ClickStack - materialized views
はじめに
ClickStack は、集約処理の多いクエリ(例: 時系列で 1 分ごとの平均リクエスト時間の計算)に依存する可視化を高速化するために、Incremental Materialized Views (IMV) を活用できます。この機能によりクエリ性能は大きく向上し、1 日あたりおよそ 10 TB 以上の大規模な導入で特に効果を発揮しつつ、1 日あたり PB クラスまでスケールすることが可能になります。インクリメンタルmaterialized view は現在 Beta 段階であり、慎重に使用する必要があります。
アラートも materialized views の恩恵を受けることができ、自動的にそれらを利用します。 これにより、多数のアラートを実行する際の計算オーバーヘッドを削減できます。特にアラートは通常非常に高頻度で実行されるため、その効果は大きくなります。 実行時間を短縮することは、応答性とリソース消費の両面で有益です。
インクリメンタルmaterialized viewとは
インクリメンタルmaterialized viewを使用すると、計算コストをクエリ実行時から挿入時にシフトできるため、SELECT クエリを大幅に高速化できます。
Postgres のようなトランザクションデータベースとは異なり、ClickHouse の materialized view は保存されたスナップショットではありません。代わりに、ソーステーブルにデータブロックが挿入されるたびにクエリを実行するトリガーとして動作します。このクエリの出力は、別のターゲットテーブルに書き込まれます。追加データが挿入されると、新しい部分結果がターゲットテーブルに追記され、マージされます。マージ後の結果は、元の全データセットに対して集約を実行した場合と同等になります。
materialized view を使用する主な目的は、ターゲットテーブルに書き込まれるデータが集約・フィルタリング・変換結果を表す点にあります。ClickStack では、これらは専ら集約のために使用されます。これらの結果は、しばしば部分的な集約状態を表現しており、生の入力データと比べて一般的に大幅に小さくなります。事前集約されたターゲットテーブルに対してクエリするだけでよいという単純さと相まって、生データに対して同じ計算をクエリ時に行う場合と比べ、クエリレイテンシを大幅に低減できます。
ClickHouse の materialized view は、データがソーステーブルに流入するのに合わせて継続的に更新され、常に最新の索引に近い振る舞いをします。これは、多くの他のデータベースにおける、定期的なリフレッシュが必要な静的スナップショットとしての materialized view とは異なります。後者は ClickHouse の リフレッシャブルmaterialized view に近いモデルです。
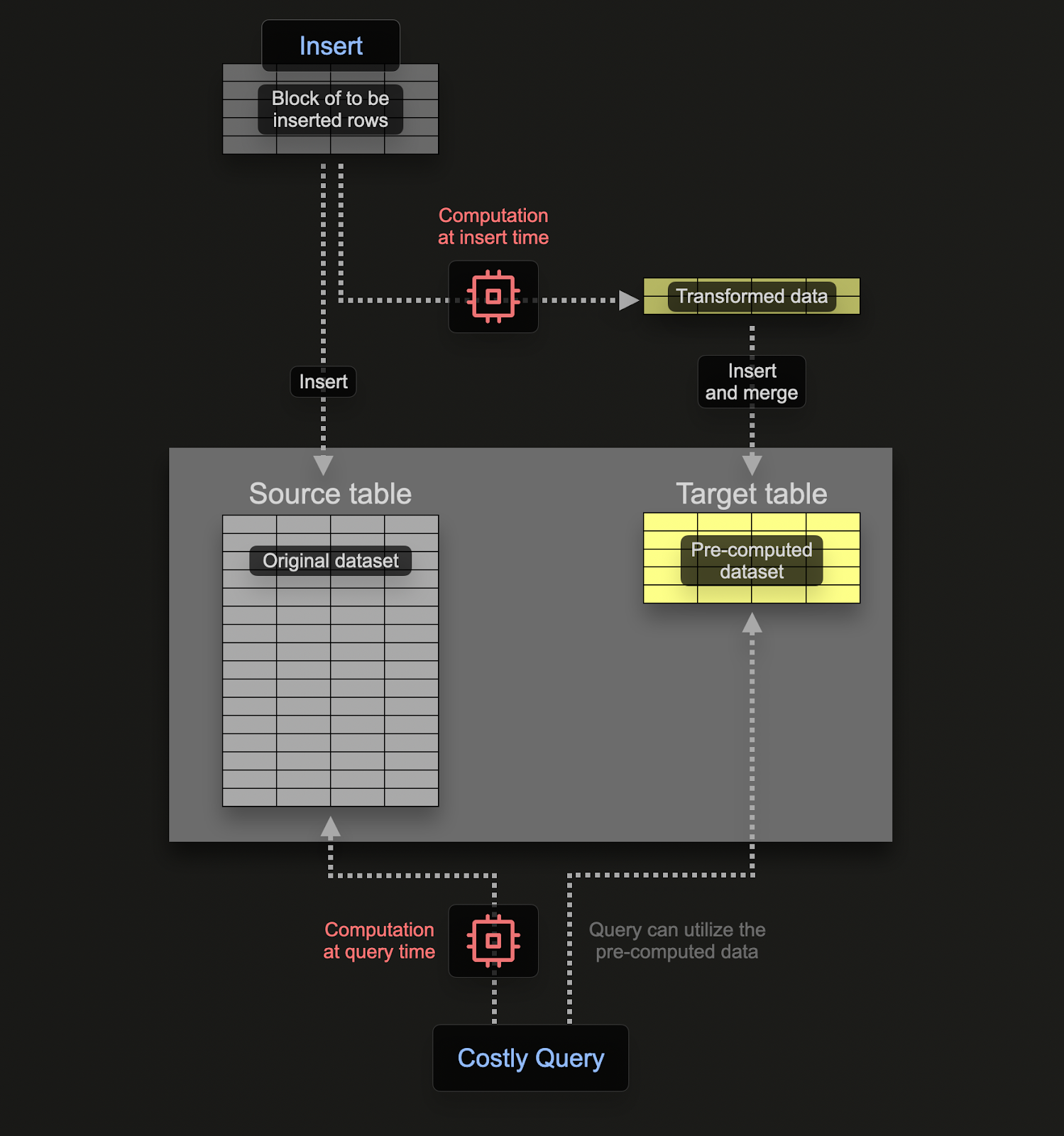
インクリメンタルmaterialized view は、新しいデータが到着したときに、そのビューに対する変更分のみを計算し、計算を挿入時にシフトします。ClickHouse はインジェストに高度に最適化されているため、挿入される各ブロックごとのビュー維持にかかるインクリメンタルなコストは、クエリ実行時に得られる節約と比較して相対的に小さくなります。集約計算のコストは、読み取りのたびに繰り返し支払うのではなく、挿入全体にわたって平準化されます。そのため、事前集約された結果に対してクエリする方が再計算するよりもはるかに低コストとなり、ペタバイトスケールであっても、下流の可視化に対して低い運用コストとほぼリアルタイムのパフォーマンスを実現できます。
このモデルは、更新のたびにビュー全体を再計算したり、スケジュールされたリフレッシュに依存したりするシステムとは根本的に異なります。materialized view がどのように動作し、どのように作成するかの詳細な説明については、上記のガイドを参照してください。
各 materialized view は挿入時の追加オーバーヘッドを発生させるため、選択的かつ計画的に使用する必要があります。
最も一般的なダッシュボードと可視化のためにのみビューを作成してください。 機能がベータ版の間は、使用するビューを 20 個未満に制限してください。 この閾値は将来のリリースで増加する予定です。
単一の materialized view で、異なるグルーピングに対する複数のメトリクスを計算できます。例えば、1 分ごとのバケットに対して、サービス名ごとの最小値・最大値・p95 の duration を計算できます。これにより、1 つのビューで単一の可視化ではなく多数の可視化に対応できます。そのため、メトリクスを共有ビューに集約することは、各ビューの価値を最大化し、ダッシュボードやワークフロー間で再利用されるようにするうえで重要です。
先に進む前に、ClickHouse における materialized view について、より深く理解しておくことを推奨します。 詳細については、インクリメンタルmaterialized view に関するガイドを参照してください。
高速化対象の可視化の選定
materialized view を作成する前に、どの可視化を高速化したいのか、そしてどのワークフローがユーザーにとって最も重要であるかを理解しておくことが重要です。
ClickStack では、materialized view は 集計処理が重い可視化を高速化する よう設計されています。これは、時間の経過に伴って 1 つ以上のメトリクスを計算するクエリを意味します。例としては、1 分あたりの平均リクエスト時間、サービスごとのリクエスト数、時間経過に伴うエラー率 などがあります。materialized view には常に集計と時間に基づくグルーピングが含まれている必要があります。これは、時系列可視化向けに提供することを目的としているためです。
