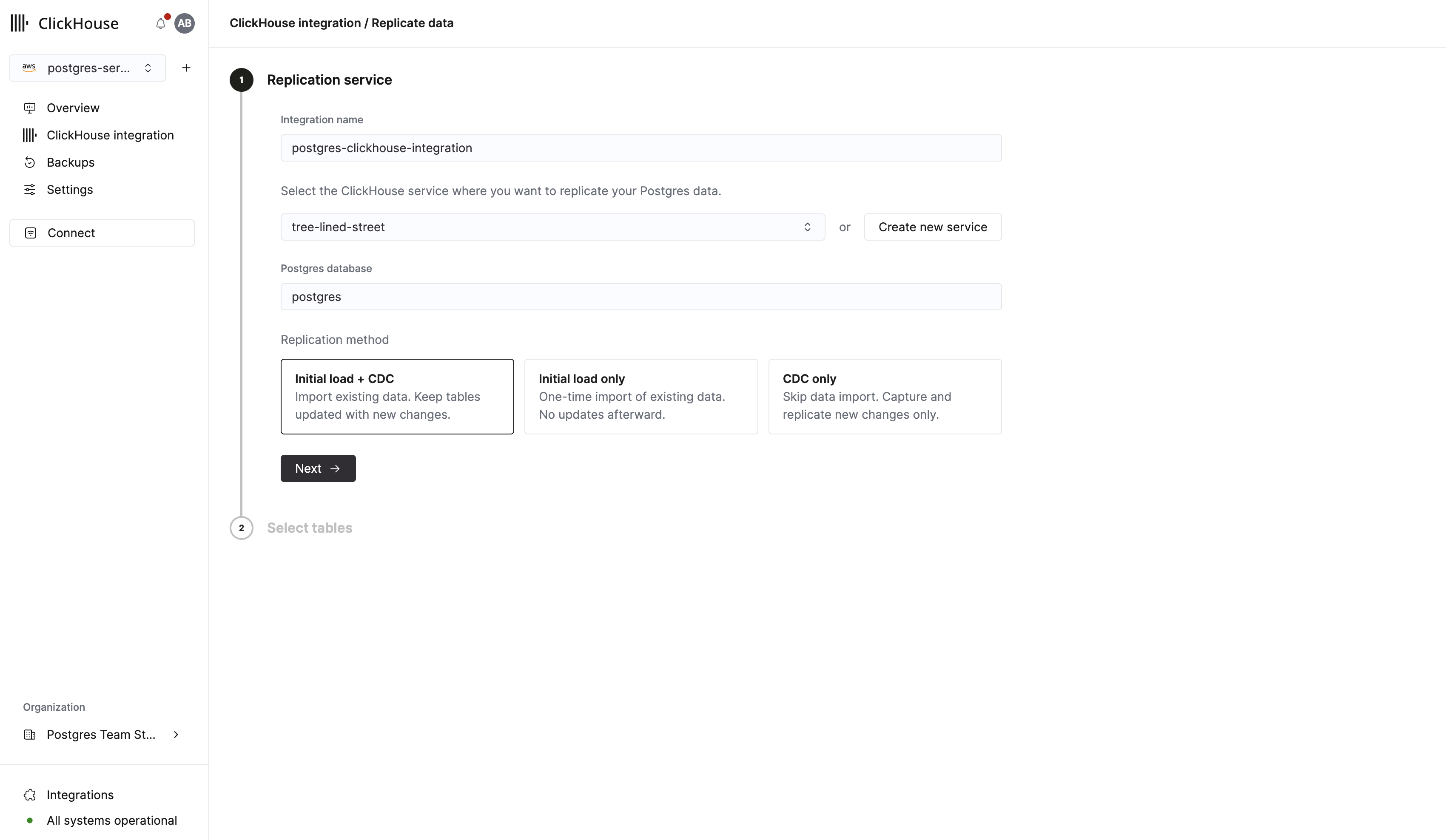
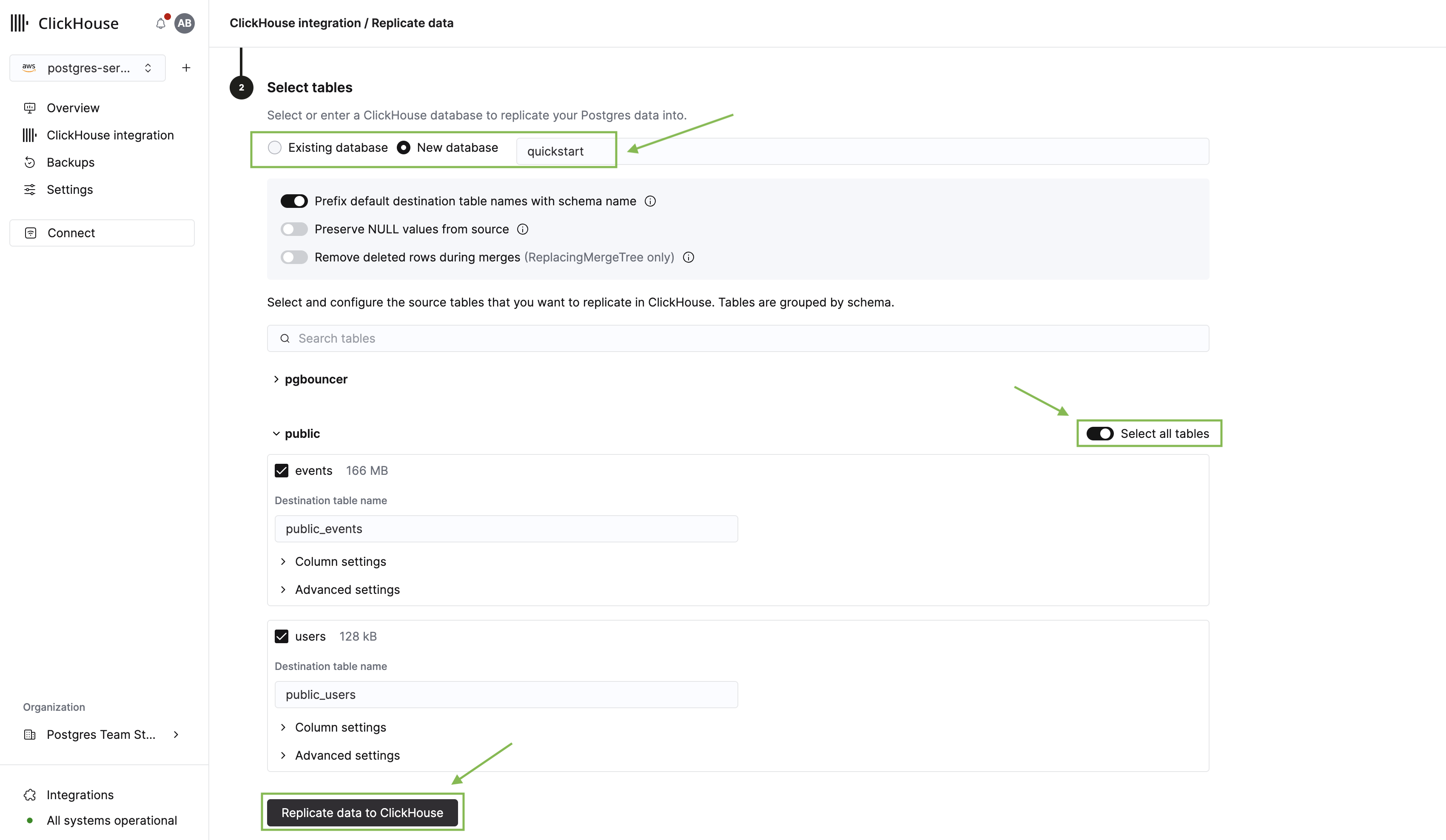
Нажмите Next, чтобы перейти к выбору таблиц. Здесь вам нужно:
- Выбрать базу данных ClickHouse, в которую будет выполняться репликация.
- Развернуть схему public и выбрать таблицы users и events, которые мы создали ранее.
- Нажать Replicate data to ClickHouse.
Процесс репликации запустится, и вы попадёте на страницу обзора интеграции. Поскольку это первая интеграция, настройка начальной инфраструктуры может занять 2–3 минуты. А пока давайте рассмотрим новое расширение pg_clickhouse.
Выполнение запросов к ClickHouse из Postgres
Расширение pg_clickhouse позволяет выполнять запросы к данным ClickHouse напрямую из Postgres, используя стандартный SQL. Это означает, что ваше приложение может использовать Postgres как единый слой для выполнения запросов как к транзакционным, так и к аналитическим данным. Подробности см. в полной документации.
