How does the PREWHERE optimization work?
The PREWHERE clause is a query execution optimization in ClickHouse. It reduces I/O and improves query speed by avoiding unnecessary data reads, and filtering out irrelevant data before reading non-filter columns from disk.
This guide explains how PREWHERE works, how to measure its impact, and how to tune it for best performance.
Query processing without PREWHERE optimization
We'll start by illustrating how a query on the uk_price_paid_simple table is processed without using PREWHERE:

① The query includes a filter on the town column, which is part of the table's primary key, and therefore also part of the primary index.
② To accelerate the query, ClickHouse loads the table's primary index into memory.
③ It scans the index entries to identify which granules from the town column might contain rows matching the predicate.
④ These potentially relevant granules are loaded into memory, along with positionally aligned granules from any other columns needed for the query.
⑤ The remaining filters are then applied during query execution.
As you can see, without PREWHERE, all potentially relevant columns are loaded before filtering, even if only a few rows actually match.
How PREWHERE improves query efficiency
The following animations show how the query from above is processed with a PREWHERE clause applied to all query predicates.
The first three processing steps are the same as before:

① The query includes a filter on the town column, which is part of the table's primary key—and therefore also part of the primary index.
② Similar to the run without the PREWHERE clause, to accelerate the query, ClickHouse loads the primary index into memory,
③ then scans the index entries to identify which granules from the town column might contain rows matching the predicate.
Now, thanks to the PREWHERE clause, the next step differs: Instead of reading all relevant columns up front, ClickHouse filters data column by column, only loading