一般的には、次のような方針を推奨します。
影響の大きい可視化を特定する
高速化の候補として最適なものは、通常次のいずれかのカテゴリに分類されます。
- 壁面ディスプレイに表示される高レベルの監視ダッシュボードなど、頻繁に更新され常時表示されているダッシュボードの可視化。
- ランブック内で使用される診断ワークフローで、インシデント対応中に特定のチャートが繰り返し参照され、結果を迅速に返す必要があるもの。
- HyperDX の主要なエクスペリエンスで、次を含みます:
- 検索ページのヒストグラムビュー。
- APM、Services、Kubernetes ビューなど、プリセットダッシュボードで使用される可視化。
これらの可視化は、ユーザーや時間範囲をまたいで繰り返し実行されることが多く、クエリ実行時の計算を挿入時へと前倒しする対象として理想的です。
挿入時のコストと効果のバランスをとる
materialized view は挿入時に追加の処理を発生させるため、選択的かつ慎重に作成する必要があります。すべての可視化が事前集計の恩恵を受けるわけではなく、ほとんど使用されないチャートを高速化しても、通常はオーバーヘッドに見合いません。materialized view の総数は最大でも 20 を超えないようにすべきです。
本番環境へ移行する前には、materialized view によって発生するリソースオーバーヘッド、特に CPU 使用率、ディスク I/O、そして マージのアクティビティ を必ず検証してください。各 materialized view は挿入時の処理量を増やし、追加のパーツを生み出すため、マージ処理が追いついているか、パーツ数が安定しているかを確認することが重要です。これは、オープンソース版 ClickHouse の system テーブル および組み込みのオブザーバビリティダッシュボード、または ClickHouse Cloud の組み込みメトリクスおよび監視ダッシュボードを通じて監視できます。過剰なパーツ数の診断と軽減については、Too many parts を参照してください。
最も重要な可視化を特定できたら、次のステップは統合です。
共有ビューに可視化を集約する
ClickStack のすべての materialized view では、toStartOfMinute などの関数を使用して、時間間隔ごとにデータをグループ化する必要があります。ただし、多くの可視化では、サービス名、スパン名、ステータスコードなどの追加のグルーピングキーも共有します。複数の可視化が同じグルーピング次元を使用する場合、それらは多くの場合、1 つの materialized view で対応できます。
たとえば(トレースの場合):
- サービス名ごとの平均 Duration の時間推移 -
SELECT avg(Duration), toStartOfMinute(Timestamp) as time, ServiceName FROM otel_traces GROUP BY ServiceName, time - サービス名ごとのリクエスト数の時間推移 -
SELECT count() count, toStartOfMinute(Timestamp) as time, ServiceName FROM otel_traces GROUP BY ServiceName, time - ステータスコードごとの平均 Duration の時間推移 -
SELECT avg(Duration), toStartOfMinute(Timestamp) as time, StatusCode FROM otel_traces GROUP BY StatusCode, time - ステータスコードごとのリクエスト数の時間推移 -
SELECT count() count, toStartOfMinute(Timestamp) as time, StatusCode FROM otel_traces GROUP BY StatusCode, time
クエリやチャートごとに個別の materialized view を作成するのではなく、サービス名とステータスコードで集約する単一の view にまとめることができます。この単一の view で count、平均 Duration、最大 Duration、さらにパーセンタイルといった複数のメトリクスを計算でき、それらを複数の可視化で再利用できます。上記を組み合わせたクエリの例を以下に示します。
このようにビューを統合することで、挿入時のオーバーヘッドを抑え、materialized view の総数を制限し、part 数に関する問題を軽減し、継続的なメンテナンスを簡素化できます。
この段階では、高速化したい可視化で発行されるクエリに焦点を当ててください。次のセクションでは、複数の集約クエリを 1 つの materialized view にまとめる方法の例を示します。
materialized view の作成
高速化したい可視化、または可視化のセットを特定できたら、次のステップは、その背後にあるクエリを特定することです。実務上は、可視化の設定を確認し、生成された SQL を精査して、使用されている集計メトリクスや適用されている関数に特に注意を払うことを意味します。
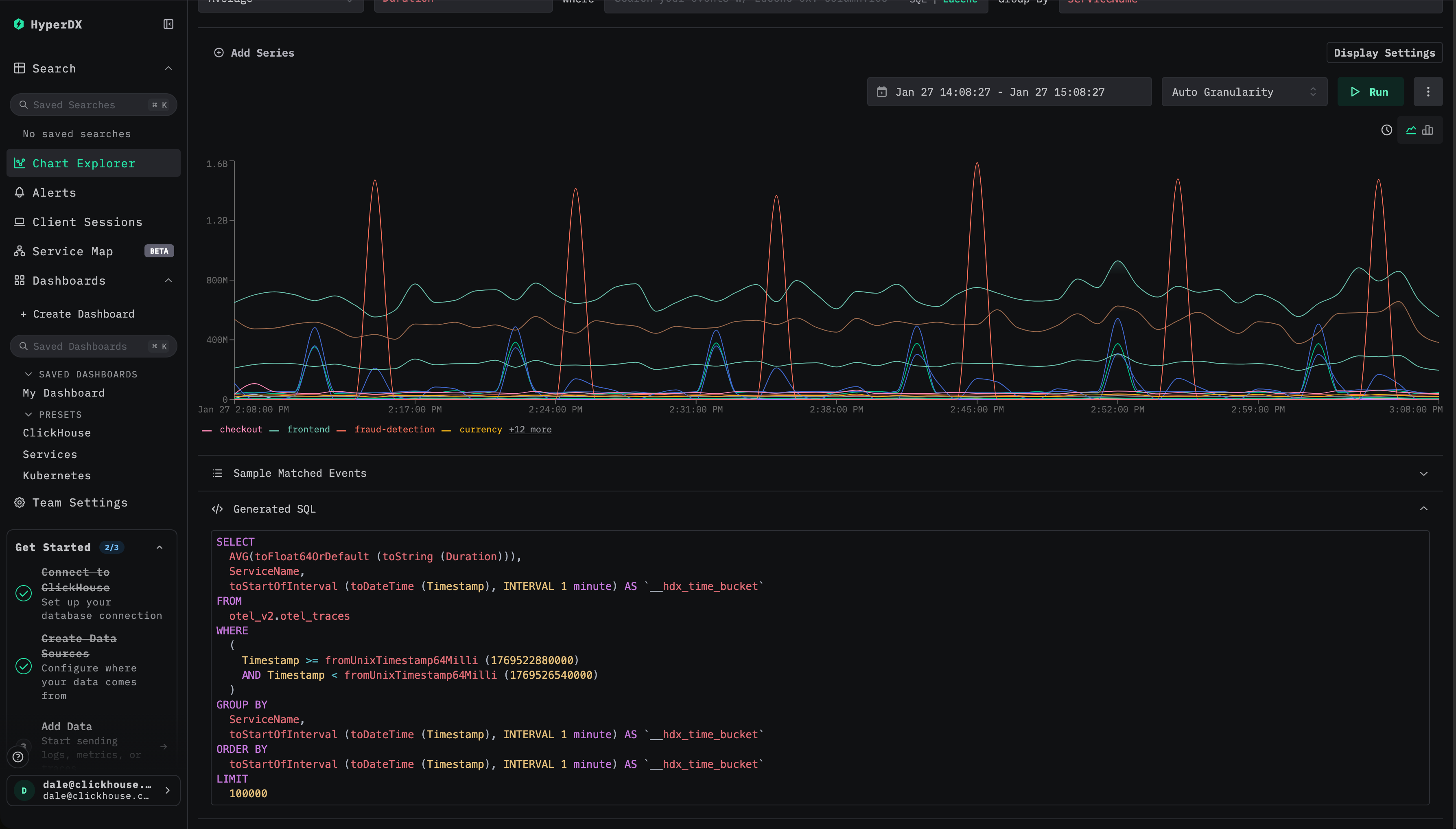
HyperDX 内のコンポーネントにデバッグパネルが用意されていない場合、ユーザーはブラウザーのコンソールを確認することで、ログに記録されたすべてのクエリを確認できます。
