ClickStack と Elastic の同等概念
Elastic Stack と ClickStack の比較
Elastic Stack と ClickStack はどちらもオブザーバビリティプラットフォームの中核的な役割をカバーしていますが、その役割に対する設計思想は異なります。これらの役割には次のものが含まれます:
- UI とアラート: データのクエリ、ダッシュボードの構築、アラートの管理を行うツール。
- ストレージとクエリエンジン: オブザーバビリティデータの保存と分析クエリの提供を担うバックエンドシステム。
- データ収集と ETL: テレメトリデータを収集し、インジェスト前に処理するエージェントおよびパイプライン。
以下の表は、各スタックがこれらの役割に対してどのコンポーネントを対応させているかを示したものです:
| Role | Elastic Stack | ClickStack | Comments |
|---|---|---|---|
| UI & Alerting | Kibana — ダッシュボード、検索、アラート | ClickStack UI (HyperDX) — リアルタイム UI、検索、アラート | いずれもユーザー向けの主要インターフェイスであり、可視化とアラート管理を提供します。ClickStack UI はオブザーバビリティ向けに特化して設計されており、OpenTelemetry のセマンティクスと密接に結合しています。 |
| Storage & Query Engine | Elasticsearch — 倒立インデックスを持つ JSON ドキュメントストア | ClickHouse — ベクトル化エンジンを備えたカラム指向データベース | Elasticsearch は検索に最適化された倒立インデックスを使用し、ClickHouse はカラムナストレージと SQL を用いて、構造化および半構造化データに対する高速な分析を実現します。 |
| Data Collection | Elastic Agent、Beats(例: Filebeat, Metricbeat) | OpenTelemetry Collector(エッジ + ゲートウェイ) | Elastic はカスタムシッパーと、Fleet によって管理される統合エージェントをサポートします。ClickStack は OpenTelemetry を採用しており、ベンダーニュートラルなデータ収集と処理を可能にします。 |
| Instrumentation SDKs | Elastic APM agents(プロプライエタリ) | OpenTelemetry SDKs(ClickStack により提供) | Elastic の SDK は Elastic スタックに密接に結び付けられています。ClickStack は主要言語向けのログ、メトリクス、トレースについて OpenTelemetry SDKs を基盤として構築しています。 |
| ETL / Data Processing | Logstash、インジェストパイプライン | OpenTelemetry Collector + ClickHouse マテリアライズドビュー | Elastic は変換処理にインジェストパイプラインと Logstash を使用します。ClickStack は、マテリアライズドビューと OTel collector のプロセッサを通じて計算を挿入時に移し、データを効率的かつ増分的に変換します。 |
| Architecture Philosophy | 垂直統合されたプロプライエタリなエージェントとフォーマット | オープンスタンダードに基づく疎結合コンポーネント | Elastic は密接に統合されたエコシステムを構築しています。ClickStack はモジュール性と標準(OpenTelemetry、SQL、オブジェクトストレージ)を重視し、柔軟性とコスト効率を高めています。 |
ClickStack は、収集から UI まで完全に OpenTelemetry ネイティブであり、オープンスタンダードと相互運用性を重視しています。対照的に、Elastic はプロプライエタリなエージェントとフォーマットを用いた、より垂直統合された密結合のエコシステムを提供します。
それぞれのスタックにおいてデータの保存、処理、クエリを担う中核エンジンが Elasticsearch と ClickHouse であることを踏まえると、両者の違いを理解することが重要です。これらのシステムは、オブザーバビリティアーキテクチャ全体の性能、スケーラビリティ、柔軟性を支える基盤となります。次のセクションでは、Elasticsearch と ClickHouse の主要な違いを、データモデル、インジェスト処理、クエリ実行、ストレージ管理の方法を含めて解説します。
Elasticsearch vs ClickHouse
