Primary indexes
This page introduces ClickHouse's sparse primary index, how it's built, how it works, and how it helps accelerate queries.
For advanced indexing strategies and deeper technical detail, see the primary indexes deep dive.
How does the sparse primary index work in ClickHouse?
The sparse primary index in ClickHouse helps efficiently identify granules—blocks of rows—that might contain data matching a query's condition on the table's primary key columns. In the next section, we explain how this index is constructed from the values in those columns.
Sparse primary index creation
To illustrate how the sparse primary index is built, we use the uk_price_paid_simple table along with some animations.
As a reminder, in our ① example table with the primary key (town, street), ② inserted data is ③ stored on disk, sorted by the primary key column values, and compressed, in separate files for each column:
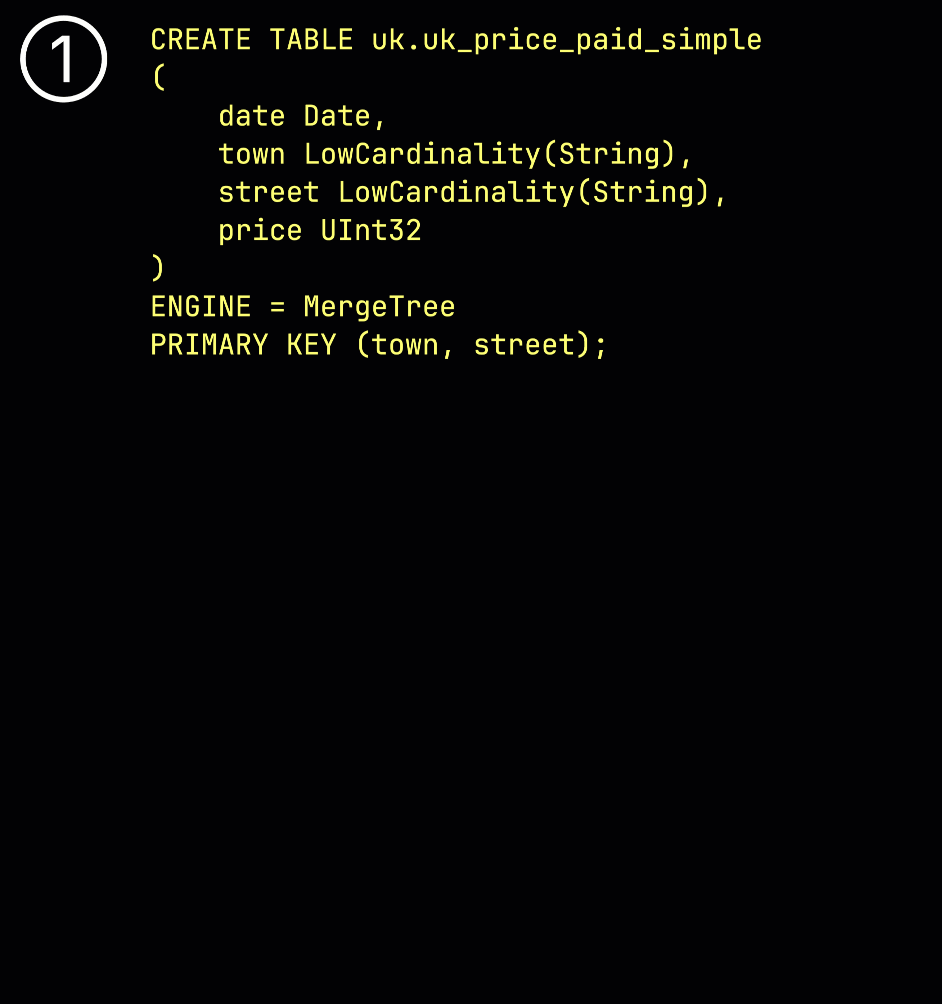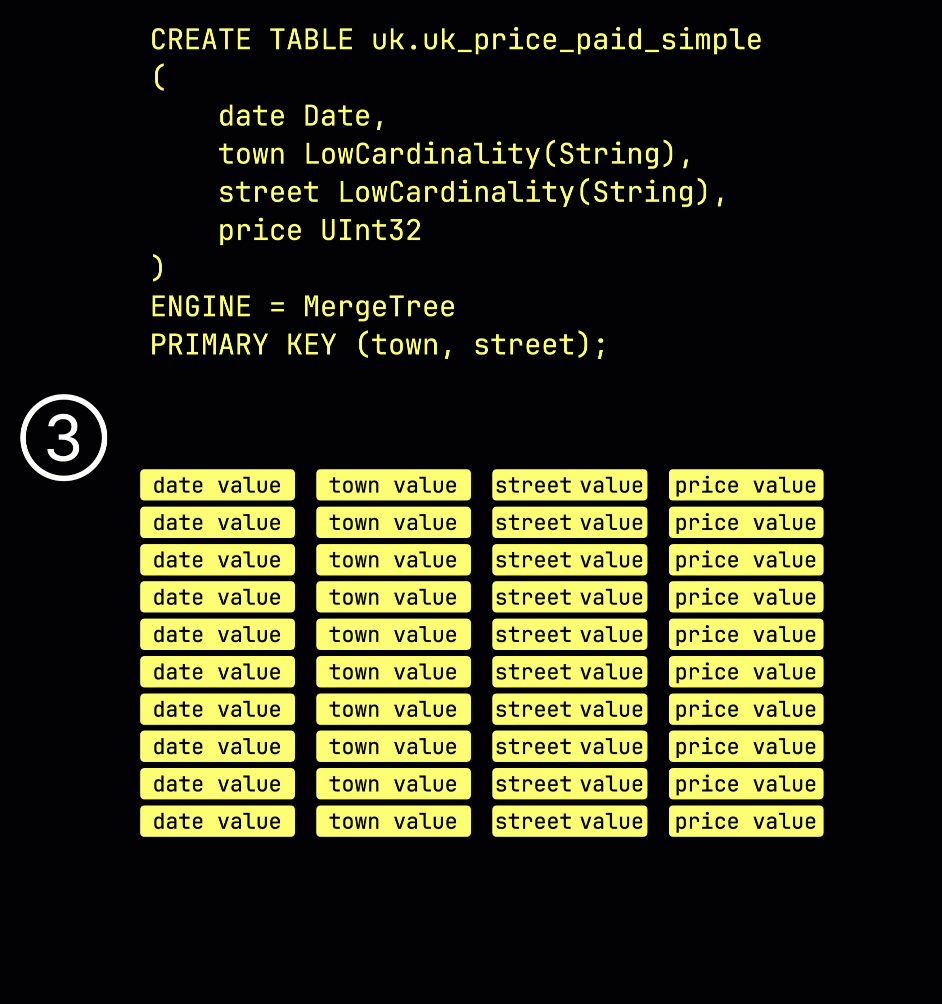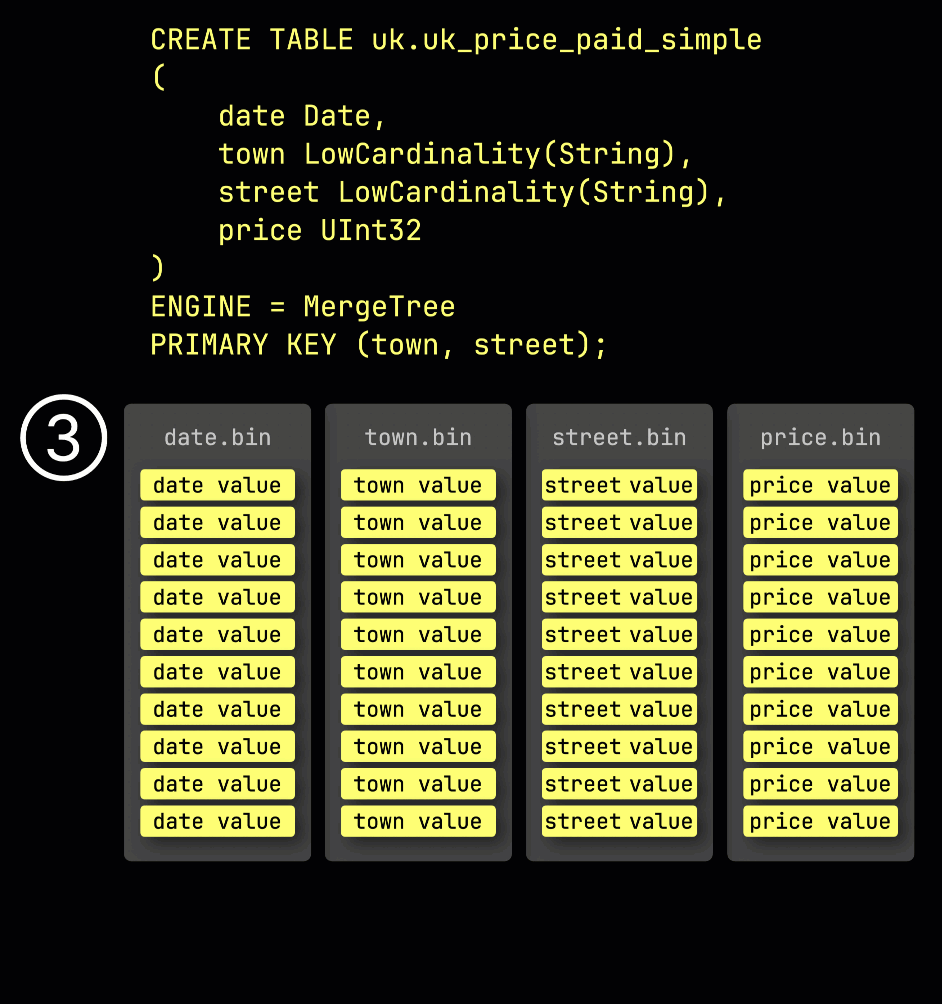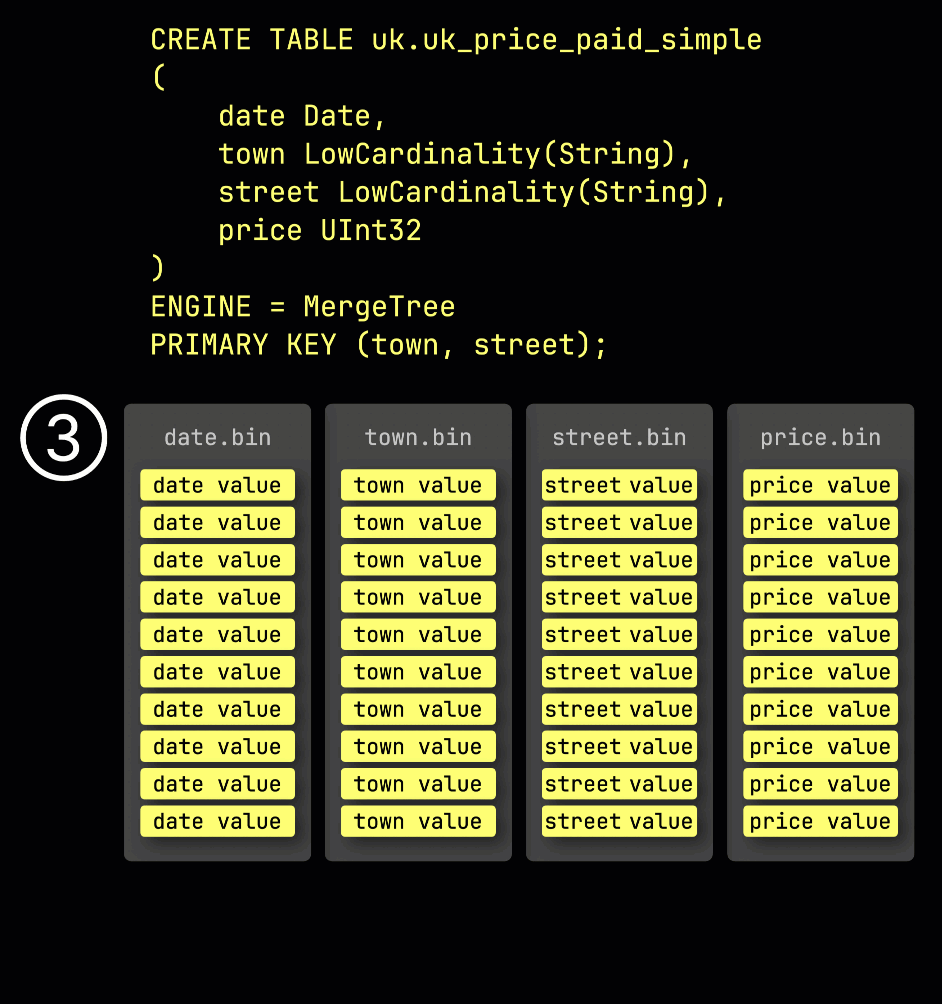
