以下の理由から、ログおよびトレース用の独自スキーマを常に作成することを推奨します。
- プライマリキーの選択 - デフォルトスキーマは、特定のアクセスパターン向けに最適化された
ORDER BY を使用しています。あなたのアクセスパターンがこれと一致する可能性は低いでしょう。
- 構造の抽出 - 既存のカラム、たとえば
Body カラムから新しいカラムを抽出したくなる場合があります。これは マテリアライズドカラム (および、より複雑なケースでは materialized views) を使用することで実現できます。このためにはスキーマ変更が必要です。
- マップの最適化 - デフォルトスキーマでは、属性の保存に マップ 型を使用しています。これらのカラムは任意のメタデータを保存できます。イベントからのメタデータは事前に定義されないことが多く、そのため ClickHouse のような強い型付けのデータベースでは他の方法で保存できないため、これは重要な機能です。一方で、マップ のキーおよびその値へのアクセスは、通常のカラムへのアクセスほど効率的ではありません。この問題には、スキーマを変更し、もっとも頻繁にアクセスされる マップ のキーをトップレベルのカラムとして定義することで対処します。詳しくは "Extracting structure with SQL" を参照してください。これにはスキーマ変更が必要です。
- マップ キーアクセスの簡素化 - マップ 内のキーにアクセスするには、より冗長な構文が必要です。これはエイリアスを使用することで軽減できます。クエリを簡略化するには "Using Aliases" を参照してください。
- セカンダリインデックス - デフォルトスキーマでは、マップ へのアクセスを高速化し、テキストクエリを高速化するためにセカンダリインデックスを使用しています。これらは通常必須ではなく、追加のディスク容量を消費します。利用は可能ですが、本当に必要かどうかを確認するためにテストすべきです。"Secondary / Data Skipping indices" を参照してください。
- Codec の利用 - 想定されるデータの特性を理解しており、その結果として圧縮率が向上することを確認できている場合は、カラムごとに codec をカスタマイズしたくなることがあります。
上記の各ユースケースについて、以下で詳細に説明します。
重要: ユーザーは最適な圧縮率とクエリ性能を得るためにスキーマを拡張および変更することが推奨されますが、可能な限りコアカラムについては OTel のスキーマ命名に従うべきです。ClickHouse Grafana プラグインは、クエリ作成を支援するために、Timestamp や SeverityText など、いくつかの基本的な OTel カラムが存在することを前提としています。ログおよびトレースに必要なカラムは、それぞれ [1][2] および こちら に記載されています。これらのカラム名は、プラグイン設定でデフォルト値を上書きすることで変更することもできます。
構造化ログ・非構造化ログのいずれを取り込む場合でも、次のような機能が必要になることがよくあります。
- 文字列の BLOB からカラムを抽出する。これらに対してクエリを実行する方が、クエリ時に文字列操作を行うよりも高速です。
- マップからキーを抽出する。デフォルトのスキーマでは、任意の属性は Map 型のカラムに格納されます。この型はスキーマレスな機能を提供し、ユーザーがログやトレースを定義する際に属性用のカラムを事前定義する必要がないという利点があります。特に、Kubernetes からログを収集し、後で検索できるようにポッドラベルを保持したい場合には、事前定義はほとんど不可能です。マップのキーとその値へアクセスするのは、通常の ClickHouse カラムに対するクエリよりも遅くなります。そのため、マップからキーを抽出してルートテーブルのカラムに展開することが望まれるケースがよくあります。
次のクエリを考えてみます。
構造化ログを使用して、どの URL パスが最も多くの POST リクエストを受け取っているかをカウントしたいとします。JSON BLOB は Body カラム内に String として保存されています。さらに、ユーザーがコレクターで json_parser を有効にしている場合、LogAttributes カラム内に Map(String, String) としても保存されている可能性があります。
SELECT LogAttributes
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
LogAttributes: {'status':'200','log.file.name':'access-structured.log','request_protocol':'HTTP/1.1','run_time':'0','time_local':'2019-01-22 00:26:14.000','size':'30577','user_agent':'Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)','referer':'-','remote_user':'-','request_type':'GET','request_path':'/filter/27|13 ,27| 5 ,p53','remote_addr':'54.36.149.41'}
LogAttributes が利用可能な場合、サイト上でどの URL パスが最も多くの POST リクエストを受けているかをカウントするクエリは次のとおりです:
SELECT path(LogAttributes['request_path']) AS path, count() AS c
FROM otel_logs
WHERE ((LogAttributes['request_type']) = 'POST')
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productModelImages │ 10866 │
│ /site/productAdditives │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.735 sec. Processed 10.36 million rows, 4.65 GB (14.10 million rows/s., 6.32 GB/s.)
Peak memory usage: 153.71 MiB.
ここでの map 構文の使い方、例えば LogAttributes['request_path']、および URL からクエリパラメータを取り除くための path 関数 に注目してください。
ユーザーがコレクター側で JSON 解析を有効化していない場合、LogAttributes は空になり、String 型の Body からカラムを抽出するために JSON 関数 を使用せざるを得なくなります。
JSON の解析には ClickHouse を推奨
一般的に、構造化ログの JSON 解析は ClickHouse 上で実行することを推奨します。ClickHouse が最速の JSON 解析実装であると自負しています。ただし、ログを他の保存先にも送信したい場合や、このロジックを SQL 内に持たせたくない場合があることも認識しています。
SELECT path(JSONExtractString(Body, 'request_path')) AS path, count() AS c
FROM otel_logs
WHERE JSONExtractString(Body, 'request_type') = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.668 sec. Processed 10.37 million rows, 5.13 GB (15.52 million rows/s., 7.68 GB/s.)
Peak memory usage: 172.30 MiB.
では、同じことを非構造化ログについても考えてみましょう。
SELECT Body, LogAttributes
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: 151.233.185.144 - - [22/Jan/2019:19:08:54 +0330] "GET /image/105/brand HTTP/1.1" 200 2653 "https://www.zanbil.ir/filter/b43,p56" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36" "-"
LogAttributes: {'log.file.name':'access-unstructured.log'}
非構造化ログに対して同様のクエリを実行するには、extractAllGroupsVertical 関数を使って正規表現を用いる必要があります。
SELECT
path((groups[1])[2]) AS path,
count() AS c
FROM
(
SELECT extractAllGroupsVertical(Body, '(\\w+)\\s([^\\s]+)\\sHTTP/\\d\\.\\d') AS groups
FROM otel_logs
WHERE ((groups[1])[1]) = 'POST'
)
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productModelImages │ 10866 │
│ /site/productAdditives │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 1.953 sec. Processed 10.37 million rows, 3.59 GB (5.31 million rows/s., 1.84 GB/s.)
非構造化ログをパースするクエリは複雑になりコストも高くなるため(パフォーマンス差に注意)、可能な限り構造化ログを使用することを推奨します。
これら 2 つのユースケースは、上記のクエリロジックを挿入時に移すことで、ClickHouse を使用してどちらも満たすことができます。以下では、いくつかのアプローチを取り上げ、それぞれが適切となる状況を説明します。
処理は OTel か ClickHouse か?
こちら で説明されているように、OTel Collector の processor や operator を使用して処理を実行することもできます。多くの場合、ClickHouse は Collector の processor よりもはるかにリソース効率が高く、高速であることが分かるでしょう。すべてのイベント処理を SQL で実行する場合の主なデメリットは、ソリューションが ClickHouse に密結合されることです。例えば、処理済みログを OTel collector から S3 などの別の宛先に送信したい場合があります。
マテリアライズドカラム
マテリアライズドカラムは、他のカラムから構造を抽出するための最も簡便な方法です。この種のカラムの値は常に挿入時に計算され、INSERT クエリ内で明示的に指定することはできません。
Overhead
マテリアライズドカラムは、値が挿入時にディスク上の新しいカラムへ抽出されるため、追加のストレージのオーバーヘッドが発生します。
マテリアライズドカラムは任意の ClickHouse 式をサポートし、文字列処理(正規表現と検索 を含む)や URL に対するあらゆる分析関数を活用できます。また、型変換、JSON からの値抽出、数学演算 を実行できます。
基本的な処理にはマテリアライズドカラムの利用を推奨します。特に、map から値を抽出してトップレベルのカラムへ昇格させたり、型変換を行ったりする場合に有用です。ごく基本的なスキーマや materialized view と組み合わせて使用する場合に、最も効果を発揮することが多いです。次のログ用スキーマでは、collector によって JSON が抽出され、LogAttributes カラムに格納されています。
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPage` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer'])
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
String 型の Body から JSON 関数を使って抽出するための同等のスキーマはこちらで確認できます。
ここでは 3 つのマテリアライズドカラムで、リクエストページ、リクエストタイプ、およびリファラのドメインを抽出しています。これらはマップのキーにアクセスし、その値に関数を適用します。これに続くクエリは大幅に高速になります。
SELECT RequestPage AS path, count() AS c
FROM otel_logs
WHERE RequestType = 'POST'
GROUP BY path
ORDER BY c DESC
LIMIT 5
┌─path─────────────────────┬─────c─┐
│ /m/updateVariation │ 12182 │
│ /site/productCard │ 11080 │
│ /site/productPrice │ 10876 │
│ /site/productAdditives │ 10866 │
│ /site/productModelImages │ 10866 │
└──────────────────────────┴───────┘
5 rows in set. Elapsed: 0.173 sec. Processed 10.37 million rows, 418.03 MB (60.07 million rows/s., 2.42 GB/s.)
Peak memory usage: 3.16 MiB.