ClickHouse と Elasticsearch は、データの構造化およびクエリ処理に異なる基盤モデルを用いますが、多くの中核的な概念は似た役割を果たします。このセクションでは、Elastic に慣れたユーザー向けに、主要な概念の対応関係を示し、それらを ClickHouse 側の概念にマッピングします。用語こそ異なるものの、ほとんどのオブザーバビリティ向けワークフローは ClickStack 上で再現でき、しかも多くの場合、より効率的に実行できます。
基本的な構造の概念
| Elasticsearch | ClickHouse / SQL | 説明 |
|---|---|---|
| Field | Column | データの基本単位であり、特定の型の 1 つ以上の値を保持します。Elasticsearch のフィールドは、プリミティブ値に加えて配列やオブジェクトも格納できます。フィールドは 1 つの型しか持てません。ClickHouse も配列やオブジェクト(Tuples、Maps、Nested)をサポートしており、さらに Variant や Dynamic のような動的型もサポートしていて、1 つのカラムに複数の型を持たせることができます。 |
| Document | Row | フィールド(カラム)の集合です。Elasticsearch のドキュメントはデフォルトで柔軟性が高く、データに基づいて新しいフィールドが動的に追加されます(型はそこから推論されます)。ClickHouse の行はデフォルトでスキーマに基づいて定義されており、ユーザーは行に対してすべてのカラム、またはそのサブセットを挿入する必要があります。ClickHouse の JSON 型は、挿入されるデータに基づく、同等の半構造化かつ動的なカラム作成をサポートします。 |
| Index | Table | クエリ実行とストレージの単位です。どちらのシステムでも、クエリは行/ドキュメントを格納しているインデックスまたはテーブルに対して実行されます。 |
| Implicit | Schema (SQL) | SQL のスキーマはテーブルをネームスペースにグループ化し、多くの場合アクセス制御に利用されます。Elasticsearch と ClickHouse にはスキーマという概念はありませんが、どちらもロールと RBAC による行レベルおよびテーブルレベルのセキュリティをサポートしています。 |
| Cluster | Cluster / Database | Elasticsearch のクラスターは、1 つ以上のインデックスを管理するランタイムインスタンスです。ClickHouse では、データベースが論理的なネームスペース内でテーブルを整理しており、Elasticsearch のクラスターと同等の論理的なグルーピングを提供します。ClickHouse クラスターは分散されたノードの集合であり、Elasticsearch と同様ですが、データ自体とは分離され独立しています。 |
データモデリングと柔軟性
Elasticsearch は、dynamic mappings によるスキーマの柔軟性で知られています。ドキュメントのインジェスト時にフィールドが作成され、スキーマが指定されていない限り、その型は自動的に推論されます。ClickHouse はデフォルトではより厳格であり、テーブルは明示的なスキーマで定義されますが、Dynamic、Variant、JSON 型によって柔軟性も提供します。これらにより、Elasticsearch と同様に、動的なカラム作成と型推論を伴う半構造化データのインジェストが可能になります。同様に、Map 型は任意のキーと値のペアを保存できますが、キーと値の両方に対して 1 つの型が強制されます。
ClickHouse における型の柔軟性へのアプローチは、より透過的で制御しやすいものです。インジェスト時の型の不一致がエラーの原因となり得る Elasticsearch と異なり、ClickHouse では Variant カラム内での混在型データを許容し、JSON 型の利用を通じてスキーマの進化をサポートします。
JSON を使用しない場合、スキーマは静的に定義されます。行に対して値が提供されない場合、それらは Nullable(ClickStack では未使用)として定義されるか、その型のデフォルト値、例えば String 型であれば空値が使用されます。
インジェストと変換
Elasticsearch では、インデックス作成前にドキュメントを変換するために、enrich、rename、grok などのプロセッサを備えた ingest パイプラインを使用します。ClickHouse では、同様の機能は インクリメンタルなマテリアライズドビュー によって実現されます。これにより、受信データをフィルタリングや変換したり、エンリッチしたりして、その結果を対象テーブルに挿入できます。マテリアライズドビューの出力だけを保存したい場合は、Null テーブルエンジンにデータを挿入することもできます。これは、すべてのマテリアライズドビューの結果のみが保持され、元のデータは破棄されることを意味し、その分ストレージ容量を節約できます。