what's truly needed. This drastically reduces I/O, especially for wide tables.
With each step, it only loads granules that contain at least one row that survived—i.e., matched—the previous filter. As a result, the number of granules to load and evaluate for each filter decreases monotonically:
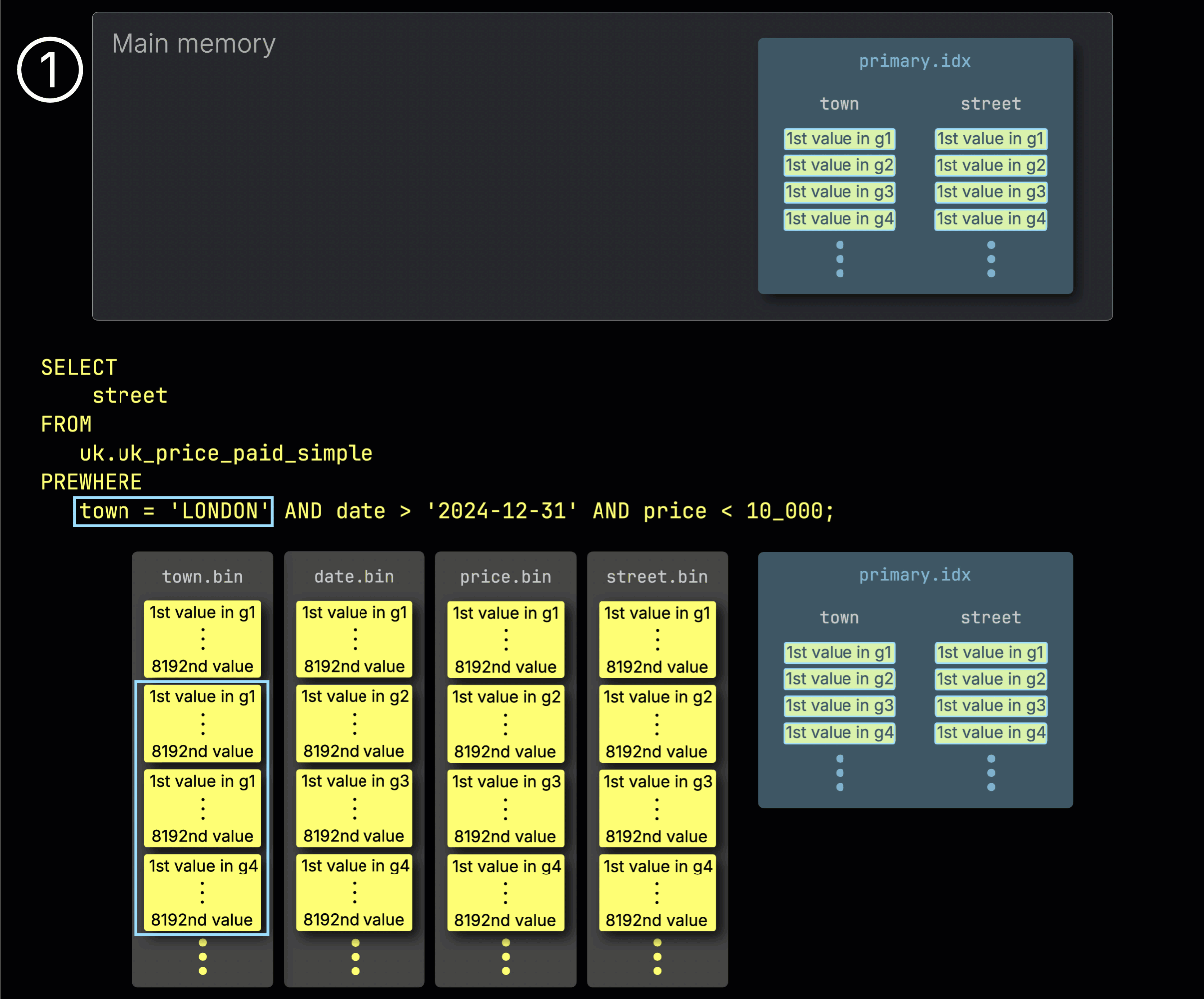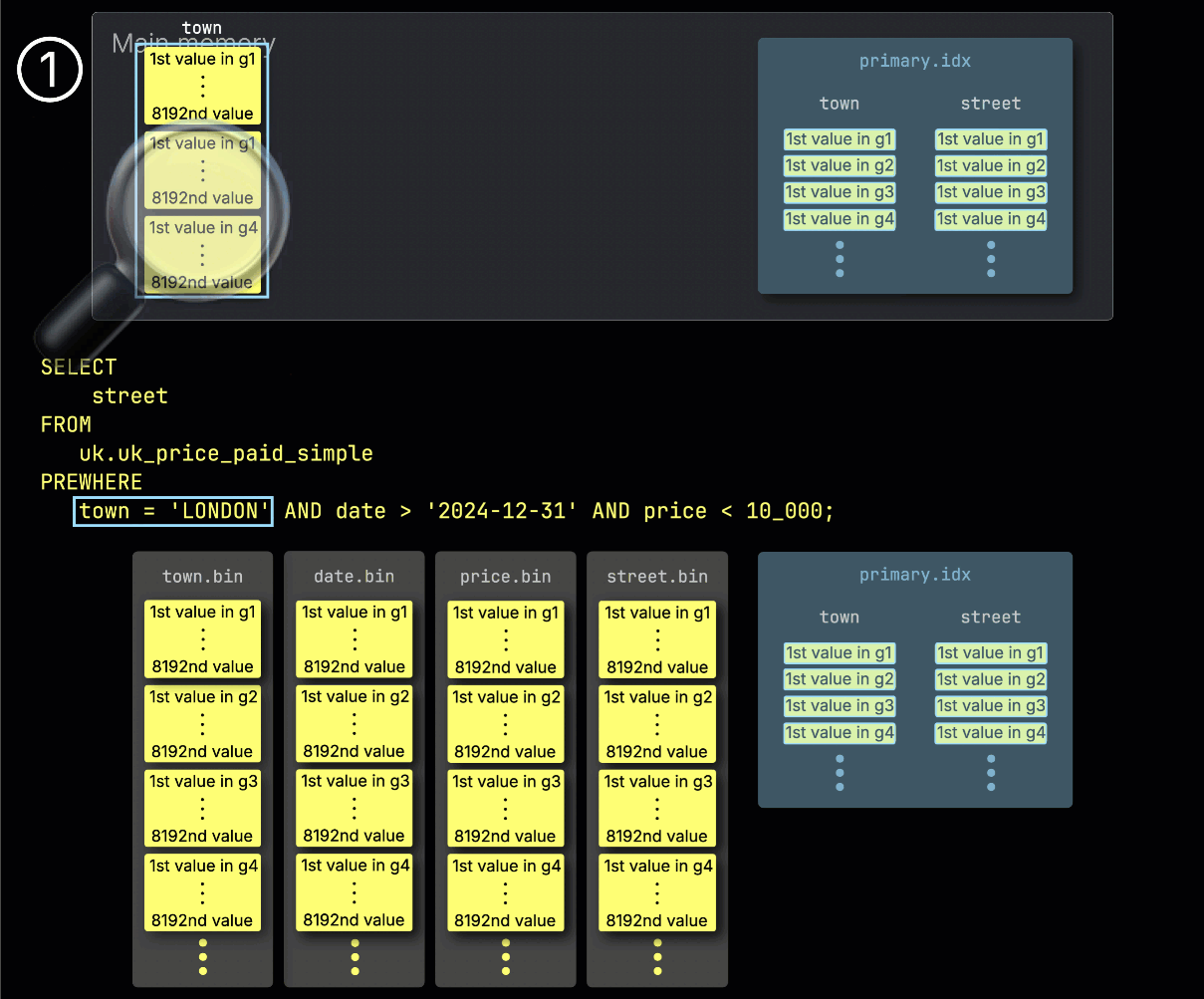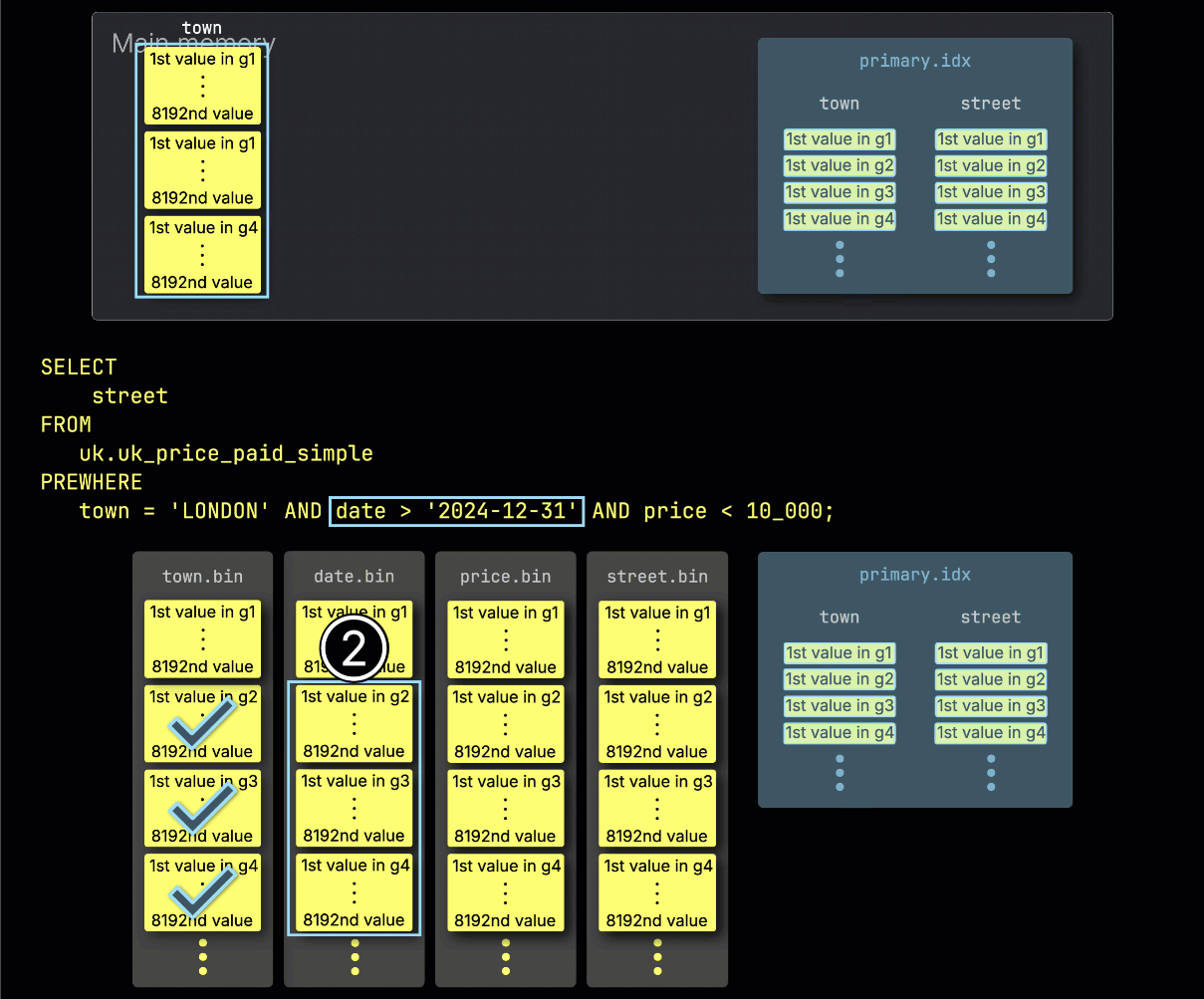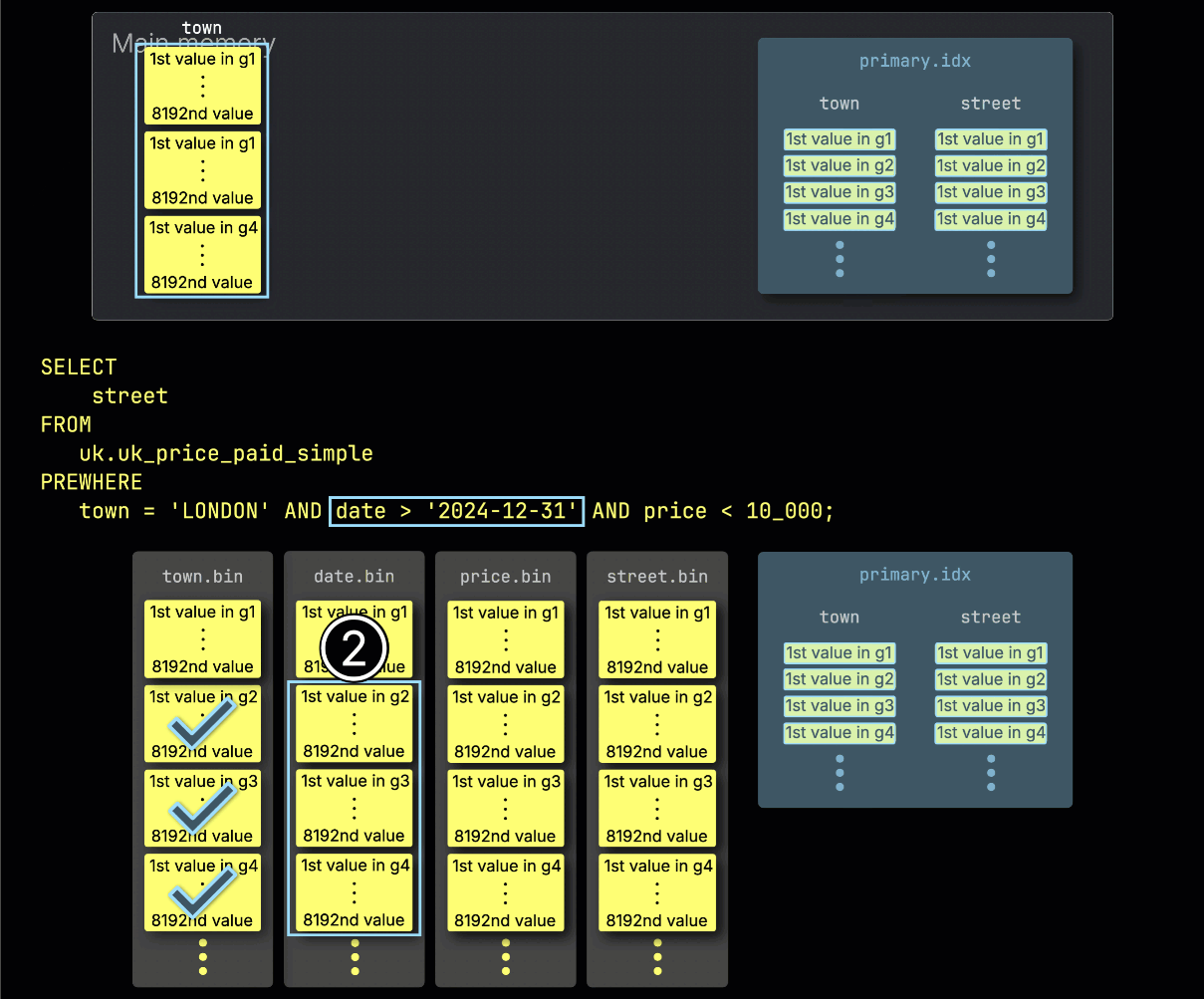
