データレイクの利用開始
データレイクのテーブルをクエリし、MergeTree で高速化し、結果を Iceberg に書き戻すための実践的な手順を紹介します。すべての手順で公開データセットを使用し、Cloud と OSS の両方で利用できます。
このガイドのスクリーンショットは ClickHouse Cloud の SQL コンソールから取得したものです。すべてのクエリは Cloud とセルフマネージド環境の両方で動作します。
Icebergデータを直接クエリする
最も手軽に始める方法は、icebergS3() テーブル関数を使用することです。S3 上の Iceberg テーブルを指定するだけで、セットアップ不要でクエリをすぐに実行できます。
スキーマを確認する:
クエリを実行します:
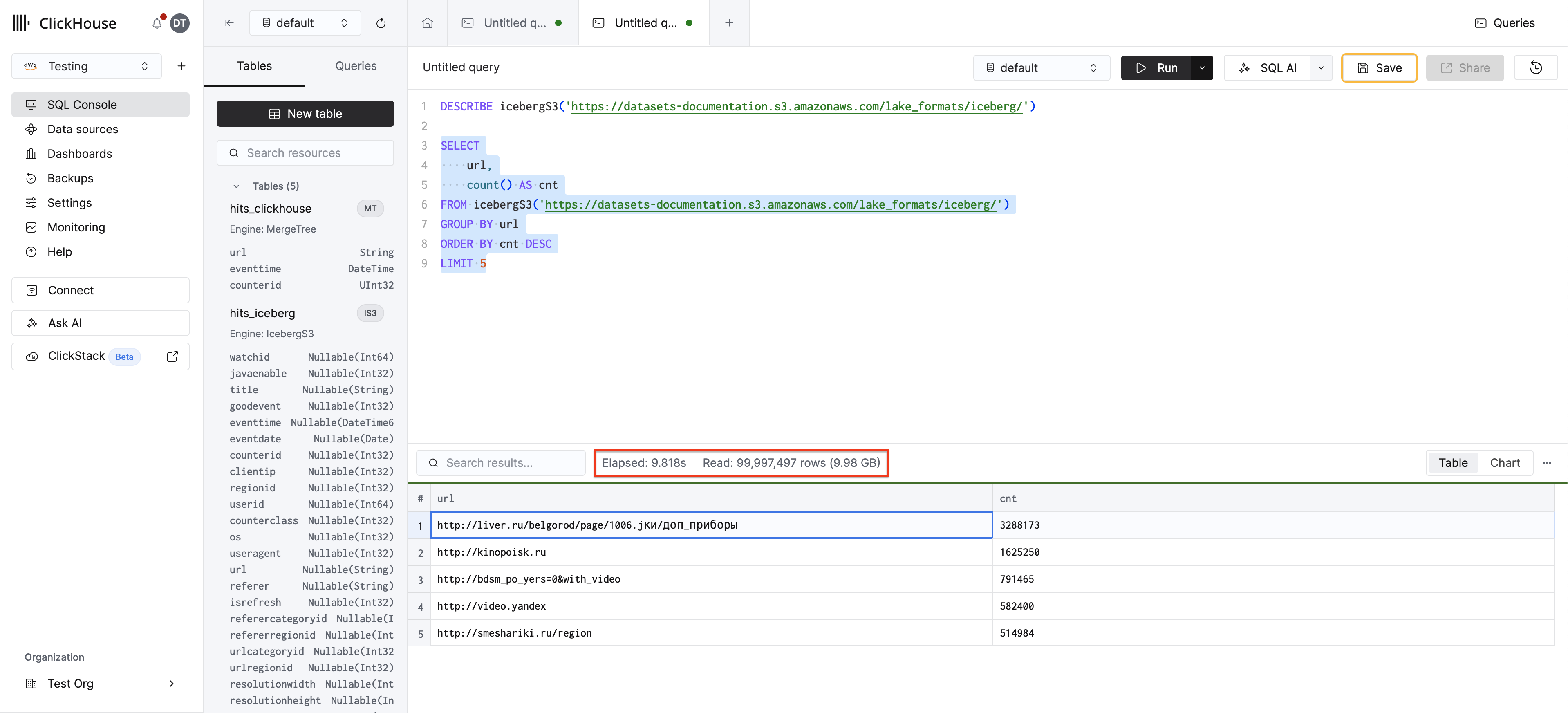
ClickHouse は Iceberg のメタデータを S3 から直接読み取り、スキーマを自動的に推論します。同じアプローチは deltaLake()、hudi()、paimon() にも適用できます。
詳細情報: オープンテーブルフォーマットへの直接クエリでは、4つのフォーマットすべて、分散読み取り用のクラスターバリアント、ストレージバックエンドオプション (S3、Azure、HDFS、ローカル) について説明しています。