データのエンリッチを行うために、Elasticsearch はドキュメントにコンテキストを追加する専用の enrich processors をサポートしています。ClickHouse では、辞書 (dictionaries) を クエリ時と インジェスト時の両方で使用して行をエンリッチできます。例えば、IP をロケーションにマッピングしたり、挿入時に ユーザーエージェントのルックアップ を適用したりできます。
クエリ言語
Elasticsearch は、DSL、ES|QL、EQL、KQL(Lucene 形式)クエリを含む複数のクエリ言語をサポートしていますが、結合のサポートは限定的で、左外部結合のみがES|QL経由で利用可能です。ClickHouse は 完全な SQL 構文 をサポートしており、すべての結合タイプ、ウィンドウ関数、サブクエリ(相関サブクエリを含む)、および CTE を利用できます。これは、オブザーバビリティ シグナルとビジネスデータやインフラストラクチャデータとの間を相関付ける必要がある場合に、大きな利点となります。
ClickStack では、UI が Lucene 互換の検索インターフェースを提供し、スムーズな移行を支援するとともに、ClickHouse バックエンド経由で完全な SQL サポートも提供します。この構文は、Elastic query string 構文と同等のものです。この構文の詳細な比較については、"Searching in ClickStack and Elastic" を参照してください。
ファイル形式とインターフェース
Elasticsearch は JSON(および限定的な CSV)のインジェストをサポートしています。ClickHouse は Parquet、Protobuf、Arrow、CSV などを含む 70 を超えるファイル形式を、インジェストとエクスポートの両方でサポートしています。これにより、外部のパイプラインやツールとの連携が容易になります。
どちらのシステムも REST API を提供しますが、ClickHouse はさらに、低レイテンシかつ高スループットなやり取りのための ネイティブプロトコル も提供しています。ネイティブインターフェースは、HTTP よりも効率的にクエリの進行状況、圧縮、およびストリーミングをサポートしており、本番環境でのインジェストの大半でデフォルトとして利用されています。
インデックス作成とストレージ
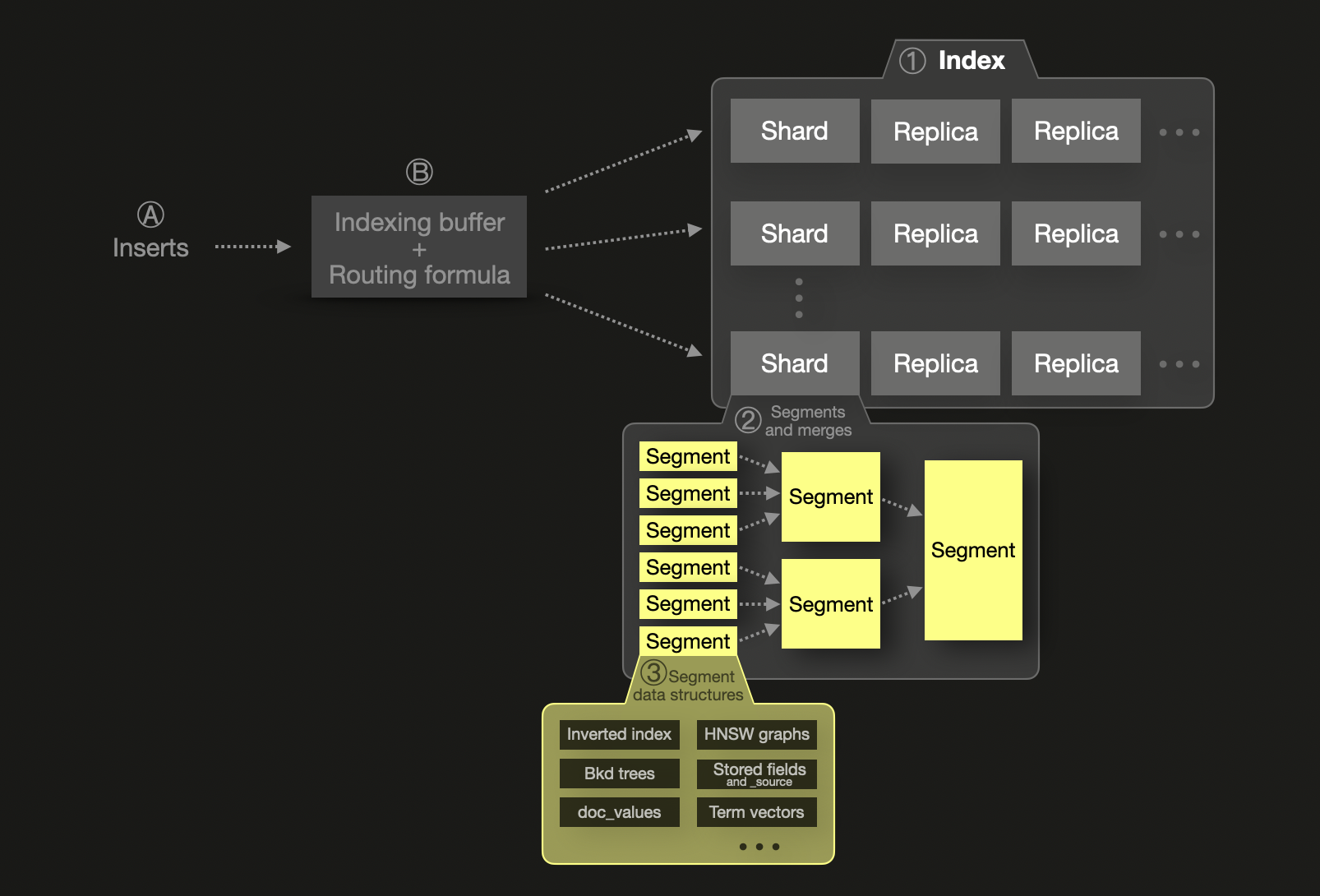
シャーディングの概念は、Elasticsearch のスケーラビリティモデルの根幹をなすものです。各 ① index は shard に分割され、それぞれがディスク上のセグメントとして保存される物理的な Lucene インデックスです。シャードは、レジリエンス向上のために replica shard と呼ばれる 1 つ以上の物理コピーを持つことができます。スケーラビリティ向上のために、シャードとレプリカは複数ノードに分散できます。単一のシャード ② は 1 つ以上のイミュータブルなセグメントで構成されます。セグメントは Lucene(Elasticsearch が基盤として利用している、インデックス作成と検索機能を提供する Java ライブラリ)の基本的なインデックス構造です。
Ⓐ 新規に挿入されたドキュメントは、まず Ⓑ インメモリのインデックスバッファに入り、デフォルトでは 1 秒ごとにフラッシュされます。フラッシュされたドキュメントに対してはルーティング式が用いられ、対象シャードが決定され、ディスク上のそのシャード向けに新しいセグメントが書き込まれます。クエリ効率を高め、削除済みまたは更新済みドキュメントを物理的に削除できるようにするために、セグメントはバックグラウンドで継続的にマージされ、最大サイズ 5 GB に達するまで、より大きなセグメントに統合されます。ただし、さらに大きなセグメントへのマージを強制することも可能です。
Elasticsearch は、JVM ヒープおよびメタデータのオーバーヘッド のため、シャードサイズを 約 50 GB または 2 億ドキュメント にすることを推奨しています。また、シャードあたり 20 億ドキュメント というハードリミットも存在します。Elasticsearch はクエリをシャード間で並列化しますが、各シャードは 単一スレッド で処理されるため、シャードを増やしすぎるとコストが高く、逆効果になります。この特性により、シャーディングとスケーリングは本質的に強く結び付けられ、性能をスケールさせるには、より多くのシャード(およびノード)が必要になります。
Elasticsearch は高速な検索のために、すべてのフィールドを inverted indices にインデックス化し、オプションで集約、ソート、スクリプトフィールドアクセスのために doc values を使用します。数値および地理空間フィールドは、地理空間データならびに数値・日付レンジ検索のために Block K-D trees を使用します。