For processing, each column's data is ④ logically divided into granules—each covering 8,192 rows—which are the smallest units ClickHouse's data processing mechanics work with.
This granule structure is also what makes the primary index sparse: instead of indexing every row, ClickHouse stores ⑤ the primary key values from just one row per granule—specifically, the first row. This results in one index entry per granule:
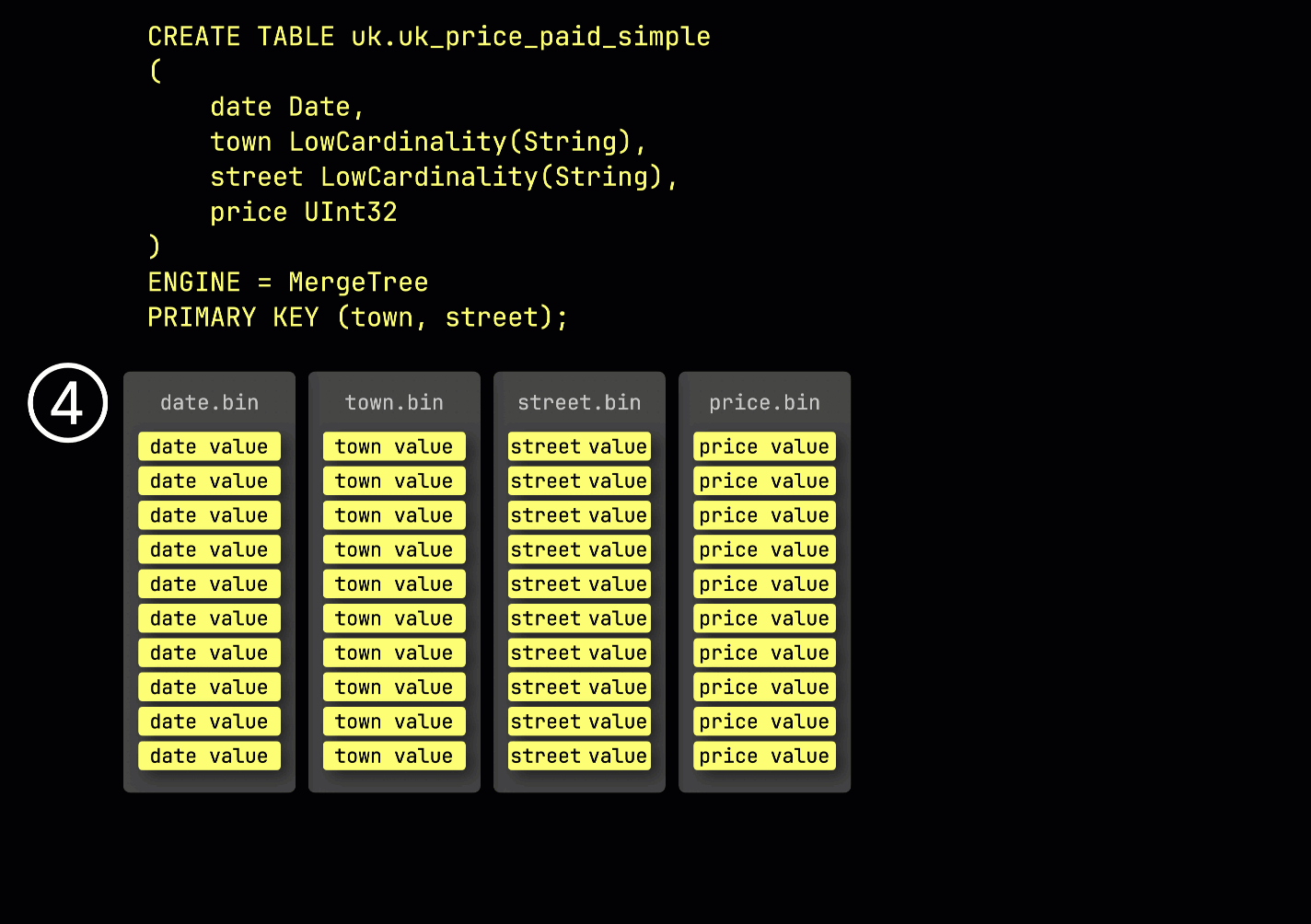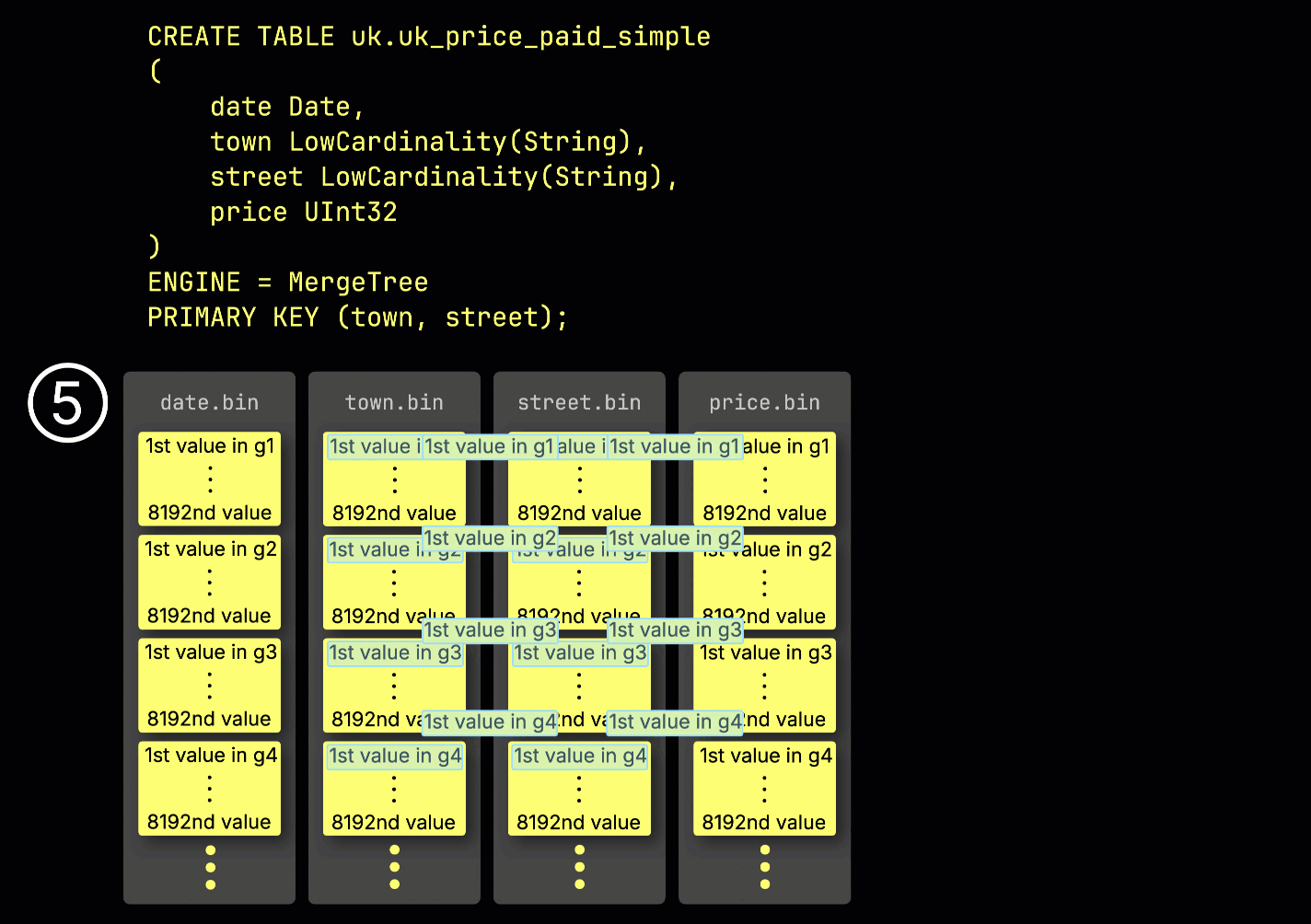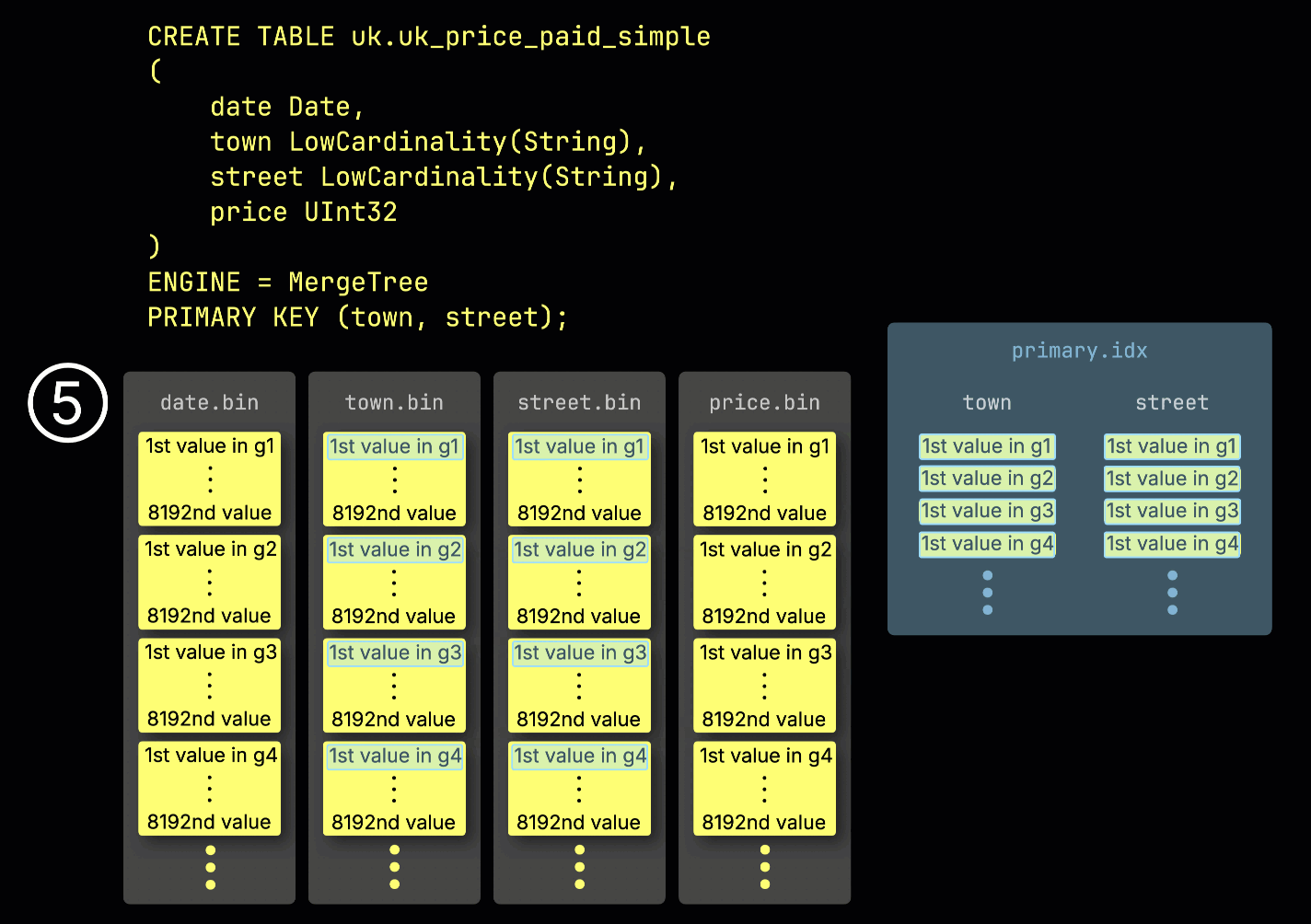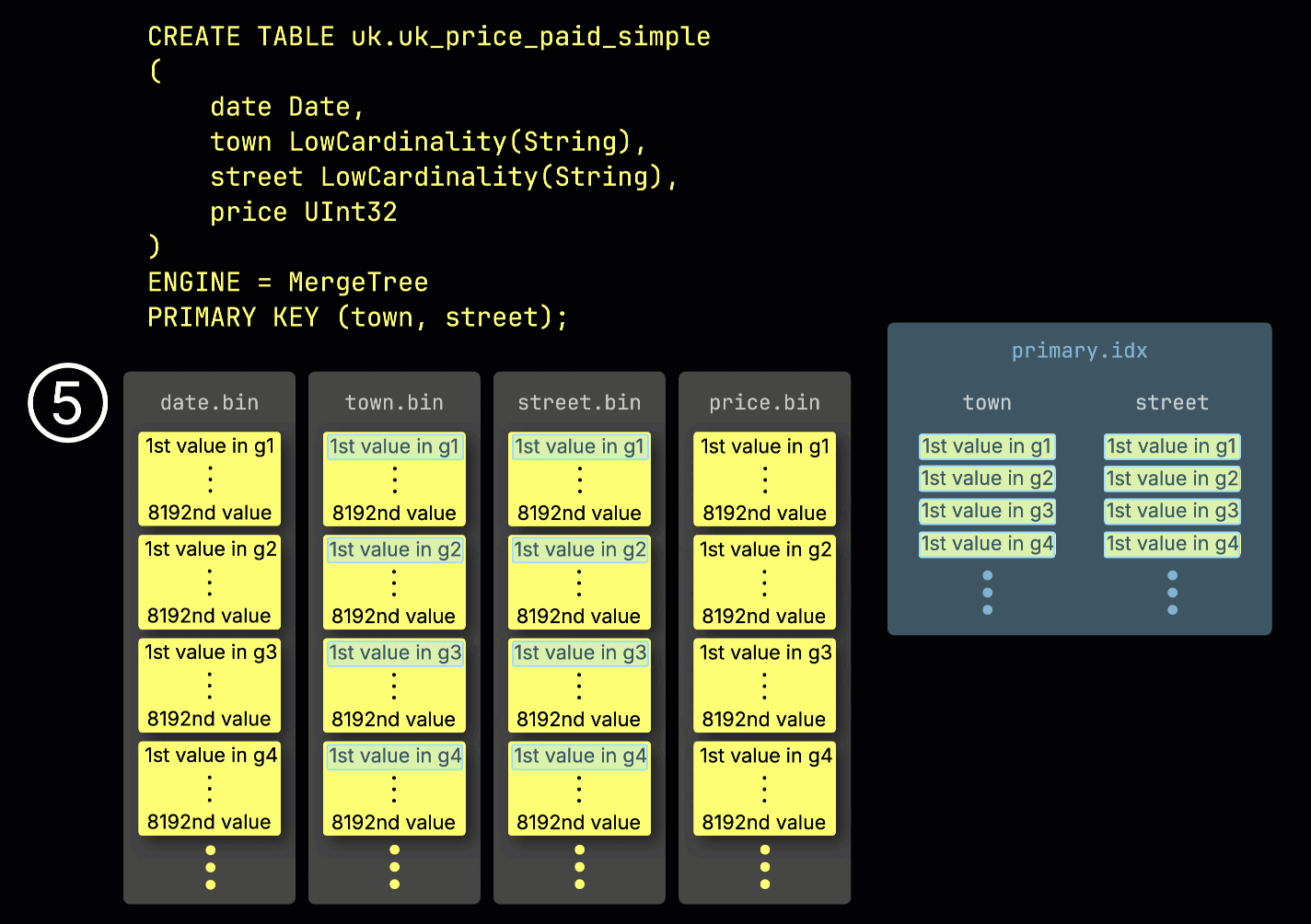
Thanks to its sparseness, the primary index is small enough to fit entirely in memory, enabling fast filtering for queries with predicates on primary key columns. In the next section, we show how it helps accelerate such queries.
