ClickHouse Cloud の監視
このガイドでは、ClickHouse Cloud を評価しているエンタープライズチーム向けに、本番環境デプロイメントにおける監視およびオブザーバビリティ機能についての包括的な情報を提供します。エンタープライズのお客様からは、すぐに利用できる監視機能、Datadog や AWS CloudWatch などのツールを含む既存のオブザーバビリティスタックとの統合、そして ClickHouse の監視機能がセルフホスト型デプロイメントとどのように比較されるのかについて、頻繁にお問い合わせをいただきます。
高度なオブザーバビリティダッシュボード
ClickHouse Cloud では、Monitoring セクションからアクセス可能な組み込みダッシュボードインターフェースを通じて包括的なモニタリング機能を提供します。これらのダッシュボードは、追加のセットアップ不要でリアルタイムにシステムおよびパフォーマンスメトリクスを可視化し、ClickHouse Cloud における本番環境のリアルタイム監視の主要なツールとして機能します。
- Advanced Dashboard: Monitoring → Advanced dashboard からアクセス可能なメインのダッシュボードインターフェースであり、クエリレート、リソース使用状況、システムヘルス、およびストレージパフォーマンスをリアルタイムで可視化します。このダッシュボードは別途の認証を必要とせず、インスタンスのアイドル状態を妨げず、本番システムへのクエリ負荷も追加しません。各可視化はカスタマイズ可能な SQL クエリによって動作し、ClickHouse 固有メトリクス、システムヘルス、Cloud 固有メトリクスのグループごとに標準提供のチャートが用意されています。ユーザーは SQL コンソールでカスタムクエリを直接作成することで、モニタリングを拡張できます。
これらのメトリクスへアクセスしても、基盤となるサービスへのクエリは発行されず、アイドル状態のサービスを起動することもありません。
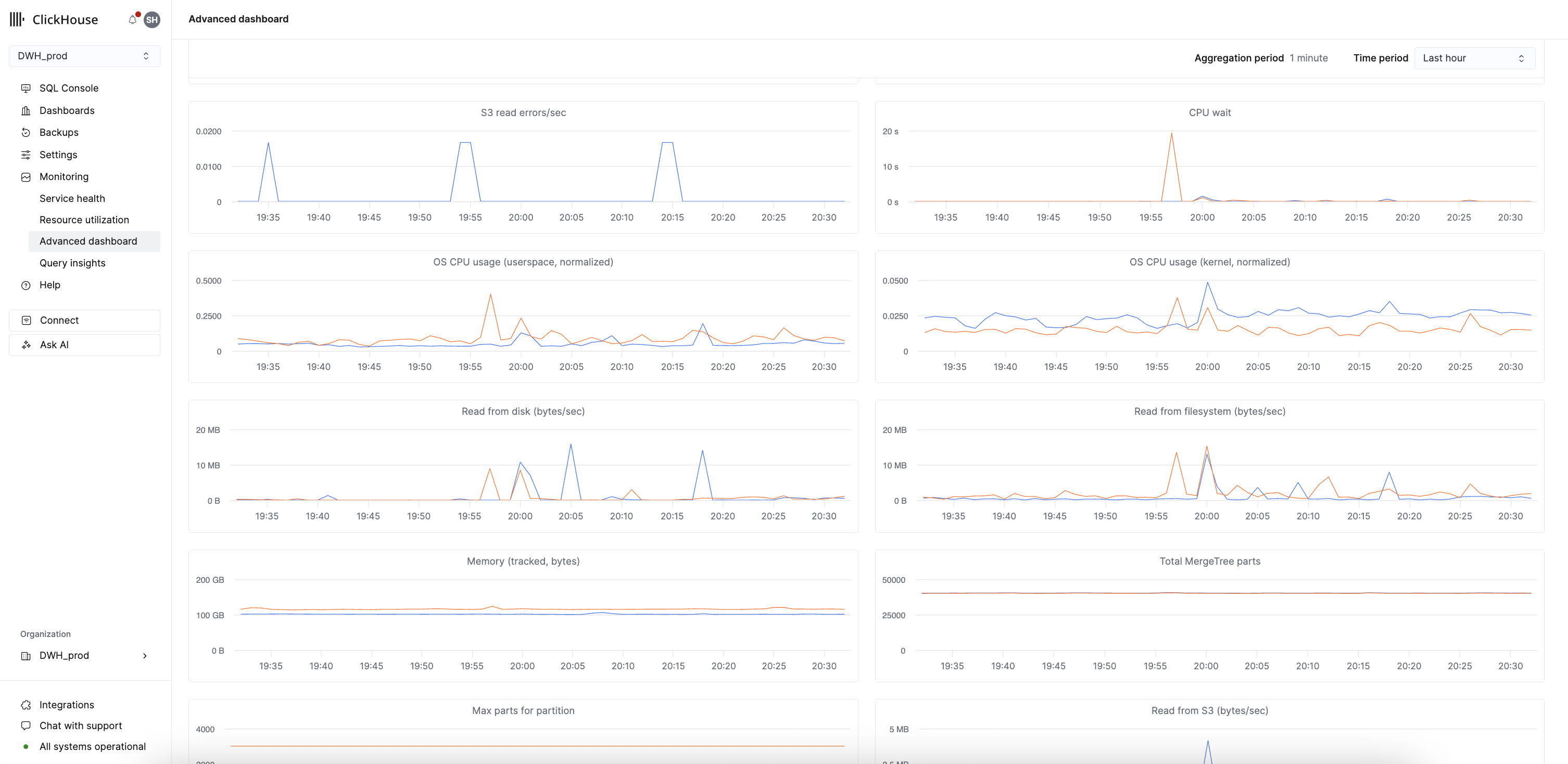
これらの可視化をさらに拡張したいユーザーは、ClickHouse Cloud のダッシュボード機能を利用し、システムテーブルに対して直接クエリを実行できます。
- ネイティブ Advanced Dashboard: Monitoring セクション内の "You can still access the native advanced dashboard" からアクセス可能な代替ダッシュボードインターフェースです。これは別タブで開かれ、認証が必要となり、システムおよびサービスヘルスのモニタリング向けの代替 UI を提供します。このダッシュボードでは、ユーザーが基盤となる SQL クエリを変更できる高度な分析が可能です。
