テーブルパーツ
ClickHouse におけるテーブルパーツとは?
ClickHouse の MergeTree engine family に属する各テーブルのデータは、ディスク上では変更不可能な data parts の集合として構成されています。
これを説明するために、この テーブル (UK property prices dataset を基にしたもの) を例として使用します。このテーブルには、英国で売却された不動産について、日付・町名・通り名・価格が記録されています。
このテーブルには、ClickHouse SQL Playground でクエリを実行できます。
データパーツは、行の集合がテーブルに挿入されるたびに作成されます。次の図はその概要を示しています。
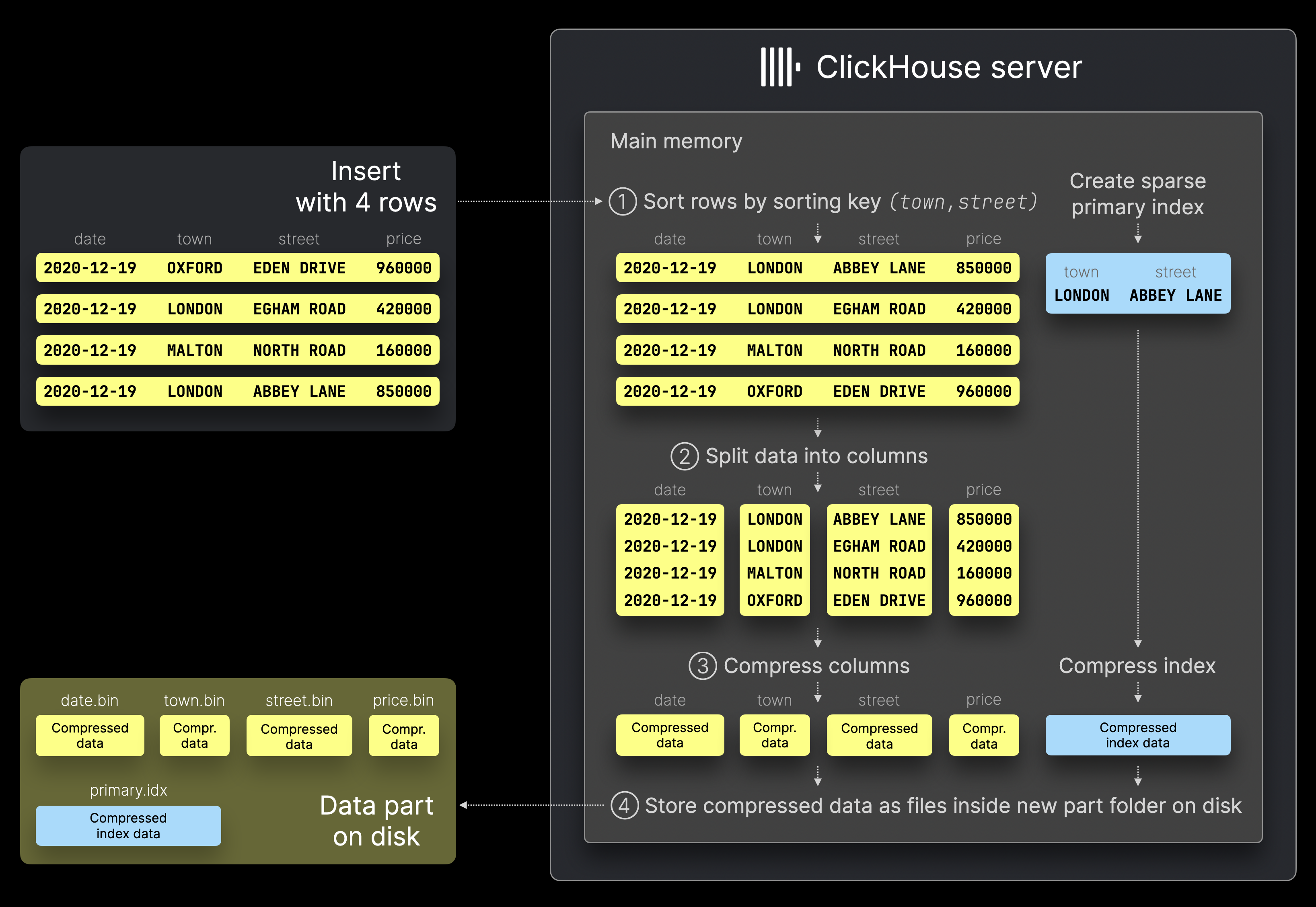
ClickHouse サーバーが、上の図に示した 4 行の INSERT (INSERT INTO 文 などを通じて) を処理するとき、いくつかのステップを実行します。
① ソート: 行はテーブルのソートキー (town, street) でソートされ、ソート済みの行に対して スパース主キーインデックス が生成されます。
② 分割: ソート済みデータは列ごとに分割されます。
③ 圧縮: 各列は圧縮されます。
④ ディスクへの書き込み: 圧縮された各列は、INSERT のデータパーツを表す新しいディレクトリ内にバイナリ列ファイルとして保存されます。スパース主キーインデックスも圧縮され、同じディレクトリに保存されます。
テーブルで使用しているエンジンに応じて、ソートと合わせて追加の変換が行われる場合があります。
データパーツは自己完結しており、中央のカタログを必要とせずにその内容を解釈するために必要な、すべてのメタデータを含みます。スパース主キーインデックスに加えて、パーツには、副次的な data skipping インデックス、カラム統計、チェックサム、 (パーティション が使われている場合の) min-max インデックス、そしてその他の情報が含まれます。