必要なクエリを洗い出したら、ClickHouse の aggregate state functions に慣れておく必要があります。materialized view は、これらの関数を使用して計算をクエリ時から挿入時へとシフトします。最終的な集計値を保存するのではなく、materialized view は 中間集計状態 を計算して保存し、これらはクエリ時にマージおよび最終化されます。これらの状態を格納したテーブルは、通常、元のテーブルよりもはるかに小さくなります。これらの状態には専用のデータ型があり、ターゲットテーブルのスキーマ内で明示的に定義する必要があります。
参考として、ClickHouse のドキュメントでは、aggregate state functions と、それらを保存するために使用されるテーブルエンジン AggregatingMergeTree の詳細な概要と例が提供されています。
以下のビデオでは、AggregatingMergeTree と Aggregate functions の使用例を確認できます。
先に進む前に、これらの概念に十分慣れておくことを強く推奨します。
materialized view の例
次の元のクエリを考えます。これは、サービス名とステータスコードごとにグループ化し、1 分あたりの平均 duration、最大 duration、イベント数、およびパーセンタイルを計算します。
このクエリを高速化するには、対応する集約状態を保持するターゲットテーブル otel_traces_1m を作成します。
materialized view otel_traces_1m_mv の定義では、新しいデータが挿入されるたびに、これらの状態を計算して書き込みます。
この materialized view は次の 2 つの要素で構成されています。
- ターゲットテーブル。中間結果を保存するために使用されるスキーマと集計状態型を定義します。これらの状態がバックグラウンドで正しくマージされるようにするには、AggregatingMergeTree エンジンが必要です。
- materialized view のクエリは、データ挿入時に自動的に実行されます。元のクエリと比べて、最終的な集計関数の代わりに
avgStateやquantilesStateなどの state 関数を使用します。
その結果、各サービス名とステータスコードごとの 1 分単位の集計状態を保存するコンパクトなテーブルが得られます。このテーブルのサイズは時間とカーディナリティに応じて予測可能に増加し、バックグラウンドマージ後には、生データに対して元の集計クエリを実行した場合と同じ結果を表します。このテーブルに対するクエリは、ソースの traces テーブルから直接集計する場合と比べて大幅にコストが低く、大規模環境においても高速かつ一貫した可視化のパフォーマンスを実現できます。
ClickStack における materialized view の利用
ClickHouse で materialized view を作成したら、それらを可視化、ダッシュボード、アラートで自動的に利用できるように、ClickStack に登録する必要があります。
materialized view を利用できるように登録する
materialized view は、その view が元になった元のソーステーブルに対応する HyperDX 上の source に対して登録する必要があります。
ソースを編集する
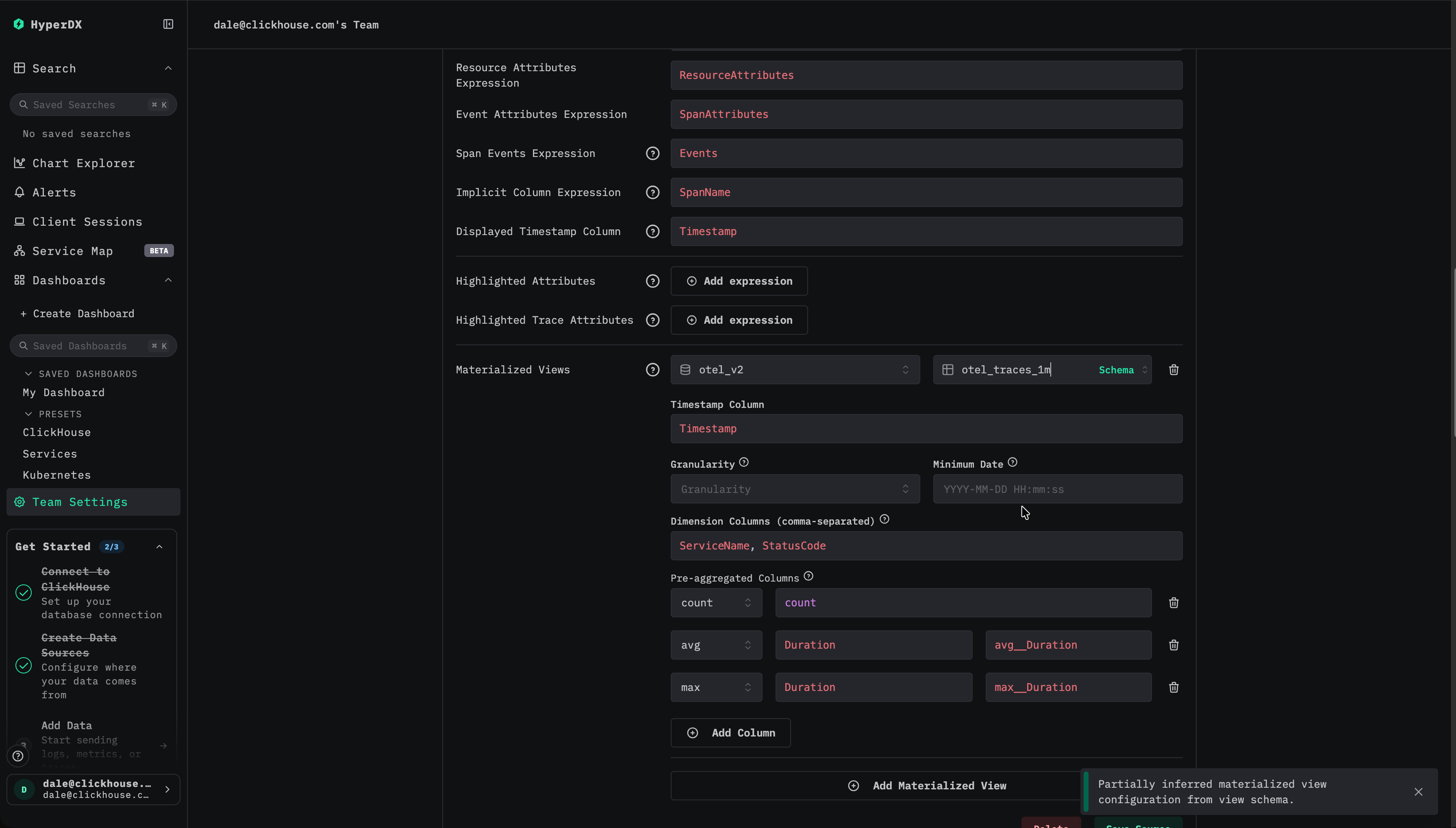
HyperDX で対象の source に移動し、Edit configuration ダイアログを開きます。materialized view 用のセクションまでスクロールします。
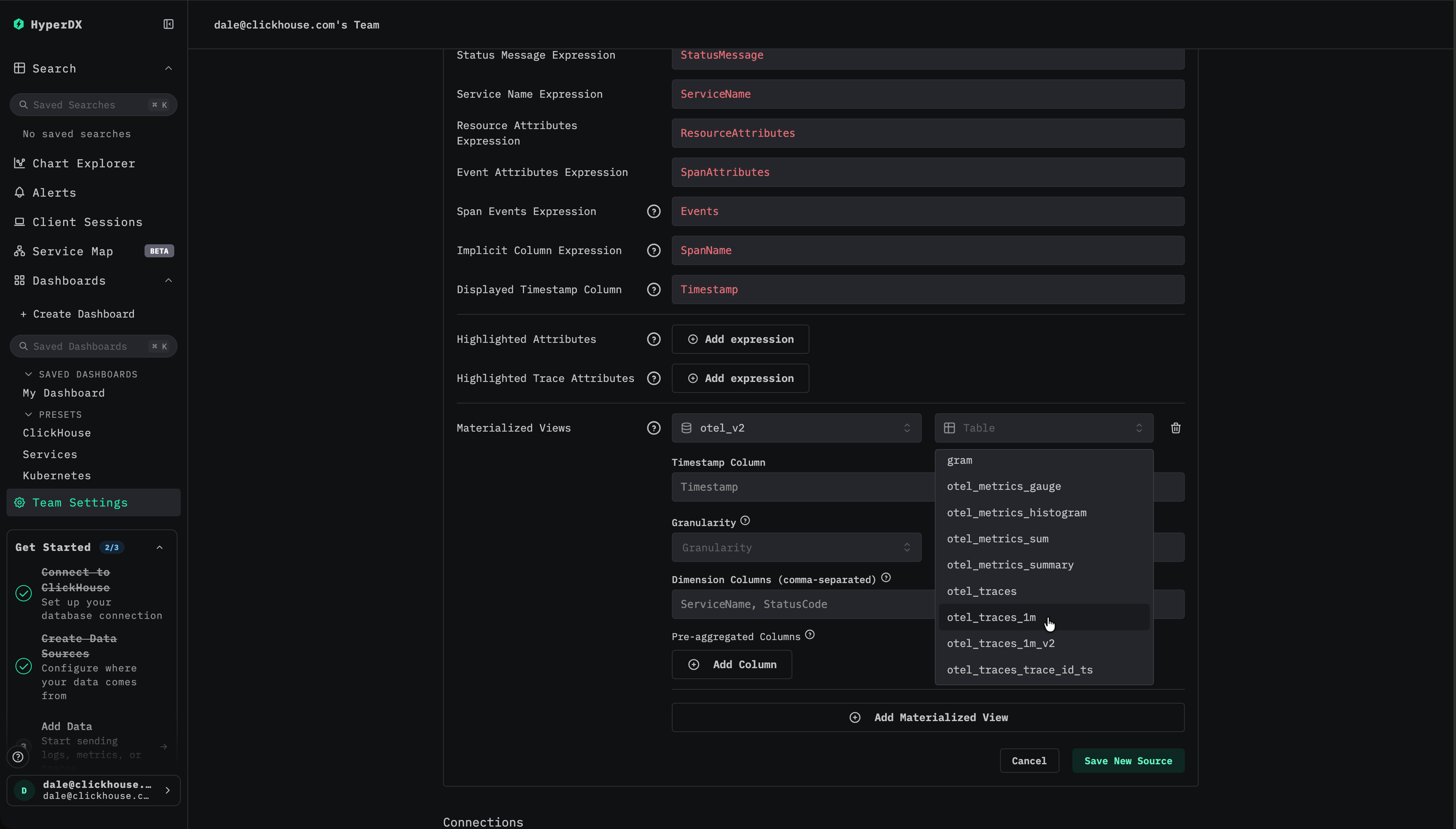
メトリクスを選択する
多くの場合、タイムスタンプ、ディメンション、メトリクスのカラムは自動的に推論されます。推論されない場合は手動で指定します。
メトリクスについては、次のようにマッピングする必要があります:
- 元のカラム名 (例:
Duration) - materialized view 内の対応する集約カラム (例:
avg__Duration)
ディメンションについては、その view がタイムスタンプ以外で GROUP BY しているすべてのカラムを指定します。
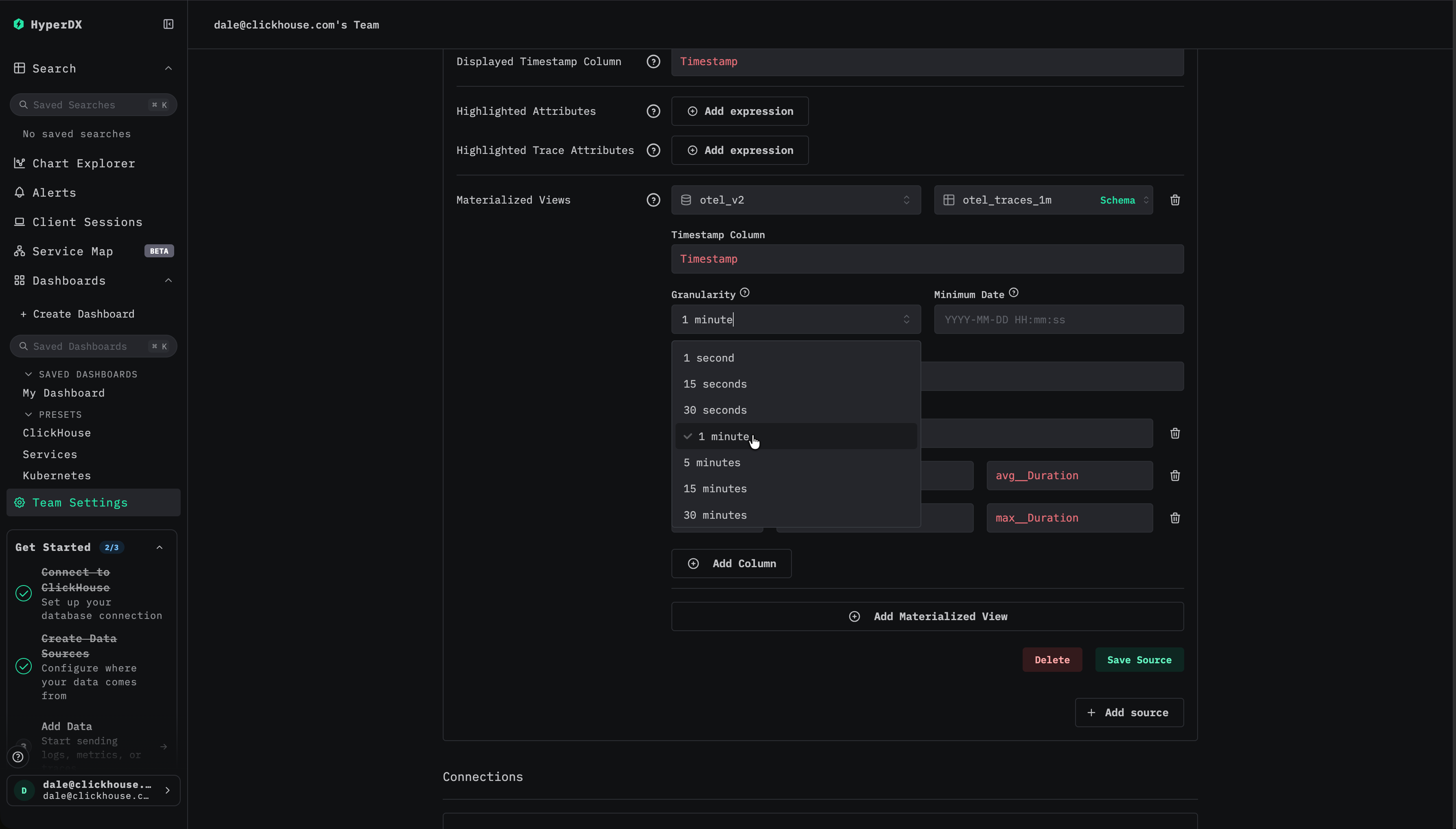
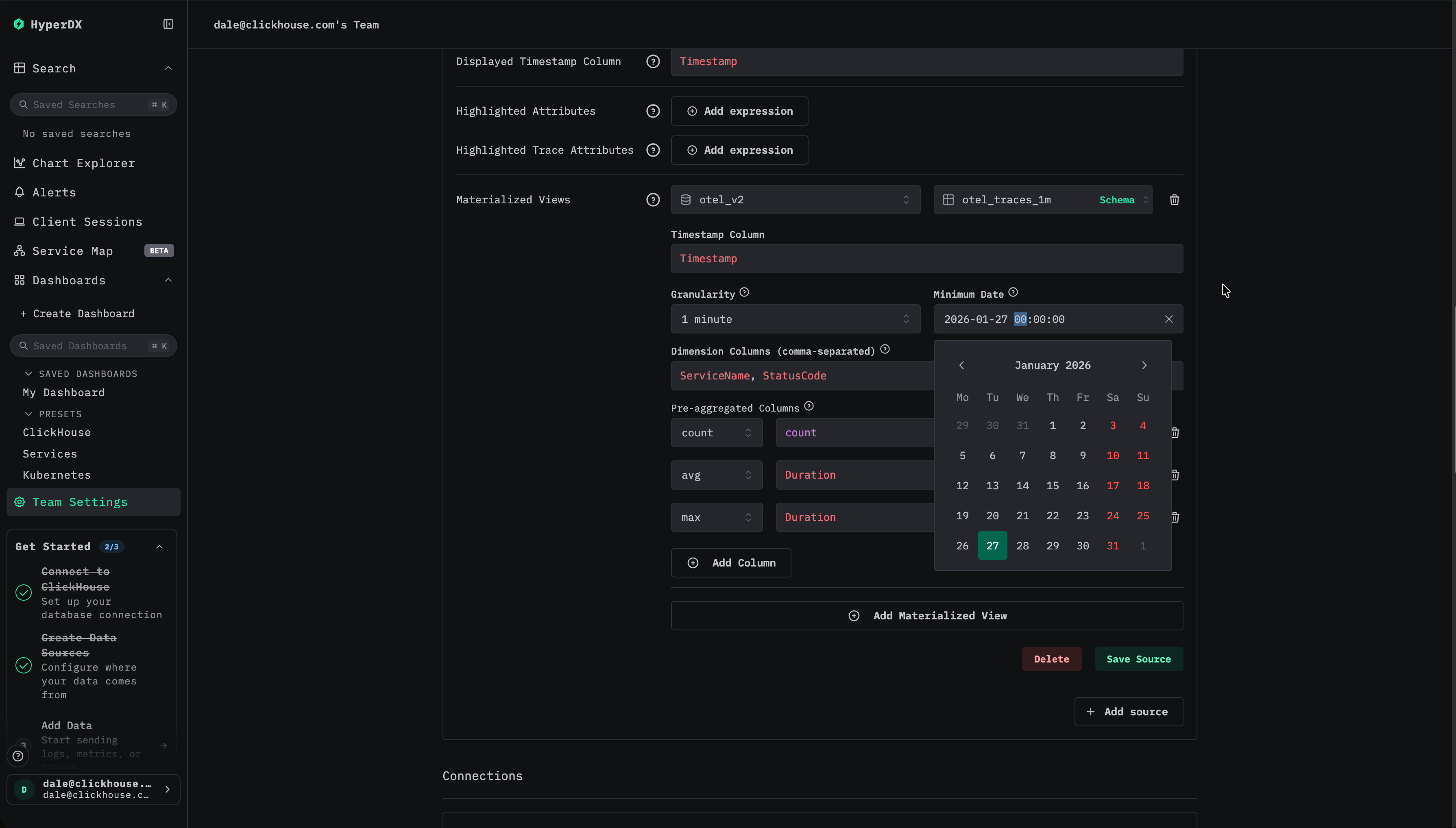
最小日付を選択する
materialized view にデータが含まれている最小日付を指定します。これは view で利用可能な最も早いタイムスタンプを表し、インジェストが継続的であると仮定すると、通常は view が作成された時刻になります。
materialized view は作成時に 自動でバックフィルされない ため、作成後に挿入されたデータから生成された行のみを含みます。 materialized view をバックフィルするための詳細なガイドは、「Backfilling Data」を参照してください。
正確な開始時刻が不明な場合は、対象テーブルから最小タイムスタンプをクエリして確認できます。例えば次のクエリを実行します:
materialized view が一度登録されると、ダッシュボード、可視化、アラートを変更することなく、クエリが適用可能な場合には常に ClickStack によって自動的に利用されます。ClickStack は各クエリを実行時に評価し、そのクエリに materialized view を適用できるかどうかを判定します。