注記
マテリアライズドカラムは、デフォルトでは SELECT * に含まれて返されません。これは、SELECT * の結果を常に INSERT を使ってテーブルへそのまま挿入できるという不変条件を維持するためです。この動作は、asterisk_include_materialized_columns=1 を設定することで変更できます。また、Grafana では(データソース設定の Additional Settings -> Custom Settings)から有効化できます。
materialized view
materialized view は、ログおよびトレースに対して SQL によるフィルタリングや変換を適用するための、より強力な手段を提供します。
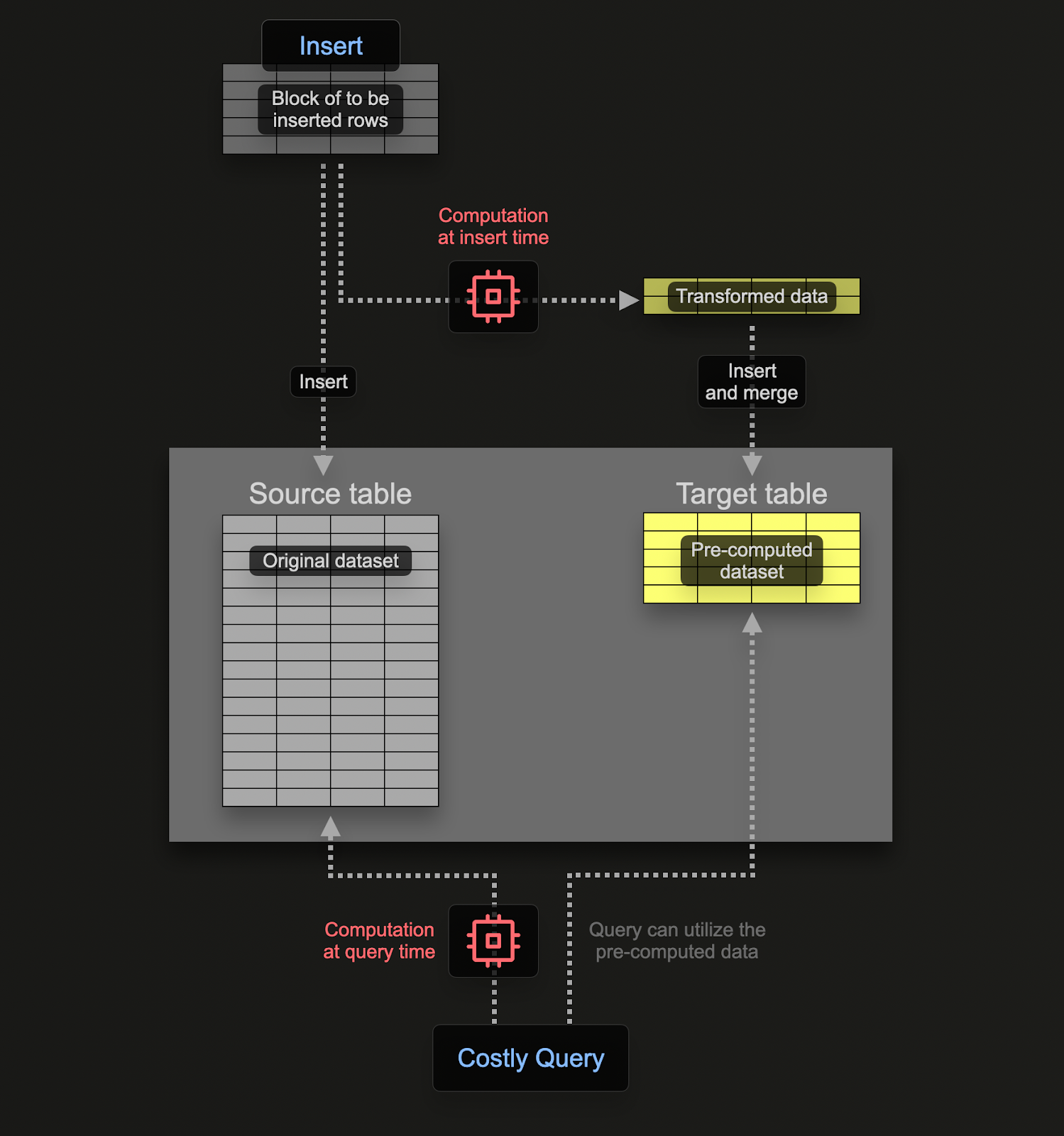
materialized view を使用すると、計算コストをクエリ時から挿入時に移すことができます。ClickHouse の materialized view は、テーブルにデータブロックが挿入される際にクエリを実行するトリガーに過ぎません。このクエリの結果は、2 つ目の「ターゲット」テーブルに挿入されます。
リアルタイム更新
ClickHouse の materialized view は、それらが基づいているテーブルにデータが流れ込むとリアルタイムで更新され続け、継続的に更新される索引のように機能します。対照的に、他のデータベースにおける materialized view は通常、クエリの静的スナップショットであり、(ClickHouse の Refreshable Materialized Views と同様に)リフレッシュが必要です。
materialized view に関連付けられたクエリは、理論的には集約を含む任意のクエリにすることができますが、Join には制限があります。ログおよびトレースに対して必要となる変換およびフィルタリングのワークロードについては、任意の SELECT ステートメントが利用可能と考えて差し支えありません。
このクエリは、テーブル(ソーステーブル)に挿入される行に対して実行されるトリガーに過ぎず、その結果が新しいテーブル(ターゲットテーブル)に送信されるだけである、という点を覚えておく必要があります。
ソーステーブルとターゲットテーブルの両方にデータを二重に永続化しないようにするために、ソーステーブルのテーブルエンジンを Null table engine に変更し、元のスキーマを維持することができます。OTel collector は引き続きこのテーブルにデータを送信します。たとえばログの場合、otel_logs テーブルは次のようになります。
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1))
) ENGINE = Null
Null テーブルエンジンは強力な最適化手段であり、/dev/null のようなものと考えることができます。このテーブル自体はデータを一切保存しませんが、紐付けられた materialized view は、行が破棄される前に、挿入された行に対して引き続き実行されます。
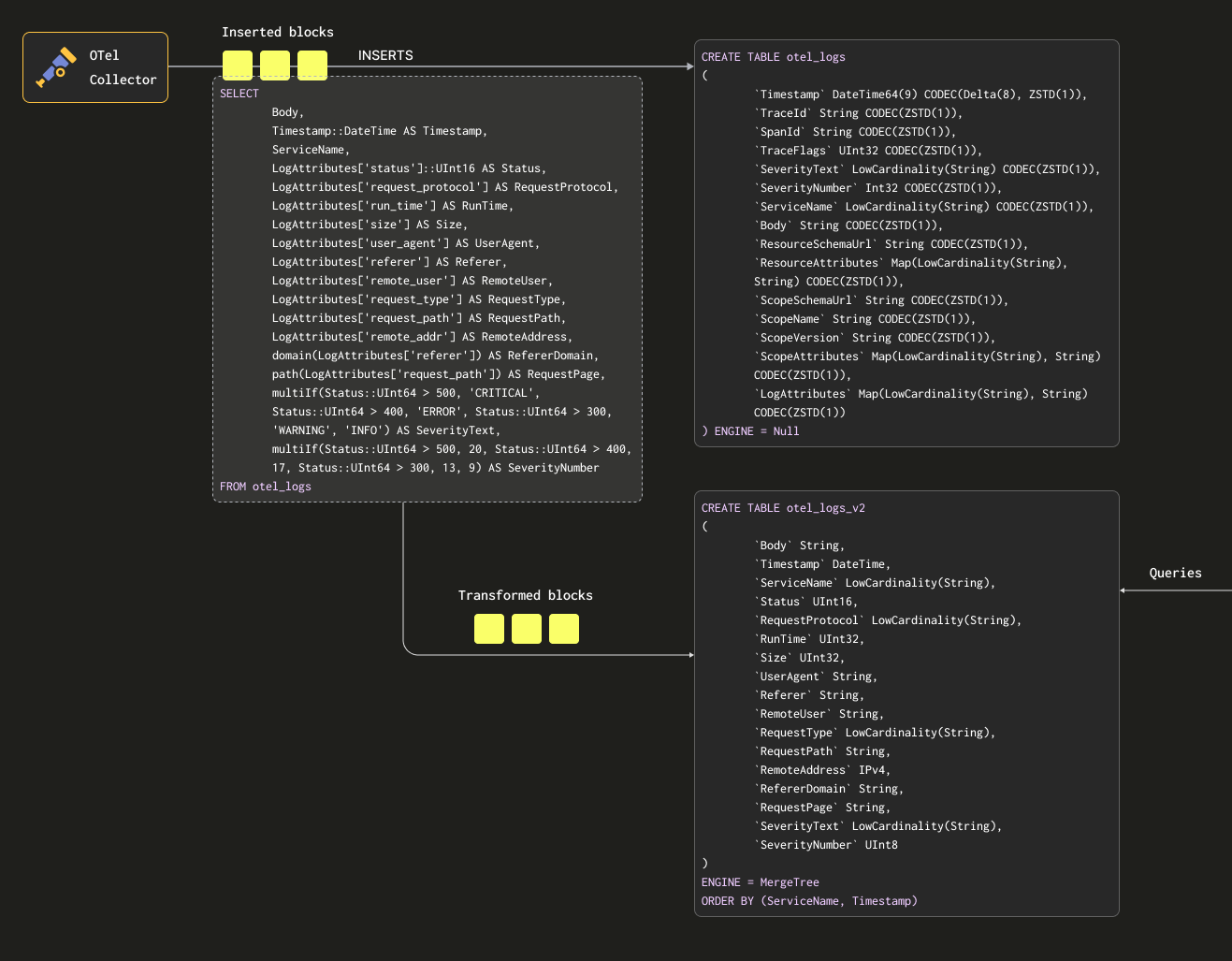
次のクエリを見てみましょう。このクエリは行を、保持したい形式に変換し、LogAttributes からすべてのカラムを抽出します(これは、コレクターが json_parser オペレーターを使って設定したものと仮定します)。さらに、SeverityText と SeverityNumber を設定します(いくつかの単純な条件と これらのカラム の定義に基づきます)。この例では、値が入ることが分かっているカラムだけを選択し、TraceId、SpanId、TraceFlags などのカラムは無視しています。
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status'] AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddr,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
Timestamp: 2019-01-22 00:26:14
ServiceName:
Status: 200
RequestProtocol: HTTP/1.1
RunTime: 0
Size: 30577
UserAgent: Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
Referer: -
RemoteUser: -
RequestType: GET
RequestPath: /filter/27|13 ,27| 5 ,p53
RemoteAddr: 54.36.149.41
RefererDomain:
RequestPage: /filter/27|13 ,27| 5 ,p53
SeverityText: INFO
SeverityNumber: 9
1 row in set. Elapsed: 0.027 sec.
また、上記で Body カラムも抽出しています。これは、後から SQL では抽出していない追加属性が加えられる場合に備えるためです。このカラムは ClickHouse で高い圧縮率が期待でき、参照頻度も低いため、クエリ性能への影響はほとんどありません。最後に、Timestamp を DateTime 型に変換してサイズを削減しています(容量節約のため。 "Optimizing Types" を参照)。この変換には cast を使用します。
Conditionals
上記では、SeverityText と SeverityNumber を抽出するために conditionals を使用している点に注意してください。これは、複雑な条件式を定義したり、マップ内で値が設定されているかを確認したりするのに非常に有用です。ここでは単純化のため、LogAttributes 内にすべてのキーが存在すると仮定しています。ユーザーの皆さんには、これらの使い方に慣れておくことを推奨します。null values を扱う関数とあわせて、ログパースにおける心強い味方になります。
これらの結果を受け取るためのテーブルが必要です。以下のターゲットテーブルは、上記のクエリと一致する構造になっています。
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
ここで選択している型は、"Optimizing types" で説明している最適化に基づいています。
注記
スキーマが大きく変わっている点に注目してください。実際には、保持しておきたいトレース用のカラムや、ResourceAttributes カラム(通常は Kubernetes メタデータを含みます)もあるはずです。Grafana はこれらのトレース関連カラムを活用して、ログとトレース間のリンク機能を提供できます。詳細は "Using Grafana" を参照してください。
以下では、otel_logs テーブルに対して上記の SELECT を実行し、その結果を otel_logs_v2 に書き込む materialized view otel_logs_mv を作成します。
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT
Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
LogAttributes['status']::UInt16 AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
上記の内容を図示すると、次のようになります。
ここで「"Exporting to ClickHouse"」で使用した Collector 設定を再起動すると、otel_logs_v2 に目的のフォーマットでデータが保存されます。型付き JSON 抽出関数を使用している点に注意してください。
SELECT *
FROM otel_logs_v2
LIMIT 1
FORMAT Vertical
Row 1:
──────
Body: {"remote_addr":"54.36.149.41","remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET","request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1","status":"200","size":"30577","referer":"-","user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"}
Timestamp: 2019-01-22 00:26:14
ServiceName:
Status: 200
RequestProtocol: HTTP/1.1
RunTime: 0
Size: 30577
UserAgent: Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
Referer: -
RemoteUser: -
RequestType: GET
RequestPath: /filter/27|13 ,27| 5 ,p53
RemoteAddress: 54.36.149.41
RefererDomain:
RequestPage: /filter/27|13 ,27| 5 ,p53
SeverityText: INFO
SeverityNumber: 9
1 row in set. Elapsed: 0.010 sec.