重要な点として、Elasticsearch は元のドキュメント全体を _source に保存します(LZ4、Deflate、ZSTD で圧縮)。一方、ClickHouse は別個のドキュメント表現を保存しません。データはクエリ時にカラムから再構成されるため、ストレージ容量を節約できます。同様の機能は、いくつかの制約 はあるものの、Elasticsearch では Synthetic _source を使うことで実現可能です。_source を無効化すると、ClickHouse には当てはまらない影響 も発生します。
Elasticsearch では、index mappings(ClickHouse におけるテーブルスキーマに相当)が、永続化およびクエリに使用されるフィールドタイプとデータ構造を制御します。
対照的に、ClickHouse は カラム指向 です — すべてのカラムは独立して保存されますが、常にテーブルの primary/ordering key でソートされます。この並び順により 疎なプライマリインデックス が可能になり、ClickHouse はクエリ実行中に効率的にデータをスキップできます。クエリがプライマリキーのフィールドでフィルタリングを行うと、ClickHouse は各カラムの関連部分のみを読み込み、ディスク I/O を大幅に削減し、パフォーマンスを向上させます — すべてのカラムに完全なインデックスを持たせなくても同様です。
ClickHouse はさらに、選択したカラムに対してインデックスデータを事前計算することでフィルタリングを高速化する skip indexes もサポートしています。これらは明示的に定義する必要がありますが、パフォーマンスを大きく向上させることができます。加えて、ClickHouse ではカラムごとに compression codecs や圧縮アルゴリズムを指定できます — これは Elasticsearch にはない機能です(Elasticsearch の compression は _source JSON ストレージにのみ適用されます)。
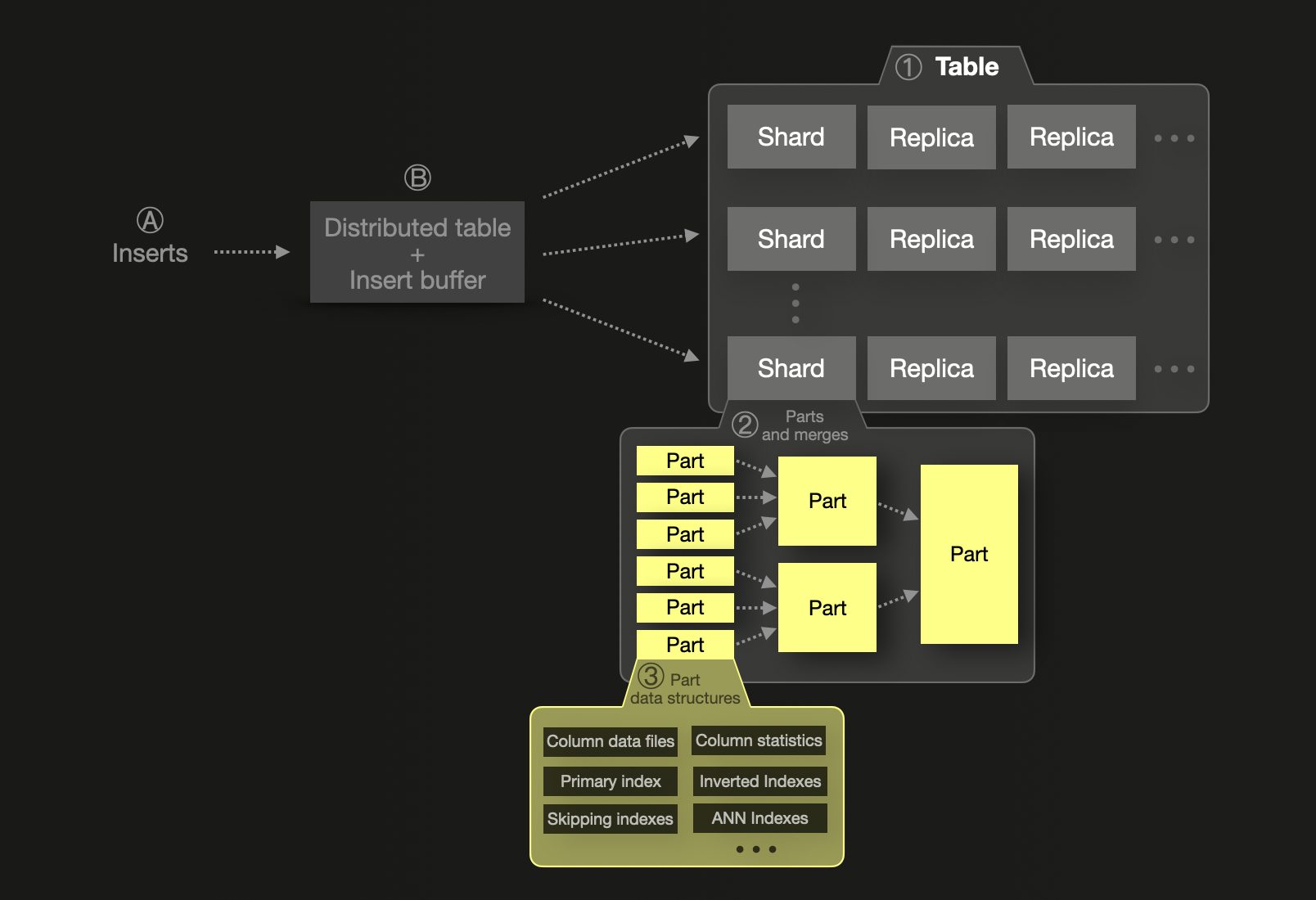
ClickHouse はシャーディングもサポートしていますが、そのモデルは垂直スケーリングを優先するよう設計されています。単一のシャードでも何兆行ものデータを保存でき、メモリ、CPU、ディスクが許す限り、高いパフォーマンスを維持できます。Elasticsearch と異なり、シャードごとの行数にハードリミットはありません。ClickHouse におけるシャードは論理的な概念であり、実質的には個々のテーブルに相当します。また、データセットが単一ノードの容量を超えない限り、パーティショニングは不要です。これは通常、ディスク容量の制約によって発生し、その場合にのみ水平方向のスケールアウトが必要になったタイミングでシャーディング①が導入されるため、複雑さとオーバーヘッドが抑えられます。このケースでは Elasticsearch と同様に、シャードはデータのサブセットを保持します。1 つのシャード内のデータは、②不変なデータパーツの集合として構成され、その内部に③複数のデータ構造が含まれています。
ClickHouse のシャード内での処理は完全に並列化されており、ノード間でデータを移動する際に発生するネットワークコストを避けるため、垂直スケーリングが推奨されます。
ClickHouse における挿入はデフォルトでは同期的であり、コミットが完了した後にのみ書き込みが確認されますが、Elasticsearch のようなバッファリングやバッチ処理に合わせて非同期挿入に構成することもできます。asynchronous data inserts を使用する場合、Ⓐ 新たに挿入された行はまず Ⓑ メモリ内の挿入バッファに入り、これは既定では 200 ミリ秒ごとにフラッシュされます。複数のシャードが使用されている場合は、新しく挿入された行をターゲットとなるシャードにルーティングするために distributed table が使用されます。ディスク上のそのシャード用に新しいパーツが書き込まれます。
分散とレプリケーション
Elasticsearch と ClickHouse はどちらも、スケーラビリティとフォールトトレランスを確保するためにクラスター、シャード、レプリカを利用しますが、そのモデルは実装やパフォーマンス特性の面で大きく異なります。
Elasticsearch はレプリケーションに プライマリ-セカンダリ モデルを使用します。データがプライマリシャードに書き込まれると、それは 1 つ以上のレプリカに同期的にコピーされます。これらのレプリカ自体がノード間に分散された完全なシャードとなり、冗長性を確保します。Elasticsearch は、必要なすべてのレプリカが処理を確認した後にのみ書き込みを確定します。このモデルはほぼ 逐次一貫性 を提供しますが、完全な同期が完了する前にレプリカから ダーティリード が発生する可能性があります。マスターノード がクラスターを調整し、シャードの割り当て、ヘルスチェック、リーダー選出を管理します。