ダッシュボードおよび可視化でのアクセラレーションの検証
インクリメンタルmaterialized view には、view が作成された後に 挿入されたデータのみが含まれることを忘れないでください。自動的に過去データで backfill されることはなく、その分軽量で運用コストも低く保たれています。このため、view を登録する際には、その view が有効な時間範囲をユーザーが明示的に指定する必要があります。
ClickStack は、materialized view の最小タイムスタンプがクエリの時間範囲の開始時刻以下である場合にのみ、その materialized view を使用します。これにより、view に必要なデータがすべて含まれていることが保証されます。クエリは内部的には時間ベースのサブクエリに分割されますが、materialized view はクエリ全体に対して適用されるか、まったく適用されないかのどちらかです。将来的な改善により、条件を満たすサブクエリに対して選択的に view を利用できるようになる可能性があります。
ClickStack では、materialized view が使用されているかどうかを確認できる、明確な視覚的インジケーターが提供されています。
- 最適化ステータスを確認する ダッシュボードや可視化を表示しているときに、稲妻アイコンまたは
Acceleratedアイコンを探します。
- 緑色の稲妻アイコン は、そのクエリが materialized view によって高速化されていることを示します。
- オレンジ色の稲妻アイコン は、そのクエリがソーステーブルに対して実行されていることを示します。
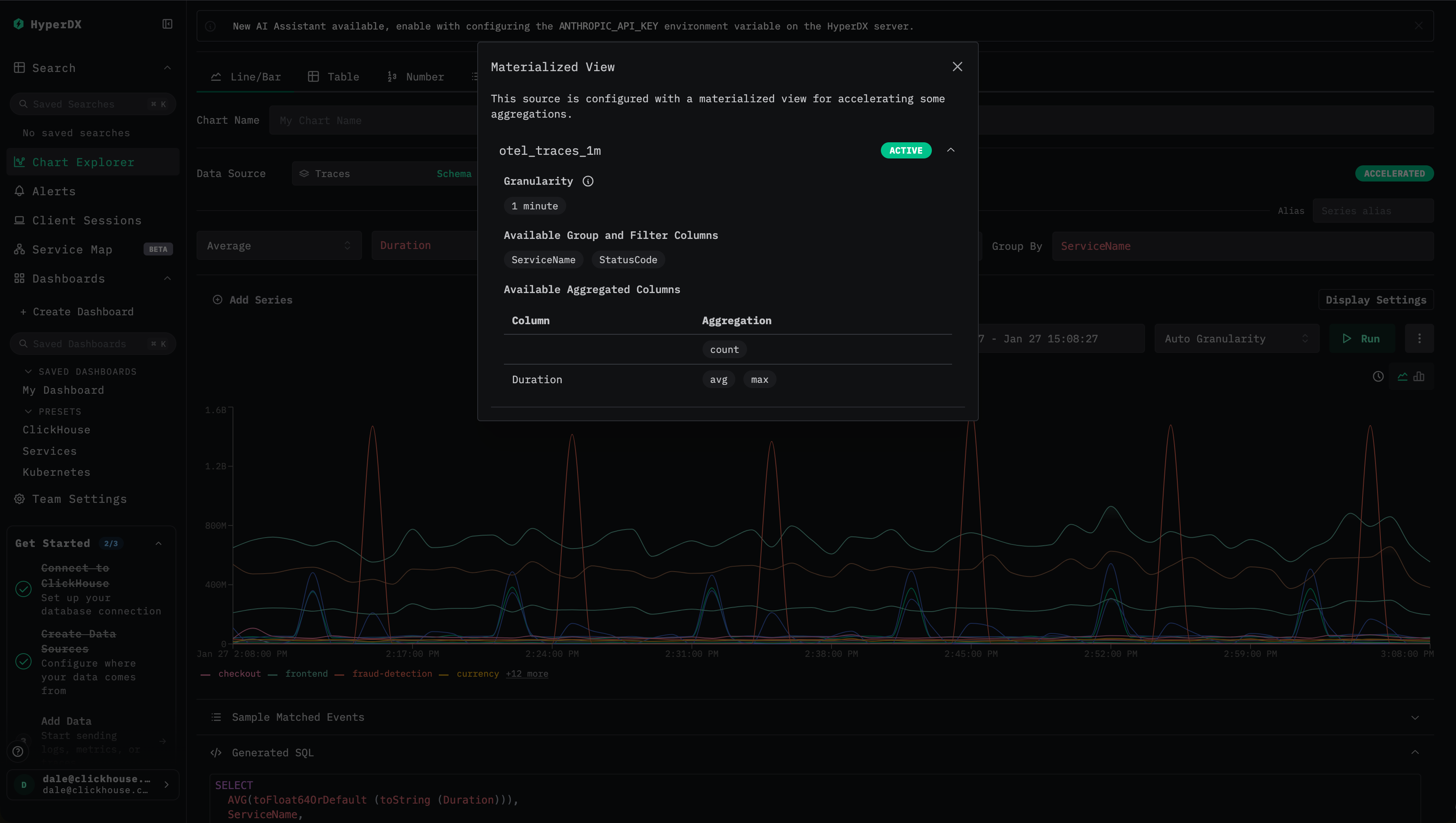
- 最適化の詳細を確認する 稲妻アイコンをクリックすると、以下の内容を表示する詳細パネルが開きます。
- Active materialized view: クエリに対して選択された view と、その推定行数。
- Skipped materialized views: 互換性はあるものの選択されなかった view と、その推定スキャンサイズ。
- Incompatible materialized views: 利用できなかった view と、その具体的な理由。
- 一般的な非互換の理由を理解する materialized view が使用されない理由として、次のようなものがあります。
- クエリの時間範囲 の開始時刻が、view の最小タイムスタンプよりも前に始まっている。
- 可視化の粒度 が、view の粒度の倍数になっていない。
- クエリで要求されている 集約関数 が、その view に含まれていない。
- クエリで
count(if(...))のような カスタム count 式 を使用しており、その集約状態を view から導出できない。
これらのインジケーターによって、可視化がアクセラレートされているかどうかを容易に確認できるほか、特定の view が選択された理由や、view が利用不可だった理由を診断できます。
可視化のために materialized view がどのように選択されるか
可視化が実行されるとき、ClickStack にはベーステーブルに加えて複数の materialized view など、複数の候補が存在する場合があります。最適なパフォーマンスを確保するために、ClickStack は ClickHouse の EXPLAIN ESTIMATE メカニズムを用いて、自動的に最も効率的なオプションを評価・選択します。
選択プロセスは、明確に定義された手順に従います。
-
互換性の検証 まず ClickStack は、次の点を確認することで、ある materialized view がクエリに対して適用可能かどうかを判定します。
- 時間範囲のカバー: クエリの時間範囲が、materialized view が保持するデータ範囲の内部に完全に収まっている必要があります。
- 粒度: 可視化のタイムバケットは、その view の粒度と同じか、それより粗い必要があります。
- 集約: 要求されたメトリクスが view 内に存在し、その集約状態から算出可能である必要があります。
-
クエリの変換 互換性のある view に対しては、ClickStack はクエリを書き換えて、その materialized view のテーブルを参照するようにします。
- 集約関数は、対応する materialized view のカラムにマッピングされます。
- 集約状態に対して
-Mergeコンビネータが適用されます。 - タイムバケットは、view の粒度に合わせて調整されます。
-
最良候補の選択 互換性のある materialized view が複数存在する場合、ClickStack は各候補に対して
EXPLAIN ESTIMATEクエリを実行し、スキャンされる推定行数とグラニュール数を比較します。推定スキャンコストが最も低い view が選択されます。 -
フォールバック処理 互換性のある materialized view が存在しない場合、ClickStack は自動的にソーステーブルへのクエリ実行にフォールバックします。
このアプローチにより、スキャンされるデータ量を一貫して最小化し、可視化定義を変更することなく、予測可能で低レイテンシなパフォーマンスを提供できます。
必要なディメンションがすべて view に含まれている限り、可視化にフィルタ、検索条件、タイムバケットが含まれている場合でも、materialized view は依然として選択対象となります。これにより、可視化定義を変更することなく、ダッシュボード、ヒストグラム、およびフィルタ済みチャートを高速化できます。
