テーブルパーティション
ClickHouse におけるテーブルパーティションとは?
パーティションは、テーブルの data parts を MergeTree engine family の中で整理された論理的な単位としてグループ化する仕組みです。これは、時間範囲、カテゴリ、その他のキー属性などの特定の条件に沿って、データを概念的に意味のある形で構造化する方法です。これらの論理的な単位によって、データの管理、クエリの実行、および最適化が容易になります。
PARTITION BY
テーブルを作成するときに PARTITION BY 句を指定することで、パーティション分割を有効にできます。この句には任意のカラムに対する SQL 式を含めることができ、その結果に基づいて各行が属するパーティションが決まります。
これを示すために、enhanceして、What are table parts のサンプルテーブルに PARTITION BY toStartOfMonth(date) 句を追加して拡張します。この句により、物件の売却月に基づいてテーブルのデータパーツが整理されます。
ClickHouse SQL Playground 上でこのテーブルに対してクエリを実行できます。
ディスク上の構造
一連の行がテーブルに挿入されるたびに、挿入されたすべての行を含む単一のデータパーツを (少なくとも1つ) 作成する代わりに (こちらで説明) 、ClickHouse は挿入された行の中の一意なパーティションキー値ごとに、新しいデータパーツを1つ作成します。
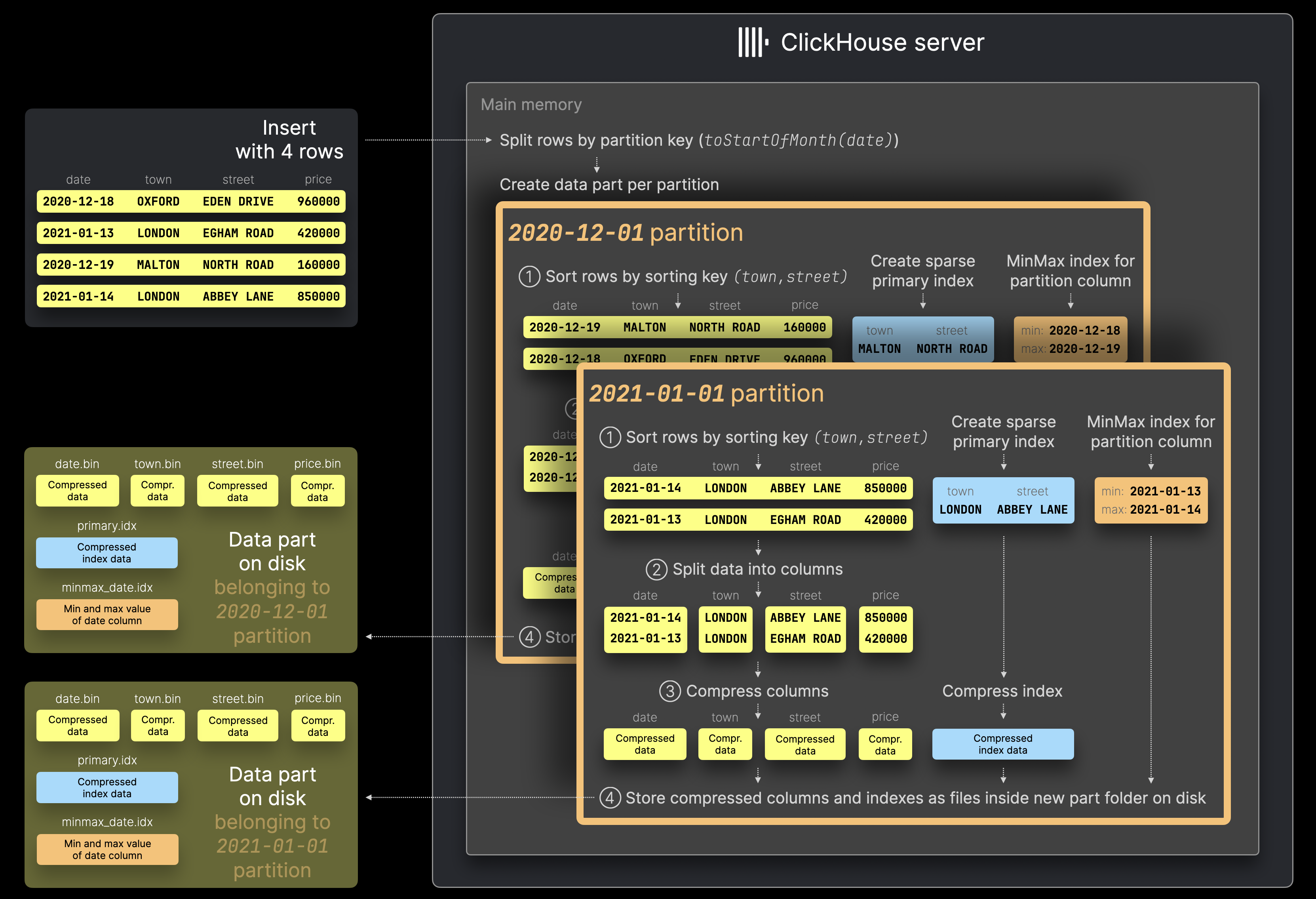
ClickHouse サーバーは、上図の例にある 4 行の挿入データを、まずパーティションキー値 toStartOfMonth(date) に基づいて分割します。
その後、特定された各パーティションごとに、行は通常どおりいくつかの連続したステップ (① ソート、② 列への分割、③ 圧縮、④ ディスクへの書き込み) で処理されます。
パーティション分割が有効な場合、ClickHouse は各データパーツに対して自動的に MinMax インデックス を作成することに注意してください。これらは、パーティションキー式で使用される各テーブル列ごとのファイルであり、そのデータパーツ内におけるその列の最小値と最大値を保持します。
