Jupyter Notebook と chDB を使ったデータ探索
このガイドでは、chDB(ClickHouse を基盤とした高速なインプロセス SQL OLAP エンジン)を利用して、Jupyter Notebook から ClickHouse Cloud 上のデータセットを探索する方法を学びます。
前提条件:
- 仮想環境
- 動作している ClickHouse Cloud サービスと、その接続情報
まだ ClickHouse Cloud アカウントをお持ちでない場合は、サインアップして トライアルに登録すると、開始用に 300 ドル分の無料クレジットを受け取れます。
このガイドで学べること:
- Jupyter Notebook から chDB を使って ClickHouse Cloud に接続する方法
- リモートデータセットをクエリし、結果を Pandas DataFrame に変換する方法
- 分析のためにクラウド上のデータとローカルの CSV ファイルを組み合わせる方法
- matplotlib を使ってデータを可視化する方法
このガイドでは、ClickHouse Cloud 上のスターターデータセットの 1 つとして提供されている UK Property Price データセットを使用します。 このデータセットには、1995 年から 2024 年までのイギリスにおける住宅の売却価格に関するデータが含まれています。
セットアップ
既存の ClickHouse Cloud サービスにこのデータセットを追加するには、アカウント情報で console.clickhouse.cloud にログインします。
左側のメニューから Data sources をクリックし、続いて Predefined sample data をクリックします:
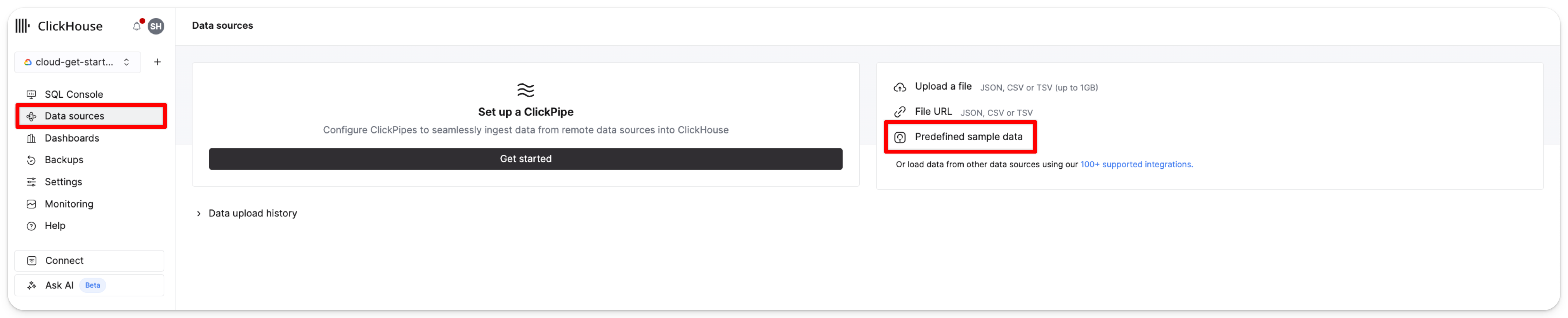
UK property price paid data (4GB) のカードで Get started を選択します:
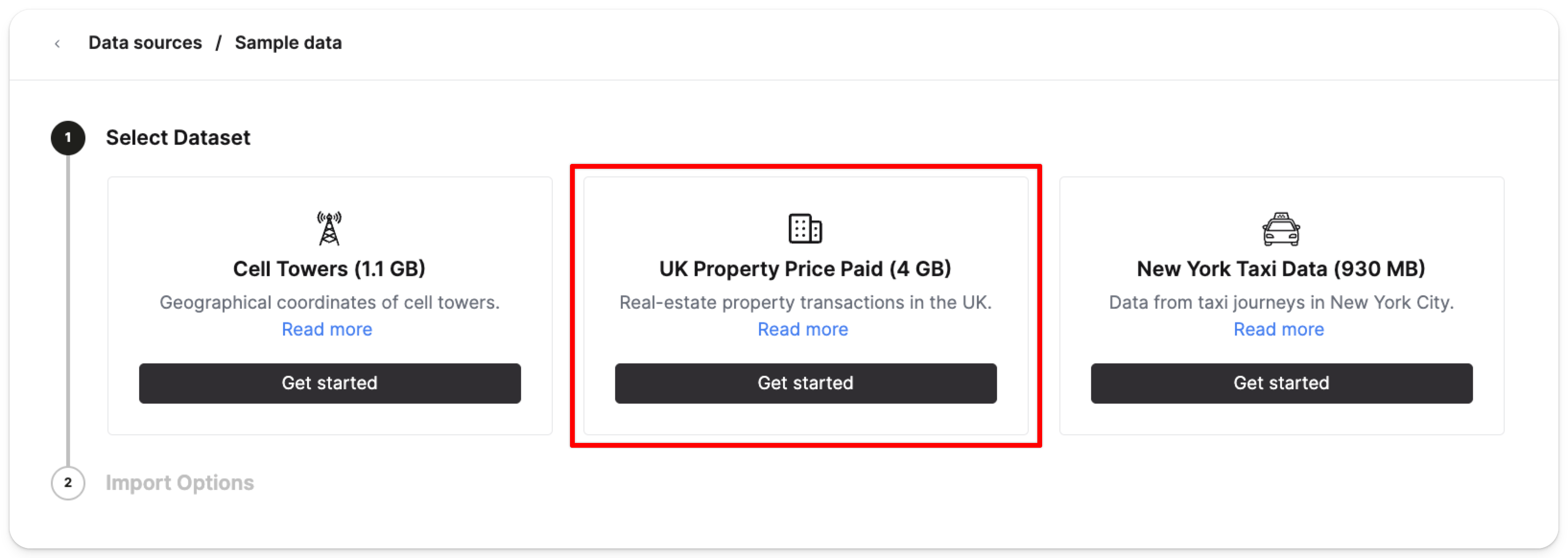
続いて Import dataset をクリックします:
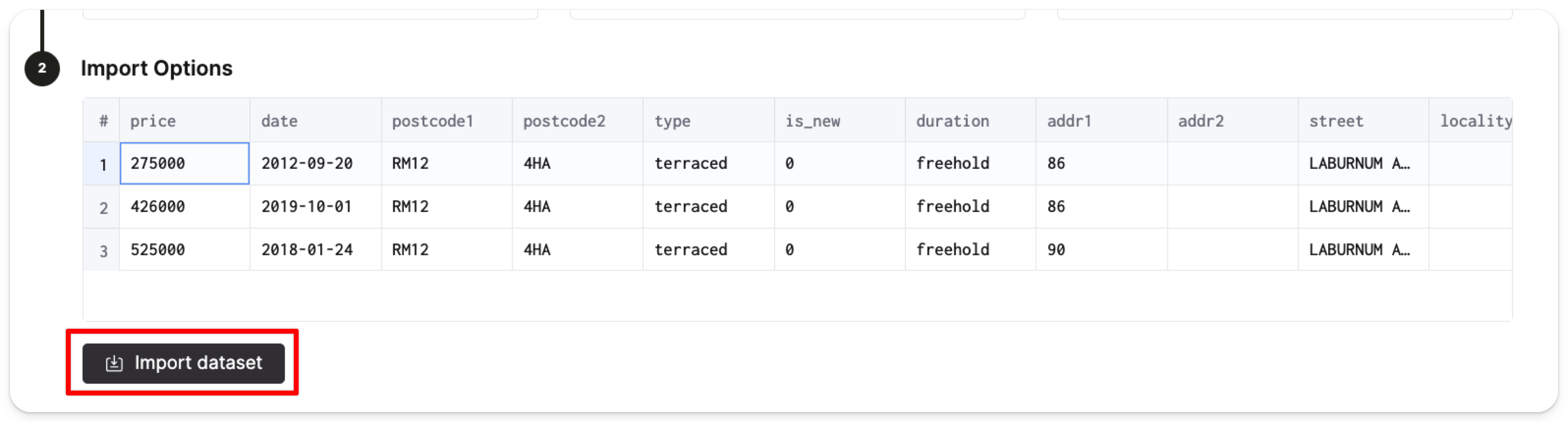
ClickHouse は自動的に pp_complete テーブルを default データベース内に作成し、そのテーブルに 2,892 万行の価格ポイントデータを投入します。