Body カラムから JSON 関数を用いてカラムを抽出する、同等の materialized view は次のとおりです。
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2 AS
SELECT Body,
Timestamp::DateTime AS Timestamp,
ServiceName,
JSONExtractUInt(Body, 'status') AS Status,
JSONExtractString(Body, 'request_protocol') AS RequestProtocol,
JSONExtractUInt(Body, 'run_time') AS RunTime,
JSONExtractUInt(Body, 'size') AS Size,
JSONExtractString(Body, 'user_agent') AS UserAgent,
JSONExtractString(Body, 'referer') AS Referer,
JSONExtractString(Body, 'remote_user') AS RemoteUser,
JSONExtractString(Body, 'request_type') AS RequestType,
JSONExtractString(Body, 'request_path') AS RequestPath,
JSONExtractString(Body, 'remote_addr') AS remote_addr,
domain(JSONExtractString(Body, 'referer')) AS RefererDomain,
path(JSONExtractString(Body, 'request_path')) AS RequestPage,
multiIf(Status::UInt64 > 500, 'CRITICAL', Status::UInt64 > 400, 'ERROR', Status::UInt64 > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(Status::UInt64 > 500, 20, Status::UInt64 > 400, 17, Status::UInt64 > 300, 13, 9) AS SeverityNumber
FROM otel_logs
型に注意
上記の materialized view は、特に LogAttributes マップを使用する場合、暗黙的なキャストに依存しています。ClickHouse は抽出された値を対象テーブルの型へ透過的にキャストすることが多く、その分記述を簡略化できます。しかし、ユーザーには、対象テーブルと同じスキーマを使用した INSERT INTO 文と、その view の SELECT 文を組み合わせて常に view をテストすることを推奨します。これにより、型が正しく処理されているか確認できます。特に次のケースに注意してください。
- マップ内にキーが存在しない場合、空文字列が返されます。数値型の場合は、これらを適切な値にマッピングする必要があります。条件式(例:
if(LogAttributes['status'] = ", 200, LogAttributes['status']))や、デフォルト値で問題ない場合は キャスト関数(例: toUInt8OrDefault(LogAttributes['status'] ))を使用して対応できます。
- 一部の型は常にキャストされるとは限りません。例えば、数値の文字列表現は enum 値にはキャストされません。
- JSON 抽出関数は、値が見つからない場合、その型に応じたデフォルト値を返します。これらの値が妥当かどうか必ず確認してください。
Nullable を避ける
ClickHouse のオブザーバビリティデータに対しては、Nullable の使用を避けてください。ログおよびトレースでは、空と null を区別する必要があるケースは稀です。この機能は追加のストレージオーバーヘッドを発生させ、クエリ性能に悪影響を与えます。詳細はこちらを参照してください。
プライマリ(並び替え)キーの選択
必要なカラムを抽出できたら、並び替えキー/プライマリキーの最適化を開始できます。
並び替えキーを選択する際には、いくつかの単純なルールを適用できます。以下の指針同士が衝突する場合もあるため、記載順に検討してください。このプロセスから複数のキー候補が得られますが、通常は 4〜5 個で十分です。
- よく利用するフィルターやアクセスパターンに合致するカラムを選択します。たとえば、典型的に特定のカラム(例: ポッド名)でフィルタリングしてオブザーバビリティの調査を開始する場合、そのカラムは
WHERE 句で頻繁に使用されます。利用頻度の低いカラムよりも、これらのカラムを優先してキーに含めてください。
- フィルタリングしたときにテーブル全体の行の大部分を除外できるカラムを優先します。これにより、読み取る必要があるデータ量を削減できます。サービス名やステータスコードは良い候補であることが多いです。ただし後者については、ほとんどの行を除外する値でフィルタする場合に限ります。例えば、200 番台でフィルタすると多くのシステムではほとんどの行にマッチしますが、500 エラーであれば行全体のうち小さなサブセットに対応します。
- テーブル内の他のカラムと強い相関がありそうなカラムを優先します。これにより、それらの値も連続して保存される傾向が強まり、圧縮率が向上します。
- 並び替えキーに含まれるカラムに対する
GROUP BY および ORDER BY の処理は、メモリ効率を高められます。
並び替えキーとして選択したカラムのサブセットは、特定の順序で宣言する必要があります。この順序は、クエリでのセカンダリキー列に対するフィルタリング効率と、テーブルのデータファイルの圧縮率の両方に大きく影響します。一般的には、カーディナリティ(取り得る値の種類の数)が小さいものから大きいものへ昇順に並べるのが最善です。このとき、並び替えキーの後ろに現れるカラムでフィルタリングすると、先頭付近のカラムでフィルタリングするよりも効率が下がることとのバランスを取る必要があります。これらの特性とアクセスパターンを総合的に考慮し、必ず複数のバリエーションを実際にテストしてください。並び替えキーのより深い理解や最適化方法については、この記事を参照することをおすすめします。
Structure first
ログの構造化が完了してから並び替えキーを決定することを推奨します。attribute map 内のキーや JSON 抽出式を並び替えキーとして使用しないでください。並び替えキーとして使用するカラムは、必ずテーブルのルートレベルのカラムとして定義されていることを確認してください。
マップの使用
前の例では、Map(String, String) カラム内の値にアクセスするために、map['key'] のようなマップ構文を使用する方法を示しました。ネストされたキーにアクセスするためにマップ構文を使用できるだけでなく、これらのカラムをフィルタリングまたは選択するために、ClickHouse に用意されている専用の map 関数も利用できます。
例えば、次のクエリは、mapKeys 関数と、それに続く(コンビネータである)groupArrayDistinctArray 関数を使用して、LogAttributes カラム内で利用可能なすべての一意なキーを特定します。
SELECT groupArrayDistinctArray(mapKeys(LogAttributes))
FROM otel_logs
FORMAT Vertical
Row 1:
──────
groupArrayDistinctArray(mapKeys(LogAttributes)): ['remote_user','run_time','request_type','log.file.name','referer','request_path','status','user_agent','remote_addr','time_local','size','request_protocol']
1 row in set. Elapsed: 1.139 sec. Processed 5.63 million rows, 2.53 GB (4.94 million rows/s., 2.22 GB/s.)
Peak memory usage: 71.90 MiB.
ドットの使用を避ける
Map カラム名にドットを使うことは推奨しておらず、将来的に非推奨となる可能性があります。代わりに _ を使用してください。
エイリアスの使用
map 型カラムへのクエリは、通常のカラムへのクエリよりも遅くなります。詳しくは "Accelerating queries" を参照してください。加えて、構文もより複雑になり、記述が煩雑になることがあります。この後者の問題に対処するため、ALIAS カラムの使用を推奨します。
ALIAS カラムはクエリ時に計算され、テーブル内には保存されません。そのため、この型のカラムに値を INSERT することはできません。エイリアスを使用することで、map のキーを参照しつつ構文を簡潔にし、map のエントリを通常のカラムとして透過的に公開できます。次の例を見てください。
CREATE TABLE otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`RequestPath` String MATERIALIZED path(LogAttributes['request_path']),
`RequestType` LowCardinality(String) MATERIALIZED LogAttributes['request_type'],
`RefererDomain` String MATERIALIZED domain(LogAttributes['referer']),
`RemoteAddr` IPv4 ALIAS LogAttributes['remote_addr']
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, Timestamp)
いくつかのマテリアライズドカラムと、マップ LogAttributes にアクセスする ALIAS カラム RemoteAddr があります。これにより、このカラム経由で LogAttributes['remote_addr'] の値をクエリできるようになり、クエリを単純化できます。たとえば、次のように記述できます。
SELECT RemoteAddr
FROM default.otel_logs
LIMIT 5
┌─RemoteAddr────┐
│ 54.36.149.41 │
│ 31.56.96.51 │
│ 31.56.96.51 │
│ 40.77.167.129 │
│ 91.99.72.15 │
└───────────────┘
5 rows in set. Elapsed: 0.011 sec.
さらに、ALTER TABLE コマンドを使えば ALIAS の追加は容易です。これらのカラムはたとえば次のようにすぐに利用できます。
ALTER TABLE default.otel_logs
(ADD COLUMN `Size` String ALIAS LogAttributes['size'])
SELECT Size
FROM default.otel_logs_v3
LIMIT 5
┌─Size──┐
│ 30577 │
│ 5667 │
│ 5379 │
│ 1696 │
│ 41483 │
└───────┘
5 rows in set. Elapsed: 0.014 sec.