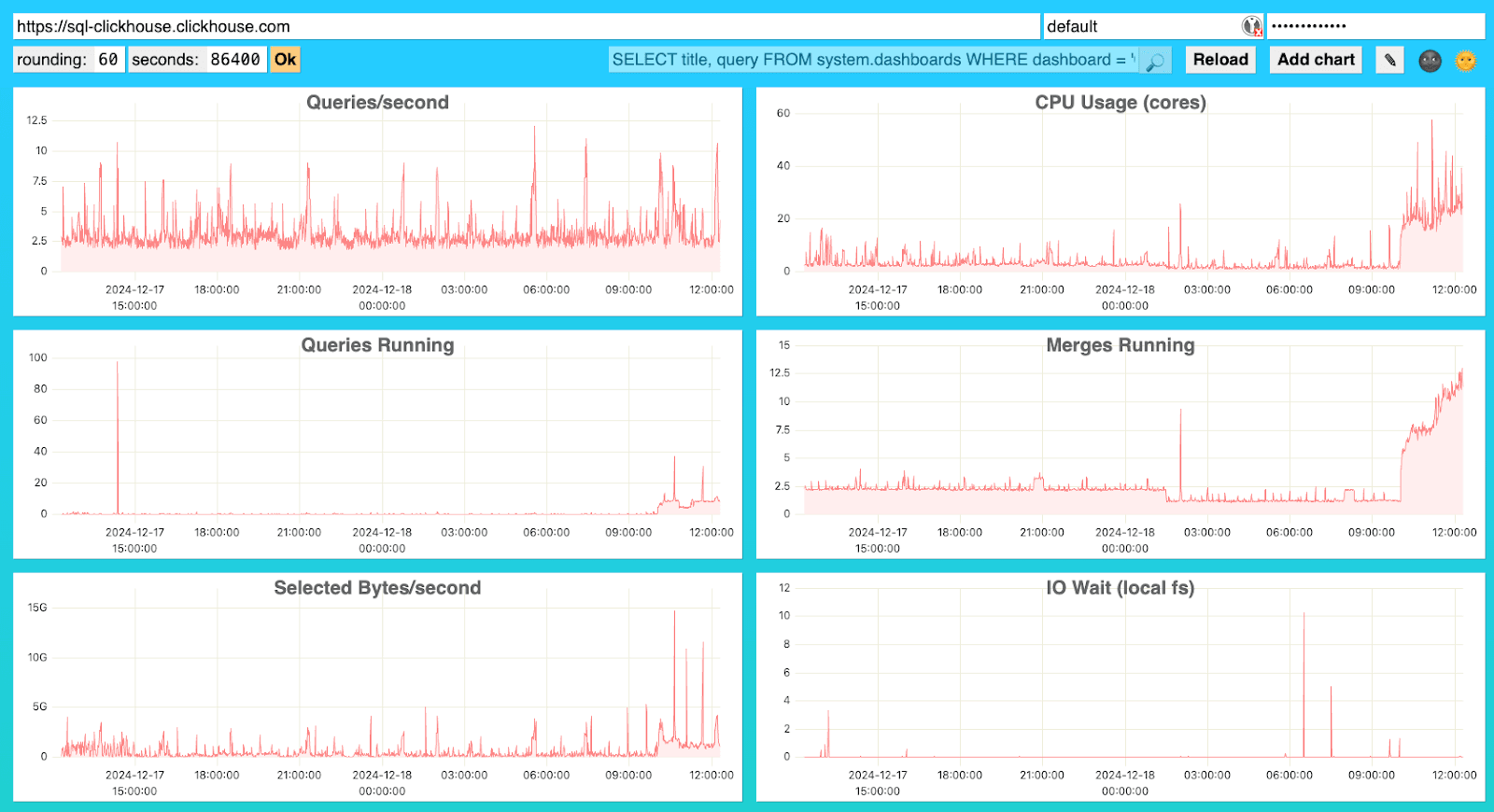
どちらのダッシュボードも外部コンポーネントに依存することなくサービスヘルスとパフォーマンスを即座に可視化でき、ClickStack のようなデバッグ特化の外部ツールとは一線を画しています。
ダッシュボードの詳細な機能および利用可能なメトリクスについては、高度なダッシュボードに関するドキュメントを参照してください。
クエリインサイトとリソース監視
ClickHouse Cloud には、次の追加監視機能が含まれます:
- Query Insights: クエリパフォーマンスの分析およびトラブルシューティングのための組み込みインターフェース
- Resource Utilization Dashboard: メモリ、CPU 割り当て、およびデータ転送パターンを追跡します。CPU 使用率とメモリ使用率のグラフは、指定した期間内での最大利用率メトリクスを表示します。CPU 使用率グラフはシステムレベルの CPU 利用率メトリクスを示しており、ClickHouse の CPU 利用率メトリクスではありません。
詳細な機能については、query insights および resource utilization のドキュメントを参照してください。
Prometheus 互換メトリクスエンドポイント
ClickHouse Cloud は Prometheus エンドポイントを提供します。これにより、ユーザーは既存のワークフローを維持し、チームが持つ既存の専門知識を活用しながら、ClickHouse のメトリクスを Grafana、Datadog、その他の Prometheus 互換ツールを含むエンタープライズ向け監視プラットフォームに統合できます。
組織レベルのエンドポイントはすべてのサービスからメトリクスをフェデレーションし、サービスごとのエンドポイントではよりきめ細かな監視が可能です。主な特長は次のとおりです。
- フィルタリング済みメトリクスオプション: オプションの
filtered_metrics=trueパラメータにより、1000 を超える利用可能なメトリクスから、コスト最適化と監視対象の明確化のために 125 個の「ミッションクリティカル」なメトリクスにペイロードを絞り込みます - キャッシュされたメトリクス配信: 本番システムへのクエリ負荷を最小化するため、1 分ごとに更新されるマテリアライズドビューを使用します
このアプローチはサービスのアイドル状態を尊重し、サービスがクエリを積極的に処理していないときにコスト最適化を可能にします。この API エンドポイントは ClickHouse Cloud の API 認証情報を利用します。エンドポイント構成の詳細については、ClickHouse Cloud の Prometheus ドキュメント を参照してください。
連携例