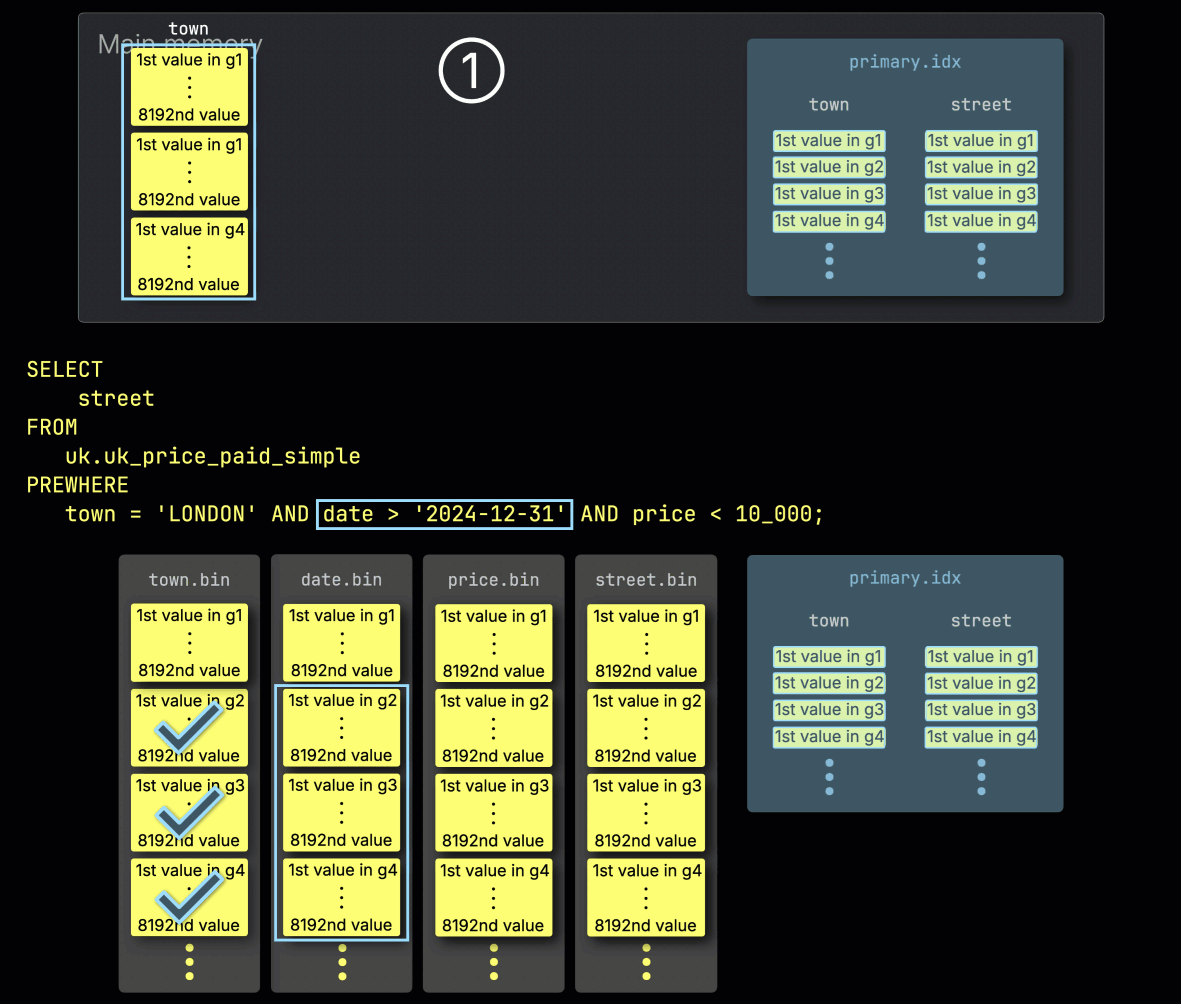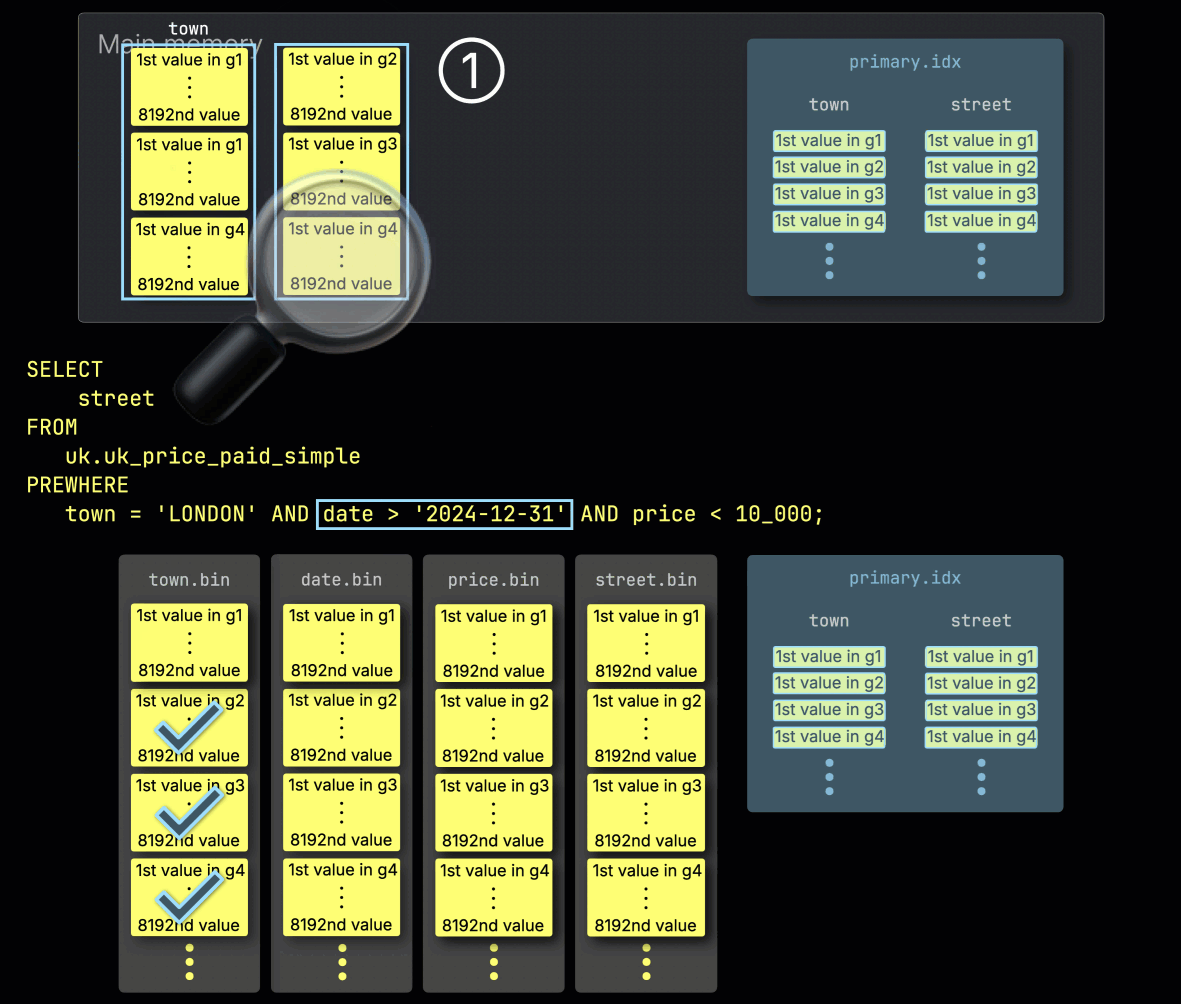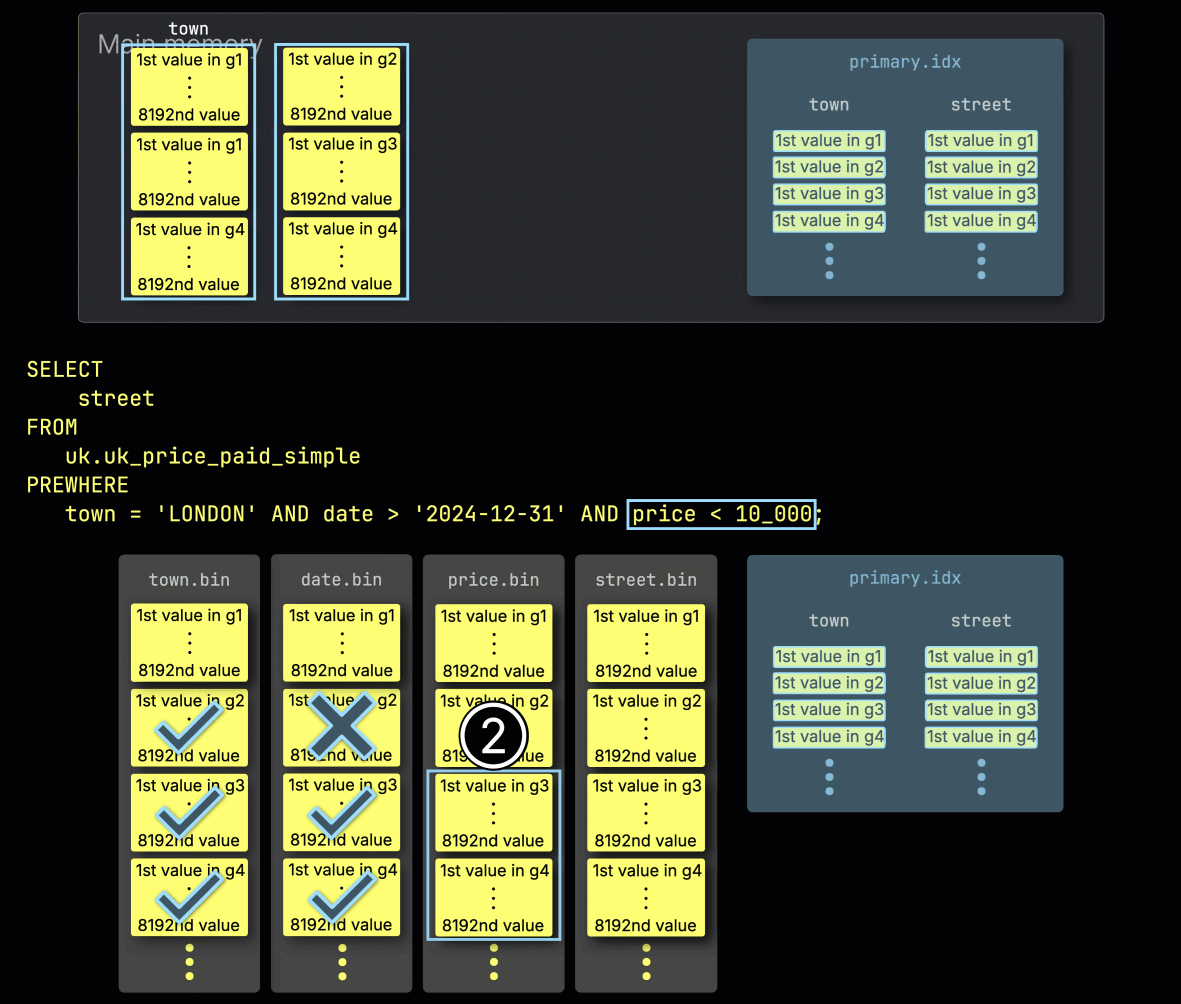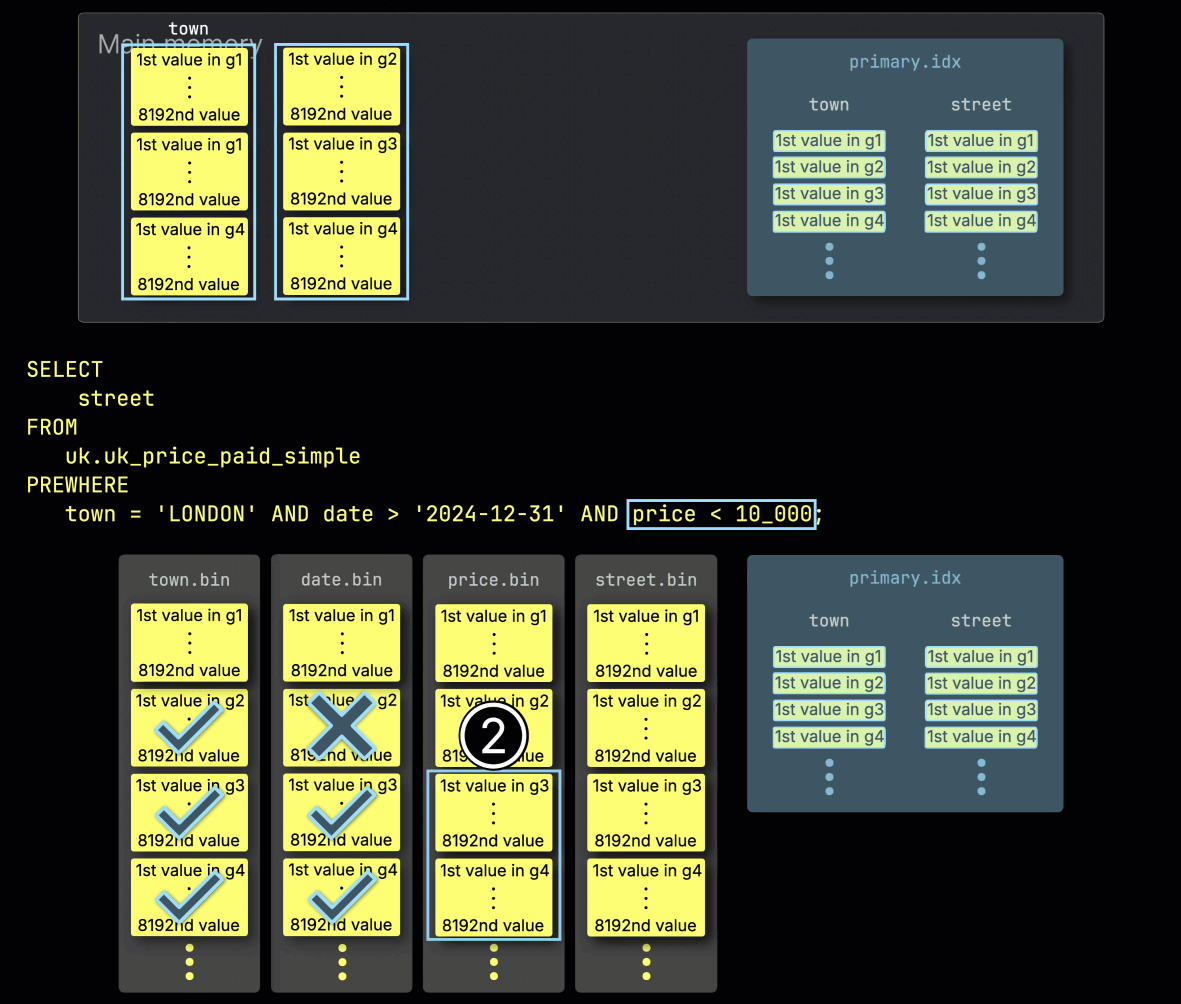
Step 1: Filtering by town
ClickHouse begins PREWHERE processing by ① reading the selected granules from the town column and checking which ones actually contain rows matching London.