認証情報が漏えいする可能性を低減するため、ClickHouse Cloud のユーザー名とパスワードをローカルマシン上の環境変数として設定することを推奨します。 ターミナルから次のコマンドを実行して、ユーザー名とパスワードを環境変数として追加します:
上記の環境変数は、現在のターミナルセッションが続いている間だけ有効です。 恒久的に設定するには、使用しているシェルの設定ファイルに追加してください。
次に、仮想環境を有効化します。 仮想環境内で、次のコマンドを使って Jupyter Notebook をインストールします。
次のコマンドで Jupyter Notebook を起動します:
新しいブラウザーウィンドウが開き、localhost:8888 上に Jupyter インターフェースが表示されます。
新しい Notebook を作成するには、File > New > Notebook をクリックします。
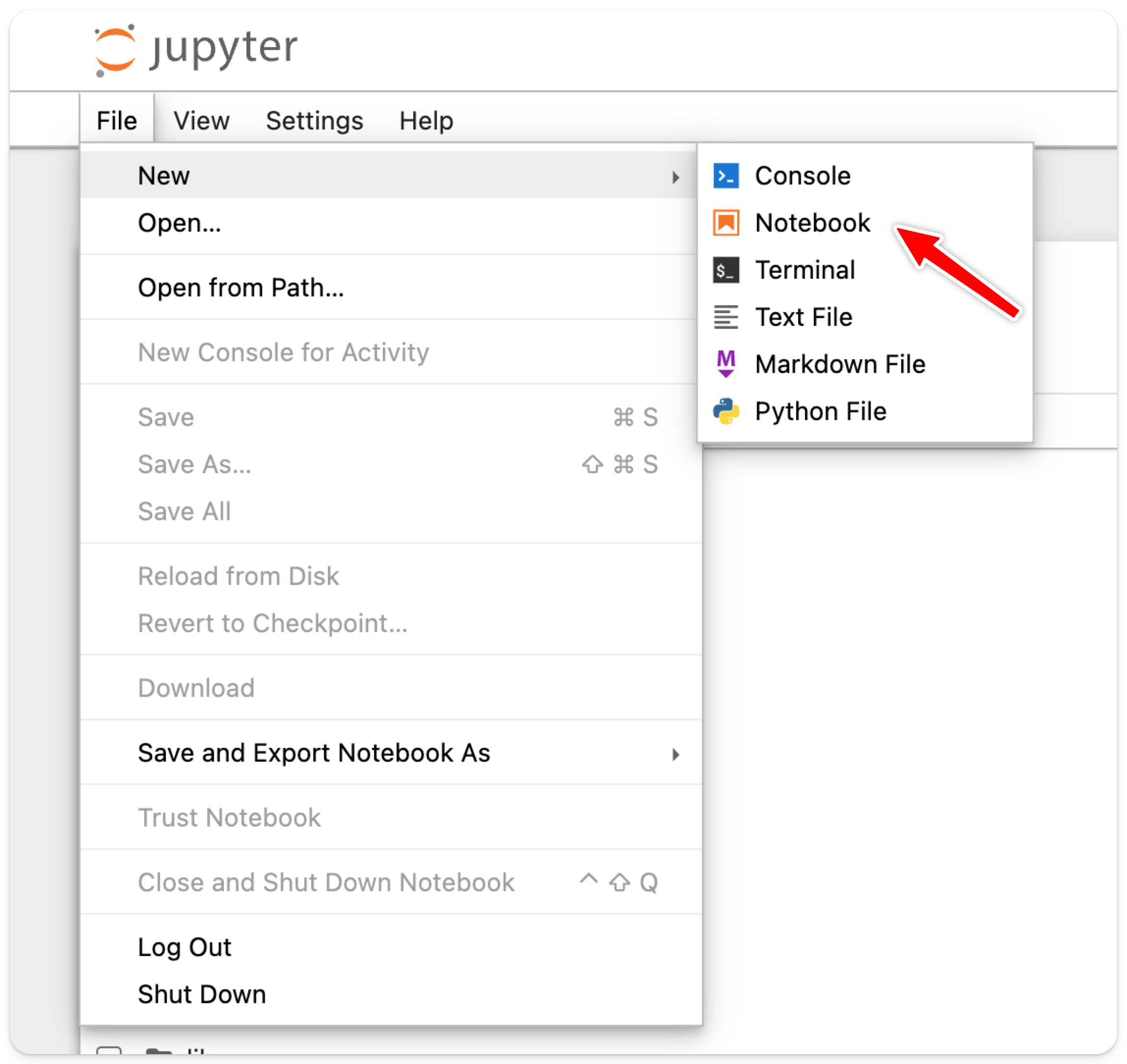
カーネルの選択を求められます。
利用可能な Python カーネルのいずれかを選択します。この例では ipykernel を選択します:
空のセルで、次のコマンドを入力して chDB をインストールします。これは、リモートの ClickHouse Cloud インスタンスに接続するために使用します。