materialized view を選択する例
同じ trace ソース上に作成された 2 つの materialized view を考えます:
- 分単位、
ServiceName、StatusCodeでグループ化されたotel_traces_1m - 分単位、
ServiceName、StatusCode、SpanNameでグループ化されたotel_traces_1m_v2
2 つ目の VIEW には追加のグルーピングキーが含まれているため、より多くの行を生成し、より多くのデータをスキャンします。
可視化で 時間経過に伴うサービスごとの平均 duration が求められる場合、両方の VIEW が技術的には有効です。ClickStack は各候補に対して EXPLAIN ESTIMATE クエリを発行し、推定 granule 数を比較します。つまり、次のようになります:
otel_traces_1m はより小さく、スキャン対象の granule 数も少ないため、自動的に選択されます。
どちらの materialized view もベーステーブルを直接クエリするより高速ですが、最小限で十分な materialized view を選択することで、最適なパフォーマンスが得られます。
アラート
アラートクエリは、互換性がある場合は自動的に materialized view を使用します。同じ最適化ロジックが適用されるため、アラートの評価をより高速に行えます。
materialized view をバックフィルする
前述のとおり、インクリメンタルmaterialized view には、view の作成後に挿入されたデータしか含まれず、自動的にバックフィルはされません。この設計により、view は軽量で保守コストも低く抑えられますが、その一方で、view に含まれる最小タイムスタンプより前のデータを必要とするクエリには利用できません。
多くの場合、これは問題になりません。一般的な ClickStack のワークロードは直近 24 時間などの最新データにフォーカスしており、新しく作成した view でも作成から 1 日以内には十分に利用可能になります。しかし、より長い期間にまたがるクエリでは、十分な時間が経過するまで view が実用的に使えないままになることがあります。
このようなケースでは、materialized view に履歴データをバックフィルすることを検討できます。
バックフィルは計算コストが高くなる可能性があります。通常の運用では、materialized view はデータ到着に合わせてインクリメンタルに埋められ、計算コストは時間とともに均等に分散されます。
バックフィルでは、この作業をはるかに短い期間に圧縮するため、単位時間あたりの CPU とメモリ使用量が大幅に増加します。
データセットのサイズおよび保持期間によっては、バックフィルを妥当な時間内に完了させるために、一時的にクラスタのスケールアップ(垂直スケール)または ClickHouse Cloud での水平スケールが必要になる場合があります。
追加リソースを確保しない場合、バックフィルは本番ワークロードに悪影響をおよぼし、クエリレイテンシやインジェストスループットを低下させる可能性があります。非常に大きなデータセットや長期間の履歴を対象とする場合、バックフィルは実用的でないか、まったく不可能な場合もあります。
まとめると、バックフィルはコストと運用リスクに見合わないことが多く、履歴データのクエリ性能向上が極めて重要な例外的ケースでのみ検討すべきです。実施する場合は、パフォーマンス、コスト、本番環境への影響のバランスを取るため、以下に示す慎重に管理された手順に従うことを推奨します。
バックフィルのアプローチ
POPULATE コマンドは、取り込みを一時停止した小規模なデータセット以外で materialized view をバックフィルする目的で使用することは推奨されません。POPULATE のハッシュ計算が完了した後に materialized view が作成された場合、そのソーステーブルに挿入された行を取り逃がす可能性があります。さらに、この POPULATE はすべてのデータに対して実行されるため、大規模なデータセットでは中断やメモリ制限の影響を受けやすくなります。
次の集約に対応する materialized view をバックフィルしたいとします。この集約は、サービス名とステータスコードごとに 1 分単位のメトリクスを計算します。
前述のとおり、インクリメンタルmaterialized view は自動でバックフィルされることはありません。新しいデータに対するインクリメンタルな動作を維持しつつ、履歴データを安全にバックフィルするには、次のプロセスを推奨します。
INSERT INTO SELECT を用いた直接バックフィル
このアプローチは、小規模なデータセットや比較的軽量な集約クエリに最も適しています。この場合、クラスタのリソースを使い果たすことなく、バックフィル全体を妥当な時間内に完了できます。一般的には、バックフィル用のクエリが数分、長くても数時間で完了し、一時的な CPU および I/O 使用量の増加が許容できる場合に適しています。より大きなデータセットや高コストな集約の場合は、代わりに以下のインクリメンタル方式やブロック単位方式のバックフィルを検討してください。
materialized view の現在のカバレッジを確認する
バックフィルを試みる前に、まず materialized view にすでに含まれているデータを把握します。これは、ターゲットテーブルに存在する最小のタイムスタンプをクエリすることで行います:
このタイムスタンプは、その view がクエリを満たせる最も早い時点を表します。このタイムスタンプより前のデータを ClickStack から要求したクエリでは、ベーステーブルが参照されます。
バックフィルが必要かどうかを判断する
多くの ClickStack デプロイメントでは、クエリの対象は直近 24 時間などの最新データです。このようなケースでは、新しく作成したビューは作成後まもなく完全に利用可能となり、バックフィルは不要です。
前のステップで得られたタイムスタンプが、あなたのユースケースにとって十分に古い場合、バックフィルは不要です。バックフィルは次のような場合にのみ検討してください:
- クエリが長期間の履歴レンジを頻繁にカバーする。
- そのレンジ全体でのパフォーマンスにとってビューが重要である。
- データセットのサイズと集約コストの観点から、バックフィルの実行が現実的である。
欠損している履歴データをバックフィルする
バックフィルが必要な場合、materialized view のターゲットテーブルに対して、現在の最小タイムスタンプより前のタイムスタンプのデータを投入します。これは、上述のタイムスタンプより古いデータのみを読み取るように変更した、ビューと同じクエリを使用して行います。ターゲットテーブルは AggregatingMergeTree を使用しているため、バックフィルクエリでは最終値ではなく、集約状態を挿入しなければなりません。
このクエリは大量のデータを処理する可能性があり、リソース負荷が高くなることがあります。バックフィルを実行する前に、利用可能な CPU、メモリ、および I/O キャパシティを必ず確認してください。有用なテクニックとして、まずクエリを FORMAT Null 付きで実行し、実行時間とリソース使用量を見積もすことが挙げられます。
クエリ自体の実行が何時間もかかると予想される場合、このアプローチは推奨されません。
以下のクエリでは、view に存在する最も早いタイムスタンプより古いデータに集約を限定するために、WHERE 句を追加している点に注目してください:
Null テーブルを使用したインクリメンタルバックフィル
大きなデータセットやリソース集約的な集計クエリでは、単一の INSERT INTO SELECT による直接バックフィルは実用的でなかったり、安全でない場合があります。こうしたケースでは、インクリメンタルバックフィル手法を推奨します。この方法は、履歴データ全体を一度に集計するのではなく、扱いやすいブロック単位で処理するという点で、通常のインクリメンタルmaterialized viewの動作により近いものです。
このアプローチが適しているのは次のような場合です:
- バックフィル用クエリをそのまま実行すると、完了までに何時間もかかってしまう。
- フル集計時のピークメモリ使用量が高すぎる。
- バックフィル中の CPU およびメモリ消費を厳密に制御したい。
- 中断されても安全に再開できる、より堅牢なプロセスが必要。
ここでの重要なアイデアは、Null テーブルをインジェスト用バッファとして使用することです。Null テーブル自体はデータを保持しませんが、それに紐付けられた任意のmaterialized viewは実行されるため、データが流れるにつれて集計状態をインクリメンタルに計算できます。
バックフィル用の Null テーブルを作成する
materialized view の集計に必要なカラムのみを含む軽量な Null テーブルを作成します。これにより I/O とメモリ使用量を最小化できます。
Null テーブルに materialized view をアタッチする
次に、Null テーブル上にmaterialized viewを作成し、メインのmaterialized viewで使用しているものと同じ集計テーブルをターゲットに指定します。
このmaterialized viewは、Null テーブルに行が挿入されるたびにインクリメンタルに実行され、小さなブロック単位で集計状態を生成します。
データをインクリメンタルにバックフィルする
最後に、履歴データを Null テーブルに挿入します。materialized view はデータをブロック単位で処理し、生の行を保持せずにターゲットテーブルへ集計状態を出力します。
データがインクリメンタルに処理されるため、メモリ使用量は通常のインジェスト動作に近いかたちで、有界かつ予測しやすいものになります。
さらなる安全性のために、バックフィル用materialized viewの出力先を一時的なターゲットテーブル(例: otel_traces_1m_v2)に向けることを検討してください。バックフィルが正常に完了したら、パーティションを移動してメインのターゲットテーブルに切り替えます(例: ALTER TABLE otel_traces_1m_v2 MOVE PARTITION '2026-01-02' TO otel_traces_1m)。これにより、リソース制限などが原因でバックフィルが中断・失敗した場合でも、容易にリカバリできます。
挿入パフォーマンスの向上やリソースの削減・制御など、このプロセスのチューニングに関する詳細は、"Backfilling." を参照してください。
推奨事項
以下の推奨事項は、ClickStack における materialized view の設計および運用に関するベストプラクティスをまとめたものです。これらのガイドラインに従うことで、materialized view を効果的で予測可能かつコスト効率の高いものにできます。
粒度の選択と整合性
materialized view が利用されるのは、そのビューの粒度が可視化またはアラートの粒度の**正確な約数(倍数関係)**になっている場合に限られます。このときの粒度がどのように決まるかは、チャートタイプによって異なります。