デフォルトでは ALIAS が除外される
デフォルトでは、SELECT * は ALIAS カラムを除外します。この挙動は、asterisk_include_alias_columns=1 を設定することで無効化できます。
型の最適化
型を最適化するための 一般的な ClickHouse のベストプラクティス は、この ClickHouse のユースケースにも適用されます。
コーデックの使用
型の最適化に加えて、ClickHouse Observability スキーマで圧縮を最適化しようとする際には、コーデックに関する一般的なベストプラクティスに従うことができます。
一般的に、ZSTD コーデックはログおよびトレースのデータセットに対して非常に有効です。デフォルト値である 1 から圧縮レベルを上げることで、圧縮率が向上する可能性があります。ただし、値を高くすると挿入時の CPU オーバーヘッドが増加するため、必ず検証する必要があります。通常、この値を上げても得られる効果はわずかであることが多いです。
さらに、タイムスタンプは、圧縮の観点ではデルタエンコーディングの恩恵を受ける一方で、このカラムをプライマリキー/並び替えキーとして使用した場合、クエリ性能の低下を招くことが示されています。圧縮効率とクエリ性能のトレードオフを評価することを推奨します。
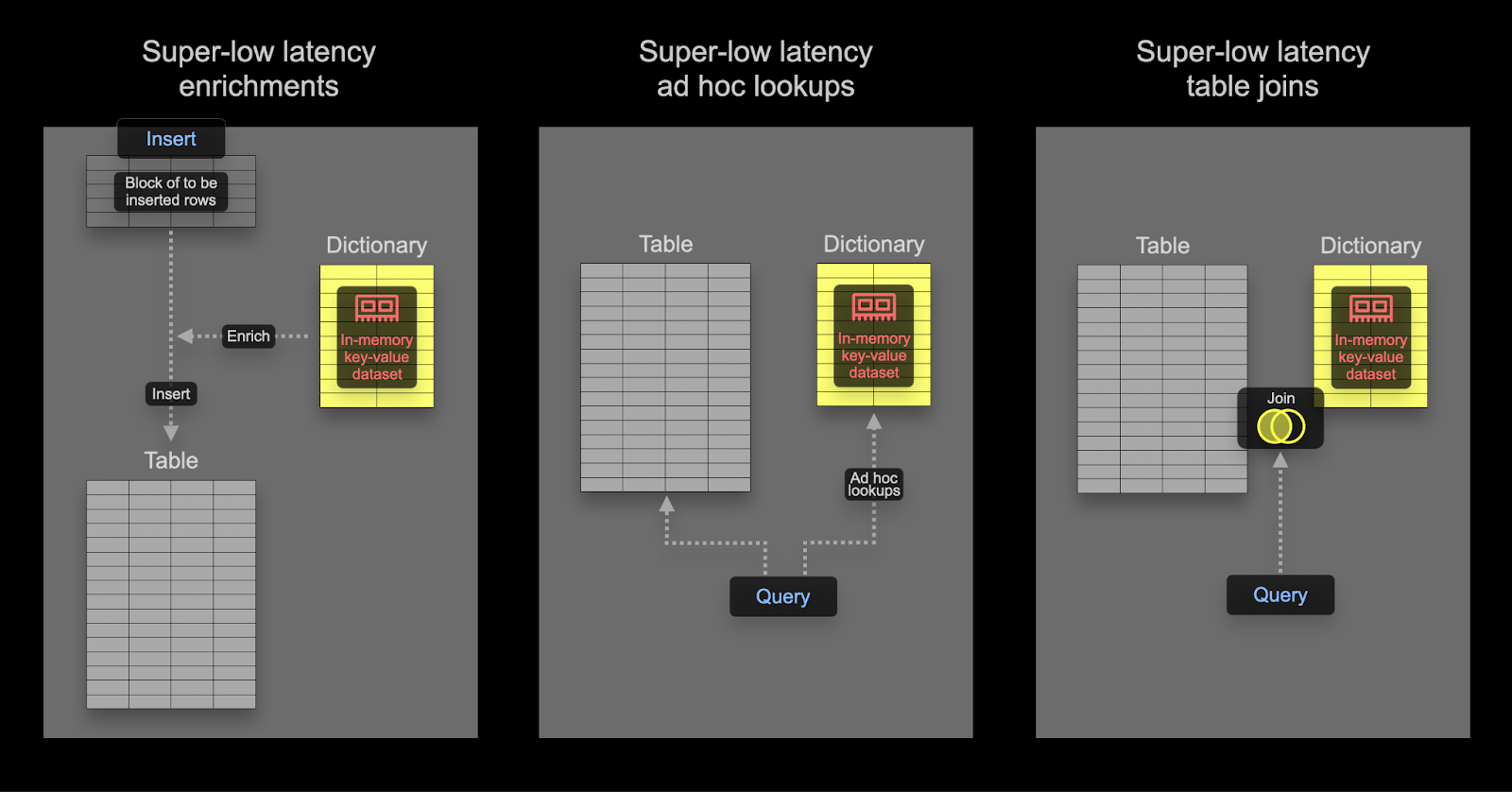
Dictionary の使用
Dictionaries は ClickHouse の重要な機能であり、さまざまな内部および外部のソースからのデータを、インメモリのkey-value形式で表現し、超低レイテンシーのルックアップクエリ向けに最適化します。
これはさまざまなシナリオで有用です。インジェスト処理を低速化することなくオンザフライでインジェスト済みデータをエンリッチしたり、一般的にクエリのパフォーマンスを向上させたりでき、特に JOIN が大きな恩恵を受けます。
オブザーバビリティのユースケースでは JOIN が必要になることは稀ですが、Dictionary はエンリッチの目的で、挿入時とクエリ時の両方で依然として有用です。以下に両方の例を示します。
JOIN の高速化
Dictionary を使って JOIN を高速化する方法に関心があるユーザーは、こちらの詳細を参照してください。
挿入時 vs クエリ時
Dictionary は、クエリ時または挿入時にデータセットをエンリッチメントするために使用できます。これらのアプローチにはそれぞれ長所と短所があります。まとめると次のとおりです。
- 挿入時 - エンリッチメントに用いる値が変化せず、Dictionary を構築するために使用できる外部ソースに存在する場合に、一般的に適しています。この場合、行を挿入時にエンリッチメントすることで、クエリ時に Dictionary を参照する必要がなくなります。その代わりに、挿入パフォーマンスの低下とストレージの追加オーバーヘッドが発生します。これは、エンリッチされた値がカラムとして保存されるためです。
- クエリ時 - Dictionary 内の値が頻繁に変更される場合は、クエリ時のルックアップの方が適していることが多いです。これにより、マッピングされた値が変わったときにカラムを更新(およびデータを書き換え)する必要がなくなります。この柔軟性は、クエリ時のルックアップコストという代償を伴います。多くの行についてルックアップが必要な場合(例: フィルタ句での Dictionary ルックアップ)には、このクエリ時コストは無視できないことがよくあります。一方、
SELECT 内での結果のエンリッチメントでは、このオーバーヘッドは通常それほど問題になりません。
Dictionary の基本を理解しておくことを推奨します。Dictionary はインメモリのルックアップテーブルを提供し、専用の特殊な関数を使って値を取得できます。
簡単なエンリッチメントの例については、Dictionary に関するガイドをこちらで参照してください。以下では、オブザーバビリティで一般的なエンリッチメントタスクに焦点を当てます。
IP Dictionary の使用
IP アドレスを使ってログやトレースに緯度・経度情報を付与してジオ情報を付加することは、一般的なオブザーバビリティ要件です。これは、構造化 Dictionary である ip_trie を使用することで実現できます。
CC BY 4.0 ライセンス の条件に基づき、DB-IP.com が提供する公開データセットである DB-IP city-level dataset を使用します。
README から、データは次のような構造になっていることがわかります。
| ip_range_start | ip_range_end | country_code | state1 | state2 | city | postcode | latitude | longitude | timezone |
この構造を踏まえて、まずはurl()テーブル関数を使ってデータを少し覗いてみましょう。
SELECT *
FROM url('https://raw.githubusercontent.com/sapics/ip-location-db/master/dbip-city/dbip-city-ipv4.csv.gz', 'CSV', '\n \tip_range_start IPv4, \n \tip_range_end IPv4, \n \tcountry_code Nullable(String), \n \tstate1 Nullable(String), \n \tstate2 Nullable(String), \n \tcity Nullable(String), \n \tpostcode Nullable(String), \n \tlatitude Float64, \n \tlongitude Float64, \n \ttimezone Nullable(String)\n \t')
LIMIT 1
FORMAT Vertical
Row 1:
──────
ip_range_start: 1.0.0.0
ip_range_end: 1.0.0.255
country_code: AU
state1: Queensland
state2: ᴺᵁᴸᴸ
city: South Brisbane
postcode: ᴺᵁᴸᴸ
latitude: -27.4767
longitude: 153.017
timezone: ᴺᵁᴸᴸ
作業を楽にするために、URL() テーブルエンジンを使用して、フィールド名を指定した ClickHouse テーブルオブジェクトを作成し、行の総数を確認しましょう。
CREATE TABLE geoip_url(
ip_range_start IPv4,
ip_range_end IPv4,
country_code Nullable(String),
state1 Nullable(String),
state2 Nullable(String),
city Nullable(String),
postcode Nullable(String),
latitude Float64,
longitude Float64,
timezone Nullable(String)
) ENGINE=URL('https://raw.githubusercontent.com/sapics/ip-location-db/master/dbip-city/dbip-city-ipv4.csv.gz', 'CSV')
select count() from geoip_url;
┌─count()─┐
│ 3261621 │ -- 3.26 million
└─────────┘
ip_trie Dictionary では、IP アドレス範囲を CIDR 記法で表す必要があるため、ip_range_start と ip_range_end を変換する必要があります。
各範囲の CIDR 表現は、次のクエリで簡単に求められます。
WITH
bitXor(ip_range_start, ip_range_end) AS xor,
if(xor != 0, ceil(log2(xor)), 0) AS unmatched,
32 - unmatched AS cidr_suffix,
toIPv4(bitAnd(bitNot(pow(2, unmatched) - 1), ip_range_start)::UInt64) AS cidr_address
SELECT
ip_range_start,
ip_range_end,
concat(toString(cidr_address),'/',toString(cidr_suffix)) AS cidr
FROM
geoip_url
LIMIT 4;
┌─ip_range_start─┬─ip_range_end─┬─cidr───────┐
│ 1.0.0.0 │ 1.0.0.255 │ 1.0.0.0/24 │
│ 1.0.1.0 │ 1.0.3.255 │ 1.0.0.0/22 │
│ 1.0.4.0 │ 1.0.7.255 │ 1.0.4.0/22 │
│ 1.0.8.0 │ 1.0.15.255 │ 1.0.8.0/21 │
└────────────────┴──────────────┴────────────┘
4 rows in set. Elapsed: 0.259 sec.
注記
上記のクエリでは多くの処理が行われています。詳細に興味がある方は、この優れた解説を参照してください。そうでなければ、「上記の処理は IP レンジに対して CIDR を計算している」と理解して先に進んでください。
ここでの目的では、必要なのは IP レンジ、国コード、および座標だけなので、新しいテーブルを作成して Geo IP データを挿入します。
CREATE TABLE geoip
(
`cidr` String,
`latitude` Float64,
`longitude` Float64,
`country_code` String
)
ENGINE = MergeTree
ORDER BY cidr
INSERT INTO geoip
WITH
bitXor(ip_range_start, ip_range_end) as xor,
if(xor != 0, ceil(log2(xor)), 0) as unmatched,
32 - unmatched as cidr_suffix,
toIPv4(bitAnd(bitNot(pow(2, unmatched) - 1), ip_range_start)::UInt64) as cidr_address
SELECT
concat(toString(cidr_address),'/',toString(cidr_suffix)) as cidr,
latitude,
longitude,
country_code
FROM geoip_url
ClickHouse で低レイテンシな IP ルックアップを行うために、Geo IP データのキーから属性へのマッピングをインメモリで保持する Dictionary を利用します。ClickHouse には、ネットワークプレフィックス(CIDR ブロック)を座標および国コードにマッピングするための ip_trie dictionary structure が用意されています。次のクエリでは、このレイアウトを用い、上記のテーブルをソースとする Dictionary を定義します。
CREATE DICTIONARY ip_trie (
cidr String,
latitude Float64,
longitude Float64,
country_code String
)
primary key cidr
source(clickhouse(table 'geoip'))
layout(ip_trie)
lifetime(3600);
Dictionary から行を選択し、このデータセットがルックアップに利用可能であることを確認できます。
SELECT * FROM ip_trie LIMIT 3
┌─cidr───────┬─latitude─┬─longitude─┬─country_code─┐
│ 1.0.0.0/22 │ 26.0998 │ 119.297 │ CN │
│ 1.0.0.0/24 │ -27.4767 │ 153.017 │ AU │
│ 1.0.4.0/22 │ -38.0267 │ 145.301 │ AU │
└────────────┴──────────┴───────────┴──────────────┘
3 rows in set. Elapsed: 4.662 sec.
定期的な更新
ClickHouse の Dictionary は、基盤となるテーブルデータと、上記で使用した lifetime 句に基づいて定期的にリフレッシュされます。DB-IP データセット内の最新の変更を Geo IP Dictionary に反映させるには、変換を適用したうえで、geoip_url リモートテーブルからデータを再挿入して geoip テーブルを更新するだけです。
これで ip_trie Dictionary(便宜上、名前も ip_trie)に Geo IP データがロードされたので、IP ジオロケーションに利用できます。これは、dictGet() 関数を次のように使用することで実現できます。
SELECT dictGet('ip_trie', ('country_code', 'latitude', 'longitude'), CAST('85.242.48.167', 'IPv4')) AS ip_details
┌─ip_details──────────────┐
│ ('PT',38.7944,-9.34284) │
└─────────────────────────┘
1 row in set. Elapsed: 0.003 sec.