一方、ClickHouse はデフォルトで 最終的な一貫性 (eventual consistency) を採用しており、Keeper(ZooKeeper の軽量な代替)によって調整されます。書き込みは任意のレプリカ、またはレプリカを自動選択する Distributed テーブル 経由で直接送信できます。レプリケーションは非同期であり、書き込みが確定された後に変更が他のレプリカへ伝播されます。より厳密な保証が必要な場合、ClickHouse は 逐次一貫性 をサポート しており、レプリカ全体へのコミット完了後にのみ書き込みを確定しますが、このモードはパフォーマンスへの影響が大きいため、実際にはあまり使用されません。Distributed テーブルは複数シャードにまたがるアクセスを統合し、SELECT クエリをすべてのシャードへフォワードして結果をマージします。INSERT 操作では、データをシャード間に均等にルーティングすることで負荷分散を行います。ClickHouse のレプリケーションは非常に柔軟であり、任意のレプリカ(シャードのコピー)が書き込みを受け付けることができ、すべての変更は他のレプリカへ非同期に同期されます。このアーキテクチャにより、障害やメンテナンス時にもクエリ提供を中断することなく、自動的に再同期が行われます。そのため、データレイヤー上でプライマリ-セカンダリモデルを強制する必要がありません。
ClickHouse Cloud では、アーキテクチャとして shared-nothing 型のコンピュートモデルが導入され、単一の シャードがオブジェクトストレージによって支えられる (backed) 形になります。これにより、従来のレプリカベースの高可用性が置き換えられ、シャードを 複数ノードから同時に読み書き可能 にします。ストレージとコンピュートを分離することで、明示的なレプリカ管理なしに弾性的なスケーリングが可能になります。
まとめると、次のとおりです。
- Elastic: シャードは JVM メモリに結びついた物理的な Lucene 構造です。シャード数を過剰に増やすとパフォーマンスペナルティが発生します。レプリケーションは同期型で、マスターノードによって調整されます。
- ClickHouse: シャードは論理的で垂直スケーラブルであり、ローカル実行が非常に効率的です。レプリケーションは非同期(ただし逐次一貫性にもできる)で、調整は軽量です。
最終的に、ClickHouse はシャードチューニングの必要性を最小限に抑えつつ、必要に応じて強い一貫性保証も提供することで、シンプルさとスケール時のパフォーマンスを重視しています。
重複排除とルーティング
Elasticsearch は _id に基づいてドキュメントを重複排除し、それに応じてシャードへルーティングします。ClickHouse はデフォルトの行識別子を持ちませんが、挿入時の重複排除 (insert-time deduplication) をサポートしており、ユーザーは失敗した挿入を安全に再試行できます。より細かく制御するには、ReplacingMergeTree などのテーブルエンジンを使用して、特定のカラムに基づく重複排除を行うことができます。
Elasticsearch におけるインデックスルーティングは、特定のドキュメントが常に特定のシャードにルーティングされることを保証します。ClickHouse では、シャードキー を定義するか、Distributed テーブルを使用することで、同様のデータ局所性を実現できます。
集約と実行モデル
両システムともデータの集約をサポートしていますが、ClickHouse は統計的、近似的、および特殊な分析関数を含む、はるかに多くの関数を提供します。
オブザーバビリティ用途において、集約の最も一般的な利用方法の 1 つは、特定のログメッセージやイベントがどれくらいの頻度で発生しているかをカウントし (頻度が異常な場合にアラートを出す) 、その頻度を把握することです。
ClickHouse における SELECT count(*) FROM ... GROUP BY ... SQL クエリに相当する Elasticsearch の機能は、Elasticsearch のバケット集約の一種である terms 集約です。
ClickHouse の GROUP BY と count(*)、および Elasticsearch の terms 集約は、機能面では概ね同等ですが、その実装、性能、および結果の品質は大きく異なります。
Elasticsearch におけるこの集約は、クエリ対象のデータが複数シャードにまたがる場合に、「トップ N」クエリ (例: カウント順の上位 10 ホスト) で結果を推定します。この推定により速度は向上しますが、精度が損なわれる可能性があります。ユーザーは doc_count_error_upper_bound を確認し、shard_size パラメータを増やすことでこの誤差を減らせますが、その代償としてメモリ使用量の増加とクエリ性能の低下が発生します。
Elasticsearch では、すべてのバケット集約に対して size 設定が必要であり、制限値を明示的に設定しないまま、すべての一意なグループを返す方法は存在しません。カーディナリティの高い集約では、max_buckets 制限に達するリスクがあるか、composite 集約を使ったページングが必要になりますが、これはしばしば複雑で非効率です。
