テーブルのシャードとレプリカ
このトピックは ClickHouse Cloud には適用されません。ClickHouse Cloud では、Parallel Replicas は従来のシェアードナッシング型 ClickHouse クラスターにおける複数シャードのように機能し、オブジェクトストレージがレプリカを代替することで、高可用性とフォールトトレランスを実現します。
ClickHouse におけるテーブルシャードとは?
従来型の shared-nothing アーキテクチャの ClickHouse クラスターでは、① データ量が単一サーバーで扱うには大きすぎる場合、または ② 単一サーバーではデータ処理が遅すぎる場合にシャーディングが行われます。次の図はケース ①、つまり uk_price_paid_simple テーブルが 1 台のマシンの容量を超えている状況を示しています:
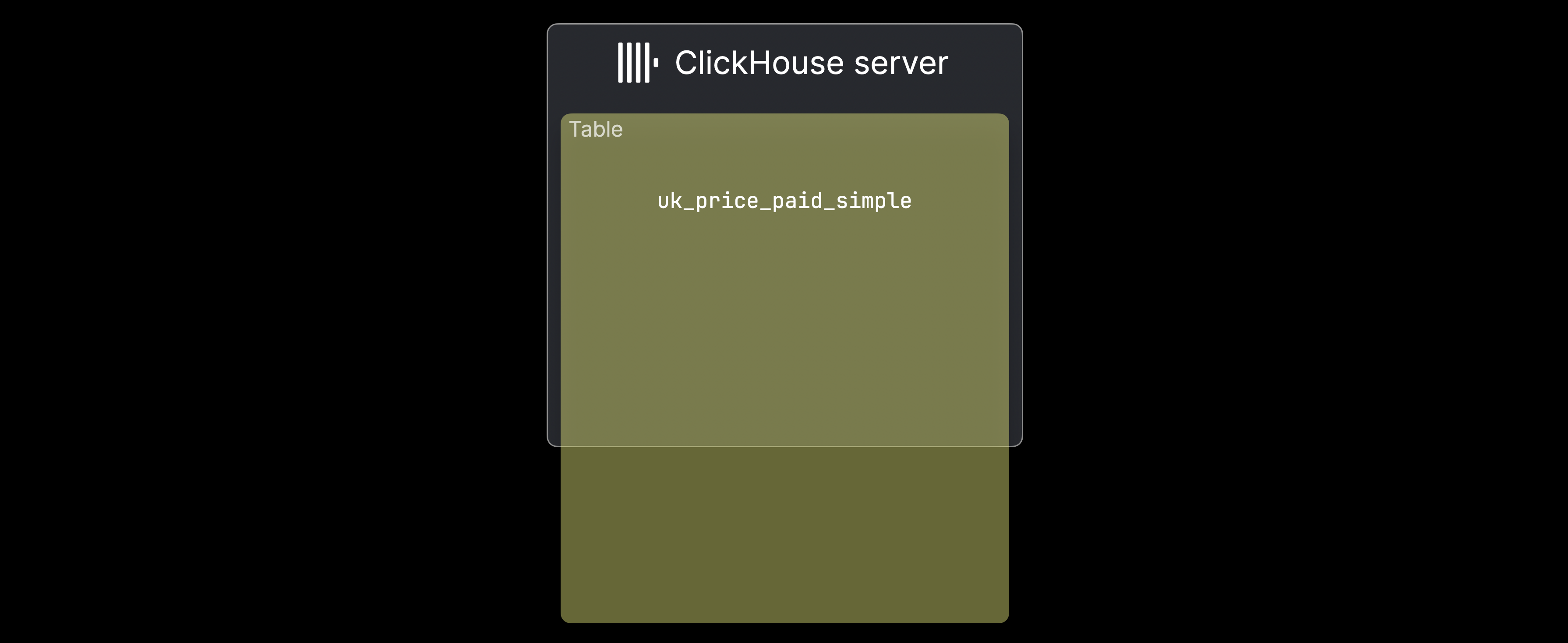
このような場合、データはテーブルシャードという形で複数の ClickHouse サーバーに分割して配置できます:
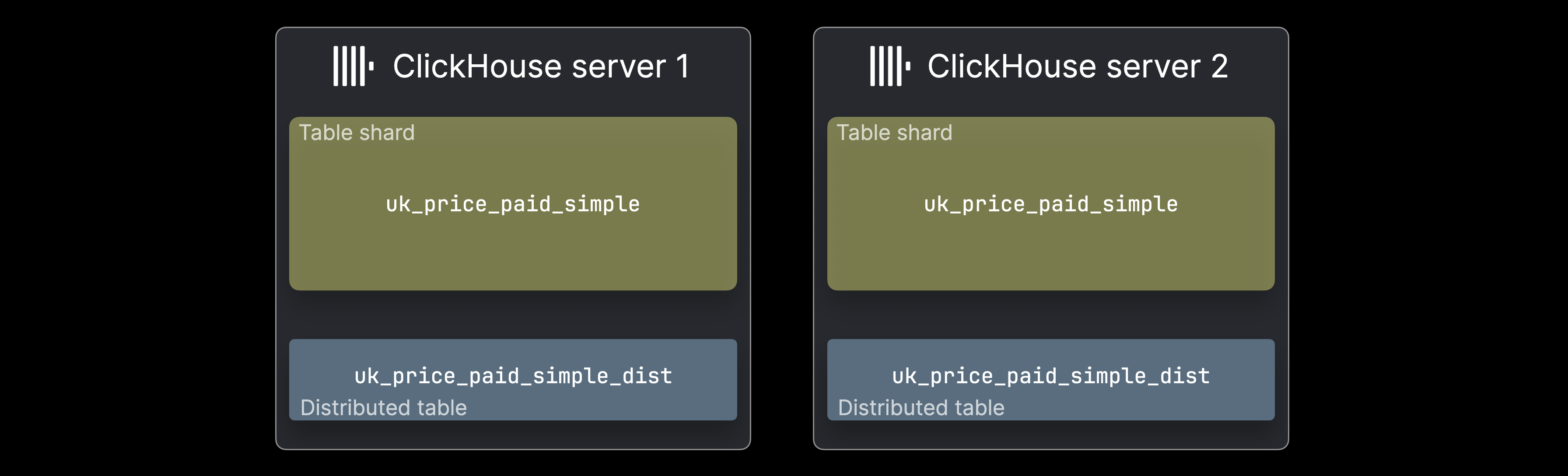