ここでの取得速度に注目してください。これにより、ログをエンリッチできます。今回のケースでは、クエリ実行時にエンリッチメントを行う方法を選択しています。
元のログデータセットに戻ると、先ほどの仕組みを利用してログを国別に集計できます。以下では、RemoteAddress カラムがすでに抽出されている、先ほどの materialized view から得られたスキーマを利用していることを前提としています。
SELECT dictGet('ip_trie', 'country_code', tuple(RemoteAddress)) AS country,
formatReadableQuantity(count()) AS num_requests
FROM default.otel_logs_v2
WHERE country != ''
GROUP BY country
ORDER BY count() DESC
LIMIT 5
┌─country─┬─num_requests────┐
│ IR │ 7.36 million │
│ US │ 1.67 million │
│ AE │ 526.74 thousand │
│ DE │ 159.35 thousand │
│ FR │ 109.82 thousand │
└─────────┴─────────────────┘
5 rows in set. Elapsed: 0.140 sec. Processed 20.73 million rows, 82.92 MB (147.79 million rows/s., 591.16 MB/s.)
Peak memory usage: 1.16 MiB.
IP アドレスから地理的位置への対応は変化し得るため、ユーザーが知りたいのは、同じアドレスの現在の地理的位置ではなく、リクエストが行われた当時にどこから送信されたかです。このため、ここではインデックス時にエンリッチメントを行う方法が望ましいと考えられます。これは、以下に示すように materialized column を使用するか、materialized view の SELECT 句内で実行できます。
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
`Country` String MATERIALIZED dictGet('ip_trie', 'country_code', tuple(RemoteAddress)),
`Latitude` Float32 MATERIALIZED dictGet('ip_trie', 'latitude', tuple(RemoteAddress)),
`Longitude` Float32 MATERIALIZED dictGet('ip_trie', 'longitude', tuple(RemoteAddress))
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
定期的な更新
ユーザーは、新しいデータに基づいて IP エンリッチメント Dictionary を定期的に更新したいと考えることが多いでしょう。これは、Dictionary の LIFETIME 句を使用することで実現できます。LIFETIME 句により、Dictionary は基盤となるテーブルから定期的に再読み込みされます。基盤となるテーブルを更新する方法については、「Refreshable Materialized views」を参照してください。
上記の国と座標を利用することで、国ごとのグルーピングやフィルタリングにとどまらない可視化が可能になります。参考として、「Visualizing geo data」も参照してください。
正規表現 Dictionary の利用(ユーザーエージェントのパース)
ユーザーエージェント文字列のパースは、古典的な正規表現の問題であり、ログやトレースを基盤とするデータセットで一般的に必要とされる処理です。ClickHouse は Regular Expression Tree Dictionary を用いて、ユーザーエージェントを効率的にパースできます。
正規表現ツリー Dictionary は、ClickHouse オープンソース版では YAMLRegExpTree dictionary source type を使用して定義されます。この型では、正規表現ツリーを含む YAML ファイルへのパスを指定します。独自の正規表現 Dictionary を使用したい場合は、必要な構造の詳細がこちらに記載されています。以下では、uap-core を用いたユーザーエージェントのパースと、サポートされている CSV 形式用 Dictionary の読み込みに焦点を当てます。このアプローチは OSS と ClickHouse Cloud の両方で利用可能です。
注記
以下の例では、2024年6月時点での uap-core におけるユーザーエージェントパース用正規表現の最新スナップショットを使用しています。随時更新される最新のファイルはこちらから取得できます。下記で使用する CSV ファイルにロードするには、こちらの手順に従ってください。
以下の Memory テーブルを作成します。これらは、デバイス、ブラウザ、オペレーティングシステムをパースするための正規表現を保持します。
CREATE TABLE regexp_os
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
CREATE TABLE regexp_browser
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
CREATE TABLE regexp_device
(
id UInt64,
parent_id UInt64,
regexp String,
keys Array(String),
values Array(String)
) ENGINE=Memory;
これらのテーブルには、url テーブル関数を使用して、以下の公開されている CSV ファイルからデータを取り込めます。
INSERT INTO regexp_os SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_os.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
INSERT INTO regexp_device SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_device.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
INSERT INTO regexp_browser SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/user_agent_regex/regexp_browser.csv', 'CSV', 'id UInt64, parent_id UInt64, regexp String, keys Array(String), values Array(String)')
メモリテーブルにデータが投入されたので、正規表現辞書を読み込むことができます。キーとなる値はカラムとして指定する必要がある点に注意してください。これらは、ユーザーエージェントから抽出できる属性になります。
CREATE DICTIONARY regexp_os_dict
(
regexp String,
os_replacement String default 'Other',
os_v1_replacement String default '0',
os_v2_replacement String default '0',
os_v3_replacement String default '0',
os_v4_replacement String default '0'
)
PRIMARY KEY regexp
SOURCE(CLICKHOUSE(TABLE 'regexp_os'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(REGEXP_TREE);
CREATE DICTIONARY regexp_device_dict
(
regexp String,
device_replacement String default 'Other',
brand_replacement String,
model_replacement String
)
PRIMARY KEY(regexp)
SOURCE(CLICKHOUSE(TABLE 'regexp_device'))
LIFETIME(0)
LAYOUT(regexp_tree);
CREATE DICTIONARY regexp_browser_dict
(
regexp String,
family_replacement String default 'Other',
v1_replacement String default '0',
v2_replacement String default '0'
)
PRIMARY KEY(regexp)
SOURCE(CLICKHOUSE(TABLE 'regexp_browser'))
LIFETIME(0)
LAYOUT(regexp_tree);
これらの Dictionary をロードしたら、サンプルの user-agent 文字列を入力して、新しい Dictionary 抽出機能をテストできます。
WITH 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:127.0) Gecko/20100101 Firefox/127.0' AS user_agent
SELECT
dictGet('regexp_device_dict', ('device_replacement', 'brand_replacement', 'model_replacement'), user_agent) AS device,
dictGet('regexp_browser_dict', ('family_replacement', 'v1_replacement', 'v2_replacement'), user_agent) AS browser,
dictGet('regexp_os_dict', ('os_replacement', 'os_v1_replacement', 'os_v2_replacement', 'os_v3_replacement'), user_agent) AS os
┌─device────────────────┬─browser───────────────┬─os─────────────────────────┐
│ ('Mac','Apple','Mac') │ ('Firefox','127','0') │ ('Mac OS X','10','15','0') │
└───────────────────────┴───────────────────────┴────────────────────────────┘
1 row in set. Elapsed: 0.003 sec.
ユーザーエージェントに関するルールが変更されることはほとんどなく、また Dictionary の更新も新しいブラウザやオペレーティングシステム、デバイスが登場したときにだけ行えばよいため、この抽出処理は挿入時に実行するのが妥当です。
この処理は、materialized column を使用して行うことも、materialized view を使用して行うこともできます。以下では、先ほど使用した materialized view を修正します。
CREATE MATERIALIZED VIEW otel_logs_mv TO otel_logs_v2
AS SELECT
Body,
CAST(Timestamp, 'DateTime') AS Timestamp,
ServiceName,
LogAttributes['status'] AS Status,
LogAttributes['request_protocol'] AS RequestProtocol,
LogAttributes['run_time'] AS RunTime,
LogAttributes['size'] AS Size,
LogAttributes['user_agent'] AS UserAgent,
LogAttributes['referer'] AS Referer,
LogAttributes['remote_user'] AS RemoteUser,
LogAttributes['request_type'] AS RequestType,
LogAttributes['request_path'] AS RequestPath,
LogAttributes['remote_addr'] AS RemoteAddress,
domain(LogAttributes['referer']) AS RefererDomain,
path(LogAttributes['request_path']) AS RequestPage,
multiIf(CAST(Status, 'UInt64') > 500, 'CRITICAL', CAST(Status, 'UInt64') > 400, 'ERROR', CAST(Status, 'UInt64') > 300, 'WARNING', 'INFO') AS SeverityText,
multiIf(CAST(Status, 'UInt64') > 500, 20, CAST(Status, 'UInt64') > 400, 17, CAST(Status, 'UInt64') > 300, 13, 9) AS SeverityNumber,
dictGet('regexp_device_dict', ('device_replacement', 'brand_replacement', 'model_replacement'), UserAgent) AS Device,
dictGet('regexp_browser_dict', ('family_replacement', 'v1_replacement', 'v2_replacement'), UserAgent) AS Browser,
dictGet('regexp_os_dict', ('os_replacement', 'os_v1_replacement', 'os_v2_replacement', 'os_v3_replacement'), UserAgent) AS Os
FROM otel_logs
そのためには、対象テーブル otel_logs_v2 のスキーマを変更する必要があります。
CREATE TABLE default.otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt8,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`remote_addr` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
`Device` Tuple(device_replacement LowCardinality(String), brand_replacement LowCardinality(String), model_replacement LowCardinality(String)),
`Browser` Tuple(family_replacement LowCardinality(String), v1_replacement LowCardinality(String), v2_replacement LowCardinality(String)),
`Os` Tuple(os_replacement LowCardinality(String), os_v1_replacement LowCardinality(String), os_v2_replacement LowCardinality(String), os_v3_replacement LowCardinality(String))
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp, Status)
コレクターを再起動し、前述の手順に従って構造化ログを取り込んだあと、新たに抽出された Device、Browser、OS 各カラムに対してクエリを実行できます。
SELECT Device, Browser, Os
FROM otel_logs_v2
LIMIT 1
FORMAT Vertical
Row 1:
──────
Device: ('Spider','Spider','Desktop')
Browser: ('AhrefsBot','6','1')
Os: ('Other','0','0','0')
複雑な構造のためのTuple
これらのユーザーエージェント用カラムでTupleを使用している点に注目してください。Tupleは、階層構造があらかじめ分かっている複雑なデータに対して推奨されます。サブカラムは、異種の型を許容しつつ(Mapのキーとは異なり)、通常のカラムと同等のパフォーマンスを発揮します。
さらに詳しく読む
Dictionary に関するさらなる例や詳細については、次の記事を参照してください。
クエリの高速化
ClickHouse は、クエリ性能を向上させるためのさまざまな手法をサポートしています。以下の手法は、まず最も一般的なアクセスパターンを最適化し、圧縮率を最大化できるような適切な primary/ordering key を選定した後にのみ検討してください。通常、これが最小限の労力で最大の性能向上をもたらします。
集約のために materialized view(インクリメンタル)を使用する
前のセクションでは、データの変換およびフィルタリングに materialized view を使用する方法を確認しました。しかし、materialized view は挿入時に集約をあらかじめ計算して結果を保存するためにも使用できます。この結果は後続の挿入の結果で更新できるため、実質的に挿入時点で集約を事前計算することができます。
ここでの主なアイデアは、結果がしばしば元データよりも小さな表現(集約の場合にはスケッチのような部分的な表現)になる、という点です。対象テーブルから結果を読み出すための、より単純なクエリと組み合わせることで、同じ計算を元データに対して実行する場合と比べて、クエリの実行時間を短縮できます。
次のクエリでは、構造化ログを用いて時間あたりの総トラフィック量を計算しています。
SELECT toStartOfHour(Timestamp) AS Hour,
sum(toUInt64OrDefault(LogAttributes['size'])) AS TotalBytes
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.666 sec. Processed 10.37 million rows, 4.73 GB (15.56 million rows/s., 7.10 GB/s.)
Peak memory usage: 1.40 MiB.