Primary index usage
We sketch how the sparse primary index is used for query acceleration with another animation:
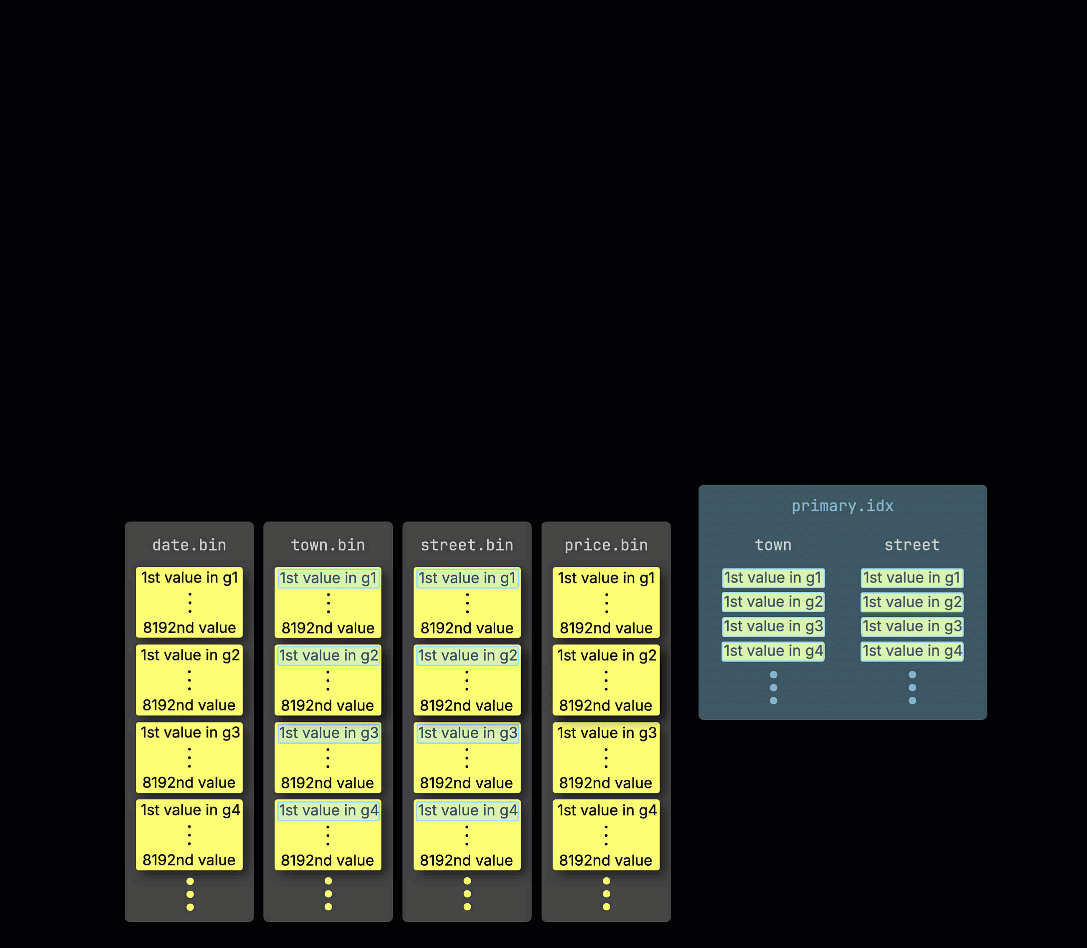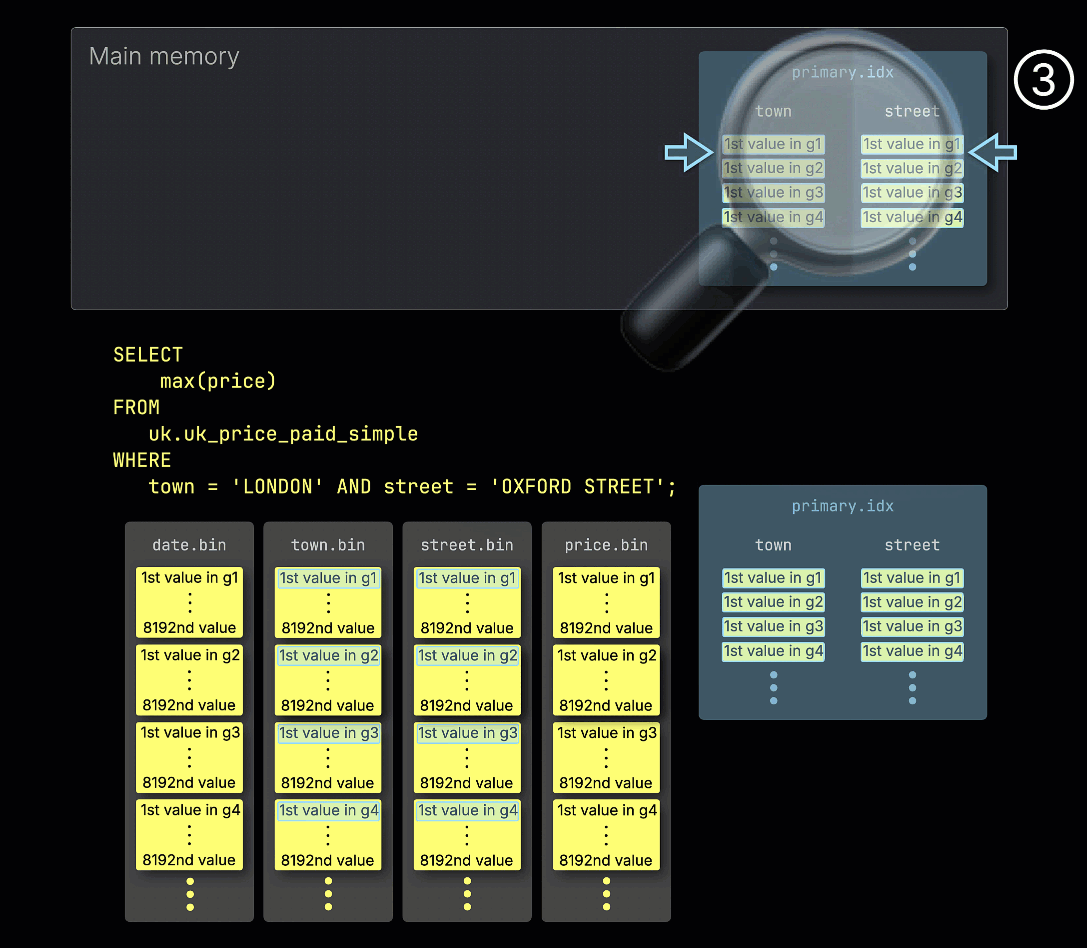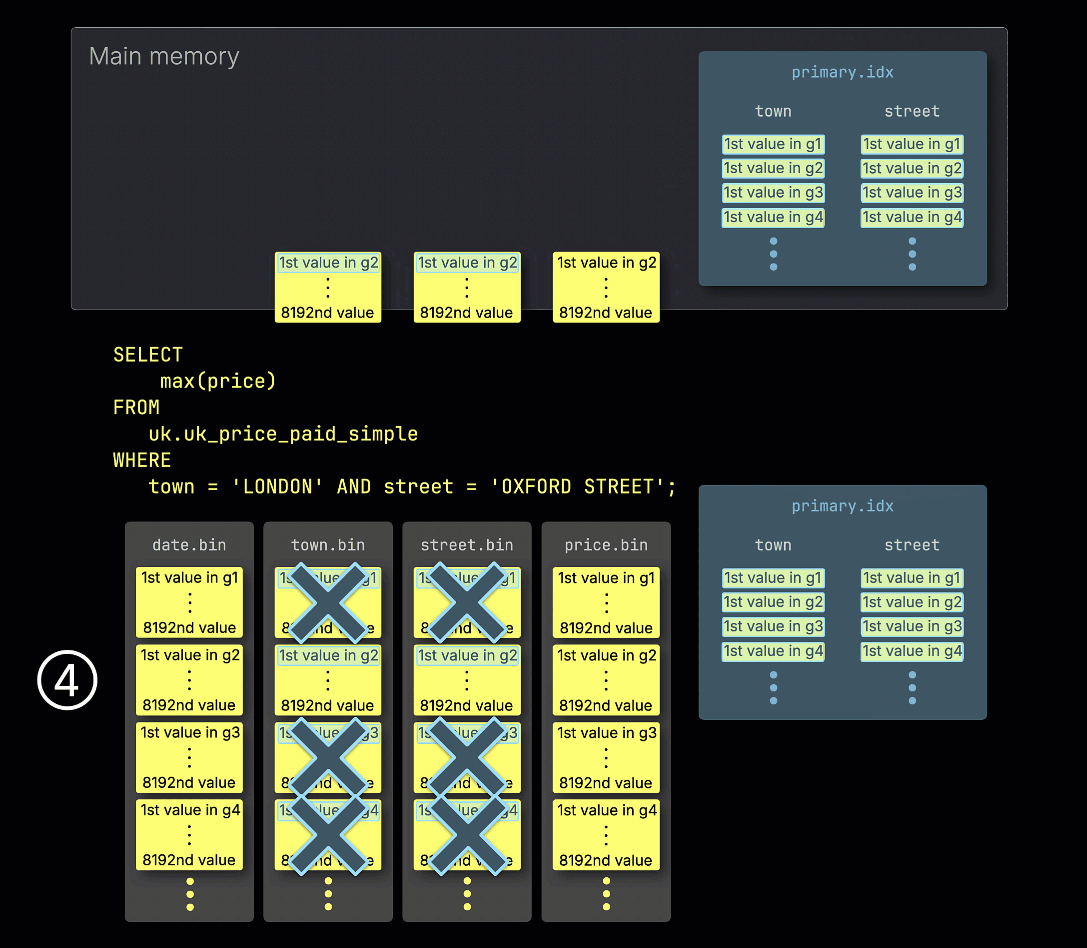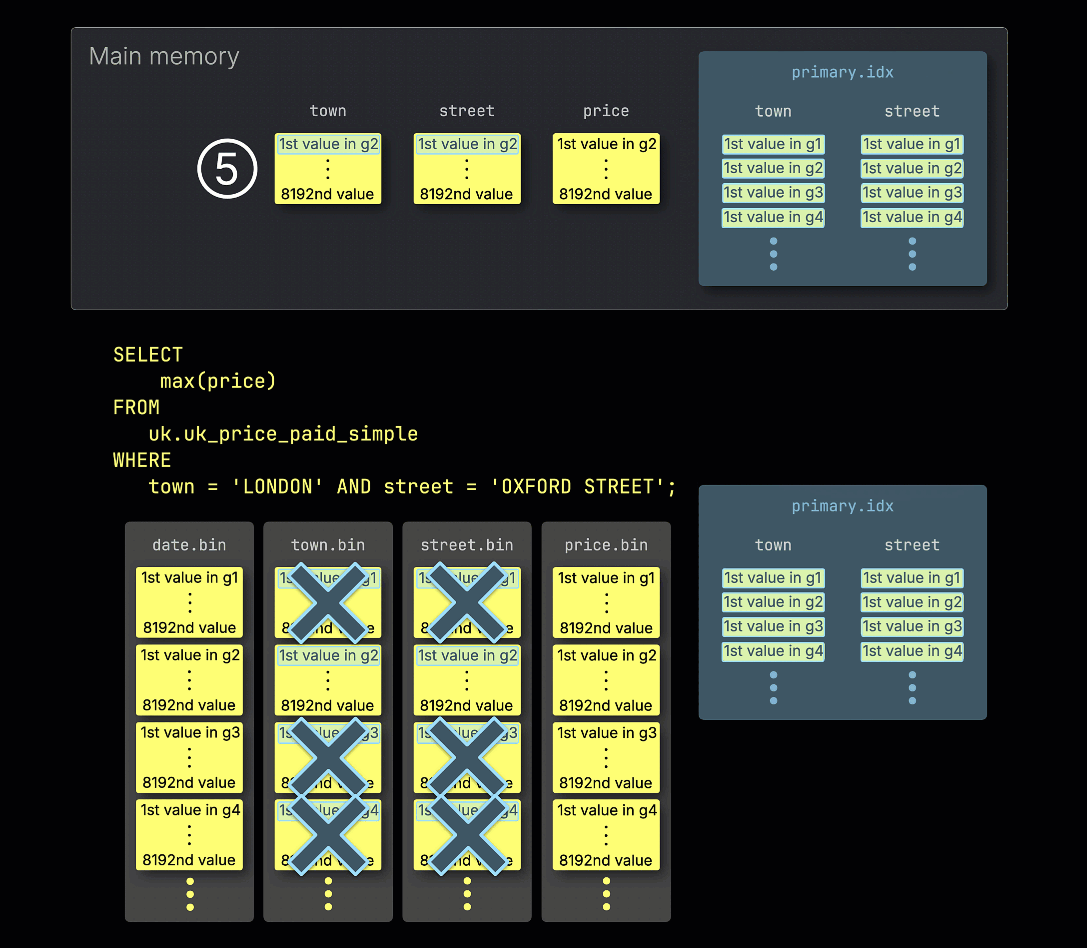
① The example query includes a predicate on both primary key columns: town = 'LONDON' AND street = 'OXFORD STREET'.
② To accelerate the query, ClickHouse loads the table's primary index into memory.
③ It then scans the index entries to identify which granules might contain rows matching the predicate—in other words, which granules can't be skipped.
④ These potentially relevant granules are then loaded and processed in memory, along with the corresponding granules from any other columns required for the query.
Monitoring primary indexes
Each data part in the table has its own primary index. We can inspect the contents of these indexes using the mergeTreeIndex table function.