各 shard はデータの一部を保持し、独立してクエリ可能な通常の ClickHouse テーブルとして動作します。ただし、そのシャードに対するクエリで処理されるのは、そのシャードに含まれるサブセットのみであり、これはデータ分布によっては妥当なユースケースになり得ます。一般的には、 (多くの場合サーバーごとに) distributed table が全データセットに対する統一的なビューを提供します。この distributed table 自体はデータを保持せず、すべてのシャードに SELECT クエリを転送して結果を集約し、INSERT をルーティングしてデータを均等に分散させます。
分散テーブルの作成
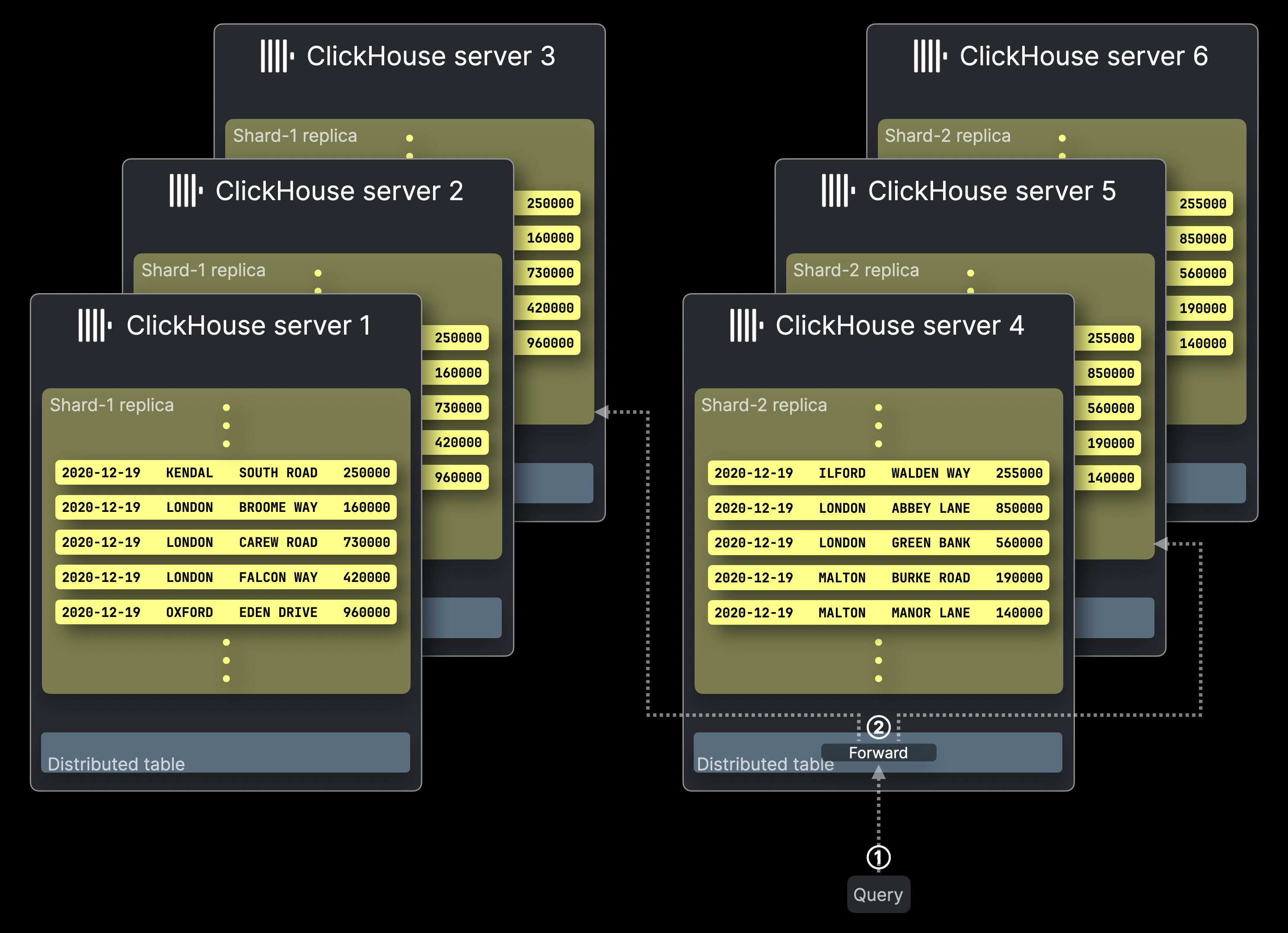
SELECT クエリのフォワーディングと INSERT のルーティングを説明するために、2 台の ClickHouse サーバー上の 2 つのシャードに分割された、テーブルパーツとは で使用したサンプルテーブルを用います。まず、この構成に対応する Distributed table を作成するための DDL ステートメントを示します。
ON CLUSTER 句は DDL ステートメントを分散 DDL ステートメントにし、ClickHouse に対して、test_cluster のクラスター定義に記載されているすべてのサーバー上にテーブルを作成するよう指示します。分散 DDL を利用するには、クラスターアーキテクチャ内に追加の Keeper コンポーネントが必要です。