対照的に、ClickHouse はデフォルトで正確な集約を実行します。count(*) のような関数は、設定を調整しなくても正確な結果を返すため、クエリの挙動がより単純で予測しやすくなります。
ClickHouse はサイズ制限を課しません。大規模なデータセットに対して、無制限の group-by クエリを実行できます。メモリ閾値を超えた場合、ClickHouse はディスクへのスピルを行うことができます。主キーのプレフィックスでグループ化する集約は特に効率的で、多くの場合、最小限のメモリ消費で実行されます。
実行モデル
上記の違いは、Elasticsearch と ClickHouse の実行モデルの違いに起因します。両者は、クエリ実行と並列性に対して根本的に異なるアプローチを取っています。
ClickHouse は、モダンなハードウェア上での効率を最大化するよう設計されています。デフォルトでは、CPU コア数が N のマシン上で、ClickHouse は SQL クエリを N 本の同時実行レーンで処理します。
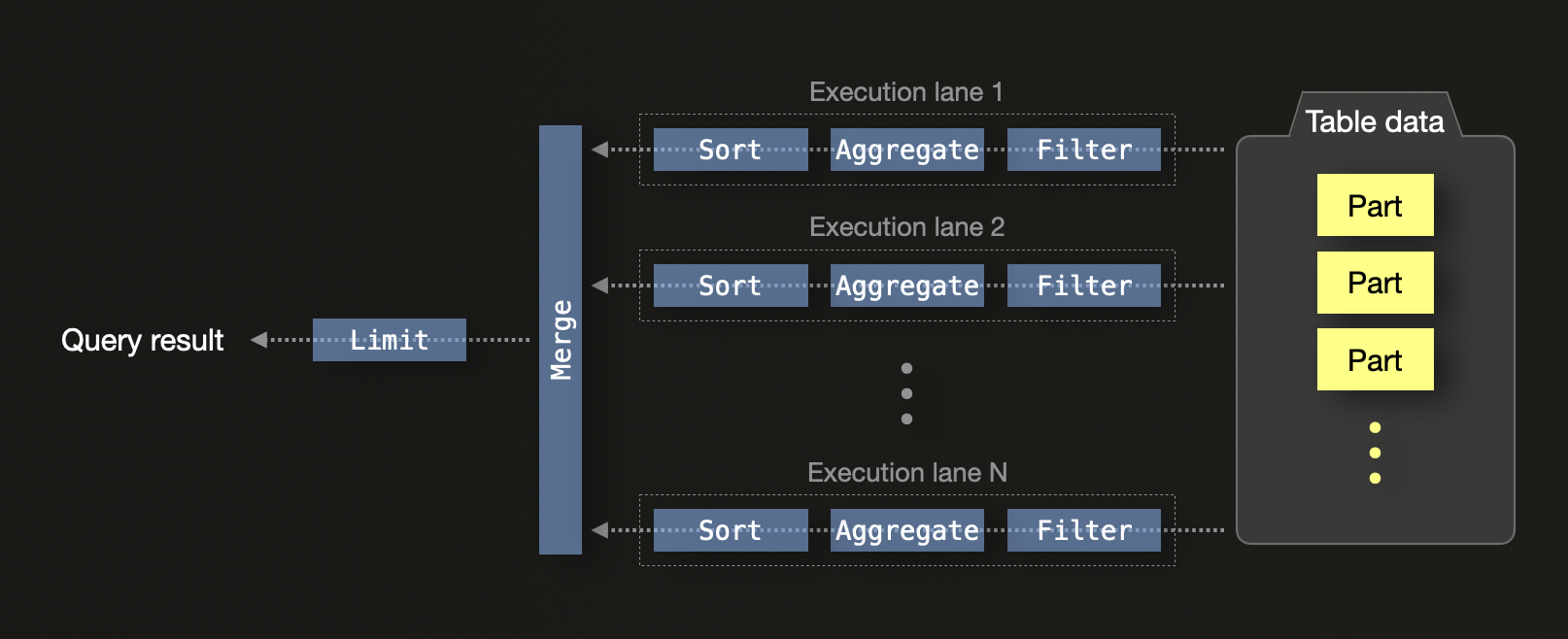
単一ノード上では、実行レーンがデータを独立した範囲に分割し、CPU スレッド間で同時に処理できるようにします。これにはフィルタリング、集約、ソートが含まれます。各レーンからのローカル結果は最終的にマージされ、クエリに LIMIT 句が含まれている場合は、LIMIT 演算子が適用されます。
クエリ実行は次のようにしてさらに並列化されます:
- SIMD ベクトル化: カラム型データに対する演算で CPU の SIMD 命令(例: AVX512)を利用し、値をバッチ処理します。
- クラスターレベルの並列性: 分散構成では、各ノードがローカルにクエリ処理を行います。部分集約状態 がクエリを開始したノードにストリーミングされ、そこでマージされます。クエリの
GROUP BYキーがシャーディングキーと整合している場合、マージ処理は 最小化、あるいは完全に回避 できます。
このモデルにより、コアおよびノード全体にわたる効率的なスケーリングが可能となり、ClickHouse は大規模分析に非常に適したものとなっています。部分集約状態 を用いることで、異なるスレッドおよびノードからの中間結果を精度を損なうことなくマージできます。
対照的に Elasticsearch では、多くの集約処理において、利用可能な CPU コア数にかかわらず、シャードごとに 1 スレッドを割り当てます。これらのスレッドは、シャードローカルな上位 N 件の結果を返し、コーディネーティングノードでマージされます。このアプローチは、システムリソースを十分に活用できない場合があり、特に頻出の語が複数シャードに分散している場合には、グローバル集約の精度に潜在的な問題を生じさせる可能性があります。shard_size パラメータを増やすことで精度を改善できますが、その代償としてメモリ使用量とクエリレイテンシが増大します。
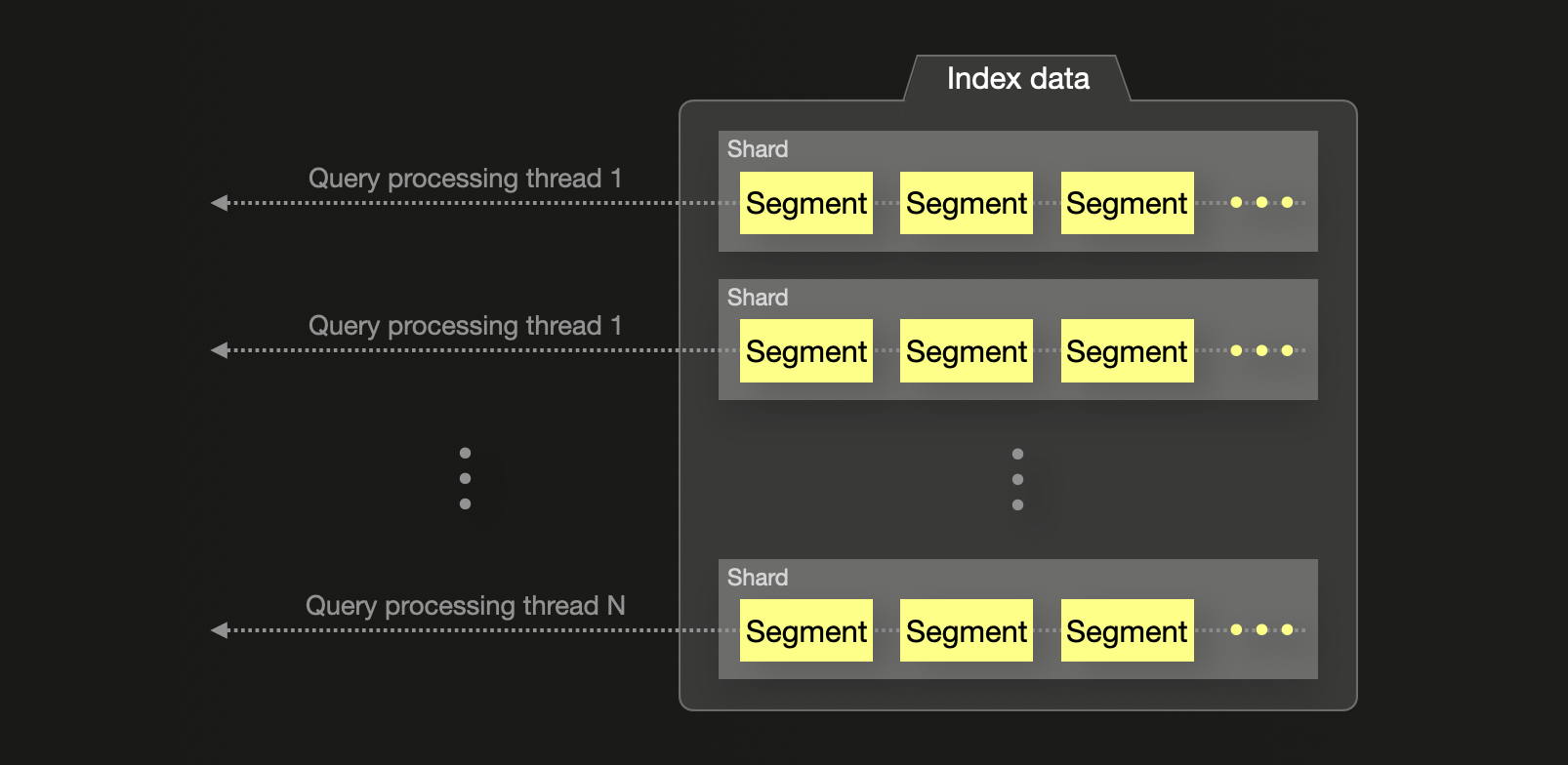
まとめると、ClickHouse はより細粒度な並列性とハードウェアリソースをきめ細かく制御しながら集約およびクエリを実行する一方で、Elasticsearch は、より制約の強いシャードベースの実行に依存しています。
それぞれの技術における集約のメカニズムについての詳細は、ブログ記事「ClickHouse vs. Elasticsearch: The Mechanics of Count Aggregations」を参照してください。
データ管理
Elasticsearch と ClickHouse は、時系列オブザーバビリティデータの管理において根本的に異なるアプローチを取っています。特に、データ保持期間、ロールオーバー、階層型ストレージの扱い方が異なります。
Index lifecycle management と ネイティブ TTL の比較
Elasticsearch では、長期保存データの管理は Index Lifecycle Management (ILM) と Data Streams によって行われます。これらの機能により、インデックスをどのタイミングでロールオーバーするか(例: 一定のサイズまたは経過時間に達したとき)、古いインデックスを低コストなストレージ(例: ウォームまたはコールドティア)へ移動するタイミング、そして最終的に削除するタイミングをポリシーとして定義できます。これは、Elasticsearch が 再シャーディングをサポートしておらず、シャードを性能が劣化せずに無制限に大きくすることはできないために必要になります。シャードサイズを管理し効率的な削除を行うためには、新しいインデックスを定期的に作成し、古いインデックスを削除する必要があります。つまり、インデックスレベルでデータをローテーションすることになります。