これで chDB をインポートし、簡単なクエリを実行して、すべてが正しくセットアップされていることを確認できます。
データの探索
UK price paid データセットの準備と、Jupyter Notebook 上での chDB の起動が完了したので、ここからデータの探索を始めましょう。
特定の地域(例えば首都ロンドン)における価格が、時間の経過とともにどのように変化してきたかを確認したいとします。
ClickHouse の remoteSecure 関数を使うと、ClickHouse Cloud から簡単にデータを取得できます。
chDB に対して、このデータをプロセス内で Pandas のデータフレームとして返すように指示できます。これは、データを扱ううえで便利で馴染みのある形式です。
次のクエリを実行して、ClickHouse Cloud サービスから UK price paid データを取得し、それを pandas.DataFrame に変換します。
上記のスニペットでは、chdb.query(query, "DataFrame") が指定したクエリを実行し、その結果を Pandas の DataFrame としてターミナル上に出力します。
このクエリでは、ClickHouse Cloud に接続するために remoteSecure 関数を使用しています。
remoteSecure 関数は、次のパラメータを取ります。
- 接続文字列
- 使用するデータベース名とテーブル名
- ユーザー名
- パスワード
セキュリティのベストプラクティスとしては、関数内で直接指定するのではなく、ユーザー名とパスワードのパラメータには環境変数を使用することを推奨しますが、必要であれば直接指定することも可能です。
remoteSecure 関数はリモートの ClickHouse Cloud サービスに接続し、クエリを実行して結果を返します。
データ量によっては、これに数秒かかる場合があります。
この例では、年ごとの平均価格を返し、town='LONDON' でフィルタしています。
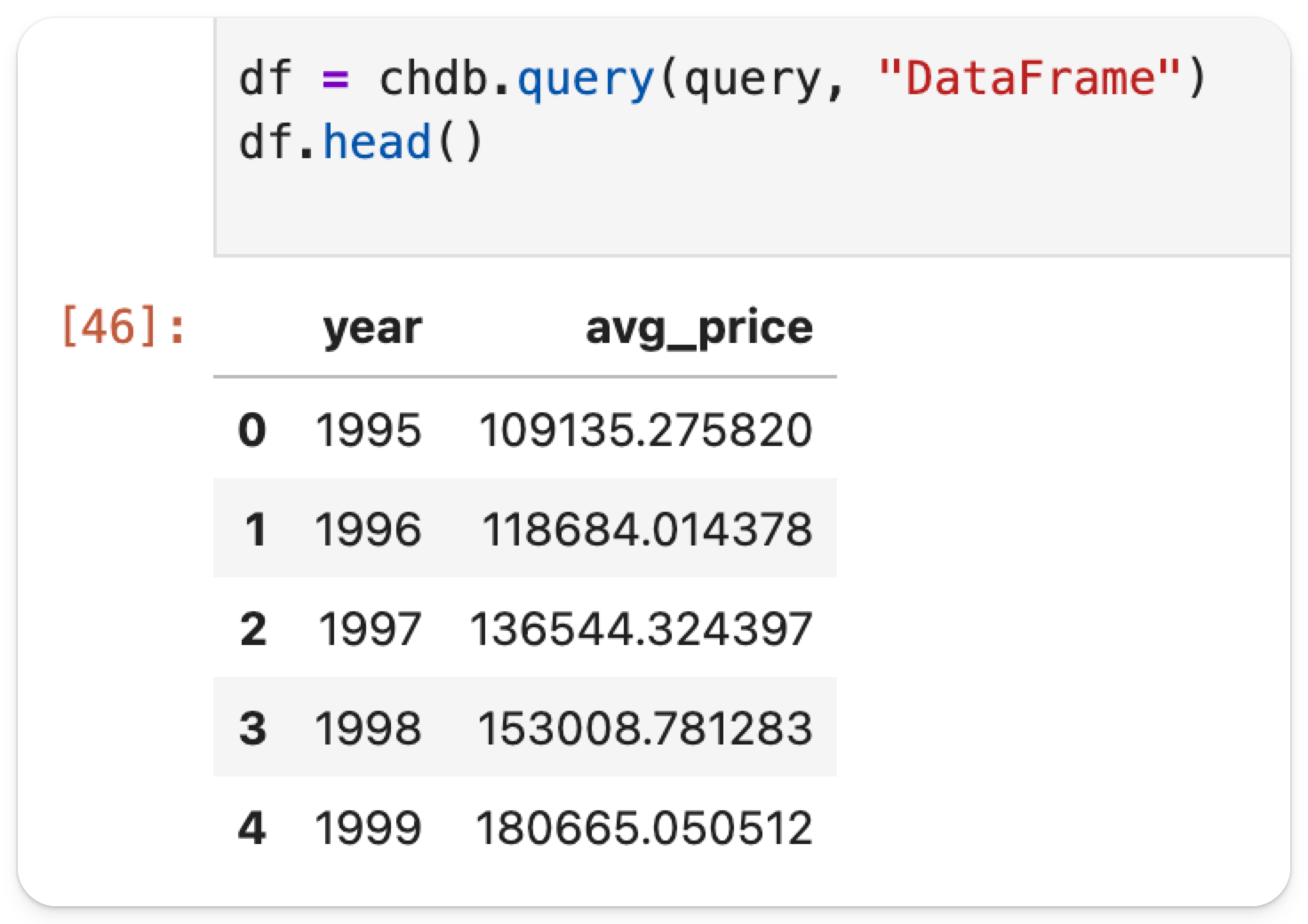
結果は df という変数の DataFrame として保存されます。
df.head は、返されたデータの先頭数行のみを表示します。
新しいセルで次のコマンドを実行して、列の型を確認します。