Distributed エンジンのパラメータとして、cluster 名 (test_cluster)、シャードされたターゲットテーブルのデータベース名 (uk)、そのターゲットテーブル名 (uk_price_paid_simple)、および INSERT ルーティング用のシャーディングキーを指定します。この例では、rand 関数を使用して、行を各シャードにランダムに割り当てます。ただし、ユースケースに応じて、複雑なものも含め任意の式をシャーディングキーとして利用できます。次のセクションでは、INSERT ルーティングがどのように動作するかを説明します。
INSERT ルーティング
以下の図は、ClickHouse において分散テーブルへの INSERT がどのように処理されるかを示しています。
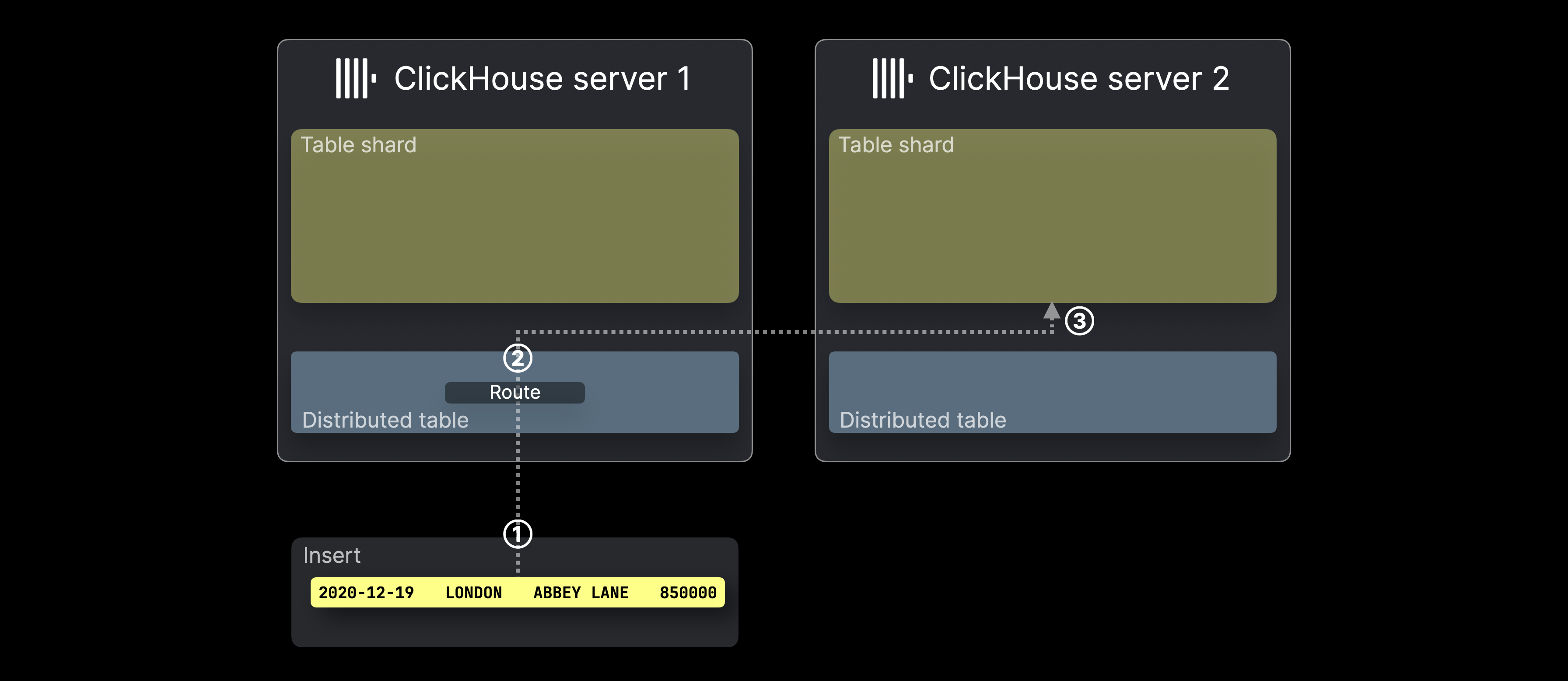
① 分散テーブルを対象とする INSERT(1 行のみ)が、テーブルをホストしている ClickHouse サーバーに、直接またはロードバランサー経由で送信されます。