ClickHouse は異なるアプローチを取ります。データは通常 単一のテーブル に保存され、カラムまたはパーティションレベルの TTL (time-to-live) 式 を用いて管理されます。データを 日付でパーティション分割 しておくことで、新しいテーブルの作成やインデックスのロールオーバーを行うことなく、効率的に削除できます。データが古くなり TTL 条件を満たすと、ClickHouse は自動的にそのデータを削除します。ローテーションを管理するために追加のインフラストラクチャは不要です。
ストレージ階層とホット・ウォームアーキテクチャ
Elasticsearch は hot-warm-cold-frozen というストレージアーキテクチャをサポートしており、異なるパフォーマンス特性を持つストレージ階層間でデータを移動できます。これは通常、ILM を通じて設定され、クラスター内のノードロールに紐づけられます。
ClickHouse は、MergeTree のようなネイティブテーブルエンジンを通じて 階層型ストレージ (tiered storage) をサポートしており、カスタムルールに基づいて、古いデータを異なる ボリューム(例: SSD から HDD、さらにオブジェクトストレージへ)間で自動的に移動できます。これにより、Elastic の hot-warm-cold アプローチを再現できますが、複数のノードロールやクラスターを管理する複雑さは伴いません。
ClickHouse Cloud では、これがさらにシームレスになります。すべてのデータは オブジェクトストレージ(例: S3) 上に保存され、コンピュートリソースは分離されています。データはクエリされるまでオブジェクトストレージに留まり、そのタイミングで取得されてローカル(または分散キャッシュ)にキャッシュされます。これにより、Elastic の frozen 層と同等のコストプロファイルを維持しつつ、より優れたパフォーマンス特性を実現できます。このアプローチでは、ストレージ階層間でデータを移動する必要がなくなり、ホット・ウォームアーキテクチャ自体が不要になります。
ロールアップ vs インクリメンタル集約
Elasticsearch では、ロールアップや集約は transforms と呼ばれるメカニズムを使って実現されます。これは、スライディングウィンドウモデルを用いて、時系列データを一定間隔 (例: 1 時間ごと、1 日ごと) で要約するために使用されます。transforms は、あるインデックスからデータを集約し、その結果を別の ロールアップインデックス に書き込む定期実行のバックグラウンドジョブとして構成されます。これにより、高カーディナリティな生データを繰り返しスキャンすることを避け、長期間のクエリのコストを削減できます。
次の図は、transforms がどのように動作するかを抽象的に示したものです (あらかじめ集約値を計算しておきたい同じバケットに属するすべてのドキュメントを青色で示しています) :
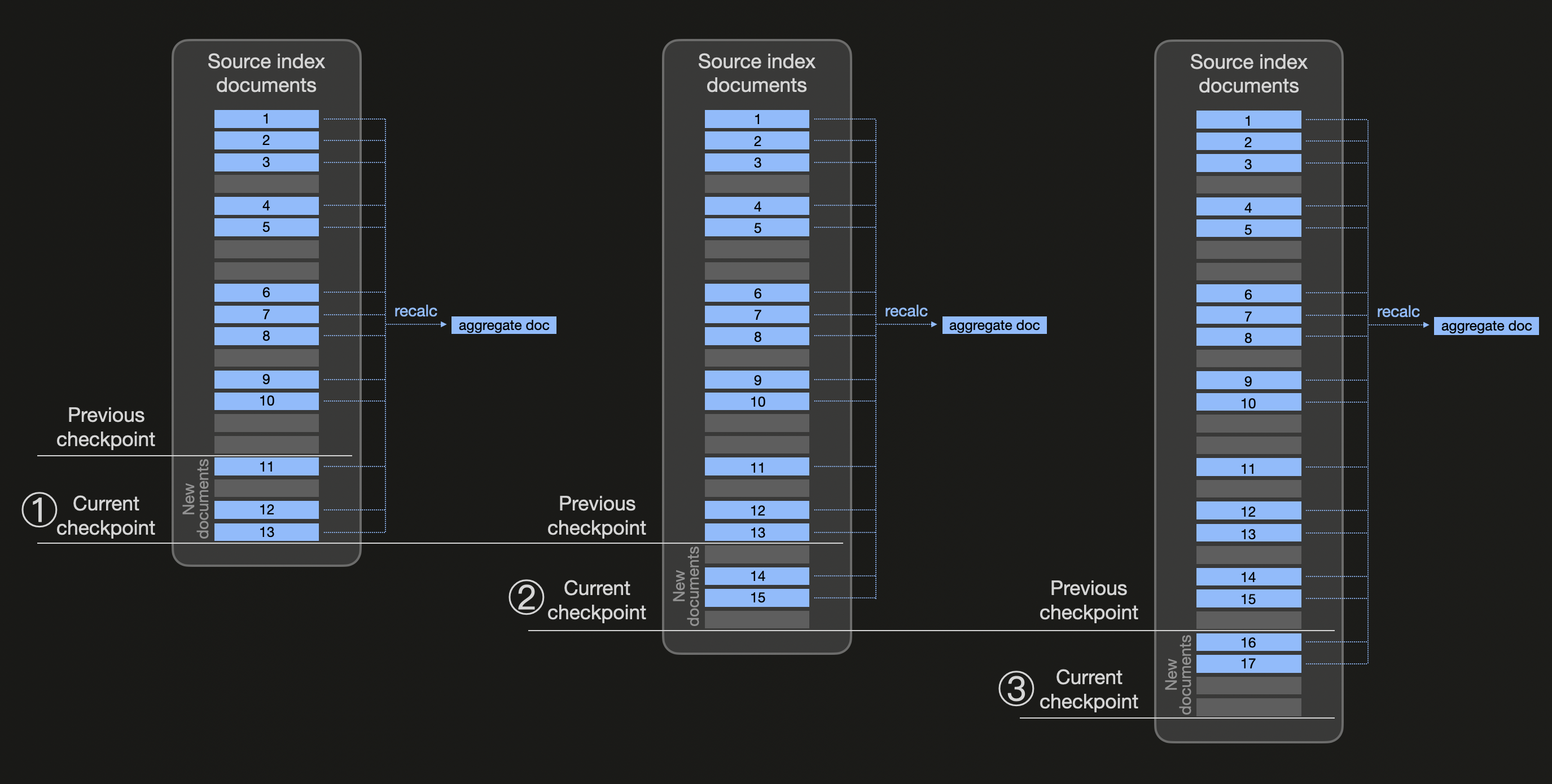
継続的な transform は、設定可能なチェック間隔時間 (デフォルト値 1 分の transform の frequency) に基づいた transform のチェックポイントを使用します。上の図では、① チェック間隔が経過すると新しいチェックポイントが作成されるものと仮定します。ここで Elasticsearch は transform のソースインデックスの変更を確認し、前回のチェックポイント以降に存在する 3 つの新しい blue ドキュメント (11、12、13) を検出します。そこで、ソースインデックスを既存のすべての blue ドキュメントに対してフィルタリングし、composite 集約 (結果のページネーションを利用するため) によって集約値を再計算します (そのうえで、前回の集約値を含むドキュメントを置き換えるドキュメントで宛先インデックスを更新します) 。同様に、② と ③ でも、新しいチェックポイントが処理され、変更を確認し、同じ blue バケットに属するすべての既存ドキュメントから集約値を再計算します。
ClickHouse は本質的に異なるアプローチを取ります。データを定期的に再集約するのではなく、ClickHouse は インクリメンタルなマテリアライズドビュー をサポートしており、データを 挿入時 に変換・集約します。新しいデータがソーステーブルに書き込まれると、マテリアライズドビューは事前に定義された SQL 集約クエリを、新しく 挿入されたブロック のみに対して実行し、集約結果をターゲットテーブルに書き込みます。
このモデルは、ClickHouse が 部分集約状態 (格納および後でマージ可能な集約関数の中間表現) をサポートしていることで実現されています。これにより、クエリが高速かつ更新コストの低い部分集約結果を維持できます。集約はデータ到着時に行われるため、高コストな定期ジョブを実行したり、古いデータを再要約したりする必要はありません。