永続テーブルエンジンの作成
繰り返しアクセスする場合は、Icebergテーブルエンジンを使用してテーブルを作成しておくと、毎回パスを指定する必要がなくなります。データはS3に保持され、複製は発生しません:
他の ClickHouse テーブルと同様にクエリを実行できます:
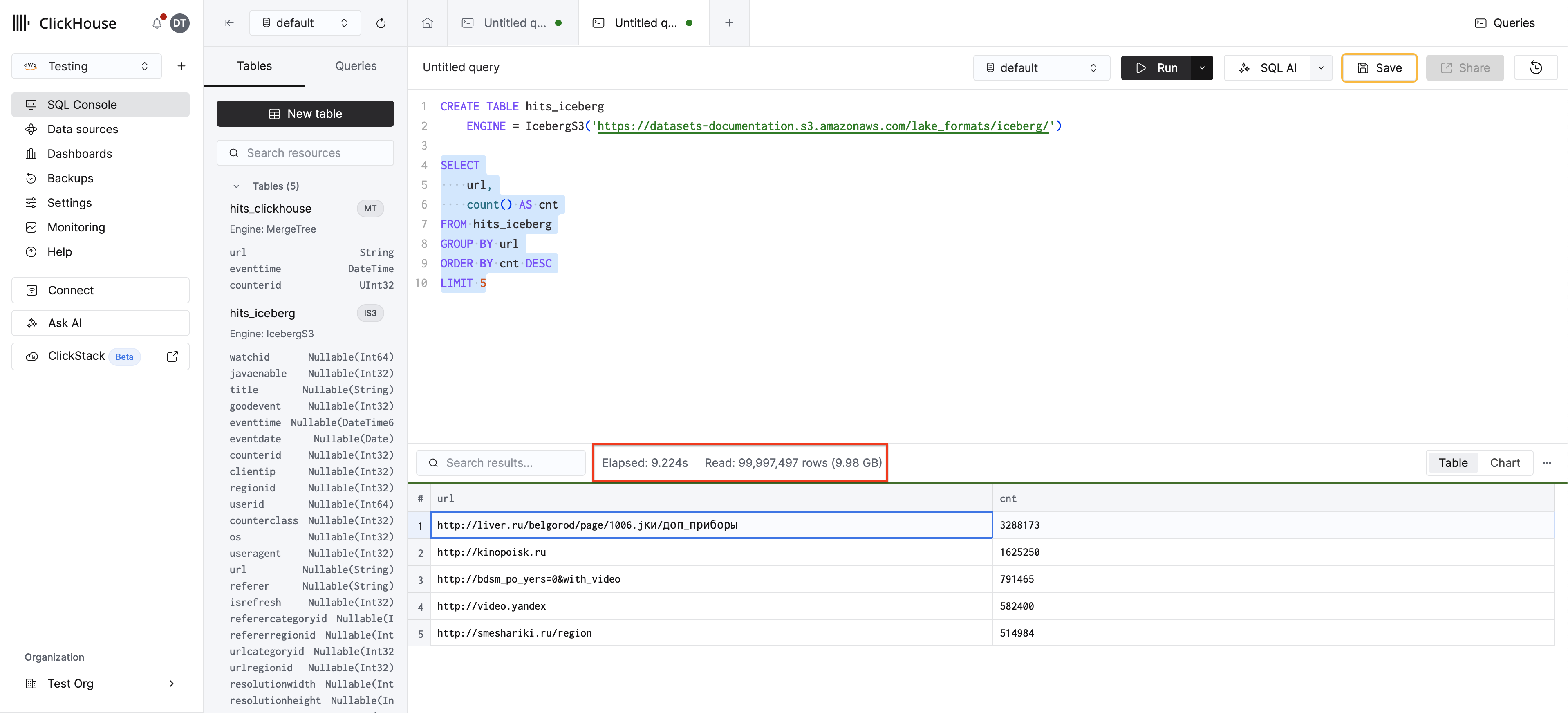
テーブルエンジンは、データキャッシュ、メタデータキャッシュ、スキーマ進化、およびタイムトラベルをサポートしています。テーブルエンジンの機能の詳細については直接クエリするガイドを、全機能の比較についてはサポートマトリックスを参照してください。
カタログへの接続
多くの組織では、テーブルのメタデータとデータディスカバリーを一元管理するために、データカタログを通じてIcebergテーブルを管理しています。ClickHouseは、DataLakeCatalogデータベースエンジンを使用してカタログへの接続をサポートしており、すべてのカタログテーブルをClickHouseデータベースとして公開します。これはよりスケーラブルなアプローチであり、新しいIcebergテーブルが作成された場合でも、追加の作業なしに常にClickHouseからアクセスできます。
以下は AWS Glue への接続例です:
各カタログタイプには固有の接続設定が必要です。サポートされているカタログの完全なリストと設定オプションについては、カタログガイドを参照してください。
テーブルの参照とクエリの実行:
ClickHouseはネイティブで複数のネームスペースをサポートしていないため、<database>.<table>はバッククォートで囲む必要があります。
詳細情報: データカタログへの接続では、DeltaおよびIcebergの例を使用したUnity Catalogの完全なセットアップ手順を説明しています。
クエリを実行する
上記のいずれの方法 (テーブル関数、テーブルエンジン、またはカタログ) を使用した場合でも、同じ ClickHouse SQL をすべてに対して使用できます。
クエリの構文は同一で、変わるのは FROM 句のみです。ClickHouse のすべての SQL 関数、結合、集計は、データソースに関わらず同じように動作します。
サブセットをClickHouseに読み込む
Icebergに直接クエリを実行するのは手軽ですが、パフォーマンスはネットワークスループットとファイルレイアウトに依存します。分析ワークロードには、ネイティブのMergeTreeテーブルにデータをロードすることを推奨します。
まず、ベースラインを取得するために、Icebergテーブルに対してフィルタリングクエリを実行します。
このクエリは、Icebergがcounteridフィルターを認識しないため、S3内のデータセット全体をスキャンします。完了まで数秒かかることを想定してください。
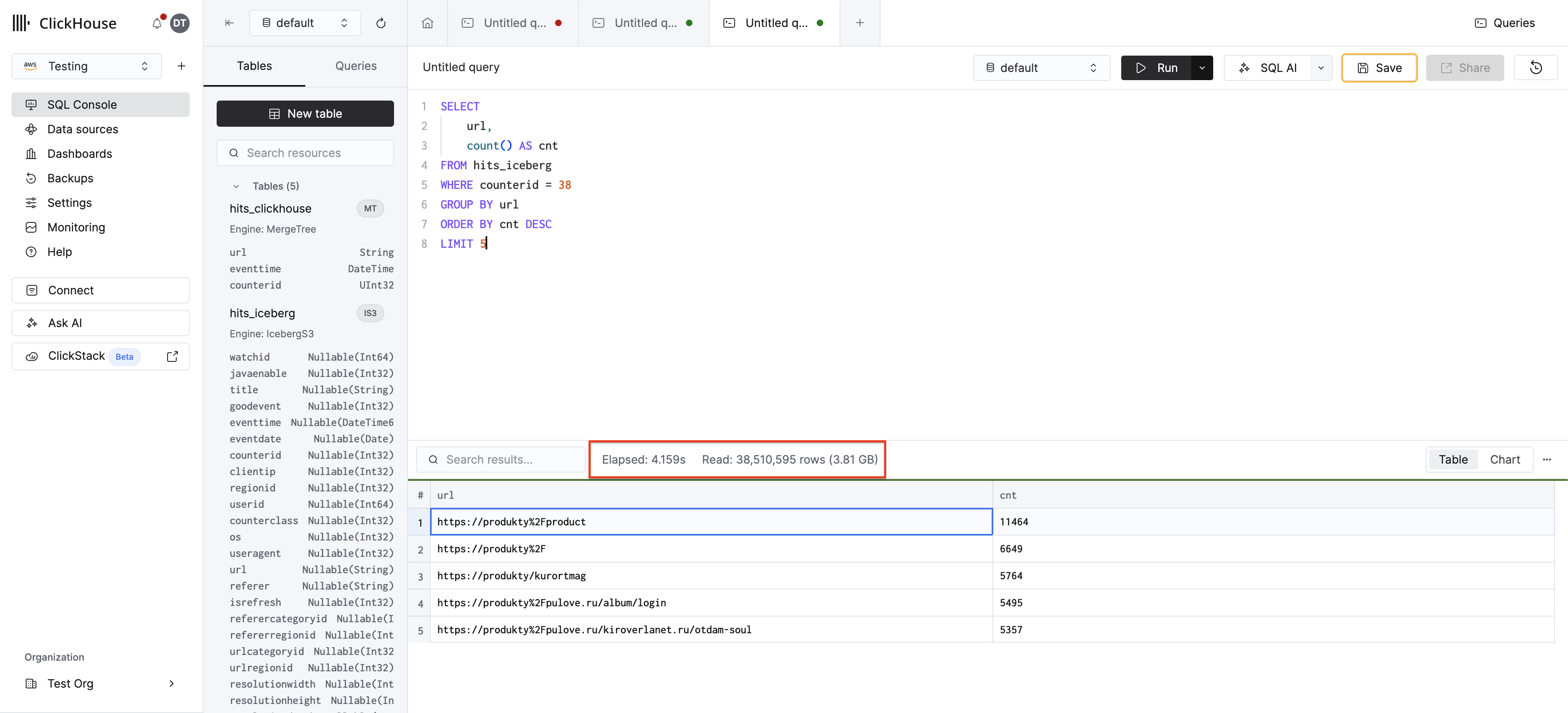
次に、MergeTreeテーブルを作成してデータをロードします:
MergeTreeテーブルに対して同じクエリを再実行します:
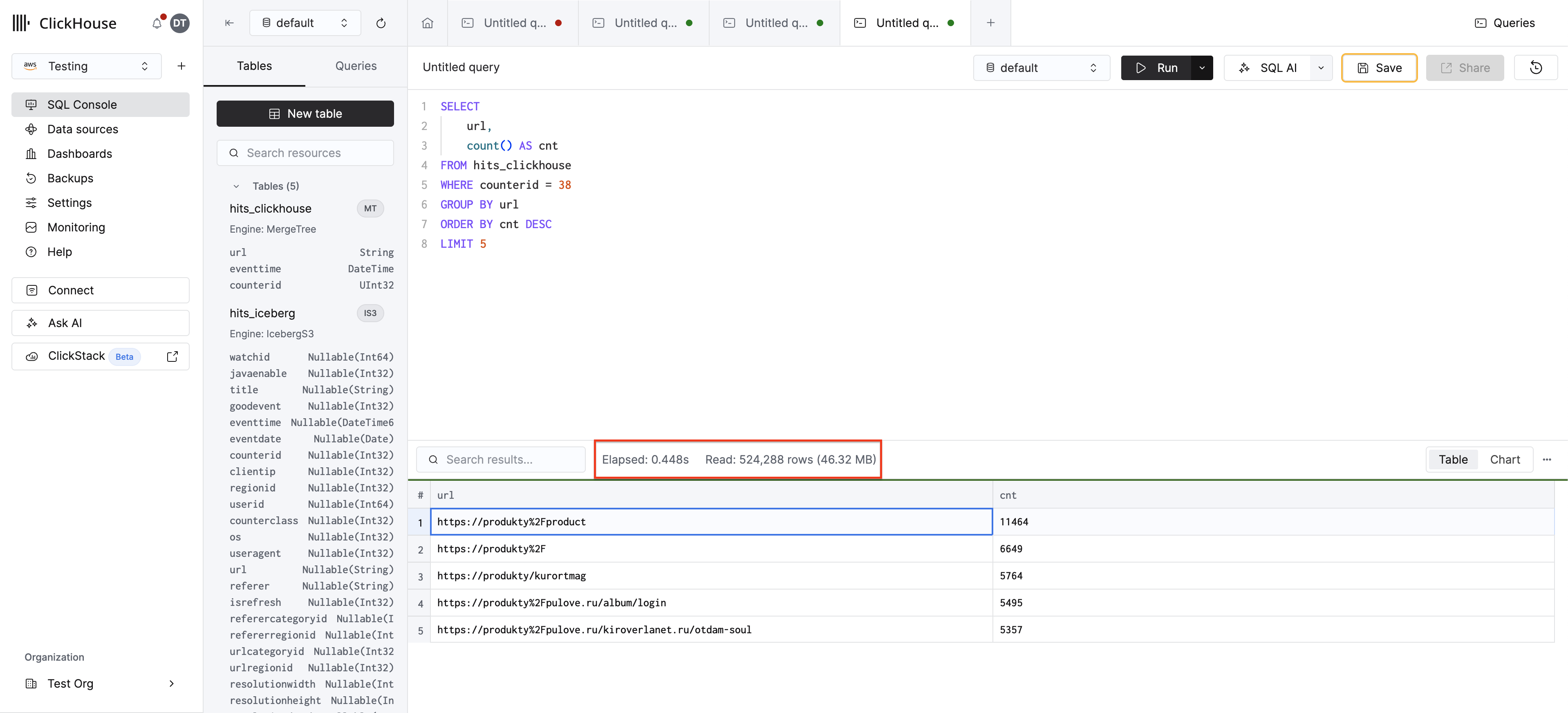
counterid は ORDER BY キーの最初のカラムであるため、ClickHouse のスパース主索引は関連するグラニュールに直接スキップします — 1億行すべてをスキャンする代わりに、counterid = 38 の行のみを読み取ります。その結果、処理速度が大幅に向上します。
分析の高速化ガイドでは、LowCardinality型、全文インデックス、最適化された順序付けキーを活用してさらに踏み込んだ内容を扱っており、2億8,300万行のデータセットで約40倍のパフォーマンス向上を実証しています。
詳細情報: MergeTreeによる分析の高速化では、スキーマの最適化、全文索引、および改善前後の包括的なパフォーマンス比較について説明しています。
Icebergへの書き込み
ClickHouseはIcebergテーブルへのデータの書き戻しも可能で、リバースETLワークフローを実現します。集計結果やサブセットを他のツール (Spark、Trino、DuckDBなど) が利用できる形式で公開することができます。
出力用のIcebergテーブルを作成します:
集計結果の書き込み:
作成されたIcebergテーブルは、Iceberg互換の任意のエンジンから読み取ることができます。
詳細情報: オープンテーブルフォーマットへのデータ書き込みでは、UK Price Paid データセットを使用した生データおよび集計結果の書き込みについて説明しています。ClickHouse の型を Iceberg にマッピングする際のスキーマの考慮事項についても取り上げています。
次のステップ
ここまででワークフロー全体を確認できたので、各項目をさらに詳しく見ていきましょう。
- 直接クエリする — 4 つの形式すべて、クラスター構成のバリエーション、テーブルエンジン、キャッシュ
- カタログに接続する — Delta と Iceberg を使用した Unity Catalog の完全なウォークスルー
- 分析を高速化する — スキーマ最適化、索引、約 40 倍高速化のデモ
- データレイクに書き込む — 生データの書き込み、集約データの書き込み、型マッピング
- サポートマトリクス — 各形式とストレージバックエンドにおける機能比較