パーツのマージ
テーブルごとの パーツ 数を管理するために、バックグラウンドマージ ジョブが一定間隔で小さな パーツ をより大きなものへと順次まとめ、設定可能な 圧縮サイズ (通常は約 150 GB) に達するまでマージを行います。マージされた パーツ は非アクティブとしてマークされ、設定可能な 時間が経過すると削除されます。時間の経過とともに、この処理によってマージ済み パーツ の階層構造が形成されるため、これを MergeTree テーブルと呼びます。
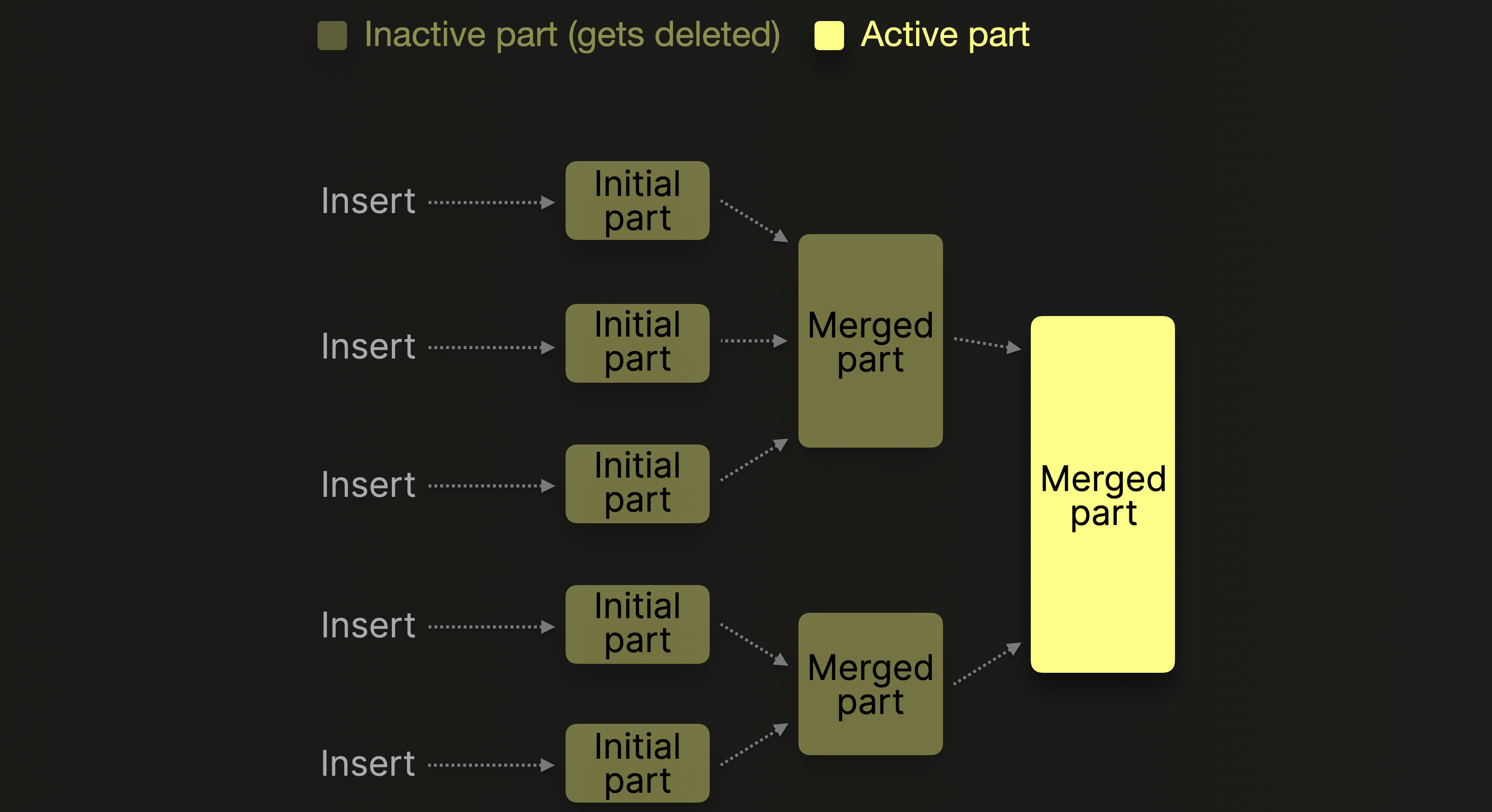
初期 パーツ 数とマージ処理のオーバーヘッドを最小限に抑えるために、データベースクライアントは、20,000 行をまとめて挿入するといった形でタプルをバルク挿入するか、あるいは 非同期挿入モード を使用することが推奨されています。非同期挿入モードでは、ClickHouse は同一テーブルに対する複数の INSERT リクエストから行をバッファリングし、バッファサイズが設定可能なしきい値を超えるか、タイムアウトが発生した時点でのみ新しいパーツを作成します。
テーブルパーツの監視
仮想列 _part を使用して、サンプルテーブルに現在存在するすべてのアクティブなパーツの一覧をクエリできます。
上記のクエリは、ディスク上のディレクトリ名を取得します。各ディレクトリはテーブルのアクティブなデータパートを表します。これらのディレクトリ名を構成する要素にはそれぞれ特定の意味があり、その詳細は、さらに深く調べたい方のために こちら に記載されています。
別の方法として、ClickHouse はすべてのテーブルのすべてのパーツに関する情報を system.parts システムテーブルで保持しており、次のクエリは、先ほどのサンプルテーブルについて、現在アクティブなすべてのパーツとそのマージレベル、および各パーツに保存されている行数の一覧を返します。
マージレベルは、そのパーツに対してマージが追加で行われるたびに 1 ずつ増加します。レベル 0 は、まだマージされていない新しいパーツであることを示します。