In our example, all selected granules do match, so ② the corresponding positionally aligned granules for the next filter column—date—are then selected for processing:
Step 2: Filtering by date
Next, ClickHouse ① reads the selected date column granules to evaluate the filter date > '2024-12-31'.
In this case, two out of three granules contain matching rows, so ② only their positionally aligned granules from the next filter column—price—are selected for further processing:
Step 3: Filtering by price
Finally, ClickHouse ① reads the two selected granules from the price column to evaluate the last filter price > 10_000.
Only one of the two granules contains matching rows, so ② just its positionally aligned granule from the SELECT column—street—needs to be loaded for further processing:

By the final step, only the minimal set of column granules, those containing matching rows, are loaded. This leads to lower memory usage, less disk I/O, and faster query execution.
Note that ClickHouse processes the same number of rows in both the PREWHERE and non-PREWHERE versions of the query. However, with PREWHERE optimizations applied, not all column values need to be loaded for every processed row.
PREWHERE optimization is automatically applied
The PREWHERE clause can be added manually, as shown in the example above. However, you don't need to write PREWHERE manually. When the setting optimize_move_to_prewhere is enabled (true by default), ClickHouse automatically moves filter conditions from WHERE to PREWHERE, prioritizing those that will reduce read volume the most.
The idea is that smaller columns are faster to scan, and by the time larger columns are processed, most granules have already been filtered out. Since all columns have the same number of rows, a column's size is primarily determined by its data type, for example, a UInt8 column is generally much smaller than a String column.
ClickHouse follows this strategy by default as of version 23.2, sorting PREWHERE filter columns for multi-step processing in ascending order of uncompressed size.
Starting with version 23.11, optional column statistics can further improve this by choosing the filter processing order based on actual data selectivity, not just column size.
How to measure PREWHERE impact
To validate that PREWHERE is helping your queries, you can compare query performance with and without the optimize_move_to_prewhere setting enabled.
We begin by running the query with the optimize_move_to_prewhere setting disabled:
ClickHouse read 23.36 MB of column data while processing 2.31 million rows for the query.
Next, we run the query with the optimize_move_to_prewhere setting enabled. (Note that this setting is optional, as the setting is enabled by default):
The same number of rows was processed (2.31 million), but thanks to PREWHERE, ClickHouse read over three times less column data—just 6.74 MB instead of 23.36 MB—which cut the total runtime by a factor of 3.
For deeper insight into how ClickHouse applies PREWHERE behind the scenes, use EXPLAIN and trace logs.
We inspect the query's logical plan using the EXPLAIN clause:
We omit most of the plan output here, as it's quite verbose. In essence, it shows that all three column predicates were automatically moved to PREWHERE.
When reproducing this yourself, you'll also see in the query plan that the order of these predicates is based on the columns' data type sizes. Since we haven't enabled column statistics, ClickHouse uses size as the fallback for determining the PREWHERE processing order.
If you want to go even further under the hood, you can observe each individual PREWHERE processing step by instructing ClickHouse to return all test-level log entries during query execution:
Key takeaways
- PREWHERE avoids reading column data that will later be filtered out, saving I/O and memory.
- It works automatically when
optimize_move_to_prewhereis enabled (default). - Filtering order matters: small and selective columns should go first.
- Use
EXPLAINand logs to verify PREWHERE is applied and understand its effect. - PREWHERE is most impactful on wide tables and large scans with selective filters.