外部連携を活用することで、組織は既存のモニタリングワークフローを維持しつつ、慣れ親しんだツールに関するチームの専門性を生かし、現在のプロセスを妨げたり大規模な再トレーニング投資を行ったりすることなく、ClickHouse のモニタリングをインフラ全体のオブザーバビリティに統合できます。 チームは既存のアラートルールやエスカレーション手順を ClickHouse のメトリクスに適用しつつ、統合されたオブザーバビリティプラットフォーム上で、アプリケーションおよびインフラのヘルスとデータベースパフォーマンスを関連付けて把握できます。このアプローチにより、現行のモニタリング環境への投資効果を最大化し、統合されたダッシュボードと使い慣れたツールインターフェースを通じて、トラブルシューティングをより迅速に行えるようになります。
Grafana Cloud によるモニタリング
Grafana は、ネイティブプラグイン連携と Prometheus ベースのアプローチの両方を通じて ClickHouse のモニタリングを提供します。Prometheus エンドポイント連携により、モニタリングワークロードと本番ワークロードの運用上の分離を維持しながら、既存の Grafana Cloud インフラ内での可視化を可能にします。設定方法については Grafana の ClickHouse ドキュメント を参照してください。
Datadog によるモニタリング
Datadog は、サービスのアイドル状態の挙動を考慮しつつ、適切なクラウドサービスモニタリングを提供する専用の API 連携を開発中です。それまでの間、チームは ClickHouse の Prometheus エンドポイント経由で OpenMetrics 連携アプローチを利用することで、運用上の分離とコスト効率の高いモニタリングを実現できます。設定方法については Datadog の Prometheus および OpenMetrics 連携ドキュメント を参照してください。
ClickStack
ClickStack は、深いシステム解析とデバッグのために ClickHouse が推奨するオブザーバビリティソリューションであり、ClickHouse をストレージエンジンとして用いながら、ログ、メトリクス、トレースを統合的に扱うプラットフォームを提供します。このアプローチは、ClickStack の UI である HyperDX が ClickHouse インスタンス内の system テーブルに直接接続することに依存しています。 HyperDX には、Select、Insert、および Infrastructure のタブを備えた ClickHouse に特化したダッシュボードが標準で用意されています。チームは Lucene または SQL 構文を使用して system テーブルやログを検索できるほか、Chart Explorer を通じてカスタム可視化を作成し、詳細なシステム解析を行うこともできます。 このアプローチは、リアルタイムの本番アラートというよりも、複雑な問題のデバッグ、パフォーマンス解析、システムの深部に対する詳細な調査に最適です。