② INSERT の各行(この例では 1 行のみ)に対して、ClickHouse はシャーディングキー(ここでは rand())を評価し、その結果を分片サーバー数で割った余りを取り、その値をターゲットサーバー ID として使用します(ID は 0 から始まり、1 ずつ増加します)。その後、その行は該当するサーバー上のテーブル分片に転送され、③ 挿入されます。
次のセクションでは、SELECT フォワーディングの仕組みについて説明します。
SELECT フォワーディング
この図は、ClickHouse で分散テーブルを使用した場合に、SELECT クエリがどのように処理されるかを示しています。
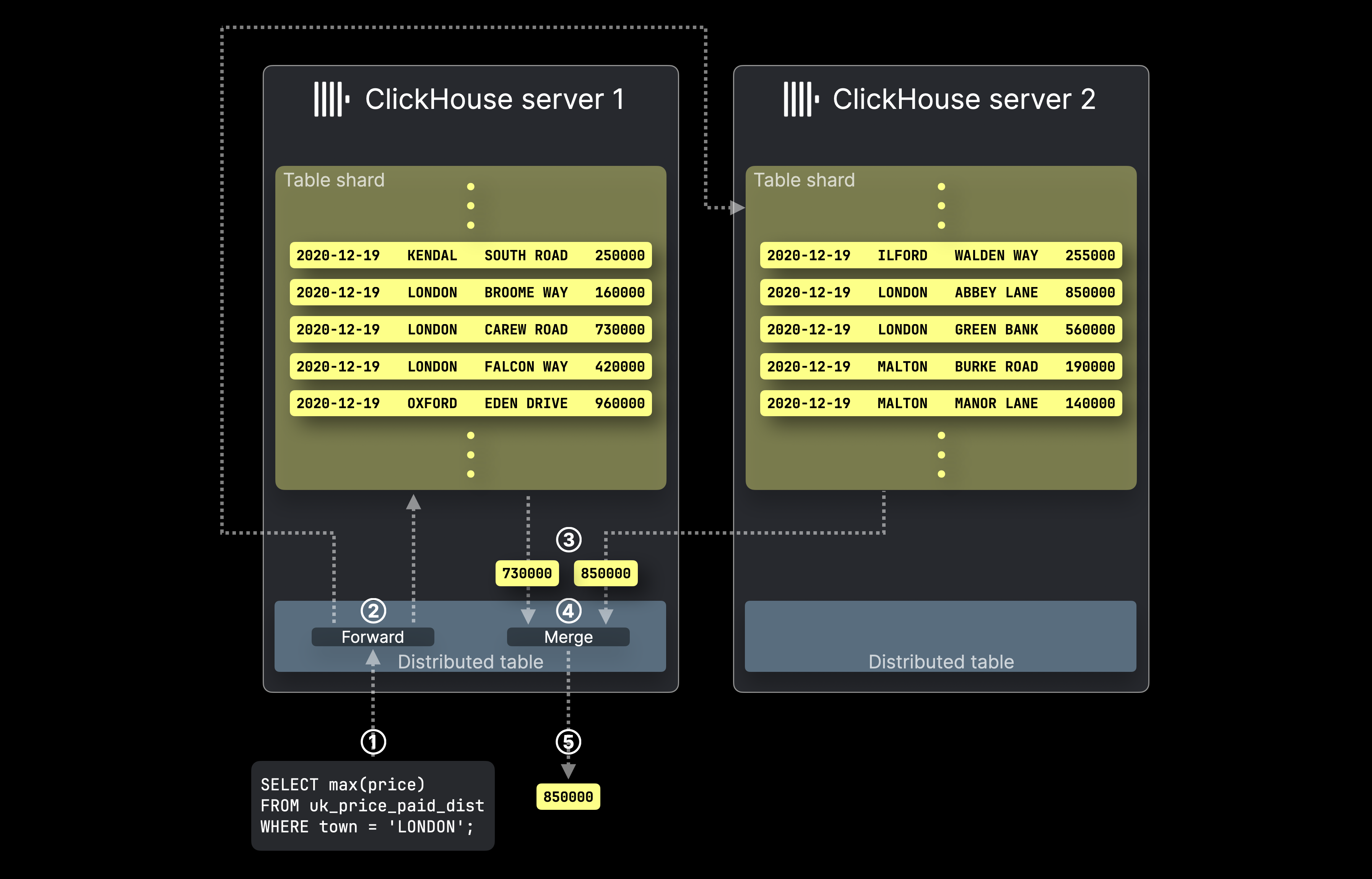
① 分散テーブルを対象とする SELECT 集計クエリが、該当する ClickHouse サーバーに、直接またはロードバランサー経由で送信されます。
② Distributed テーブルは、対象テーブルの分片をホストしているすべてのサーバーにクエリを転送し、各 ClickHouse サーバーはそれぞれのローカル集計結果を 並列に 計算します。
その後、最初に対象となった分散テーブルをホストする ClickHouse サーバーが、③ すべてのローカル結果を収集し、④ それらをマージして最終的なグローバル結果を作成し、⑤ クエリ送信元に返します。