ClickHouse では date は型 Date ですが、生成されたデータフレームでは型が uint16 であることに注意してください。
chDB は、DataFrame を返す際に最も適切な型を自動的に推論します。
データが馴染みのある形式で利用できるようになったので、ロンドンの不動産価格が時間とともにどのように変化してきたかを確認してみましょう。
新しいセルで次のコマンドを実行し、matplotlib を使ってロンドンの価格の時間変化を示すシンプルなグラフを作成します。
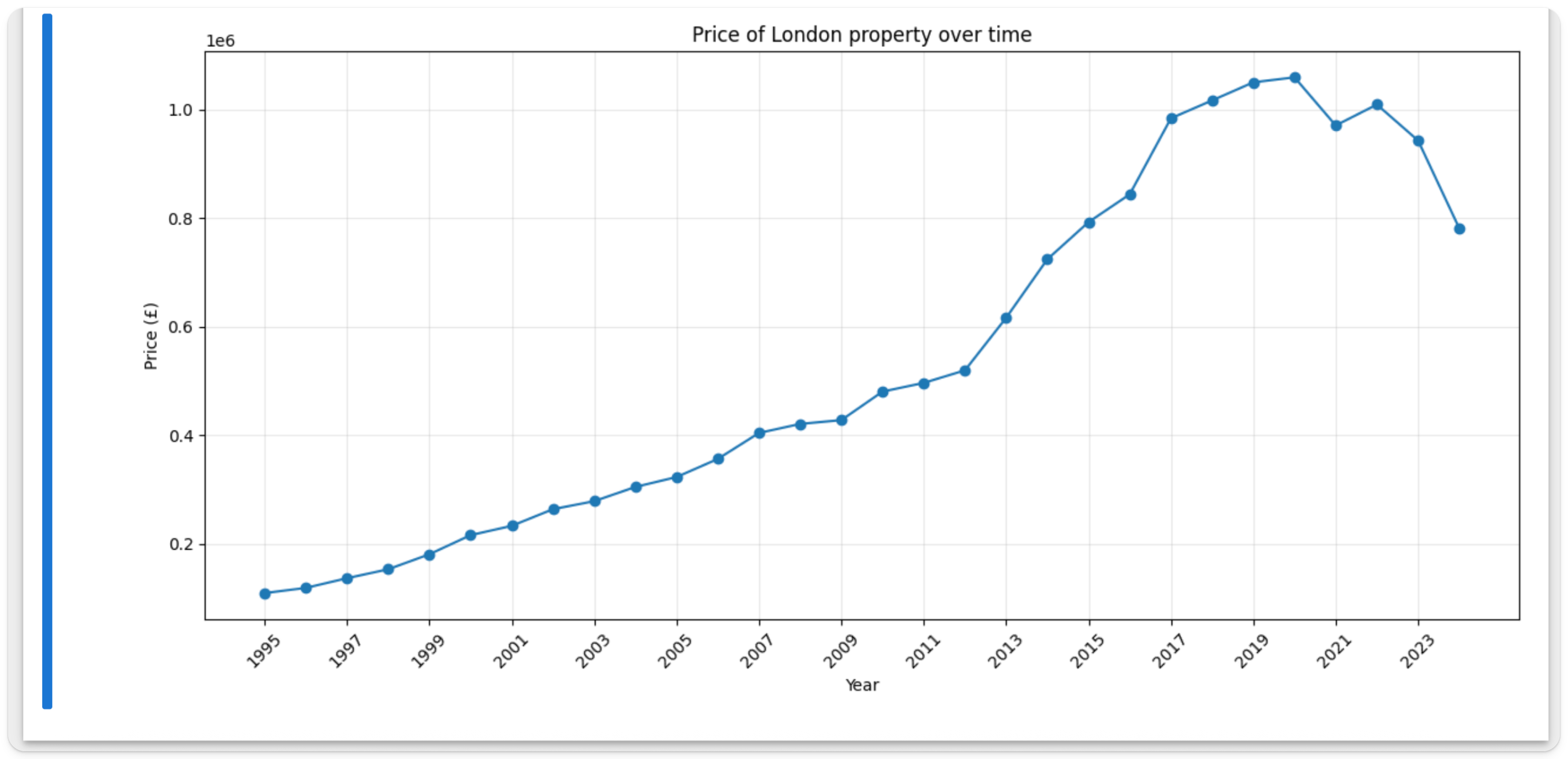
おそらく想像がつくと思いますが、ロンドンの不動産価格は時間の経過とともに大きく上昇しています。
同僚のデータサイエンティストが、住宅関連の変数を追加した .csv ファイルを送ってくれており、 ロンドンで販売された住宅の件数が時間とともにどのように変化してきたのかに関心を持っています。 これらの変数のいくつかを住宅価格とあわせてプロットし、相関関係が見られるか確認してみましょう。
ローカルマシン上のファイルを直接読み込むには、file テーブルエンジンを使用できます。
新しいセルで、次のコマンドを実行してローカルの .csv ファイルから新しい DataFrame を作成します。