The following query lists the number of entries in the primary index for each data part of our example table:
This query shows the first 10 entries from the primary index of one of the current data parts. Note that these parts are continuously merged in the background into larger parts:
Lastly, we use the EXPLAIN clause to see how the primary indexes of all data parts are used to skip granules that can't possibly contain rows matching the example query's predicates. These granules are excluded from loading and processing:
Note how row 13 of the EXPLAIN output above shows that only 3 out of 3,609 granules across all data parts were selected by the primary index analysis for processing. The remaining granules were skipped entirely.
We can also observe that most of the data was skipped by simply running the query:
As shown above, only around 25,000 rows were processed out of approximately 30 million rows in the example table:
Key takeaways
-
Sparse primary indexes help ClickHouse skip unnecessary data by identifying which granules might contain rows matching query conditions on primary key columns.
-
Each index stores only the primary key values from the first row of every granule (a granule has 8,192 rows by default), making it compact enough to fit in memory.
-
Each data part in a MergeTree table has its own primary index, which is used independently during query execution.
-
During queries, the index allows ClickHouse to skip granules, reducing I/O and memory usage while accelerating performance.
-
You can inspect index contents using the
mergeTreeIndextable function and monitor index usage with theEXPLAINclause.
Where to find more information
For a deeper look at how sparse primary indexes work in ClickHouse, including how they differ from traditional database indexes and best practices for using them, check out our detailed indexing deep dive.
If you're interested in how ClickHouse processes data selected by the primary index scan in a highly parallel way, see the query parallelism guide here.