このアプローチでは、HyperDX が system テーブルに直接クエリを発行するため、アイドル状態のサービスが起動される点に注意してください。
ClickStack のデプロイオプション
- ClickHouse Cloud 上の HyperDX(プライベートプレビュー):HyperDX は任意の ClickHouse Cloud サービス上で起動できます。
- Helm:Kubernetes ベースのデバッグ用環境に推奨されます。ClickHouse Cloud との連携をサポートし、
values.yamlを通じて環境固有の設定、リソース制限、およびスケーリングを行えます。 - Docker Compose:各コンポーネント(ClickHouse、HyperDX、OTel collector、MongoDB)を個別にデプロイします。特に ClickHouse Cloud と連携する際には、compose ファイルを変更して、ClickHouse や OpenTelemetry Collector など未使用のコンポーネントを削除できます。
- HyperDX のみ:スタンドアロンの HyperDX コンテナ。
利用可能なデプロイオプションやアーキテクチャの詳細については、ClickStack のドキュメントおよびデータインジェストガイドを参照してください。
ClickHouse Cloud の Prometheus エンドポイントから OpenTelemetry Collector 経由でメトリクスを収集し、可視化のために別の ClickStack デプロイメントへ転送することもできます。
Grafana プラグインによる直接統合
Grafana 向け ClickHouse データソースプラグインを使用すると、ClickHouse のシステムテーブルを利用して、ClickHouse から直接データを可視化および探索できます。このアプローチは、パフォーマンスの監視や、詳細なシステム分析のためのカスタムダッシュボードの作成に適しています。 プラグインのインストールおよび設定の詳細については、ClickHouse の data source plugin を参照してください。あらかじめ作成されたダッシュボードとアラートルールを備えた Prometheus-Grafana ミックスインを用いた完全な監視セットアップについては、Monitor ClickHouse with the new Prometheus-Grafana mix-in を参照してください。
Datadog との直接統合