パーティションごとのマージ
パーティション分割が有効になっている場合、ClickHouse はマージをパーティション内のデータパートに対してのみ行い、パーティションをまたいでは行いません。上で示した例のテーブルでは、これは次のようになります。
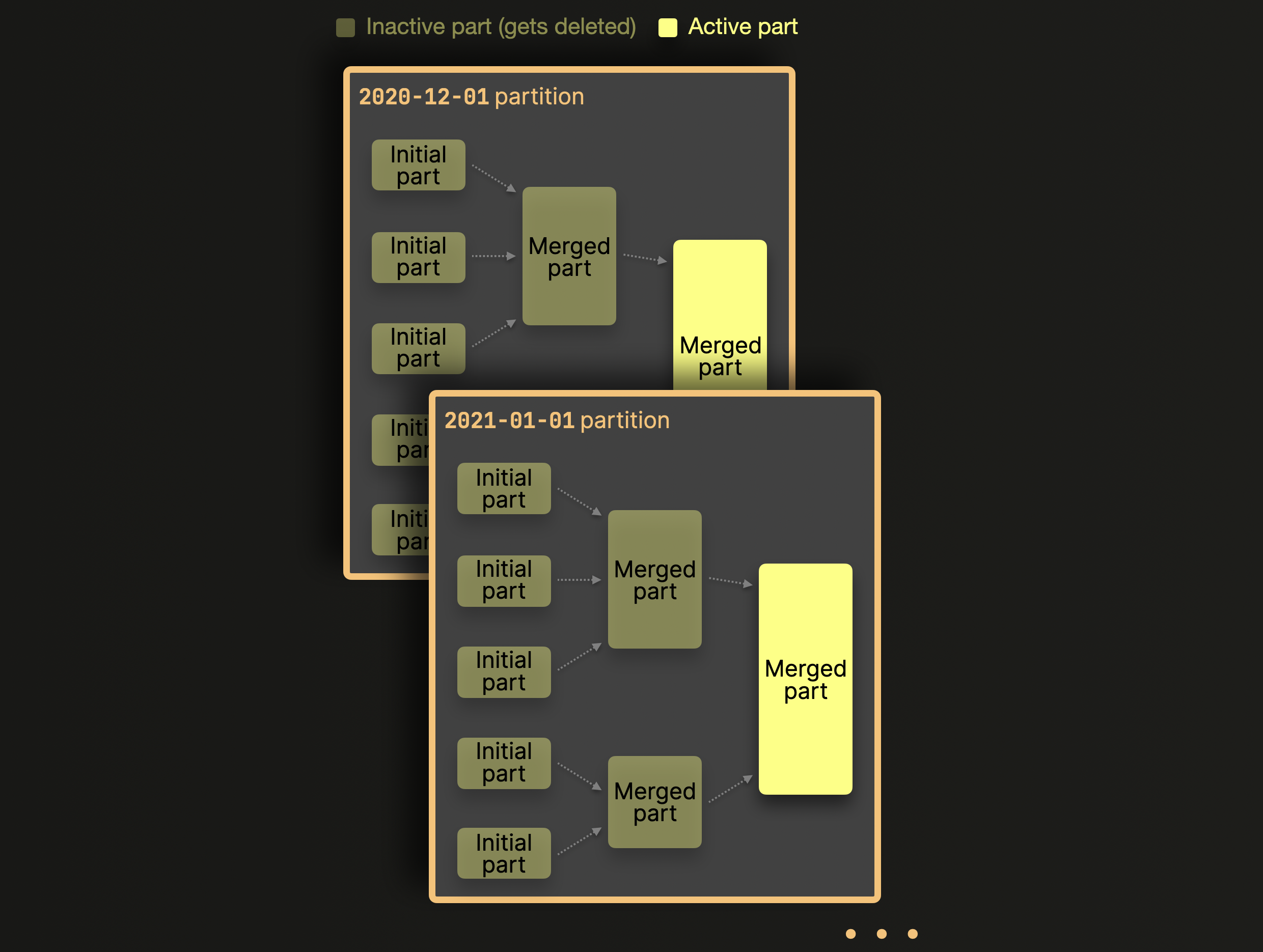
上の図に示されているように、異なるパーティションに属するパートがマージされることはありません。カーディナリティの高いパーティションキーを選択すると、何千ものパーティションにまたがって分散したパートはマージ候補になることがなく、事前設定された上限を超えて、悪名高い Too many parts エラーの原因になります。この問題への対処は簡単で、カーディナリティが 1000..10000 未満の適切なパーティションキーを選ぶだけです。
パーティションの監視
仮想列 _partition_value を使用して、サンプルテーブルに存在するすべての一意なパーティションの一覧をクエリで取得できます。
別の方法としては、ClickHouse ではすべてのテーブルのすべてのパーツとパーティションが system.parts システムテーブルで管理されており、次のクエリを実行すると、先ほどのサンプルテーブルについて、すべてのパーティションの一覧に加えて、各パーティションごとの現在アクティブなパーツ数と、それらのパーツに含まれる行数の合計が返されます:
テーブルパーティションは何のために使われますか?
データ管理
ClickHouse においてパーティションは、主にデータ管理のための機能です。パーティション式に基づいてデータを論理的に整理することで、それぞれのパーティションを個別に管理できます。例えば、上記の例のテーブルのパーティションスキームでは、TTL ルール を用いて古いデータを自動的に削除することで、メインテーブルには直近 12 か月分のデータのみを保持するといったシナリオを実現できます (DDL ステートメントに追加された最後の行を参照してください) 。