このクエリは、Grafana でユーザーがよく描画する折れ線グラフをイメージすると分かりやすいでしょう。このクエリは確かに非常に高速です。データセットはわずか 1,000 万行であり、かつ ClickHouse は高速です。しかし、これを数十億・数兆行へとスケールさせた場合でも、このクエリ性能を維持できることが理想です。
注記
このクエリは、以前の materialized view の結果である otel_logs_v2 テーブルを使えば 10 倍高速になります。この materialized view は、LogAttributes マップから size キーを抽出しています。ここでは説明のために生データを使用していますが、これが一般的に実行されるクエリであれば、前述の view を使用することを推奨します。
materialized view を使って INSERT 時にこれを計算したい場合、その結果を書き込むテーブルが必要です。このテーブルは 1 時間あたり 1 行のみを保持する必要があります。既存の時間に対する更新が届いた場合、他のカラムはその時間の既存行にマージされる必要があります。このように増分状態をマージできるようにするには、他のカラムについて中間状態(部分的な集計状態)を保持しておく必要があります。
これには ClickHouse の特別なテーブルエンジンが必要です: SummingMergeTree です。これは、同じソートキーを持つすべての行を、数値カラムの値を合計した 1 行に置き換えます。次のテーブルは、同じ日付を持つ任意の行をマージし、すべての数値カラムを合計します。
CREATE TABLE bytes_per_hour
(
`Hour` DateTime,
`TotalBytes` UInt64
)
ENGINE = SummingMergeTree
ORDER BY Hour
materialized view の動作を示すために、まず bytes_per_hour テーブルは空で、まだデータを一切受け取っていないものと仮定します。materialized view は、otel_logs に挿入されたデータに対して上記の SELECT を実行し(これは設定されたサイズのブロック単位で実行されます)、その結果を bytes_per_hour に送ります。構文は次のとおりです。
CREATE MATERIALIZED VIEW bytes_per_hour_mv TO bytes_per_hour AS
SELECT toStartOfHour(Timestamp) AS Hour,
sum(toUInt64OrDefault(LogAttributes['size'])) AS TotalBytes
FROM otel_logs
GROUP BY Hour
ここで重要なのは TO 句であり、結果の送信先、すなわち bytes_per_hour を示します。
OTel collector を再起動してログを再送信すると、bytes_per_hour テーブルには上記のクエリ結果が増分的に蓄積されていきます。処理完了後に bytes_per_hour のサイズを確認します。1 時間あたり 1 行になっているはずです。
SELECT count()
FROM bytes_per_hour
FINAL
┌─count()─┐
│ 113 │
└─────────┘
1 row in set. Elapsed: 0.039 sec.
ここでは、クエリの結果を保存することで、otel_logs の行数を1,000万行から113行へと効果的に削減しました。ここでのポイントは、新しいログが otel_logs テーブルに挿入されると、それぞれの時間帯に対応する新しい値が bytes_per_hour に書き込まれ、バックグラウンドで非同期に自動マージされることです。その結果、bytes_per_hour では1時間あたり1行のみを保持することで、常にサイズが小さく、かつ最新の状態を維持できます。
行のマージは非同期で行われるため、ユーザーがクエリを実行した時点では、1時間あたり複数行存在する可能性があります。クエリ実行時に未マージの行を確実にマージするには、次の2つのオプションがあります。
- テーブル名に対して(上記の件数クエリで行ったように)
FINAL 修飾子 を使用する。
- 最終テーブルで使用している並び替えキー(Timestamp)で集約し、メトリクスを合計する。
一般的に、2つ目のオプションの方が効率的かつ柔軟です(テーブルを他の用途にも利用できる)が、1つ目のオプションは一部のクエリではより単純に扱えます。以下に両方の例を示します。
SELECT
Hour,
sum(TotalBytes) AS TotalBytes
FROM bytes_per_hour
GROUP BY Hour
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.008 sec.
SELECT
Hour,
TotalBytes
FROM bytes_per_hour
FINAL
ORDER BY Hour DESC
LIMIT 5
┌────────────────Hour─┬─TotalBytes─┐
│ 2019-01-26 16:00:00 │ 1661716343 │
│ 2019-01-26 15:00:00 │ 1824015281 │
│ 2019-01-26 14:00:00 │ 1506284139 │
│ 2019-01-26 13:00:00 │ 1580955392 │
│ 2019-01-26 12:00:00 │ 1736840933 │
└─────────────────────┴────────────┘
5 rows in set. Elapsed: 0.005 sec.
この結果、クエリの実行時間は 0.6 秒から 0.008 秒へと短縮され、75 倍以上高速になりました。
注記
この効果は、より大きなデータセットやより複雑なクエリに対してはさらに大きくなる可能性があります。例についてはこちらを参照してください。
さらに複雑な例
上記の例では、SummingMergeTree を使って、時間ごとの単純なカウントを集計しています。単純な合計を超える統計量が必要な場合は、別のターゲットテーブルエンジン、つまり AggregatingMergeTree を使用する必要があります。
1 日あたりの一意な IP アドレス数(または一意なユーザー数)を計算したいとします。このときのクエリは次のようになります。
SELECT toStartOfHour(Timestamp) AS Hour, uniq(LogAttributes['remote_addr']) AS UniqueUsers
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
┌────────────────Hour─┬─UniqueUsers─┐
│ 2019-01-26 16:00:00 │ 4763 │
│ 2019-01-22 00:00:00 │ 536 │
└─────────────────────┴─────────────┘
113 rows in set. Elapsed: 0.667 sec. Processed 10.37 million rows, 4.73 GB (15.53 million rows/s., 7.09 GB/s.)
インクリメンタルな更新でカーディナリティのカウントを永続的に保持するには、AggregatingMergeTree が必要です。
CREATE TABLE unique_visitors_per_hour
(
`Hour` DateTime,
`UniqueUsers` AggregateFunction(uniq, IPv4)
)
ENGINE = AggregatingMergeTree
ORDER BY Hour
ClickHouse に集約状態を保存することを認識させるために、UniqueUsers カラムを型 AggregateFunction として定義し、部分状態の集約関数(uniq)と、その入力カラムの型(IPv4)を指定します。SummingMergeTree と同様に、同じ ORDER BY キー値を持つ行はマージされます(上記の例では Hour)。
対応する materialized view では、先ほどのクエリを使用します。
CREATE MATERIALIZED VIEW unique_visitors_per_hour_mv TO unique_visitors_per_hour AS
SELECT toStartOfHour(Timestamp) AS Hour,
uniqState(LogAttributes['remote_addr']::IPv4) AS UniqueUsers
FROM otel_logs
GROUP BY Hour
ORDER BY Hour DESC
集約関数の末尾にサフィックスとして State を付与していることに注目してください。これにより、関数の最終結果ではなく、集約状態が返されます。この集約状態には、この部分的な状態を他の状態とマージできるようにするための追加情報が含まれます。
Collector を再起動してデータを再読み込みしたら、unique_visitors_per_hour テーブルに 113 行が存在することを確認できます。
SELECT count()
FROM unique_visitors_per_hour
FINAL
┌─count()─┐
│ 113 │
└─────────┘
1 row in set. Elapsed: 0.009 sec.
最終的なクエリでは、(カラムに部分的な集約状態が保持されているため)Merge サフィックス付きの関数を使用する必要があります。
SELECT Hour, uniqMerge(UniqueUsers) AS UniqueUsers
FROM unique_visitors_per_hour
GROUP BY Hour
ORDER BY Hour DESC
┌────────────────Hour─┬─UniqueUsers─┐
│ 2019-01-26 16:00:00 │ 4763 │
│ 2019-01-22 00:00:00 │ 536 │
└─────────────────────┴─────────────┘
113 rows in set. Elapsed: 0.027 sec.
ここでは FINAL ではなく GROUP BY を使用している点に注意してください。
materialized view(インクリメンタル)を利用した高速なルックアップ
ClickHouse のオーダリングキーを選択する際は、フィルター句や集約句で頻繁に使用されるカラムを含めて、アクセスパターンを考慮する必要があります。これはオブザーバビリティのユースケースでは制約となり得ます。ユーザーのアクセスパターンがより多様で、単一のカラム集合には集約しきれないことが多いためです。この点は、デフォルトの OTel スキーマに組み込まれている例で示すとわかりやすくなります。トレース向けのデフォルトスキーマを考えてみましょう。
CREATE TABLE otel_traces
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`TraceState` String CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`Duration` Int64 CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
`Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)),
`Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
`Links.TraceId` Array(String) CODEC(ZSTD(1)),
`Links.SpanId` Array(String) CODEC(ZSTD(1)),
`Links.TraceState` Array(String) CODEC(ZSTD(1)),
`Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
このスキーマは、ServiceName、SpanName、Timestamp によるフィルタリングに最適化されています。トレーシングでは、特定の TraceId で検索し、そのトレースに対応する span を取得できることも必要です。TraceId 自体はオーダリングキーに含まれていますが、末尾に位置しているため フィルタリング効率が下がり、単一のトレースを取得するだけでも大量のデータをスキャンする必要が生じる可能性があります。
この課題に対処するため、OTel collector は materialized view と、それに対応するテーブルもインストールします。テーブルとビューを以下に示します。
CREATE TABLE otel_traces_trace_id_ts
(
`TraceId` String CODEC(ZSTD(1)),
`Start` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`End` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.01) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY (TraceId, toUnixTimestamp(Start))
CREATE MATERIALIZED VIEW otel_traces_trace_id_ts_mv TO otel_traces_trace_id_ts
(
`TraceId` String,
`Start` DateTime64(9),
`End` DateTime64(9)
)
AS SELECT
TraceId,
min(Timestamp) AS Start,
max(Timestamp) AS End
FROM otel_traces
WHERE TraceId != ''
GROUP BY TraceId
この VIEW により、テーブル otel_traces_trace_id_ts が各トレースに対して最小および最大のタイムスタンプを保持することが実質的に保証されます。このテーブルは TraceId でソートされており、これらのタイムスタンプを効率的に取得できます。さらに、これらのタイムスタンプの範囲は、メインの otel_traces テーブルをクエリする際に利用できます。より具体的には、トレースをその ID で取得する際に、Grafana は次のクエリを使用します。