ClickHouseのテーブルレプリカとは何ですか?
ClickHouseのレプリケーションは、分片データのコピーを複数のサーバーに保持することで、データ整合性とフェイルオーバーを実現します。ハードウェア障害は避けられないため、レプリケーションによって各分片に複数のレプリカを持たせることで、データ損失を防止できます。書き込みは任意のレプリカに対して、直接、または処理対象のレプリカを選択する分散テーブル経由で行えます。変更は自動的に他のレプリカへ伝播されます。障害やメンテナンスが発生した場合でも、データは他のレプリカで引き続き利用可能であり、障害が発生したホストが復旧すると、自動的に同期して最新の状態に保たれます。
レプリケーションには、クラスタアーキテクチャにおけるKeeperコンポーネントが必要である点に注意してください。
次の図は、6台のサーバーで構成されるClickHouseクラスタを示しています。先に紹介した2つのテーブル分片 Shard-1 と Shard-2 には、それぞれ3つのレプリカがあります。このクラスタにクエリが送信されます。
クエリ処理はレプリカのない構成とほぼ同様で、各分片から1つのレプリカだけがクエリを実行します。
レプリカはデータ整合性とフェイルオーバーを実現するだけでなく、複数のクエリを異なるレプリカで並列実行できるようにすることで、クエリ処理のスループットも向上させます。
① 分散テーブルを対象とするクエリが、直接またはロードバランサー経由で、対応するClickHouseサーバーに送信されます。
② 分散テーブルはクエリを各分片の1つのレプリカに転送し、選択されたレプリカをホストする各ClickHouseサーバーが、それぞれローカルのクエリ結果を並列に計算します。
以降の処理は、レプリカのない構成の場合と同じであり、上の図には示していません。最初に対象となった分散テーブルをホストするClickHouseサーバーが、すべてのローカル結果を収集し、それらをマージして最終的なグローバル結果を生成し、クエリ送信元に返します。
② のクエリ転送戦略はClickHouseで設定できる点に注意してください。デフォルトでは、この図とは異なり、分散テーブルは利用可能であればローカルレプリカをprefersしますが、他のロードバランシング戦略も使用できます。
もっと詳しい情報を探すには
テーブルの分片とレプリカに関するこの概要レベルの紹介より詳しい内容については、デプロイとスケーリングガイドを参照してください。
また、ClickHouse の分片とレプリカについてさらに深く理解するには、次のチュートリアル動画も強く推奨します。