テーブルは toStartOfMonth(date) でパーティション分割されているため、TTL 条件を満たすパーティション (テーブルパーツ の集合) 全体が削除され、パーツを書き換える必要なく、クリーンアップ処理をより効率的に実行できます。
同様に、古いデータを削除する代わりに、よりコスト効率の高い ストレージ階層へ自動的かつ効率的に移動することもできます。
クエリ最適化
パーティションはクエリのパフォーマンス向上に役立つ場合がありますが、その効果はアクセスパターンに大きく依存します。クエリが少数のパーティション (理想的には 1 つ) だけを対象とする場合、パフォーマンスが向上する可能性があります。これは、以下の例のクエリに示すように、パーティションキーがプライマリキーに含まれておらず、そのキーでフィルタリングしている場合にのみ、一般的に有用です。
このクエリは、先ほどのサンプルテーブルに対して実行され、テーブルのパーティションキーに使われているカラム (date) と、テーブルの主キーに使われているカラム (town) の両方でフィルタすることで、2020 年 12 月にロンドンで売却されたすべての物件の中での最高価格を計算します (date は主キーの一部ではありません) 。
ClickHouse は、そのクエリを処理する際に、一連のプルーニング手法を適用して、関係のないデータの評価を回避します。
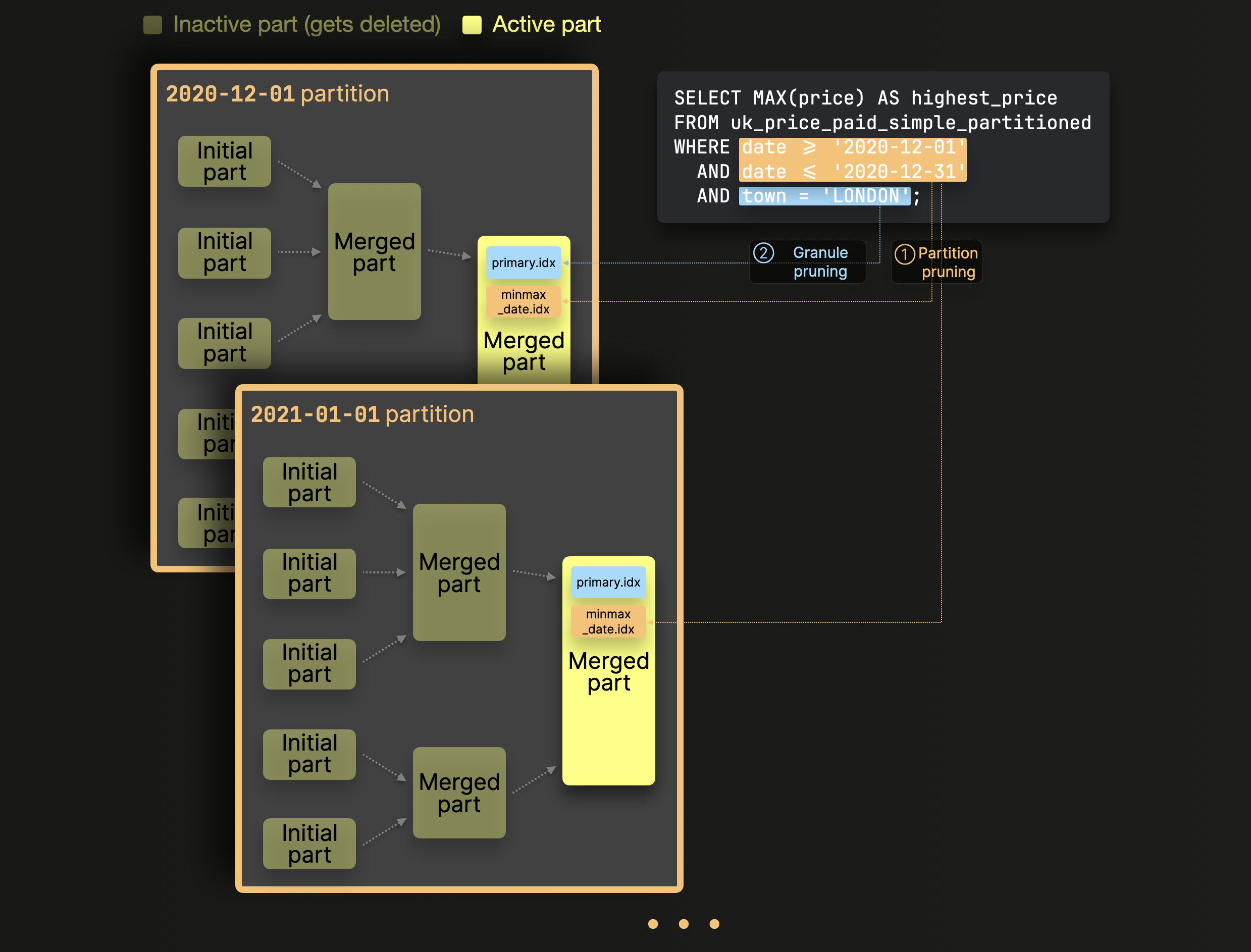
① パーティションプルーニング: MinMax インデックスを使用して、テーブルのパーティションキーに使われているカラムに対するクエリのフィルタ条件に論理的に一致し得ないパーティション (複数のパーツの集合) 全体を無視します。
② グラニュールプルーニング: 手順 ① で残ったデータパーツに対して、そのプライマリインデックスを使用し、テーブルの主キーに使われているカラムに対するクエリのフィルタ条件に論理的に一致し得ないすべてのグラニュール (行のブロック) を無視します。
これらのデータプルーニング手順は、EXPLAIN 句を使って上記のサンプルクエリの物理クエリ実行プランを確認することで観察できます。