-
時間チャート(x 軸が時刻の折れ線グラフまたは棒グラフ)の場合: チャートで明示的に指定された粒度は、materialized view の粒度の倍数である必要があります。 たとえば、10 分粒度のチャートでは、10 分、5 分、2 分、1 分の粒度を持つ materialized view は利用できますが、20 分や 3 分のビューは利用できません。
-
非時間チャート(ナンバー、テーブル、サマリーチャート)の場合: 実効粒度は
(time range / 80)から導出され、HyperDX がサポートする最も近い粒度に切り上げられます。この導出された粒度も、materialized view の粒度の倍数である必要があります。
これらのルールにより、次の点に注意してください。
- 10 分粒度の materialized view は作成しないでください。 ClickStack はチャートやアラートに対して 15 分粒度をサポートしていますが、10 分粒度はサポートしていません。そのため、10 分粒度の materialized view は、一般的な 15 分単位の可視化やアラートと互換性がありません。
- 多くのチャートおよびアラート設定と整合的に組み合わせられる 1 分 または 1 時間 の粒度を優先してください。
より粗い粒度(たとえば 1 時間)は、ビューのサイズを小さくし、ストレージのオーバーヘッドを削減します。一方、より細かい粒度(たとえば 1 分)は、詳細な分析の柔軟性を高めます。重要なワークフローを十分にサポートできる範囲で、可能な限り小さい粒度を選択してください。
materialized view を制限し統合する
各 materialized view は、挿入時の追加オーバーヘッドを発生させ、part およびマージ処理への負荷を高めます。 次のガイドラインを推奨します:
- ソースあたり 20 個以内の materialized view に抑える。
- おおよそ 10 個の materialized view が一般的には最適です。
- 共通のディメンションを共有する場合は、複数の可視化を 1 つのビューに統合する。
可能なかぎり、同じ materialized view から複数のメトリクスを計算し、複数のチャートをサポートするようにします。
次元を慎重に選択する
グルーピングやフィルタリングでよく利用される次元のみを含めます:
- グループ化用のカラムを追加するたびに、ビューのサイズが増加します。
- クエリの柔軟性と、ストレージおよび挿入時のコストとのバランスを取ります。
- ビューに含まれないカラムでフィルタすると、ClickStack はソーステーブルへのフォールバックを行います。
一般的かつほぼ常に有用なベースラインとしては、service name でグループ化し、count メトリクスを持つ materialized view が挙げられます。これにより、検索やダッシュボードでの高速なヒストグラムおよびサービスレベルの概要表示が可能になります。
集約カラムの命名規則
materialized view の集約カラムは、自動推論を有効にするため、厳密な命名規則に従わなければなりません:
- パターン:
<aggFn>__<sourceColumn> - 例:
avg__Durationmax__Duration- 行数カウント用の
count__
ClickStack は、この命名規則に基づいて、クエリを materialized view のカラムへ正しくマッピングします。
分位点とスケッチの選択
分位点関数ごとに、パフォーマンスとストレージ特性が異なります。
quantilesはディスク上のスケッチは大きくなりますが、挿入時の計算コストは低くなります。quantileTDigestは挿入時の計算コストは高くなりますが、スケッチは小さくなり、多くの場合、VIEW に対するクエリがより高速になります。
両方の関数に対して、スケッチサイズ(たとえば、挿入時に quantile(0.5))を指定できます。生成されたスケッチは、後から他の分位点の値、たとえば quantile(0.95) に対してもクエリ可能です。ワークロードに対して最適なバランスを見つけるために、実際に試してみることを推奨します。
効果を継続的に検証する
materialized view が実際に効果を発揮しているかを継続的に確認します。
- UI のアクセラレーションインジケーターを使って利用状況を確認します。
- materialized view を有効化する前後でクエリのパフォーマンスを比較します。
- リソース使用状況とマージ動作を監視します。
materialized view は、クエリパターンの変化に応じて定期的なレビューと調整が必要なパフォーマンス最適化手法として扱う必要があります。
高度な構成
より複雑なワークロードでは、複数の materialized view を使用して、異なるアクセスパターンをサポートできます。例としては次のようなものがあります。
- 高解像度の最新データと、粒度の粗い履歴ビュー
- 概要用のサービスレベルのビューと、詳細な診断用のエンドポイントレベルのビュー
これらのパターンは、選択的に適用した場合にパフォーマンスを大幅に向上させられますが、より単純な構成を検証した後にのみ導入するようにしてください。
これらの推奨事項に従うことで、materialized view を有効かつ保守しやすい状態に保ち、ClickStack の実行モデルとの整合性を確保できます。
制限事項
一般的な非互換となる理由
以下のいずれかの条件に当てはまる場合、materialized view は使用されません:
-