WITH 'ae9226c78d1d360601e6383928e4d22d' AS trace_id,
(
SELECT min(Start)
FROM default.otel_traces_trace_id_ts
WHERE TraceId = trace_id
) AS trace_start,
(
SELECT max(End) + 1
FROM default.otel_traces_trace_id_ts
WHERE TraceId = trace_id
) AS trace_end
SELECT
TraceId AS traceID,
SpanId AS spanID,
ParentSpanId AS parentSpanID,
ServiceName AS serviceName,
SpanName AS operationName,
Timestamp AS startTime,
Duration * 0.000001 AS duration,
arrayMap(key -> map('key', key, 'value', SpanAttributes[key]), mapKeys(SpanAttributes)) AS tags,
arrayMap(key -> map('key', key, 'value', ResourceAttributes[key]), mapKeys(ResourceAttributes)) AS serviceTags
FROM otel_traces
WHERE (traceID = trace_id) AND (startTime >= trace_start) AND (startTime <= trace_end)
LIMIT 1000
この CTE では、トレース ID ae9226c78d1d360601e6383928e4d22d に対する最小および最大のタイムスタンプを特定し、その結果を用いて、対応する span を含むメインの otel_traces を絞り込んでいます。
同様のアクセスパターンにも、この手法をそのまま適用できます。類似の例については、データモデリングのこちらを参照してください。
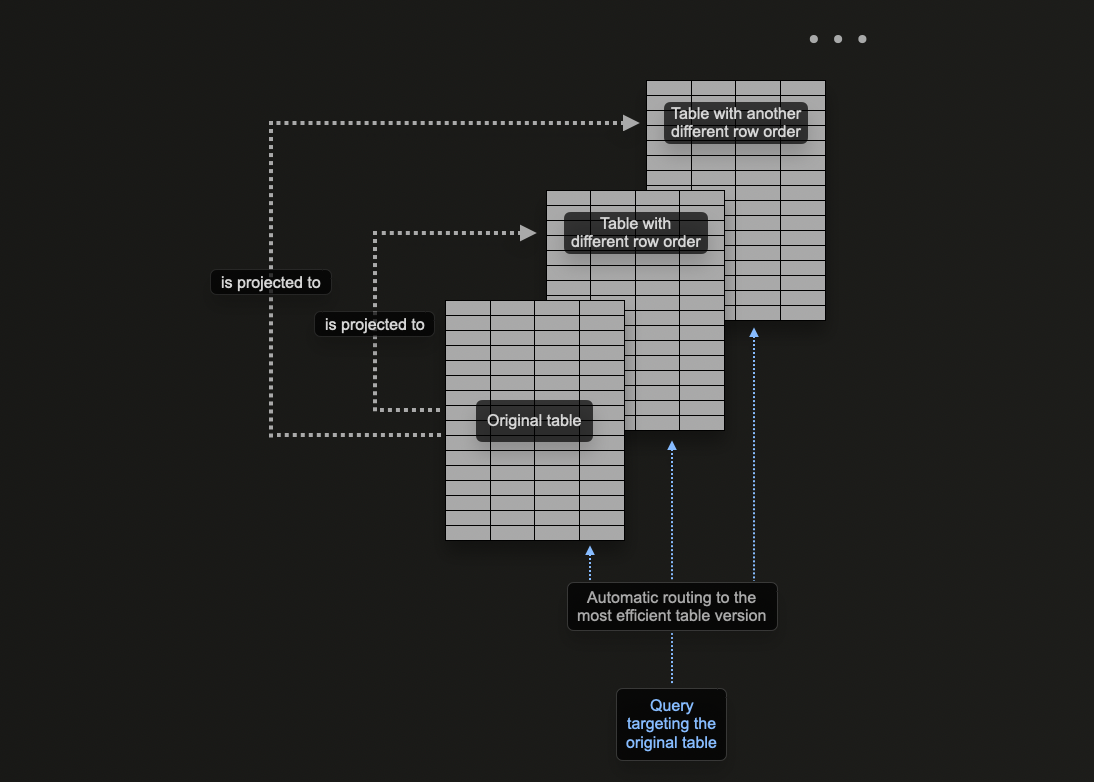
プロジェクションの使用
ClickHouseのプロジェクションを使用すると、1つのテーブルに対して複数のORDER BY句を指定できます。
前のセクションでは、ClickHouseでマテリアライズドビューを使用して、集計の事前計算、行の変換、さまざまなアクセスパターンに対するオブザーバビリティクエリの最適化を行う方法を説明しました。
トレースIDによる検索を最適化するため、マテリアライズドビューが挿入を受け取る元のテーブルとは異なる順序キーを持つターゲットテーブルに行を送信する例を示しました。
プロジェクションを使用することで同じ問題に対処でき、プライマリキーに含まれないカラムに対するクエリをユーザーが最適化できるようになります。
理論上、この機能はテーブルに複数の並び替えキーを提供するために使用できますが、明確な欠点が1つあります。それはデータの重複です。具体的には、各プロジェクションに指定された順序に加えて、メインのプライマリキーの順序でもデータを書き込む必要があります。これにより、挿入が遅くなり、より多くのディスク領域を消費します。
PROJECTIONとmaterialized viewの比較
PROJECTIONはmaterialized viewと同様の機能を多く提供しますが、一般的にはmaterialized viewの使用が推奨されるため、PROJECTIONは慎重に使用する必要があります。それぞれの欠点と適切な使用場面を理解しておく必要があります。例えば、PROJECTIONは集計の事前計算に使用できますが、この用途にはmaterialized viewの使用を推奨します。
以下のクエリは、otel_logs_v2 テーブルを 500 エラーコードでフィルタリングします。これは、エラーコードでフィルタリングを行う際の一般的なアクセスパターンです。
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
FROM otel_logs_v2
WHERE Status = 500
FORMAT `Null`
Ok.
0 rows in set. Elapsed: 0.177 sec. Processed 10.37 million rows, 685.32 MB (58.66 million rows/s., 3.88 GB/s.)
Peak memory usage: 56.54 MiB.
パフォーマンス測定には Null を使用
ここでは FORMAT Null を使って結果を出力していません。これによりすべての結果が読み取られるものの返されないため、LIMIT によるクエリの早期終了を防げます。これは 1000 万行すべてをスキャンするのにかかった時間を示すためのものです。
上記のクエリでは、選択したソートキー (ServiceName, Timestamp) による線形スキャンが必要です。ソートキーの末尾に Status を追加することで上記のクエリのパフォーマンスを向上させることができますが、PROJECTIONを追加する方法もあります。
ALTER TABLE otel_logs_v2 (
ADD PROJECTION status
(
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent ORDER BY Status
)
)
ALTER TABLE otel_logs_v2 MATERIALIZE PROJECTION status
まず PROJECTION を作成し、次にそれをマテリアライズする必要があります。このマテリアライズコマンドにより、データは2つの異なる順序でディスク上に2回保存されます。PROJECTION は、以下に示すように、テーブル作成時に定義することもでき、データ挿入時に自動的に維持されます。
CREATE TABLE otel_logs_v2
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
PROJECTION status
(
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
ORDER BY Status
)
)
ENGINE = MergeTree
ORDER BY (ServiceName, Timestamp)
重要な点として、プロジェクションがALTERを介して作成される場合、MATERIALIZE PROJECTIONコマンドが発行されると、その作成は非同期で実行されます。この操作の進行状況は、以下のクエリで確認でき、is_done=1になるまで待機してください。
SELECT parts_to_do, is_done, latest_fail_reason
FROM system.mutations
WHERE (`table` = 'otel_logs_v2') AND (command LIKE '%MATERIALIZE%')
┌─parts_to_do─┬─is_done─┬─latest_fail_reason─┐
│ 0 │ 1 │ │
└─────────────┴─────────┴────────────────────┘
1 row in set. Elapsed: 0.008 sec.
上記のクエリを再実行すると、追加のストレージを代償としてパフォーマンスが大幅に向上していることが確認できます(測定方法については"テーブルサイズと圧縮の測定"を参照してください)。
SELECT Timestamp, RequestPath, Status, RemoteAddress, UserAgent
FROM otel_logs_v2
WHERE Status = 500
FORMAT `Null`
0 rows in set. Elapsed: 0.031 sec. Processed 51.42 thousand rows, 22.85 MB (1.65 million rows/s., 734.63 MB/s.)
Peak memory usage: 27.85 MiB.
上記の例では、先ほどのクエリで使用したカラムを PROJECTION で指定しています。これにより、PROJECTION の一部としてディスク上に保存されるのは、指定したこれらのカラムのみとなり、Status でソートされた状態になります。代わりにここで SELECT * を使用した場合は、すべてのカラムが保存されます。これは、任意のカラムのサブセットを使用する、より多くのクエリが PROJECTION の恩恵を受けられる一方で、追加のストレージが必要になることを意味します。ディスク容量と圧縮率の測定方法については、「テーブルサイズと圧縮の測定」 を参照してください。
セカンダリ/データスキップ索引
ClickHouse でプライマリキーをどれだけ適切にチューニングしても、一部のクエリではフルテーブルスキャンが避けられなくなります。これは materialized view(および一部のクエリではプロジェクション)を使用することで軽減できますが、これらには追加のメンテナンスが必要であるうえ、ユーザー側もその存在を理解し、意識して利用してもらう必要があります。従来のリレーショナルデータベースでは、これをセカンダリ索引によって解決しますが、ClickHouse のようなカラム指向データベースではこれは効果的ではありません。その代わりに ClickHouse では「スキップ」索引を使用し、一致する値を含まない大きなデータ chunk をスキップできるようにすることで、クエリ性能を大幅に向上させます。
デフォルトの OTel スキーマでは、map 型へのアクセスを高速化しようとしてセカンダリ索引を使用しています。これは一般的にあまり効果的ではなく、カスタムスキーマにそのままコピーすることは推奨しませんが、スキップ索引自体は依然として有用な場合があります。
適用を試みる前に、必ずセカンダリ索引に関するガイドを読み、理解してください。
一般的に、プライマリキーと対象となる非プライマリカラム/式との間に強い相関があり、ユーザーがまれな値、すなわち多くのグラニュールには出現しない値を検索している場合に有効です。
フルテキスト検索のためのテキスト索引
ClickHouse はフルテキスト検索のために専用のテキスト索引を提供しています。
この索引はトークン化されたテキストデータに対して逆インデックスを構築し、トークンベースの検索クエリを高速に実行できるようにします。
テキスト索引は、ClickHouse バージョン 26.2 以降で利用可能です。
MergeTree テーブルでは、次のカラム型のカラムに対して定義できます: String、FixedString、Array(String)、Array(FixedString)、および Map(mapKeys と mapValues の map 関数経由)。
テキスト索引を定義する際には tokenizer 引数の指定が必須です。オプションとして、トークナイズ前に入力文字列を変換する前処理関数を指定できます。
索引を検索する際に推奨される関数は、hasAnyTokens と hasAllTokens です。
一部の従来型の文字列検索関数も、テキスト索引が存在する場合には自動的に最適化されます。詳細およびサポートされている関数については、こちらおよびこちらのドキュメントを参照してください。
以下の例では、構造化ログのデータセットを用います。
CREATE TABLE otel_logs
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8
)
ENGINE = MergeTree
ORDER BY Timestamp
SETTINGS index_granularity = 8192
hasAnyTokens もテキスト索引なしで使用できますが、その場合クエリは Body カラムを遅いフルスキャンで処理します。
SELECT count()
FROM otel_logs
WHERE hasAllTokens(Body, ['Connection', 'accepted'])
Query id: ff0b866c-6df7-47be-9e36-795ef3888169
┌─count()─┐
1. │ 27281 │
└─────────┘
1 row in set. Elapsed: 0.584 sec. Processed 19.95 million rows, 3.08 GB (34.15 million rows/s., 5.27 GB/s.)
テキスト索引の追加
Body カラムに対するテキスト索引は、テーブル作成時に追加できます。
CREATE TABLE otel_logs_index_body
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
INDEX idx_body Body TYPE text(tokenizer = splitByNonAlpha) GRANULARITY 100000000
)
ENGINE = MergeTree
ORDER BY Timestamp
SETTINGS index_granularity = 8192
または ALTER TABLE を使用して後から追加できます:
ALTER TABLE otel_logs ADD INDEX idx_body Body TYPE text(tokenizer = splitByNonAlpha) GRANULARITY 100000000;
ALTER TABLE otel_logs MATERIALIZE INDEX idx_body;
同じ SELECT クエリを再度実行すると、テキスト索引を使ったルックアップが行われます。
アクセスされるデータ量はギガバイトからメガバイトへと削減され、パフォーマンスは約 45x 向上します。
SELECT count()
FROM otel_logs_index_body
WHERE hasAllTokens(Body, ['Connection', 'accepted'])
Query id: ebc31a94-92b3-48aa-860a-939d7e788ef4
┌─count()─┐
1. │ 27281 │
└─────────┘
1 row in set. Elapsed: 0.013 sec. Processed 20.41 million rows, 20.41 MB (1.59 billion rows/s., 1.59 GB/s.)