上記の出力は次のことを示しています。
① パーティションプルーニング: 上記の EXPLAIN 出力の 7 行目から 18 行目から、ClickHouse がまず date フィールドの MinMax index を使用して、既存の 3257 個のグラニュール (行のブロック) のうち 11 個を特定していることがわかります。これらは、存在する 436 個のアクティブなデータパーツのうち 1 個に保存されており、クエリの date フィルタに一致する行を含んでいます。
② グラニュールプルーニング: 上記の EXPLAIN 出力の 19 行目から 24 行目からは、ClickHouse がステップ ① で特定されたデータパーツの primary index (town フィールドに対して作成されたもの) を使用し、 (クエリの town フィルタにも一致する可能性のある行を含む) グラニュールの数をさらに 11 個から 1 個へと絞り込んでいることが示されています。これは、先ほどクエリ実行時に表示した clickhouse-client の出力にも反映されています。
つまり、これは ClickHouse がクエリ結果を算出するために、1つのグラニュール (8192 行のブロック) を 6ミリ秒でスキャンして処理したことを意味します。
パーティション分割は主にデータ管理のための機能です
すべてのパーティションをまたいでクエリを実行する場合、通常、同じクエリを非パーティションテーブルで実行するよりも遅くなることに注意してください。
パーティション分割を行うと、データは通常、より多くのデータパーツ (data part) に分割・配置されるため、ClickHouse がスキャンおよび処理するデータ量が増える傾向があります。
これを示すために、What are table parts の例のテーブル (パーティション分割を有効にしていないもの) と、上で使用した現在の例のテーブル (パーティション分割を有効にしているもの) の両方に対して、同じクエリを実行してみます。どちらのテーブルも同じデータおよび行数を含んでいます。