インクリメンタルなマテリアライズドビューの仕組みを抽象的に示すと次のようになります (あらかじめ集約値を計算しておきたい同じグループに属するすべての行を青色で示しています) :
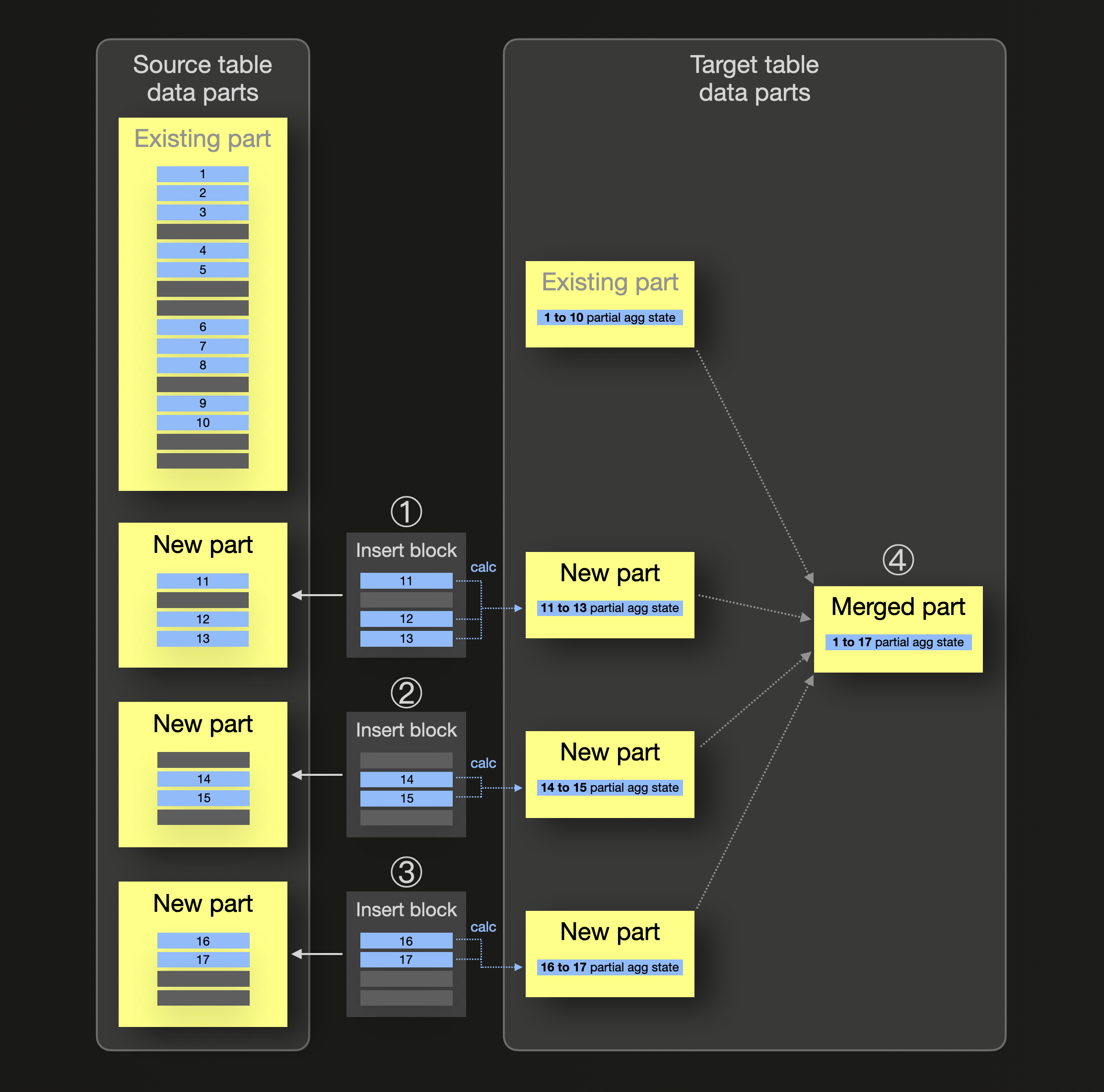
上の図では、マテリアライズドビューのソーステーブルにはすでに、同じグループに属する blue 行 (1〜10) を格納するデータパーツが含まれています。このグループに対しては、ビューのターゲットテーブル側にも、blue グループの 部分集約状態 を格納するデータパーツがすでに存在します。① ② ③ のように新しい行がソーステーブルに挿入されると、それぞれの挿入に対応するソーステーブルのデータパーツが作成され、並行して、新しく挿入された各行ブロックごとに 部分集約状態 が計算され、データパーツの形でマテリアライズドビューのターゲットテーブルに挿入されます。④ バックグラウンドでのパーツマージ処理の際に、これらの 部分集約状態 がマージされ、インクリメンタルなデータ集約が行われます。
aggregate functions (90 種類以上) 、およびそれらを aggregate function の combinators と組み合わせたものはすべて、部分集約状態 をサポートしている点に注意してください。
インクリメンタル集約における Elasticsearch と ClickHouse の、より具体的な比較例については、このサンプルを参照してください。
ClickHouse のアプローチの利点には、次のようなものがあります:
- 常に最新の集約結果: マテリアライズドビューは常にソーステーブルと同期しています。
- バックグラウンドジョブが不要: 集約処理はクエリ実行時ではなく挿入時に行われます。
- 優れたリアルタイム性能: オブザーバビリティワークロードやリアルタイム分析など、最新の集約結果を即時に必要とするユースケースに最適です。
- 合成可能: マテリアライズドビューは、他のビューやテーブルと重ねたり結合したりして、より複雑なクエリ高速化戦略を構成できます。
- 異なる TTL 設定: マテリアライズドビューのソーステーブルとターゲットテーブルには、異なる TTL 設定を適用できます。
このモデルは、クエリごとに数十億件の生データをスキャンすることなく、1 分あたりのエラー率やレイテンシ、上位 N の内訳といったメトリクスを計算する必要があるオブザーバビリティのユースケースにおいて、特に強力です。
レイクハウス対応
ClickHouse と Elasticsearch では、レイクハウス統合へのアプローチが本質的に異なります。ClickHouse はフル機能のクエリ実行エンジンであり、Iceberg や Delta Lake といったレイクハウス形式に対するクエリを実行できるだけでなく、AWS Glue や Unity Catalog といったデータレイクカタログとの統合にも対応しています。これらの形式は Parquet ファイルに対する効率的なクエリを前提としており、ClickHouse はこれを完全にサポートします。ClickHouse は Iceberg と Delta Lake の両方のテーブルを直接読み取ることができるため、最新のデータレイクアーキテクチャとシームレスに統合できます。
対照的に、Elasticsearch は内部データ形式と Lucene ベースのストレージエンジンに強く結び付いています。レイクハウス形式や Parquet ファイルを直接クエリできないため、最新のデータレイクアーキテクチャを活用するうえで大きな制約となります。Elasticsearch では、クエリを実行する前に、データを独自形式へ変換してロードする必要があります。
ClickHouse のレイクハウス機能は、単にデータを読み取るだけにとどまりません。
- データカタログ統合: ClickHouse は AWS Glue のようなデータカタログとの統合をサポートし、オブジェクトストレージ上のテーブルを自動的に検出してアクセスできるようにします。
- オブジェクトストレージ対応: データの移動を必要とせずに、S3、GCS、Azure Blob Storage に格納されたデータに対するネイティブなクエリ実行をサポートします。
- クエリフェデレーション: レイクハウステーブル、従来型データベース、ClickHouse テーブルを含む複数のソース間でデータを相関付けることができ、外部ディクショナリ や テーブル関数 を利用して実現します。
- 増分ロード: S3Queue や ClickPipes などの機能を利用し、レイクハウステーブルからローカルの MergeTree テーブルへの継続的なロードをサポートします。
- パフォーマンス最適化: cluster 関数 を用いたレイクハウスデータに対する分散クエリ実行により、パフォーマンスを向上させます。
これらの機能により、ClickHouse はレイクハウスアーキテクチャを採用する組織にとって自然な選択肢となり、データレイクの柔軟性とカラムナデータベースの性能の両方を活用できるようにします。