Peak memory usage: 15.23 MiB.
プリプロセッサーの使用
このデータセットでは、Body カラムには複数のキーと値のペア(例: msg、id、ctx、attr など)を含む JSON 形式の文字列が格納されています。
ここでは msg フィールドのみを検索対象にしたいとします。
JSON 文字列全体に索引を作成する代わりに、トークナイズの前に msg の値だけを抽出するプリプロセッサーを定義できます。
例えば:
INDEX idx_text Body TYPE text(tokenizer = splitByNonAlpha,
preprocessor = JSONExtract(Body, 'msg', 'String'))
この例では、プリプロセッサーにより次の効果が得られます。
- トークン化およびインデックス化されるテキスト量を削減する
- 索引のサイズを小さくする
- 誤検知の可能性を減らす
- クエリのパフォーマンスを向上させる
SELECT count()
FROM otel_logs_text_body_preprocessed
WHERE hasAllTokens(Body, ['Connection', 'accepted'])
Query id: f6a5cd9c-665f-4e4f-82f2-d6a4408a68a8
┌─count()─┐
1. │ 27281 │
└─────────┘
1 row in set. Elapsed: 0.006 sec. Processed 13.54 million rows, 13.54 MB (2.45 billion rows/s., 2.45 GB/s.)
Peak memory usage: 1.95 MiB.
前処理を行っていない索引と比べると、パフォーマンスは約 2 倍向上します。
プリプロセッサを使用すると、索引サイズもギガバイトから数百キロバイト程度まで(元のサイズのおよそ 0.01%)削減できます。
SELECT
`table`,
formatReadableSize(data_compressed_bytes) AS compressed_size,
formatReadableSize(data_uncompressed_bytes) AS uncompressed_size
FROM system.data_skipping_indices
WHERE startsWith(`table`, 'otel_logs')
Query id: 730e4b77-e697-40b3-a24d-67219ec42075
┌─table───────────────────────────────────┬─compressed_size─┬─uncompressed_size─┐
1. │ otel_logs_text_index_body_preprocessed │ 423.98 KiB │ 424.29 KiB │
2. │ otel_logs_text_index_body │ 2.76 GiB │ 2.78 GiB │
└─────────────────────────────────────────┴─────────────────┴───────────────────┘
**テキスト検索用のその他の索引
セカンダリ スキップ索引の詳細についてはこちらを参照してください。
テキスト検索用のBloomフィルタ
注記
ngrambf_v1 および tokenbf_v1 索引は、全文検索への使用は推奨されなくなりました。
ngramおよびトークンベースのブルームフィルタ索引であるngrambf_v1とtokenbf_v1を使用することで、LIKE、IN、hasToken演算子を用いたStringカラムに対する検索を高速化できます。 重要な点として、トークンベース索引は英数字以外の文字を区切り文字として使用してトークンを生成します。 これは、クエリ実行時にはトークン(または単語全体)のみがマッチング対象となることを意味します。 より細かい粒度でのマッチングが必要な場合は、N-gramブルームフィルタを使用できます。 これは文字列を指定されたサイズのngramに分割することで、単語内の部分マッチングを可能にします。
生成されマッチングされるトークンを評価するには、tokens関数を使用します:
SELECT tokens('https://www.zanbil.ir/m/filter/b113')
┌─tokens────────────────────────────────────────────┐
│ ['https','www','zanbil','ir','m','filter','b113'] │
└───────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.008 sec.
ngram関数も同様の機能を提供します。第2パラメータとしてngramのサイズを指定できます:
SELECT ngrams('https://www.zanbil.ir/m/filter/b113', 3)
┌─ngrams('https://www.zanbil.ir/m/filter/b113', 3)────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ ['htt','ttp','tps','ps:','s:/','://','//w','/ww','www','ww.','w.z','.za','zan','anb','nbi','bil','il.','l.i','.ir','ir/','r/m','/m/','m/f','/fi','fil','ilt','lte','ter','er/','r/b','/b1','b11','113'] │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.008 sec.
この例では、構造化ログデータセットを使用します。Refererカラムにultraが含まれるログの件数を取得したいとします。
SELECT count()
FROM otel_logs_v2
WHERE Referer LIKE '%ultra%'
┌─count()─┐
│ 114514 │
└─────────┘
1 row in set. Elapsed: 0.177 sec. Processed 10.37 million rows, 908.49 MB (58.57 million rows/s., 5.13 GB/s.)
ここでは、ngramサイズを3にしてマッチングする必要があります。そのため、ngrambf_v1索引を作成します。
CREATE TABLE otel_logs_bloom
(
`Body` String,
`Timestamp` DateTime,
`ServiceName` LowCardinality(String),
`Status` UInt16,
`RequestProtocol` LowCardinality(String),
`RunTime` UInt32,
`Size` UInt32,
`UserAgent` String,
`Referer` String,
`RemoteUser` String,
`RequestType` LowCardinality(String),
`RequestPath` String,
`RemoteAddress` IPv4,
`RefererDomain` String,
`RequestPage` String,
`SeverityText` LowCardinality(String),
`SeverityNumber` UInt8,
INDEX idx_span_attr_value Referer TYPE ngrambf_v1(3, 10000, 3, 7) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY (Timestamp)
索引 ngrambf_v1(3, 10000, 3, 7) は4つのパラメータを取ります。最後のパラメータ(値7)はシード値を表します。その他のパラメータは、ngramサイズ(3)、値 m(フィルタサイズ)、ハッシュ関数の数 k(7)を表します。k と m はチューニングが必要であり、一意のngram/トークンの数とフィルタが真陰性を返す確率(つまり、値がグラニュール内に存在しないことを確認する確率)に基づいて設定されます。これらの値を決定するには、これらの関数を参照することを推奨します。
適切にチューニングされた場合、ここでの高速化は大幅なものになります:
SELECT count()
FROM otel_logs_bloom
WHERE Referer LIKE '%ultra%'
┌─count()─┐
│ 182 │
└─────────┘
1 row in set. Elapsed: 0.077 sec. Processed 4.22 million rows, 375.29 MB (54.81 million rows/s., 4.87 GB/s.)
Peak memory usage: 129.60 KiB.
例示のみ
上記は説明目的のみです。トークンベースのブルームフィルタを使用してテキスト検索を最適化しようとするのではなく、挿入時にログから構造を抽出することを推奨します。ただし、スタックトレースやその他の大きなStringを持つ場合など、構造が不確定なためにテキスト検索が有用となるケースも存在します。
ブルームフィルタの使用に関する一般的なガイドライン:
ブルームフィルタの目的はグラニュールをフィルタリングすることであり、カラムのすべての値を読み込んで線形スキャンを実行する必要をなくします。EXPLAIN句にパラメータindexes=1を指定することで、スキップされたグラニュールの数を確認できます。元のテーブルotel_logs_v2とngramブルームフィルタを持つテーブルotel_logs_bloomに対する以下のレスポンスを参照してください。
EXPLAIN indexes = 1
SELECT count()
FROM otel_logs_v2
WHERE Referer LIKE '%ultra%'
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter ((WHERE + Change column names to column identifiers)) │
│ ReadFromMergeTree (default.otel_logs_v2) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 9/9 │
│ Granules: 1278/1278 │
└────────────────────────────────────────────────────────────────────┘
10 rows in set. Elapsed: 0.016 sec.
EXPLAIN indexes = 1
SELECT count()
FROM otel_logs_bloom
WHERE Referer LIKE '%ultra%'
┌─explain────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter ((WHERE + Change column names to column identifiers)) │
│ ReadFromMergeTree (default.otel_logs_bloom) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 8/8 │
│ Granules: 1276/1276 │
│ Skip │
│ Name: idx_span_attr_value │
│ Description: ngrambf_v1 GRANULARITY 1 │
│ Parts: 8/8 │
│ Granules: 517/1276 │
└────────────────────────────────────────────────────────────────────┘
ブルームフィルタは、カラム自体よりも小さい場合にのみ高速化の効果が得られます。フィルタの方が大きい場合、パフォーマンス上のメリットはほとんど期待できません。以下のクエリを使用して、フィルタのサイズとカラムのサイズを比較してください:
SELECT
name,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (`table` = 'otel_logs_bloom') AND (name = 'Referer')
GROUP BY name
ORDER BY sum(data_compressed_bytes) DESC
┌─name────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ Referer │ 56.16 MiB │ 789.21 MiB │ 14.05 │
└─────────┴─────────────────┴───────────────────┴───────┘
1 row in set. Elapsed: 0.018 sec.
SELECT
`table`,
formatReadableSize(data_compressed_bytes) AS compressed_size,
formatReadableSize(data_uncompressed_bytes) AS uncompressed_size
FROM system.data_skipping_indices
WHERE `table` = 'otel_logs_bloom'
┌─table───────────┬─compressed_size─┬─uncompressed_size─┐
│ otel_logs_bloom │ 12.03 MiB │ 12.17 MiB │
└─────────────────┴─────────────────┴───────────────────┘
1 row in set. Elapsed: 0.004 sec.
上記の例では、セカンダリブルームフィルタ索引は12MBであり、カラム自体の圧縮サイズ56MBと比較して約5分の1のサイズであることがわかります。
ブルームフィルタは大幅なチューニングが必要になる場合があります。最適な設定を特定するために、こちらのノートを参照することを推奨します。また、ブルームフィルタはインサート時およびマージ時にコストがかかる場合があります。本番環境にブルームフィルタを追加する前に、インサートパフォーマンスへの影響を評価してください。
Map 型は OTel のスキーマで広く使用されています。この型では、値とキーが同じ型である必要があり、Kubernetes のラベルのようなメタデータには十分です。Map 型のサブキーに対してクエリを実行する場合、親のカラム全体が読み込まれる点に注意してください。マップに多くのキーがあると、キーが個別のカラムとして存在する場合と比べてディスクから読み取るデータ量が増えるため、クエリの実行コストが大きくなる可能性があります。
特定のキーに対して頻繁にクエリを実行する場合は、そのキーをルート階層に専用のカラムとして切り出すことを検討してください。これは通常、よくあるアクセスパターンやデプロイ後の利用状況に応じて行われるタスクであり、本番稼働前に予測するのは難しい場合があります。デプロイ後にスキーマをどのように変更するかについては、"Managing schema changes" を参照してください。
テーブルサイズと圧縮の測定
ClickHouse がオブザーバビリティに利用される主な理由の 1 つは圧縮です。
ストレージコストを大幅に削減できるだけでなく、ディスク上のデータ量が少ないほど I/O が減り、クエリおよび挿入処理は高速になります。I/O の削減効果は、CPU 使用量の観点では、どのような圧縮アルゴリズムによるオーバーヘッドよりも大きくなります。したがって、ClickHouse のクエリを高速に保つためにチューニングする際は、まずデータの圧縮を向上させることに注力すべきです。
圧縮の測定方法に関する詳細はこちらを参照してください。