しかし、パーティションが有効になっているテーブルは、このように より多くのアクティブな data parts を含みます。というのも、上で述べたとおり、ClickHouse はパーティション内の data parts だけをマージします が、パーティションをまたいではマージしないためです。
上でも示したように、パーティション分割されたテーブル uk_price_paid_simple_partitioned には 600 を超えるパーティションがあり、その結果、600,306 個のアクティブなデータパーツが存在します。一方、パーティション分割されていないテーブル uk_price_paid_simple では、すべての初期データパーツがバックグラウンドマージによって 1 つのアクティブなパーツにマージされました。
上で使用した例のクエリについて、パーティション分割されたテーブルに対してパーティションフィルタなしで実行した場合の物理クエリ実行計画を、EXPLAIN 句を用いて確認すると、下記出力の 19 行目と 20 行目から、ClickHouse が既存の 3257 個のグラニュール (行ブロック) のうち 671 個、および既存の 436 個のアクティブなデータパーツのうち 431 個を、クエリのフィルタ条件に一致する行を含む可能性があるものとして特定しており、そのためクエリエンジンによってスキャンおよび処理されることが分かります。
パーティションを持たない同じテーブル上で実行した同一の例クエリに対する物理クエリ実行プランからは、以下の出力の 11 行目と 12 行目に示されているように、ClickHouse がテーブルの単一のアクティブなデータパート内に存在する 3083 個の行ブロックのうち、クエリのフィルター条件に一致する可能性のある行を含む 241 個のブロックを特定したことが分かります。
パーティション分割されたテーブルに対してクエリを実行すると、ClickHouse は 90 ミリ秒で約 550 万行からなる 671 個のブロックをスキャンして処理します。
一方、パーティション分割されていないテーブルで同じクエリを実行すると、ClickHouse は 241 ブロック (約 200 万行) をスキャンして処理し、その所要時間は 12 ミリ秒です。