Details
1 回のステップで複数のソースから読み込む
1 回のステップで複数のソースから読み込むことも可能です。次のクエリのようにJOIN を使用して実行できます: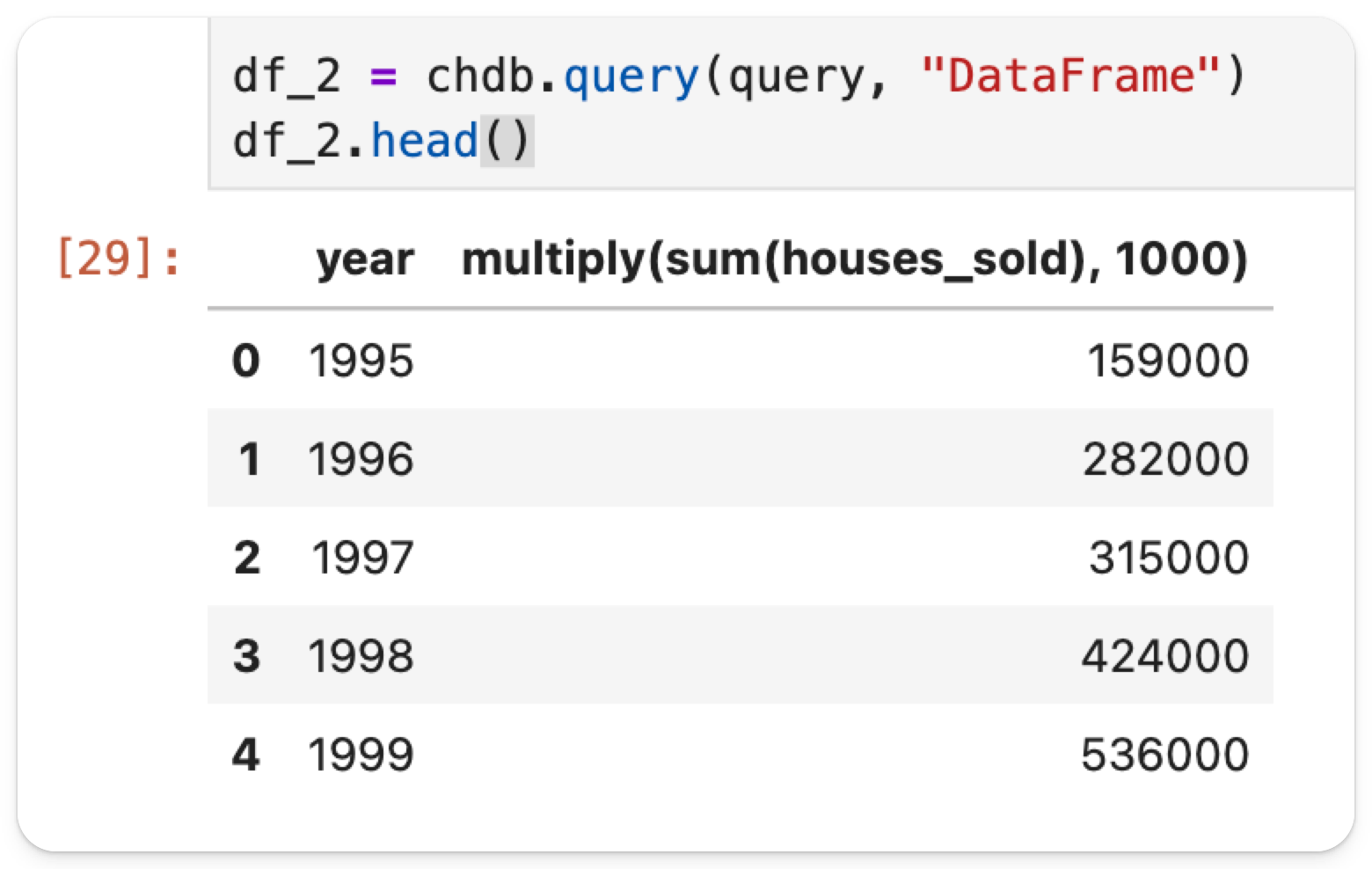
2020年以降のデータはありませんが、1995年から2019年までの各年について、2つのデータセットを比較してプロットできます。 新しいセルで次のコマンドを実行します:
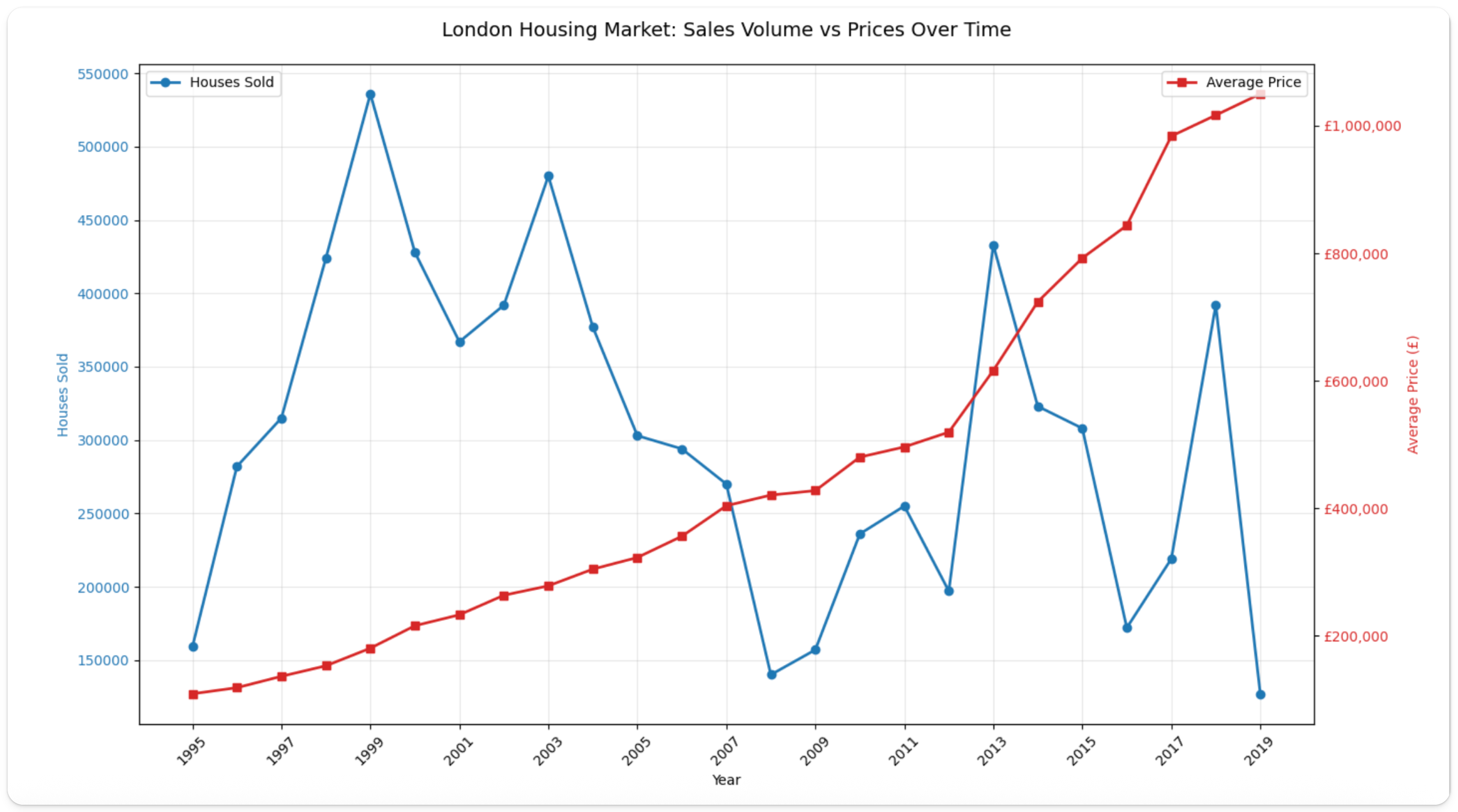
プロットされたデータから、1995年には販売件数が約160,000件でスタートし、急速に増加して1999年には約540,000件でピークに達していることが分かります。 その後は2000年代半ばにかけて急激に減少し、2007〜2008年の金融危機の際に大きく落ち込み、約140,000件まで低下しています。 一方で価格は、1995年の約£150,000から2005年までに約£300,000へと、着実かつ一貫した成長を示しています。 2012年以降は成長が大きく加速し、概ね£400,000から2019年までに£1,000,000を超える水準まで急激に上昇しています。 販売件数とは異なり、価格は2008年の危機の影響をほとんど受けず、上昇基調を維持し続けています。驚くべき動きです。
まとめ
このガイドでは、ClickHouse Cloud とローカルのデータソースを接続することで、chDB により Jupyter Notebook 上でシームレスにデータ探索を行えることを示しました。
UK Property Price データセットを使用して、remoteSecure() 関数でリモートの ClickHouse Cloud 上のデータにクエリを実行し、file() テーブルエンジンでローカルの CSV ファイルを読み込み、結果をそのまま分析や可視化に用いる Pandas DataFrame に変換する方法を説明しました。
chDB を通じて、データサイエンティストは ClickHouse の強力な SQL 機能を、Pandas や matplotlib といった馴染みのある Python ツールと組み合わせて利用でき、複数のデータソースを統合した包括的な分析を容易に実現できます。
ロンドン在住の多くのデータサイエンティストは、当面は自分の家やアパートを買う余裕はないかもしれませんが、少なくとも自分たちを市場から締め出しているそのマーケットを分析することはできます。