Datadog は、エージェント向けに ClickHouse Monitoring プラグインを提供しており、システムテーブルに直接クエリを実行します。この統合により、clusterAllReplicas 機能を通じてクラスタを意識した包括的なデータベース監視が可能になります。
この統合は、コスト最適化を目的としたアイドル時の動作との非互換性およびクラウドプロキシレイヤーの運用上の制約により、ClickHouse Cloud のデプロイメントでは推奨されません。
システムテーブルを直接利用する
特に system.query_log などの ClickHouse システムテーブルに接続して直接クエリを実行することで、クエリパフォーマンスの詳細な分析を行うことができます。SQL コンソールまたは clickhouse client を使用することで、チームは低速クエリを特定し、リソース使用状況を分析し、組織全体にわたる利用パターンを追跡できます。
クエリパフォーマンス分析
システムテーブルのクエリログを使用してクエリパフォーマンス分析を実行できます。
クエリ例: すべてのクラスタレプリカにまたがる実行時間の長いクエリ上位 5 件を抽出します:
コミュニティによる監視ソリューション
ClickHouse コミュニティは、一般的なオブザーバビリティスタックと連携する包括的な監視ソリューションを開発しています。ClickHouse Monitoring は、あらかじめ用意されたダッシュボードを備えた完全な監視環境を提供します。このオープンソースプロジェクトは、確立されたベストプラクティスと実績のあるダッシュボード構成に基づいて ClickHouse の監視を導入したいチームに、迅速に開始するための手段を提供します。
他のデータベースの直接監視アプローチと同様に、このソリューションは ClickHouse の system テーブルに直接クエリを実行するため、インスタンスがアイドル状態になるのを防ぎ、その結果コスト最適化に影響します。
システムへの影響に関する考慮事項
上記のアプローチはいずれも、Prometheus エンドポイントへの依存、ClickHouse Cloud による管理、またはシステムテーブルへの直接クエリのいずれか、もしくはそれらの組み合わせを利用します。 このうち後者の選択肢は、本番環境の ClickHouse サービスへのクエリに依存します。これは監視対象システムへのクエリ負荷を増加させ、ClickHouse Cloud インスタンスがアイドル状態になることを防ぐため、コスト最適化に影響します。さらに、本番システムが障害を起こした場合、両者が密結合しているために監視も影響を受ける可能性があります。このアプローチは詳細な内部観察やデバッグには有効ですが、リアルタイムな本番監視にはあまり適していません。直接的な Grafana 連携と、次のセクションで説明する外部ツール連携アプローチを評価する際には、詳細なシステム分析能力と運用上のオーバーヘッドとのトレードオフを考慮してください。