Активируйте расширение:
Затем создайте подключение к внешнему серверу ClickHouse. Используйте драйвер http с портом 8443 для защищённых подключений:
Замените <clickhouse_cloud_host> на ваш хост ClickHouse и <database_name> на базу данных, которую вы выбрали при настройке репликации. Имя хоста можно найти в вашем сервисе ClickHouse, нажав Connect в боковой панели.
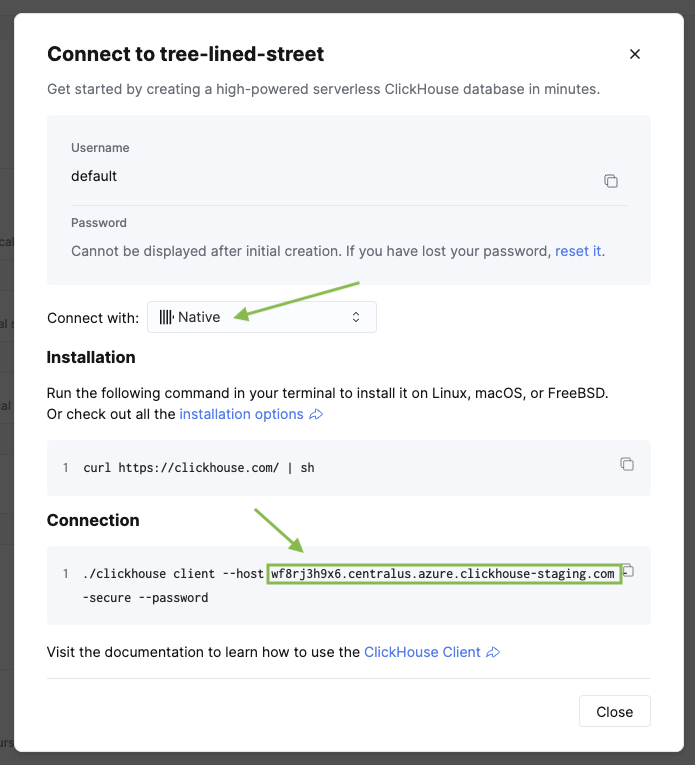
Теперь сопоставим пользователя Postgres с учётными данными сервиса ClickHouse:
Теперь импортируйте таблицы ClickHouse в схему Postgres:
Замените <database_name> тем же именем базы данных, которое вы использовали при создании сервера.
Теперь в клиенте Postgres отображаются все таблицы ClickHouse:
Посмотрите аналитику в действии
Вернёмся на страницу интеграции. Вы должны увидеть, что начальная репликация завершена. Нажмите на имя интеграции, чтобы просмотреть подробную информацию.

Нажмите на имя сервиса, чтобы открыть консоль ClickHouse и увидеть свои реплицированные таблицы.
Сравнение производительности Postgres и ClickHouse
Теперь запустим несколько аналитических запросов и сравним производительность Postgres и ClickHouse. Обратите внимание, что реплицированные таблицы используют схему именования public_<table_name>.
Запрос 1: Пользователи с наибольшей активностью
Этот запрос находит самых активных пользователей с несколькими агрегирующими функциями:
Запрос 2: вовлечённость пользователей по странам и платформам
Этот запрос соединяет события с пользователями и вычисляет метрики вовлечённости:
Сравнение производительности:
| Запрос | Postgres (NVMe) | ClickHouse (через pg_clickhouse) | Ускорение |
|---|---|---|---|
| Топ пользователей (5 агрегаций) | 555 ms | 164 ms | 3.4x |
| Вовлечённость пользователей (JOIN + агрегации) | 1,246 ms | 170 ms | 7.3x |
Даже на этом наборе данных объёмом 1M строк ClickHouse обеспечивает ускорение в 3–7 раз для сложных аналитических запросов с JOIN и множественными агрегациями. Разница становится ещё более существенной на больших объёмах (100M+ строк), где столбцовое хранение и векторизованное выполнение ClickHouse могут давать ускорение в 10–100 раз.
Время выполнения запросов зависит от размера экземпляра, сетевой задержки между сервисами, характеристик данных и текущей нагрузки.
Очистка
Чтобы удалить ресурсы, созданные в этом кратком руководстве:
- Сначала удалите интеграцию ClickPipe в сервисе ClickHouse
- Затем удалите экземпляр Managed Postgres в Cloud Console