クエリの時間範囲 クエリの時間範囲の開始時刻が、materialized view の最小タイムスタンプより前になっている場合。materialized view は自動的に過去データでバックフィルされないため、その materialized view が完全にカバーしている時間範囲のクエリに対してのみ利用できます。
-
粒度の不一致 可視化の実効粒度は、materialized view の粒度の整数倍である必要があります。具体的には:
- 時間チャート(x 軸が時間の折れ線グラフや棒グラフ)の場合、チャートで選択された粒度は、materialized view の粒度の倍数でなければなりません。たとえば、10 分粒度のチャートは、10 分・5 分・2 分・1 分粒度の materialized view は利用できますが、20 分や 3 分粒度の materialized view は利用できません。
- 非時間チャート(数値チャートやテーブルチャート)の場合、実効粒度は
(time range / 80)で計算され、HyperDX がサポートする最も近い粒度に切り上げられ、その値が materialized view の粒度の倍数である必要があります。
-
未サポートの集約関数 クエリが、materialized view に存在しない集約を要求している場合。materialized view 内で明示的に計算・保存されている集約のみが利用できます。
-
カスタムの count 式
count(if(...))のような式や、その他の条件付きカウントを使用するクエリは、標準的な集約状態から導出できないため、materialized view を利用できません。
設計および運用上の制約
-
自動バックフィルなし インクリメンタルmaterialized view には作成後に挿入されたデータのみが含まれます。履歴データのクエリを高速化するには明示的なバックフィルが必要であり、大規模なデータセットではコストが高くなったり、実用的でない場合があります。
-
粒度のトレードオフ 非常に細かい粒度のビューはストレージサイズと挿入時のオーバーヘッドを増加させる一方、粗い粒度のビューは柔軟性を低下させます。粒度は、想定されるクエリパターンに合うよう慎重に選定する必要があります。
-
ディメンション爆発 多数のグルーピングディメンションを追加すると、ビューのサイズが大幅に増加し、有効性が低下する可能性があります。ビューには、一般的に使用されるグルーピングおよびフィルタリングのカラムのみを含めるべきです。
-
ビュー数に関するスケーラビリティの制約 各materialized view は挿入時のオーバーヘッドを追加し、マージ処理への負荷も増やします。ビューを作成しすぎると、インジェストおよびバックグラウンドマージに悪影響を及ぼす可能性があります。
これらの制約を理解しておくことで、materialized view を実際にメリットをもたらす箇所にのみ適用し、クエリが暗黙的により低速なソーステーブルへの参照にフォールバックしてしまうような構成を避けることができます。
トラブルシューティング
materialized view が利用されていない
チェック 1: 日付範囲
- 最適化モーダルを開き、「Date range not supported.」と表示されていないか確認します。
- クエリの日付範囲が materialized view の最小日付より後になっていることを確認します。
- materialized view がすべての過去データを保持している場合は、最小日付の指定を削除します。
チェック 2: 粒度
- チャートの粒度が MV の粒度の倍数になっていることを確認します。
- チャートを「Auto」に設定するか、互換性のある粒度を手動で選択してみてください。
チェック 3: 集約
- チャートで使用している集約が MV に含まれているか確認します。
- 最適化モーダルの「Available aggregated columns」を確認します。
チェック 4: ディメンション
- GROUP BY のカラムが MV のディメンションカラムに含まれていることを確認します。
- 最適化モーダルの「Available group/filter columns」を確認します。
materialized view クエリが遅い
問題 1: materialized view の粒度が細かすぎる
- 粒度が細かすぎる(例: 1 秒)ため、MV の行数が多くなっている。
- 解決策: より粗い粒度の MV を作成する(例: 1 分または 1 時間)。
問題 2: 次元が多すぎる
- 多数の次元カラムにより、MV のカーディナリティが高くなっている。
- 解決策: 最もよく使われるものに次元カラムを絞り込む。
問題 3: 高い行数を持つ複数の MV
- システムが各 MV に対して
EXPLAINを実行している。 - 解決策: ほとんど使われない、または常にスキップされる MV を削除する。
設定エラー
エラー: "At least one aggregated column is required"
- MV の設定に少なくとも 1 つの集約カラムを追加してください。
エラー: "Source column is required for non-count aggregations"
- どのカラムを集約するか指定してください(COUNT の場合のみ source カラムを省略できます)。
エラー: "Invalid granularity format"
- ドロップダウンからプリセットの粒度のいずれかを選択してください。
- 形式は有効な SQL interval である必要があります(例:
1 hではなく1 hour)。
